 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Predicting Infant Brain Connectivity with Federated Multi-Trajectory GNNs using Scarce Data
Jan 08, 2024
The understanding of the convoluted evolution of infant brain networks during the first postnatal year is pivotal for identifying the dynamics of early brain connectivity development. Existing deep learning solutions suffer from three major limitations. First, they cannot generalize to multi-trajectory prediction tasks, where each graph trajectory corresponds to a particular imaging modality or connectivity type (e.g., T1-w MRI). Second, existing models require extensive training datasets to achieve satisfactory performance which are often challenging to obtain. Third, they do not efficiently utilize incomplete time series data. To address these limitations, we introduce FedGmTE-Net++, a federated graph-based multi-trajectory evolution network. Using the power of federation, we aggregate local learnings among diverse hospitals with limited datasets. As a result, we enhance the performance of each hospital's local generative model, while preserving data privacy. The three key innovations of FedGmTE-Net++ are: (i) presenting the first federated learning framework specifically designed for brain multi-trajectory evolution prediction in a data-scarce environment, (ii) incorporating an auxiliary regularizer in the local objective function to exploit all the longitudinal brain connectivity within the evolution trajectory and maximize data utilization, (iii) introducing a two-step imputation process, comprising a preliminary KNN-based precompletion followed by an imputation refinement step that employs regressors to improve similarity scores and refine imputations. Our comprehensive experimental results showed the outperformance of FedGmTE-Net++ in brain multi-trajectory prediction from a single baseline graph in comparison with benchmark methods.
Rethinking Urban Mobility Prediction: A Super-Multivariate Time Series Forecasting Approach
Dec 04, 2023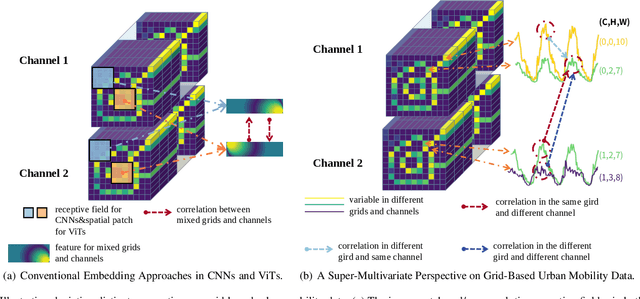
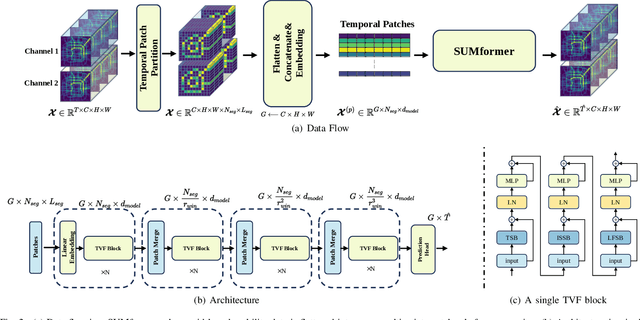
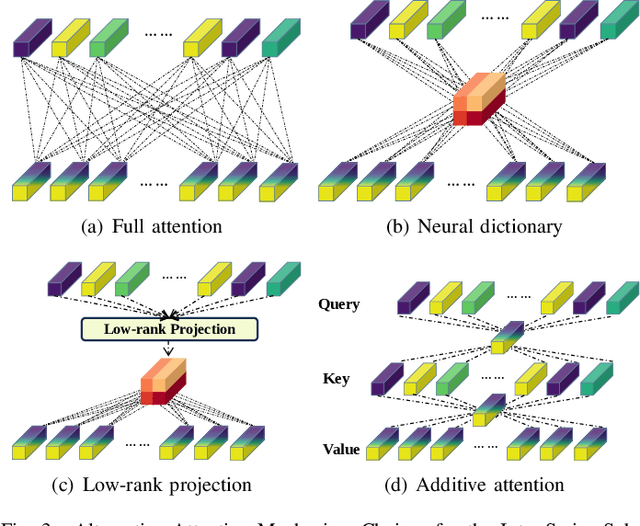
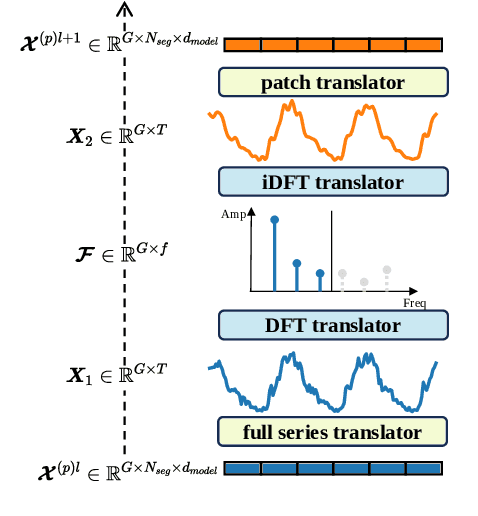
Long-term urban mobility predictions play a crucial role in the effective management of urban facilities and services. Conventionally, urban mobility data has been structured as spatiotemporal videos, treating longitude and latitude grids as fundamental pixels. Consequently, video prediction methods, relying on Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), have been instrumental in this domain. In our research, we introduce a fresh perspective on urban mobility prediction. Instead of oversimplifying urban mobility data as traditional video data, we regard it as a complex multivariate time series. This perspective involves treating the time-varying values of each grid in each channel as individual time series, necessitating a thorough examination of temporal dynamics, cross-variable correlations, and frequency-domain insights for precise and reliable predictions. To address this challenge, we present the Super-Multivariate Urban Mobility Transformer (SUMformer), which utilizes a specially designed attention mechanism to calculate temporal and cross-variable correlations and reduce computational costs stemming from a large number of time series. SUMformer also employs low-frequency filters to extract essential information for long-term predictions. Furthermore, SUMformer is structured with a temporal patch merge mechanism, forming a hierarchical framework that enables the capture of multi-scale correlations. Consequently, it excels in urban mobility pattern modeling and long-term prediction, outperforming current state-of-the-art methods across three real-world datasets.
Space-Time Approximation with Shallow Neural Networks in Fourier Lebesgue spaces
Dec 13, 2023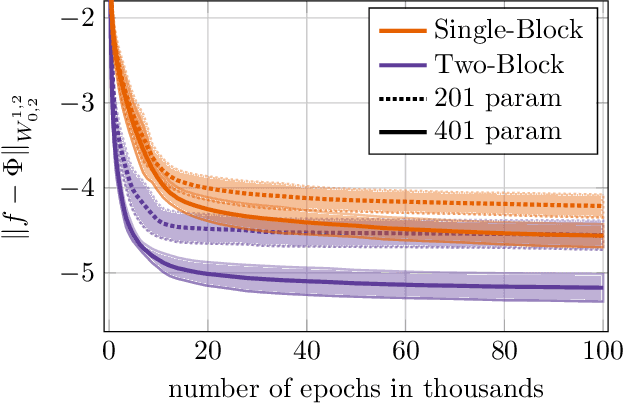
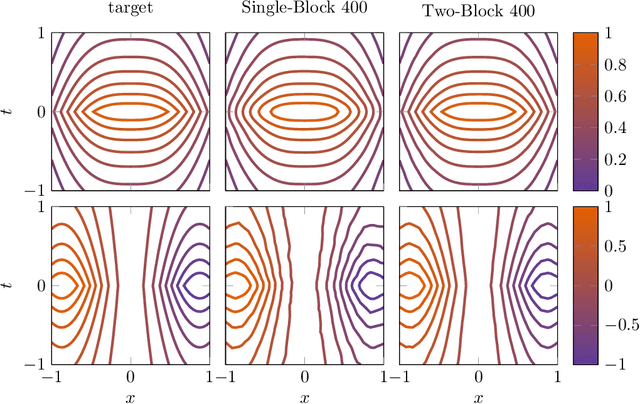
Approximation capabilities of shallow neural networks (SNNs) form an integral part in understanding the properties of deep neural networks (DNNs). In the study of these approximation capabilities some very popular classes of target functions are the so-called spectral Barron spaces. This spaces are of special interest when it comes to the approximation of partial differential equation (PDE) solutions. It has been shown that the solution of certain static PDEs will lie in some spectral Barron space. In order to alleviate the limitation to static PDEs and include a time-domain that might have a different regularity than the space domain, we extend the notion of spectral Barron spaces to anisotropic weighted Fourier-Lebesgue spaces. In doing so, we consider target functions that have two blocks of variables, among which each block is allowed to have different decay and integrability properties. For these target functions we first study the inclusion of anisotropic weighted Fourier-Lebesgue spaces in the Bochner-Sobolev spaces. With that we can now also measure the approximation error in terms of an anisotropic Sobolev norm, namely the Bochner-Sobolev norm. We use this observation in a second step where we establish a bound on the approximation rate for functions from the anisotropic weighted Fourier-Lebesgue spaces and approximation via SNNs in the Bochner-Sobolev norm.
Preference as Reward, Maximum Preference Optimization with Importance Sampling
Jan 08, 2024Preference learning is a key technology for aligning language models with human values. Reinforcement Learning from Human Feedback (RLHF) is a model based algorithm to optimize preference learning, which first fitting a reward model for preference score, and then optimizing generating policy with on-policy PPO algorithm to maximize the reward. The processing of RLHF is complex, time-consuming and unstable. Direct Preference Optimization (DPO) algorithm using off-policy algorithm to direct optimize generating policy and eliminating the need for reward model, which is data efficient and stable. DPO use Bradley-Terry model and log-loss which leads to over-fitting to the preference data at the expense of ignoring KL-regularization term when preference is deterministic. IPO uses a root-finding MSE loss to solve the ignoring KL-regularization problem. In this paper, we'll figure out, although IPO fix the problem when preference is deterministic, but both DPO and IPO fails the KL-regularization term because the support of preference distribution not equal to reference distribution. Then, we design a simple and intuitive off-policy preference optimization algorithm from an importance sampling view, which we call Maximum Preference Optimization (MPO), and add off-policy KL-regularization terms which makes KL-regularization truly effective. The objective of MPO bears resemblance to RLHF's objective, and likes IPO, MPO is off-policy. So, MPO attains the best of both worlds. To simplify the learning process and save memory usage, MPO eliminates the needs for both reward model and reference policy.
SeTformer is What You Need for Vision and Language
Jan 07, 2024The dot product self-attention (DPSA) is a fundamental component of transformers. However, scaling them to long sequences, like documents or high-resolution images, becomes prohibitively expensive due to quadratic time and memory complexities arising from the softmax operation. Kernel methods are employed to simplify computations by approximating softmax but often lead to performance drops compared to softmax attention. We propose SeTformer, a novel transformer, where DPSA is purely replaced by Self-optimal Transport (SeT) for achieving better performance and computational efficiency. SeT is based on two essential softmax properties: maintaining a non-negative attention matrix and using a nonlinear reweighting mechanism to emphasize important tokens in input sequences. By introducing a kernel cost function for optimal transport, SeTformer effectively satisfies these properties. In particular, with small and basesized models, SeTformer achieves impressive top-1 accuracies of 84.7% and 86.2% on ImageNet-1K. In object detection, SeTformer-base outperforms the FocalNet counterpart by +2.2 mAP, using 38% fewer parameters and 29% fewer FLOPs. In semantic segmentation, our base-size model surpasses NAT by +3.5 mIoU with 33% fewer parameters. SeTformer also achieves state-of-the-art results in language modeling on the GLUE benchmark. These findings highlight SeTformer's applicability in vision and language tasks.
Modal smoothing for analysis of room reflections measured with spherical microphone and loudspeaker arrays
Jan 07, 2024Spatial analysis of room acoustics is an ongoing research topic. Microphone arrays have been employed for spatial analyses with an important objective being the estimation of the direction-of-arrival (DOA) of direct sound and early room reflections using room impulse responses (RIRs). An optimal method for DOA estimation is the multiple signal classification algorithm. When RIRs are considered, this method typically fails due to the correlation of room reflections, which leads to rank deficiency of the cross-spectrum matrix. Preprocessing methods for rank restoration, which may involve averaging over frequency, for example, have been proposed exclusively for spherical arrays. However, these methods fail in the case of reflections with equal time delays, which may arise in practice and could be of interest. In this paper, a method is proposed for systems that combine a spherical microphone array and a spherical loudspeaker array, referred to as multiple-input multiple-output systems. This method, referred to as modal smoothing, exploits the additional spatial diversity for rank restoration and succeeds where previous methods fail, as demonstrated in a simulation study. Finally, combining modal smoothing with a preprocessing method is proposed in order to increase the number of DOAs that can be estimated using low-order spherical loudspeaker arrays.
Dance of Channel and Sequence: An Efficient Attention-Based Approach for Multivariate Time Series Forecasting
Dec 11, 2023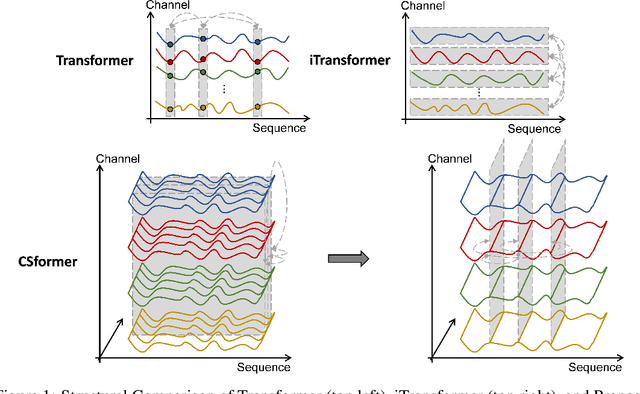

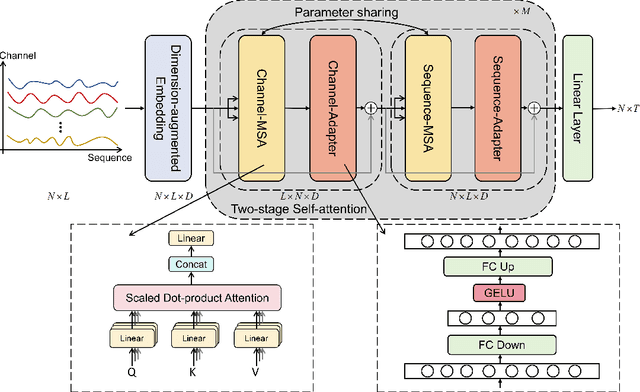
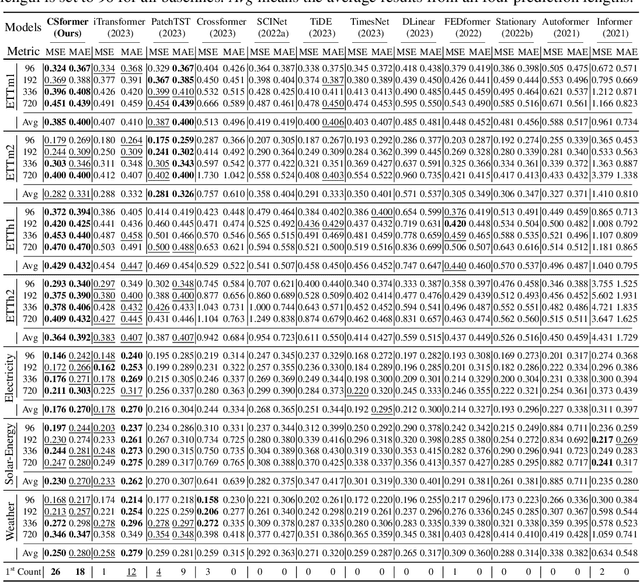
In recent developments, predictive models for multivariate time series analysis have exhibited commendable performance through the adoption of the prevalent principle of channel independence. Nevertheless, it is imperative to acknowledge the intricate interplay among channels, which fundamentally influences the outcomes of multivariate predictions. Consequently, the notion of channel independence, while offering utility to a certain extent, becomes increasingly impractical, leading to information degradation. In response to this pressing concern, we present CSformer, an innovative framework characterized by a meticulously engineered two-stage self-attention mechanism. This mechanism is purposefully designed to enable the segregated extraction of sequence-specific and channel-specific information, while sharing parameters to promote synergy and mutual reinforcement between sequences and channels. Simultaneously, we introduce sequence adapters and channel adapters, ensuring the model's ability to discern salient features across various dimensions. Rigorous experimentation, spanning multiple real-world datasets, underscores the robustness of our approach, consistently establishing its position at the forefront of predictive performance across all datasets. This augmentation substantially enhances the capacity for feature extraction inherent to multivariate time series data, facilitating a more comprehensive exploitation of the available information.
The Smooth Trajectory Estimator for LMB Filters
Jan 01, 2024This paper proposes a smooth-trajectory estimator for the labelled multi-Bernoulli (LMB) filter by exploiting the special structure of the generalised labelled multi-Bernoulli (GLMB) filter. We devise a simple and intuitive approach to store the best association map when approximating the GLMB random finite set (RFS) to the LMB RFS. In particular, we construct a smooth-trajectory estimator (i.e., an estimator over the entire trajectories of labelled estimates) for the LMB filter based on the history of the best association map and all of the measurements up to the current time. Experimental results under two challenging scenarios demonstrate significant tracking accuracy improvements with negligible additional computational time compared to the conventional LMB filter. The source code is publicly available at https://tinyurl.com/ste-lmb, aimed at promoting advancements in MOT algorithms.
An Investigation of Time Reversal Symmetry in Reinforcement Learning
Nov 28, 2023One of the fundamental challenges associated with reinforcement learning (RL) is that collecting sufficient data can be both time-consuming and expensive. In this paper, we formalize a concept of time reversal symmetry in a Markov decision process (MDP), which builds upon the established structure of dynamically reversible Markov chains (DRMCs) and time-reversibility in classical physics. Specifically, we investigate the utility of this concept in reducing the sample complexity of reinforcement learning. We observe that utilizing the structure of time reversal in an MDP allows every environment transition experienced by an agent to be transformed into a feasible reverse-time transition, effectively doubling the number of experiences in the environment. To test the usefulness of this newly synthesized data, we develop a novel approach called time symmetric data augmentation (TSDA) and investigate its application in both proprioceptive and pixel-based state within the realm of off-policy, model-free RL. Empirical evaluations showcase how these synthetic transitions can enhance the sample efficiency of RL agents in time reversible scenarios without friction or contact. We also test this method in more realistic environments where these assumptions are not globally satisfied. We find that TSDA can significantly degrade sample efficiency and policy performance, but can also improve sample efficiency under the right conditions. Ultimately we conclude that time symmetry shows promise in enhancing the sample efficiency of reinforcement learning and provide guidance when the environment and reward structures are of an appropriate form for TSDA to be employed effectively.
Towards Auto-Modeling of Formal Verification for NextG Protocols: A Multimodal cross- and self-attention Large Language Model Approach
Jan 02, 2024This paper introduces Auto-modeling of Formal Verification with Real-world Prompting for 5G and NextG protocols (AVRE), a novel system designed for the formal verification of Next Generation (NextG) communication protocols, addressing the increasing complexity and scalability challenges in network protocol design and verification. Utilizing Large Language Models (LLMs), AVRE transforms protocol descriptions into dependency graphs and formal models, efficiently resolving ambiguities and capturing design intent. The system integrates a transformer model with LLMs to autonomously establish quantifiable dependency relationships through cross- and self-attention mechanisms. Enhanced by iterative feedback from the HyFuzz experimental platform, AVRE significantly advances the accuracy and relevance of formal verification in complex communication protocols, offering a groundbreaking approach to validating sophisticated communication systems. We compare CAL's performance with state-of-the-art LLM-based models and traditional time sequence models, demonstrating its superiority in accuracy and robustness, achieving an accuracy of 95.94\% and an AUC of 0.98. This NLP-based approach enables, for the first time, the creation of exploits directly from design documents, making remarkable progress in scalable system verification and validation.