 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Universal Framework for Featurization of Atomistic Systems
Feb 05, 2021
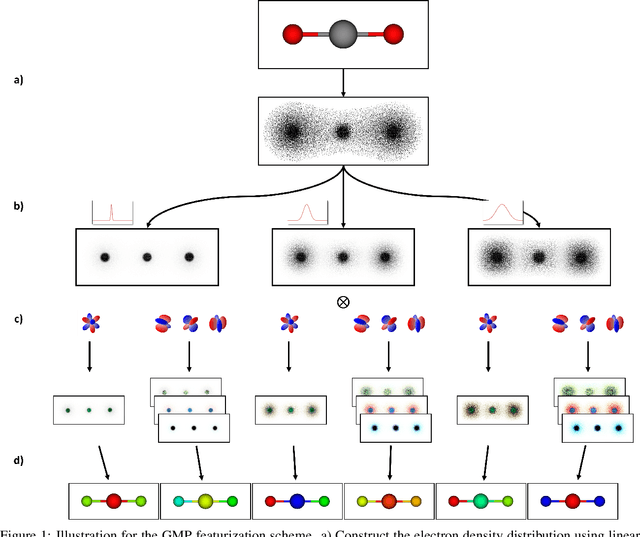

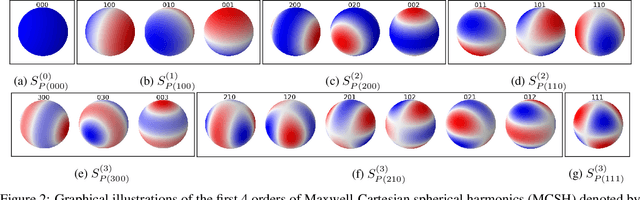
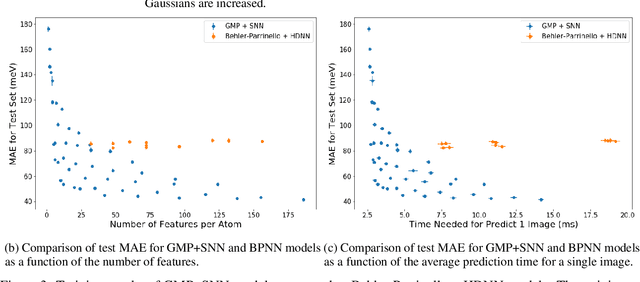
Molecular dynamics simulations are an invaluable tool in numerous scientific fields. However, the ubiquitous classical force fields cannot describe reactive systems, and quantum molecular dynamics are too computationally demanding to treat large systems or long timescales. Reactive force fields based on physics or machine learning can be used to bridge the gap in time and length scales, but these force fields require substantial effort to construct and are highly specific to given chemical composition and application. The extreme flexibility of machine learning models promises to yield reactive force fields that provide a more general description of chemical bonding. However, a significant limitation of machine learning models is the use of element-specific features, leading to models that scale poorly with the number of elements. This work introduces the Gaussian multi-pole (GMP) featurization scheme that utilizes physically-relevant multi-pole expansions of the electron density around atoms to yield feature vectors that interpolate between element types and have a fixed dimension regardless of the number of elements present. We combine GMP with neural networks to directly compare it to the widely-used Behler-Parinello symmetry functions for the MD17 dataset, revealing that it exhibits improved accuracy and computational efficiency. Further, we demonstrate that GMP-based models can achieve chemical accuracy for the QM9 dataset, and their accuracy remains reasonable even when extrapolating to new elements. Finally, we test GMP-based models for the Open Catalysis Project (OCP) dataset, revealing comparable performance and improved learning rates when compared to graph convolutional deep learning models. The results indicate that this featurization scheme fills a critical gap in the construction of efficient and transferable reactive force fields.
Searching for a Search Method: Benchmarking Search Algorithms for Generating NLP Adversarial Examples
Sep 09, 2020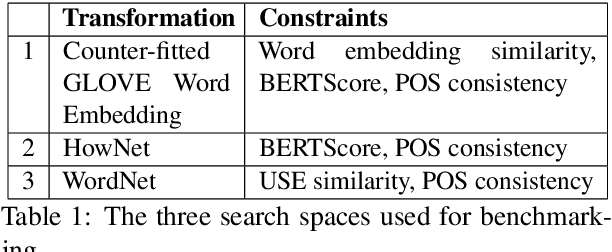
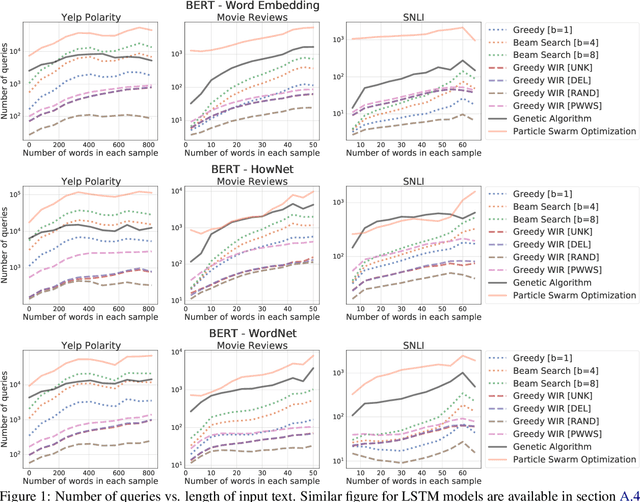
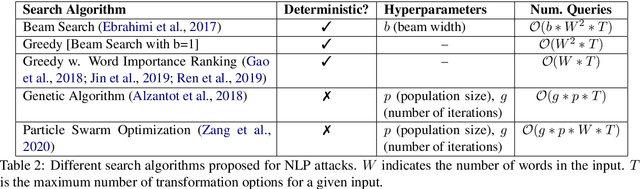
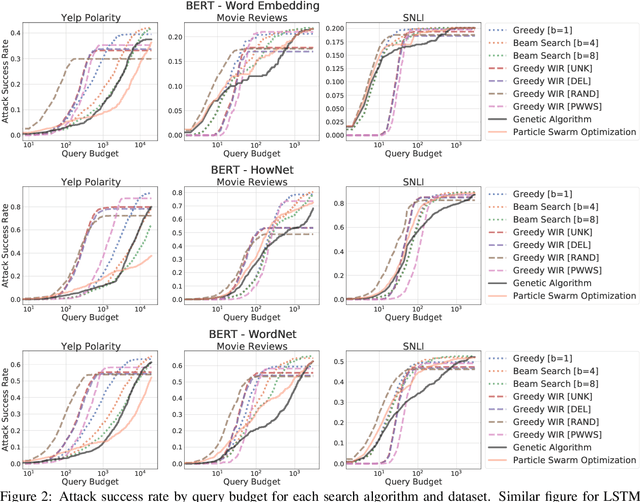
We study the behavior of several black-box search algorithms used for generating adversarial examples for natural language processing (NLP) tasks. We perform a fine-grained analysis of three elements relevant to search: search algorithm, search space, and search budget. When new search methods are proposed in past work, the attack search space is often modified alongside the search method. Without ablation studies benchmarking the search algorithm change with the search space held constant, an increase in attack success rate could from an improved search method or a less restrictive search space. Additionally, many previous studies fail to properly consider the search algorithms' run-time cost, which is essential for downstream tasks like adversarial training. Our experiments provide a reproducible benchmark of search algorithms across a variety of search spaces and query budgets to guide future research in adversarial NLP. Based on our experiments, we recommend greedy attacks with word importance ranking when under a time constraint or attacking long inputs, and either beam search or particle swarm optimization otherwise. Code implementation shared via https://github.com/QData/TextAttack
Hyperspectral Image Classification -- Traditional to Deep Models: A Survey for Future Prospects
Jan 15, 2021
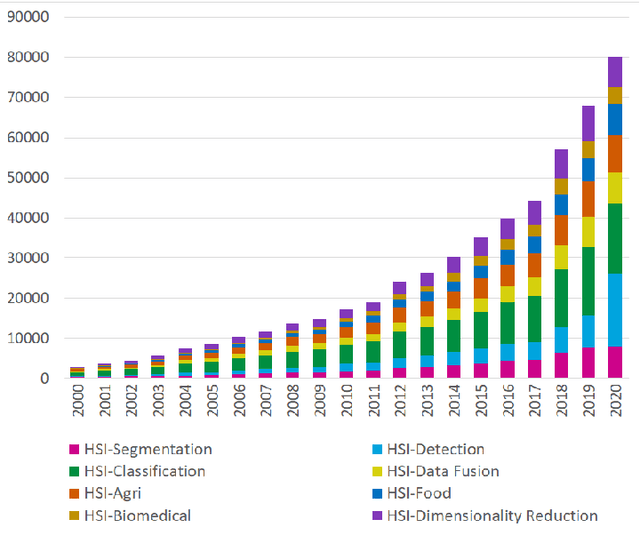
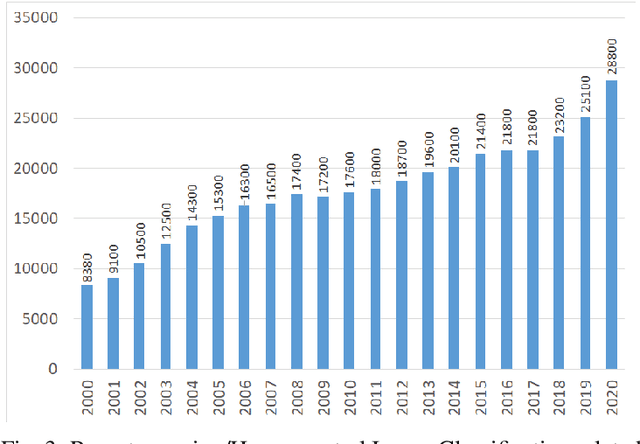
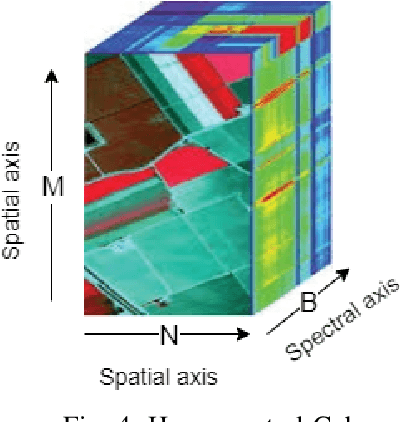
Hyperspectral Imaging (HSI) has been extensively utilized in many real-life applications because it benefits from the detailed spectral information contained in each pixel. Notably, the complex characteristics i.e., the nonlinear relation among the captured spectral information and the corresponding object of HSI data make accurate classification challenging for traditional methods. In the last few years, deep learning (DL) has been substantiated as a powerful feature extractor that effectively addresses the nonlinear problems that appeared in a number of computer vision tasks. This prompts the deployment of DL for HSI classification (HSIC) which revealed good performance. This survey enlists a systematic overview of DL for HSIC and compared state-of-the-art strategies of the said topic. Primarily, we will encapsulate the main challenges of traditional machine learning for HSIC and then we will acquaint the superiority of DL to address these problems. This survey breakdown the state-of-the-art DL frameworks into spectral-features, spatial-features, and together spatial-spectral features to systematically analyze the achievements (future directions as well) of these frameworks for HSIC. Moreover, we will consider the fact that DL requires a large number of labeled training examples whereas acquiring such a number for HSIC is challenging in terms of time and cost. Therefore, this survey discusses some strategies to improve the generalization performance of DL strategies which can provide some future guidelines.
Auto-MVCNN: Neural Architecture Search for Multi-view 3D Shape Recognition
Dec 10, 2020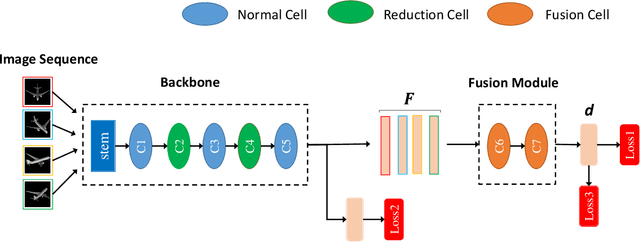
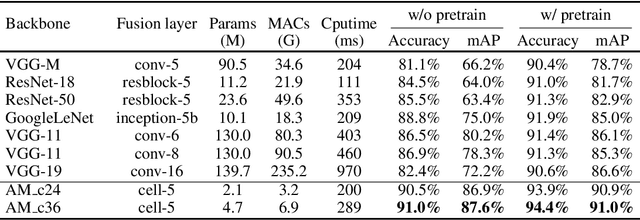
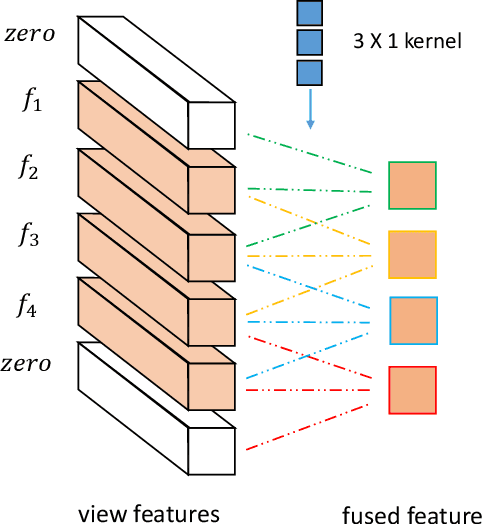
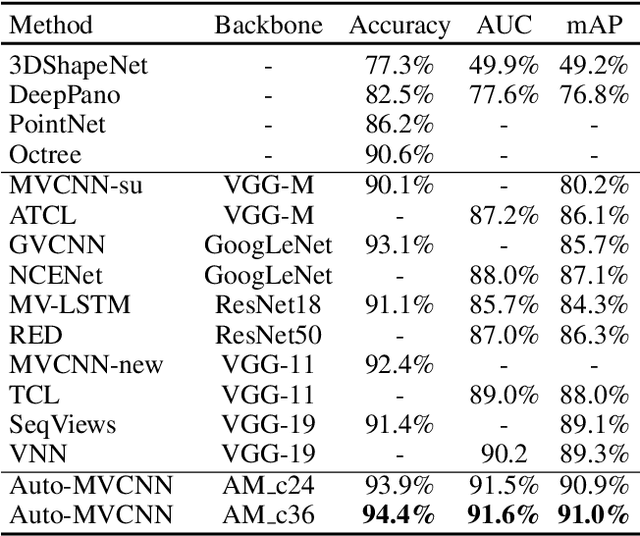
In 3D shape recognition, multi-view based methods leverage human's perspective to analyze 3D shapes and have achieved significant outcomes. Most existing research works in deep learning adopt handcrafted networks as backbones due to their high capacity of feature extraction, and also benefit from ImageNet pretraining. However, whether these network architectures are suitable for 3D analysis or not remains unclear. In this paper, we propose a neural architecture search method named Auto-MVCNN which is particularly designed for optimizing architecture in multi-view 3D shape recognition. Auto-MVCNN extends gradient-based frameworks to process multi-view images, by automatically searching the fusion cell to explore intrinsic correlation among view features. Moreover, we develop an end-to-end scheme to enhance retrieval performance through the trade-off parameter search. Extensive experimental results show that the searched architectures significantly outperform manually designed counterparts in various aspects, and our method achieves state-of-the-art performance at the same time.
When Can Models Learn From Explanations? A Formal Framework for Understanding the Roles of Explanation Data
Feb 10, 2021
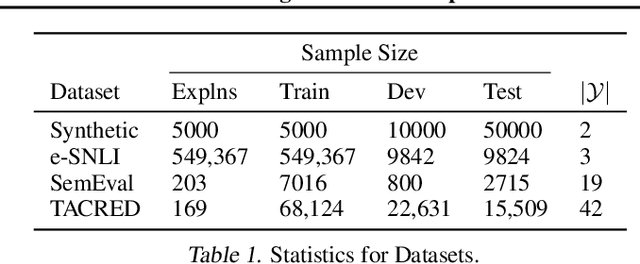
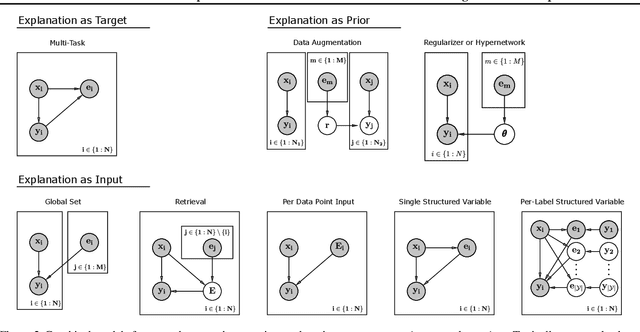

Many methods now exist for conditioning model outputs on task instructions, retrieved documents, and user-provided explanations and feedback. Rather than relying solely on examples of task inputs and outputs, these approaches use valuable additional data for improving model correctness and aligning learned models with human priors. Meanwhile, a growing body of evidence suggests that some language models can (1) store a large amount of knowledge in their parameters, and (2) perform inference over tasks in textual inputs at test time. These results raise the possibility that, for some tasks, humans cannot explain to a model any more about the task than it already knows or could infer on its own. In this paper, we study the circumstances under which explanations of individual data points can (or cannot) improve modeling performance. In order to carefully control important properties of the data and explanations, we introduce a synthetic dataset for experiments, and we also make use of three existing datasets with explanations: e-SNLI, TACRED, and SemEval. We first give a formal framework for the available modeling approaches, in which explanation data can be used as model inputs, as targets, or as a prior. After arguing that the most promising role for explanation data is as model inputs, we propose to use a retrieval-based method and show that it solves our synthetic task with accuracies upwards of 95%, while baselines without explanation data achieve below 65% accuracy. We then identify properties of datasets for which retrieval-based modeling fails. With the three existing datasets, we find no improvements from explanation retrieval. Drawing on findings from our synthetic task, we suggest that at least one of six preconditions for successful modeling fails to hold with these datasets. Our code is publicly available at https://github.com/peterbhase/ExplanationRoles
High-level Approaches to Detect Malicious Political Activity on Twitter
Feb 04, 2021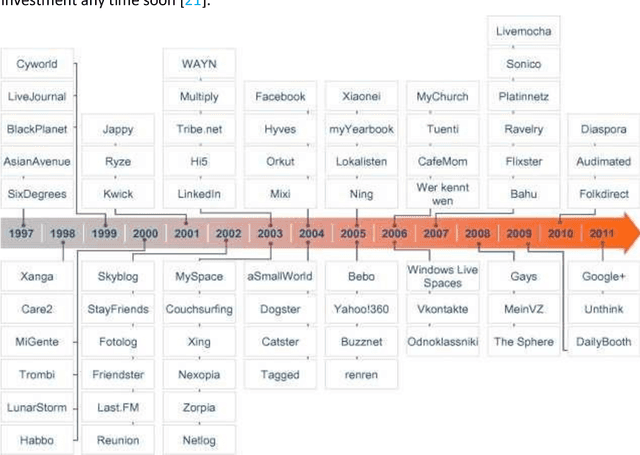
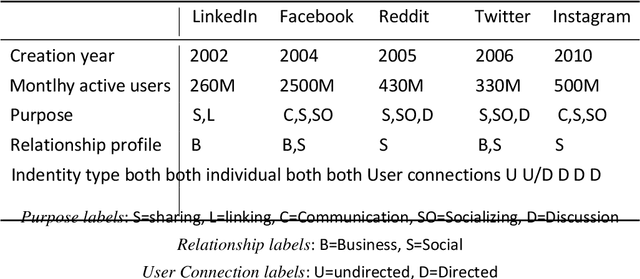
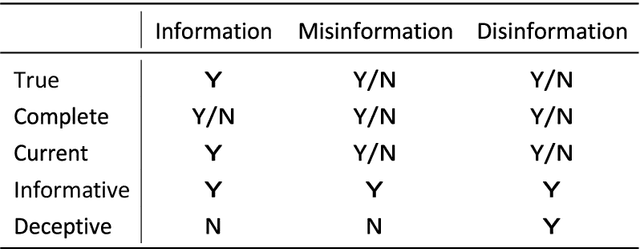
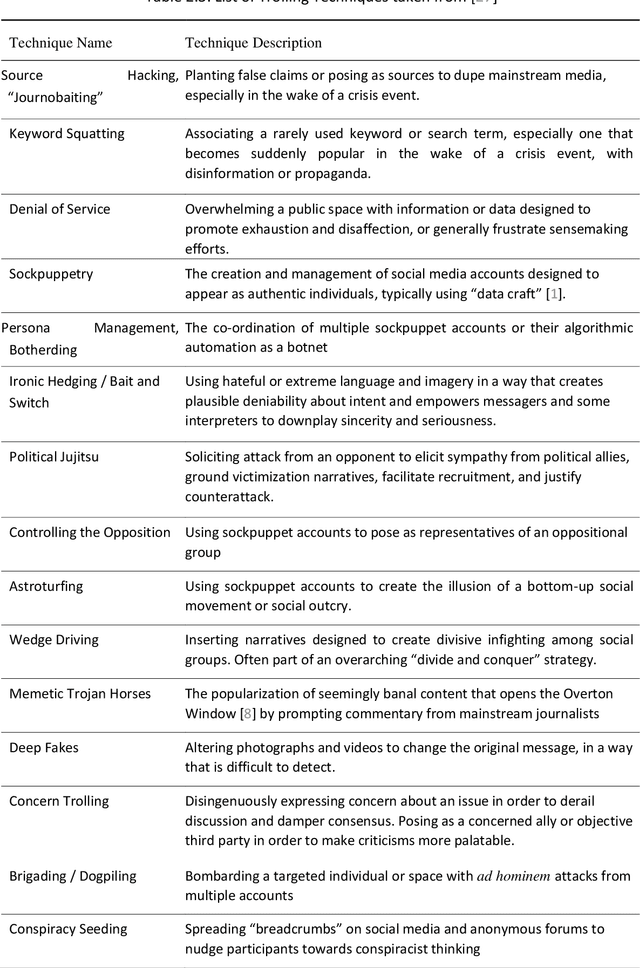
Our work represents another step into the detection and prevention of these ever-more present political manipulation efforts. We, therefore, start by focusing on understanding what the state-of-the-art approaches lack -- since the problem remains, this is a fair assumption. We find concerning issues within the current literature and follow a diverging path. Notably, by placing emphasis on using data features that are less susceptible to malicious manipulation and also on looking for high-level approaches that avoid a granularity level that is biased towards easy-to-spot and low impact cases. We designed and implemented a framework -- Twitter Watch -- that performs structured Twitter data collection, applying it to the Portuguese Twittersphere. We investigate a data snapshot taken on May 2020, with around 5 million accounts and over 120 million tweets (this value has since increased to over 175 million). The analyzed time period stretches from August 2019 to May 2020, with a focus on the Portuguese elections of October 6th, 2019. However, the Covid-19 pandemic showed itself in our data, and we also delve into how it affected typical Twitter behavior. We performed three main approaches: content-oriented, metadata-oriented, and network interaction-oriented. We learn that Twitter's suspension patterns are not adequate to the type of political trolling found in the Portuguese Twittersphere -- identified by this work and by an independent peer - nor to fake news posting accounts. We also surmised that the different types of malicious accounts we independently gathered are very similar both in terms of content and interaction, through two distinct analysis, and are simultaneously very distinct from regular accounts.
Bridging Cost-sensitive and Neyman-Pearson Paradigms for Asymmetric Binary Classification
Dec 29, 2020
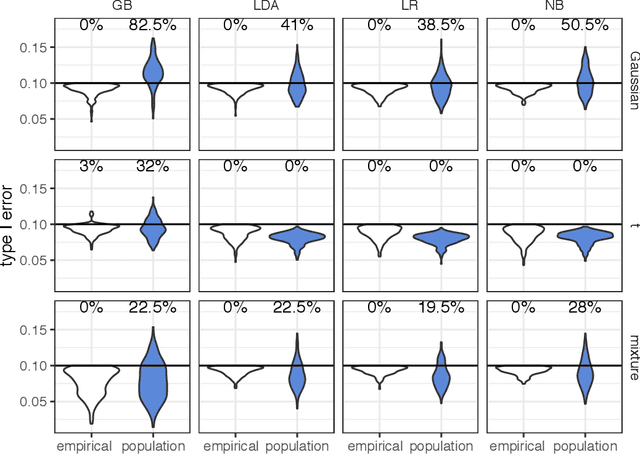
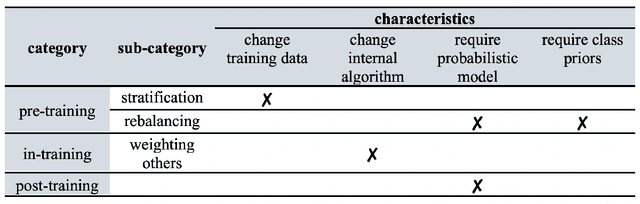
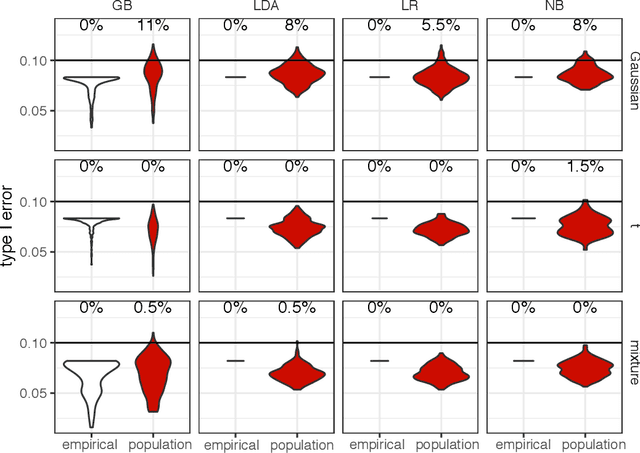
Asymmetric binary classification problems, in which the type I and II errors have unequal severity, are ubiquitous in real-world applications. To handle such asymmetry, researchers have developed the cost-sensitive and Neyman-Pearson paradigms for training classifiers to control the more severe type of classification error, say the type I error. The cost-sensitive paradigm is widely used and has straightforward implementations that do not require sample splitting; however, it demands an explicit specification of the costs of the type I and II errors, and an open question is what specification can guarantee a high-probability control on the population type I error. In contrast, the Neyman-Pearson paradigm can train classifiers to achieve a high-probability control of the population type I error, but it relies on sample splitting that reduces the effective training sample size. Since the two paradigms have complementary strengths, it is reasonable to combine their strengths for classifier construction. In this work, we for the first time study the methodological connections between the two paradigms, and we develop the TUBE-CS algorithm to bridge the two paradigms from the perspective of controlling the population type I error.
On-Manifold Preintegration for Real-Time Visual-Inertial Odometry
Oct 30, 2016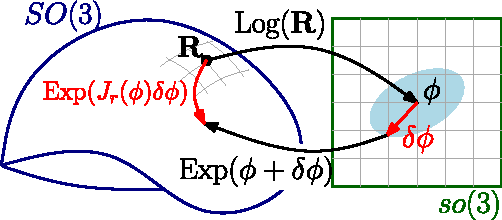
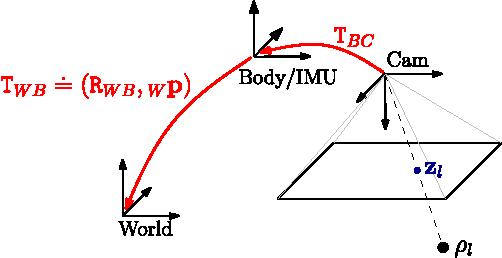
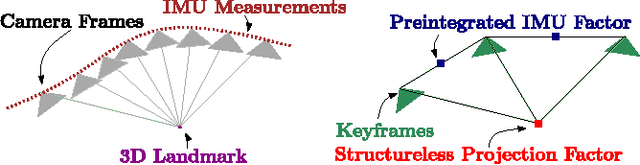
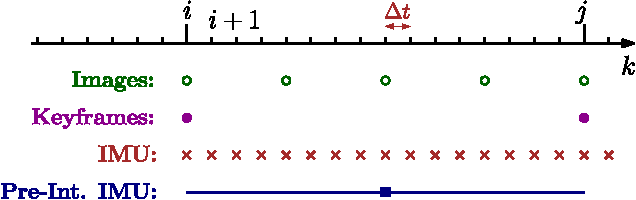
Current approaches for visual-inertial odometry (VIO) are able to attain highly accurate state estimation via nonlinear optimization. However, real-time optimization quickly becomes infeasible as the trajectory grows over time, this problem is further emphasized by the fact that inertial measurements come at high rate, hence leading to fast growth of the number of variables in the optimization. In this paper, we address this issue by preintegrating inertial measurements between selected keyframes into single relative motion constraints. Our first contribution is a \emph{preintegration theory} that properly addresses the manifold structure of the rotation group. We formally discuss the generative measurement model as well as the nature of the rotation noise and derive the expression for the \emph{maximum a posteriori} state estimator. Our theoretical development enables the computation of all necessary Jacobians for the optimization and a-posteriori bias correction in analytic form. The second contribution is to show that the preintegrated IMU model can be seamlessly integrated into a visual-inertial pipeline under the unifying framework of factor graphs. This enables the application of incremental-smoothing algorithms and the use of a \emph{structureless} model for visual measurements, which avoids optimizing over the 3D points, further accelerating the computation. We perform an extensive evaluation of our monocular \VIO pipeline on real and simulated datasets. The results confirm that our modelling effort leads to accurate state estimation in real-time, outperforming state-of-the-art approaches.
Multimodal Engagement Analysis from Facial Videos in the Classroom
Jan 22, 2021
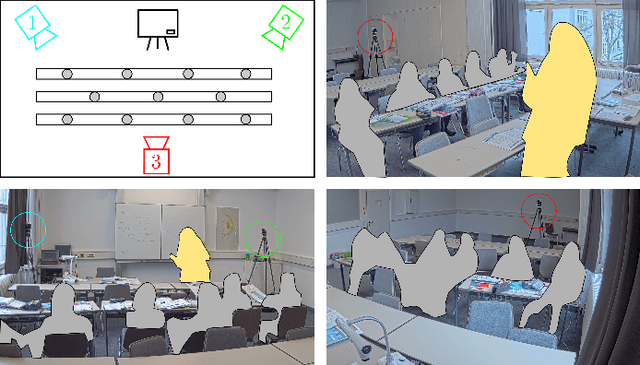
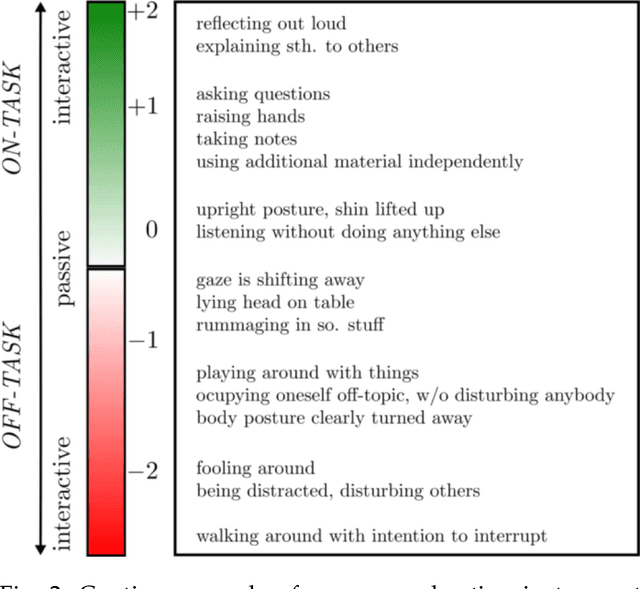
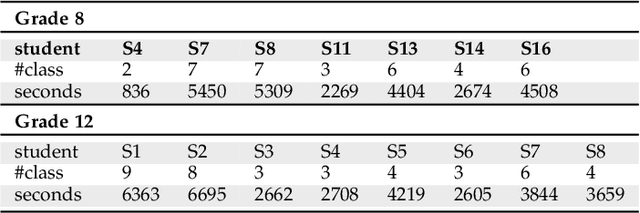
Student engagement is a key construct for learning and teaching. While most of the literature explored the student engagement analysis on computer-based settings, this paper extends that focus to classroom instruction. To best examine student visual engagement in the classroom, we conducted a study utilizing the audiovisual recordings of classes at a secondary school over one and a half month's time, acquired continuous engagement labeling per student (N=15) in repeated sessions, and explored computer vision methods to classify engagement levels from faces in the classroom. We trained deep embeddings for attentional and emotional features, training Attention-Net for head pose estimation and Affect-Net for facial expression recognition. We additionally trained different engagement classifiers, consisting of Support Vector Machines, Random Forest, Multilayer Perceptron, and Long Short-Term Memory, for both features. The best performing engagement classifiers achieved AUCs of .620 and .720 in Grades 8 and 12, respectively. We further investigated fusion strategies and found score-level fusion either improves the engagement classifiers or is on par with the best performing modality. We also investigated the effect of personalization and found that using only 60-seconds of person-specific data selected by margin uncertainty of the base classifier yielded an average AUC improvement of .084. 4.Our main aim with this work is to provide the technical means to facilitate the manual data analysis of classroom videos in research on teaching quality and in the context of teacher training.
Community detection using fast low-cardinality semidefinite programming
Dec 04, 2020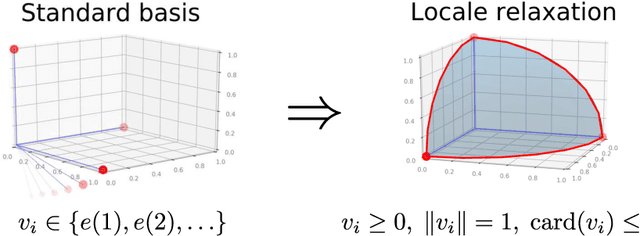
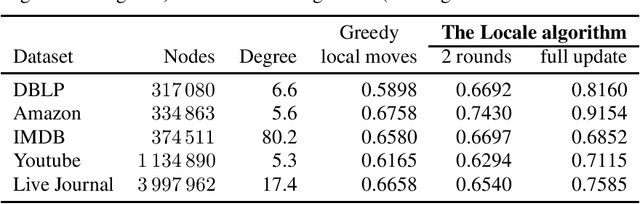

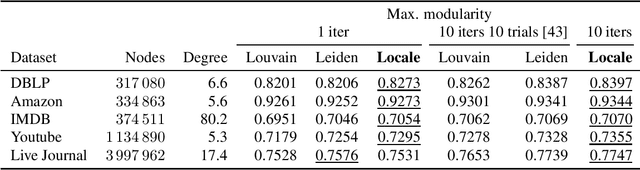
Modularity maximization has been a fundamental tool for understanding the community structure of a network, but the underlying optimization problem is nonconvex and NP-hard to solve. State-of-the-art algorithms like the Louvain or Leiden methods focus on different heuristics to help escape local optima, but they still depend on a greedy step that moves node assignment locally and is prone to getting trapped. In this paper, we propose a new class of low-cardinality algorithm that generalizes the local update to maximize a semidefinite relaxation derived from max-k-cut. This proposed algorithm is scalable, empirically achieves the global semidefinite optimality for small cases, and outperforms the state-of-the-art algorithms in real-world datasets with little additional time cost. From the algorithmic perspective, it also opens a new avenue for scaling-up semidefinite programming when the solutions are sparse instead of low-rank.