 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CNN Application in Detection of Privileged Documents in Legal Document Review
Feb 09, 2021
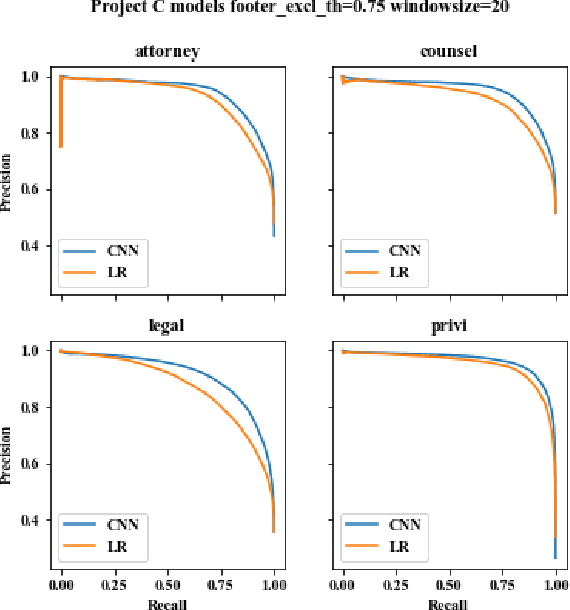
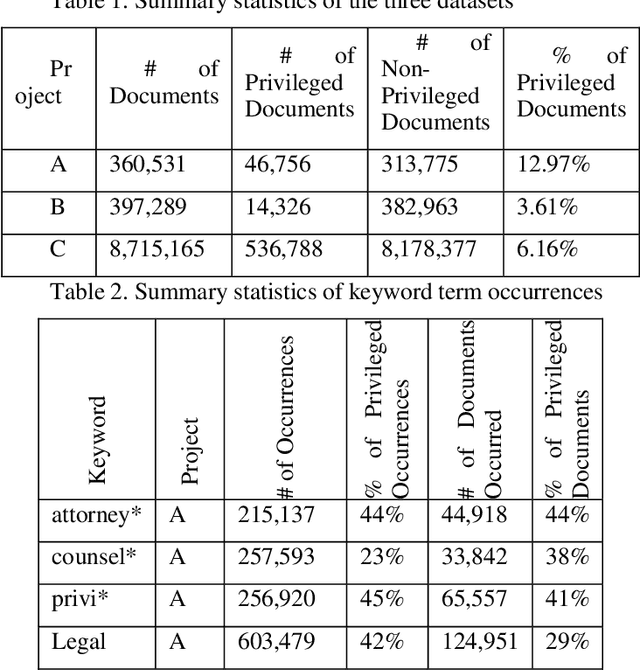
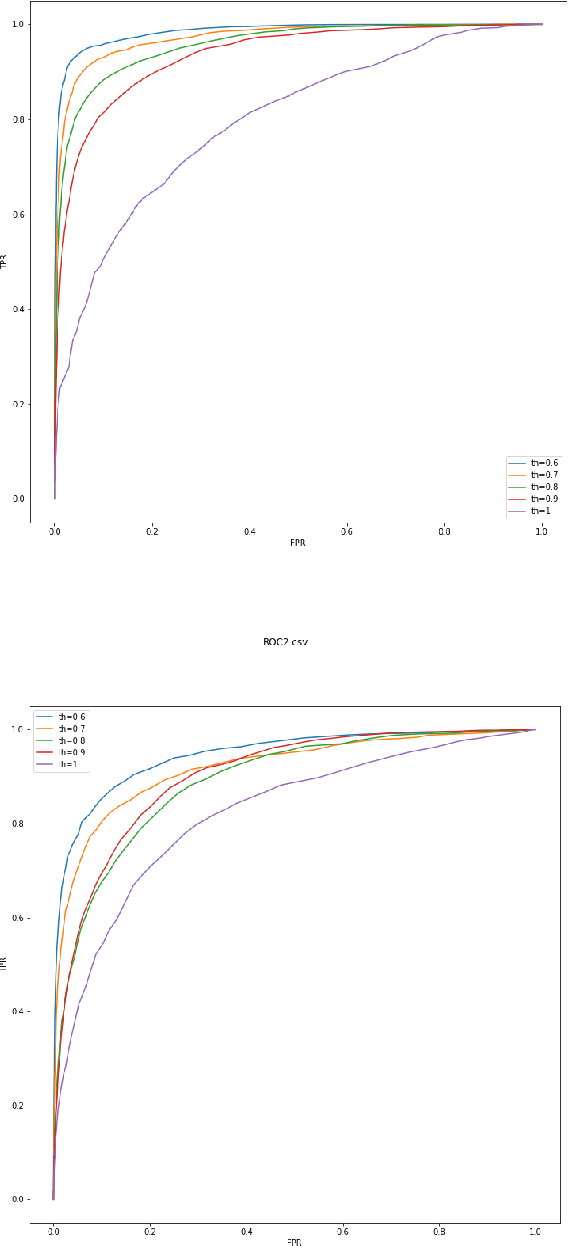
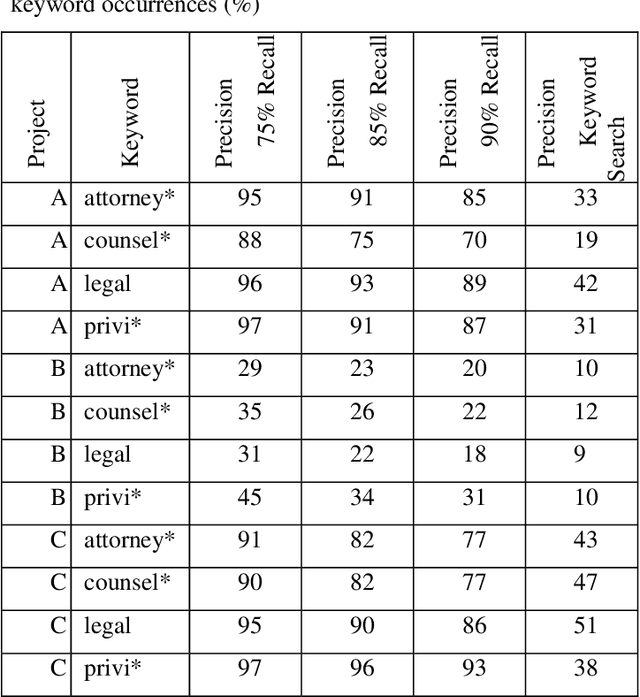
Protecting privileged communications and data from disclosure is paramount for legal teams. Legal advice, such as attorney-client communications or litigation strategy are typically exempt from disclosure in litigations or regulatory events and are vital to the attorney-client relationship. To protect this information from disclosure, companies and outside counsel often review vast amounts of documents to determine those that contain privileged material. This process is extremely costly and time consuming. As data volumes increase, legal counsel normally employs methods to reduce the number of documents requiring review while balancing the need to ensure the protection of privileged information. Keyword searching is relied upon as a method to target privileged information and reduce document review populations. Keyword searches are effective at casting a wide net but often return overly inclusive results - most of which do not contain privileged information. To overcome the weaknesses of keyword searching, legal teams increasingly are using machine learning techniques to target privileged information. In these studies, classic text classification techniques are applied to build classification models to identify privileged documents. In this paper, the authors propose a different method by applying machine learning / convolutional neural network techniques (CNN) to identify privileged documents. Our proposed method combines keyword searching with CNN. For each keyword term, a CNN model is created using the context of the occurrences of the keyword. In addition, a method was proposed to select reliable privileged (positive) training keyword occurrences from labeled positive training documents. Extensive experiments were conducted, and the results show that the proposed methods can significantly reduce false positives while still capturing most of the true positives.
Fusion of rain radar images and wind forecasts in a deep learning model applied to rain nowcasting
Dec 09, 2020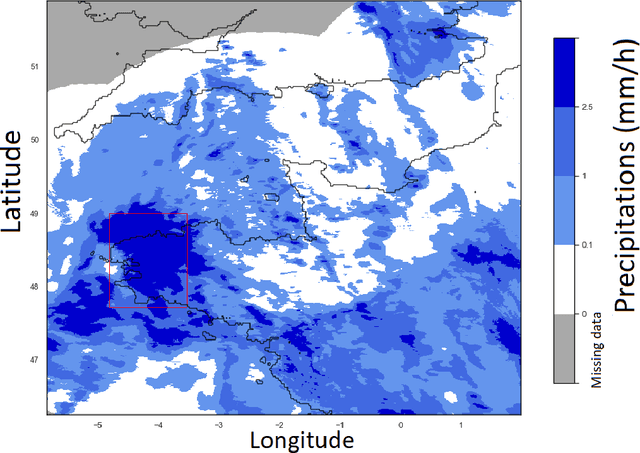

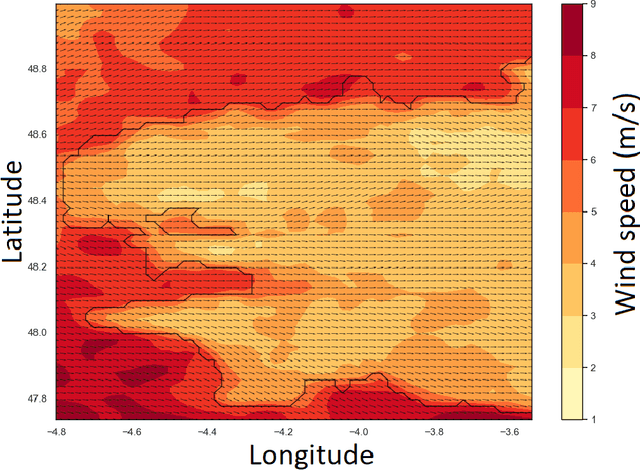
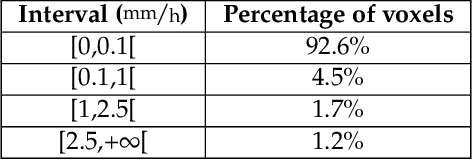
Short or mid-term rainfall forecasting is a major task for several environmental applications, such as agricultural management or monitoring flood risks. Existing data-driven approaches, especially deep learning models, have shown significant skill at this task, using only rain radar images as inputs. In order to determine whether using other meteorological parameters such as wind would improve forecasts, we trained a deep learning model on a fusion of rain radar images and wind velocity produced by a weather forecast model. The network was compared to a similar architecture trained only on rainfall data, to a basic persistence model and to an approach based on optical flow. Our network outperforms the F1-score calculated for the optical flow on moderate and higher rain events for forecasts at a horizon time of 30 minutes by 8%. Furthermore, it outperforms the same architecture trained using only rainfalls by 7%.
Fast Perturbative Algorithm Configurators
Jul 07, 2020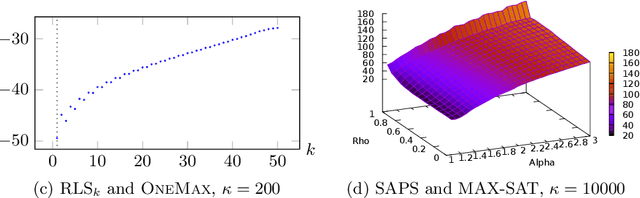
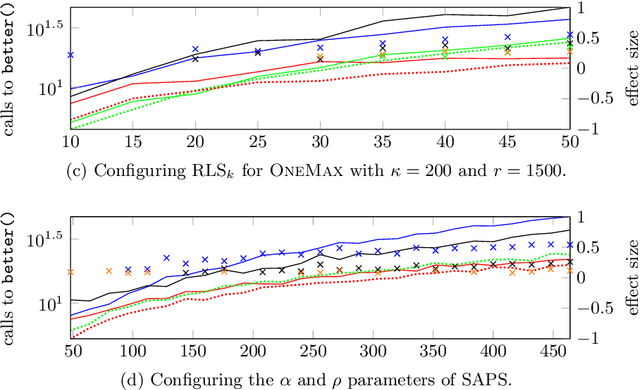
Recent work has shown that the ParamRLS and ParamILS algorithm configurators can tune some simple randomised search heuristics for standard benchmark functions in linear expected time in the size of the parameter space. In this paper we prove a linear lower bound on the expected time to optimise any parameter tuning problem for ParamRLS, ParamILS as well as for larger classes of algorithm configurators. We propose a harmonic mutation operator for perturbative algorithm configurators that provably tunes single-parameter algorithms in polylogarithmic time for unimodal and approximately unimodal (i.e., non-smooth, rugged with an underlying gradient towards the optimum) parameter spaces. It is suitable as a general-purpose operator since even on worst-case (e.g., deceptive) landscapes it is only by at most a logarithmic factor slower than the default ones used by ParamRLS and ParamILS. An experimental analysis confirms the superiority of the approach in practice for a number of configuration scenarios, including ones involving more than one parameter.
AttnMove: History Enhanced Trajectory Recovery via Attentional Network
Jan 03, 2021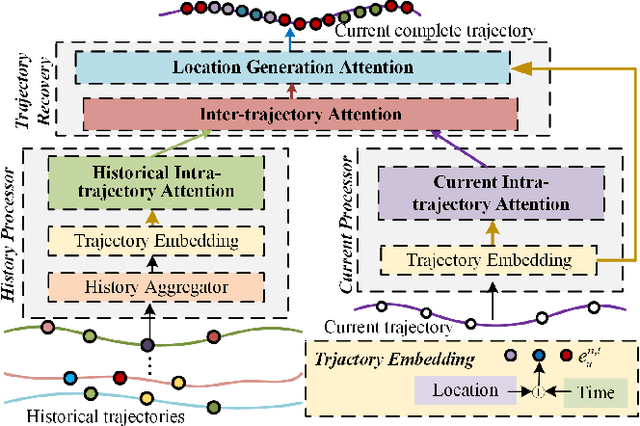
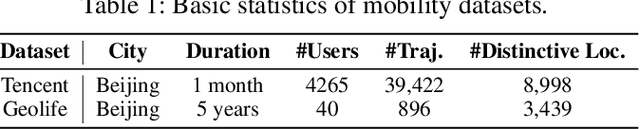
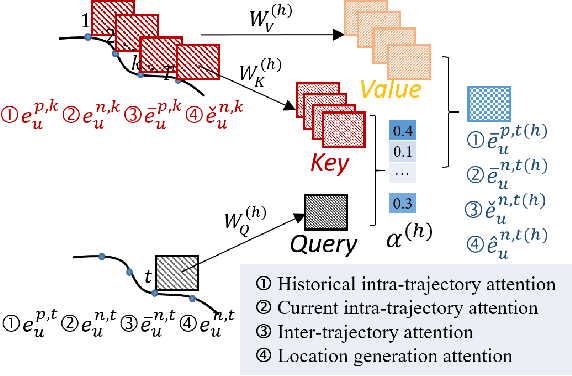
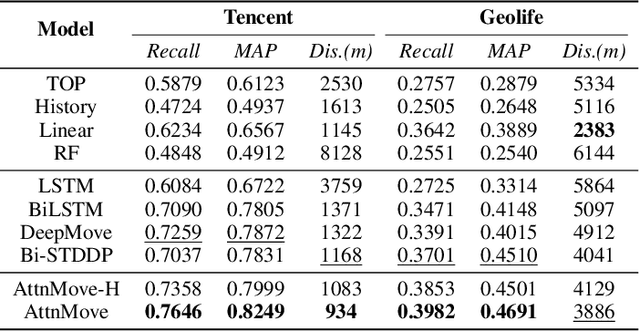
A considerable amount of mobility data has been accumulated due to the proliferation of location-based service. Nevertheless, compared with mobility data from transportation systems like the GPS module in taxis, this kind of data is commonly sparse in terms of individual trajectories in the sense that users do not access mobile services and contribute their data all the time. Consequently, the sparsity inevitably weakens the practical value of the data even it has a high user penetration rate. To solve this problem, we propose a novel attentional neural network-based model, named AttnMove, to densify individual trajectories by recovering unobserved locations at a fine-grained spatial-temporal resolution. To tackle the challenges posed by sparsity, we design various intra- and inter- trajectory attention mechanisms to better model the mobility regularity of users and fully exploit the periodical pattern from long-term history. We evaluate our model on two real-world datasets, and extensive results demonstrate the performance gain compared with the state-of-the-art methods. This also shows that, by providing high-quality mobility data, our model can benefit a variety of mobility-oriented down-stream applications.
Spinal Codes Optimization: Error Probability Analysis and Transmission Scheme Design
Jan 20, 2021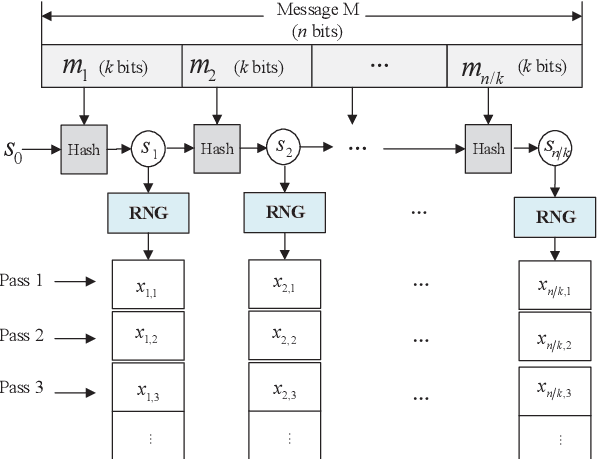

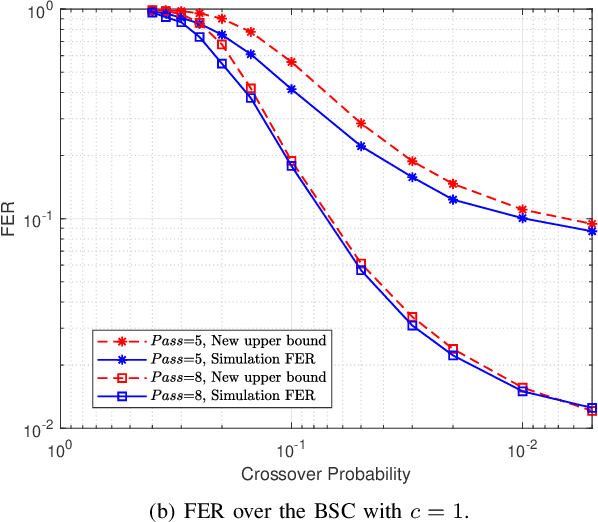
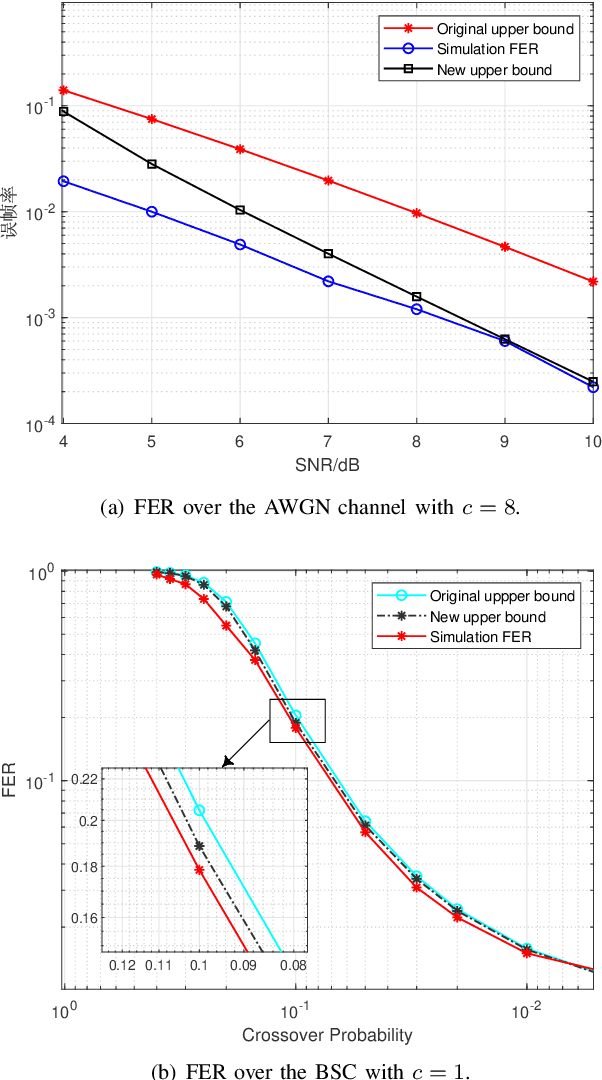
Spinal codes are known to be capacity achieving over both the additive white Gaussian noise (AWGN) channel and the binary symmetric channel (BSC). Over wireless channels, Spinal encoding can also be regarded as an adaptive-coded-modulation (ACM) technique due to its rateless property, which fits it with mobile communications. Due to lack of tight analysis on error probability of Spinal codes, optimization of transmission scheme using Spinal codes has not been fully explored. In this work, we firstly derive new tight upper bounds of the frame error rate (FER) of Spinal codes for both the AWGN channel and the BSC in the finite block-length (FBL) regime. Based on the derived upper bounds, we then design the optimal transmission scheme. Specifically, we formulate a rate maximization problem as a nonlinear integer programming problem, and solve it by an iterative algorithm for its dual problem. As the optimal solution exhibits an incremental-tail-transmission pattern, we propose an improved transmission scheme for Spinal codes. Moreover, we develop a bubble decoding with memory (BD-M) algorithm to reduce the decoding time complexity without loss of rate performance. The improved transmission scheme at the transmitter and the BD-M algorithm at the receiver jointly constitute an "encoding-decoding" system of Spinal codes. Simulation results demonstrate that it can improve both the rate performance and the decoding throughput of Spinal codes.
Towards an AI assistant for human grid operators
Dec 03, 2020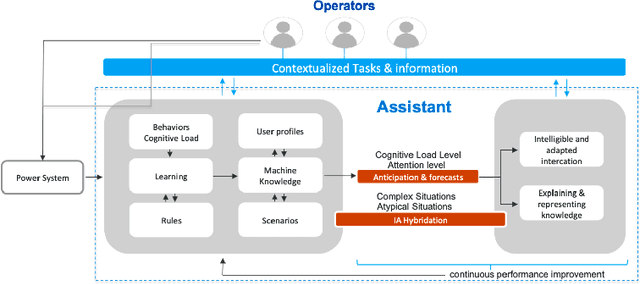

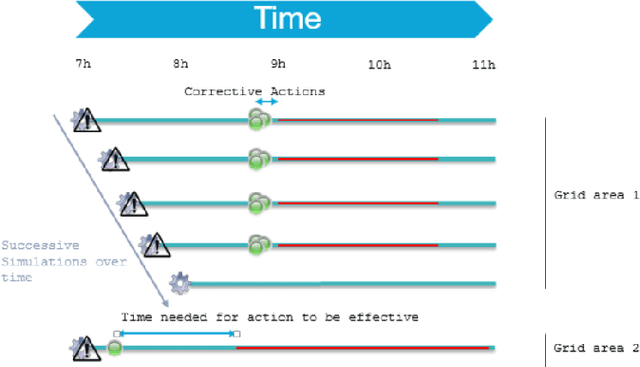
Power systems are becoming more complex to operate in the digital age. As a result, real-time decision-making is getting more challenging as the human operator has to deal with more information, more uncertainty, more applications and more coordination. While supervision has been primarily used to help them make decisions over the last decades, it cannot reasonably scale up anymore. There is a great need for rethinking the human-machine interface under more unified and interactive frameworks. Taking advantage of the latest developments in Human-machine Interactions and Artificial intelligence, we share the vision of a new assistant framework relying on an hypervision interface and greater bidirectional interactions. We review the known principles of decision-making that drives the assistant design and supporting assistance functions we present. We finally share some guidelines to make progress towards the development of such an assistant.
Split Computing for Complex Object Detectors: Challenges and Preliminary Results
Jul 27, 2020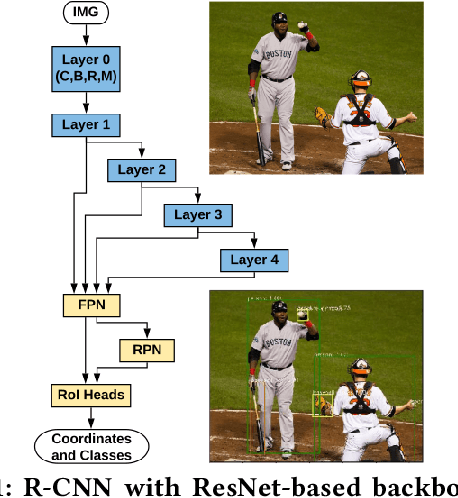
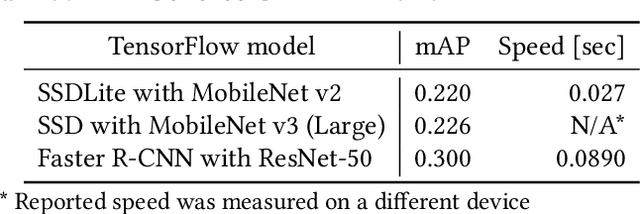
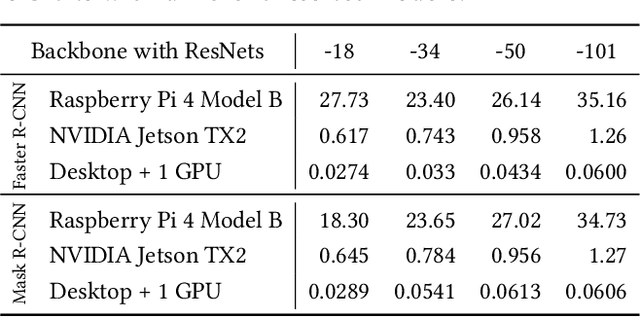
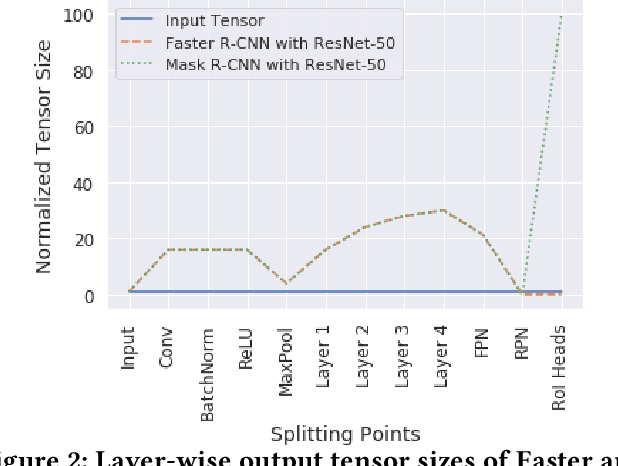
Following the trends of mobile and edge computing for DNN models, an intermediate option, split computing, has been attracting attentions from the research community. Previous studies empirically showed that while mobile and edge computing often would be the best options in terms of total inference time, there are some scenarios where split computing methods can achieve shorter inference time. All the proposed split computing approaches, however, focus on image classification tasks, and most are assessed with small datasets that are far from the practical scenarios. In this paper, we discuss the challenges in developing split computing methods for powerful R-CNN object detectors trained on a large dataset, COCO 2017. We extensively analyze the object detectors in terms of layer-wise tensor size and model size, and show that naive split computing methods would not reduce inference time. To the best of our knowledge, this is the first study to inject small bottlenecks to such object detectors and unveil the potential of a split computing approach. The source code and trained models' weights used in this study are available at https://github.com/yoshitomo-matsubara/hnd-ghnd-object-detectors .
Recurrence-free unconstrained handwritten text recognition using gated fully convolutional network
Dec 09, 2020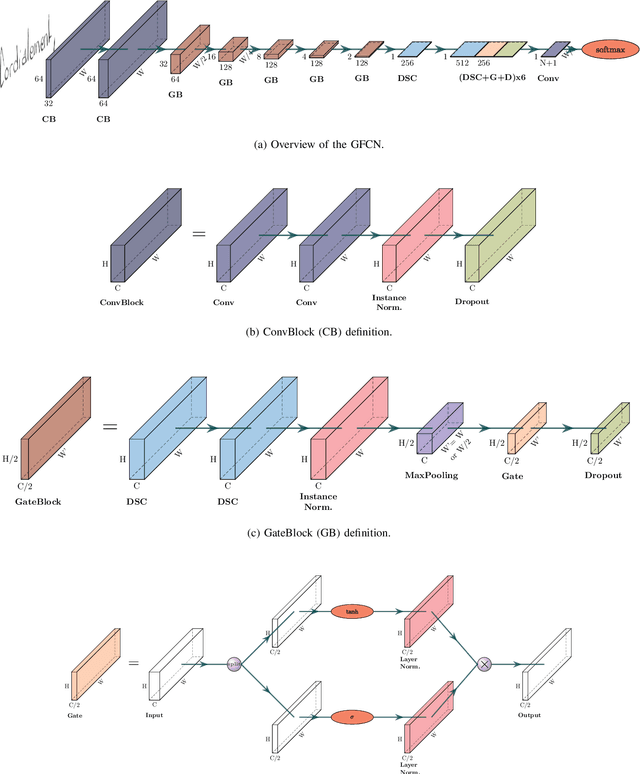
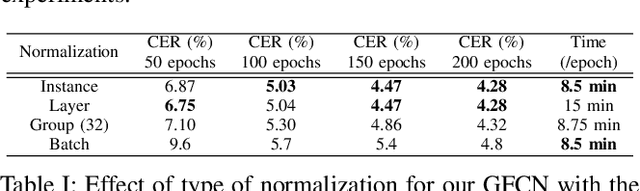
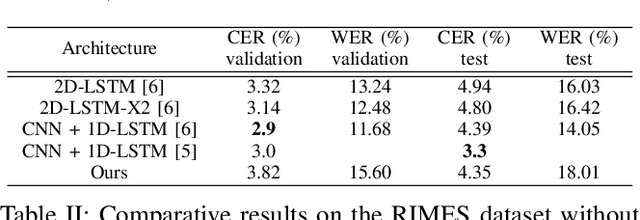
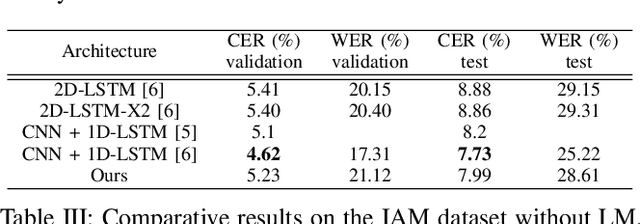
Unconstrained handwritten text recognition is a major step in most document analysis tasks. This is generally processed by deep recurrent neural networks and more specifically with the use of Long Short-Term Memory cells. The main drawbacks of these components are the large number of parameters involved and their sequential execution during training and prediction. One alternative solution to using LSTM cells is to compensate the long time memory loss with an heavy use of convolutional layers whose operations can be executed in parallel and which imply fewer parameters. In this paper we present a Gated Fully Convolutional Network architecture that is a recurrence-free alternative to the well-known CNN+LSTM architectures. Our model is trained with the CTC loss and shows competitive results on both the RIMES and IAM datasets. We release all code to enable reproduction of our experiments: https://github.com/FactoDeepLearning/LinePytorchOCR.
A Framework for Efficient Robotic Manipulation
Dec 14, 2020
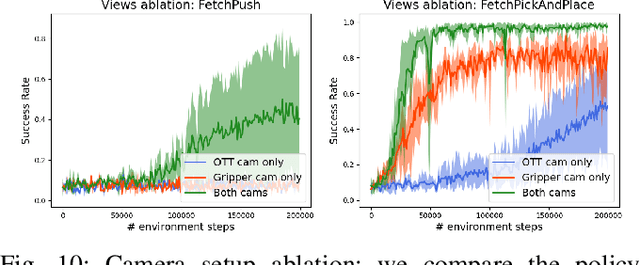
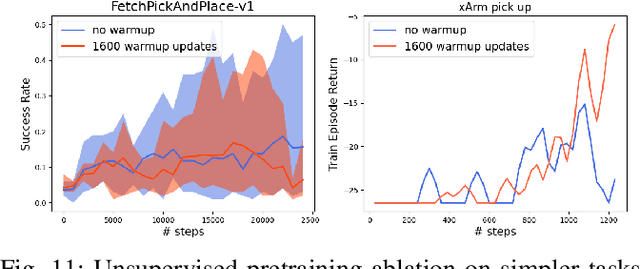
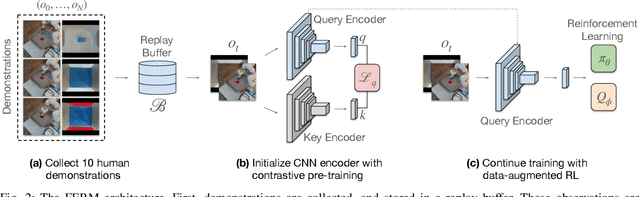
Data-efficient learning of manipulation policies from visual observations is an outstanding challenge for real-robot learning. While deep reinforcement learning (RL) algorithms have shown success learning policies from visual observations, they still require an impractical number of real-world data samples to learn effective policies. However, recent advances in unsupervised representation learning and data augmentation significantly improved the sample efficiency of training RL policies on common simulated benchmarks. Building on these advances, we present a Framework for Efficient Robotic Manipulation (FERM) that utilizes data augmentation and unsupervised learning to achieve extremely sample-efficient training of robotic manipulation policies with sparse rewards. We show that, given only 10 demonstrations, a single robotic arm can learn sparse-reward manipulation policies from pixels, such as reaching, picking, moving, pulling a large object, flipping a switch, and opening a drawer in just 15-50 minutes of real-world training time. We include videos, code, and additional information on the project website -- https://sites.google.com/view/efficient-robotic-manipulation.
Automatic Failure Recovery and Re-Initialization for Online UAV Tracking with Joint Scale and Aspect Ratio Optimization
Aug 10, 2020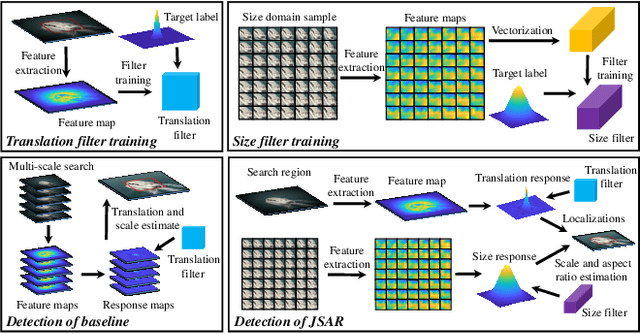
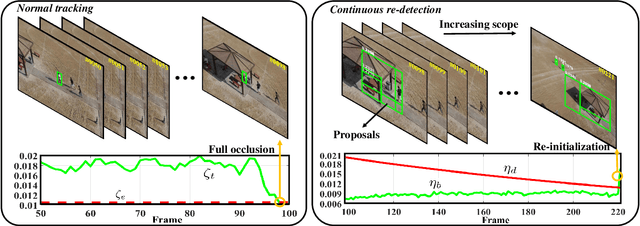
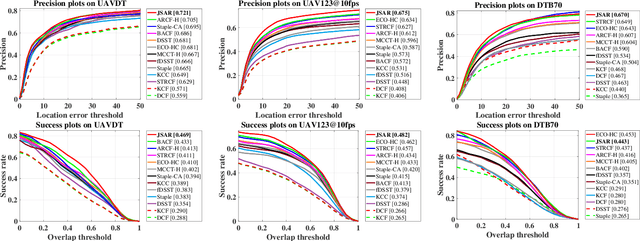

Current unmanned aerial vehicle (UAV) visual tracking algorithms are primarily limited with respect to: (i) the kind of size variation they can deal with, (ii) the implementation speed which hardly meets the real-time requirement. In this work, a real-time UAV tracking algorithm with powerful size estimation ability is proposed. Specifically, the overall tracking task is allocated to two 2D filters: (i) translation filter for location prediction in the space domain, (ii) size filter for scale and aspect ratio optimization in the size domain. Besides, an efficient two-stage re-detection strategy is introduced for long-term UAV tracking tasks. Large-scale experiments on four UAV benchmarks demonstrate the superiority of the presented method which has computation feasibility on a low-cost CPU.