 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the performance of deep learning for numerical optimization: an application to protein structure prediction
Dec 17, 2020
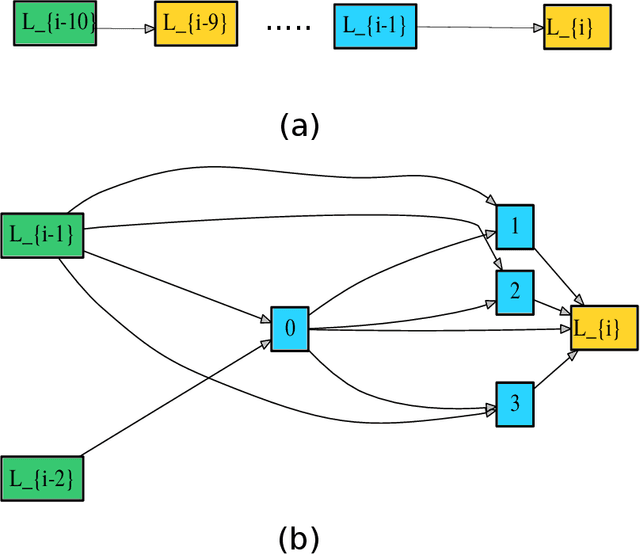
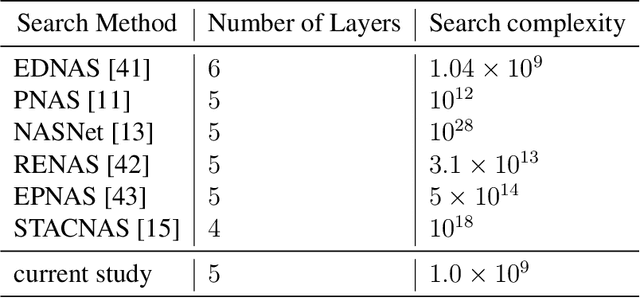
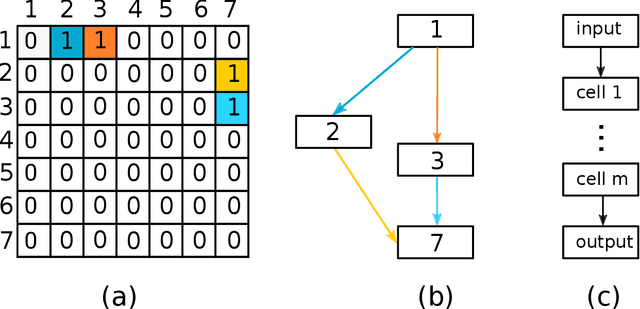
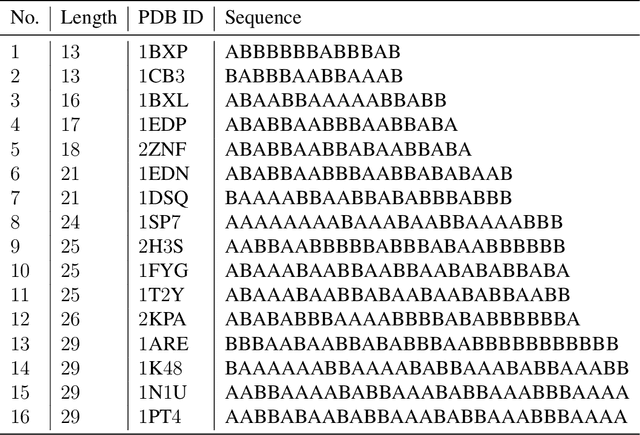
Deep neural networks have recently drawn considerable attention to build and evaluate artificial learning models for perceptual tasks. Here, we present a study on the performance of the deep learning models to deal with global optimization problems. The proposed approach adopts the idea of the neural architecture search (NAS) to generate efficient neural networks for solving the problem at hand. The space of network architectures is represented using a directed acyclic graph and the goal is to find the best architecture to optimize the objective function for a new, previously unknown task. Different from proposing very large networks with GPU computational burden and long training time, we focus on searching for lightweight implementations to find the best architecture. The performance of NAS is first analyzed through empirical experiments on CEC 2017 benchmark suite. Thereafter, it is applied to a set of protein structure prediction (PSP) problems. The experiments reveal that the generated learning models can achieve competitive results when compared to hand-designed algorithms; given enough computational budget
Linear, Machine Learning and Probabilistic Approaches for Time Series Analysis
Feb 26, 2017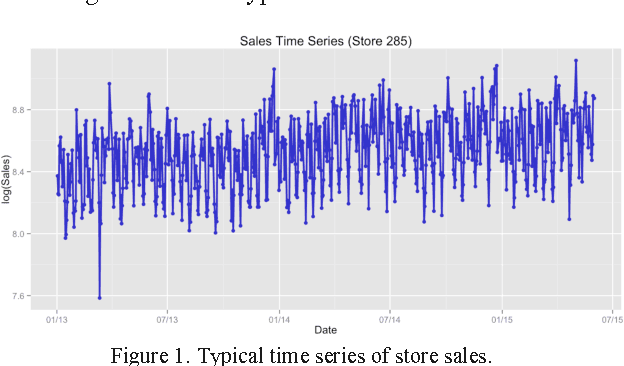
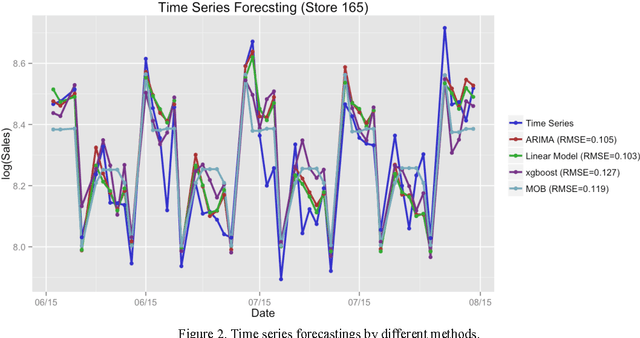
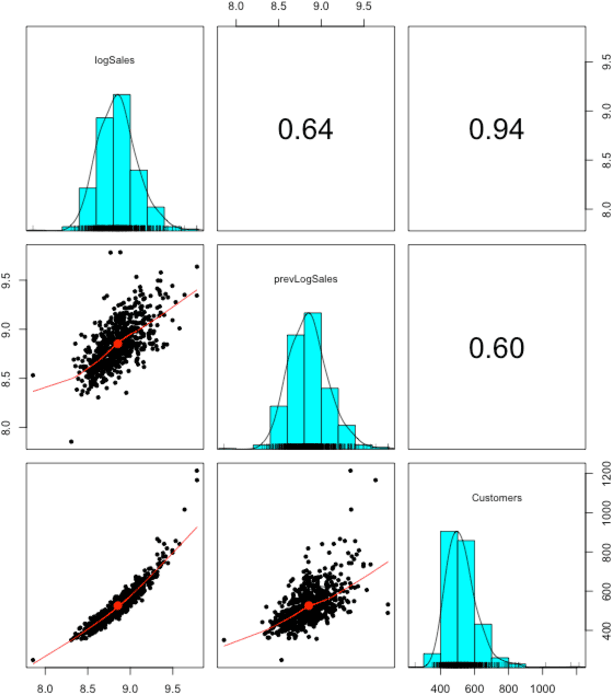
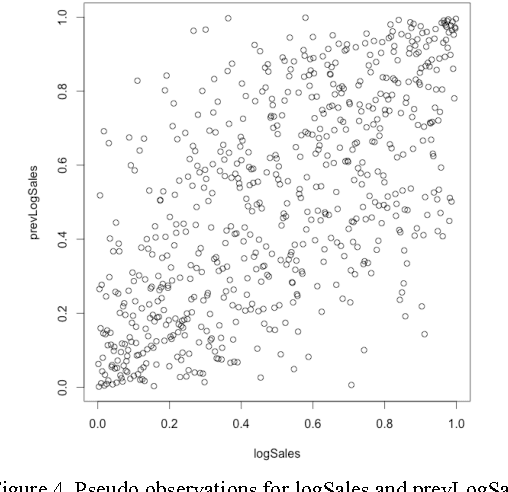
In this paper we study different approaches for time series modeling. The forecasting approaches using linear models, ARIMA alpgorithm, XGBoost machine learning algorithm are described. Results of different model combinations are shown. For probabilistic modeling the approaches using copulas and Bayesian inference are considered.
GloDyNE: Global Topology Preserving Dynamic Network Embedding
Aug 05, 2020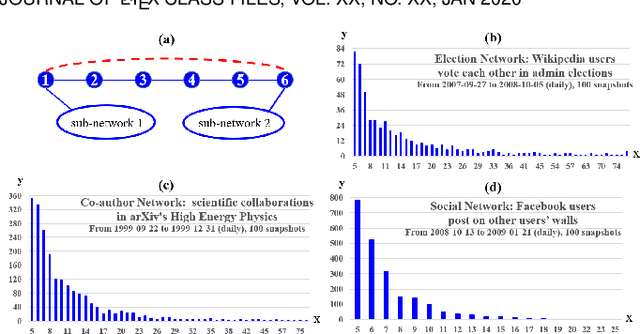
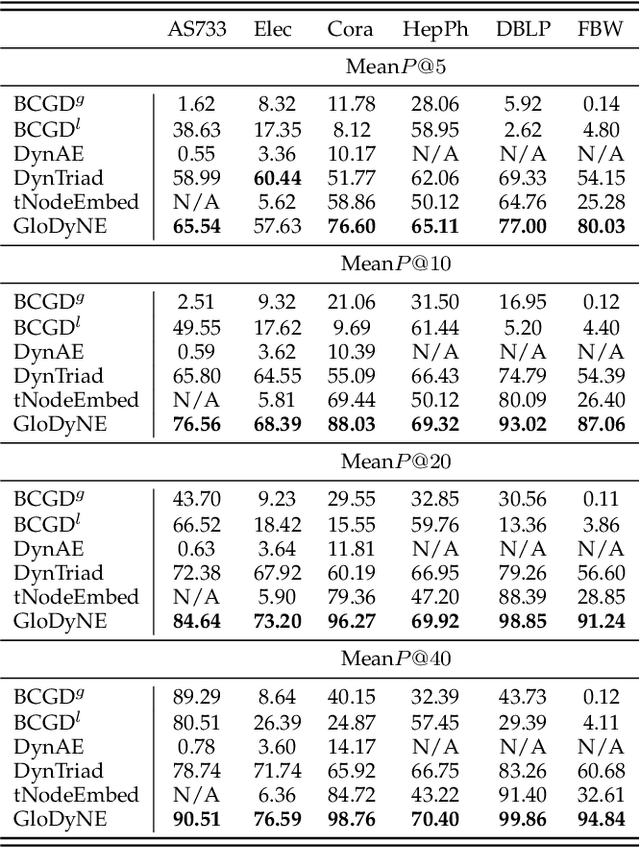
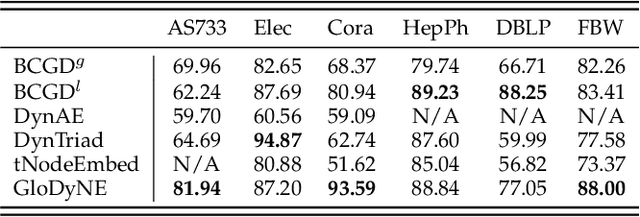
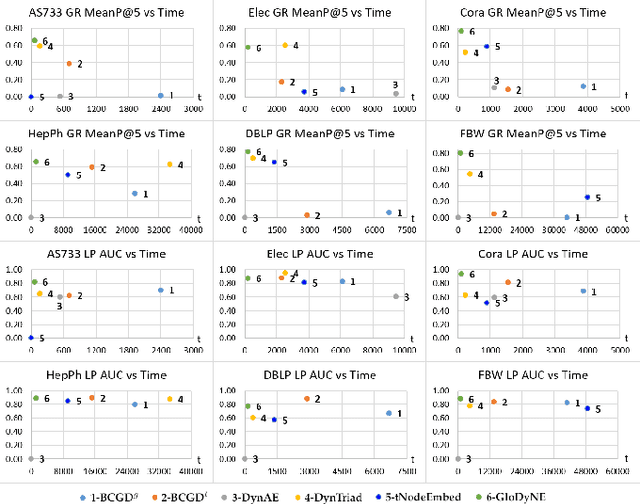
Learning low-dimensional topological representation of a network in dynamic environments is attracting much attention due to the time-evolving nature of many real-world networks. The main and common objective of Dynamic Network Embedding (DNE) is to efficiently update node embeddings while preserving network topology at each time step. The idea of most existing DNE methods is to capture the topological changes at or around the most affected nodes (instead of all nodes) and accordingly update node embeddings. Unfortunately, this kind of approximation, although can improve efficiency, cannot effectively preserve the global topology of a dynamic network at each time step, due to not considering the inactive sub-networks that receive accumulated topological changes propagated via the high-order proximity. To tackle this challenge, we propose a novel node selecting strategy to diversely select the representative nodes over a network, which is coordinated with a new incremental learning paradigm of Skip-Gram based embedding approach. The extensive experiments show GloDyNE, with a small fraction of nodes being selected, can already achieve the superior or comparable performance w.r.t. the state-of-the-art DNE methods in three typical downstream tasks. Particularly, GloDyNE significantly outperforms other methods in the graph reconstruction task, which demonstrates its ability of global topology preservation. The source code is available at https://github.com/houchengbin/GloDyNE
AI-enabled Prediction of eSports Player Performance Using the Data from Heterogeneous Sensors
Dec 07, 2020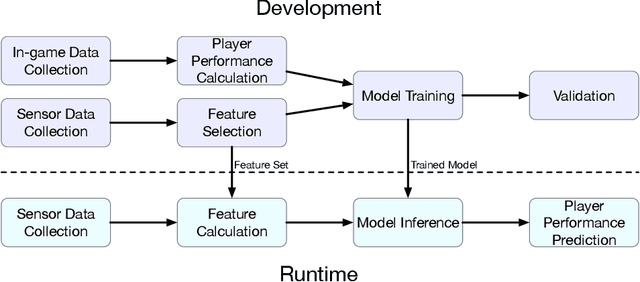

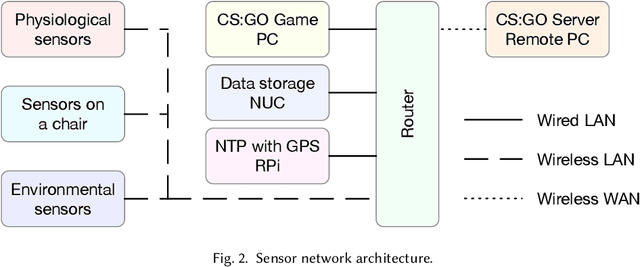
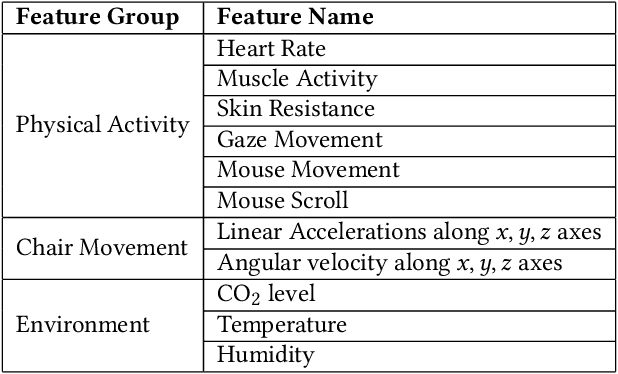
The emerging progress of eSports lacks the tools for ensuring high-quality analytics and training in Pro and amateur eSports teams. We report on an Artificial Intelligence (AI) enabled solution for predicting the eSports player in-game performance using exclusively the data from sensors. For this reason, we collected the physiological, environmental, and the game chair data from Pro and amateur players. The player performance is assessed from the game logs in a multiplayer game for each moment of time using a recurrent neural network. We have investigated that attention mechanism improves the generalization of the network and provides the straightforward feature importance as well. The best model achieves ROC AUC score 0.73. The prediction of the performance of particular player is realized although his data are not utilized in the training set. The proposed solution has a number of promising applications for Pro eSports teams as well as a learning tool for amateur players.
PupilNet v2.0: Convolutional Neural Networks for CPU based real time Robust Pupil Detection
Oct 30, 2017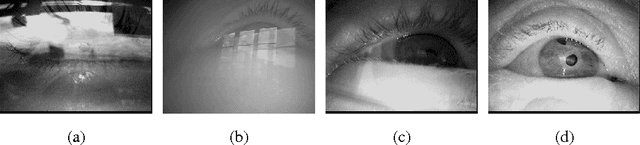
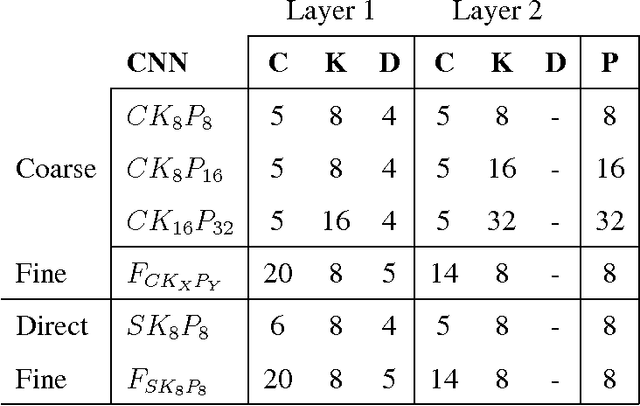
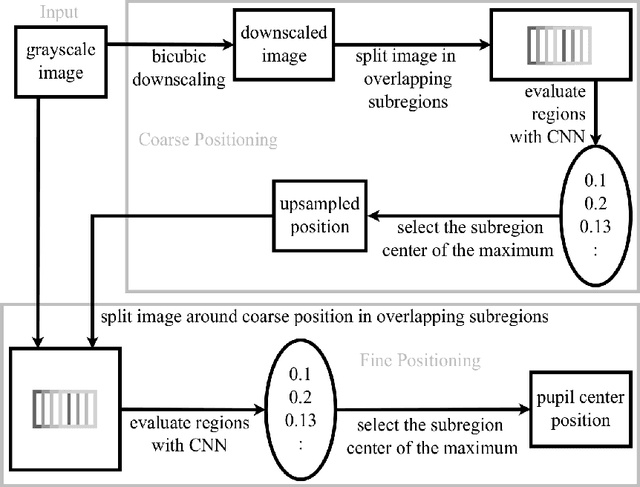
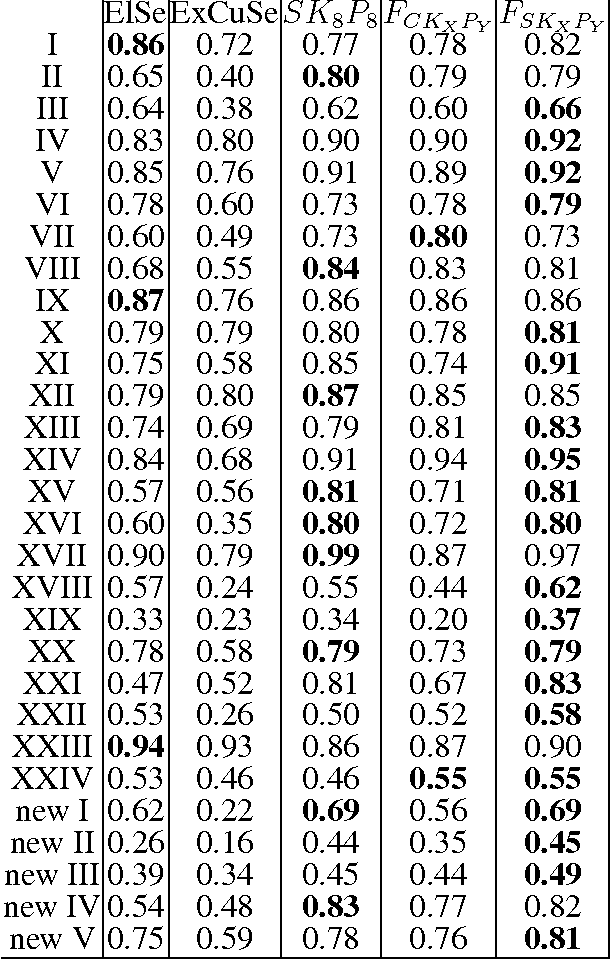
Real-time, accurate, and robust pupil detection is an essential prerequisite for pervasive video-based eye-tracking. However, automated pupil detection in realworld scenarios has proven to be an intricate challenge due to fast illumination changes, pupil occlusion, non-centered and off-axis eye recording, as well as physiological eye characteristics. In this paper, we approach this challenge through: I) a convolutional neural network (CNN) running in real time on a single core, II) a novel computational intensive two stage CNN for accuracy improvement, and III) a fast propability distribution based refinement method as a practical alternative to II. We evaluate the proposed approaches against the state-of-the-art pupil detection algorithms, improving the detection rate up to ~9% percent points on average over all data sets (~7% on one CPU core 7ms). This evaluation was performed on over 135,000 images: 94,000 images from the literature, and 41,000 new hand-labeled and challenging images contributed by this work (v1.0).
Privacy Preserving Visual SLAM
Jul 27, 2020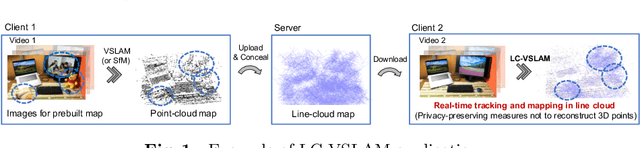

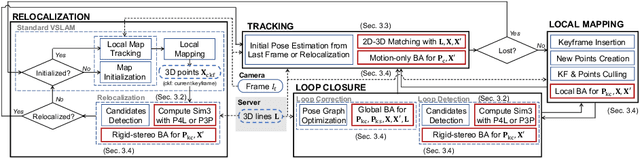

This study proposes a privacy-preserving Visual SLAM framework for estimating camera poses and performing bundle adjustment with mixed line and point clouds in real time. Previous studies have proposed localization methods to estimate a camera pose using a line-cloud map for a single image or a reconstructed point cloud. These methods offer a scene privacy protection against the inversion attacks by converting a point cloud to a line cloud, which reconstruct the scene images from the point cloud. However, they are not directly applicable to a video sequence because they do not address computational efficiency. This is a critical issue to solve for estimating camera poses and performing bundle adjustment with mixed line and point clouds in real time. Moreover, there has been no study on a method to optimize a line-cloud map of a server with a point cloud reconstructed from a client video because any observation points on the image coordinates are not available to prevent the inversion attacks, namely the reversibility of the 3D lines. The experimental results with synthetic and real data show that our Visual SLAM framework achieves the intended privacy-preserving formation and real-time performance using a line-cloud map.
Short Text Classification Approach to Identify Child Sexual Exploitation Material
Oct 29, 2020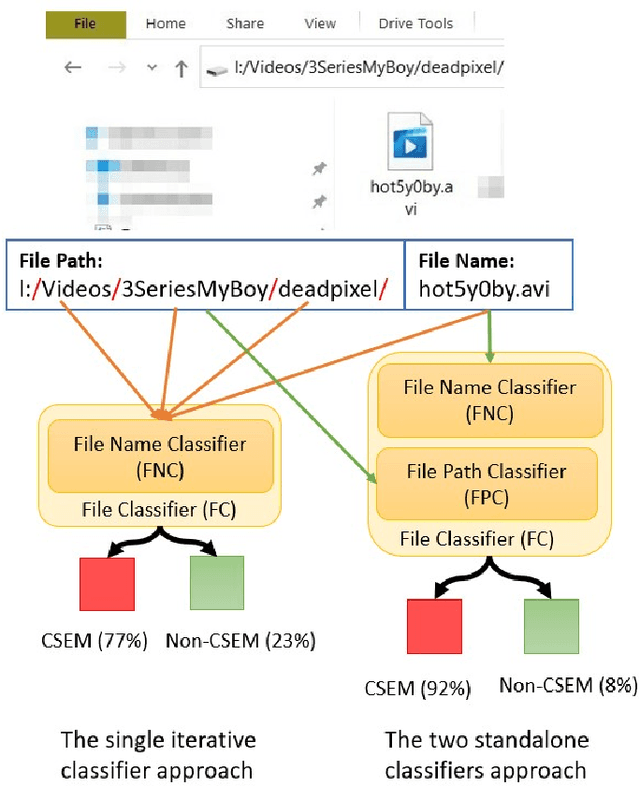
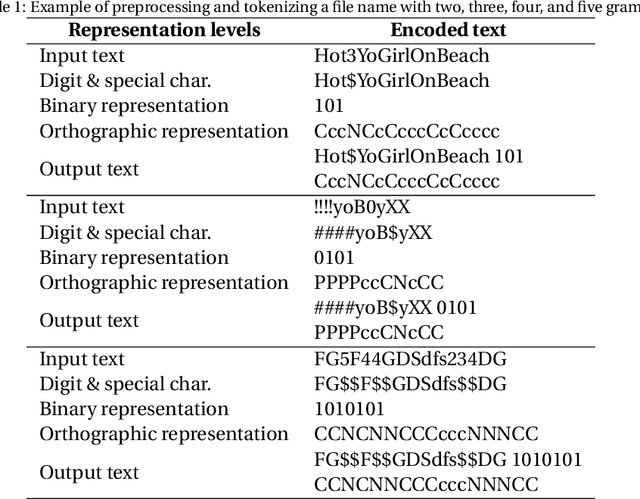
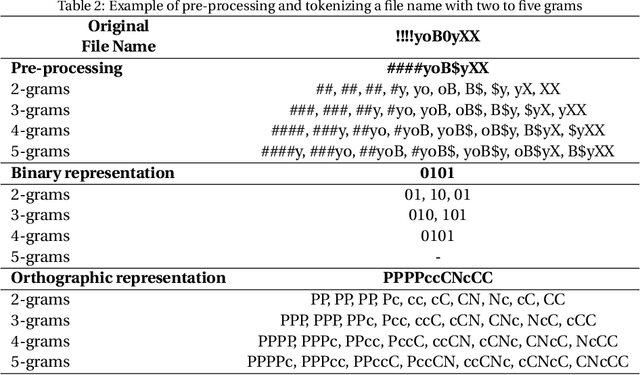

Producing or sharing Child Sexual Exploitation Material (CSEM) is a serious crime fought vigorously by Law Enforcement Agencies (LEAs). When an LEA seizes a computer from a potential producer or consumer of CSEM, they need to analyze the suspect's hard disk's files looking for pieces of evidence. However, a manual inspection of the file content looking for CSEM is a time-consuming task. In most cases, it is unfeasible in the amount of time available for the Spanish police using a search warrant. Instead of analyzing its content, another approach that can be used to speed up the process is to identify CSEM by analyzing the file names and their absolute paths. The main challenge for this task lies behind dealing with short text distorted deliberately by the owners of this material using obfuscated words and user-defined naming patterns. This paper presents and compares two approaches based on short text classification to identify CSEM files. The first one employs two independent supervised classifiers, one for the file name and the other for the path, and their outputs are later on fused into a single score. Conversely, the second approach uses only the file name classifier to iterate over the file's absolute path. Both approaches operate at the character n-grams level, while binary and orthographic features enrich the file name representation, and a binary Logistic Regression model is used for classification. The presented file classifier achieved an average class recall of 0.98. This solution could be integrated into forensic tools and services to support Law Enforcement Agencies to identify CSEM without tackling every file's visual content, which is computationally much more highly demanding.
Model identification and local linear convergence of coordinate descent
Oct 22, 2020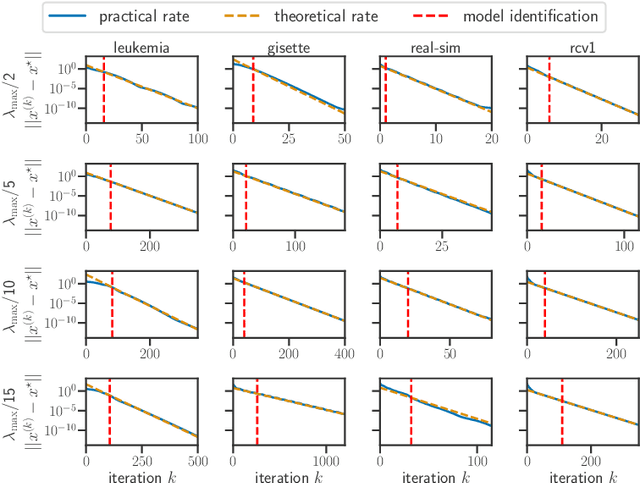
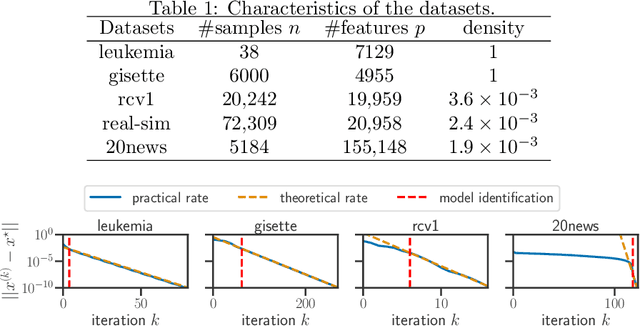
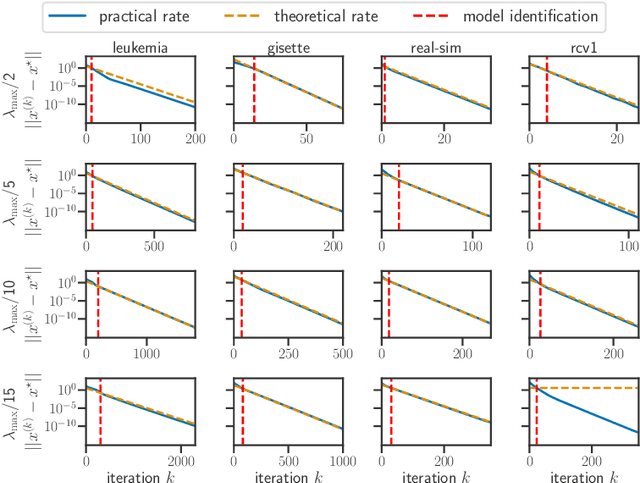
For composite nonsmooth optimization problems, Forward-Backward algorithm achieves model identification (e.g. support identification for the Lasso) after a finite number of iterations, provided the objective function is regular enough. Results concerning coordinate descent are scarcer and model identification has only been shown for specific estimators, the support-vector machine for instance. In this work, we show that cyclic coordinate descent achieves model identification in finite time for a wide class of functions. In addition, we prove explicit local linear convergence rates for coordinate descent. Extensive experiments on various estimators and on real datasets demonstrate that these rates match well empirical results.
A Legged Soft Robot Platform for Dynamic Locomotion
Nov 13, 2020
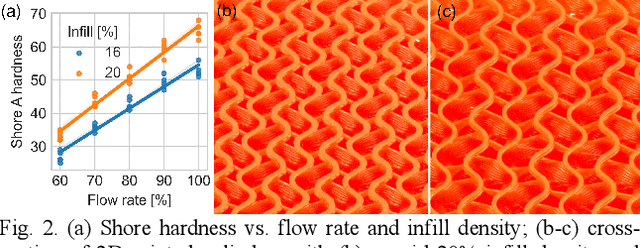

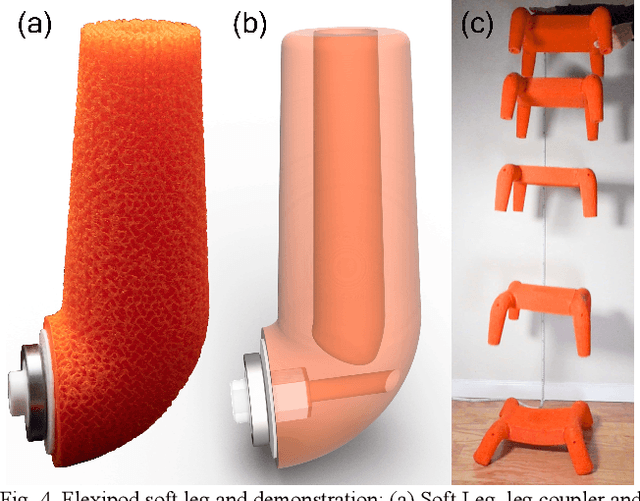
We present an open-source untethered quadrupedal soft robot platform for dynamic locomotion (e.g., high-speed running and backflipping). The robot is mostly soft (80 vol.%) while driven by four geared servo motors. The robot's soft body and soft legs were 3D printed with gyroid infill using a flexible material, enabling it to conform to the environment and passively stabilize during locomotion on multi-terrain environments. In addition, we simulated the robot in a real-time soft body simulation. With tuned gaits in simulation, the real robot can locomote at a speed of 0.9 m/s (2.5 body length/second), substantially faster than most untethered legged soft robots published to date. We hope this platform, along with its verified simulator, can catalyze the development of soft robotics.
Parallel Tracking and Verifying: A Framework for Real-Time and High Accuracy Visual Tracking
Aug 01, 2017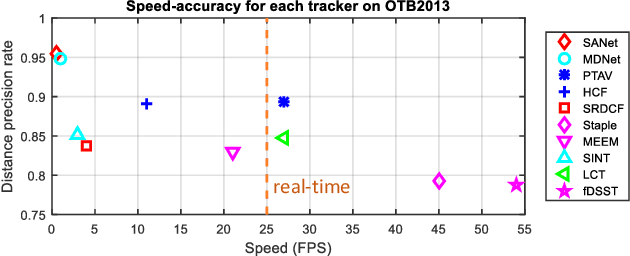
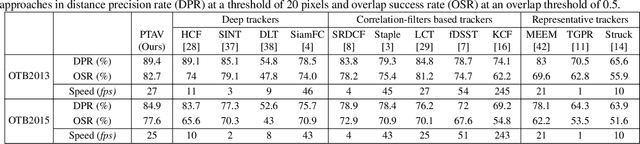

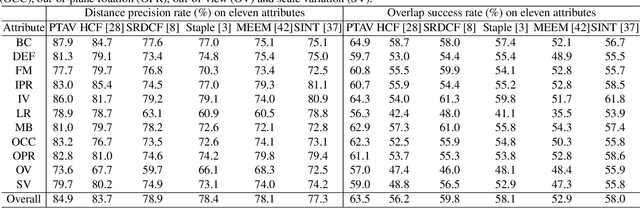
Being intensively studied, visual tracking has seen great recent advances in either speed (e.g., with correlation filters) or accuracy (e.g., with deep features). Real-time and high accuracy tracking algorithms, however, remain scarce. In this paper we study the problem from a new perspective and present a novel parallel tracking and verifying (PTAV) framework, by taking advantage of the ubiquity of multi-thread techniques and borrowing from the success of parallel tracking and mapping in visual SLAM. Our PTAV framework typically consists of two components, a tracker T and a verifier V, working in parallel on two separate threads. The tracker T aims to provide a super real-time tracking inference and is expected to perform well most of the time; by contrast, the verifier V checks the tracking results and corrects T when needed. The key innovation is that, V does not work on every frame but only upon the requests from T; on the other end, T may adjust the tracking according to the feedback from V. With such collaboration, PTAV enjoys both the high efficiency provided by T and the strong discriminative power by V. In our extensive experiments on popular benchmarks including OTB2013, OTB2015, TC128 and UAV20L, PTAV achieves the best tracking accuracy among all real-time trackers, and in fact performs even better than many deep learning based solutions. Moreover, as a general framework, PTAV is very flexible and has great rooms for improvement and generalization.