 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Asymptotic study of stochastic adaptive algorithm in non-convex landscape
Dec 14, 2020
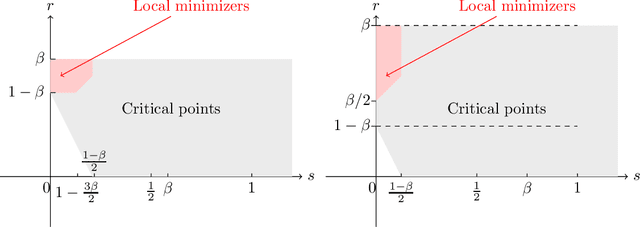
This paper studies some asymptotic properties of adaptive algorithms widely used in optimization and machine learning, and among them Adagrad and Rmsprop, which are involved in most of the blackbox deep learning algorithms. Our setup is the non-convex landscape optimization point of view, we consider a one time scale parametrization and we consider the situation where these algorithms may be used or not with mini-batches. We adopt the point of view of stochastic algorithms and establish the almost sure convergence of these methods when using a decreasing step-size point of view towards the set of critical points of the target function. With a mild extra assumption on the noise, we also obtain the convergence towards the set of minimizer of the function. Along our study, we also obtain a "convergence rate" of the methods, in the vein of the works of \cite{GhadimiLan}.
Federated Intrusion Detection for IoT with Heterogeneous Cohort Privacy
Jan 25, 2021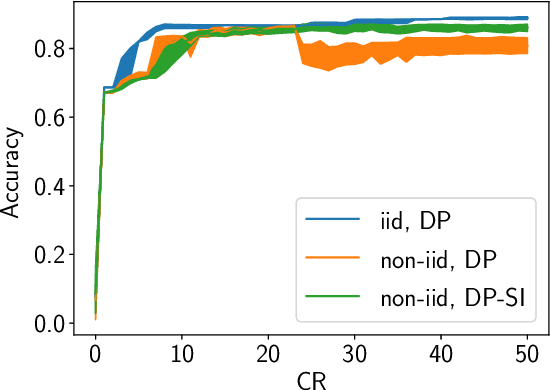
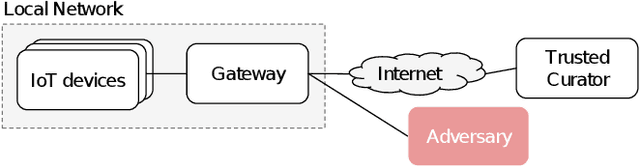
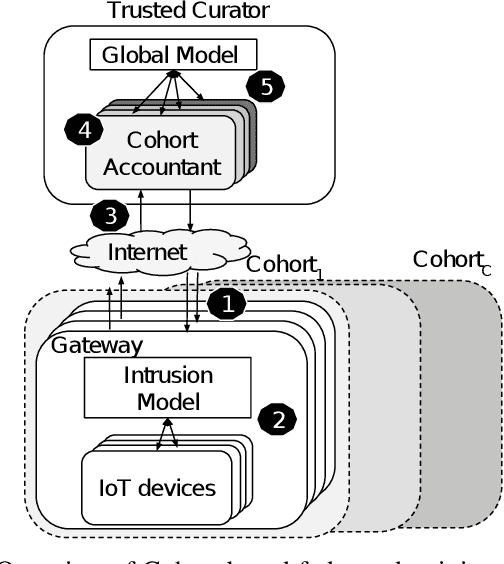
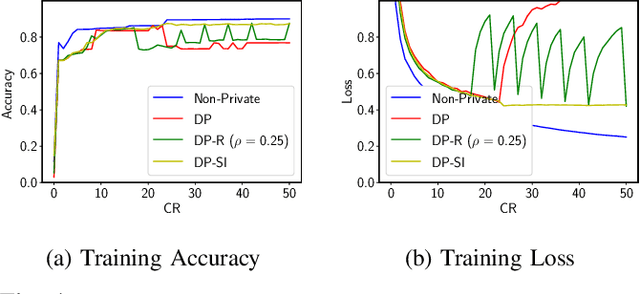
Internet of Things (IoT) devices are becoming increasingly popular and are influencing many application domains such as healthcare and transportation. These devices are used for real-world applications such as sensor monitoring, real-time control. In this work, we look at differentially private (DP) neural network (NN) based network intrusion detection systems (NIDS) to detect intrusion attacks on networks of such IoT devices. Existing NN training solutions in this domain either ignore privacy considerations or assume that the privacy requirements are homogeneous across all users. We show that the performance of existing differentially private stochastic methods degrade for clients with non-identical data distributions when clients' privacy requirements are heterogeneous. We define a cohort-based $(\epsilon,\delta)$-DP framework that models the more practical setting of IoT device cohorts with non-identical clients and heterogeneous privacy requirements. We propose two novel continual-learning based DP training methods that are designed to improve model performance in the aforementioned setting. To the best of our knowledge, ours is the first system that employs a continual learning-based approach to handle heterogeneity in client privacy requirements. We evaluate our approach on real datasets and show that our techniques outperform the baselines. We also show that our methods are robust to hyperparameter changes. Lastly, we show that one of our proposed methods can easily adapt to post-hoc relaxations of client privacy requirements.
TSEC: a framework for online experimentation under experimental constraints
Jan 17, 2021



Thompson sampling is a popular algorithm for solving multi-armed bandit problems, and has been applied in a wide range of applications, from website design to portfolio optimization. In such applications, however, the number of choices (or arms) $N$ can be large, and the data needed to make adaptive decisions require expensive experimentation. One is then faced with the constraint of experimenting on only a small subset of $K \ll N$ arms within each time period, which poses a problem for traditional Thompson sampling. We propose a new Thompson Sampling under Experimental Constraints (TSEC) method, which addresses this so-called "arm budget constraint". TSEC makes use of a Bayesian interaction model with effect hierarchy priors, to model correlations between rewards on different arms. This fitted model is then integrated within Thompson sampling, to jointly identify a good subset of arms for experimentation and to allocate resources over these arms. We demonstrate the effectiveness of TSEC in two problems with arm budget constraints. The first is a simulated website optimization study, where TSEC shows noticeable improvements over industry benchmarks. The second is a portfolio optimization application on industry-based exchange-traded funds, where TSEC provides more consistent and greater wealth accumulation over standard investment strategies.
How to find a unicorn: a novel model-free, unsupervised anomaly detection method for time series
Apr 23, 2020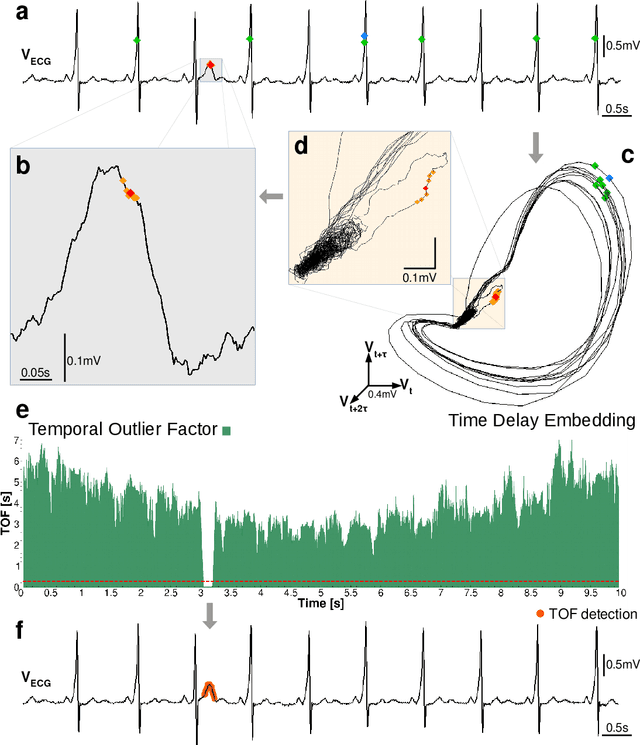
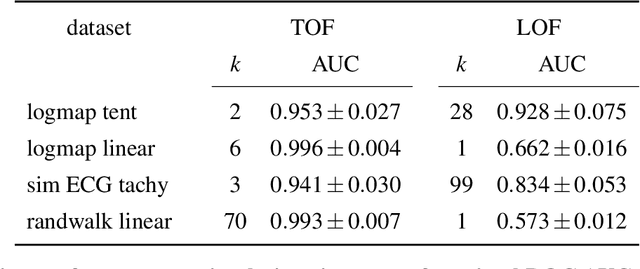
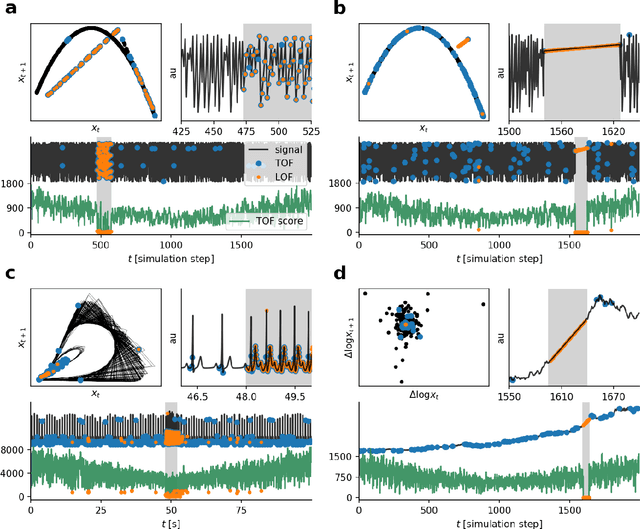
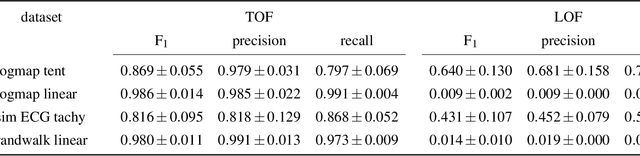
Recognition of anomalous events is a challenging but critical task in many scientific and industrial fields, especially when the properties of anomalies are unknown. In this paper, we present a new anomaly concept called "unicorn" or unique event and present a new, model-independent, unsupervised detection algorithm to detect unicorns. The Temporal Outlier Factor (TOF) is introduced to measure the uniqueness of events in continuous data sets from dynamic systems. The concept of unique events differ significantly from traditional outliers in many aspects: while repetitive outliers are no longer unique events, a unique event is not necessarily outlier in either pointwise or collective sense, it does not necessarily fall out from the distribution of normal activity. We examined the performance of our algorithm in recognizing unique events on different types of simulated data sets with anomalies and compared it with the standard Local Outlier Factor (LOF). TOF had superior performance compared to LOF even in recognizing traditional outliers and also recognized unique events that LOF did not. Benefits of the unicorn concept and the new detection method was illustrated by example data sets from very different scientific fields. In cases where the unique event is already known, our algorithm successfully recognized them: the gravitational waves of a black hole merger on LIGO detector data and the signs of respiratory failure on ECG data series. Furthermore, unique events were found on the LIBOR data set of the last 30 years.
STEER: Simple Temporal Regularization For Neural ODEs
Jul 01, 2020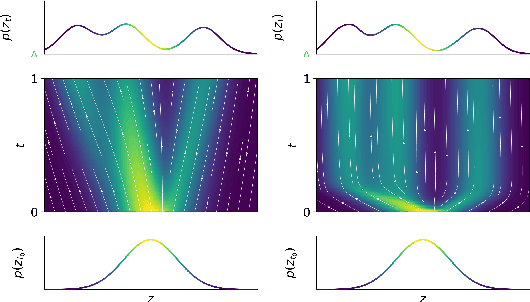
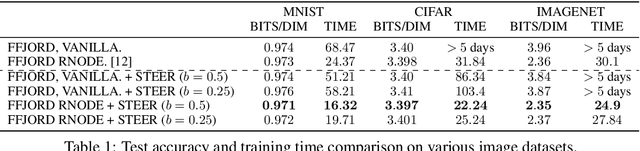
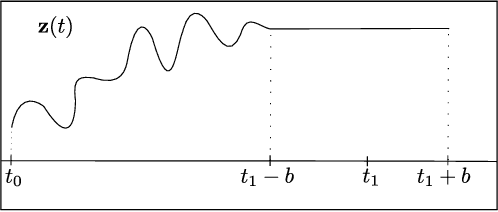
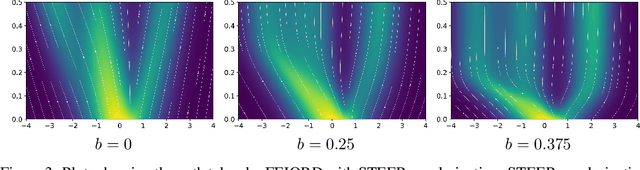
Training Neural Ordinary Differential Equations (ODEs) is often computationally expensive. Indeed, computing the forward pass of such models involves solving an ODE which can become arbitrarily complex during training. Recent works have shown that regularizing the dynamics of the ODE can partially alleviate this. In this paper we propose a new regularization technique: randomly sampling the end time of the ODE during training. The proposed regularization is simple to implement, has negligible overhead and is effective across a wide variety of tasks. Further, the technique is orthogonal to several other methods proposed to regularize the dynamics of ODEs and as such can be used in conjunction with them. We show through experiments on normalizing flows, time series models and image recognition that the proposed regularization can significantly decrease training time and even improve performance over baseline models.
Tailored Learning-Based Scheduling for Kubernetes-Oriented Edge-Cloud System
Jan 17, 2021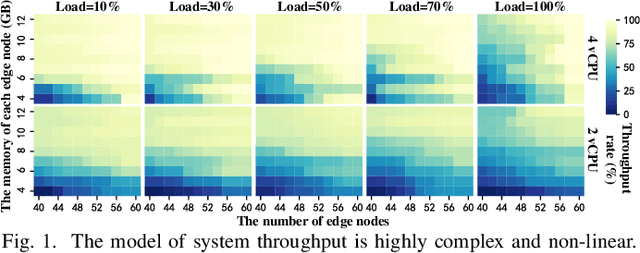
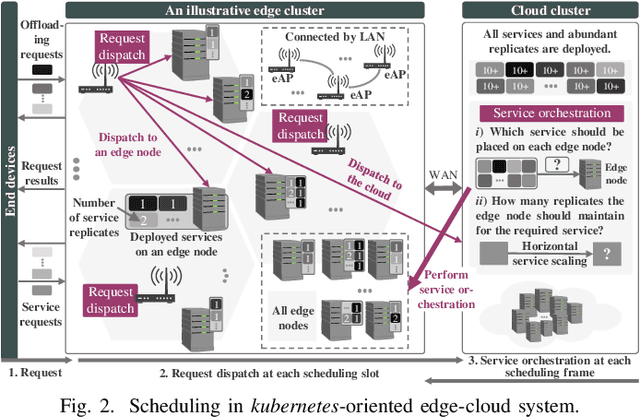
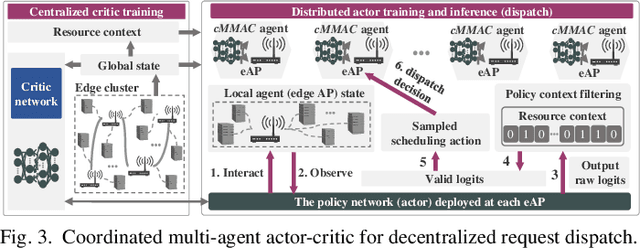
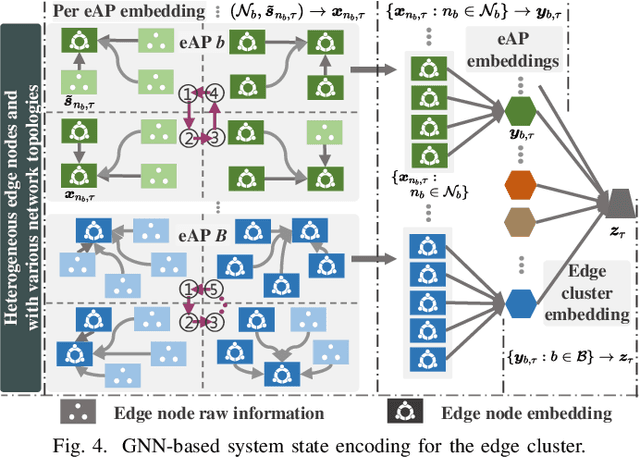
Kubernetes (k8s) has the potential to merge the distributed edge and the cloud but lacks a scheduling framework specifically for edge-cloud systems. Besides, the hierarchical distribution of heterogeneous resources and the complex dependencies among requests and resources make the modeling and scheduling of k8s-oriented edge-cloud systems particularly sophisticated. In this paper, we introduce KaiS, a learning-based scheduling framework for such edge-cloud systems to improve the long-term throughput rate of request processing. First, we design a coordinated multi-agent actor-critic algorithm to cater to decentralized request dispatch and dynamic dispatch spaces within the edge cluster. Second, for diverse system scales and structures, we use graph neural networks to embed system state information, and combine the embedding results with multiple policy networks to reduce the orchestration dimensionality by stepwise scheduling. Finally, we adopt a two-time-scale scheduling mechanism to harmonize request dispatch and service orchestration, and present the implementation design of deploying the above algorithms compatible with native k8s components. Experiments using real workload traces show that KaiS can successfully learn appropriate scheduling policies, irrespective of request arrival patterns and system scales. Moreover, KaiS can enhance the average system throughput rate by 14.3% while reducing scheduling cost by 34.7% compared to baselines.
Text Analytics for Resilience-Enabled Extreme EventsReconnaissance
Nov 26, 2020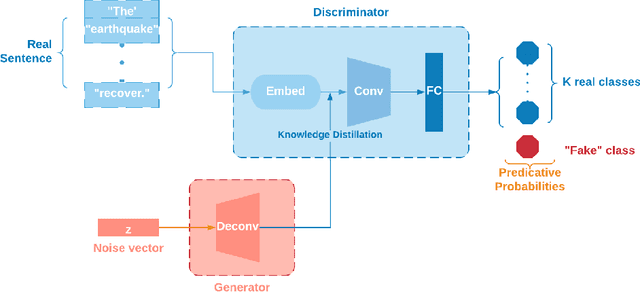
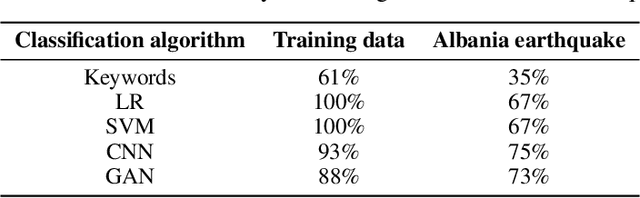
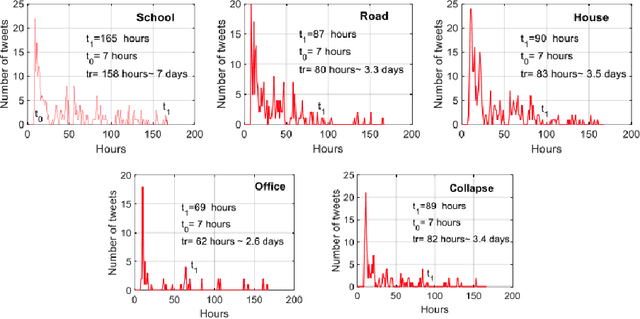

Post-hazard reconnaissance for natural disasters (e.g., earthquakes) is important for understanding the performance of the built environment, speeding up the recovery, enhancing resilience and making informed decisions related to current and future hazards. Natural language processing (NLP) is used in this study for the purposes of increasing the accuracy and efficiency of natural hazard reconnaissance through automation. The study particularly focuses on (1) automated data (news and social media) collection hosted by the Pacific Earthquake Engineering Research (PEER) Center server, (2) automatic generation of reconnaissance reports, and (3) use of social media to extract post-hazard information such as the recovery time. Obtained results are encouraging for further development and wider usage of various NLP methods in natural hazard reconnaissance.
Time-Contrastive Networks: Self-Supervised Learning from Video
Mar 20, 2018

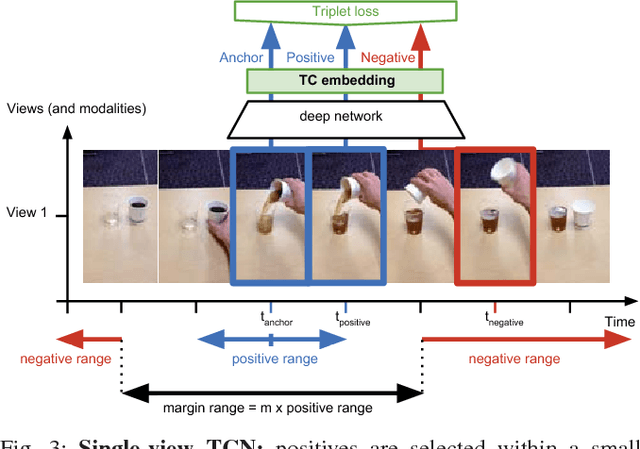
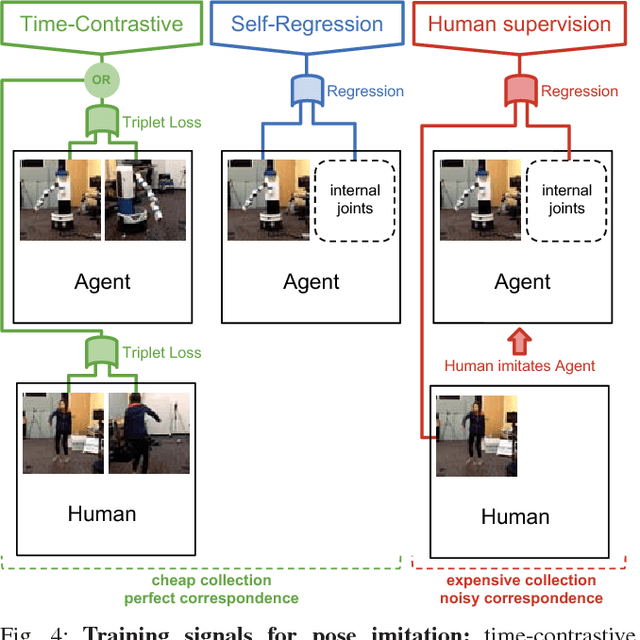
We propose a self-supervised approach for learning representations and robotic behaviors entirely from unlabeled videos recorded from multiple viewpoints, and study how this representation can be used in two robotic imitation settings: imitating object interactions from videos of humans, and imitating human poses. Imitation of human behavior requires a viewpoint-invariant representation that captures the relationships between end-effectors (hands or robot grippers) and the environment, object attributes, and body pose. We train our representations using a metric learning loss, where multiple simultaneous viewpoints of the same observation are attracted in the embedding space, while being repelled from temporal neighbors which are often visually similar but functionally different. In other words, the model simultaneously learns to recognize what is common between different-looking images, and what is different between similar-looking images. This signal causes our model to discover attributes that do not change across viewpoint, but do change across time, while ignoring nuisance variables such as occlusions, motion blur, lighting and background. We demonstrate that this representation can be used by a robot to directly mimic human poses without an explicit correspondence, and that it can be used as a reward function within a reinforcement learning algorithm. While representations are learned from an unlabeled collection of task-related videos, robot behaviors such as pouring are learned by watching a single 3rd-person demonstration by a human. Reward functions obtained by following the human demonstrations under the learned representation enable efficient reinforcement learning that is practical for real-world robotic systems. Video results, open-source code and dataset are available at https://sermanet.github.io/imitate
Gaussian RAM: Lightweight Image Classification via Stochastic Retina-Inspired Glimpse and Reinforcement Learning
Nov 12, 2020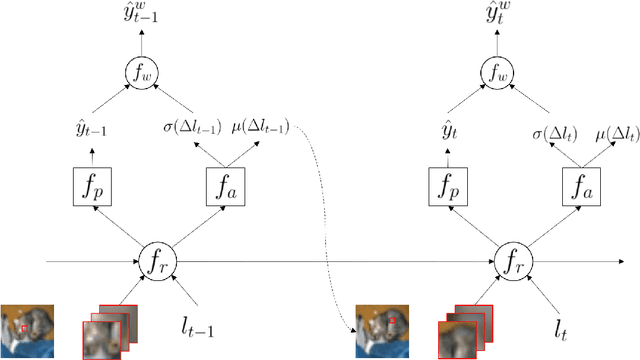


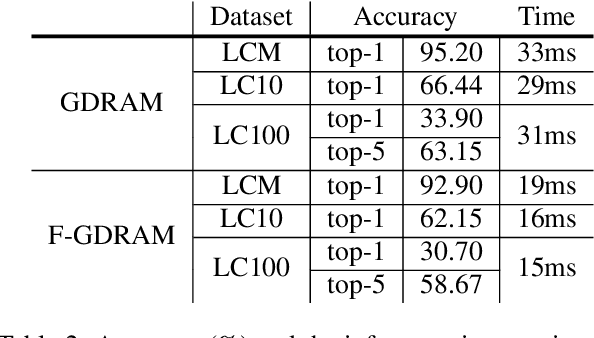
Previous studies on image classification have mainly focused on the performance of the networks, not on real-time operation or model compression. We propose a Gaussian Deep Recurrent visual Attention Model (GDRAM)- a reinforcement learning based lightweight deep neural network for large scale image classification that outperforms the conventional CNN (Convolutional Neural Network) which uses the entire image as input. Highly inspired by the biological visual recognition process, our model mimics the stochastic location of the retina with Gaussian distribution. We evaluate the model on Large cluttered MNIST, Large CIFAR-10 and Large CIFAR-100 datasets which are resized to 128 in both width and height.
Using Feature Alignment can Improve Clean Average Precision and Adversarial Robustness in Object Detection
Dec 08, 2020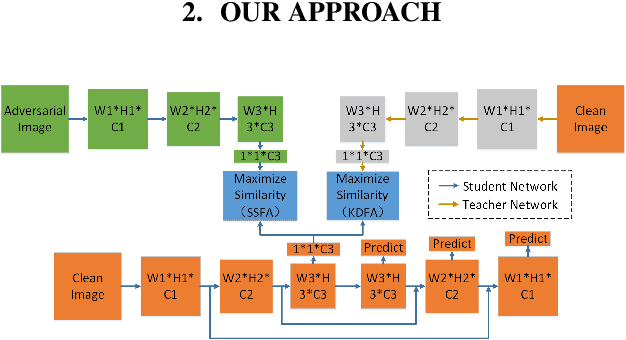
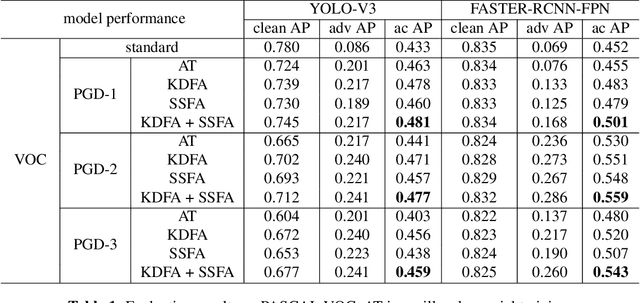
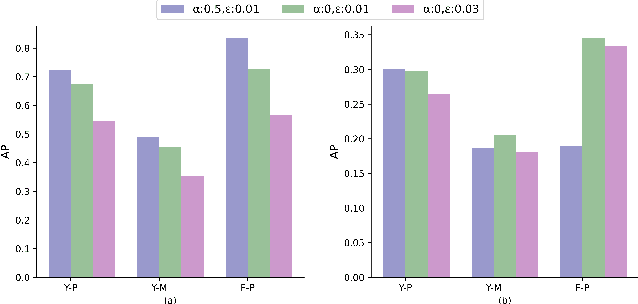
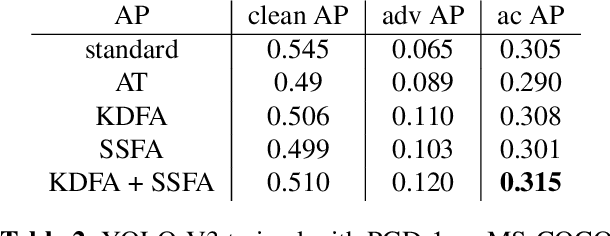
The 2D object detection in clean images has been a well studied topic, but its vulnerability against adversarial attacks is still worrying. Existing work has improved the robustness of object detector by adversarial training, but at the same time, the average precision (AP) on clean images drops significantly. In this paper, we improve object detection algorithm by guiding the output of intermediate feature layer. On the basis of adversarial training, we propose two feature alignment methods, namely Knowledge-Distilled Feature Alignment (KDFA) and Self-Supervised Feature Alignment (SSFA). The detector's clean AP and robustness can be improved by aligning the features of the middle layer of the network. We conduct extensive experiments on PASCAL VOC and MS-COCO datasets to verify the effectiveness of our proposed approach. The code of our experiments is available at https://github.com/grispeut/Feature-Alignment.git.