 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
mlOSP: Towards a Unified Implementation of Regression Monte Carlo Algorithms
Dec 01, 2020
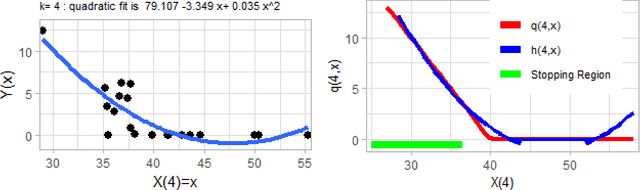
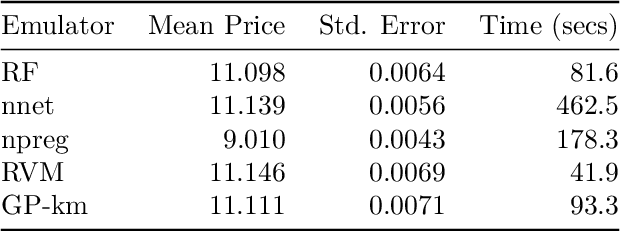
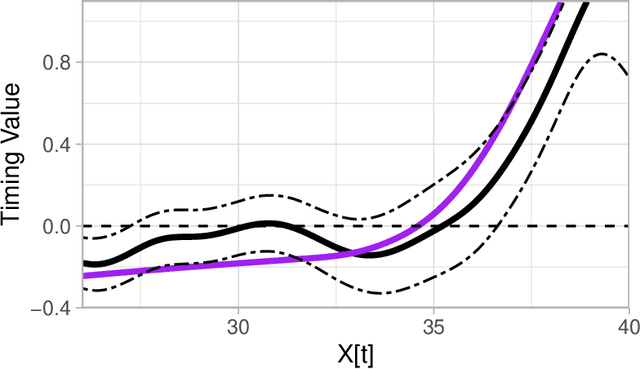
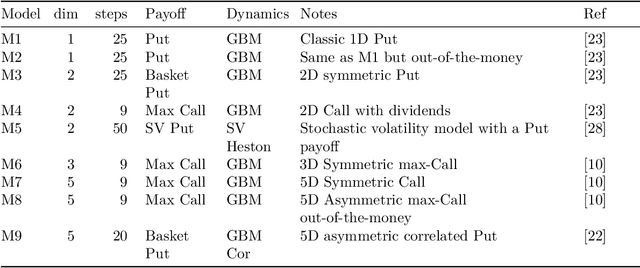
We introduce mlOSP, a computational template for Machine Learning for Optimal Stopping Problems. The template is implemented in the R statistical environment and publicly available via a GitHub repository. mlOSP presents a unified numerical implementation of Regression Monte Carlo (RMC) approaches to optimal stopping, providing a state-of-the-art, open-source, reproducible and transparent platform. Highlighting its modular nature, we present multiple novel variants of RMC algorithms, especially in terms of constructing simulation designs for training the regressors, as well as in terms of machine learning regression modules. At the same time, mlOSP nests most of the existing RMC schemes, allowing for a consistent and verifiable benchmarking of extant algorithms. The article contains extensive R code snippets and figures, and serves the dual role of presenting new RMC features and as a vignette to the underlying software package.
Automatic Liver Segmentation from CT Images Using Deep Learning Algorithms: A Comparative Study
Jan 25, 2021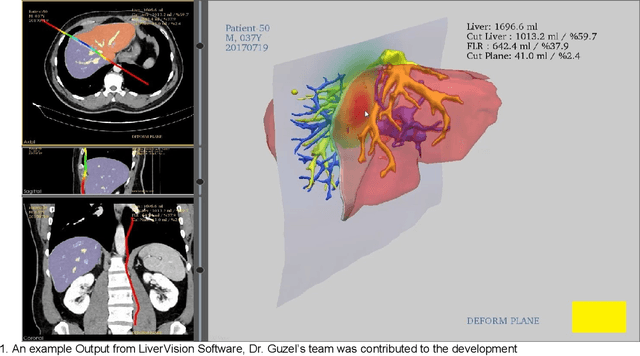
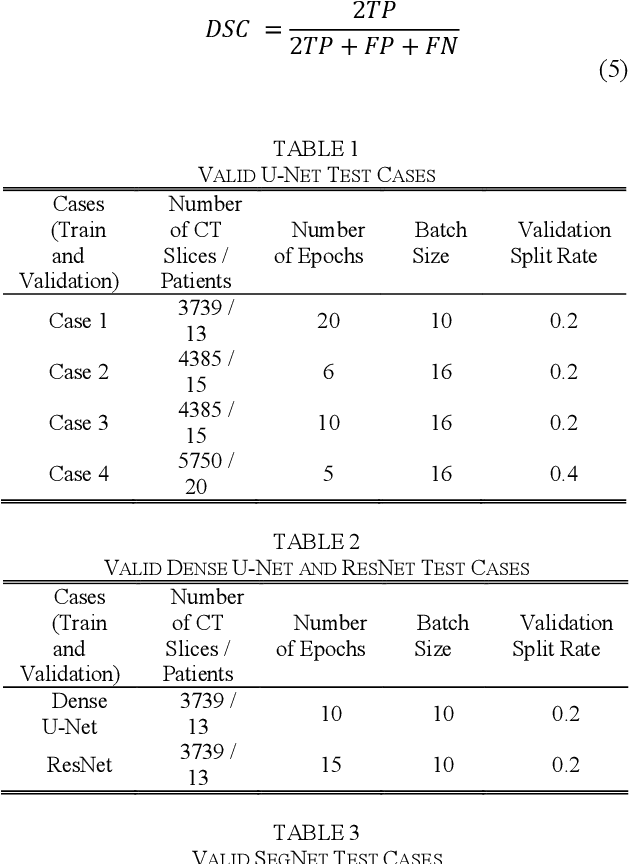
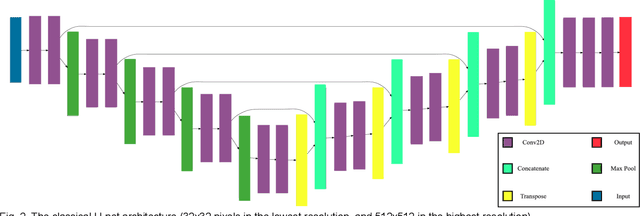
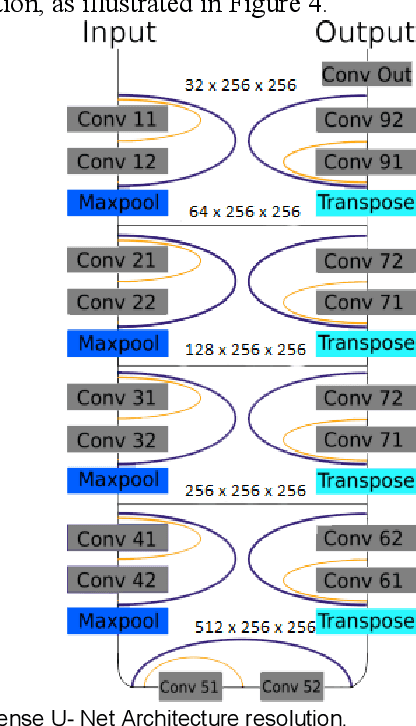
Medical imaging has been employed to support medical diagnosis and treatment. It may also provide crucial information to surgeons to facilitate optimal surgical preplanning and perioperative management. Essentially, semi-automatic organ and tumor segmentation has been studied by many researchers. Recently, with the development of Deep Learning (DL) algorithms, automatic organ segmentation has been gathered lots of attention from the researchers. This paper addresses to propose the most efficient DL architectures for Liver segmentation by adapting and comparing state-of-the-art DL frameworks, studied in different disciplines. These frameworks are implemented and adapted into a Commercial software, 'LiverVision'. It is aimed to reveal the most effective and accurate DL architecture for fully automatic liver segmentation. Equal conditions were provided to all architectures in the experiments so as to measure the effectiveness of algorithms accuracy, and Dice coefficient metrics were also employed to support comparative analysis. Experimental results prove that 'U-Net' and 'SegNet' have been superior in line with the experiments conducted considering the concepts of time, cost, and effectiveness. Considering both architectures, 'SegNet' was observed to be more successful in eliminating false-positive values. Besides, it was seen that the accuracy metric used to measure effectiveness in image segmentation alone was not enough. Results reveal that DL algorithms are able to automate organ segmentation from DICOM images with high accuracy. This contribution is critical for surgical preplanning and motivates author to apply this approach to the different organs and field of medicine.
CFC-Net: A Critical Feature Capturing Network for Arbitrary-Oriented Object Detection in Remote Sensing Images
Jan 18, 2021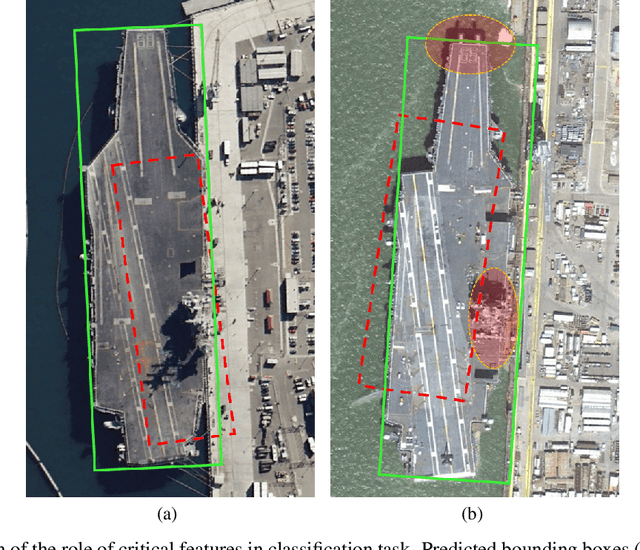
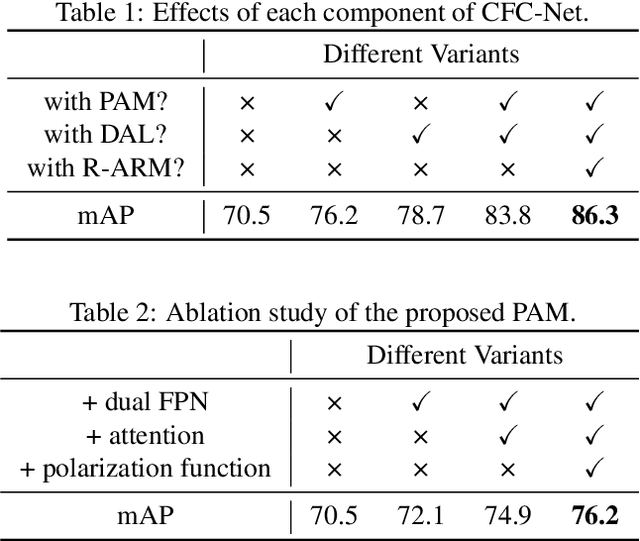
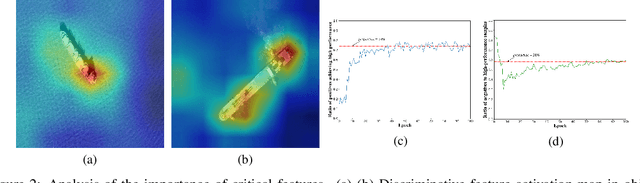
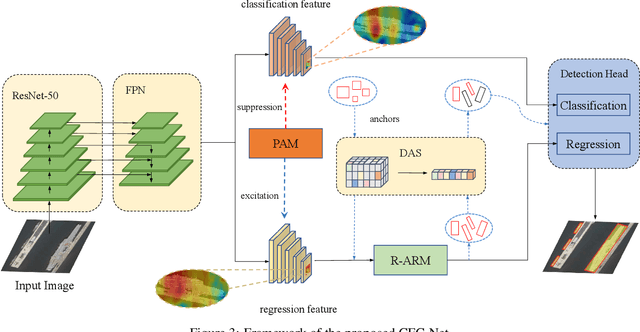
Object detection in optical remote sensing images is an important and challenging task. In recent years, the methods based on convolutional neural networks have made good progress. However, due to the large variation in object scale, aspect ratio, and arbitrary orientation, the detection performance is difficult to be further improved. In this paper, we discuss the role of discriminative features in object detection, and then propose a Critical Feature Capturing Network (CFC-Net) to improve detection accuracy from three aspects: building powerful feature representation, refining preset anchors, and optimizing label assignment. Specifically, we first decouple the classification and regression features, and then construct robust critical features adapted to the respective tasks through the Polarization Attention Module (PAM). With the extracted discriminative regression features, the Rotation Anchor Refinement Module (R-ARM) performs localization refinement on preset horizontal anchors to obtain superior rotation anchors. Next, the Dynamic Anchor Learning (DAL) strategy is given to adaptively select high-quality anchors based on their ability to capture critical features. The proposed framework creates more powerful semantic representations for objects in remote sensing images and achieves high-performance real-time object detection. Experimental results on three remote sensing datasets including HRSC2016, DOTA, and UCAS-AOD show that our method achieves superior detection performance compared with many state-of-the-art approaches. Code and models are available at https://github.com/ming71/CFC-Net.
Real Time Image Saliency for Black Box Classifiers
May 22, 2017



In this work we develop a fast saliency detection method that can be applied to any differentiable image classifier. We train a masking model to manipulate the scores of the classifier by masking salient parts of the input image. Our model generalises well to unseen images and requires a single forward pass to perform saliency detection, therefore suitable for use in real-time systems. We test our approach on CIFAR-10 and ImageNet datasets and show that the produced saliency maps are easily interpretable, sharp, and free of artifacts. We suggest a new metric for saliency and test our method on the ImageNet object localisation task. We achieve results outperforming other weakly supervised methods.
Sparse Array Beamformer Design for Active and Passive Sensing
Jan 18, 2021
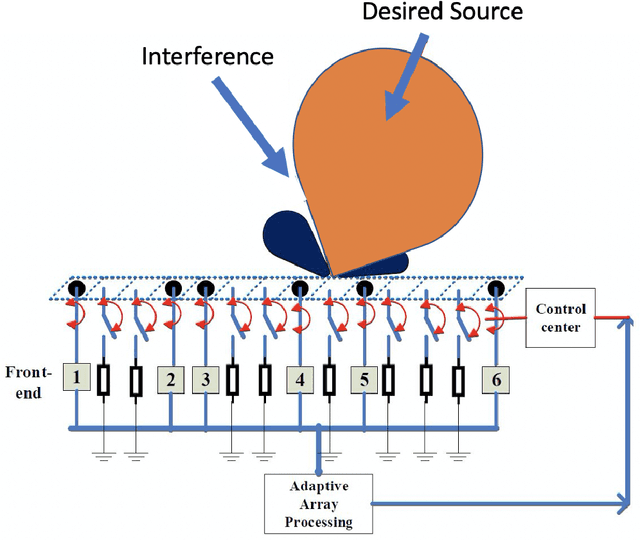
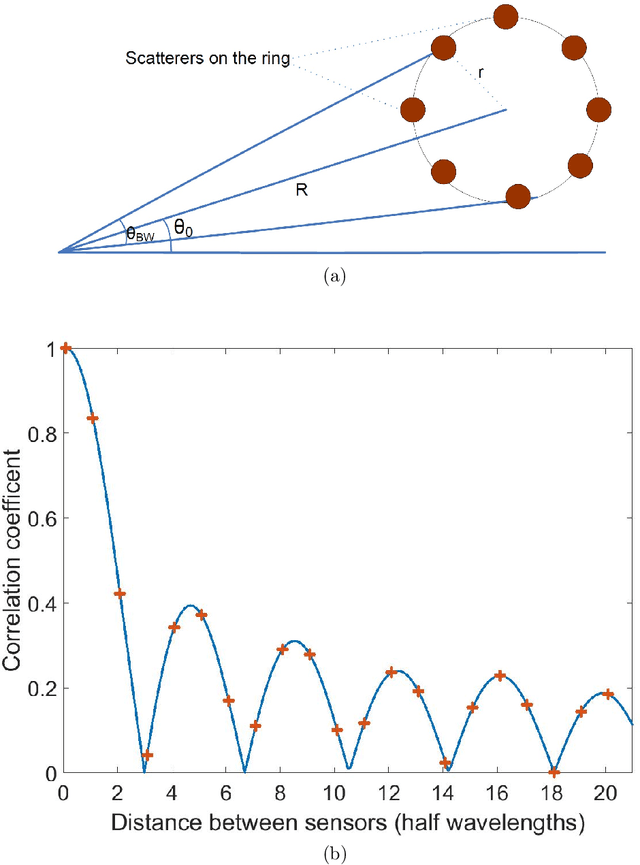
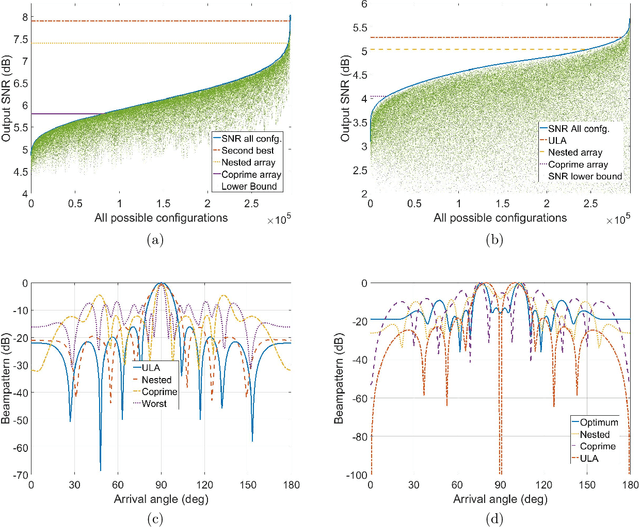
Sparse sensor placement, with various design objectives, has successfully been employed in diverse application areas, particularly for enhanced parameter estimation and receiver performance. The sparse array design criteria are generally categorized into environment-independent and environment-dependent performance metrics. The former are largely benign to the underlying environment and, in principle, seek to maximize the spatial degrees of freedom by extending the coarray aperture. Environment-dependent objectives, on the other hand, consider the operating conditions characterized by emitters and targets in the array field of view, in addition to receiver noise. In this regard, applying such objectives renders the array configuration as well as the array weights time-varying in response to dynamic and changing environment. This work is geared towards designing environment-dependent sparse array beamformer to improve the output signal-to-interference and noise ratio using both narrowband and wideband signal platforms. One key challenge in implementing the data-dependent approaches is the lack of knowledge of exact or estimated values of the data autocorrelation function across the full sparse array aperture. At the core of this work is to address the aforementioned issues by devising innovative solutions using convex optimization and machine learning tools, structured sparsity concepts, low rank matrix completion schemes and fusing the environment-dependent and environment-independent deigns by developing a hybrid approach.
MonoComb: A Sparse-to-Dense Combination Approach for Monocular Scene Flow
Nov 12, 2020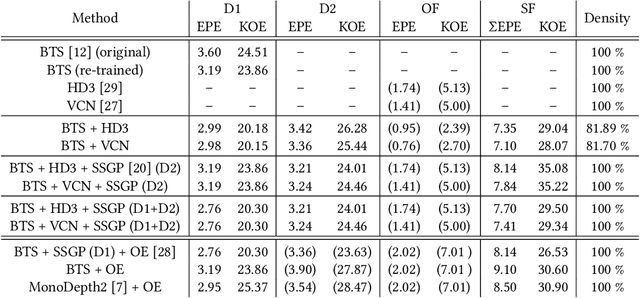


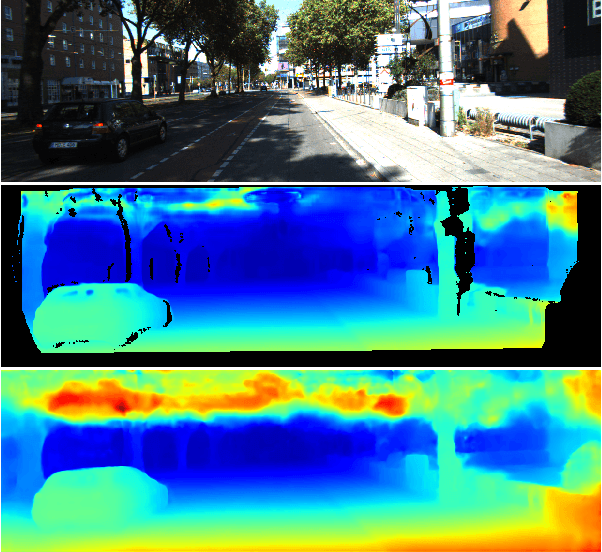
Contrary to the ongoing trend in automotive applications towards usage of more diverse and more sensors, this work tries to solve the complex scene flow problem under a monocular camera setup, i.e. using a single sensor. Towards this end, we exploit the latest achievements in single image depth estimation, optical flow, and sparse-to-dense interpolation and propose a monocular combination approach (MonoComb) to compute dense scene flow. MonoComb uses optical flow to relate reconstructed 3D positions over time and interpolates occluded areas. This way, existing monocular methods are outperformed in dynamic foreground regions which leads to the second best result among the competitors on the challenging KITTI 2015 scene flow benchmark.
Lorenz Trajectories Prediction: Travel Through Time
Mar 18, 2019
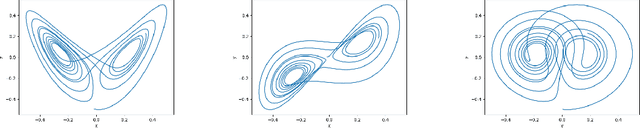

In this article the Lorenz dynamical system is revived and revisited and the current state of the art results for one step ahead forecasting for the Lorenz trajectories are published. The article is a reflection upon the evolution of neural networks with regards to the prediction performance on this canonical task.
Learning a time-dependent master saliency map from eye-tracking data in videos
Feb 02, 2017
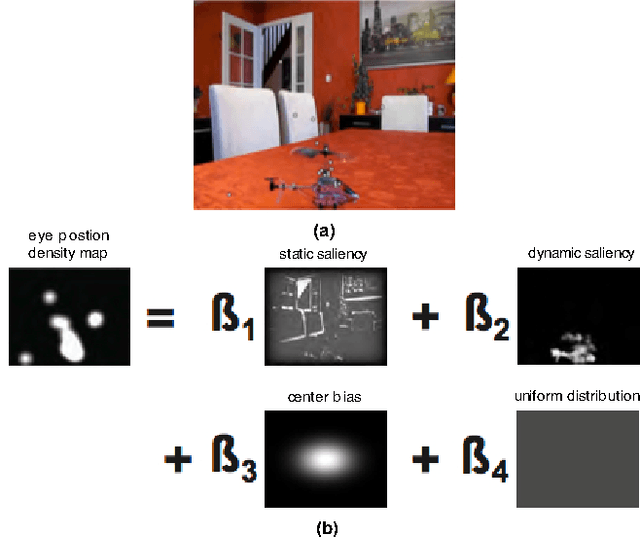
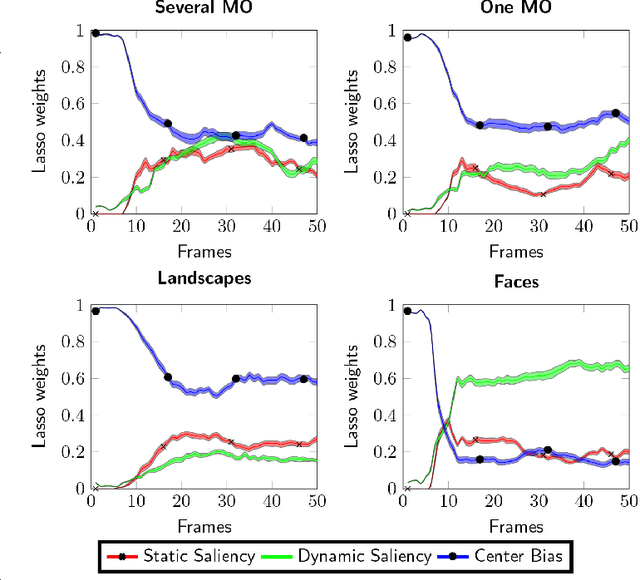
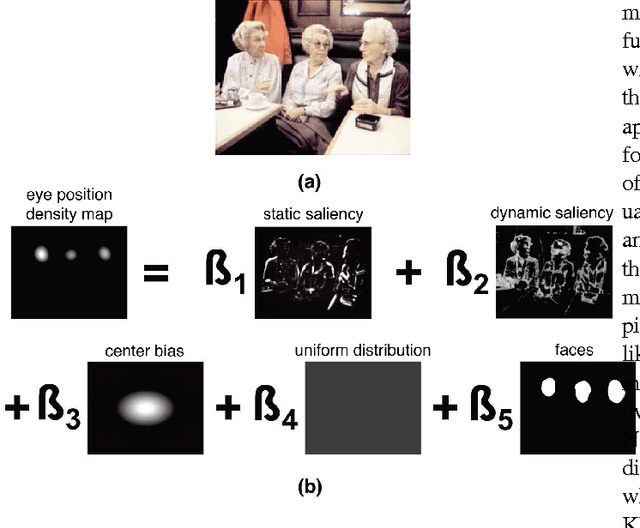
To predict the most salient regions of complex natural scenes, saliency models commonly compute several feature maps (contrast, orientation, motion...) and linearly combine them into a master saliency map. Since feature maps have different spatial distribution and amplitude dynamic ranges, determining their contributions to overall saliency remains an open problem. Most state-of-the-art models do not take time into account and give feature maps constant weights across the stimulus duration. However, visual exploration is a highly dynamic process shaped by many time-dependent factors. For instance, some systematic viewing patterns such as the center bias are known to dramatically vary across the time course of the exploration. In this paper, we use maximum likelihood and shrinkage methods to dynamically and jointly learn feature map and systematic viewing pattern weights directly from eye-tracking data recorded on videos. We show that these weights systematically vary as a function of time, and heavily depend upon the semantic visual category of the videos being processed. Our fusion method allows taking these variations into account, and outperforms other state-of-the-art fusion schemes using constant weights over time. The code, videos and eye-tracking data we used for this study are available online: http://antoinecoutrot.magix.net/public/research.html
Continuous Time Markov Networks
Jun 27, 2012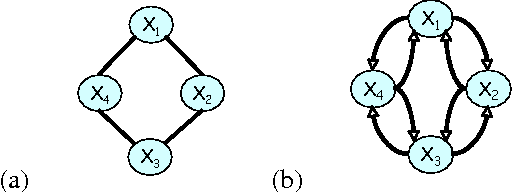
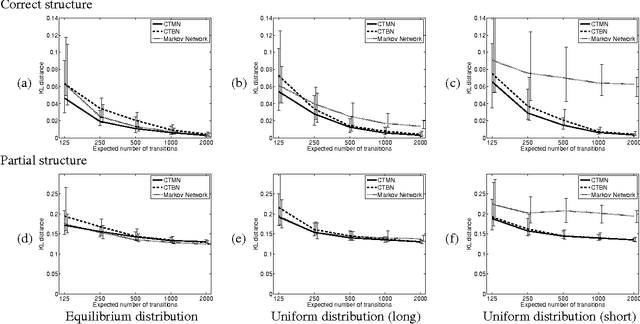
A central task in many applications is reasoning about processes that change in a continuous time. The mathematical framework of Continuous Time Markov Processes provides the basic foundations for modeling such systems. Recently, Nodelman et al introduced continuous time Bayesian networks (CTBNs), which allow a compact representation of continuous-time processes over a factored state space. In this paper, we introduce continuous time Markov networks (CTMNs), an alternative representation language that represents a different type of continuous-time dynamics. In many real life processes, such as biological and chemical systems, the dynamics of the process can be naturally described as an interplay between two forces - the tendency of each entity to change its state, and the overall fitness or energy function of the entire system. In our model, the first force is described by a continuous-time proposal process that suggests possible local changes to the state of the system at different rates. The second force is represented by a Markov network that encodes the fitness, or desirability, of different states; a proposed local change is then accepted with a probability that is a function of the change in the fitness distribution. We show that the fitness distribution is also the stationary distribution of the Markov process, so that this representation provides a characterization of a temporal process whose stationary distribution has a compact graphical representation. This allows us to naturally capture a different type of structure in complex dynamical processes, such as evolving biological sequences. We describe the semantics of the representation, its basic properties, and how it compares to CTBNs. We also provide algorithms for learning such models from data, and discuss its applicability to biological sequence evolution.
A Unified Analysis of First-Order Methods for Smooth Games via Integral Quadratic Constraints
Oct 02, 2020
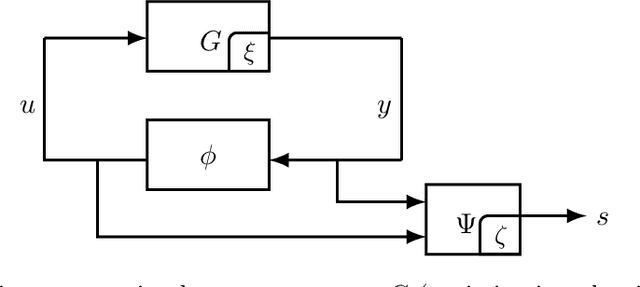
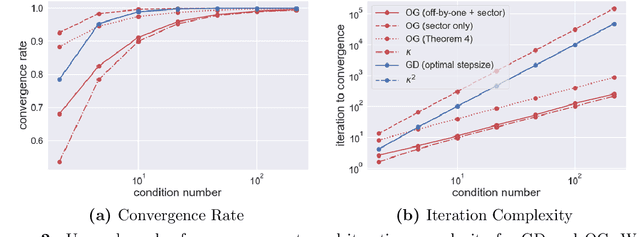
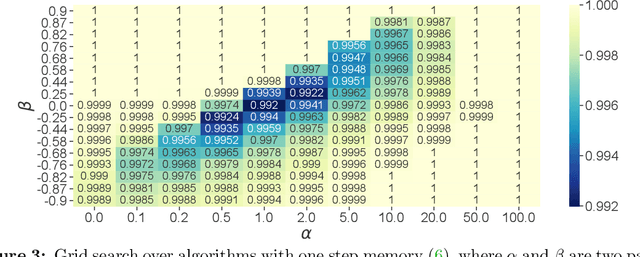
The theory of integral quadratic constraints (IQCs) allows the certification of exponential convergence of interconnected systems containing nonlinear or uncertain elements. In this work, we adapt the IQC theory to study first-order methods for smooth and strongly-monotone games and show how to design tailored quadratic constraints to get tight upper bounds of convergence rates. Using this framework, we recover the existing bound for the gradient method~(GD), derive sharper bounds for the proximal point method~(PPM) and optimistic gradient method~(OG), and provide \emph{for the first time} a global convergence rate for the negative momentum method~(NM) with an iteration complexity $\bigo(\kappa^{1.5})$, which matches its known lower bound. In addition, for time-varying systems, we prove that the gradient method with optimal step size achieves the fastest provable worst-case convergence rate with quadratic Lyapunov functions. Finally, we further extend our analysis to stochastic games and study the impact of multiplicative noise on different algorithms. We show that it is impossible for an algorithm with one step of memory to achieve acceleration if it only queries the gradient once per batch (in contrast with the stochastic strongly-convex optimization setting, where such acceleration has been demonstrated). However, we exhibit an algorithm which achieves acceleration with two gradient queries per batch.