 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Primal-dual Learning for the Model-free Risk-constrained Linear Quadratic Regulator
Dec 10, 2020
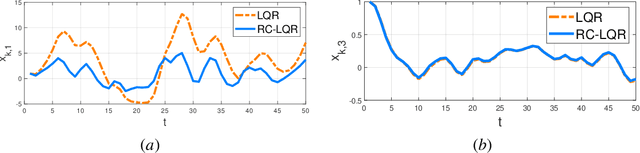
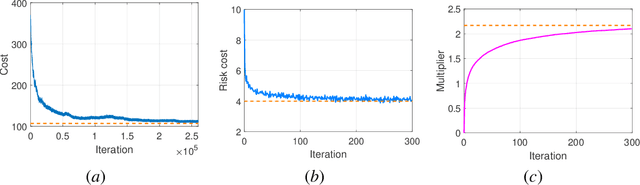
Risk-aware control, though with promise to tackle unexpected events, requires a known exact dynamical model. In this work, we propose a model-free framework to learn a risk-aware controller with a focus on the linear system. We formulate it as a discrete-time infinite-horizon LQR problem with a state predictive variance constraint. To solve it, we parameterize the policy with a feedback gain pair and leverage primal-dual methods to optimize it by solely using data. We first study the optimization landscape of the Lagrangian function and establish the strong duality in spite of its non-convex nature. Alongside, we find that the Lagrangian function enjoys an important local gradient dominance property, which is then exploited to develop a convergent random search algorithm to learn the dual function. Furthermore, we propose a primal-dual algorithm with global convergence to learn the optimal policy-multiplier pair. Finally, we validate our results via simulations.
A Review on Deep Learning in UAV Remote Sensing
Jan 22, 2021

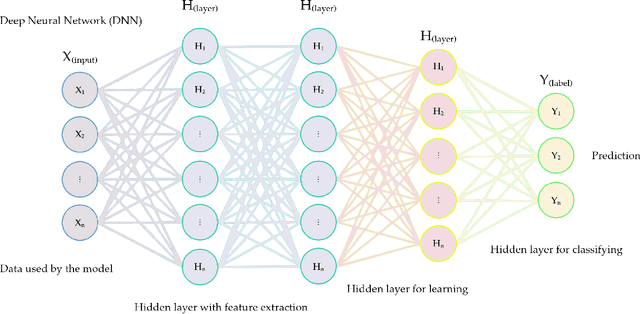
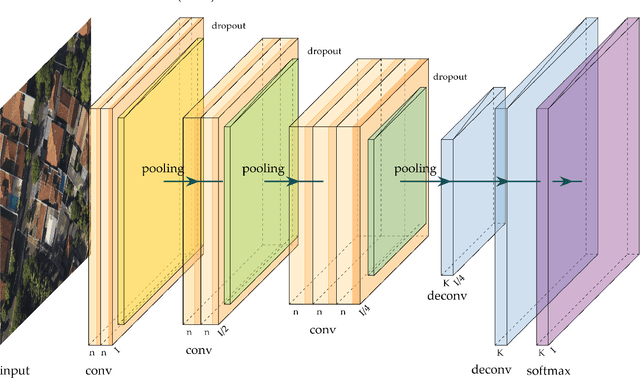
Deep Neural Networks (DNNs) learn representation from data with an impressive capability, and brought important breakthroughs for processing images, time-series, natural language, audio, video, and many others. In the remote sensing field, surveys and literature revisions specifically involving DNNs algorithms' applications have been conducted in an attempt to summarize the amount of information produced in its subfields. Recently, Unmanned Aerial Vehicles (UAV) based applications have dominated aerial sensing research. However, a literature revision that combines both "deep learning" and "UAV remote sensing" thematics has not yet been conducted. The motivation for our work was to present a comprehensive review of the fundamentals of Deep Learning (DL) applied in UAV-based imagery. We focused mainly on describing classification and regression techniques used in recent applications with UAV-acquired data. For that, a total of 232 papers published in international scientific journal databases was examined. We gathered the published material and evaluated their characteristics regarding application, sensor, and technique used. We relate how DL presents promising results and has the potential for processing tasks associated with UAV-based image data. Lastly, we project future perspectives, commentating on prominent DL paths to be explored in the UAV remote sensing field. Our revision consists of a friendly-approach to introduce, commentate, and summarize the state-of-the-art in UAV-based image applications with DNNs algorithms in diverse subfields of remote sensing, grouping it in the environmental, urban, and agricultural contexts.
Bid Shading by Win-Rate Estimation and Surplus Maximization
Sep 19, 2020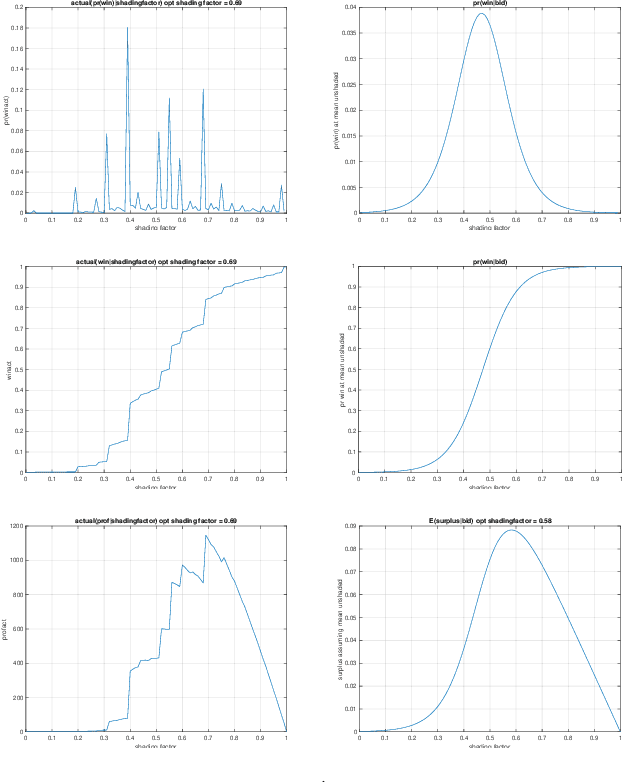
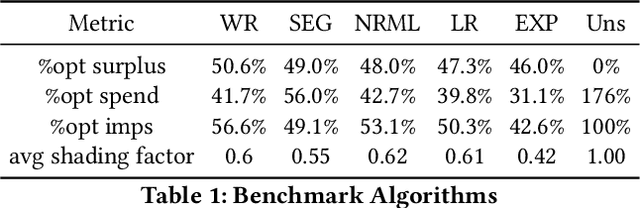
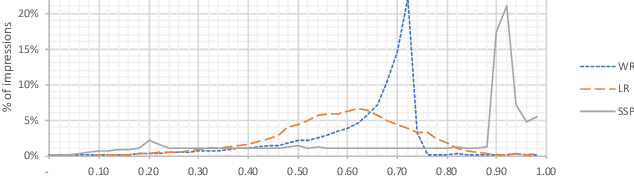
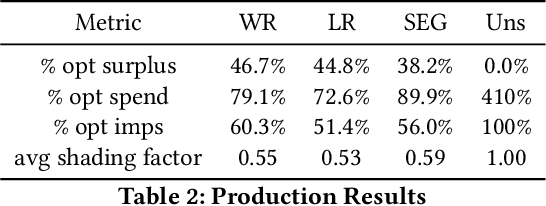
This paper describes a new win-rate based bid shading algorithm (WR) that does not rely on the minimum-bid-to-win feedback from a Sell-Side Platform (SSP). The method uses a modified logistic regression to predict the profit from each possible shaded bid price. The function form allows fast maximization at run-time, a key requirement for Real-Time Bidding (RTB) systems. We report production results from this method along with several other algorithms. We found that bid shading, in general, can deliver significant value to advertisers, reducing price per impression to about 55% of the unshaded cost. Further, the particular approach described in this paper captures 7% more profit for advertisers, than do benchmark methods of just bidding the most probable winning price. We also report 4.3% higher surplus than an industry Sell-Side Platform shading service. Furthermore, we observed 3% - 7% lower eCPM, eCPC and eCPA when the algorithm was integrated with budget controllers. We attribute the gains above as being mainly due to the explicit maximization of the surplus function, and note that other algorithms can take advantage of this same approach.
Low-light Environment Neural Surveillance
Jul 02, 2020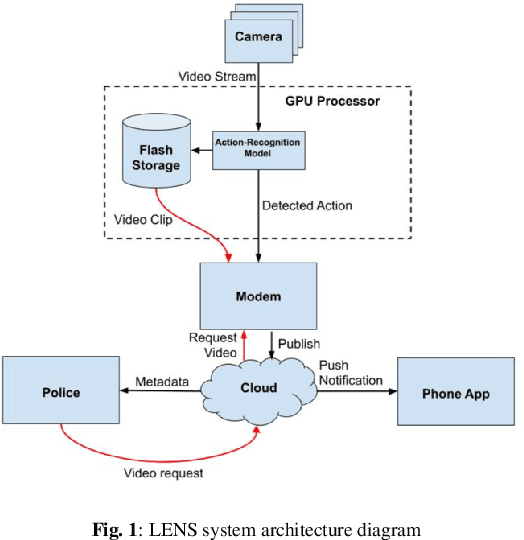
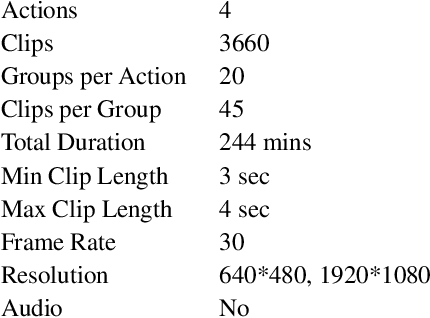
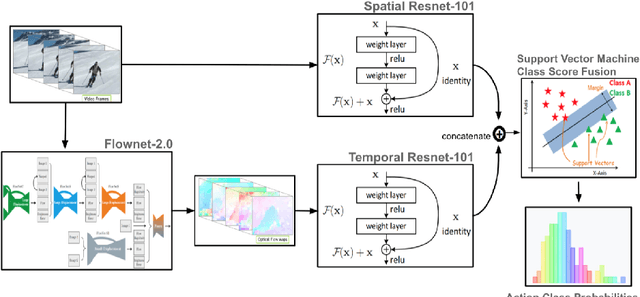
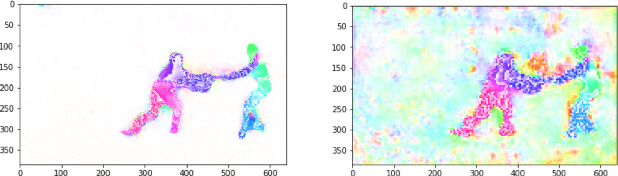
We design and implement an end-to-end system for real-time crime detection in low-light environments. Unlike Closed-Circuit Television, which performs reactively, the Low-Light Environment Neural Surveillance provides real time crime alerts. The system uses a low-light video feed processed in real-time by an optical-flow network, spatial and temporal networks, and a Support Vector Machine to identify shootings, assaults, and thefts. We create a low-light action-recognition dataset, LENS-4, which will be publicly available. An IoT infrastructure set up via Amazon Web Services interprets messages from the local board hosting the camera for action recognition and parses the results in the cloud to relay messages. The system achieves 71.5% accuracy at 20 FPS. The user interface is a mobile app which allows local authorities to receive notifications and to view a video of the crime scene. Citizens have a public app which enables law enforcement to push crime alerts based on user proximity.
Comparative Study of Machine Learning Models and BERT on SQuAD
May 22, 2020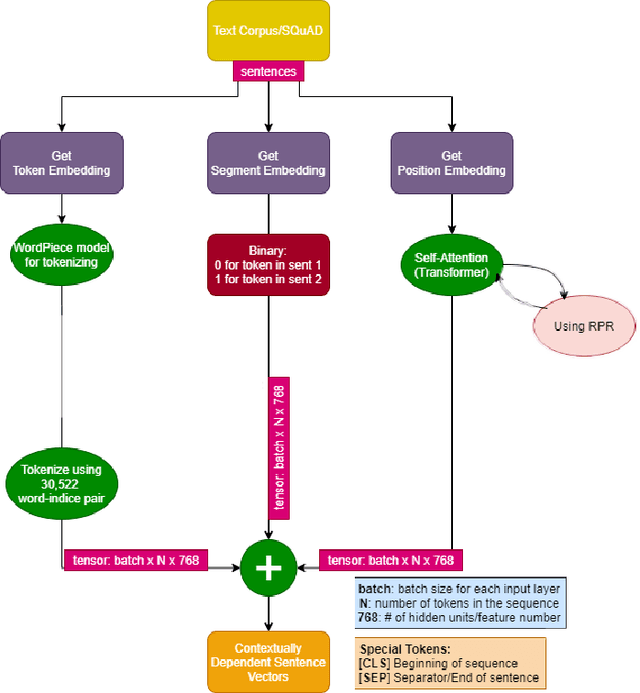
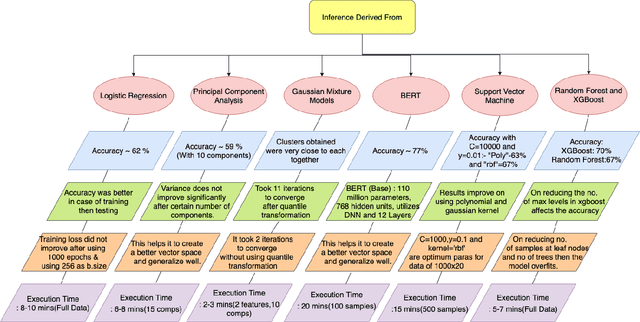
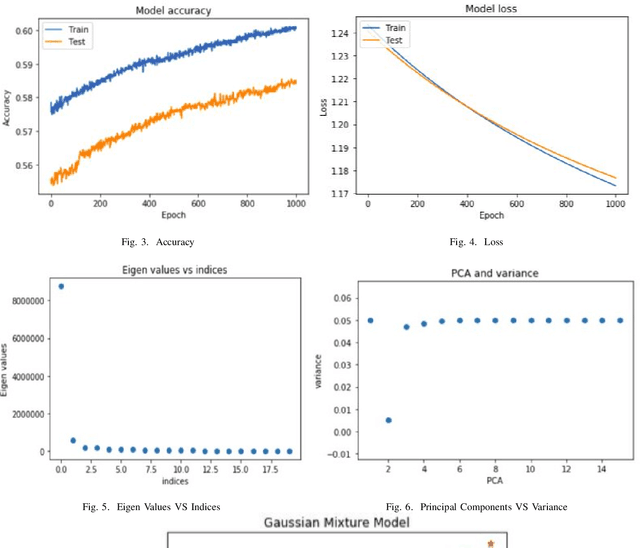
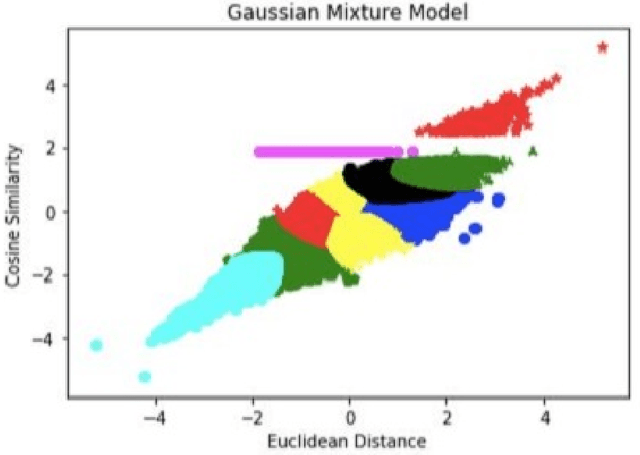
This study aims to provide a comparative analysis of performance of certain models popular in machine learning and the BERT model on the Stanford Question Answering Dataset (SQuAD). The analysis shows that the BERT model, which was once state-of-the-art on SQuAD, gives higher accuracy in comparison to other models. However, BERT requires a greater execution time even when only 100 samples are used. This shows that with increasing accuracy more amount of time is invested in training the data. Whereas in case of preliminary machine learning models, execution time for full data is lower but accuracy is compromised.
Intelligent Reflecting Surface Enhanced Multi-UAV NOMA Networks
Jan 22, 2021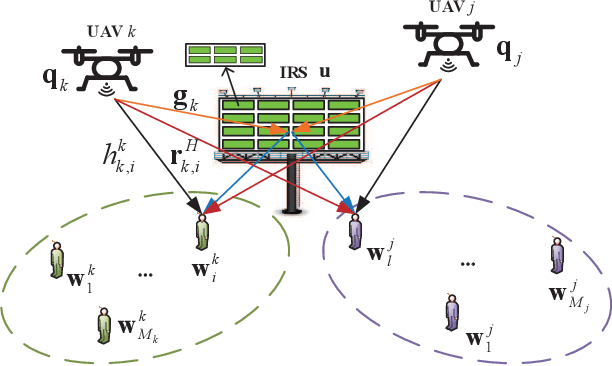
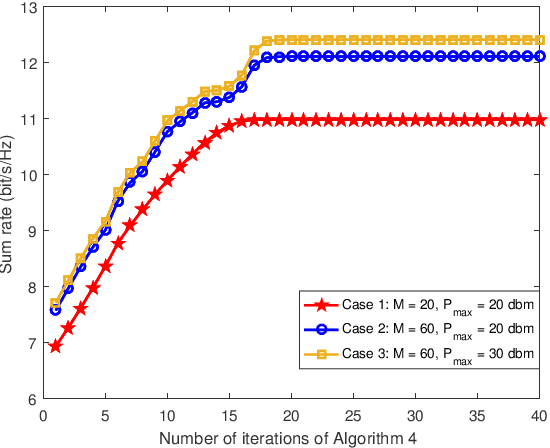
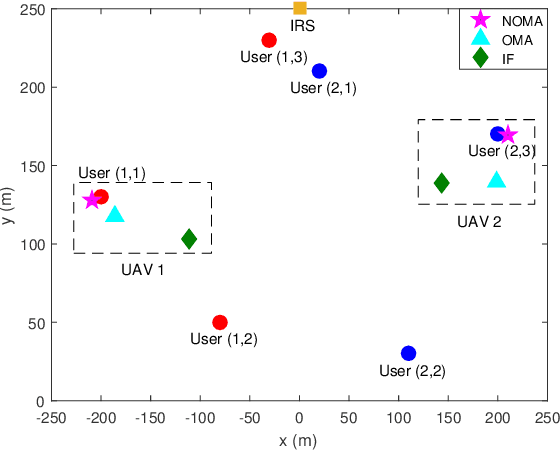
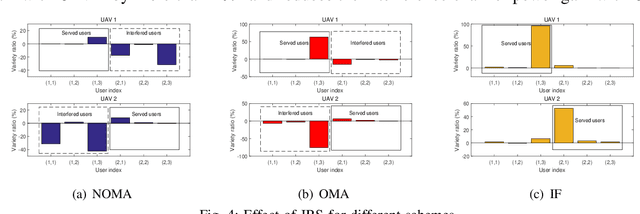
Intelligent reflecting surface (IRS) enhanced multi-unmanned aerial vehicle (UAV) non-orthogonal multiple access (NOMA) networks are investigated. A new transmission framework is proposed, where multiple UAV-mounted base stations employ NOMA to serve multiple groups of ground users with the aid of an IRS. The three-dimensional (3D) placement and transmit power of UAVs, the reflection matrix of the IRS, and the NOMA decoding orders among users are jointly optimized for maximization of the sum rate of considered networks. To tackle the formulated mixed-integer non-convex optimization problem with coupled variables, a block coordinate descent (BCD)-based iterative algorithm is developed. Specifically, the original problem is decomposed into three subproblems, which are alternatingly solved by exploiting the penalty method and the successive convex approximation technique. The proposed BCD-based algorithm is demonstrated to be able to obtain a stationary point of the original problem with polynomial time complexity. Numerical results show that: 1) the proposed NOMA-IRS scheme for multi-UAV networks achieves a higher sum rate compared to the benchmark schemes, i.e., orthogonal multiple access (OMA)-IRS and NOMA without IRS; 2) the use of IRS is capable of providing performance gain for multi-UAV networks by both enhancing channel qualities of UAVs to their served users and mitigating the inter-UAV interference; and 3) optimizing the UAV placement can make the sum rate gain brought by NOMA more distinct due to the flexible decoding order design.
On-Manifold Preintegration for Real-Time Visual-Inertial Odometry
Oct 30, 2016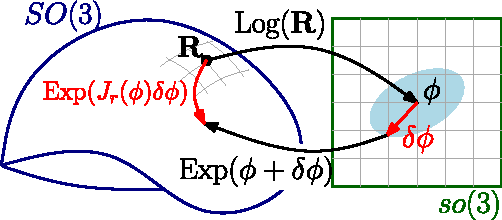
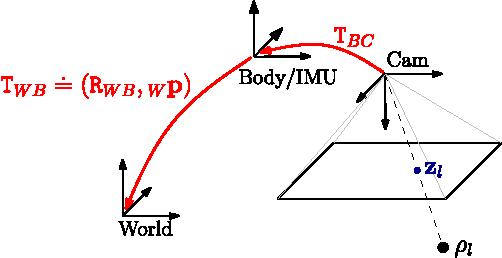
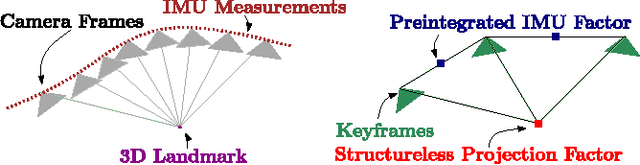
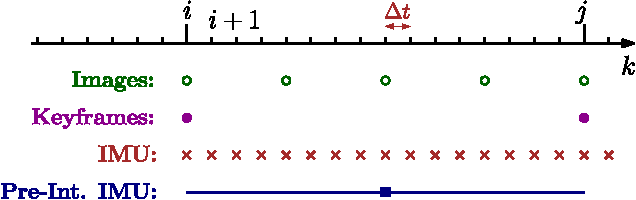
Current approaches for visual-inertial odometry (VIO) are able to attain highly accurate state estimation via nonlinear optimization. However, real-time optimization quickly becomes infeasible as the trajectory grows over time, this problem is further emphasized by the fact that inertial measurements come at high rate, hence leading to fast growth of the number of variables in the optimization. In this paper, we address this issue by preintegrating inertial measurements between selected keyframes into single relative motion constraints. Our first contribution is a \emph{preintegration theory} that properly addresses the manifold structure of the rotation group. We formally discuss the generative measurement model as well as the nature of the rotation noise and derive the expression for the \emph{maximum a posteriori} state estimator. Our theoretical development enables the computation of all necessary Jacobians for the optimization and a-posteriori bias correction in analytic form. The second contribution is to show that the preintegrated IMU model can be seamlessly integrated into a visual-inertial pipeline under the unifying framework of factor graphs. This enables the application of incremental-smoothing algorithms and the use of a \emph{structureless} model for visual measurements, which avoids optimizing over the 3D points, further accelerating the computation. We perform an extensive evaluation of our monocular \VIO pipeline on real and simulated datasets. The results confirm that our modelling effort leads to accurate state estimation in real-time, outperforming state-of-the-art approaches.
Convolutional Neural Network Training with Distributed K-FAC
Jul 01, 2020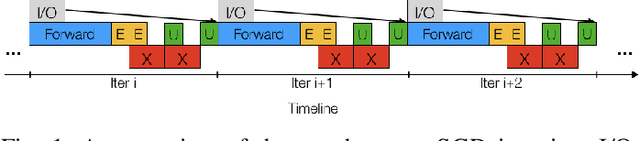
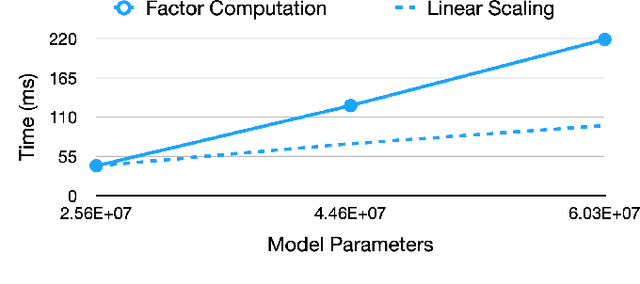
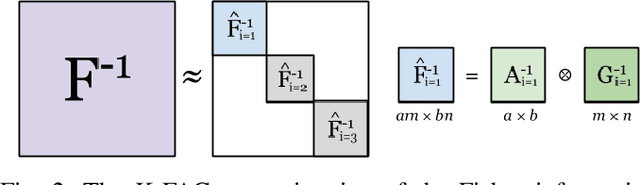
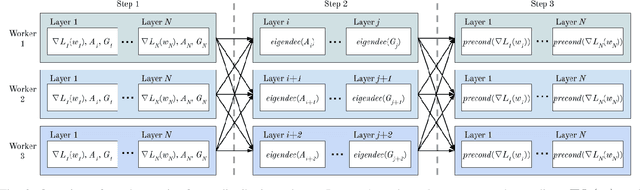
Training neural networks with many processors can reduce time-to-solution; however, it is challenging to maintain convergence and efficiency at large scales. The Kronecker-factored Approximate Curvature (K-FAC) was recently proposed as an approximation of the Fisher Information Matrix that can be used in natural gradient optimizers. We investigate here a scalable K-FAC design and its applicability in convolutional neural network (CNN) training at scale. We study optimization techniques such as layer-wise distribution strategies, inverse-free second-order gradient evaluation, and dynamic K-FAC update decoupling to reduce training time while preserving convergence. We use residual neural networks (ResNet) applied to the CIFAR-10 and ImageNet-1k datasets to evaluate the correctness and scalability of our K-FAC gradient preconditioner. With ResNet-50 on the ImageNet-1k dataset, our distributed K-FAC implementation converges to the 75.9% MLPerf baseline in 18-25% less time than does the classic stochastic gradient descent (SGD) optimizer across scales on a GPU cluster.
Speech Recognition for Endangered and Extinct Samoyedic languages
Dec 09, 2020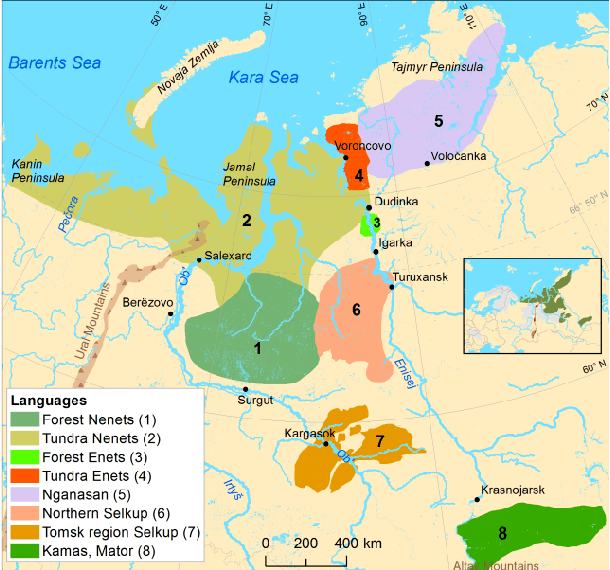
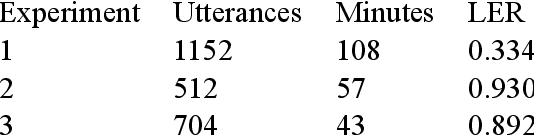

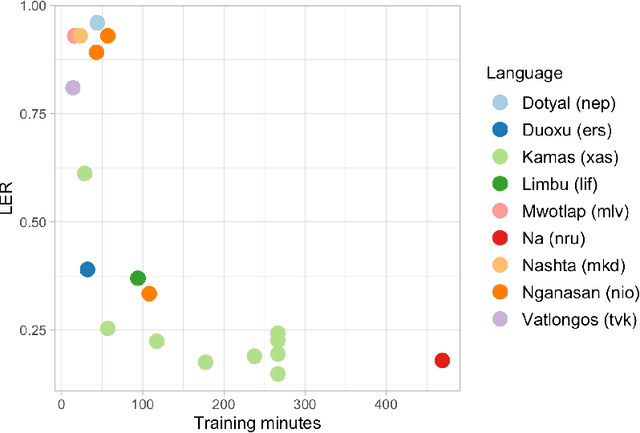
Our study presents a series of experiments on speech recognition with endangered and extinct Samoyedic languages, spoken in Northern and Southern Siberia. To best of our knowledge, this is the first time a functional ASR system is built for an extinct language. We achieve with Kamas language a Label Error Rate of 15\%, and conclude through careful error analysis that this quality is already very useful as a starting point for refined human transcriptions. Our results with related Nganasan language are more modest, with best model having the error rate of 33\%. We show, however, through experiments where Kamas training data is enlarged incrementally, that Nganasan results are in line with what is expected under low-resource circumstances of the language. Based on this, we provide recommendations for scenarios in which further language documentation or archive processing activities could benefit from modern ASR technology. All training data and processing scripts haven been published on Zenodo with clear licences to ensure further work in this important topic.
DSAL: Deeply Supervised Active Learning from Strong and Weak Labelers for Biomedical Image Segmentation
Jan 22, 2021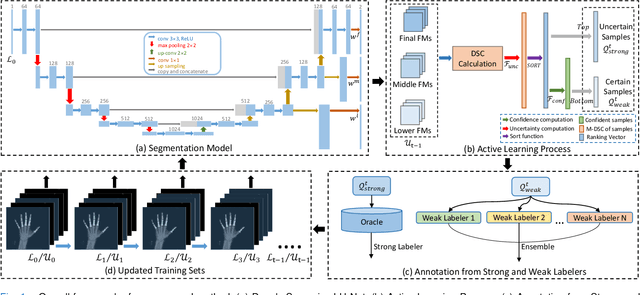
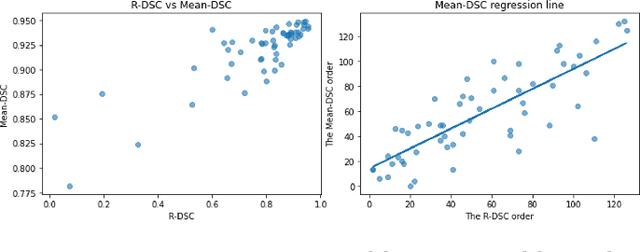
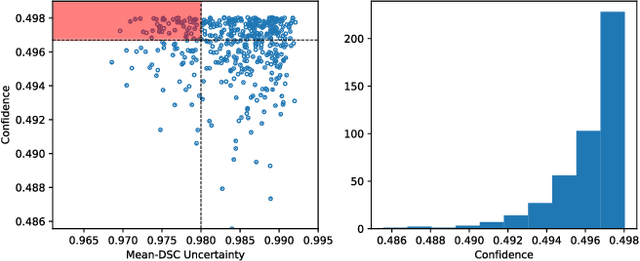
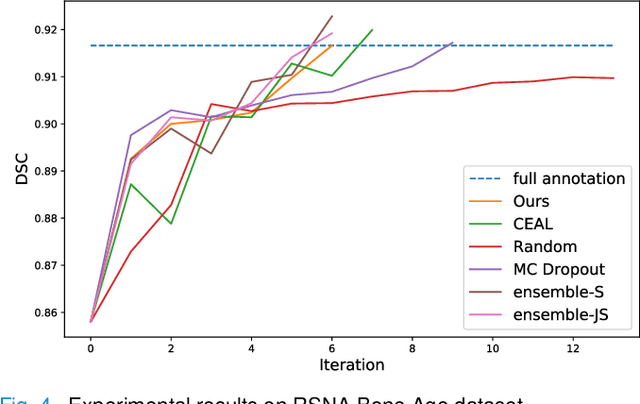
Image segmentation is one of the most essential biomedical image processing problems for different imaging modalities, including microscopy and X-ray in the Internet-of-Medical-Things (IoMT) domain. However, annotating biomedical images is knowledge-driven, time-consuming, and labor-intensive, making it difficult to obtain abundant labels with limited costs. Active learning strategies come into ease the burden of human annotation, which queries only a subset of training data for annotation. Despite receiving attention, most of active learning methods generally still require huge computational costs and utilize unlabeled data inefficiently. They also tend to ignore the intermediate knowledge within networks. In this work, we propose a deep active semi-supervised learning framework, DSAL, combining active learning and semi-supervised learning strategies. In DSAL, a new criterion based on deep supervision mechanism is proposed to select informative samples with high uncertainties and low uncertainties for strong labelers and weak labelers respectively. The internal criterion leverages the disagreement of intermediate features within the deep learning network for active sample selection, which subsequently reduces the computational costs. We use the proposed criteria to select samples for strong and weak labelers to produce oracle labels and pseudo labels simultaneously at each active learning iteration in an ensemble learning manner, which can be examined with IoMT Platform. Extensive experiments on multiple medical image datasets demonstrate the superiority of the proposed method over state-of-the-art active learning methods.