 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RODEO: Replay for Online Object Detection
Aug 14, 2020
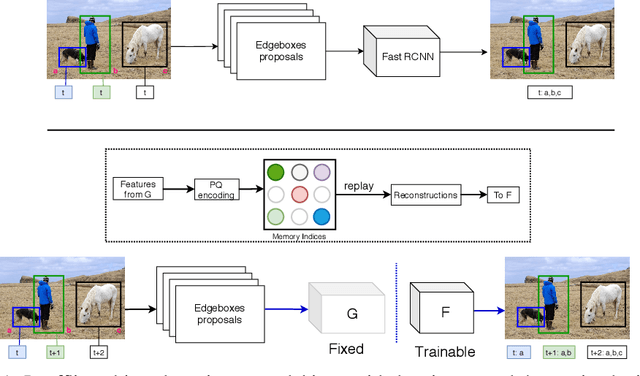
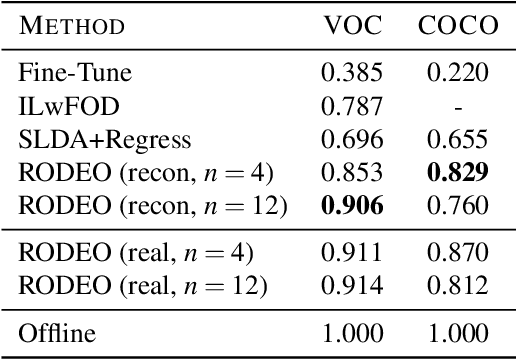
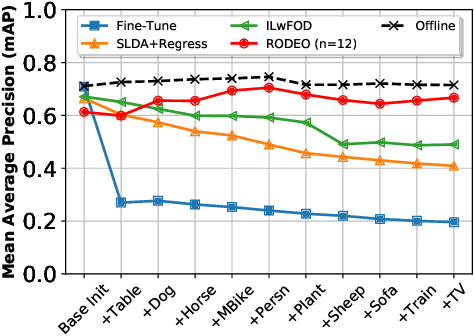
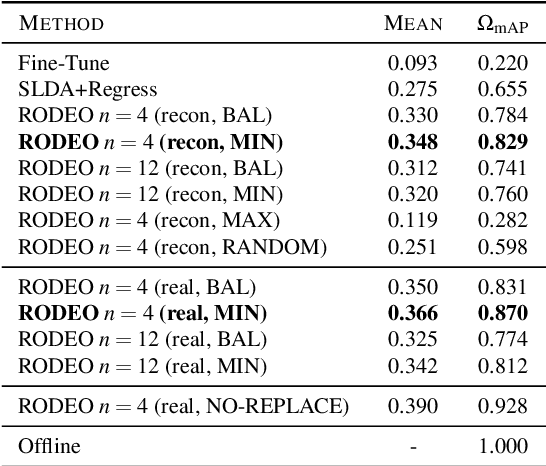
Humans can incrementally learn to do new visual detection tasks, which is a huge challenge for today's computer vision systems. Incrementally trained deep learning models lack backwards transfer to previously seen classes and suffer from a phenomenon known as $"catastrophic forgetting."$ In this paper, we pioneer online streaming learning for object detection, where an agent must learn examples one at a time with severe memory and computational constraints. In object detection, a system must output all bounding boxes for an image with the correct label. Unlike earlier work, the system described in this paper can learn this task in an online manner with new classes being introduced over time. We achieve this capability by using a novel memory replay mechanism that efficiently replays entire scenes. We achieve state-of-the-art results on both the PASCAL VOC 2007 and MS COCO datasets.
Passive Approach for the K-means Problem on Streaming Data
Dec 07, 2020
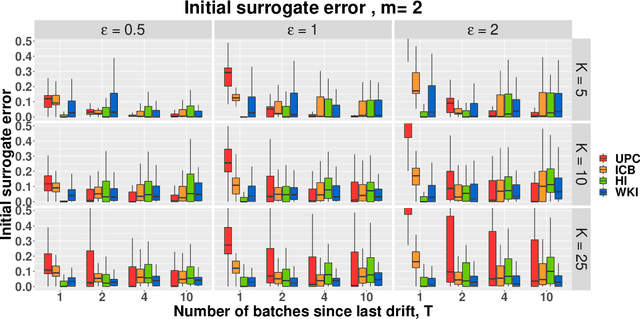
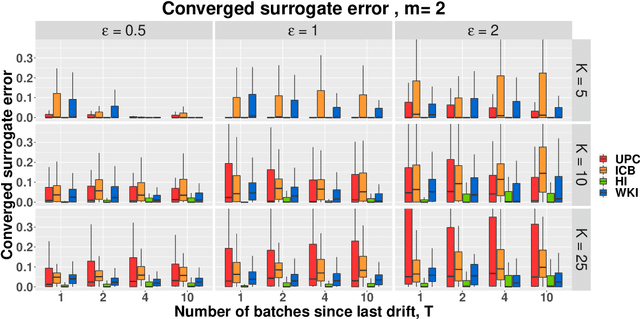
Currently the amount of data produced worldwide is increasing beyond measure, thus a high volume of unsupervised data must be processed continuously. One of the main unsupervised data analysis is clustering. In streaming data scenarios, the data is composed by an increasing sequence of batches of samples where the concept drift phenomenon may happen. In this paper, we formally define the Streaming $K$-means(S$K$M) problem, which implies a restart of the error function when a concept drift occurs. We propose a surrogate error function that does not rely on concept drift detection. We proof that the surrogate is a good approximation of the S$K$M error. Hence, we suggest an algorithm which minimizes this alternative error each time a new batch arrives. We present some initialization techniques for streaming data scenarios as well. Besides providing theoretical results, experiments demonstrate an improvement of the converged error for the non-trivial initialization methods.
Practical Speech Re-use Prevention in Voice-driven Services
Jan 12, 2021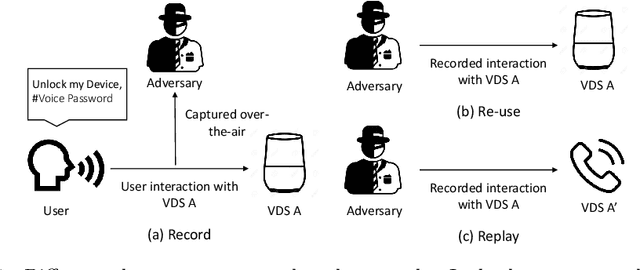


Voice-driven services (VDS) are being used in a variety of applications ranging from smart home control to payments using digital assistants. The input to such services is often captured via an open voice channel, e.g., using a microphone, in an unsupervised setting. One of the key operational security requirements in such setting is the freshness of the input speech. We present AEOLUS, a security overlay that proactively embeds a dynamic acoustic nonce at the time of user interaction, and detects the presence of the embedded nonce in the recorded speech to ensure freshness. We demonstrate that acoustic nonce can (i) be reliably embedded and retrieved, and (ii) be non-disruptive (and even imperceptible) to a VDS user. Optimal parameters (acoustic nonce's operating frequency, amplitude, and bitrate) are determined for (i) and (ii) from a practical perspective. Experimental results show that AEOLUS yields 0.5% FRR at 0% FAR for speech re-use prevention upto a distance of 4 meters in three real-world environments with different background noise levels. We also conduct a user study with 120 participants, which shows that the acoustic nonce does not degrade overall user experience for 94.16% of speech samples, on average, in these environments. AEOLUS can therefore be used in practice to prevent speech re-use and ensure the freshness of speech input.
PupilNet v2.0: Convolutional Neural Networks for CPU based real time Robust Pupil Detection
Oct 30, 2017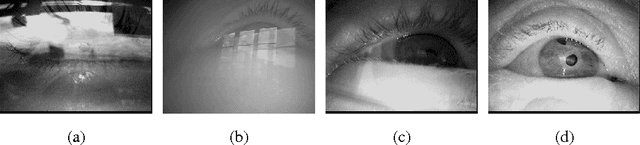
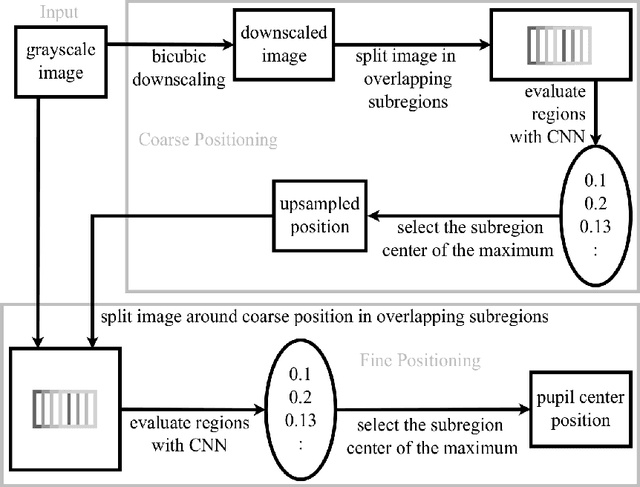
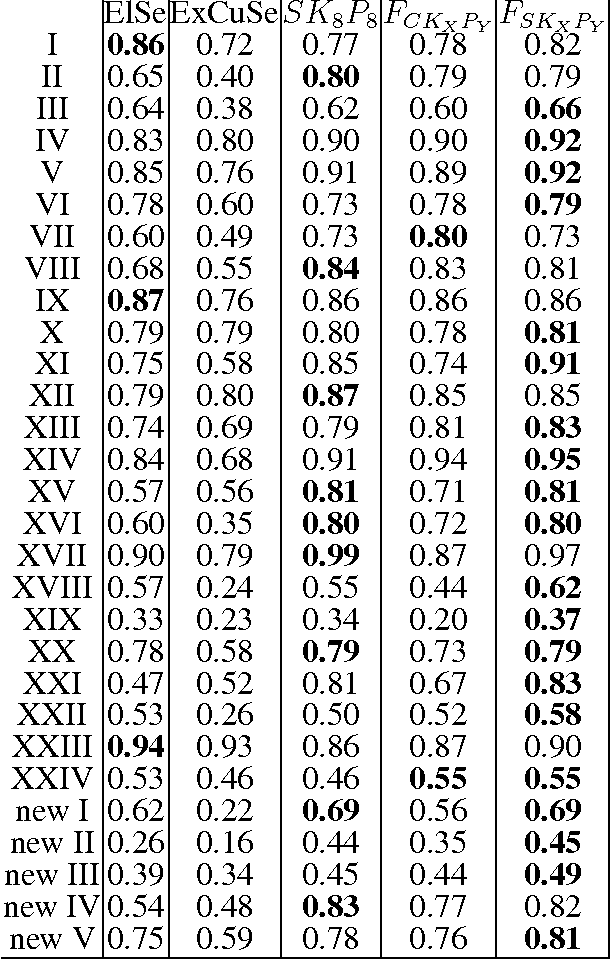
Real-time, accurate, and robust pupil detection is an essential prerequisite for pervasive video-based eye-tracking. However, automated pupil detection in realworld scenarios has proven to be an intricate challenge due to fast illumination changes, pupil occlusion, non-centered and off-axis eye recording, as well as physiological eye characteristics. In this paper, we approach this challenge through: I) a convolutional neural network (CNN) running in real time on a single core, II) a novel computational intensive two stage CNN for accuracy improvement, and III) a fast propability distribution based refinement method as a practical alternative to II. We evaluate the proposed approaches against the state-of-the-art pupil detection algorithms, improving the detection rate up to ~9% percent points on average over all data sets (~7% on one CPU core 7ms). This evaluation was performed on over 135,000 images: 94,000 images from the literature, and 41,000 new hand-labeled and challenging images contributed by this work (v1.0).
Malware Detection using Artificial Bee Colony Algorithm
Dec 01, 2020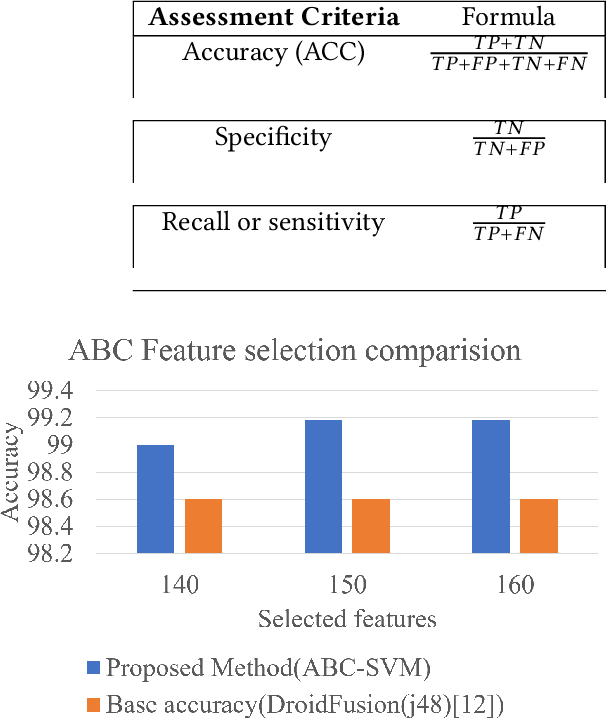

Malware detection has become a challenging task due to the increase in the number of malware families. Universal malware detection algorithms that can detect all the malware families are needed to make the whole process feasible. However, the more universal an algorithm is, the higher number of feature dimensions it needs to work with, and that inevitably causes the emerging problem of Curse of Dimensionality (CoD). Besides, it is also difficult to make this solution work due to the real-time behavior of malware analysis. In this paper, we address this problem and aim to propose a feature selection based malware detection algorithm using an evolutionary algorithm that is referred to as Artificial Bee Colony (ABC). The proposed algorithm enables researchers to decrease the feature dimension and as a result, boost the process of malware detection. The experimental results reveal that the proposed method outperforms the state-of-the-art.
Weight and Gradient Centralization in Deep Neural Networks
Oct 30, 2020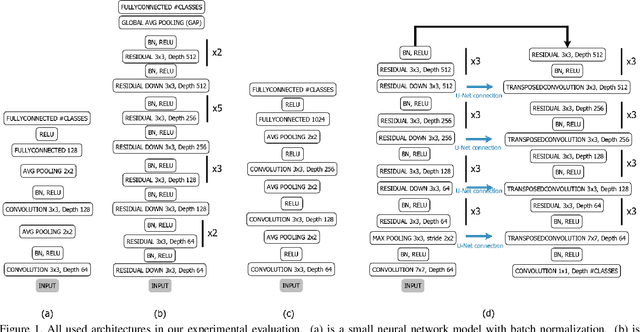
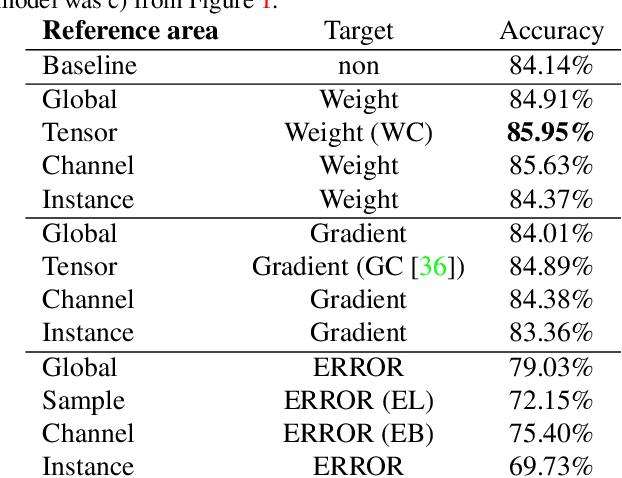
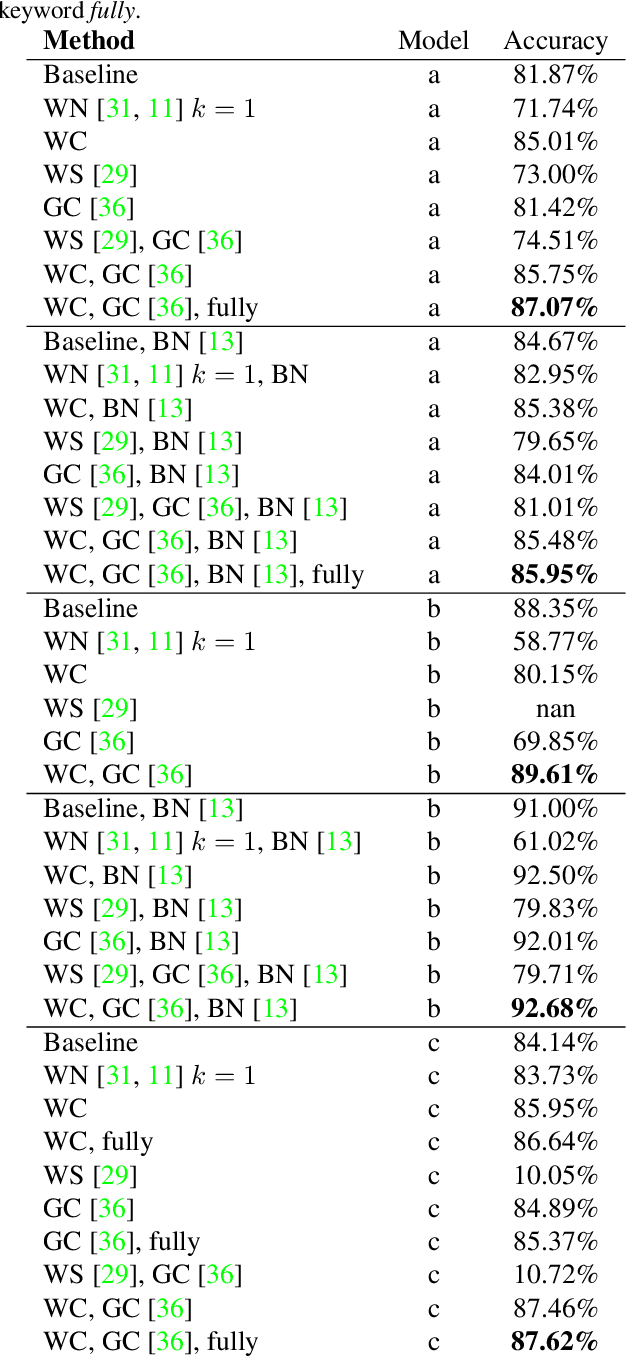
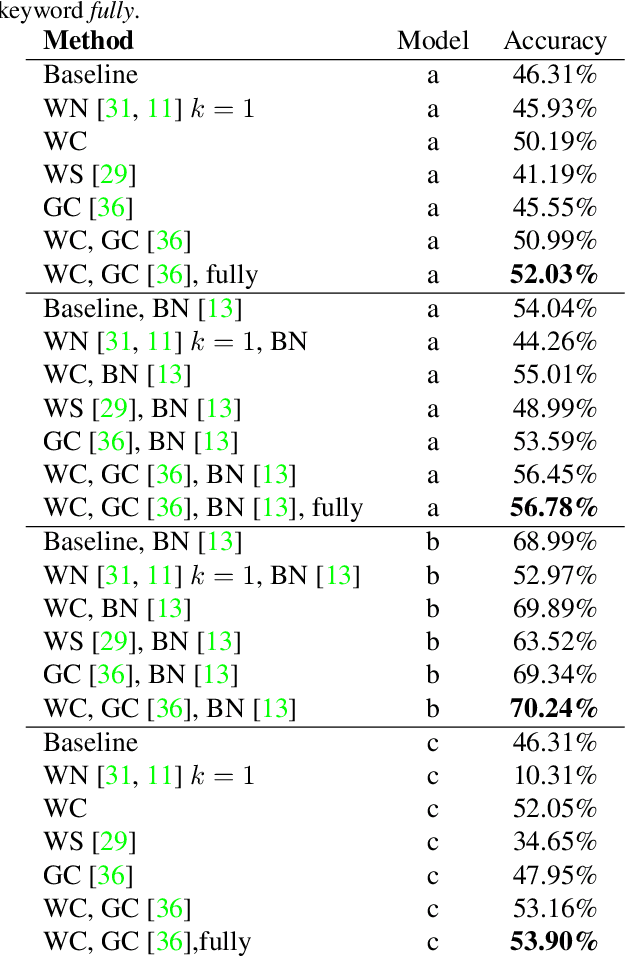
Batch normalization is currently the most widely used variant of internal normalization for deep neural networks. Additional work has shown that the normalization of weights and additional conditioning as well as the normalization of gradients further improve the generalization. In this work, we combine several of these methods and thereby increase the generalization of the networks. The advantage of the newer methods compared to the batch normalization is not only increased generalization, but also that these methods only have to be applied during training and, therefore, do not influence the running time during use. Link to CUDA code https://atreus.informatik.uni-tuebingen.de/seafile/d/8e2ab8c3fdd444e1a135/
Non-trivial informational closure of a Bayesian hyperparameter
Oct 05, 2020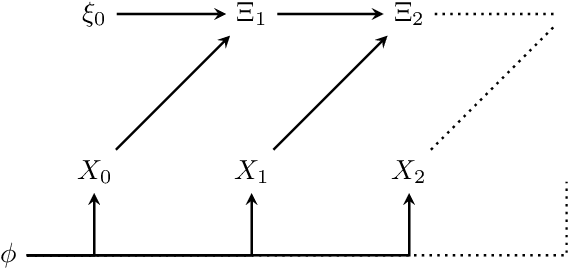
We investigate the non-trivial informational closure (NTIC) of a Bayesian hyperparameter inferring the underlying distribution of an identically and independently distributed finite random variable. For this we embed both the Bayesian hyper-parameter updating process and the random data process into a Markov chain. The original publication by Bertschinger et al. (2006) mentioned that NTIC may be able to capture an abstract notion of modeling that is agnostic to the specific internal structure of and existence of explicit representations within the modeling process. The Bayesian hyperparameter is of interest since it has a well defined interpretation as a model of the data process and at the same time its dynamics can be specified without reference to this interpretation. On the one hand we show explicitly that the NTIC of the hyperparameter increases indefinitely over time. On the other hand we attempt to establish a connection between a quantity that is a feature of the interpretation of the hyperparameter as a model, namely the information gain, and the one-step pointwise NTIC which is a quantity that does not depend on this interpretation. We find that in general we cannot use the one-step pointwise NTIC as an indicator for information gain. We hope this exploratory work can lead to further rigorous studies of the relation between NTIC and modeling.
Provable Multi-Objective Reinforcement Learning with Generative Models
Nov 19, 2020Multi-objective reinforcement learning (MORL) is an extension of ordinary, single-objective reinforcement learning (RL) that is applicable to many real world tasks where multiple objectives exist without known relative costs. We study the problem of single policy MORL, which learns an optimal policy given the preference of objectives. Existing methods require strong assumptions such as exact knowledge of the multi-objective Markov decision process, and are analyzed in the limit of infinite data and time. We propose a new algorithm called model-based envelop value iteration (EVI), which generalizes the enveloped multi-objective $Q$-learning algorithm in Yang, 2019. Our method can learn a near-optimal value function with polynomial sample complexity and linear convergence speed. To the best of our knowledge, this is the first finite-sample analysis of MORL algorithms.
Searching for Efficient Architecture for Instrument Segmentation in Robotic Surgery
Jul 08, 2020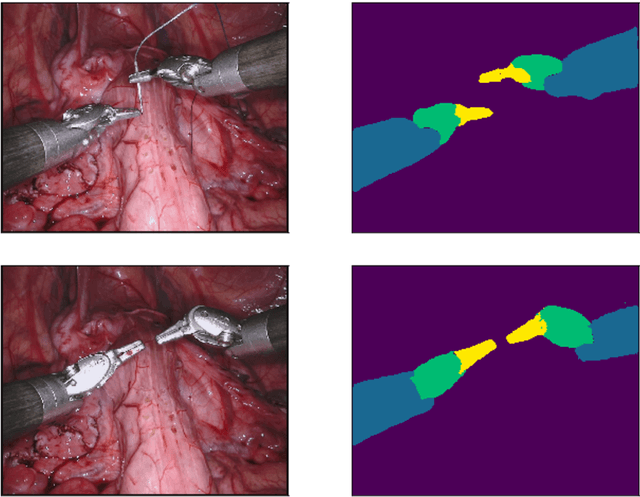
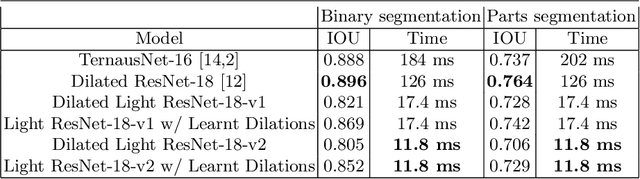
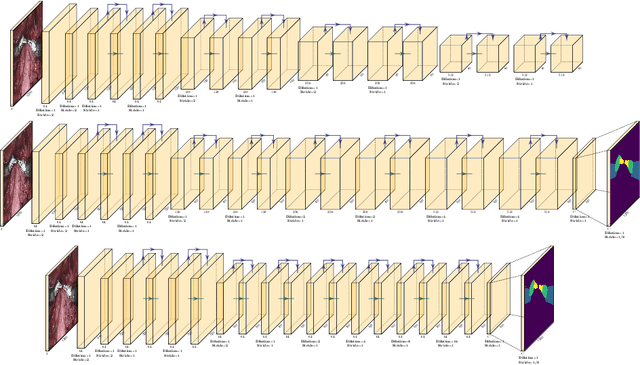

Segmentation of surgical instruments is an important problem in robot-assisted surgery: it is a crucial step towards full instrument pose estimation and is directly used for masking of augmented reality overlays during surgical procedures. Most applications rely on accurate real-time segmentation of high-resolution surgical images. While previous research focused primarily on methods that deliver high accuracy segmentation masks, majority of them can not be used for real-time applications due to their computational cost. In this work, we design a light-weight and highly-efficient deep residual architecture which is tuned to perform real-time inference of high-resolution images. To account for reduced accuracy of the discovered light-weight deep residual network and avoid adding any additional computational burden, we perform a differentiable search over dilation rates for residual units of our network. We test our discovered architecture on the EndoVis 2017 Robotic Instruments dataset and verify that our model is the state-of-the-art in terms of speed and accuracy tradeoff with a speed of up to 125 FPS on high resolution images.
Self-supervised Temporal Discriminative Learning for Video Representation Learning
Aug 05, 2020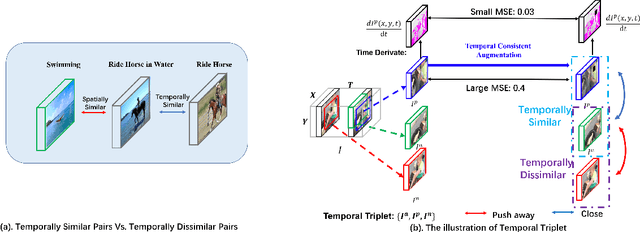
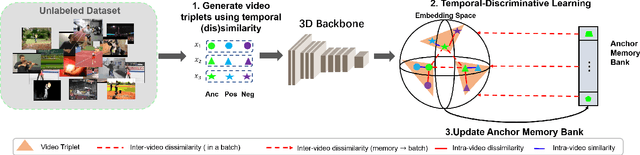
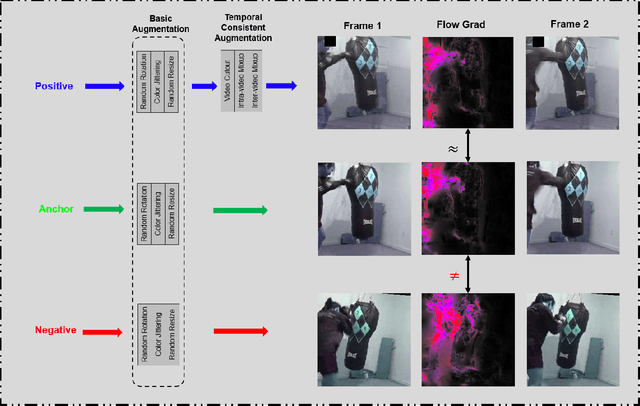
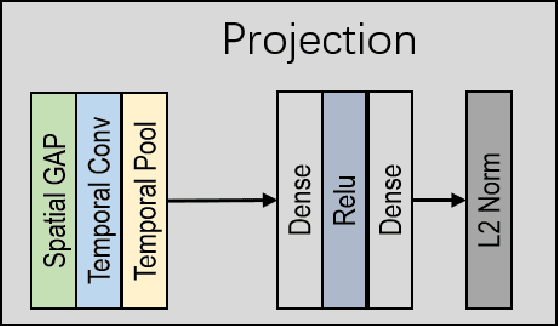
Temporal cues in videos provide important information for recognizing actions accurately. However, temporal-discriminative features can hardly be extracted without using an annotated large-scale video action dataset for training. This paper proposes a novel Video-based Temporal-Discriminative Learning (VTDL) framework in self-supervised manner. Without labelled data for network pretraining, temporal triplet is generated for each anchor video by using segment of the same or different time interval so as to enhance the capacity for temporal feature representation. Measuring temporal information by time derivative, Temporal Consistent Augmentation (TCA) is designed to ensure that the time derivative (in any order) of the augmented positive is invariant except for a scaling constant. Finally, temporal-discriminative features are learnt by minimizing the distance between each anchor and its augmented positive, while the distance between each anchor and its augmented negative as well as other videos saved in the memory bank is maximized to enrich the representation diversity. In the downstream action recognition task, the proposed method significantly outperforms existing related works. Surprisingly, the proposed self-supervised approach is better than fully-supervised methods on UCF101 and HMDB51 when a small-scale video dataset (with only thousands of videos) is used for pre-training. The code has been made publicly available on https://github.com/FingerRec/Self-Supervised-Temporal-Discriminative-Representation-Learning-for-Video-Action-Recognition.