 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Occlusion-robust Deformable Object Tracking without Physics Simulation
Jan 04, 2021



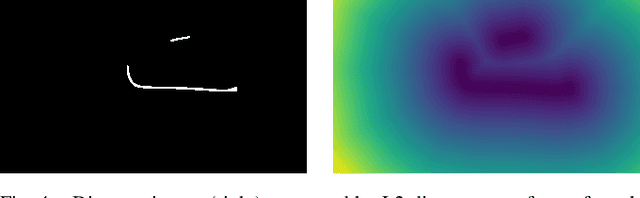
Estimating the state of a deformable object is crucial for robotic manipulation, yet accurate tracking is challenging when the object is partially-occluded. To address this problem, we propose an occlusion-robust RGBD sequence tracking framework based on Coherent Point Drift (CPD). To mitigate the effects of occlusion, our method 1) Uses a combination of locally linear embedding and constrained optimization to regularize the output of CPD, thus enforcing topological consistency when occlusions create disconnected pieces of the object; 2) Reasons about the free-space visible by an RGBD sensor to better estimate the prior on point location and to detect tracking failures during occlusion; and 3) Uses shape descriptors to find the most relevant previous state of the object to use for tracking after a severe occlusion. Our method does not rely on physics simulation or a physical model of the object, which can be difficult to obtain in unstructured environments. Despite having no physical model, our experiments demonstrate that our method achieves improved accuracy in the presence of occlusion as compared to a physics-based CPD method while maintaining adequate run-time.
Modeling Heterogeneous Statistical Patterns in High-dimensional Data by Adversarial Distributions: An Unsupervised Generative Framework
Dec 15, 2020
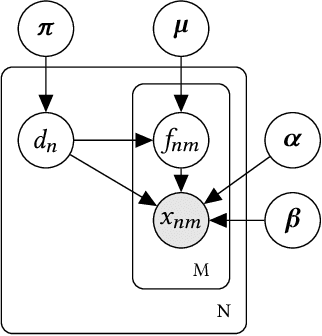

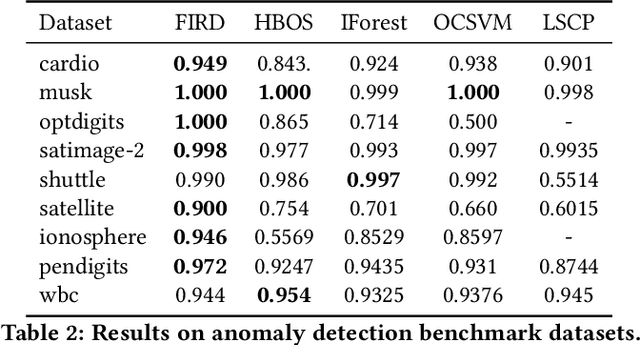
Since the label collecting is prohibitive and time-consuming, unsupervised methods are preferred in applications such as fraud detection. Meanwhile, such applications usually require modeling the intrinsic clusters in high-dimensional data, which usually displays heterogeneous statistical patterns as the patterns of different clusters may appear in different dimensions. Existing methods propose to model the data clusters on selected dimensions, yet globally omitting any dimension may damage the pattern of certain clusters. To address the above issues, we propose a novel unsupervised generative framework called FIRD, which utilizes adversarial distributions to fit and disentangle the heterogeneous statistical patterns. When applying to discrete spaces, FIRD effectively distinguishes the synchronized fraudsters from normal users. Besides, FIRD also provides superior performance on anomaly detection datasets compared with SOTA anomaly detection methods (over 5% average AUC improvement). The significant experiment results on various datasets verify that the proposed method can better model the heterogeneous statistical patterns in high-dimensional data and benefit downstream applications.
Black-Box Control for Linear Dynamical Systems
Jul 13, 2020We consider the problem of controlling an unknown linear time-invariant dynamical system from a single chain of black-box interactions, and with no access to resets or offline simulation. Under the assumption that the system is controllable, we give the first efficient algorithm that is capable of attaining sublinear regret in a single trajectory under the setting of online nonstochastic control. We give finite-time regret bound of our algorithm, as well as a nearly-matching lower bound that shows this regret to be almost best-attainable by any algorithm.
AsyncTaichi: Whole-Program Optimizations for Megakernel Sparse Computation and Differentiable Programming
Dec 15, 2020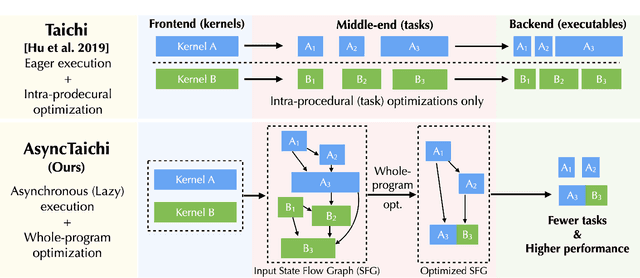
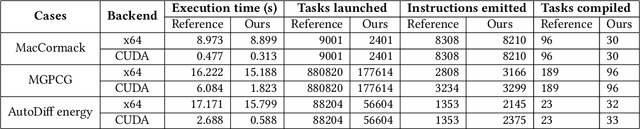
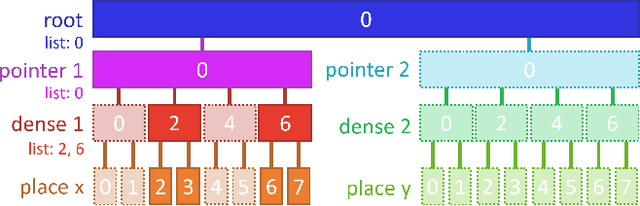
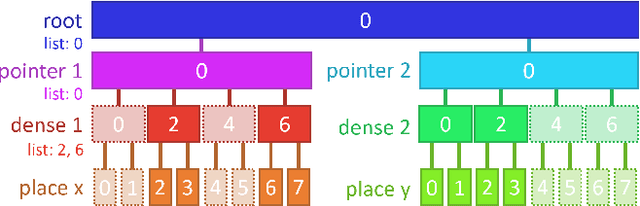
We present a whole-program optimization framework for the Taichi programming language. As an imperative language tailored for sparse and differentiable computation, Taichi's unique computational patterns lead to attractive optimization opportunities that do not present in other compiler or runtime systems. For example, to support iteration over sparse voxel grids, excessive list generation tasks are often inserted. By analyzing sparse computation programs at a higher level, our optimizer is able to remove the majority of unnecessary list generation tasks. To provide maximum programming flexibility, our optimization system conducts on-the-fly optimization of the whole computational graph consisting of Taichi kernels. The optimized Taichi kernels are then just-in-time compiled in parallel, and dispatched to parallel devices such as multithreaded CPU and massively parallel GPUs. Without any code modification on Taichi programs, our new system leads to $3.07 - 3.90\times$ fewer kernel launches and $1.73 - 2.76\times$ speed up on our benchmarks including sparse-grid physical simulation and differentiable programming.
Incremental Data-driven Optimization of Complex Systems in Nonstationary Environments
Dec 25, 2020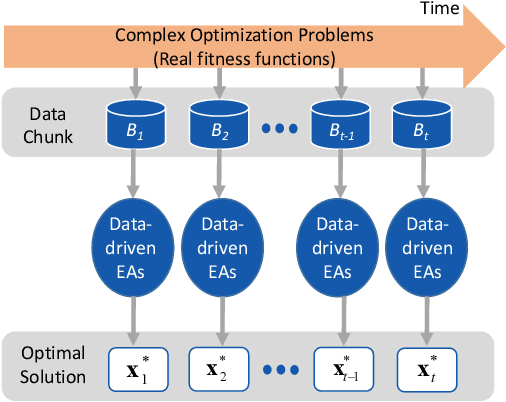
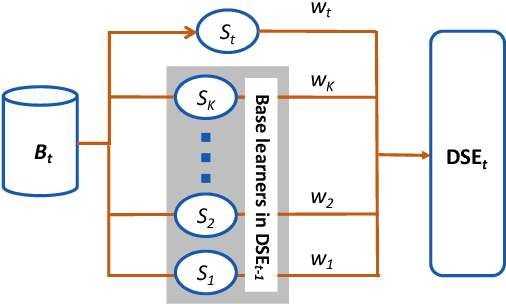
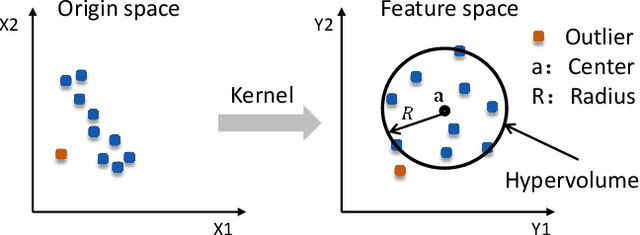
Existing work on data-driven optimization focuses on problems in static environments, but little attention has been paid to problems in dynamic environments. This paper proposes a data-driven optimization algorithm to deal with the challenges presented by the dynamic environments. First, a data stream ensemble learning method is adopted to train the surrogates so that each base learner of the ensemble learns the time-varying objective function in the previous environments. After that, a multi-task evolutionary algorithm is employed to simultaneously optimize the problems in the past environments assisted by the ensemble surrogate. This way, the optimization tasks in the previous environments can be used to accelerate the tracking of the optimum in the current environment. Since the real fitness function is not available for verifying the surrogates in offline data-driven optimization, a support vector domain description that was designed for outlier detection is introduced to select a reliable solution. Empirical results on six dynamic optimization benchmark problems demonstrate the effectiveness of the proposed algorithm compared with four state-of-the-art data-driven optimization algorithms.
Class-incremental Learning with Rectified Feature-Graph Preservation
Dec 15, 2020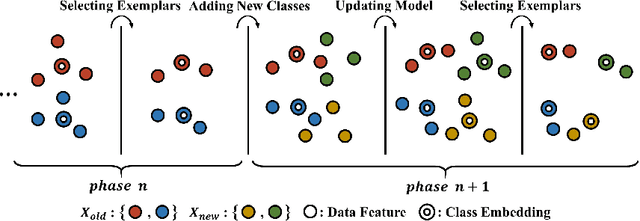
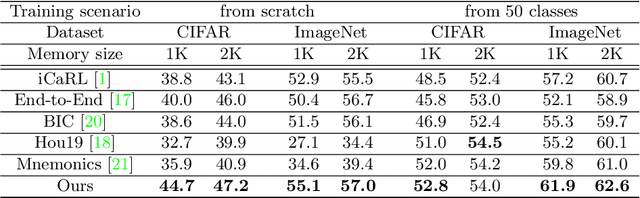
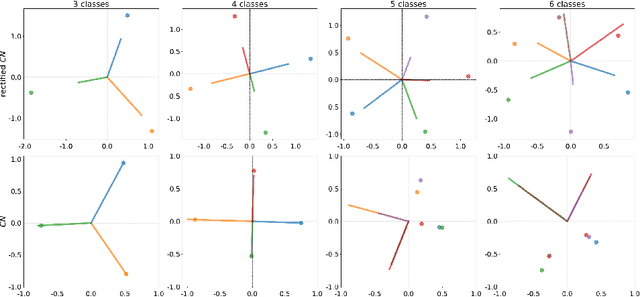
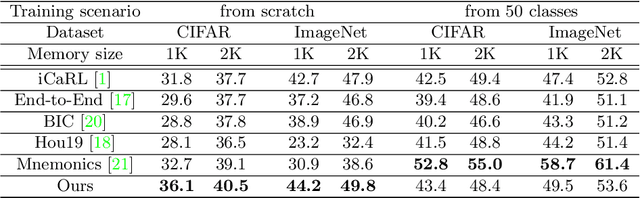
In this paper, we address the problem of distillation-based class-incremental learning with a single head. A central theme of this task is to learn new classes that arrive in sequential phases over time while keeping the model's capability of recognizing seen classes with only limited memory for preserving seen data samples. Many regularization strategies have been proposed to mitigate the phenomenon of catastrophic forgetting. To understand better the essence of these regularizations, we introduce a feature-graph preservation perspective. Insights into their merits and faults motivate our weighted-Euclidean regularization for old knowledge preservation. We further propose rectified cosine normalization and show how it can work with binary cross-entropy to increase class separation for effective learning of new classes. Experimental results on both CIFAR-100 and ImageNet datasets demonstrate that our method outperforms the state-of-the-art approaches in reducing classification error, easing catastrophic forgetting, and encouraging evenly balanced accuracy over different classes. Our project page is at : https://github.com/yhchen12101/FGP-ICL.
Achieving the time of $1$-NN, but the accuracy of $k$-NN
Dec 22, 2017
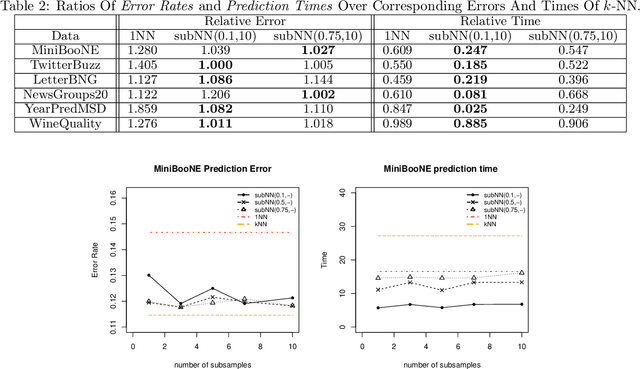
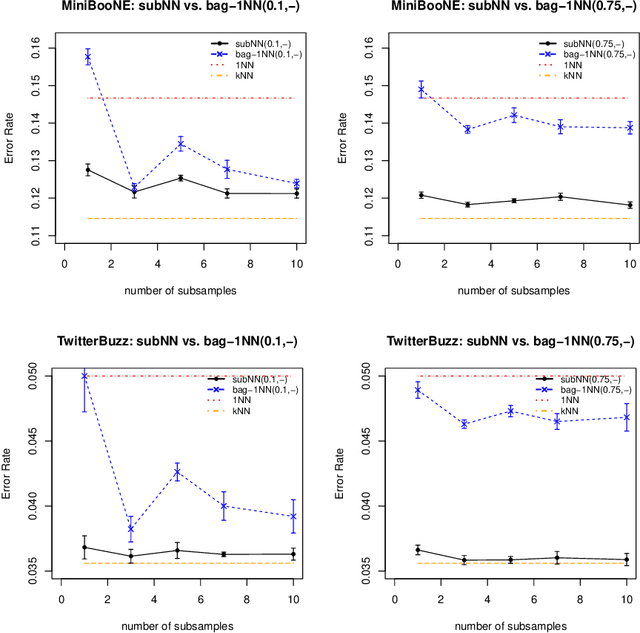
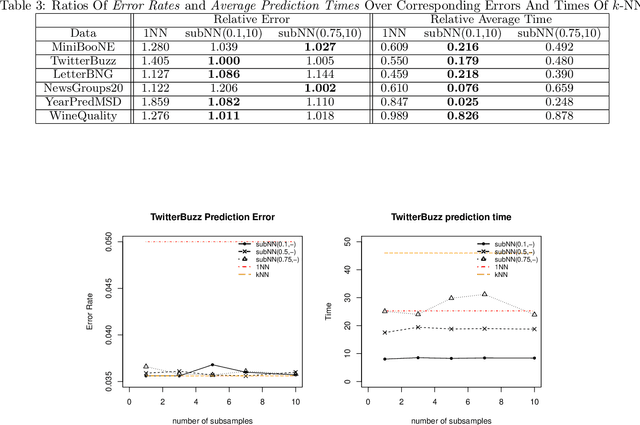
We propose a simple approach which, given distributed computing resources, can nearly achieve the accuracy of $k$-NN prediction, while matching (or improving) the faster prediction time of $1$-NN. The approach consists of aggregating denoised $1$-NN predictors over a small number of distributed subsamples. We show, both theoretically and experimentally, that small subsample sizes suffice to attain similar performance as $k$-NN, without sacrificing the computational efficiency of $1$-NN.
Scenic: A Language for Scenario Specification and Data Generation
Oct 13, 2020
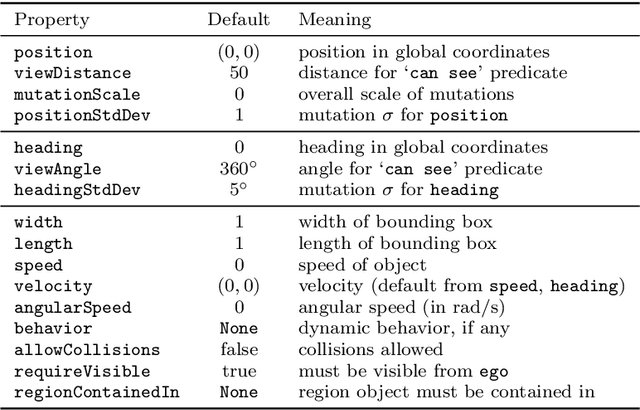
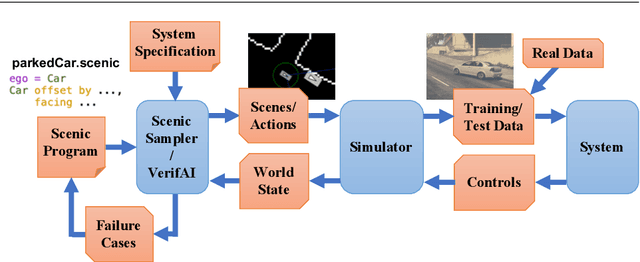
We propose a new probabilistic programming language for the design and analysis of cyber-physical systems, especially those based on machine learning. Specifically, we consider the problems of training a system to be robust to rare events, testing its performance under different conditions, and debugging failures. We show how a probabilistic programming language can help address these problems by specifying distributions encoding interesting types of inputs, then sampling these to generate specialized training and test data. More generally, such languages can be used to write environment models, an essential prerequisite to any formal analysis. In this paper, we focus on systems like autonomous cars and robots, whose environment at any point in time is a 'scene', a configuration of physical objects and agents. We design a domain-specific language, Scenic, for describing scenarios that are distributions over scenes and the behaviors of their agents over time. As a probabilistic programming language, Scenic allows assigning distributions to features of the scene, as well as declaratively imposing hard and soft constraints over the scene. We develop specialized techniques for sampling from the resulting distribution, taking advantage of the structure provided by Scenic's domain-specific syntax. Finally, we apply Scenic in a case study on a convolutional neural network designed to detect cars in road images, improving its performance beyond that achieved by state-of-the-art synthetic data generation methods.
CNN Application in Detection of Privileged Documents in Legal Document Review
Feb 09, 2021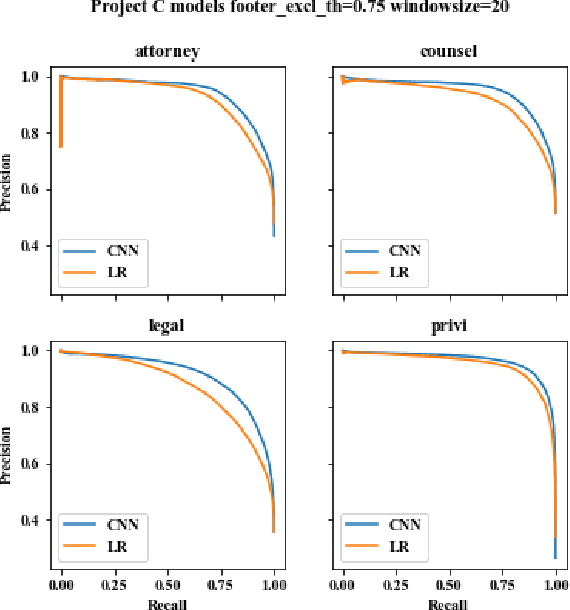
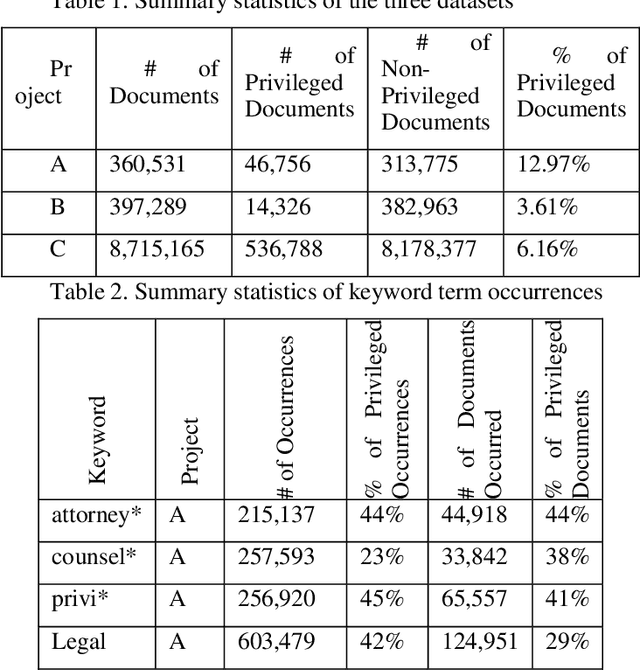
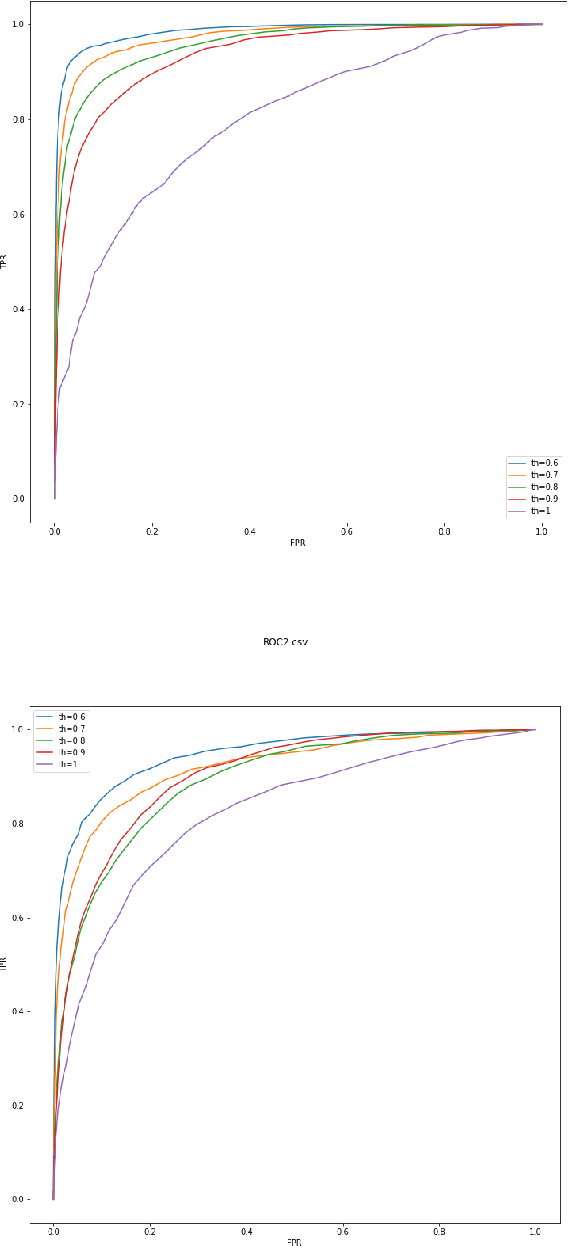
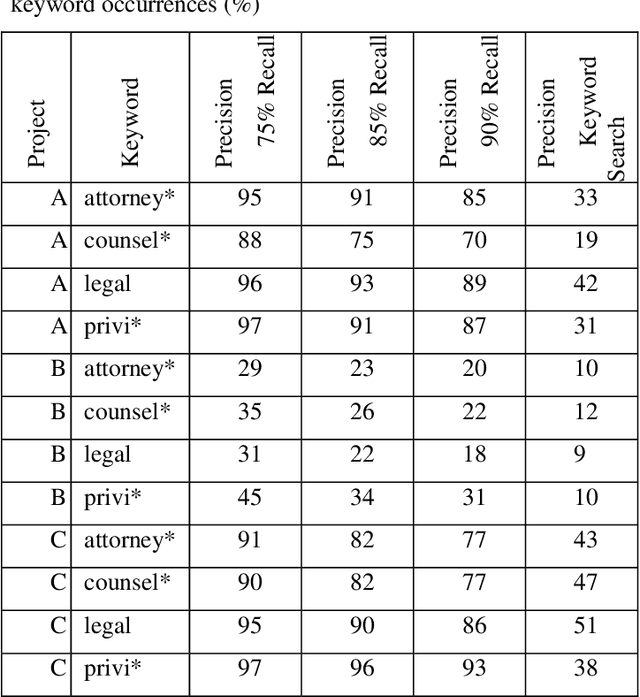
Protecting privileged communications and data from disclosure is paramount for legal teams. Legal advice, such as attorney-client communications or litigation strategy are typically exempt from disclosure in litigations or regulatory events and are vital to the attorney-client relationship. To protect this information from disclosure, companies and outside counsel often review vast amounts of documents to determine those that contain privileged material. This process is extremely costly and time consuming. As data volumes increase, legal counsel normally employs methods to reduce the number of documents requiring review while balancing the need to ensure the protection of privileged information. Keyword searching is relied upon as a method to target privileged information and reduce document review populations. Keyword searches are effective at casting a wide net but often return overly inclusive results - most of which do not contain privileged information. To overcome the weaknesses of keyword searching, legal teams increasingly are using machine learning techniques to target privileged information. In these studies, classic text classification techniques are applied to build classification models to identify privileged documents. In this paper, the authors propose a different method by applying machine learning / convolutional neural network techniques (CNN) to identify privileged documents. Our proposed method combines keyword searching with CNN. For each keyword term, a CNN model is created using the context of the occurrences of the keyword. In addition, a method was proposed to select reliable privileged (positive) training keyword occurrences from labeled positive training documents. Extensive experiments were conducted, and the results show that the proposed methods can significantly reduce false positives while still capturing most of the true positives.
Spinal Codes Optimization: Error Probability Analysis and Transmission Scheme Design
Jan 20, 2021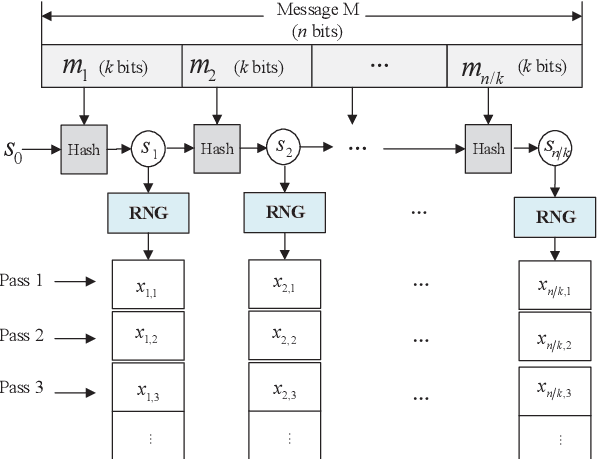

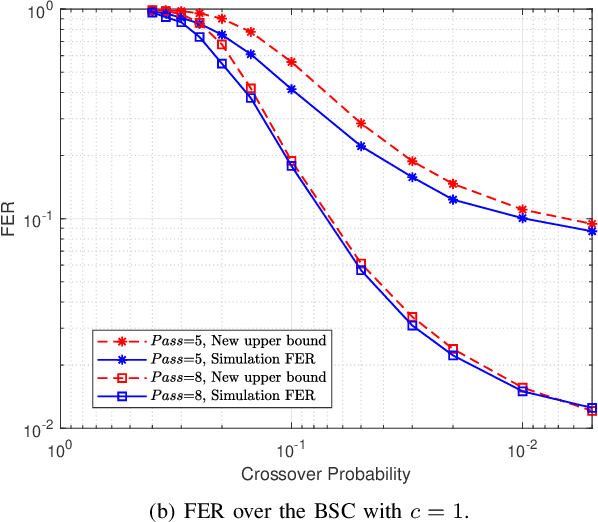
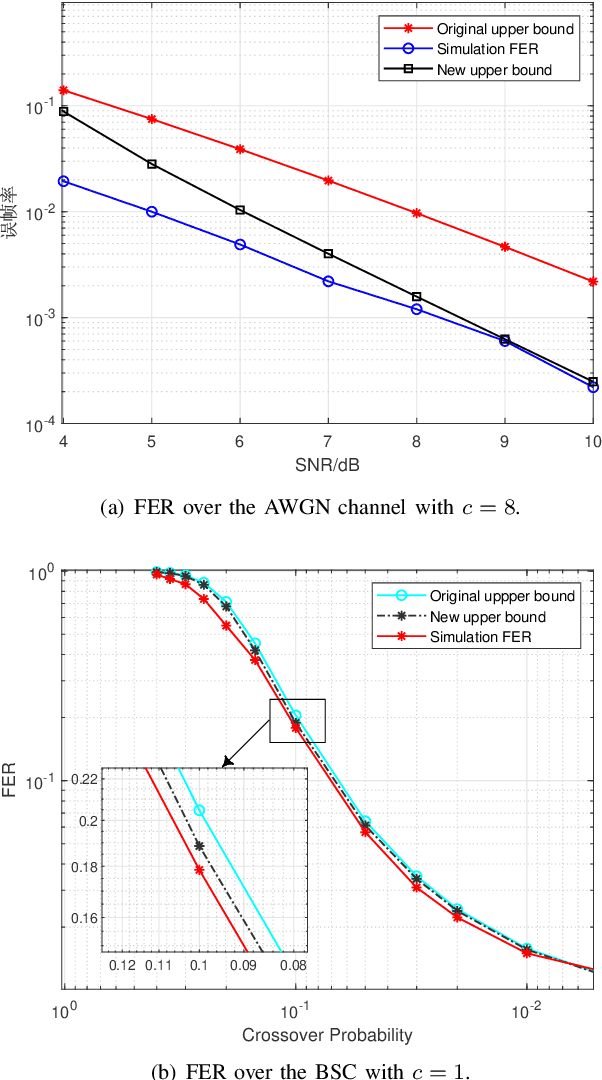
Spinal codes are known to be capacity achieving over both the additive white Gaussian noise (AWGN) channel and the binary symmetric channel (BSC). Over wireless channels, Spinal encoding can also be regarded as an adaptive-coded-modulation (ACM) technique due to its rateless property, which fits it with mobile communications. Due to lack of tight analysis on error probability of Spinal codes, optimization of transmission scheme using Spinal codes has not been fully explored. In this work, we firstly derive new tight upper bounds of the frame error rate (FER) of Spinal codes for both the AWGN channel and the BSC in the finite block-length (FBL) regime. Based on the derived upper bounds, we then design the optimal transmission scheme. Specifically, we formulate a rate maximization problem as a nonlinear integer programming problem, and solve it by an iterative algorithm for its dual problem. As the optimal solution exhibits an incremental-tail-transmission pattern, we propose an improved transmission scheme for Spinal codes. Moreover, we develop a bubble decoding with memory (BD-M) algorithm to reduce the decoding time complexity without loss of rate performance. The improved transmission scheme at the transmitter and the BD-M algorithm at the receiver jointly constitute an "encoding-decoding" system of Spinal codes. Simulation results demonstrate that it can improve both the rate performance and the decoding throughput of Spinal codes.