 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Benchmarking of eight recurrent neural network variants for breath phase and adventitious sound detection on a self-developed open-access lung sound database-HF_Lung_V1
Feb 05, 2021
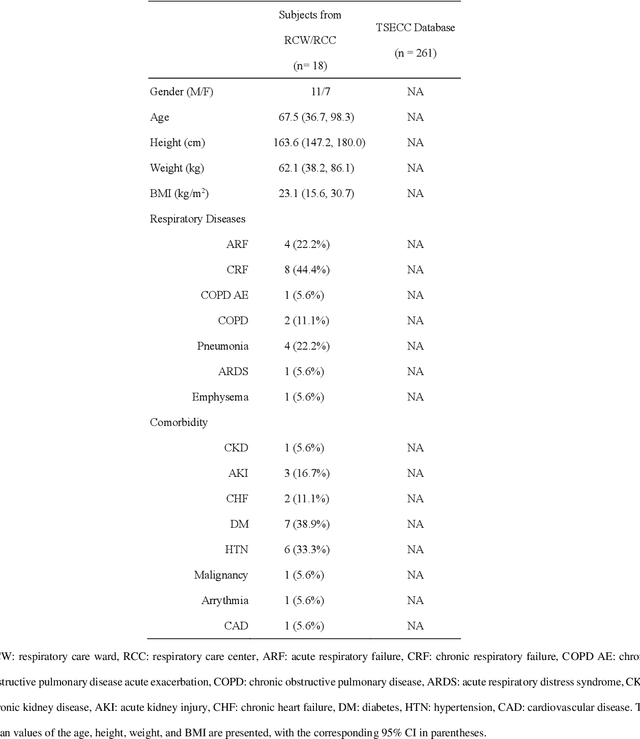

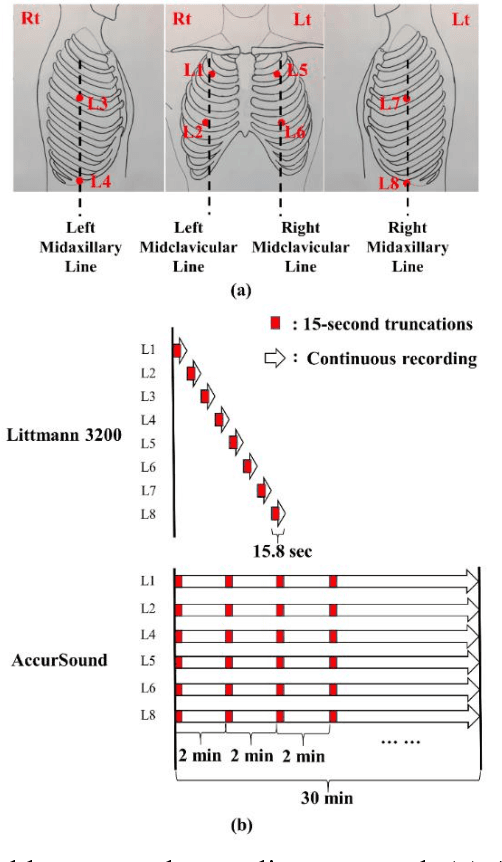
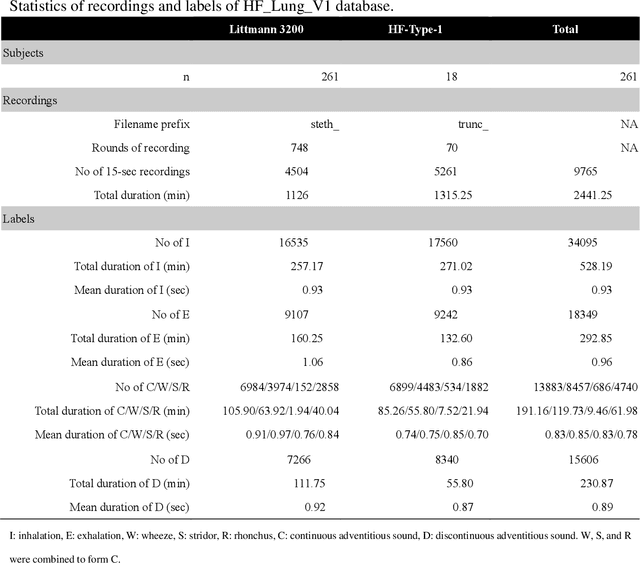
A reliable, remote, and continuous real-time respiratory sound monitor with automated respiratory sound analysis ability is urgently required in many clinical scenarios-such as in monitoring disease progression of coronavirus disease 2019-to replace conventional auscultation with a handheld stethoscope. However, a robust computerized respiratory sound analysis algorithm has not yet been validated in practical applications. In this study, we developed a lung sound database (HF_Lung_V1) comprising 9,765 audio files of lung sounds (duration of 15 s each), 34,095 inhalation labels, 18,349 exhalation labels, 13,883 continuous adventitious sound (CAS) labels (comprising 8,457 wheeze labels, 686 stridor labels, and 4,740 rhonchi labels), and 15,606 discontinuous adventitious sound labels (all crackles). We conducted benchmark tests for long short-term memory (LSTM), gated recurrent unit (GRU), bidirectional LSTM (BiLSTM), bidirectional GRU (BiGRU), convolutional neural network (CNN)-LSTM, CNN-GRU, CNN-BiLSTM, and CNN-BiGRU models for breath phase detection and adventitious sound detection. We also conducted a performance comparison between the LSTM-based and GRU-based models, between unidirectional and bidirectional models, and between models with and without a CNN. The results revealed that these models exhibited adequate performance in lung sound analysis. The GRU-based models outperformed, in terms of F1 scores and areas under the receiver operating characteristic curves, the LSTM-based models in most of the defined tasks. Furthermore, all bidirectional models outperformed their unidirectional counterparts. Finally, the addition of a CNN improved the accuracy of lung sound analysis, especially in the CAS detection tasks.
Discovery of Governing Equations with Recursive Deep Neural Networks
Sep 24, 2020
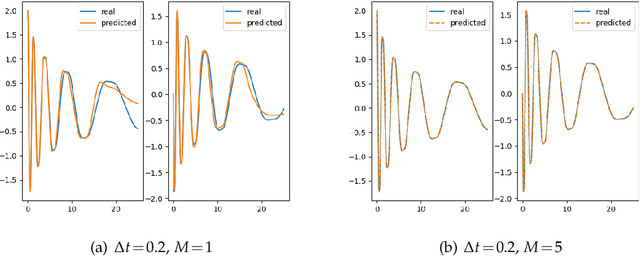
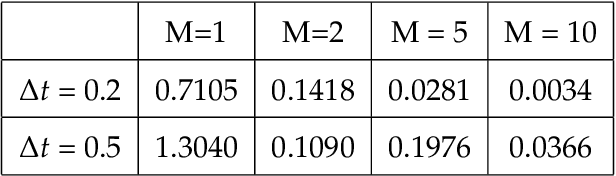
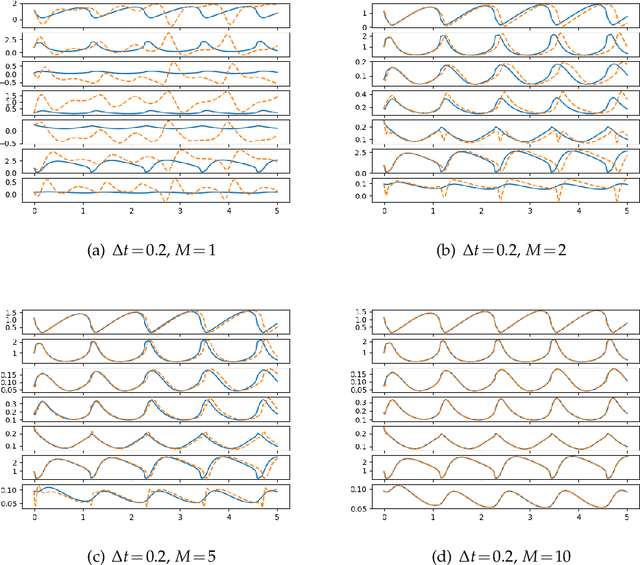
Model discovery based on existing data has been one of the major focuses of mathematical modelers for decades. Despite tremendous achievements of model identification from adequate data, how to unravel the models from limited data is less resolved. In this paper, we focus on the model discovery problem when the data is not efficiently sampled in time. This is common due to limited experimental accessibility and labor/resource constraints. Specifically, we introduce a recursive deep neural network (RDNN) for data-driven model discovery. This recursive approach can retrieve the governing equation in a simple and efficient manner, and it can significantly improve the approximation accuracy by increasing the recursive stages. In particular, our proposed approach shows superior power when the existing data are sampled with a large time lag, from which the traditional approach might not be able to recover the model well. Several widely used examples of dynamical systems are used to benchmark this newly proposed recursive approach. Numerical comparisons confirm the effectiveness of this recursive neural network for model discovery.
Uniform Object Rearrangement: From Complete Monotone Primitives to Efficient Non-Monotone Informed Search
Jan 28, 2021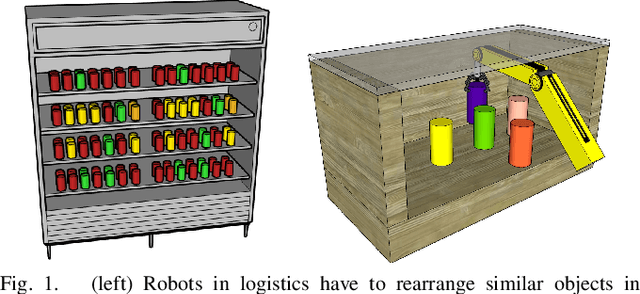

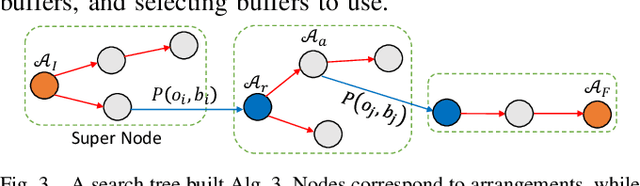
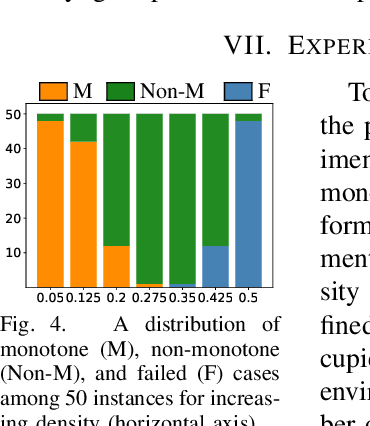
Object rearrangement is a widely-applicable and challenging task for robots. Geometric constraints must be carefully examined to avoid collisions and combinatorial issues arise as the number of objects increases. This work studies the algorithmic structure of rearranging uniform objects, where robot-object collisions do not occur but object-object collisions have to be avoided. The objective is minimizing the number of object transfers under the assumption that the robot can manipulate one object at a time. An efficiently computable decomposition of the configuration space is used to create a "region graph", which classifies all continuous paths of equivalent collision possibilities. Based on this compact but rich representation, a complete dynamic programming primitive DFSDP performs a recursive depth first search to solve monotone problems quickly, i.e., those instances that do not require objects to be moved first to an intermediate buffer. DFSDP is extended to solve single-buffer, non-monotone instances, given a choice of an object and a buffer. This work utilizes these primitives as local planners in an informed search framework for more general, non-monotone instances. The search utilizes partial solutions from the primitives to identify the most promising choice of objects and buffers. Experiments demonstrate that the proposed solution returns near-optimal paths with higher success rate, even for challenging non-monotone instances, than other leading alternatives.
Mixup Without Hesitation
Jan 12, 2021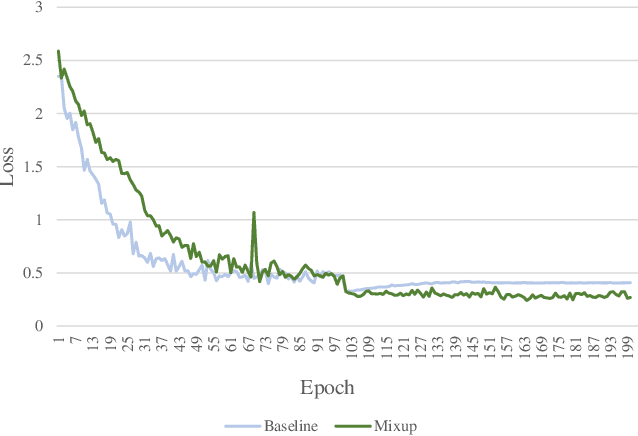
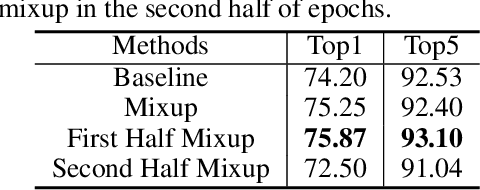


Mixup linearly interpolates pairs of examples to form new samples, which is easy to implement and has been shown to be effective in image classification tasks. However, there are two drawbacks in mixup: one is that more training epochs are needed to obtain a well-trained model; the other is that mixup requires tuning a hyper-parameter to gain appropriate capacity but that is a difficult task. In this paper, we find that mixup constantly explores the representation space, and inspired by the exploration-exploitation dilemma in reinforcement learning, we propose mixup Without hesitation (mWh), a concise, effective, and easy-to-use training algorithm. We show that mWh strikes a good balance between exploration and exploitation by gradually replacing mixup with basic data augmentation. It can achieve a strong baseline with less training time than original mixup and without searching for optimal hyper-parameter, i.e., mWh acts as mixup without hesitation. mWh can also transfer to CutMix, and gain consistent improvement on other machine learning and computer vision tasks such as object detection. Our code is open-source and available at https://github.com/yuhao318/mwh
tf.data: A Machine Learning Data Processing Framework
Jan 28, 2021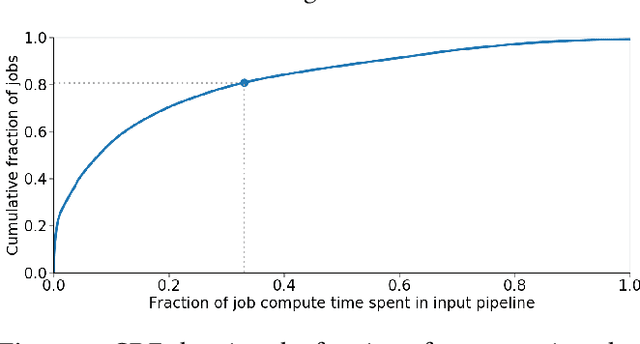

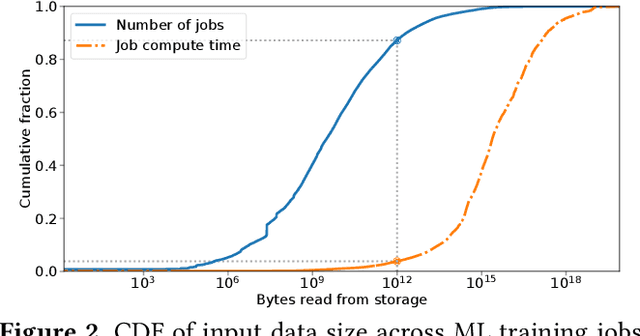
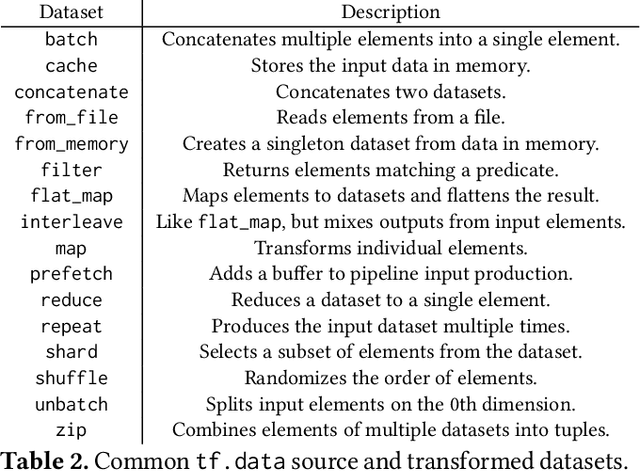
Training machine learning models requires feeding input data for models to ingest. Input pipelines for machine learning jobs are often challenging to implement efficiently as they require reading large volumes of data, applying complex transformations, and transferring data to hardware accelerators while overlapping computation and communication to achieve optimal performance. We present tf.data, a framework for building and executing efficient input pipelines for machine learning jobs. The tf.data API provides operators which can be parameterized with user-defined computation, composed, and reused across different machine learning domains. These abstractions allow users to focus on the application logic of data processing, while tf.data's runtime ensures that pipelines run efficiently. We demonstrate that input pipeline performance is critical to the end-to-end training time of state-of-the-art machine learning models. tf.data delivers the high performance required, while avoiding the need for manual tuning of performance knobs. We show that tf.data features, such as parallelism, caching, static optimizations, and non-deterministic execution are essential for high performance. Finally, we characterize machine learning input pipelines for millions of jobs that ran in Google's fleet, showing that input data processing is highly diverse and consumes a significant fraction of job resources. Our analysis motivates future research directions, such as sharing computation across jobs and pushing data projection to the storage layer.
Statistical Estimation of High-Dimensional Vector Autoregressive Models
Jun 09, 2020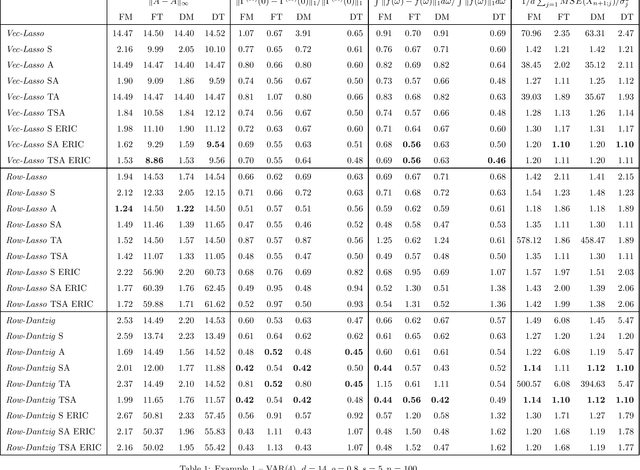
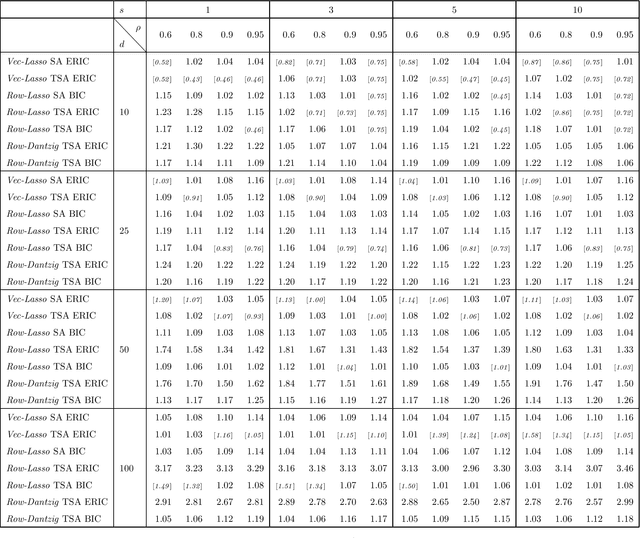
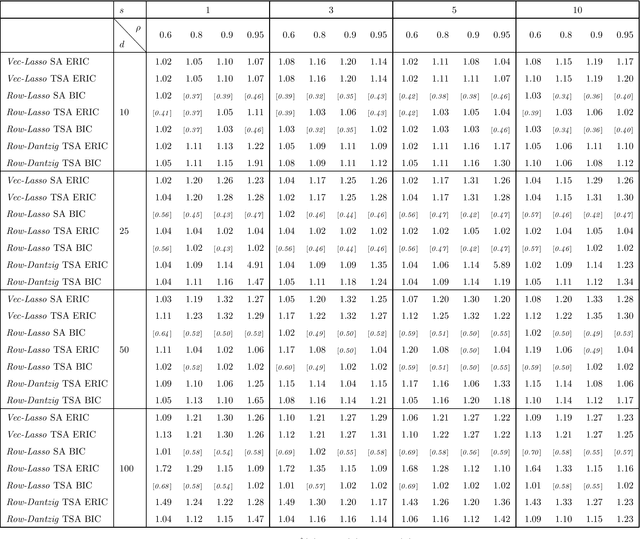
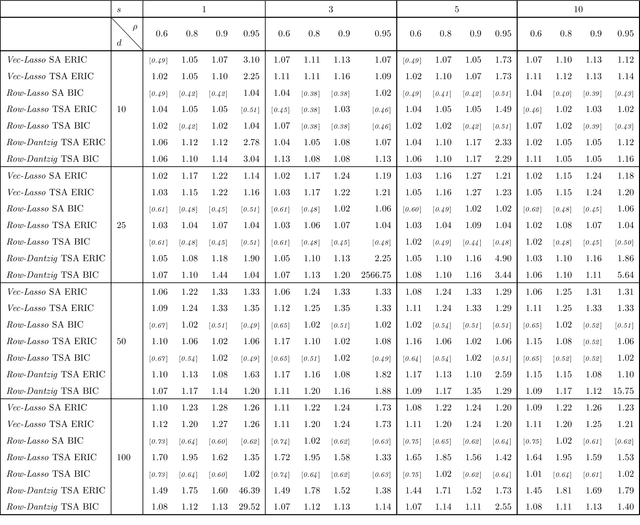
High-dimensional vector autoregressive (VAR) models are important tools for the analysis of multivariate time series. This paper focuses on high-dimensional time series and on the different regularized estimation procedures proposed for fitting sparse VAR models to such time series. Attention is paid to the different sparsity assumptions imposed on the VAR parameters and how these sparsity assumptions are related to the particular consistency properties of the estimators established. A sparsity scheme for high-dimensional VAR models is proposed which is found to be more appropriate for the time series setting considered. Furthermore, it is shown that, under this sparsity setting, threholding extents the consistency properties of regularized estimators to a wide range of matrix norms. Among other things, this enables application of the VAR parameters estimators to different inference problems, like forecasting or estimating the second-order characteristics of the underlying VAR process. Extensive simulations compare the finite sample behavior of the different regularized estimators proposed using a variety of performance criteria.
How to Train Your Robot with Deep Reinforcement Learning; Lessons We've Learned
Feb 04, 2021



Deep reinforcement learning (RL) has emerged as a promising approach for autonomously acquiring complex behaviors from low level sensor observations. Although a large portion of deep RL research has focused on applications in video games and simulated control, which does not connect with the constraints of learning in real environments, deep RL has also demonstrated promise in enabling physical robots to learn complex skills in the real world. At the same time,real world robotics provides an appealing domain for evaluating such algorithms, as it connects directly to how humans learn; as an embodied agent in the real world. Learning to perceive and move in the real world presents numerous challenges, some of which are easier to address than others, and some of which are often not considered in RL research that focuses only on simulated domains. In this review article, we present a number of case studies involving robotic deep RL. Building off of these case studies, we discuss commonly perceived challenges in deep RL and how they have been addressed in these works. We also provide an overview of other outstanding challenges, many of which are unique to the real-world robotics setting and are not often the focus of mainstream RL research. Our goal is to provide a resource both for roboticists and machine learning researchers who are interested in furthering the progress of deep RL in the real world.
Edge Federated Learning Via Unit-Modulus Over-The-Air Computation (Extended Version)
Jan 28, 2021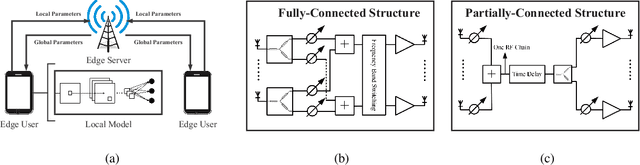
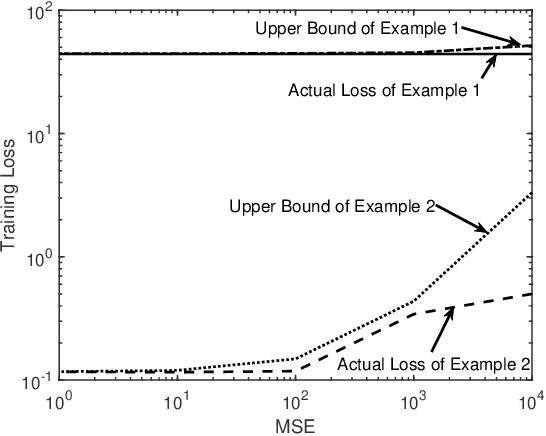
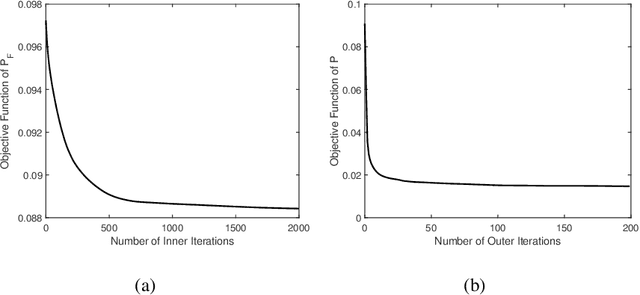
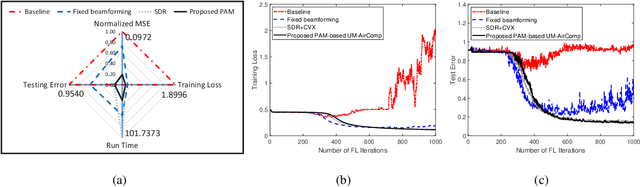
Edge federated learning (FL) is an emerging machine learning paradigm that trains a global parametric model from distributed datasets via wireless communications. This paper proposes a unit-modulus over-the-air computation (UM-AirComp) framework to facilitate efficient edge federated learning, which simultaneously uploads local model parameters and updates global model parameters via analog beamforming. The proposed framework avoids sophisticated baseband signal processing, leading to low communication delays and implementation costs. A training loss bound of UM-AirComp is derived and two low-complexity algorithms, termed penalty alternating minimization (PAM) and accelerated gradient projection (AGP), are proposed to minimize the nonconvex nonsmooth loss bound. Simulation results show that the proposed UM-AirComp framework with PAM algorithm not only achieves a smaller mean square error of model parameters' estimation, training loss, and testing error, but also requires a significantly shorter run time than that of other benchmark schemes. Moreover, the proposed UM-AirComp framework with AGP algorithm achieves satisfactory performance while reduces the computational complexity by orders of magnitude compared with existing optimization algorithms. Finally, we demonstrate the implementation of UM-AirComp in a vehicle-to-everything autonomous driving simulation platform. It is found that autonomous driving tasks are more sensitive to model parameter errors than other tasks since their neural networks are more sophisticated containing sparser model parameters.
Making Efficient Use of a Domain Expert's Time in Relation Extraction
Jul 12, 2018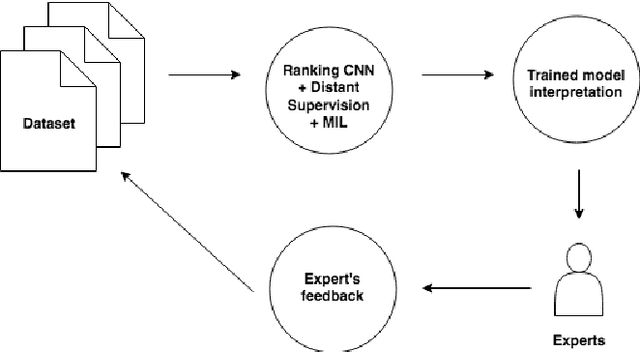
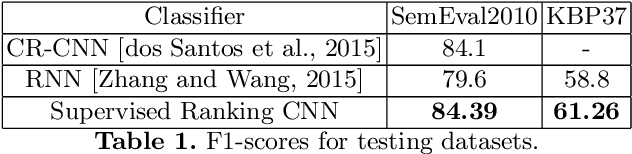
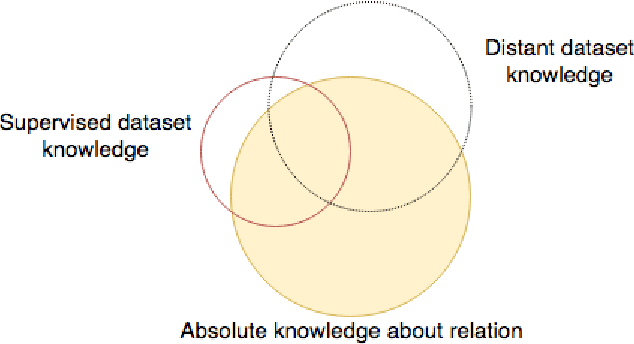
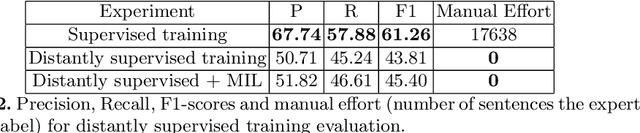
Scarcity of labeled data is one of the most frequent problems faced in machine learning. This is particularly true in relation extraction in text mining, where large corpora of texts exists in many application domains, while labeling of text data requires an expert to invest much time to read the documents. Overall, state-of-the art models, like the convolutional neural network used in this paper, achieve great results when trained on large enough amounts of labeled data. However, from a practical point of view the question arises whether this is the most efficient approach when one takes the manual effort of the expert into account. In this paper, we report on an alternative approach where we first construct a relation extraction model using distant supervision, and only later make use of a domain expert to refine the results. Distant supervision provides a mean of labeling data given known relations in a knowledge base, but it suffers from noisy labeling. We introduce an active learning based extension, that allows our neural network to incorporate expert feedback and report on first results on a complex data set.
1-bit Adam: Communication Efficient Large-Scale Training with Adam's Convergence Speed
Feb 04, 2021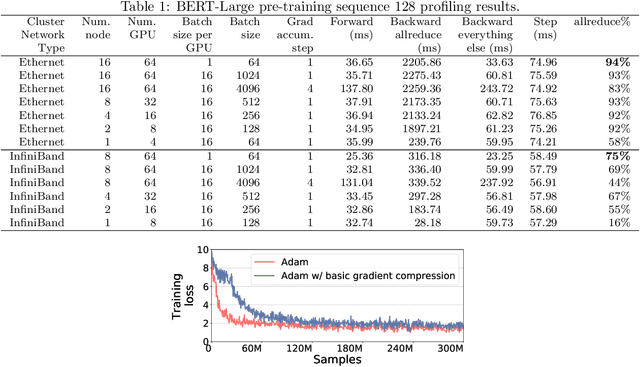
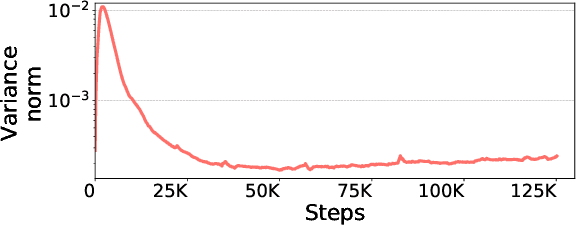
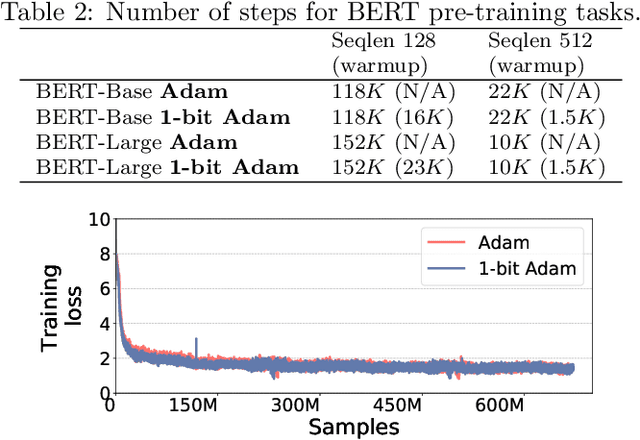

Scalable training of large models (like BERT and GPT-3) requires careful optimization rooted in model design, architecture, and system capabilities. From a system standpoint, communication has become a major bottleneck, especially on commodity systems with standard TCP interconnects that offer limited network bandwidth. Communication compression is an important technique to reduce training time on such systems. One of the most effective methods is error-compensated compression, which offers robust convergence speed even under 1-bit compression. However, state-of-the-art error compensation techniques only work with basic optimizers like SGD and momentum SGD, which are linearly dependent on the gradients. They do not work with non-linear gradient-based optimizers like Adam, which offer state-of-the-art convergence efficiency and accuracy for models like BERT. In this paper, we propose 1-bit Adam that reduces the communication volume by up to $5\times$, offers much better scalability, and provides the same convergence speed as uncompressed Adam. Our key finding is that Adam's variance (non-linear term) becomes stable (after a warmup phase) and can be used as a fixed precondition for the rest of the training (compression phase). Experiments on up to 256 GPUs show that 1-bit Adam enables up to $3.3\times$ higher throughput for BERT-Large pre-training and up to $2.9\times$ higher throughput for SQuAD fine-tuning. In addition, we provide theoretical analysis for our proposed work.