 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generating Large-Scale Trajectories Efficiently using Double Descriptions of Polynomials
Nov 06, 2020

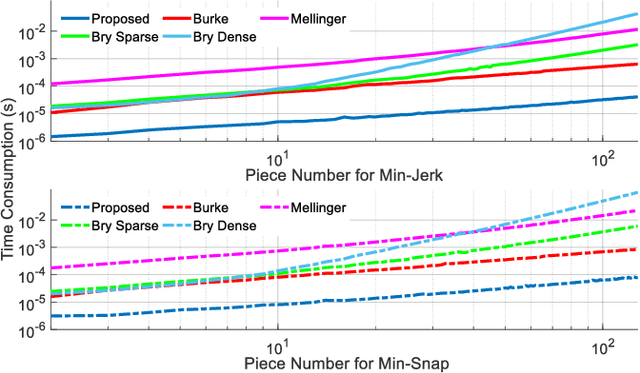
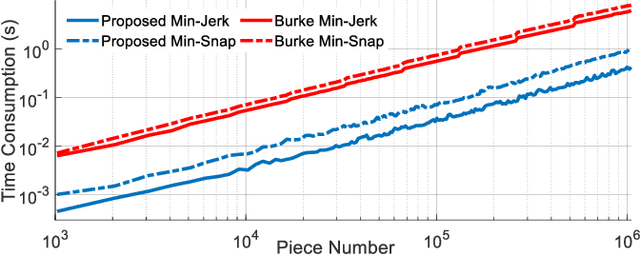
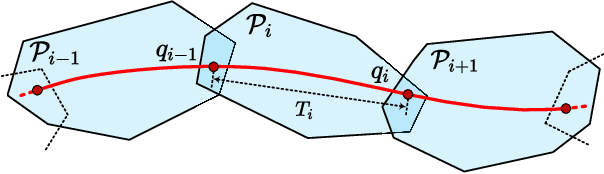
For quadrotor trajectory planning, describing a polynomial trajectory through coefficients and end-derivatives both enjoy their own convenience in energy minimization. We name them double descriptions of polynomial trajectories. The transformation between them, causing most of the inefficiency and instability, is formally analyzed in this paper. Leveraging its analytic structure, we design a linear-complexity scheme for both jerk/snap minimization and parameter gradient evaluation, which possesses efficiency, stability, flexibility, and scalability. With the help of our scheme, generating an energy optimal (minimum snap) trajectory only costs 1 $\mu s$ per piece at the scale up to 1,000,000 pieces. Moreover, generating large-scale energy-time optimal trajectories is also accelerated by an order of magnitude against conventional methods.
Improved Runtime Results for Simple Randomised Search Heuristics on Linear Functions with a Uniform Constraint
Oct 21, 2020In the last decade remarkable progress has been made in development of suitable proof techniques for analysing randomised search heuristics. The theoretical investigation of these algorithms on classes of functions is essential to the understanding of the underlying stochastic process. Linear functions have been traditionally studied in this area resulting in tight bounds on the expected optimisation time of simple randomised search algorithms for this class of problems. Recently, the constrained version of this problem has gained attention and some theoretical results have also been obtained on this class of problems. In this paper we study the class of linear functions under uniform constraint and investigate the expected optimisation time of Randomised Local Search (RLS) and a simple evolutionary algorithm called (1+1) EA. We prove a tight bound of $\Theta(n^2)$ for RLS and improve the previously best known upper bound of (1+1) EA from $O(n^2 \log (Bw_{\max}))$ to $O(n^2\log B)$ in expectation and to $O(n^2 \log n)$ with high probability, where $w_{\max}$ and $B$ are the maximum weight of the linear objective function and the bound of the uniform constraint, respectively. Also, we obtain a tight bound of $O(n^2)$ for the (1+1) EA on a special class of instances. We complement our theoretical studies by experimental investigations that consider different values of $B$ and also higher mutation rates that reflect the fact that $2$-bit flips are crucial for dealing with the uniform constraint.
Neural Stochastic Contraction Metrics for Robust Control and Estimation
Nov 06, 2020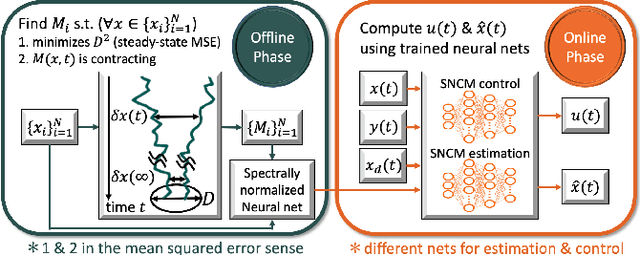
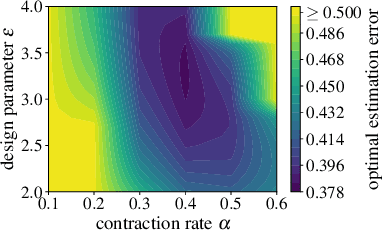
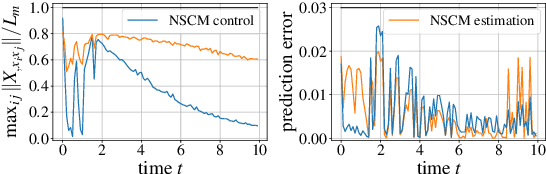
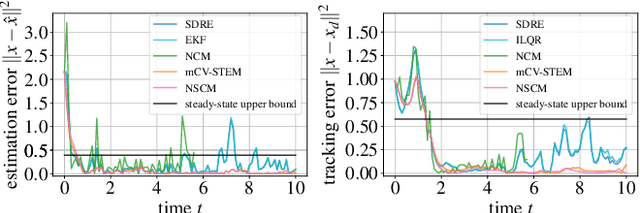
We present neural stochastic contraction metrics, a new design framework for provably-stable robust control and estimation for a class of stochastic nonlinear systems. It exploits a spectrally-normalized deep neural network to construct a contraction metric, sampled via simplified convex optimization in the stochastic setting. Spectral normalization constrains the state-derivatives of the metric to be Lipschitz continuous, and thereby ensures exponential boundedness of the mean squared distance of system trajectories under stochastic disturbances. This framework allows autonomous agents to approximate optimal stable control and estimation policies in real-time, and outperforms existing nonlinear control and estimation techniques including the state-dependent Riccati equation, iterative LQR, EKF, and deterministic neural contraction metric method, as illustrated in simulations.
Low Bandwidth Video-Chat Compression using Deep Generative Models
Dec 01, 2020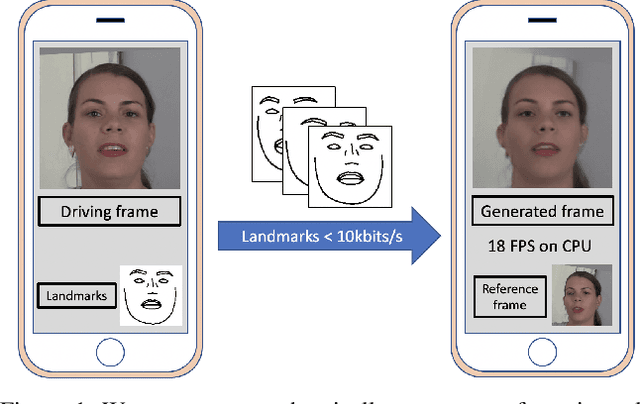
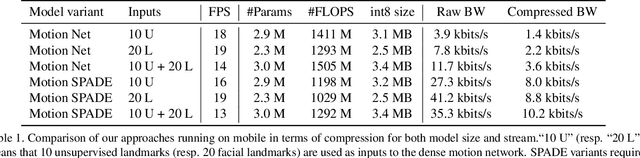
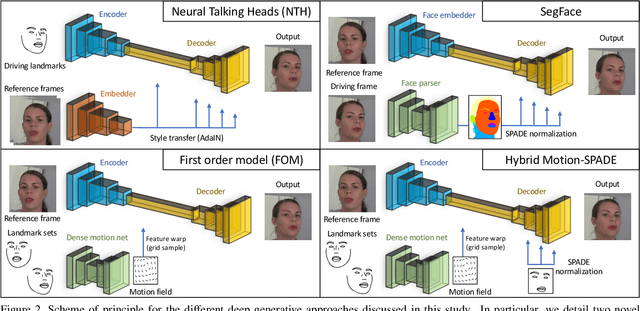
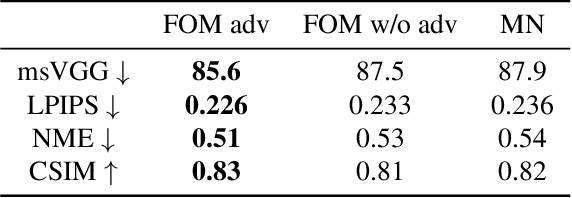
To unlock video chat for hundreds of millions of people hindered by poor connectivity or unaffordable data costs, we propose to authentically reconstruct faces on the receiver's device using facial landmarks extracted at the sender's side and transmitted over the network. In this context, we discuss and evaluate the benefits and disadvantages of several deep adversarial approaches. In particular, we explore quality and bandwidth trade-offs for approaches based on static landmarks, dynamic landmarks or segmentation maps. We design a mobile-compatible architecture based on the first order animation model of Siarohin et al. In addition, we leverage SPADE blocks to refine results in important areas such as the eyes and lips. We compress the networks down to about 3MB, allowing models to run in real time on iPhone 8 (CPU). This approach enables video calling at a few kbits per second, an order of magnitude lower than currently available alternatives.
Selection of Summary Statistics for Network Model Choice with Approximate Bayesian Computation
Jan 19, 2021
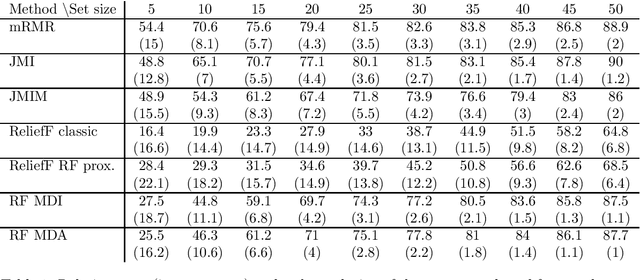
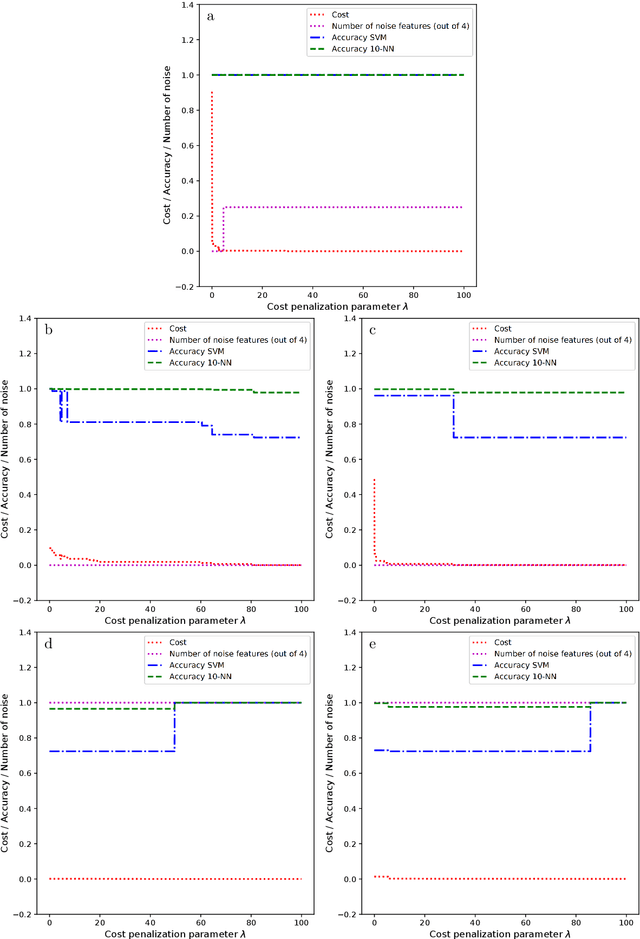
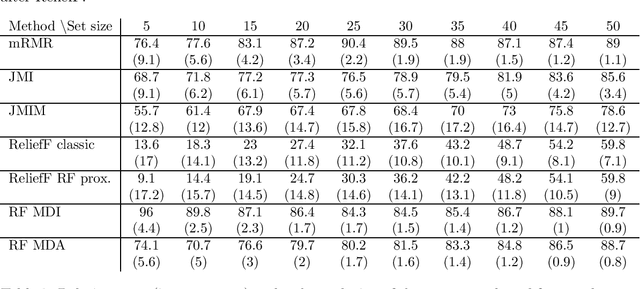
Approximate Bayesian Computation (ABC) now serves as one of the major strategies to perform model choice and parameter inference on models with intractable likelihoods. An essential component of ABC involves comparing a large amount of simulated data with the observed data through summary statistics. To avoid the curse of dimensionality, summary statistic selection is of prime importance, and becomes even more critical when applying ABC to mechanistic network models. Indeed, while many summary statistics can be used to encode network structures, their computational complexity can be highly variable. For large networks, computation of summary statistics can quickly create a bottleneck, making the use of ABC difficult. To reduce this computational burden and make the analysis of mechanistic network models more practical, we investigated two questions in a model choice framework. First, we studied the utility of cost-based filter selection methods to account for different summary costs during the selection process. Second, we performed selection using networks generated with a smaller number of nodes to reduce the time required for the selection step. Our findings show that computationally inexpensive summary statistics can be efficiently selected with minimal impact on classification accuracy. Furthermore, we found that networks with a smaller number of nodes can only be employed to eliminate a moderate number of summaries. While this latter finding is network specific, the former is general and can be adapted to any ABC application.
ImageCHD: A 3D Computed Tomography Image Dataset for Classification of Congenital Heart Disease
Jan 26, 2021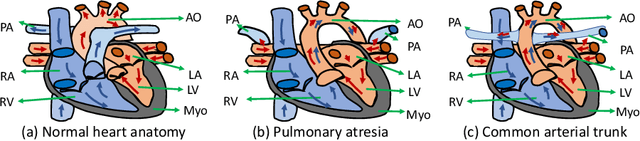
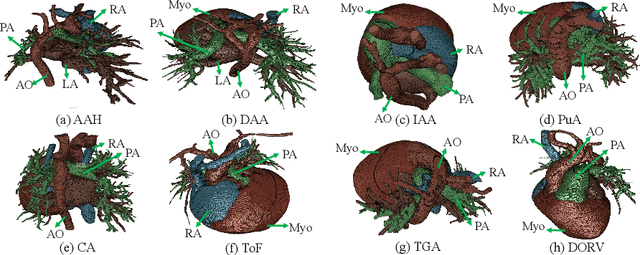
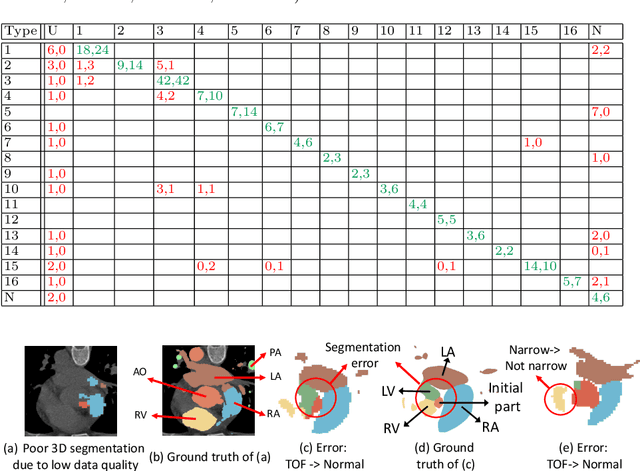
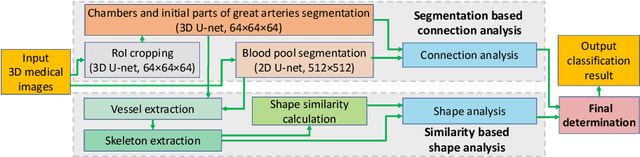
Congenital heart disease (CHD) is the most common type of birth defect, which occurs 1 in every 110 births in the United States. CHD usually comes with severe variations in heart structure and great artery connections that can be classified into many types. Thus highly specialized domain knowledge and the time-consuming human process is needed to analyze the associated medical images. On the other hand, due to the complexity of CHD and the lack of dataset, little has been explored on the automatic diagnosis (classification) of CHDs. In this paper, we present ImageCHD, the first medical image dataset for CHD classification. ImageCHD contains 110 3D Computed Tomography (CT) images covering most types of CHD, which is of decent size Classification of CHDs requires the identification of large structural changes without any local tissue changes, with limited data. It is an example of a larger class of problems that are quite difficult for current machine-learning-based vision methods to solve. To demonstrate this, we further present a baseline framework for the automatic classification of CHD, based on a state-of-the-art CHD segmentation method. Experimental results show that the baseline framework can only achieve a classification accuracy of 82.0\% under a selective prediction scheme with 88.4\% coverage, leaving big room for further improvement. We hope that ImageCHD can stimulate further research and lead to innovative and generic solutions that would have an impact in multiple domains. Our dataset is released to the public compared with existing medical imaging datasets.
AIFNet: Automatic Vascular Function Estimation for Perfusion Analysis Using Deep Learning
Oct 04, 2020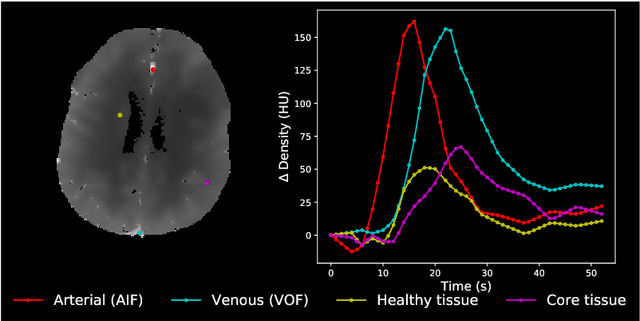

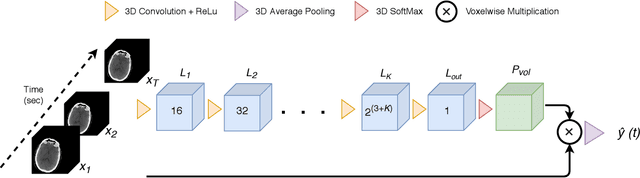
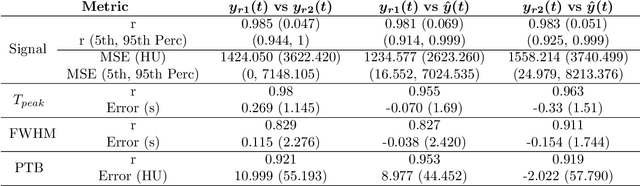
Perfusion imaging is crucial in acute ischemic stroke for quantifying the salvageable penumbra and irreversibly damaged core lesions. As such, it helps clinicians to decide on the optimal reperfusion treatment. In perfusion CT imaging, deconvolution methods are used to obtain clinically interpretable perfusion parameters that allow identifying brain tissue abnormalities. Deconvolution methods require the selection of two reference vascular functions as inputs to the model: the arterial input function (AIF) and the venous output function, with the AIF as the most critical model input. When manually performed, the vascular function selection is time demanding, suffers from poor reproducibility and is subject to the professionals' experience. This leads to potentially unreliable quantification of the penumbra and core lesions and, hence, might harm the treatment decision process. In this work we automatize the perfusion analysis with AIFNet, a fully automatic and end-to-end trainable deep learning approach for estimating the vascular functions. Unlike previous methods using clustering or segmentation techniques to select vascular voxels, AIFNet is directly optimized at the vascular function estimation, which allows to better recognise the time-curve profiles. Validation on the public ISLES18 stroke database shows that AIFNet reaches inter-rater performance for the vascular function estimation and, subsequently, for the parameter maps and core lesion quantification obtained through deconvolution. We conclude that AIFNet has potential for clinical transfer and could be incorporated in perfusion deconvolution software.
Efficient Golf Ball Detection and Tracking Based on Convolutional Neural Networks and Kalman Filter
Dec 17, 2020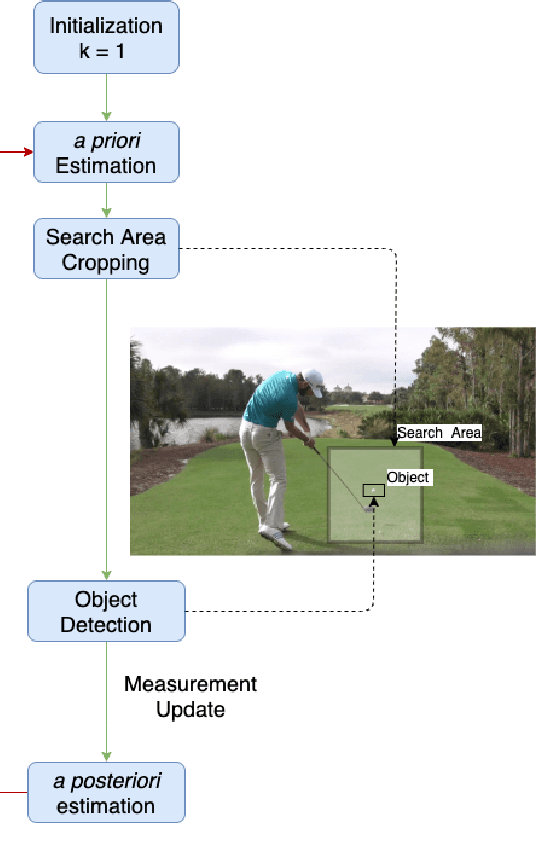

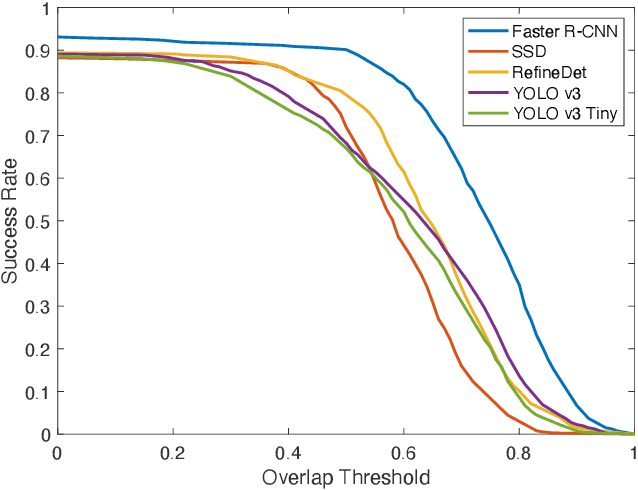
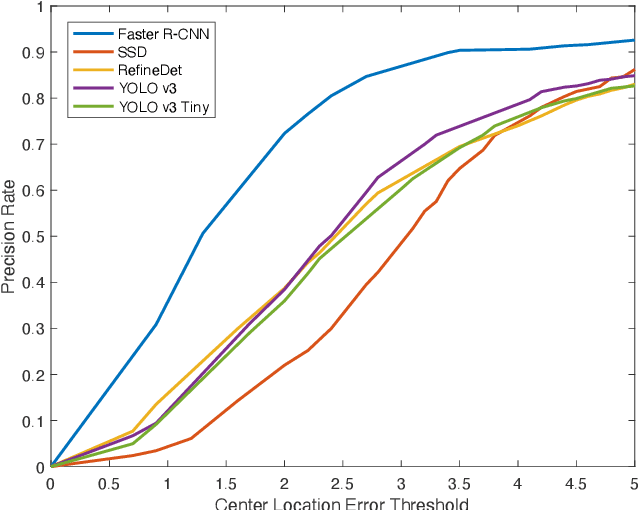
This paper focuses on the problem of online golf ball detection and tracking from image sequences. An efficient real-time approach is proposed by exploiting convolutional neural networks (CNN) based object detection and a Kalman filter based prediction. Five classical deep learning-based object detection networks are implemented and evaluated for ball detection, including YOLO v3 and its tiny version, YOLO v4, Faster R-CNN, SSD, and RefineDet. The detection is performed on small image patches instead of the entire image to increase the performance of small ball detection. At the tracking stage, a discrete Kalman filter is employed to predict the location of the ball and a small image patch is cropped based on the prediction. Then, the object detector is utilized to refine the location of the ball and update the parameters of Kalman filter. In order to train the detection models and test the tracking algorithm, a collection of golf ball dataset is created and annotated. Extensive comparative experiments are performed to demonstrate the effectiveness and superior tracking performance of the proposed scheme.
Parallel Tracking and Verifying: A Framework for Real-Time and High Accuracy Visual Tracking
Aug 01, 2017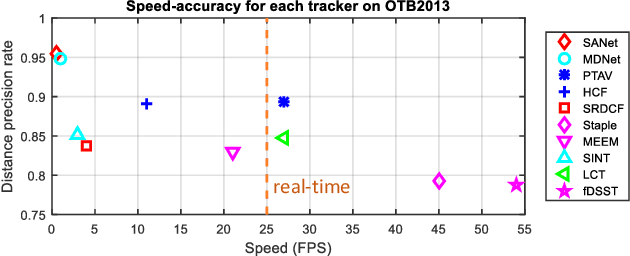
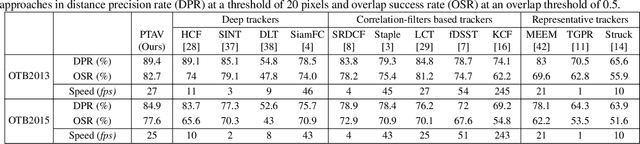

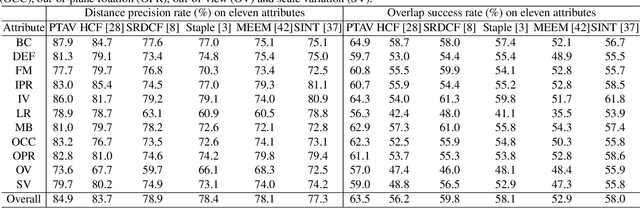
Being intensively studied, visual tracking has seen great recent advances in either speed (e.g., with correlation filters) or accuracy (e.g., with deep features). Real-time and high accuracy tracking algorithms, however, remain scarce. In this paper we study the problem from a new perspective and present a novel parallel tracking and verifying (PTAV) framework, by taking advantage of the ubiquity of multi-thread techniques and borrowing from the success of parallel tracking and mapping in visual SLAM. Our PTAV framework typically consists of two components, a tracker T and a verifier V, working in parallel on two separate threads. The tracker T aims to provide a super real-time tracking inference and is expected to perform well most of the time; by contrast, the verifier V checks the tracking results and corrects T when needed. The key innovation is that, V does not work on every frame but only upon the requests from T; on the other end, T may adjust the tracking according to the feedback from V. With such collaboration, PTAV enjoys both the high efficiency provided by T and the strong discriminative power by V. In our extensive experiments on popular benchmarks including OTB2013, OTB2015, TC128 and UAV20L, PTAV achieves the best tracking accuracy among all real-time trackers, and in fact performs even better than many deep learning based solutions. Moreover, as a general framework, PTAV is very flexible and has great rooms for improvement and generalization.
Transformer in action: a comparative study of transformer-based acoustic models for large scale speech recognition applications
Oct 29, 2020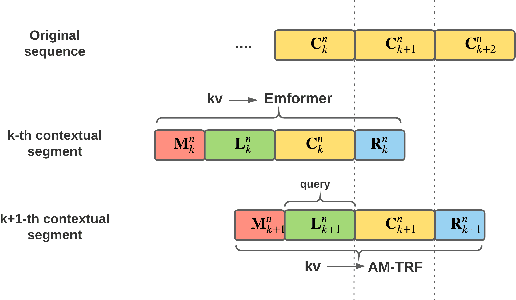
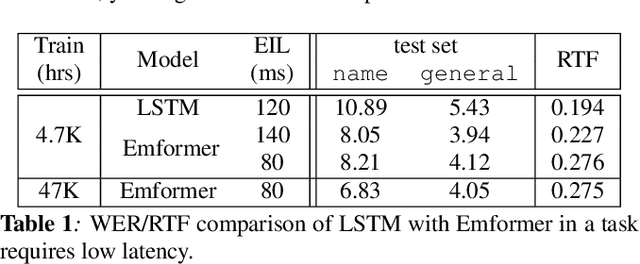
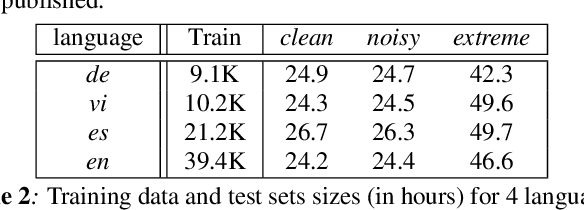
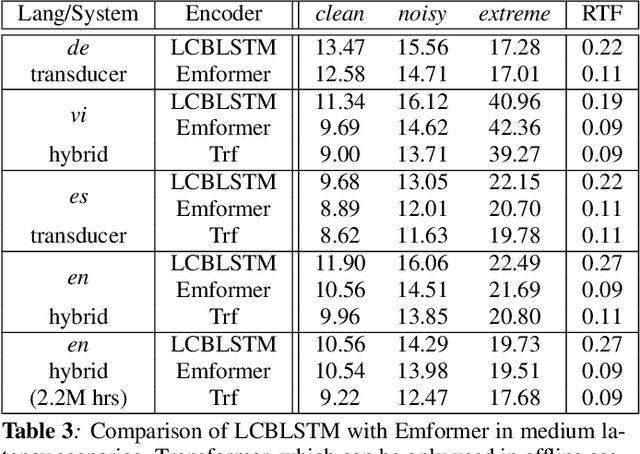
In this paper, we summarize the application of transformer and its streamable variant, Emformer based acoustic model for large scale speech recognition applications. We compare the transformer based acoustic models with their LSTM counterparts on industrial scale tasks. Specifically, we compare Emformer with latency-controlled BLSTM (LCBLSTM) on medium latency tasks and LSTM on low latency tasks. On a low latency voice assistant task, Emformer gets 24% to 26% relative word error rate reductions (WERRs). For medium latency scenarios, comparing with LCBLSTM with similar model size and latency, Emformer gets significant WERR across four languages in video captioning datasets with 2-3 times inference real-time factors reduction.