 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Super-Human Performance in Gran Turismo Sport Using Deep Reinforcement Learning
Aug 18, 2020
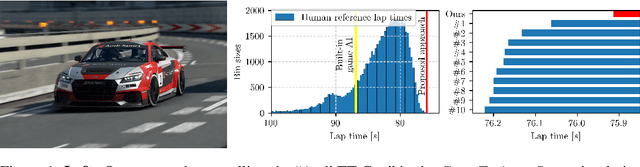

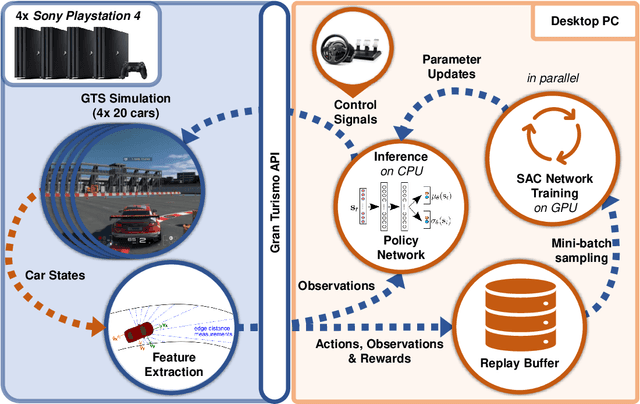

Autonomous car racing raises fundamental robotics challenges such as planning minimum-time trajectories under uncertain dynamics and controlling the car at its friction limits. In this project, we consider the task of autonomous car racing in the top-selling car racing game Gran Turismo Sport. Gran Turismo Sport is known for its detailed physics simulation of various cars and tracks. Our approach makes use of maximum-entropy deep reinforcement learning and a new reward design to train a sensorimotor policy to complete a given race track as fast as possible. We evaluate our approach in three different time trial settings with different cars and tracks. Our results show that the obtained controllers not only beat the built-in non-player character of Gran Turismo Sport, but also outperform the fastest known times in a dataset of personal best lap times of over 50,000 human drivers.
Accurate and Scalable Matching of Translators to Displaced Persons for Overcoming Language Barriers
Nov 30, 2020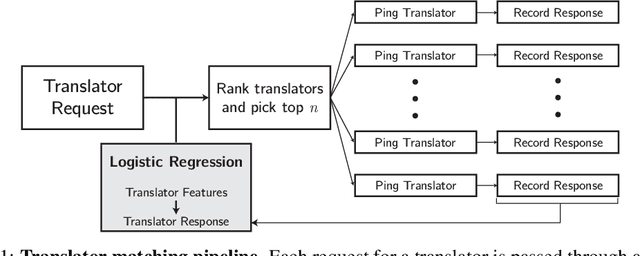
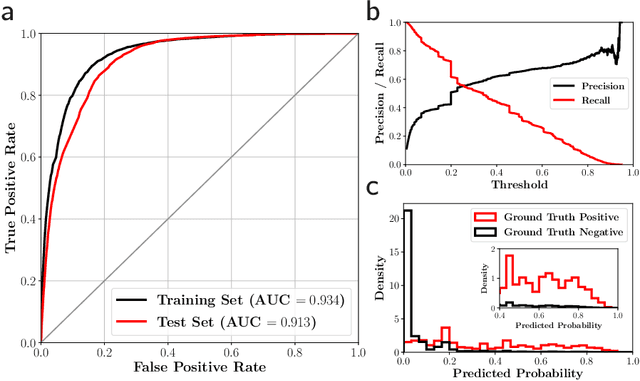
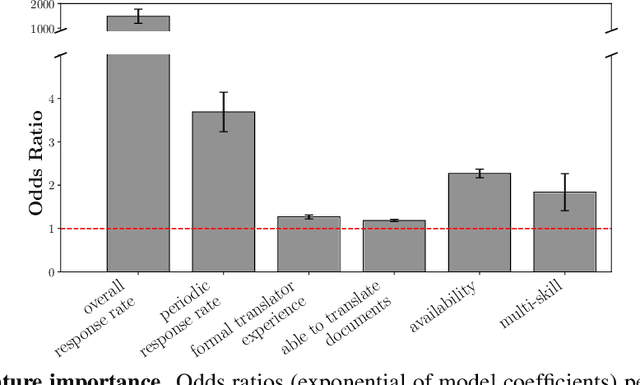
Residents of developing countries are disproportionately susceptible to displacement as a result of humanitarian crises. During such crises, language barriers impede aid workers in providing services to those displaced. To build resilience, such services must be flexible and robust to a host of possible languages. \textit{Tarjimly} aims to overcome the barriers by providing a platform capable of matching bilingual volunteers to displaced persons or aid workers in need of translating. However, Tarjimly's large pool of translators comes with the challenge of selecting the right translator per request. In this paper, we describe a machine learning system that matches translator requests to volunteers at scale. We demonstrate that a simple logistic regression, operating on easily computable features, can accurately predict and rank translator response. In deployment, this lightweight system matches 82\% of requests with a median response time of 59 seconds, allowing aid workers to accelerate their services supporting displaced persons.
Polyblur: Removing mild blur by polynomial reblurring
Dec 16, 2020

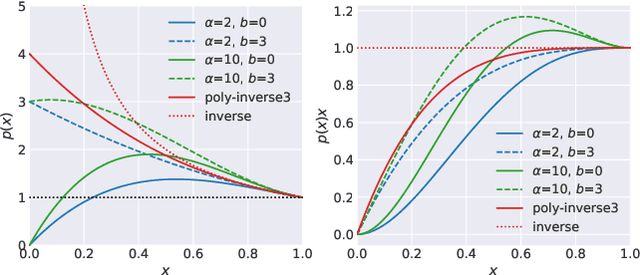
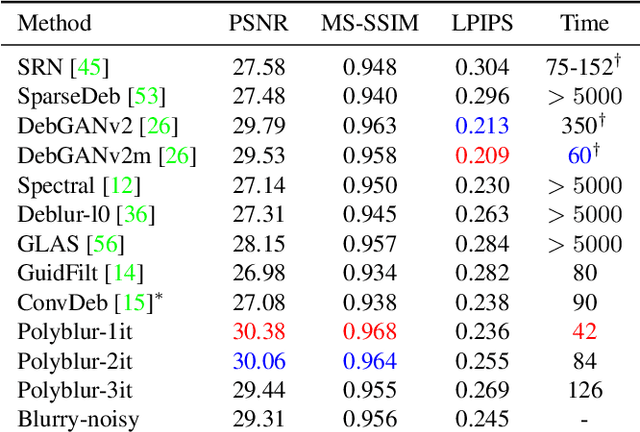
We present a highly efficient blind restoration method to remove mild blur in natural images. Contrary to the mainstream, we focus on removing slight blur that is often present, damaging image quality and commonly generated by small out-of-focus, lens blur, or slight camera motion. The proposed algorithm first estimates image blur and then compensates for it by combining multiple applications of the estimated blur in a principled way. To estimate blur we introduce a simple yet robust algorithm based on empirical observations about the distribution of the gradient in sharp natural images. Our experiments show that, in the context of mild blur, the proposed method outperforms traditional and modern blind deblurring methods and runs in a fraction of the time. Our method can be used to blindly correct blur before applying off-the-shelf deep super-resolution methods leading to superior results than other highly complex and computationally demanding techniques. The proposed method estimates and removes mild blur from a 12MP image on a modern mobile phone in a fraction of a second.
ImageCHD: A 3D Computed Tomography Image Dataset for Classification of Congenital Heart Disease
Jan 26, 2021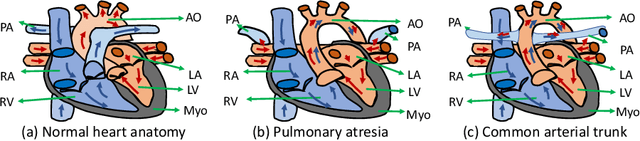
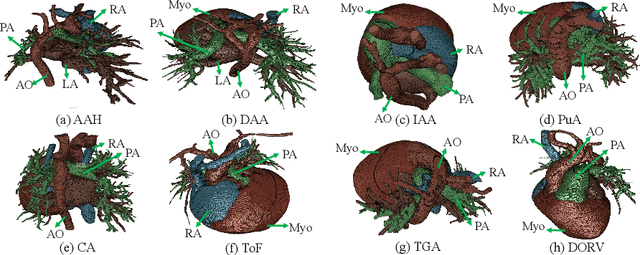
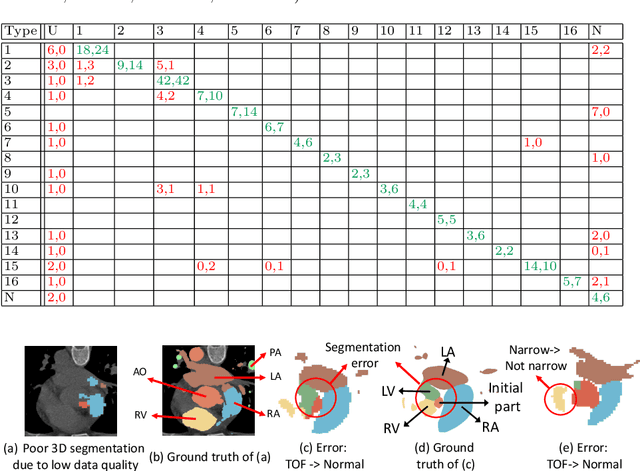
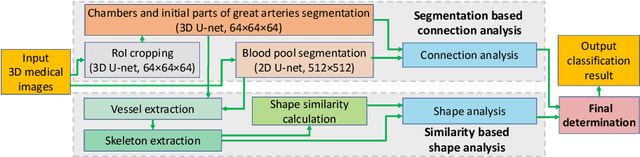
Congenital heart disease (CHD) is the most common type of birth defect, which occurs 1 in every 110 births in the United States. CHD usually comes with severe variations in heart structure and great artery connections that can be classified into many types. Thus highly specialized domain knowledge and the time-consuming human process is needed to analyze the associated medical images. On the other hand, due to the complexity of CHD and the lack of dataset, little has been explored on the automatic diagnosis (classification) of CHDs. In this paper, we present ImageCHD, the first medical image dataset for CHD classification. ImageCHD contains 110 3D Computed Tomography (CT) images covering most types of CHD, which is of decent size Classification of CHDs requires the identification of large structural changes without any local tissue changes, with limited data. It is an example of a larger class of problems that are quite difficult for current machine-learning-based vision methods to solve. To demonstrate this, we further present a baseline framework for the automatic classification of CHD, based on a state-of-the-art CHD segmentation method. Experimental results show that the baseline framework can only achieve a classification accuracy of 82.0\% under a selective prediction scheme with 88.4\% coverage, leaving big room for further improvement. We hope that ImageCHD can stimulate further research and lead to innovative and generic solutions that would have an impact in multiple domains. Our dataset is released to the public compared with existing medical imaging datasets.
Dirichlet policies for reinforced factor portfolios
Nov 12, 2020

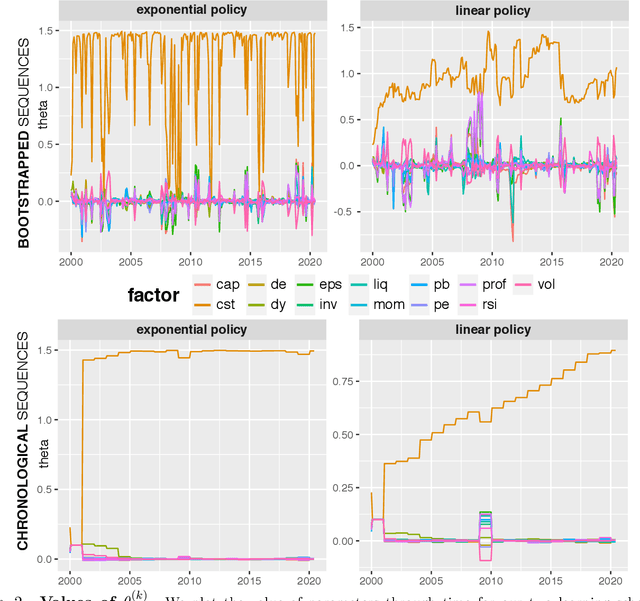
This article aims to combine factor investing and reinforcement learning (RL). The agent learns through sequential random allocations which rely on firms' characteristics. Using Dirichlet distributions as the driving policy, we derive closed forms for the policy gradients and analytical properties of the performance measure. This enables the implementation of REINFORCE methods, which we perform on a large dataset of US equities. Across a large range of implementation choices, our result indicates that RL-based portfolios are very close to the equally-weighted (1/N) allocation. This implies that the agent learns to be agnostic with regard to factors. This is partly consistent with cross-sectional regressions showing a strong time variation in the relationship between returns and firm characteristics.
In-N-Out: Pre-Training and Self-Training using Auxiliary Information for Out-of-Distribution Robustness
Dec 16, 2020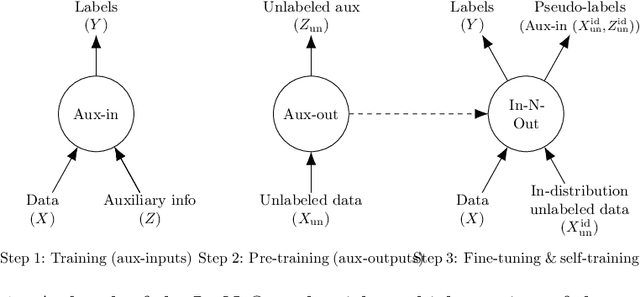
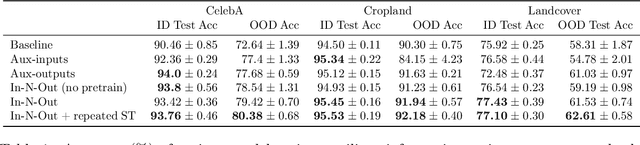

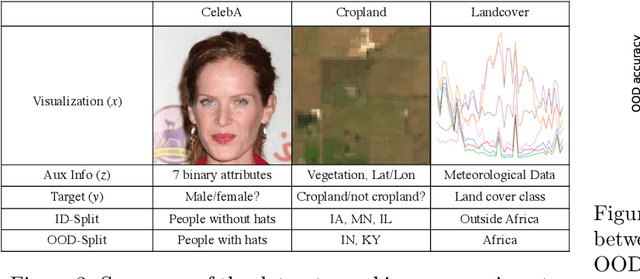
Consider a prediction setting where a few inputs (e.g., satellite images) are expensively annotated with the prediction targets (e.g., crop types), and many inputs are cheaply annotated with auxiliary information (e.g., climate information). How should we best leverage this auxiliary information for the prediction task? Empirically across three image and time-series datasets, and theoretically in a multi-task linear regression setting, we show that (i) using auxiliary information as input features improves in-distribution error but can hurt out-of-distribution (OOD) error; while (ii) using auxiliary information as outputs of auxiliary tasks to pre-train a model improves OOD error. To get the best of both worlds, we introduce In-N-Out, which first trains a model with auxiliary inputs and uses it to pseudolabel all the in-distribution inputs, then pre-trains a model on OOD auxiliary outputs and fine-tunes this model with the pseudolabels (self-training). We show both theoretically and empirically that In-N-Out outperforms auxiliary inputs or outputs alone on both in-distribution and OOD error.
Generating Knowledge Graphs by Employing Natural Language Processing and Machine Learning Techniques within the Scholarly Domain
Oct 28, 2020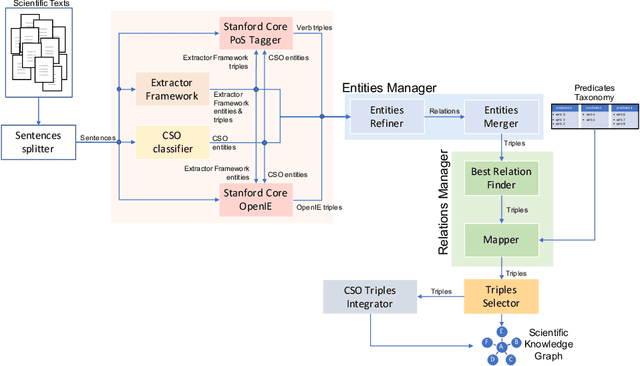
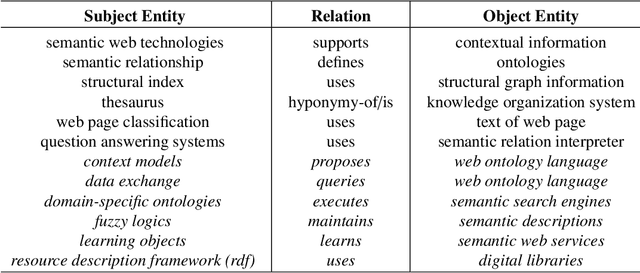
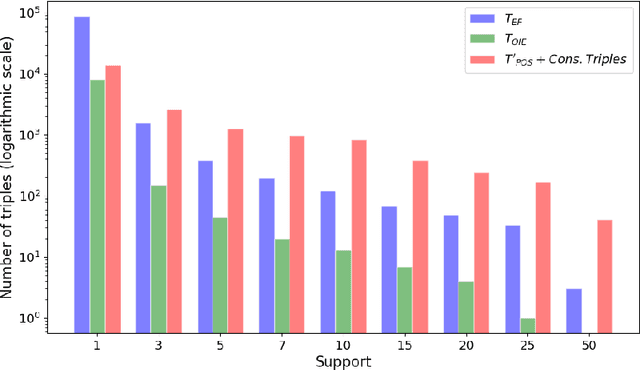
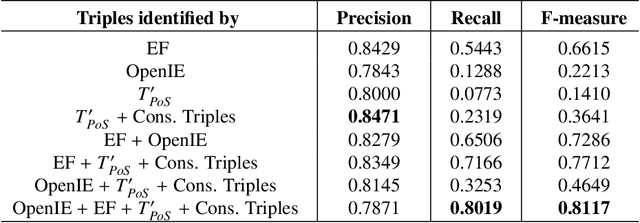
The continuous growth of scientific literature brings innovations and, at the same time, raises new challenges. One of them is related to the fact that its analysis has become difficult due to the high volume of published papers for which manual effort for annotations and management is required. Novel technological infrastructures are needed to help researchers, research policy makers, and companies to time-efficiently browse, analyse, and forecast scientific research. Knowledge graphs i.e., large networks of entities and relationships, have proved to be effective solution in this space. Scientific knowledge graphs focus on the scholarly domain and typically contain metadata describing research publications such as authors, venues, organizations, research topics, and citations. However, the current generation of knowledge graphs lacks of an explicit representation of the knowledge presented in the research papers. As such, in this paper, we present a new architecture that takes advantage of Natural Language Processing and Machine Learning methods for extracting entities and relationships from research publications and integrates them in a large-scale knowledge graph. Within this research work, we i) tackle the challenge of knowledge extraction by employing several state-of-the-art Natural Language Processing and Text Mining tools, ii) describe an approach for integrating entities and relationships generated by these tools, iii) show the advantage of such an hybrid system over alternative approaches, and vi) as a chosen use case, we generated a scientific knowledge graph including 109,105 triples, extracted from 26,827 abstracts of papers within the Semantic Web domain. As our approach is general and can be applied to any domain, we expect that it can facilitate the management, analysis, dissemination, and processing of scientific knowledge.
Twitter Subjective Well-Being Indicator During COVID-19 Pandemic: A Cross-Country Comparative Study
Jan 19, 2021
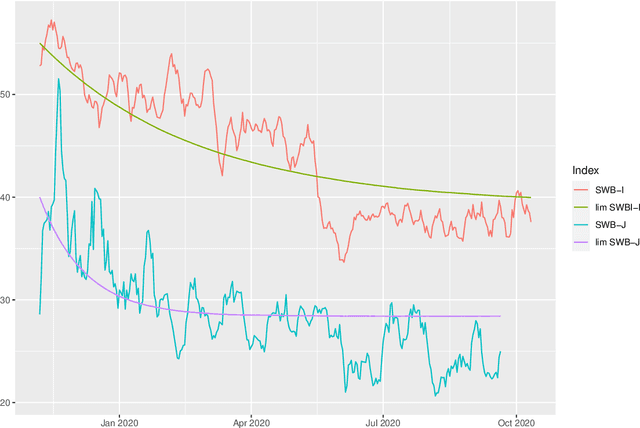
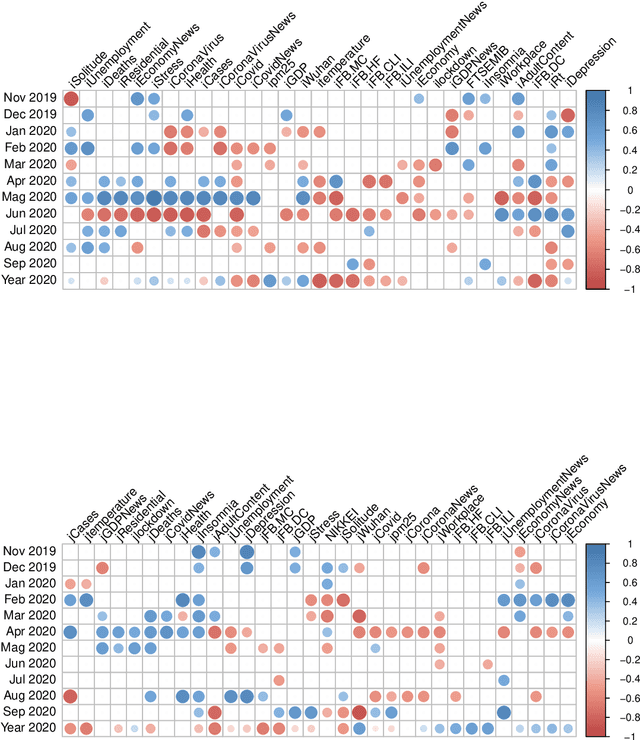

This study analyzes the impact of the COVID-19 pandemic on the subjective well-being as measured through Twitter data indicators for Japan and Italy. It turns out that, overall, the subjective well-being dropped by 11.7% for Italy and 8.3% for Japan in the first nine months of 2020 compared to the last two months of 2019 and even more compared to the historical mean of the indexes. Through a data science approach we try to identify the possible causes of this drop down by considering several explanatory variables including, climate and air quality data, number of COVID-19 cases and deaths, Facebook Covid and flu symptoms global survey, Google Trends data and coronavirus-related searches, Google mobility data, policy intervention measures, economic variables and their Google Trends proxies, as well as health and stress proxy variables based on big data. We show that a simple static regression model is not able to capture the complexity of well-being and therefore we propose a dynamic elastic net approach to show how different group of factors may impact the well-being in different periods, even over a short time length, and showing further country-specific aspects. Finally, a structural equation modeling analysis tries to address the causal relationships among the COVID-19 factors and subjective well-being showing that, overall, prolonged mobility restrictions,flu and Covid-like symptoms, economic uncertainty, social distancing and news about the pandemic have negative effects on the subjective well-being.
Contract Scheduling With Predictions
Nov 24, 2020
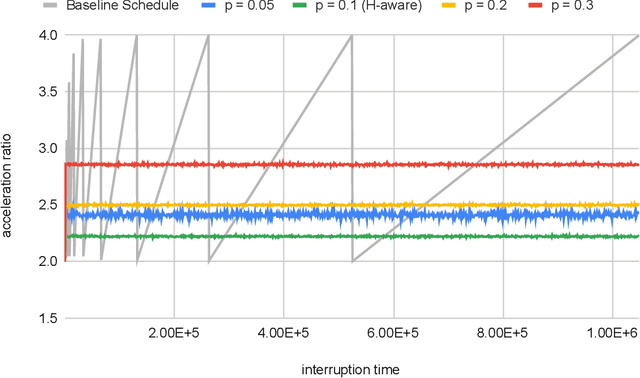
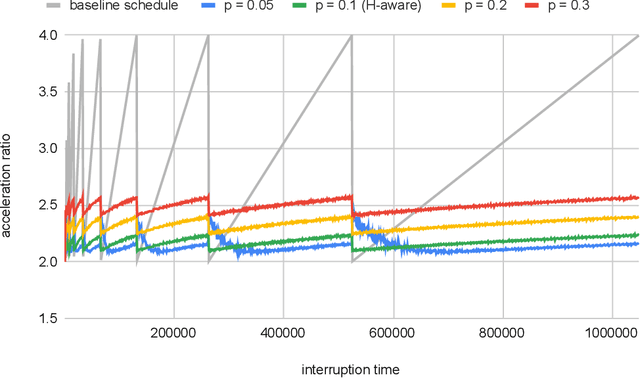

Contract scheduling is a general technique that allows to design a system with interruptible capabilities, given an algorithm that is not necessarily interruptible. Previous work on this topic has largely assumed that the interruption is a worst-case deadline that is unknown to the scheduler. In this work, we study the setting in which there is a potentially erroneous prediction concerning the interruption. Specifically, we consider the setting in which the prediction describes the time that the interruption occurs, as well as the setting in which the prediction is obtained as a response to a single or multiple binary queries. For both settings, we investigate tradeoffs between the robustness (i.e., the worst-case performance assuming adversarial prediction) and the consistency (i.e, the performance assuming that the prediction is error-free), both from the side of positive and negative results.
Distributed Infrastructure Inspection Path Planning subject to Time Constraints
Dec 25, 2016
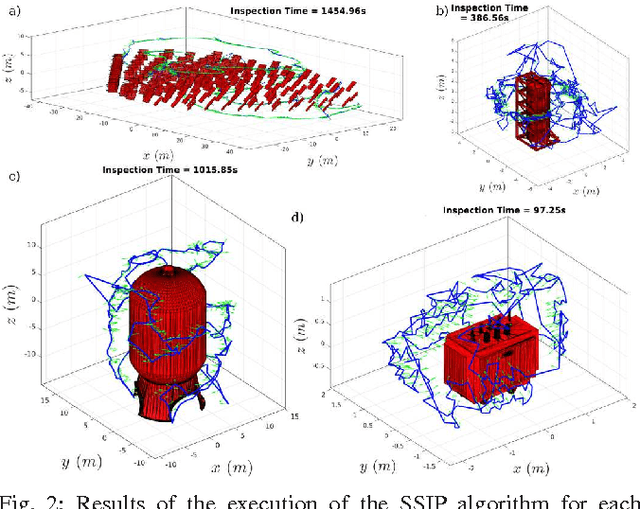
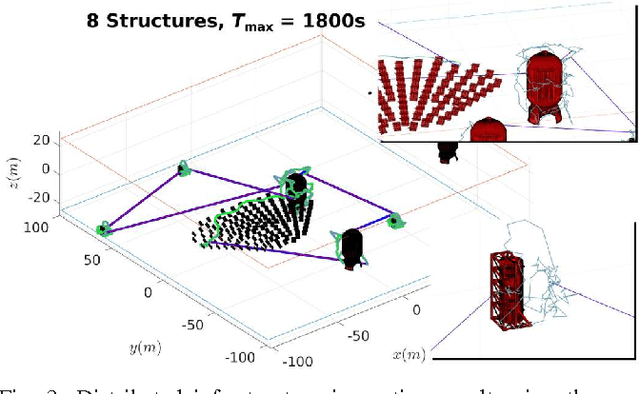
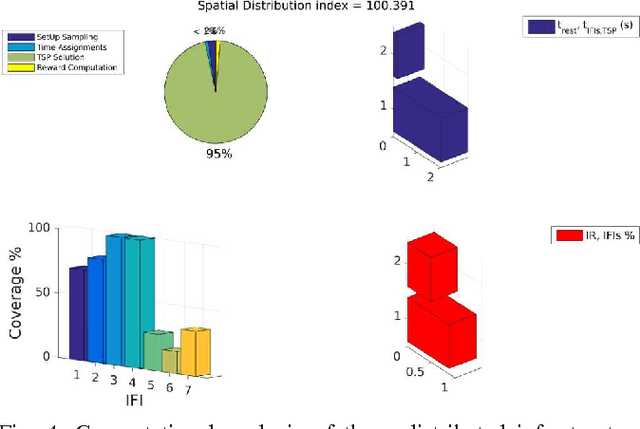
Within this paper, the problem of 3D structural inspection path planning for distributed infrastructure using aerial robots that are subject to time constraints is addressed. The proposed algorithm handles varying spatial properties of the infrastructure facilities, accounts for their different importance and exploration function and computes an overall inspection path of high inspection reward while respecting the robot endurance or mission time constraints as well as the vehicle dynamics and sensor limitations. To achieve its goal, it employs an iterative, 3-step optimization strategy at each iteration of which it first randomly samples a set of possible structures to visit, subsequently solves the derived traveling salesman problem and computes the travel costs, while finally it samples and assigns inspection times to each structure and evaluates the total inspection reward. For the derivation of the inspection paths per each independent facility, it interfaces a path planner dedicated to the 3D coverage of single structures. The resulting algorithm properties, computational performance and path quality are evaluated using simulation studies as well as experimental test-cases employing a multirotor micro aerial vehicle.