 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ControlFlag: A Self-supervised Idiosyncratic Pattern Detection System for Software Control Structures
Nov 06, 2020
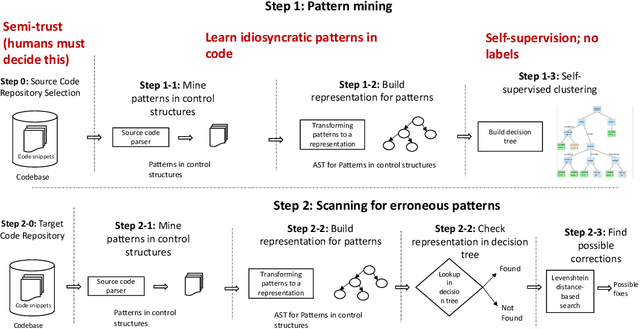

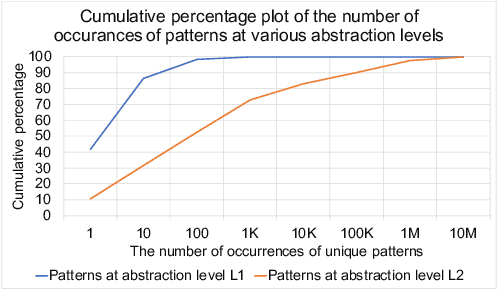

Software debugging has been shown to utilize upwards of 50% of developers' time. Machine programming, the field concerned with the automation of software (and hardware) development, has recently made progress in both research and production-quality automated debugging systems. In this paper, we present ControlFlag, a system that detects possible idiosyncratic violations in software control structures. ControlFlag also suggests possible corrections in the event a true error is detected. A novelty of ControlFlag is that it is entirely self-supervised; that is, it requires no labels to learn about the potential idiosyncratic programming pattern violations. In addition to presenting ControlFlag's design, we also provide an abbreviated experimental evaluation.
Spinal Codes Optimization: Error Probability Analysis and Transmission Scheme Design
Jan 20, 2021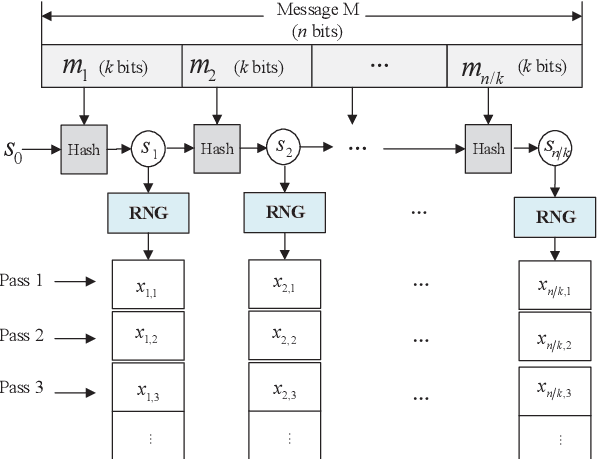

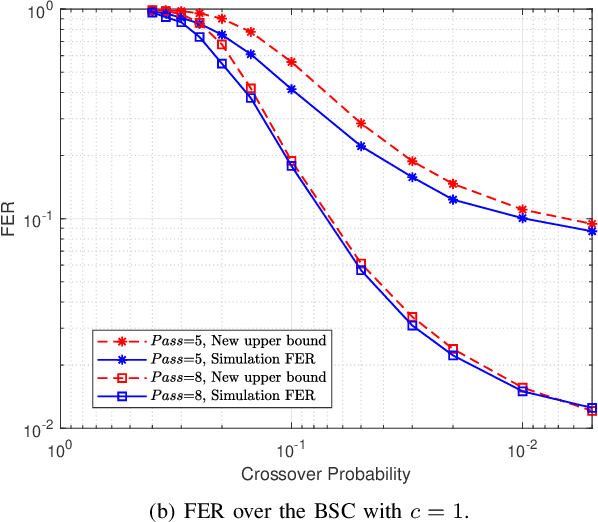
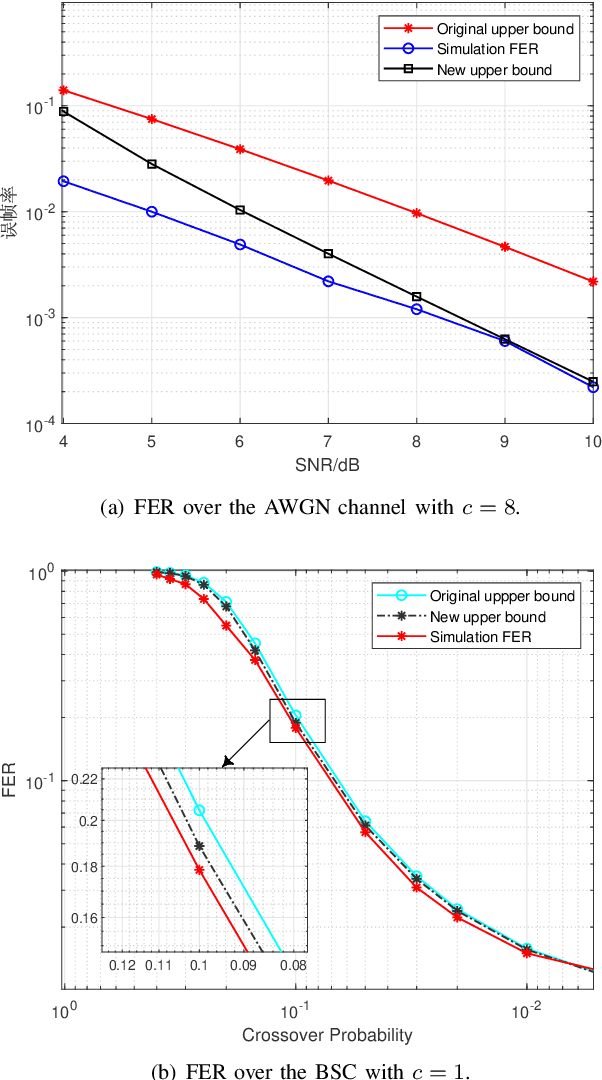
Spinal codes are known to be capacity achieving over both the additive white Gaussian noise (AWGN) channel and the binary symmetric channel (BSC). Over wireless channels, Spinal encoding can also be regarded as an adaptive-coded-modulation (ACM) technique due to its rateless property, which fits it with mobile communications. Due to lack of tight analysis on error probability of Spinal codes, optimization of transmission scheme using Spinal codes has not been fully explored. In this work, we firstly derive new tight upper bounds of the frame error rate (FER) of Spinal codes for both the AWGN channel and the BSC in the finite block-length (FBL) regime. Based on the derived upper bounds, we then design the optimal transmission scheme. Specifically, we formulate a rate maximization problem as a nonlinear integer programming problem, and solve it by an iterative algorithm for its dual problem. As the optimal solution exhibits an incremental-tail-transmission pattern, we propose an improved transmission scheme for Spinal codes. Moreover, we develop a bubble decoding with memory (BD-M) algorithm to reduce the decoding time complexity without loss of rate performance. The improved transmission scheme at the transmitter and the BD-M algorithm at the receiver jointly constitute an "encoding-decoding" system of Spinal codes. Simulation results demonstrate that it can improve both the rate performance and the decoding throughput of Spinal codes.
Non-Parallel Voice Conversion with Augmented Classifier Star Generative Adversarial Networks
Sep 02, 2020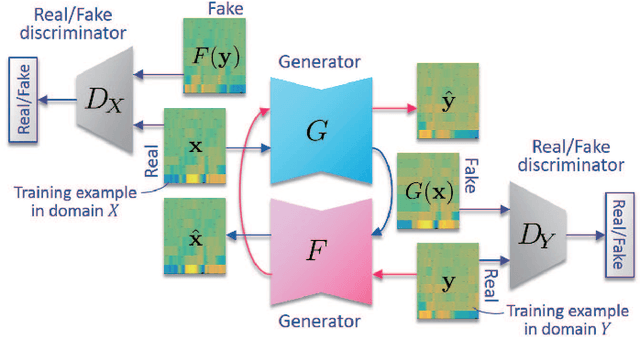
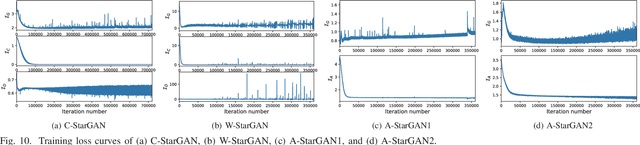
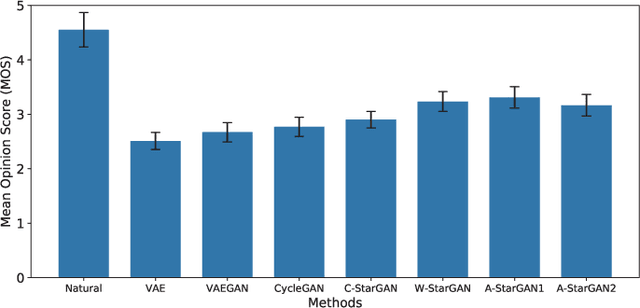
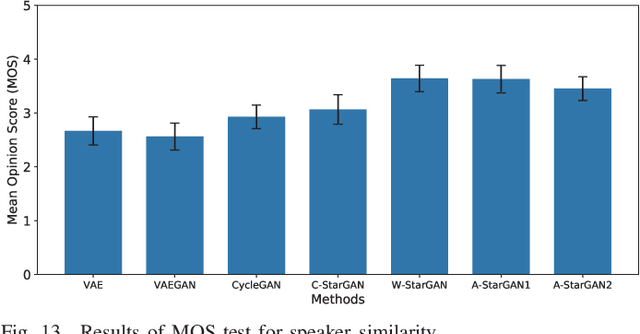
We have previously proposed a method that allows for non-parallel voice conversion (VC) by using a variant of generative adversarial networks (GANs) called StarGAN. The main features of our method, called StarGAN-VC, are as follows: First, it requires no parallel utterances, transcriptions, or time alignment procedures for speech generator training. Second, it can simultaneously learn mappings across multiple domains using a single generator network so that it can fully exploit available training data collected from multiple domains to capture latent features that are common to all the domains. Third, it is able to generate converted speech signals quickly enough to allow real-time implementations and requires only several minutes of training examples to generate reasonably realistic-sounding speech. In this paper, we describe three formulations of StarGAN, including a newly introduced novel StarGAN variant called "Augmented classifier StarGAN (A-StarGAN)", and compare them in a non-parallel VC task. We also compare them with several baseline methods.
Cross-Correlation Based Discriminant Criterion for Channel Selection in Motor Imagery BCI Systems
Dec 03, 2020Many electroencephalogram (EEG)-based brain-computer interface (BCI) systems use a large amount of channels for higher performance, which is time-consuming to set up and inconvenient for practical applications. Finding an optimal subset of channels without compromising the performance is a necessary and challenging task. In this article, we proposed a cross-correlation based discriminant criterion (XCDC) which assesses the importance of a channel for discriminating the mental states of different motor imagery (MI) tasks. The performance of XCDC is evaluated on two motor imagery EEG datasets. In both datasets, XCDC significantly reduces the amount of channels without compromising classification accuracy compared to the all-channel setups. Under the same constraint of accuracy, the proposed method requires fewer channels than existing channel selection methods based on Pearson's correlation coefficient and common spatial pattern. Visualization of XCDC shows consistent results with neurophysiological principles.
CNN Application in Detection of Privileged Documents in Legal Document Review
Feb 09, 2021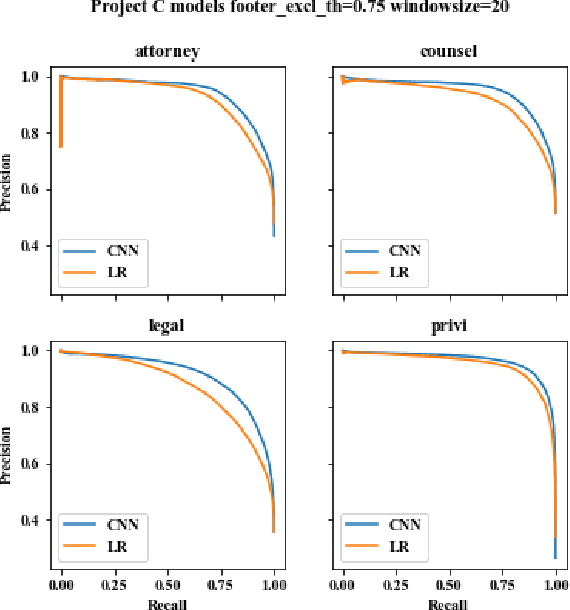
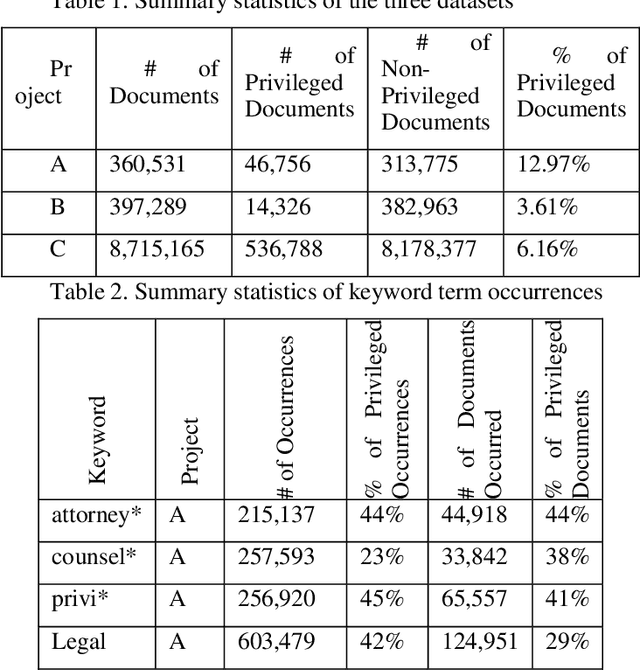
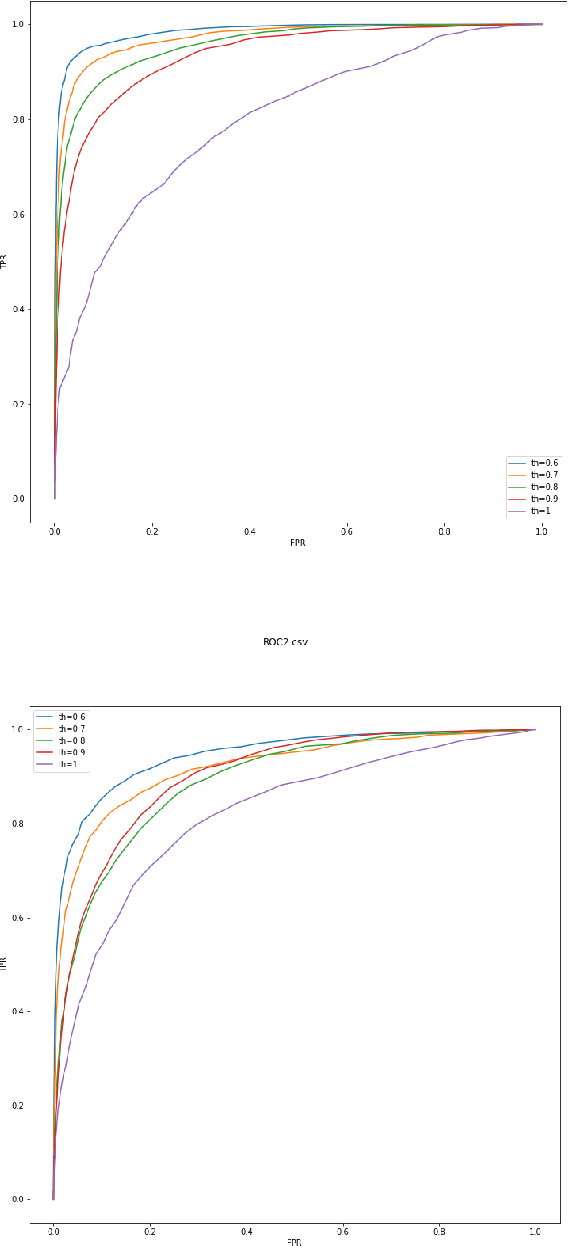
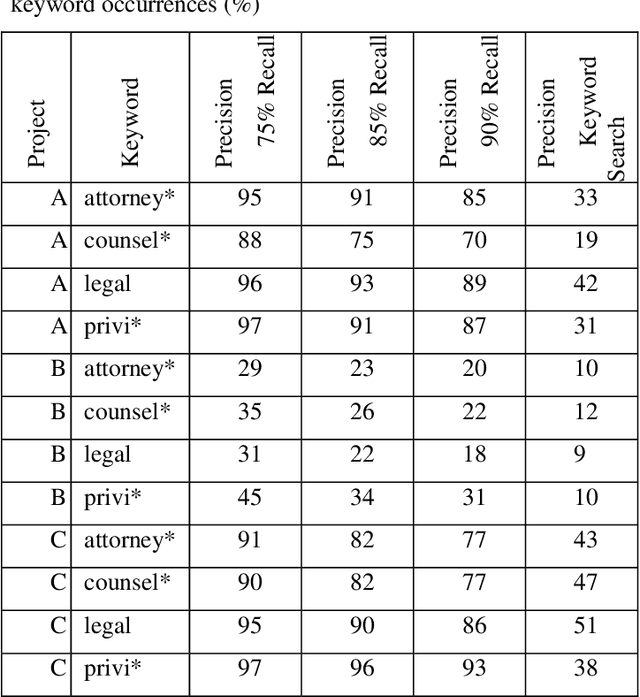
Protecting privileged communications and data from disclosure is paramount for legal teams. Legal advice, such as attorney-client communications or litigation strategy are typically exempt from disclosure in litigations or regulatory events and are vital to the attorney-client relationship. To protect this information from disclosure, companies and outside counsel often review vast amounts of documents to determine those that contain privileged material. This process is extremely costly and time consuming. As data volumes increase, legal counsel normally employs methods to reduce the number of documents requiring review while balancing the need to ensure the protection of privileged information. Keyword searching is relied upon as a method to target privileged information and reduce document review populations. Keyword searches are effective at casting a wide net but often return overly inclusive results - most of which do not contain privileged information. To overcome the weaknesses of keyword searching, legal teams increasingly are using machine learning techniques to target privileged information. In these studies, classic text classification techniques are applied to build classification models to identify privileged documents. In this paper, the authors propose a different method by applying machine learning / convolutional neural network techniques (CNN) to identify privileged documents. Our proposed method combines keyword searching with CNN. For each keyword term, a CNN model is created using the context of the occurrences of the keyword. In addition, a method was proposed to select reliable privileged (positive) training keyword occurrences from labeled positive training documents. Extensive experiments were conducted, and the results show that the proposed methods can significantly reduce false positives while still capturing most of the true positives.
Solar Coronal Magnetic Field Extrapolation from Synchronic Data with AI-generated Farside
Oct 21, 2020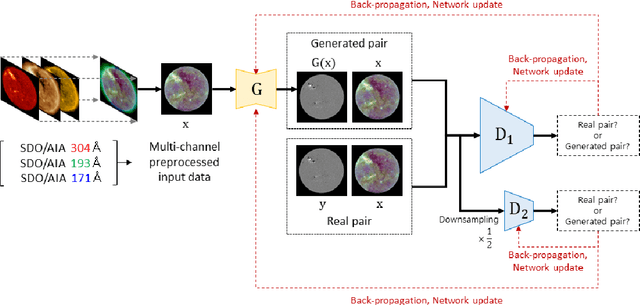
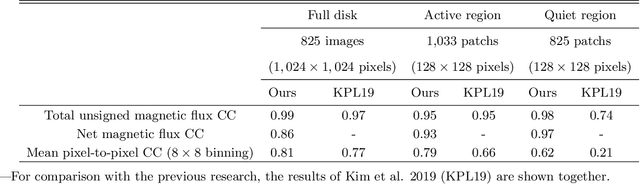
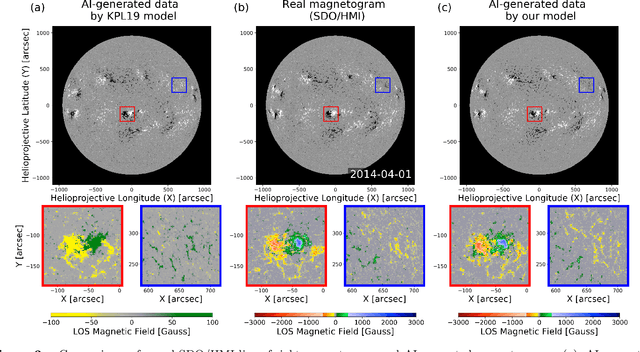
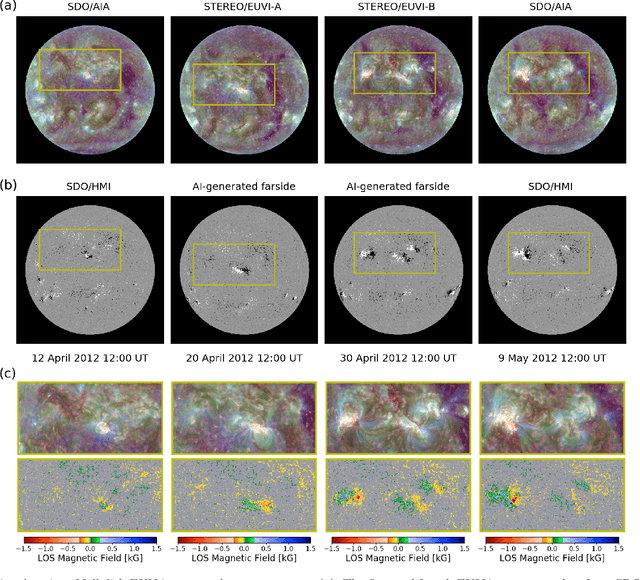
Solar magnetic fields play a key role in understanding the nature of the coronal phenomena. Global coronal magnetic fields are usually extrapolated from photospheric fields for which farside data were taken about two weeks ago when it was at the frontside. For the first time we have constructed the extrapolations of global magnetic fields using frontside and AI-generated farside magnetic fields at a near-real time basis. We generate the farside magnetograms from three channel farside observations of Solar Terrestrial Relations Observatory (STEREO) $-$Ahead (A) and $-$Behind (B) by our deep learning model trained with frontside Solar Dynamics Observatory (SDO) EUV images and magnetograms. For frontside testing data sets, we demonstrate that the generated magnetic field distributions are consistent with the real ones; not only active regions (ARs), but also quiet regions of the Sun. We make global magnetic field synchronic maps in which conventional farside data are replaced by farside ones generated by our model. The synchronic maps show much better not only the appearance of ARs but also the disappearance of others on the solar surface than before. We use these synchronized magnetic data to extrapolate the global coronal fields using Potential Field Source Surface (PFSS) model. We show that our results are much more consistent with coronal observations than those of the conventional method in view of solar active regions and coronal holes. We present several positive prospects of our new methodology for the study of solar corona, heliosphere, and space weather.
EPEM: Efficient Parameter Estimation for Multiple Class Monotone Missing Data
Sep 23, 2020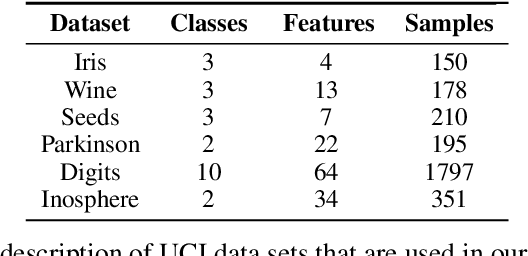
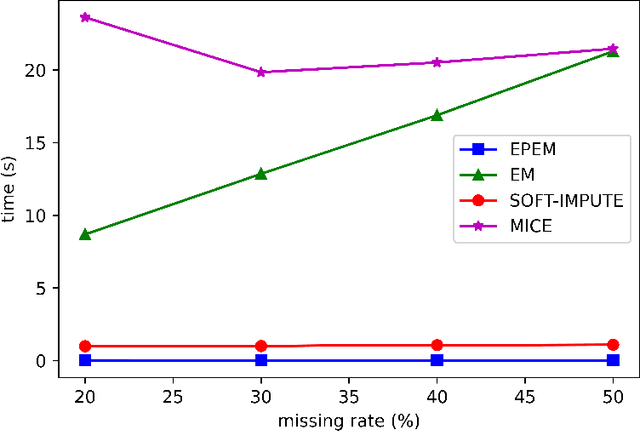

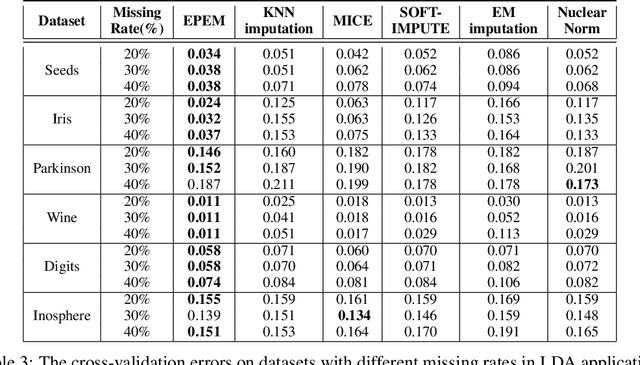
The problem of monotone missing data has been broadly studied during the last two decades and has many applications in different fields such as bioinformatics or statistics. Commonly used imputation techniques require multiple iterations through the data before yielding convergence. Moreover, those approaches may introduce extra noises and biases to the subsequent modeling. In this work, we derive exact formulas and propose a novel algorithm to compute the maximum likelihood estimators (MLEs) of a multiple class, monotone missing dataset when all the covariance matrices of all categories are assumed to be equal, namely EPEM. We then illustrate an application of our proposed methods in Linear Discriminant Analysis (LDA). As the computation is exact, our EPEM algorithm does not require multiple iterations through the data as other imputation approaches, thus promising to handle much less time-consuming than other methods. This effectiveness was validated by empirical results when EPEM reduced the error rates significantly and required a short computation time compared to several imputation-based approaches. We also release all codes and data of our experiments in one GitHub repository to contribute to the research community related to this problem.
Adversarial Attacks on Deep Algorithmic Trading Policies
Oct 22, 2020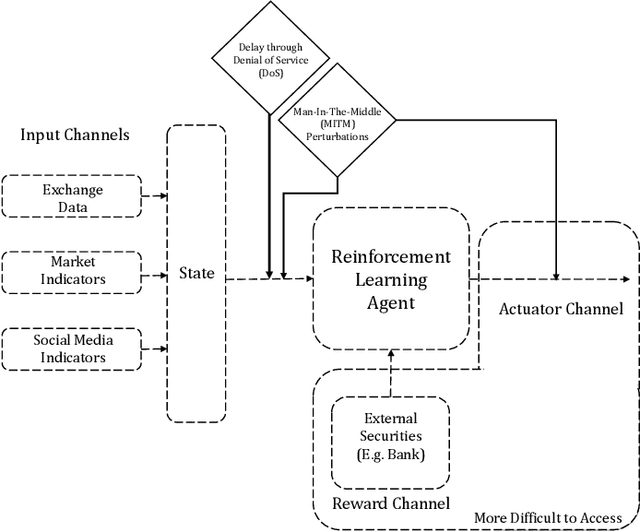

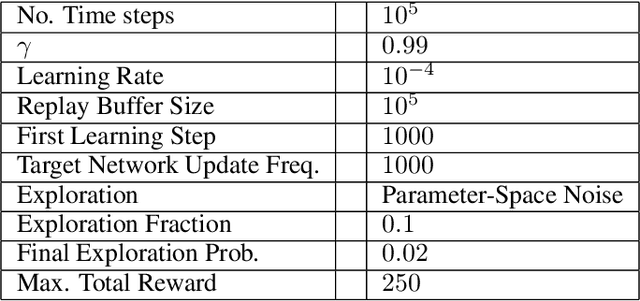
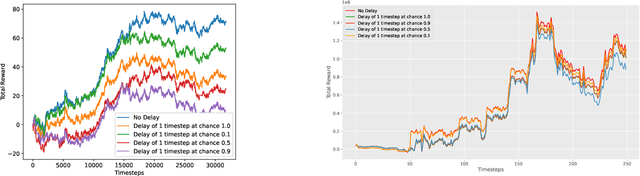
Deep Reinforcement Learning (DRL) has become an appealing solution to algorithmic trading such as high frequency trading of stocks and cyptocurrencies. However, DRL have been shown to be susceptible to adversarial attacks. It follows that algorithmic trading DRL agents may also be compromised by such adversarial techniques, leading to policy manipulation. In this paper, we develop a threat model for deep trading policies, and propose two attack techniques for manipulating the performance of such policies at test-time. Furthermore, we demonstrate the effectiveness of the proposed attacks against benchmark and real-world DQN trading agents.
ResPerfNet: Deep Residual Learning for Regressional Performance Modeling of Deep Neural Networks
Dec 03, 2020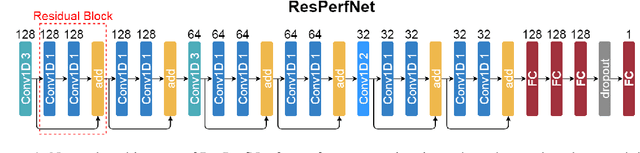

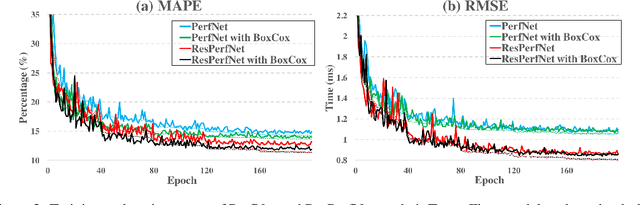

The rapid advancements of computing technology facilitate the development of diverse deep learning applications. Unfortunately, the efficiency of parallel computing infrastructures varies widely with neural network models, which hinders the exploration of the design space to find high-performance neural network architectures on specific computing platforms for a given application. To address such a challenge, we propose a deep learning-based method, ResPerfNet, which trains a residual neural network with representative datasets obtained on the target platform to predict the performance for a deep neural network. Our experimental results show that ResPerfNet can accurately predict the execution time of individual neural network layers and full network models on a variety of platforms. In particular, ResPerfNet achieves 8.4% of mean absolute percentage error for LeNet, AlexNet and VGG16 on the NVIDIA GTX 1080Ti, which is substantially lower than the previously published works.
Online Forgetting Process for Linear Regression Models
Dec 03, 2020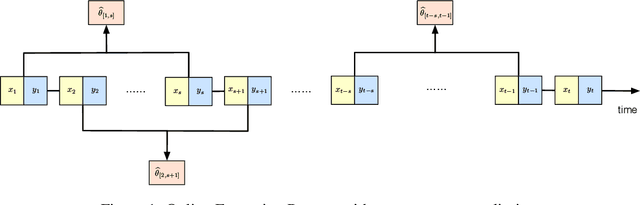
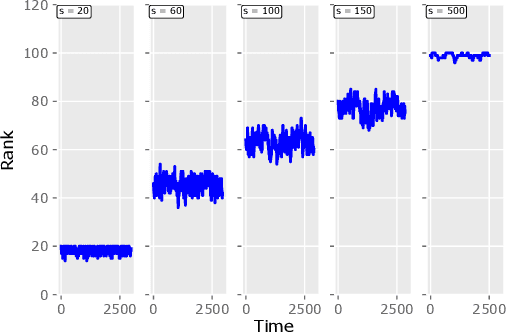
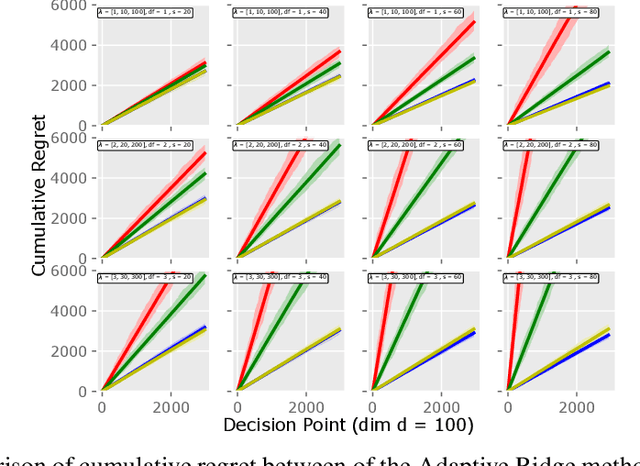
Motivated by the EU's "Right To Be Forgotten" regulation, we initiate a study of statistical data deletion problems where users' data are accessible only for a limited period of time. This setting is formulated as an online supervised learning task with \textit{constant memory limit}. We propose a deletion-aware algorithm \texttt{FIFD-OLS} for the low dimensional case, and witness a catastrophic rank swinging phenomenon due to the data deletion operation, which leads to statistical inefficiency. As a remedy, we propose the \texttt{FIFD-Adaptive Ridge} algorithm with a novel online regularization scheme, that effectively offsets the uncertainty from deletion. In theory, we provide the cumulative regret upper bound for both online forgetting algorithms. In the experiment, we showed \texttt{FIFD-Adaptive Ridge} outperforms the ridge regression algorithm with fixed regularization level, and hopefully sheds some light on more complex statistical models.