 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficiently Combining Human Demonstrations and Interventions for Safe Training of Autonomous Systems in Real-Time
Nov 28, 2018
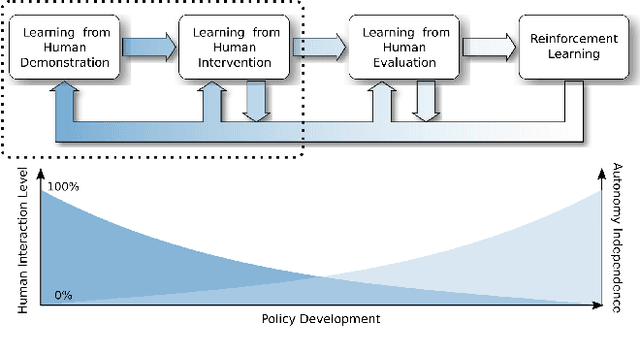
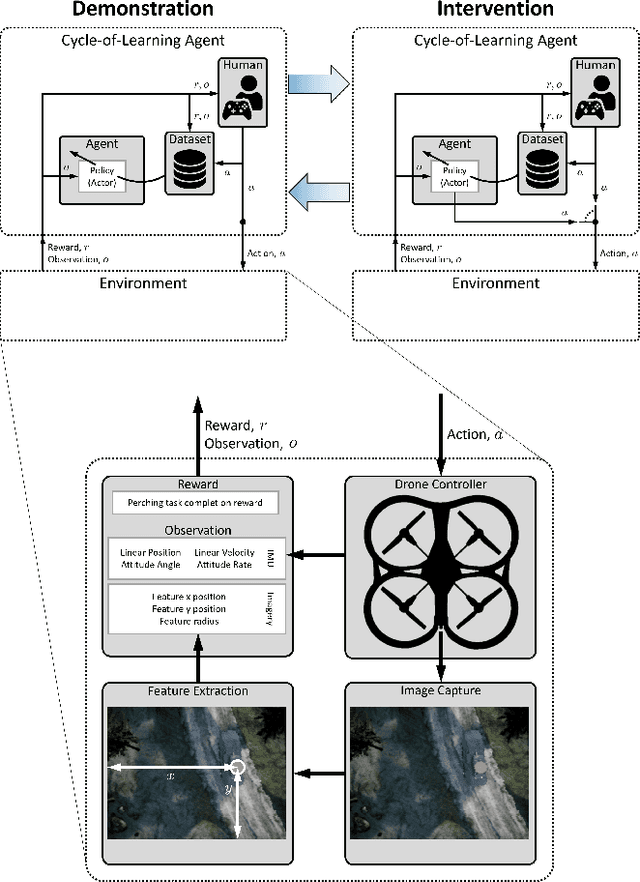
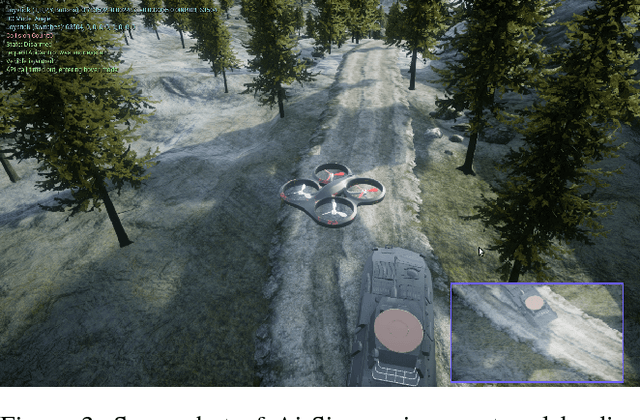
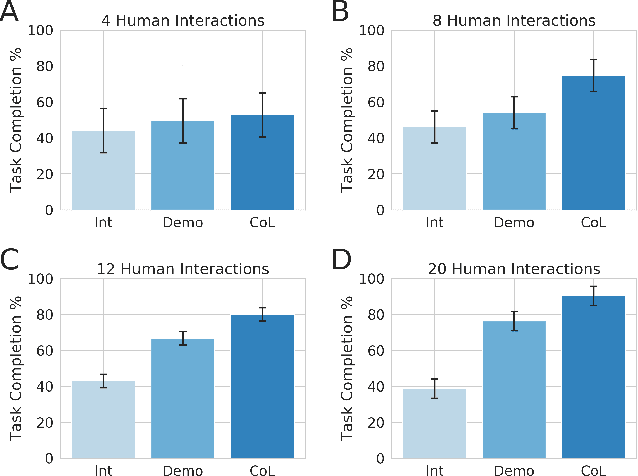
This paper investigates how to utilize different forms of human interaction to safely train autonomous systems in real-time by learning from both human demonstrations and interventions. We implement two components of the Cycle-of-Learning for Autonomous Systems, which is our framework for combining multiple modalities of human interaction. The current effort employs human demonstrations to teach a desired behavior via imitation learning, then leverages intervention data to correct for undesired behaviors produced by the imitation learner to teach novel tasks to an autonomous agent safely, after only minutes of training. We demonstrate this method in an autonomous perching task using a quadrotor with continuous roll, pitch, yaw, and throttle commands and imagery captured from a downward-facing camera in a high-fidelity simulated environment. Our method improves task completion performance for the same amount of human interaction when compared to learning from demonstrations alone, while also requiring on average 32% less data to achieve that performance. This provides evidence that combining multiple modes of human interaction can increase both the training speed and overall performance of policies for autonomous systems.
Finding Fast Transformers: One-Shot Neural Architecture Search by Component Composition
Aug 15, 2020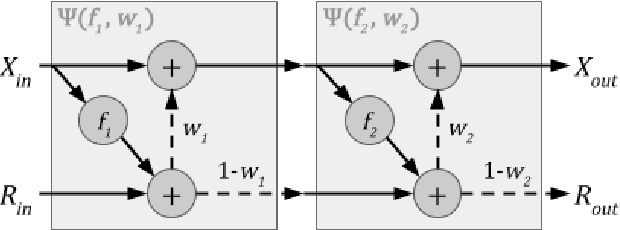
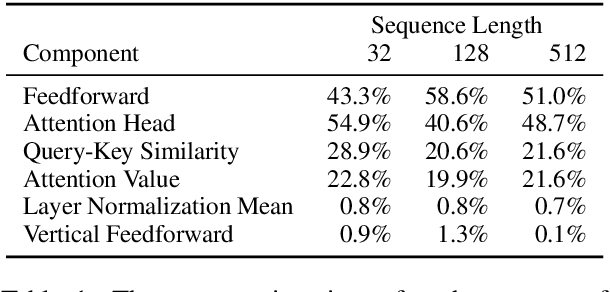
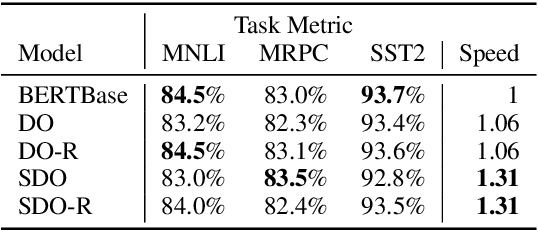
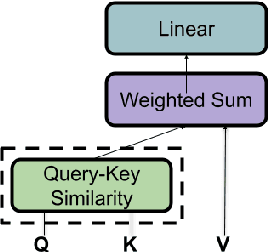
Transformer-based models have achieved stateof-the-art results in many tasks in natural language processing. However, such models are usually slow at inference time, making deployment difficult. In this paper, we develop an efficient algorithm to search for fast models while maintaining model quality. We describe a novel approach to decompose the Transformer architecture into smaller components, and propose a sampling-based one-shot architecture search method to find an optimal model for inference. The model search process is more efficient than alternatives, adding only a small overhead to training time. By applying our methods to BERT-base architectures, we achieve 10% to 30% speedup for pre-trained BERT and 70% speedup on top of a previous state-of-the-art distilled BERT model on Cloud TPU-v2 with a generally acceptable drop in performance.
Approaches to Fraud Detection on Credit Card Transactions Using Artificial Intelligence Methods
Jul 29, 2020
Credit card fraud is an ongoing problem for almost all industries in the world, and it raises millions of dollars to the global economy each year. Therefore, there is a number of research either completed or proceeding in order to detect these kinds of frauds in the industry. These researches generally use rule-based or novel artificial intelligence approaches to find eligible solutions. The ultimate goal of this paper is to summarize state-of-the-art approaches to fraud detection using artificial intelligence and machine learning techniques. While summarizing, we will categorize the common problems such as imbalanced dataset, real time working scenarios, and feature engineering challenges that almost all research works encounter, and identify general approaches to solve them. The imbalanced dataset problem occurs because the number of legitimate transactions is much higher than the fraudulent ones whereas applying the right feature engineering is substantial as the features obtained from the industries are limited, and applying feature engineering methods and reforming the dataset is crucial. Also, adapting the detection system to real time scenarios is a challenge since the number of credit card transactions in a limited time period is very high. In addition, we will discuss how evaluation metrics and machine learning methods differentiate among each research.
* 10 pages, 1 table, conference paper
Where is my hand? Deep hand segmentation for visual self-recognition in humanoid robots
Feb 09, 2021
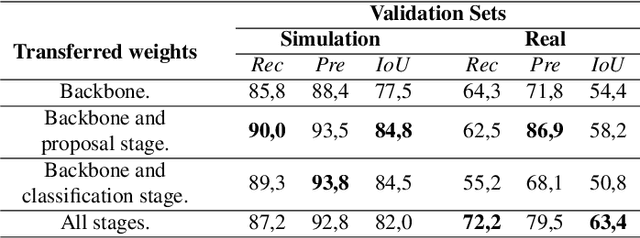
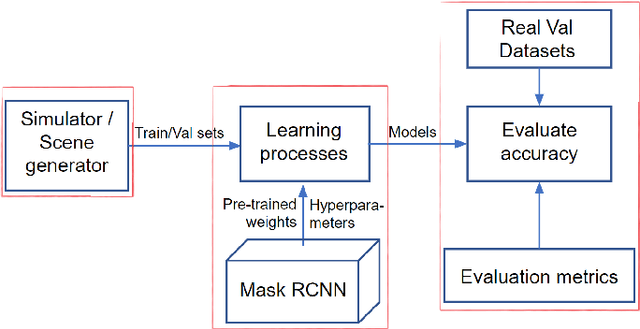
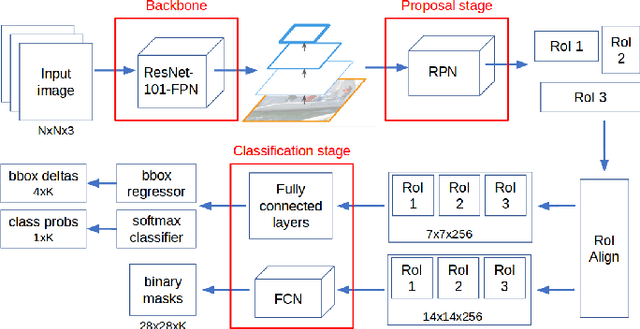
The ability to distinguish between the self and the background is of paramount importance for robotic tasks. The particular case of hands, as the end effectors of a robotic system that more often enter into contact with other elements of the environment, must be perceived and tracked with precision to execute the intended tasks with dexterity and without colliding with obstacles. They are fundamental for several applications, from Human-Robot Interaction tasks to object manipulation. Modern humanoid robots are characterized by high number of degrees of freedom which makes their forward kinematics models very sensitive to uncertainty. Thus, resorting to vision sensing can be the only solution to endow these robots with a good perception of the self, being able to localize their body parts with precision. In this paper, we propose the use of a Convolution Neural Network (CNN) to segment the robot hand from an image in an egocentric view. It is known that CNNs require a huge amount of data to be trained. To overcome the challenge of labeling real-world images, we propose the use of simulated datasets exploiting domain randomization techniques. We fine-tuned the Mask-RCNN network for the specific task of segmenting the hand of the humanoid robot Vizzy. We focus our attention on developing a methodology that requires low amounts of data to achieve reasonable performance while giving detailed insight on how to properly generate variability in the training dataset. Moreover, we analyze the fine-tuning process within the complex model of Mask-RCNN, understanding which weights should be transferred to the new task of segmenting robot hands. Our final model was trained solely on synthetic images and achieves an average IoU of 82% on synthetic validation data and 56.3% on real test data. These results were achieved with only 1000 training images and 3 hours of training time using a single GPU.
New Bag of Deep Visual Words based features to classify chest x-ray images for COVID-19 diagnosis
Jan 28, 2021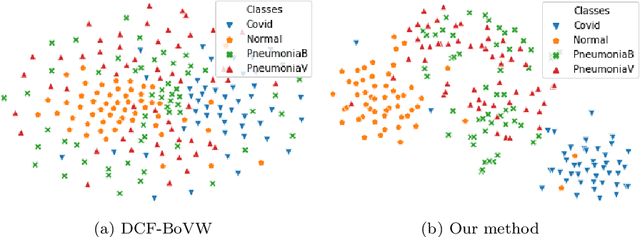

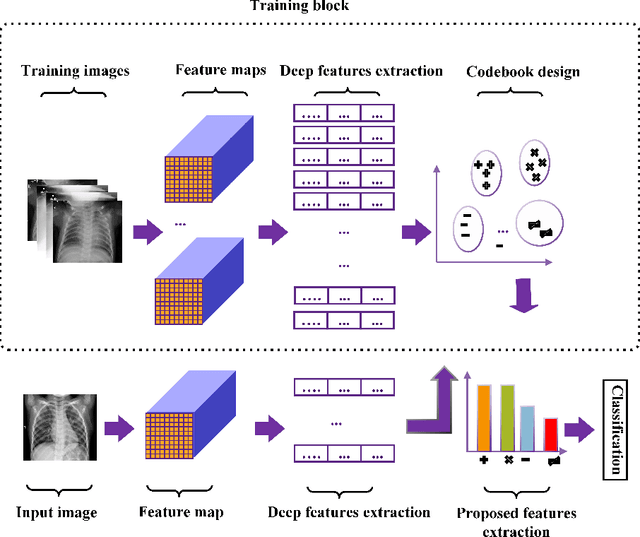
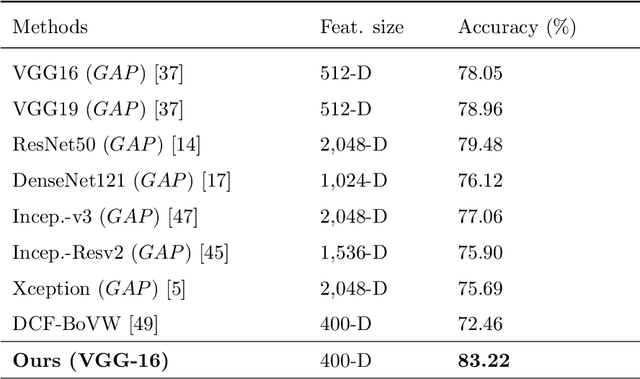
Because the infection by Severe Acute Respiratory Syndrome Coronavirus 2 (COVID-19) causes the pneumonia-like effect in the lungs, the examination of chest x-rays can help to diagnose the diseases. For automatic analysis of images, they are represented in machines by a set of semantic features. Deep Learning (DL) models are widely used to extract features from images. General deep features may not be appropriate to represent chest x-rays as they have a few semantic regions. Though the Bag of Visual Words (BoVW) based features are shown to be more appropriate for x-ray type of images, existing BoVW features may not capture enough information to differentiate COVID-19 infection from other pneumonia-related infections. In this paper, we propose a new BoVW method over deep features, called Bag of Deep Visual Words (BoDVW), by removing the feature map normalization step and adding deep features normalization step on the raw feature maps. This helps to preserve the semantics of each feature map that may have important clues to differentiate COVID-19 from pneumonia. We evaluate the effectiveness of our proposed BoDVW features in chest x-rays classification using Support Vector Machine (SVM) to diagnose COVID-19. Our results on a publicly available COVID-19 x-ray dataset reveal that our features produce stable and prominent classification accuracy, particularly differentiating COVID-19 infection from other pneumonia, in shorter computation time compared to the state-of-the-art methods. Thus, our method could be a very useful tool for quick diagnosis of COVID-19 patients on a large scale.
CM-NAS: Rethinking Cross-Modality Neural Architectures for Visible-Infrared Person Re-Identification
Jan 21, 2021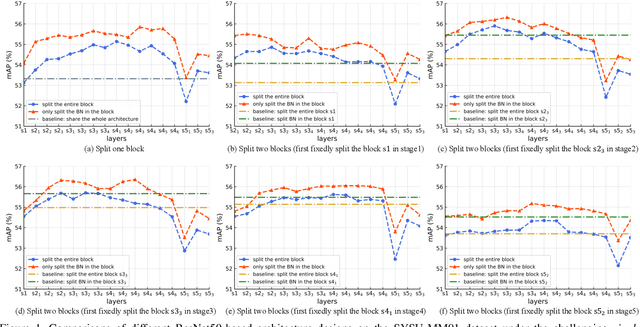
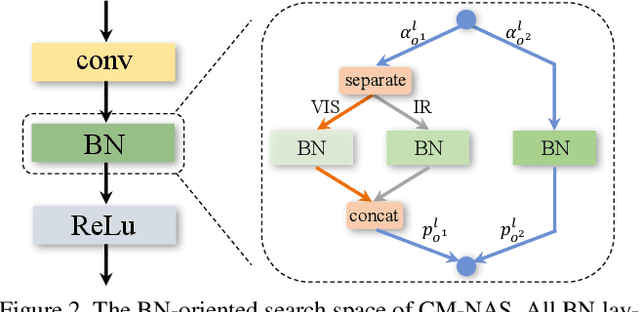
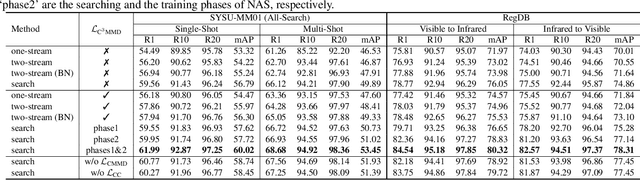
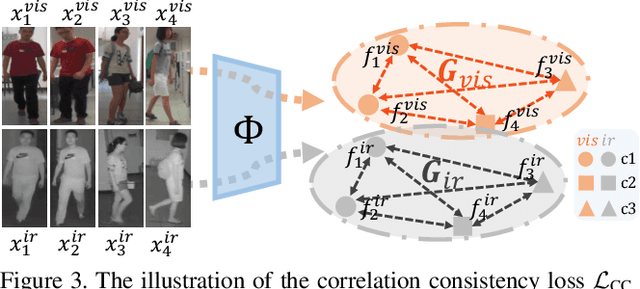
Visible-Infrared person re-identification (VI-ReID) aims at matching cross-modality pedestrian images, breaking through the limitation of single-modality person ReID in dark environment. In order to mitigate the impact of large modality discrepancy, existing works manually design various two-stream architectures to separately learn modality-specific and modality-sharable representations. Such a manual design routine, however, highly depends on massive experiments and empirical practice, which is time consuming and labor intensive. In this paper, we systematically study the manually designed architectures, and identify that appropriately splitting Batch Normalization (BN) layers to learn modality-specific representations will bring a great boost towards cross-modality matching. Based on this observation, the essential objective is to find the optimal splitting scheme for each BN layer. To this end, we propose a novel method, named Cross-Modality Neural Architecture Search (CM-NAS). It consists of a BN-oriented search space in which the standard optimization can be fulfilled subject to the cross-modality task. Besides, in order to better guide the search process, we further formulate a new Correlation Consistency based Class-specific Maximum Mean Discrepancy (C3MMD) loss. Apart from the modality discrepancy, it also concerns the similarity correlations, which have been overlooked before, in the two modalities. Resorting to these advantages, our method outperforms state-of-the-art counterparts in extensive experiments, improving the Rank-1/mAP by 6.70%/6.13% on SYSU-MM01 and 12.17%/11.23% on RegDB. The source code will be released soon.
A Deep Learning-Based Approach to Extracting Periosteal and Endosteal Contours of Proximal Femur in Quantitative CT Images
Feb 03, 2021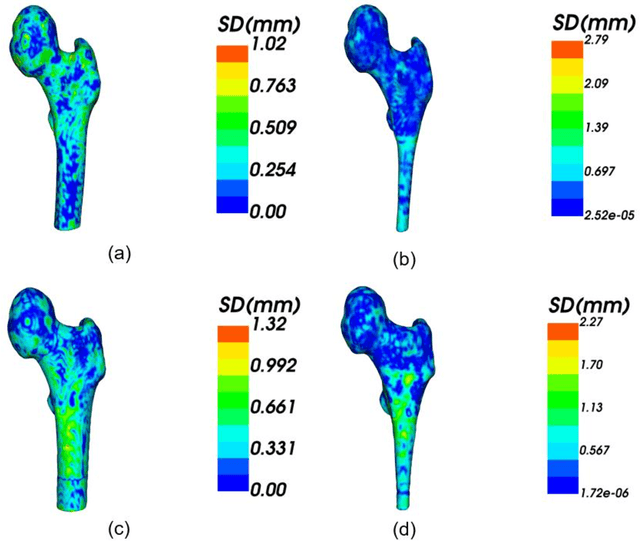
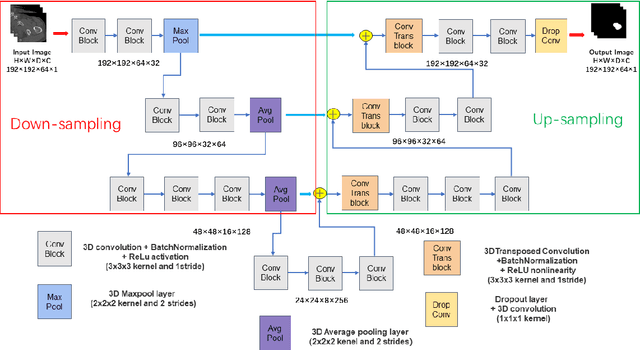
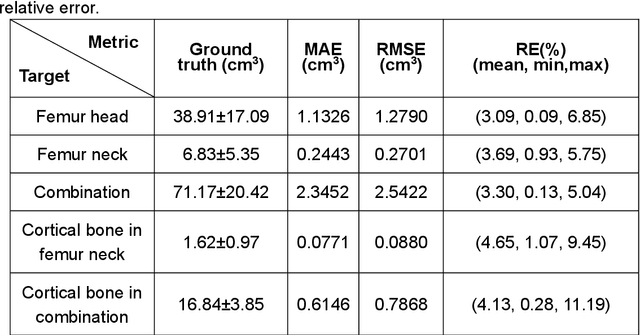
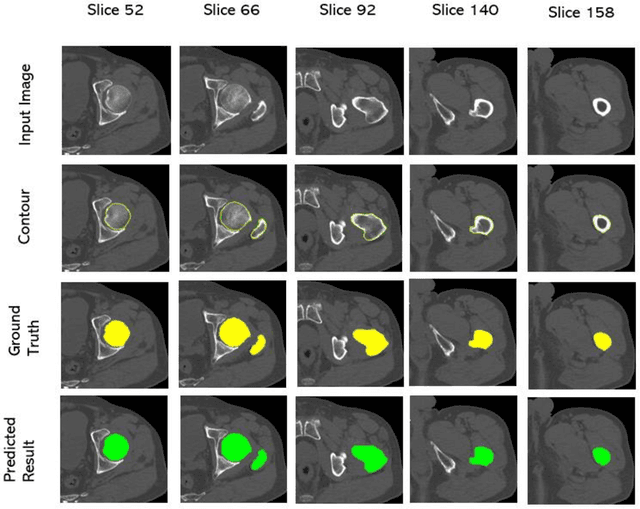
Automatic CT segmentation of proximal femur is crucial for the diagnosis and risk stratification of orthopedic diseases; however, current methods for the femur CT segmentation mainly rely on manual interactive segmentation, which is time-consuming and has limitations in both accuracy and reproducibility. In this study, we proposed an approach based on deep learning for the automatic extraction of the periosteal and endosteal contours of proximal femur in order to differentiate cortical and trabecular bone compartments. A three-dimensional (3D) end-to-end fully convolutional neural network, which can better combine the information between neighbor slices and get more accurate segmentation results, was developed for our segmentation task. 100 subjects aged from 50 to 87 years with 24,399 slices of proximal femur CT images were enrolled in this study. The separation of cortical and trabecular bone derived from the QCT software MIAF-Femur was used as the segmentation reference. We randomly divided the whole dataset into a training set with 85 subjects for 10-fold cross-validation and a test set with 15 subjects for evaluating the performance of models. Two models with the same network structures were trained and they achieved a dice similarity coefficient (DSC) of 97.87% and 96.49% for the periosteal and endosteal contours, respectively. To verify the excellent performance of our model for femoral segmentation, we measured the volume of different parts of the femur and compared it with the ground truth and the relative errors between predicted result and ground truth are all less than 5%. It demonstrated a strong potential for clinical use, including the hip fracture risk prediction and finite element analysis.
Logarithmic-Time Updates and Queries in Probabilistic Networks
Aug 07, 2014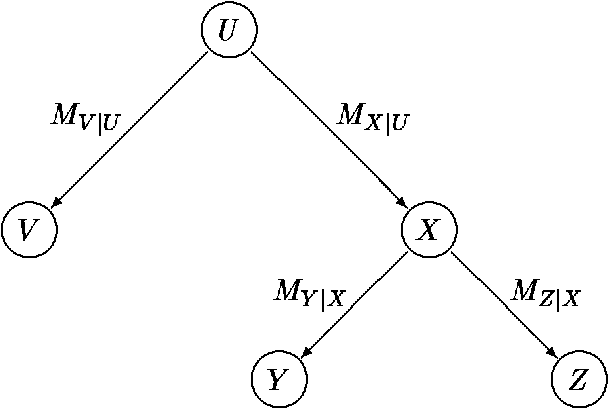
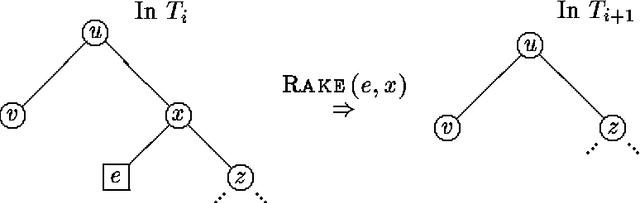
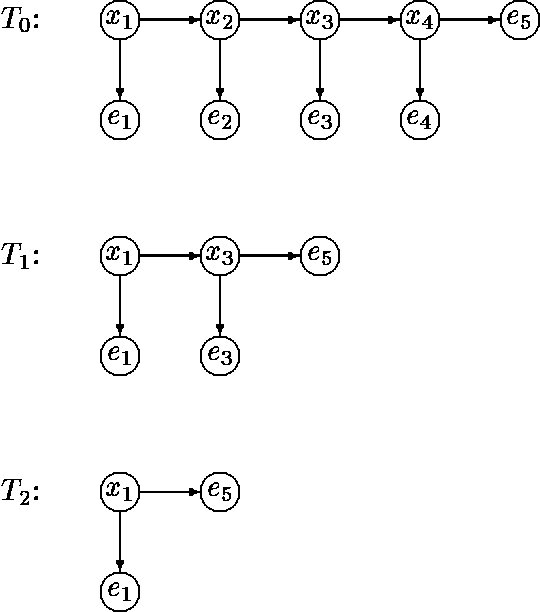

In this paper we propose a dynamic data structure that supports efficient algorithms for updating and querying singly connected Bayesian networks (causal trees and polytrees). In the conventional algorithms, new evidence in absorbed in time O(1) and queries are processed in time O(N), where N is the size of the network. We propose a practical algorithm which, after a preprocessing phase, allows us to answer queries in time O(log N) at the expense of O(logn N) time per evidence absorption. The usefulness of sub-linear processing time manifests itself in applications requiring (near) real-time response over large probabilistic databases.
Forecasting the Olympic medal distribution during a pandemic: a socio-economic machine learning model
Dec 08, 2020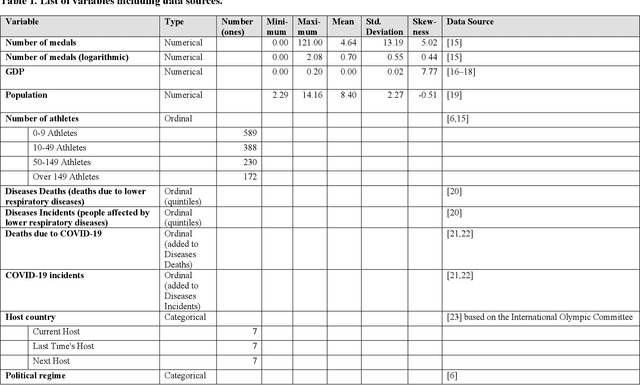
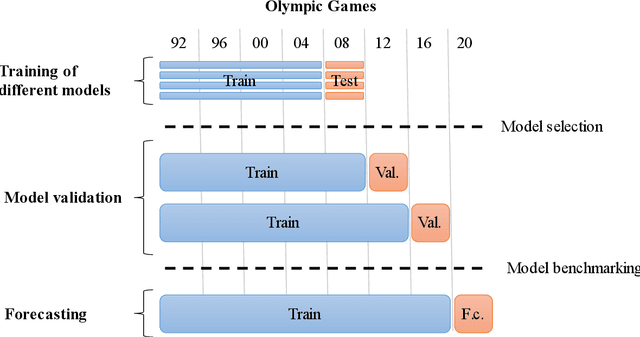
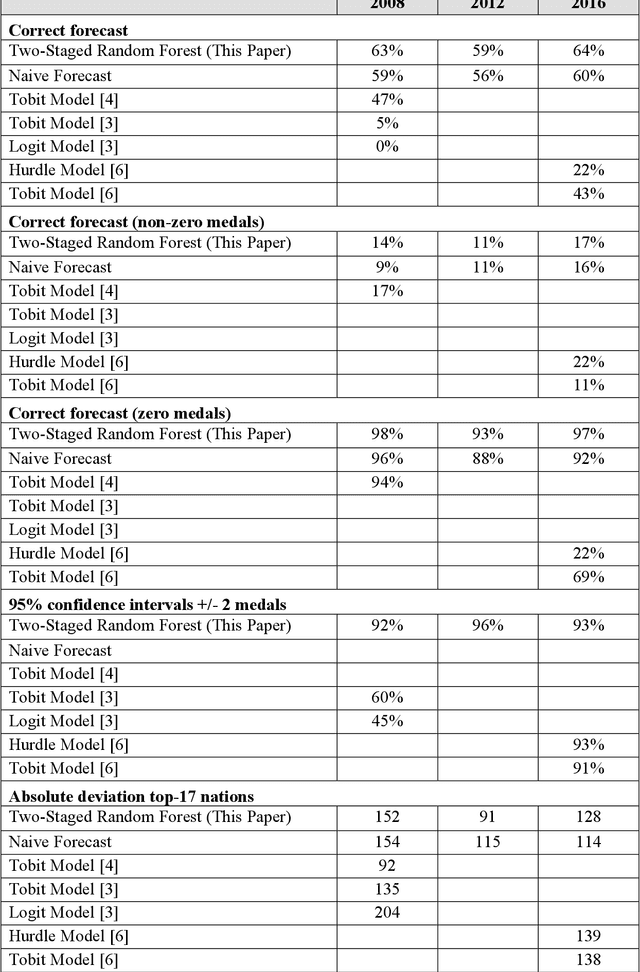
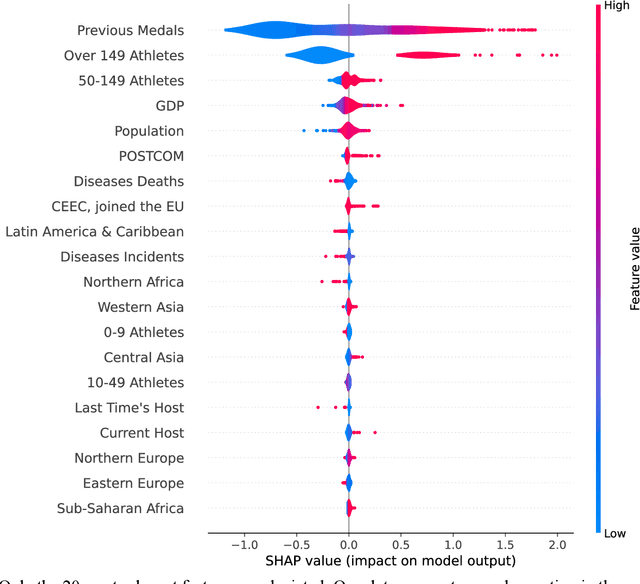
Forecasting the number of Olympic medals for each nation is highly relevant for different stakeholders: Ex ante, sports betting companies can determine the odds while sponsors and media companies can allocate their resources to promising teams. Ex post, sports politicians and managers can benchmark the performance of their teams and evaluate the drivers of success. To significantly increase the Olympic medal forecasting accuracy, we apply machine learning, more specifically a two-staged Random Forest, thus outperforming more traditional na\"ive forecast for three previous Olympics held between 2008 and 2016 for the first time. Regarding the Tokyo 2020 Games in 2021, our model suggests that the United States will lead the Olympic medal table, winning 120 medals, followed by China (87) and Great Britain (74). Intriguingly, we predict that the current COVID-19 pandemic will not significantly alter the medal count as all countries suffer from the pandemic to some extent (data inherent) and limited historical data points on comparable diseases (model inherent).
ExGAN: Adversarial Generation of Extreme Samples
Sep 17, 2020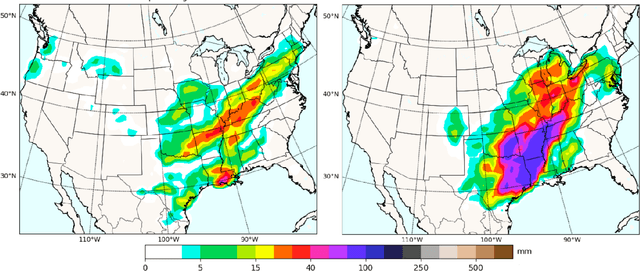

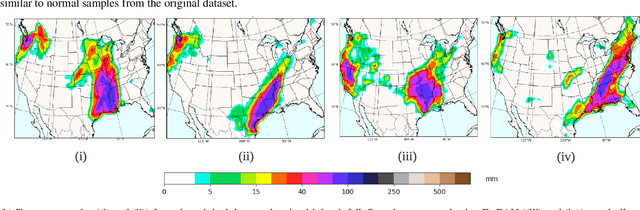
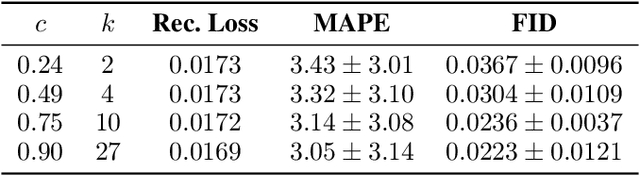
Mitigating the risk arising from extreme events is a fundamental goal with many applications, such as the modelling of natural disasters, financial crashes, epidemics, and many others. To manage this risk, a vital step is to be able to understand or generate a wide range of extreme scenarios. Existing approaches based on Generative Adversarial Networks (GANs) excel at generating realistic samples, but seek to generate typical samples, rather than extreme samples. Hence, in this work, we propose ExGAN, a GAN-based approach to generate realistic and extreme samples. To model the extremes of the training distribution in a principled way, our work draws from Extreme Value Theory (EVT), a probabilistic approach for modelling the extreme tails of distributions. For practical utility, our framework allows the user to specify both the desired extremeness measure, as well as the desired extremeness probability they wish to sample at. Experiments on real US Precipitation data show that our method generates realistic samples, based on visual inspection and quantitative measures, in an efficient manner. Moreover, generating increasingly extreme examples using ExGAN can be done in constant time (with respect to the extremeness probability), as opposed to the exponential time required by the baseline approach.