 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Class-incremental Learning with Rectified Feature-Graph Preservation
Dec 15, 2020
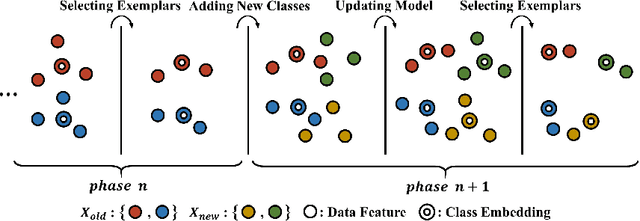
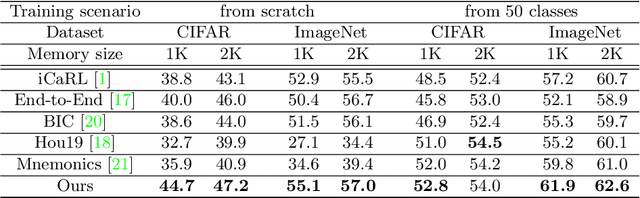
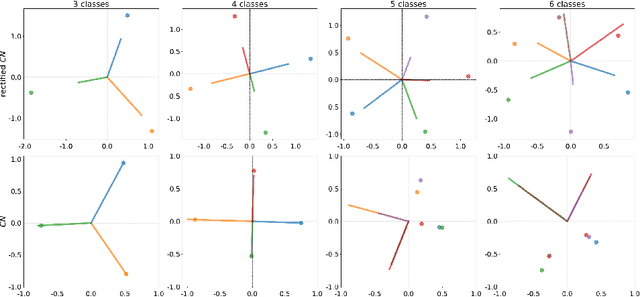
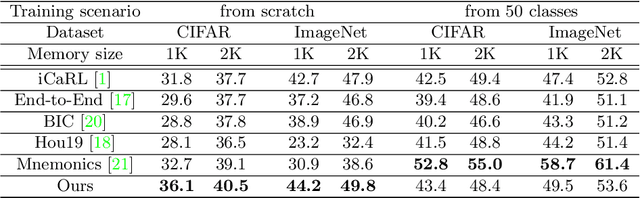
In this paper, we address the problem of distillation-based class-incremental learning with a single head. A central theme of this task is to learn new classes that arrive in sequential phases over time while keeping the model's capability of recognizing seen classes with only limited memory for preserving seen data samples. Many regularization strategies have been proposed to mitigate the phenomenon of catastrophic forgetting. To understand better the essence of these regularizations, we introduce a feature-graph preservation perspective. Insights into their merits and faults motivate our weighted-Euclidean regularization for old knowledge preservation. We further propose rectified cosine normalization and show how it can work with binary cross-entropy to increase class separation for effective learning of new classes. Experimental results on both CIFAR-100 and ImageNet datasets demonstrate that our method outperforms the state-of-the-art approaches in reducing classification error, easing catastrophic forgetting, and encouraging evenly balanced accuracy over different classes. Our project page is at : https://github.com/yhchen12101/FGP-ICL.
Occlusion-robust Deformable Object Tracking without Physics Simulation
Jan 04, 2021


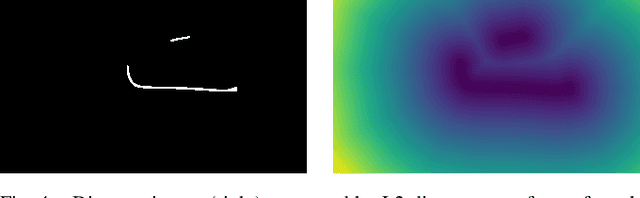
Estimating the state of a deformable object is crucial for robotic manipulation, yet accurate tracking is challenging when the object is partially-occluded. To address this problem, we propose an occlusion-robust RGBD sequence tracking framework based on Coherent Point Drift (CPD). To mitigate the effects of occlusion, our method 1) Uses a combination of locally linear embedding and constrained optimization to regularize the output of CPD, thus enforcing topological consistency when occlusions create disconnected pieces of the object; 2) Reasons about the free-space visible by an RGBD sensor to better estimate the prior on point location and to detect tracking failures during occlusion; and 3) Uses shape descriptors to find the most relevant previous state of the object to use for tracking after a severe occlusion. Our method does not rely on physics simulation or a physical model of the object, which can be difficult to obtain in unstructured environments. Despite having no physical model, our experiments demonstrate that our method achieves improved accuracy in the presence of occlusion as compared to a physics-based CPD method while maintaining adequate run-time.
Neural Ordinary Differential Equation based Recurrent Neural Network Model
May 20, 2020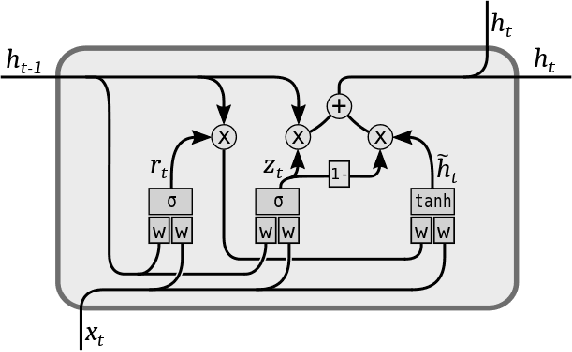
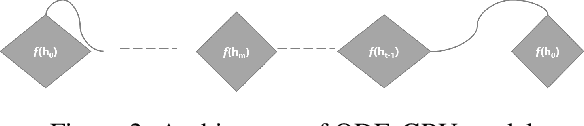
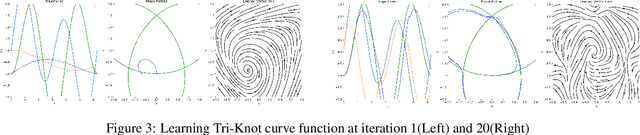

Neural differential equations are a promising new member in the neural network family. They show the potential of differential equations for time series data analysis. In this paper, the strength of the ordinary differential equation (ODE) is explored with a new extension. The main goal of this work is to answer the following questions: (i)~can ODE be used to redefine the existing neural network model? (ii)~can Neural ODEs solve the irregular sampling rate challenge of existing neural network models for a continuous time series, i.e., length and dynamic nature, (iii)~how to reduce the training and evaluation time of existing Neural ODE systems? This work leverages the mathematical foundation of ODEs to redesign traditional RNNs such as Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU). The main contribution of this paper is to illustrate the design of two new ODE-based RNN models (GRU-ODE model and LSTM-ODE) which can compute the hidden state and cell state at any point of time using an ODE solver. These models reduce the computation overhead of hidden state and cell state by a vast amount. The performance evaluation of these two new models for learning continuous time series with irregular sampling rate is then demonstrated. Experiments show that these new ODE based RNN models require less training time than Latent ODEs and conventional Neural ODEs. They can achieve higher accuracy quickly, and the design of the neural network is simpler than, previous neural ODE systems.
Snapshot Difference Imaging using Time-of-Flight Sensors
May 19, 2017
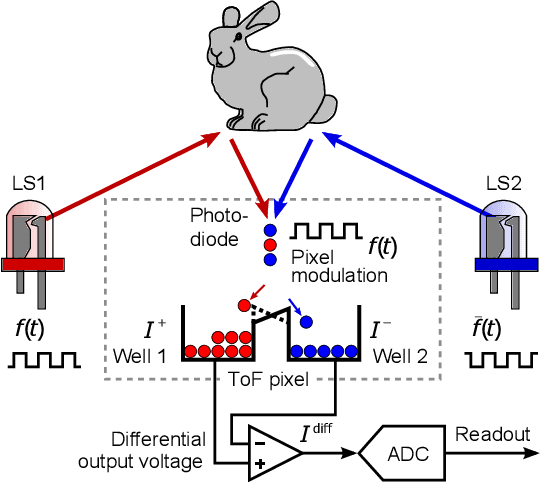
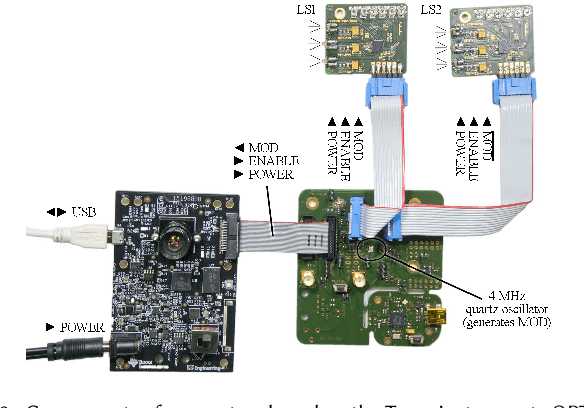
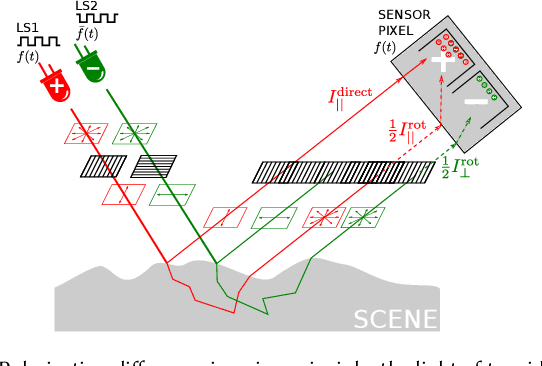
Computational photography encompasses a diversity of imaging techniques, but one of the core operations performed by many of them is to compute image differences. An intuitive approach to computing such differences is to capture several images sequentially and then process them jointly. Usually, this approach leads to artifacts when recording dynamic scenes. In this paper, we introduce a snapshot difference imaging approach that is directly implemented in the sensor hardware of emerging time-of-flight cameras. With a variety of examples, we demonstrate that the proposed snapshot difference imaging technique is useful for direct-global illumination separation, for direct imaging of spatial and temporal image gradients, for direct depth edge imaging, and more.
Incremental Data-driven Optimization of Complex Systems in Nonstationary Environments
Dec 25, 2020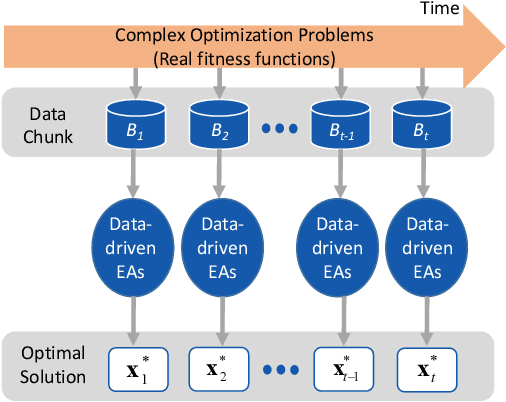
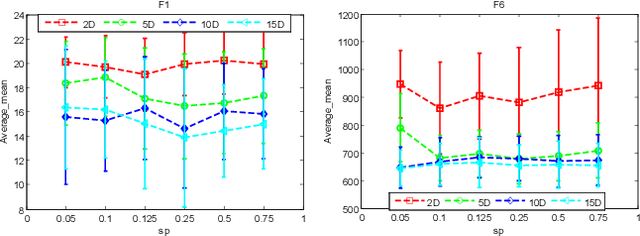
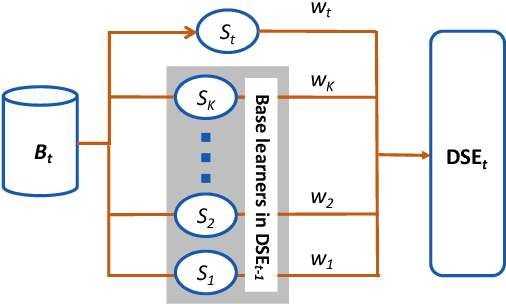
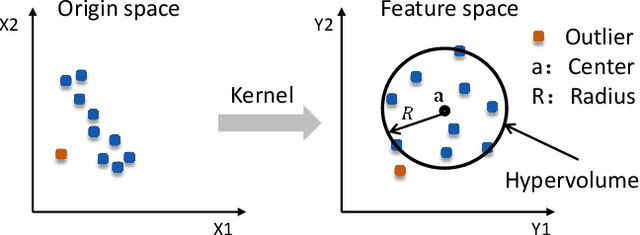
Existing work on data-driven optimization focuses on problems in static environments, but little attention has been paid to problems in dynamic environments. This paper proposes a data-driven optimization algorithm to deal with the challenges presented by the dynamic environments. First, a data stream ensemble learning method is adopted to train the surrogates so that each base learner of the ensemble learns the time-varying objective function in the previous environments. After that, a multi-task evolutionary algorithm is employed to simultaneously optimize the problems in the past environments assisted by the ensemble surrogate. This way, the optimization tasks in the previous environments can be used to accelerate the tracking of the optimum in the current environment. Since the real fitness function is not available for verifying the surrogates in offline data-driven optimization, a support vector domain description that was designed for outlier detection is introduced to select a reliable solution. Empirical results on six dynamic optimization benchmark problems demonstrate the effectiveness of the proposed algorithm compared with four state-of-the-art data-driven optimization algorithms.
Lorenz Trajectories Prediction: Travel Through Time
Mar 18, 2019
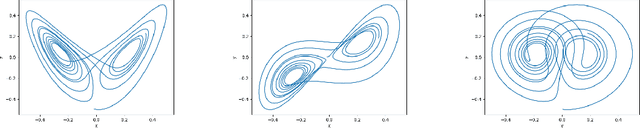

In this article the Lorenz dynamical system is revived and revisited and the current state of the art results for one step ahead forecasting for the Lorenz trajectories are published. The article is a reflection upon the evolution of neural networks with regards to the prediction performance on this canonical task.
Digital Twins: State of the Art Theory and Practice, Challenges, and Open Research Questions
Nov 06, 2020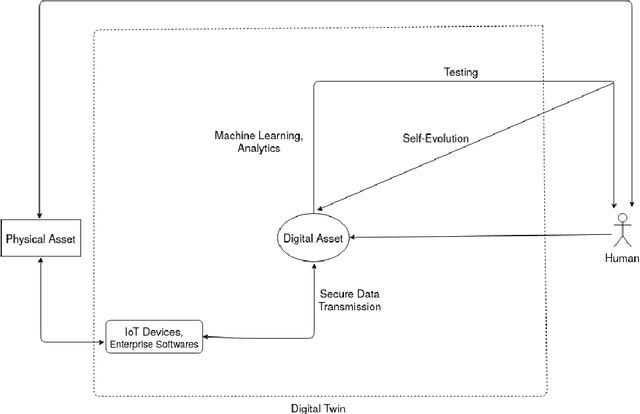
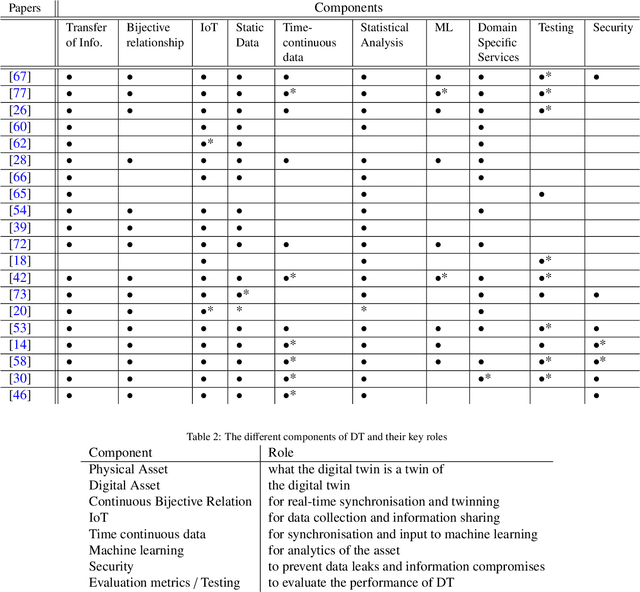
Digital Twin was introduced over a decade ago, as an innovative all-encompassing tool, with perceived benefits including real-time monitoring, simulation and forecasting. However, the theoretical framework and practical implementations of digital twins (DT) are still far from this vision. Although successful implementations exist, sufficient implementation details are not publicly available, therefore it is difficult to assess their effectiveness, draw comparisons and jointly advance the DT methodology. This work explores the various DT features and current approaches, the shortcomings and reasons behind the delay in the implementation and adoption of digital twin. Advancements in machine learning, internet of things and big data have contributed hugely to the improvements in DT with regards to its real-time monitoring and forecasting properties. Despite this progress and individual company-based efforts, certain research gaps exist in the field, which have caused delay in the widespread adoption of this concept. We reviewed relevant works and identified that the major reasons for this delay are the lack of a universal reference framework, domain dependence, security concerns of shared data, reliance of digital twin on other technologies, and lack of quantitative metrics. We define the necessary components of a digital twin required for a universal reference framework, which also validate its uniqueness as a concept compared to similar concepts like simulation, autonomous systems, etc. This work further assesses the digital twin applications in different domains and the current state of machine learning and big data in it. It thus answers and identifies novel research questions, both of which will help to better understand and advance the theory and practice of digital twins.
Correlation-wise Smoothing: Lightweight Knowledge Extraction for HPC Monitoring Data
Oct 13, 2020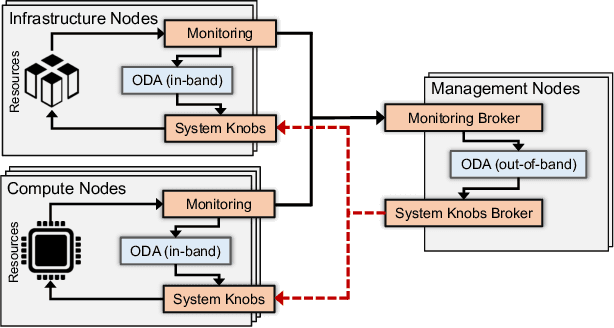
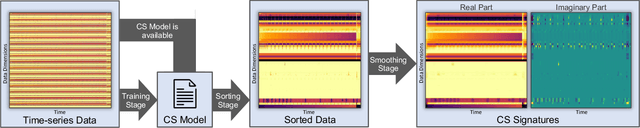
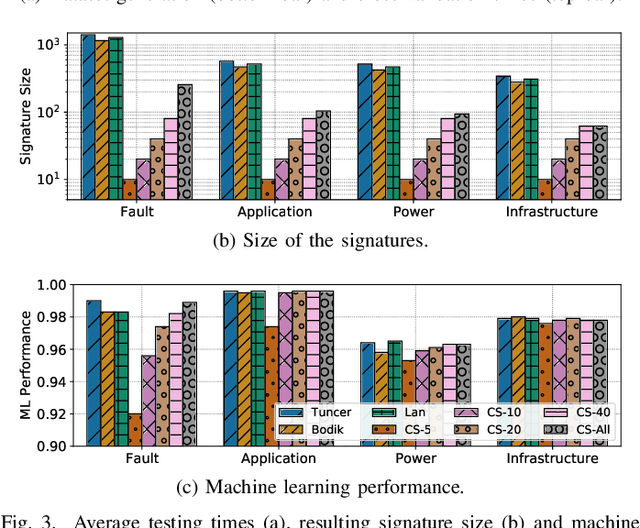
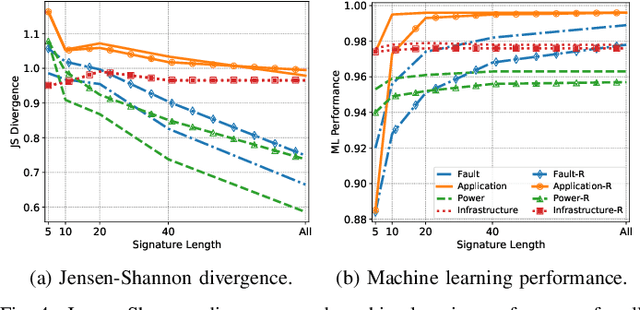
Modern High-Performance Computing (HPC) and data center operators rely more and more on data analytics techniques to improve the efficiency and reliability of their operations. They employ models that ingest time-series monitoring sensor data and transform it into actionable knowledge for system tuning: a process known as Operational Data Analytics (ODA). However, monitoring data has a high dimensionality, is hardware-dependent and difficult to interpret. This, coupled with the strict requirements of ODA, makes most traditional data mining methods impractical and in turn renders this type of data cumbersome to process. Most current ODA solutions use ad-hoc processing methods that are not generic, are sensible to the sensors' features and are not fit for visualization. In this paper we propose a novel method, called Correlation-wise Smoothing (CS), to extract descriptive signatures from time-series monitoring data in a generic and lightweight way. Our CS method exploits correlations between data dimensions to form groups and produces image-like signatures that can be easily manipulated, visualized and compared. We evaluate the CS method on HPC-ODA, a collection of datasets that we release with this work, and show that it leads to the same performance as most state-of-the-art methods while producing signatures that are up to ten times smaller and up to ten times faster, while gaining visualizability, portability across systems and clear scaling properties.
Fusion of rain radar images and wind forecasts in a deep learning model applied to rain nowcasting
Dec 09, 2020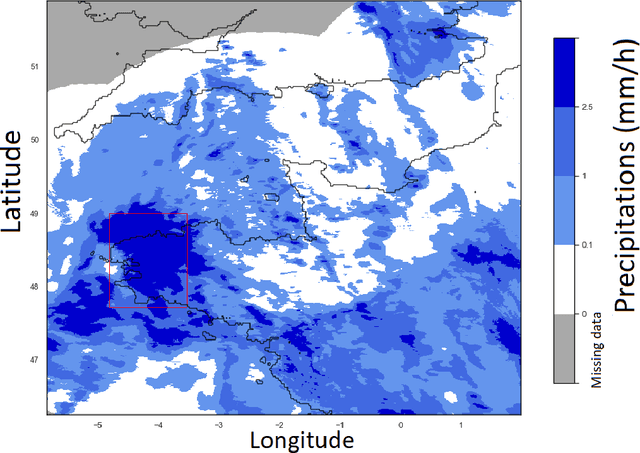

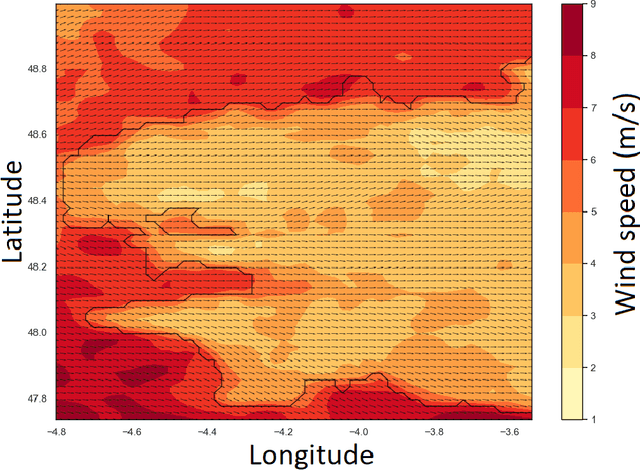
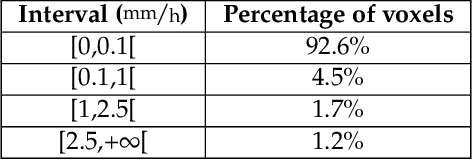
Short or mid-term rainfall forecasting is a major task for several environmental applications, such as agricultural management or monitoring flood risks. Existing data-driven approaches, especially deep learning models, have shown significant skill at this task, using only rain radar images as inputs. In order to determine whether using other meteorological parameters such as wind would improve forecasts, we trained a deep learning model on a fusion of rain radar images and wind velocity produced by a weather forecast model. The network was compared to a similar architecture trained only on rainfall data, to a basic persistence model and to an approach based on optical flow. Our network outperforms the F1-score calculated for the optical flow on moderate and higher rain events for forecasts at a horizon time of 30 minutes by 8%. Furthermore, it outperforms the same architecture trained using only rainfalls by 7%.
Systolic Computing on GPUs for Productive Performance
Oct 29, 2020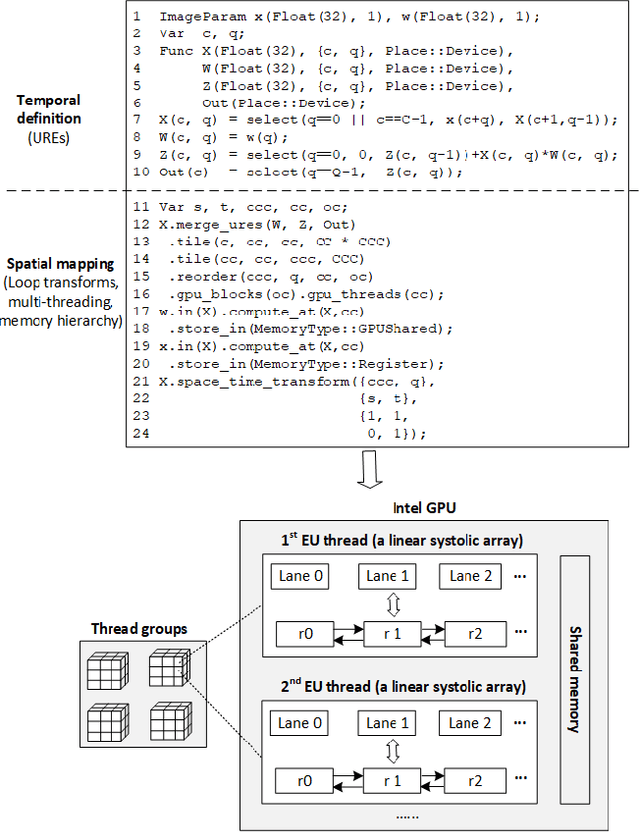
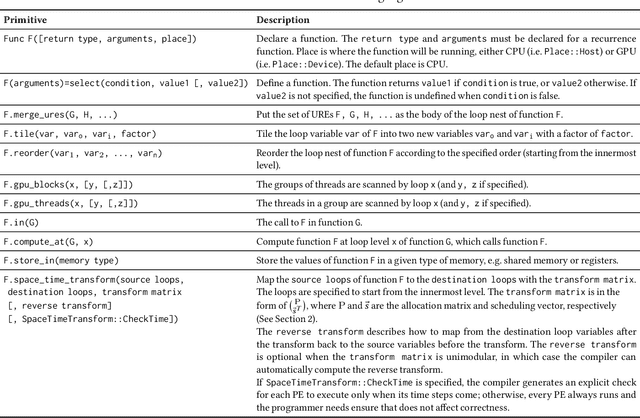
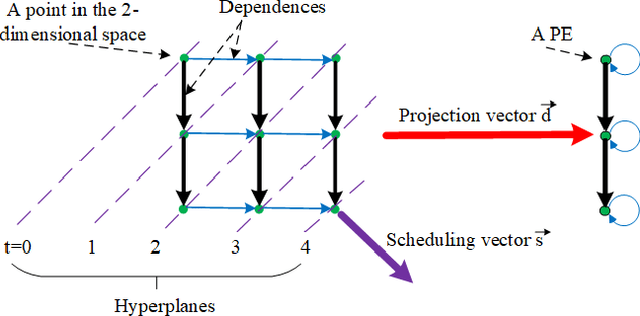
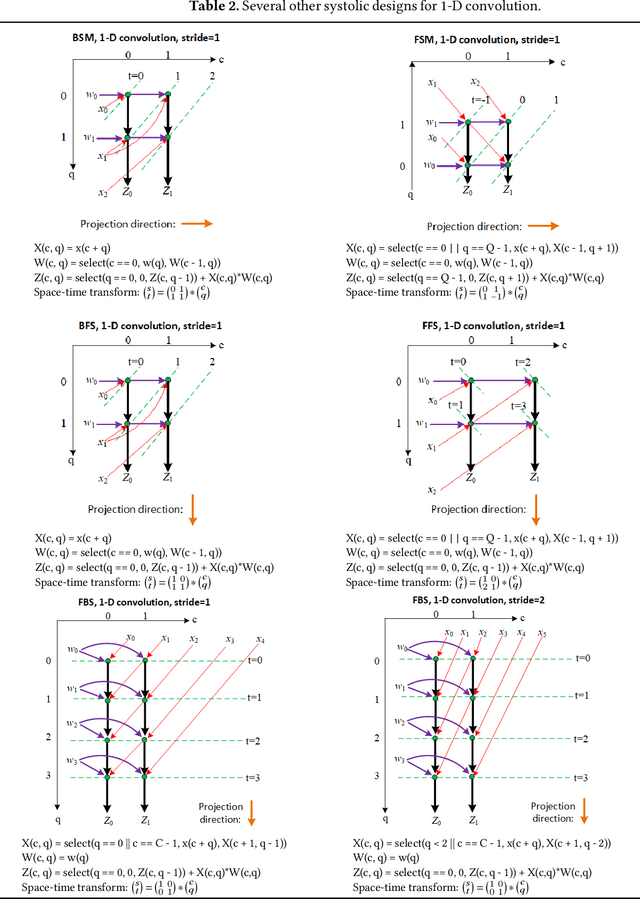
We propose a language and compiler to productively build high-performance {\it software systolic arrays} that run on GPUs. Based on a rigorous mathematical foundation (uniform recurrence equations and space-time transform), our language has a high abstraction level and covers a wide range of applications. A programmer {\it specifies} a projection of a dataflow compute onto a linear systolic array, while leaving the detailed implementation of the projection to a compiler; the compiler implements the specified projection and maps the linear systolic array to the SIMD execution units and vector registers of GPUs. In this way, both productivity and performance are achieved in the same time. This approach neatly combines loop transformations, data shuffling, and vector register allocation into a single framework. Meanwhile, many other optimizations can be applied as well; the compiler composes the optimizations together to generate efficient code. We implemented the approach on Intel GPUs. This is the first system that allows productive construction of systolic arrays on GPUs. We allow multiple projections, arbitrary projection directions and linear schedules, which can express most, if not all, systolic arrays in practice. Experiments with 1- and 2-D convolution on an Intel GEN9.5 GPU have demonstrated the generality of the approach, and its productivity in expressing various systolic designs for finding the best candidate. Although our systolic arrays are purely software running on generic SIMD hardware, compared with the GPU's specialized, hardware samplers that perform the same convolutions, some of our best designs are up to 59\% faster. Overall, this approach holds promise for productive high-performance computing on GPUs.