 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TIME: A Transparent, Interpretable, Model-Adaptive and Explainable Neural Network for Dynamic Physical Processes
Mar 05, 2020
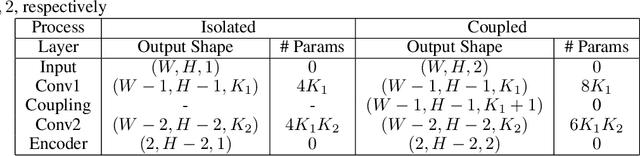

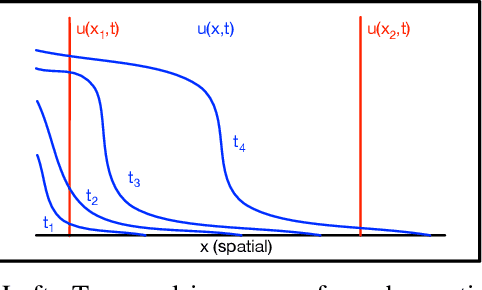
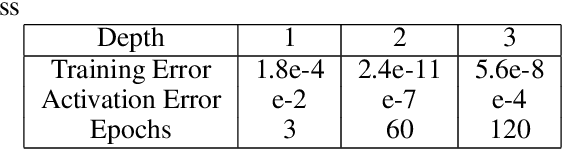
Partial Differential Equations are infinite dimensional encoded representations of physical processes. However, imbibing multiple observation data towards a coupled representation presents significant challenges. We present a fully convolutional architecture that captures the invariant structure of the domain to reconstruct the observable system. The proposed architecture is significantly low-weight compared to other networks for such problems. Our intent is to learn coupled dynamic processes interpreted as deviations from true kernels representing isolated processes for model-adaptivity. Experimental analysis shows that our architecture is robust and transparent in capturing process kernels and system anomalies. We also show that high weights representation is not only redundant but also impacts network interpretability. Our design is guided by domain knowledge, with isolated process representations serving as ground truths for verification. These allow us to identify redundant kernels and their manifestations in activation maps to guide better designs that are both interpretable and explainable unlike traditional deep-nets.
S++: A Fast and Deployable Secure-Computation Framework for Privacy-Preserving Neural Network Training
Jan 28, 2021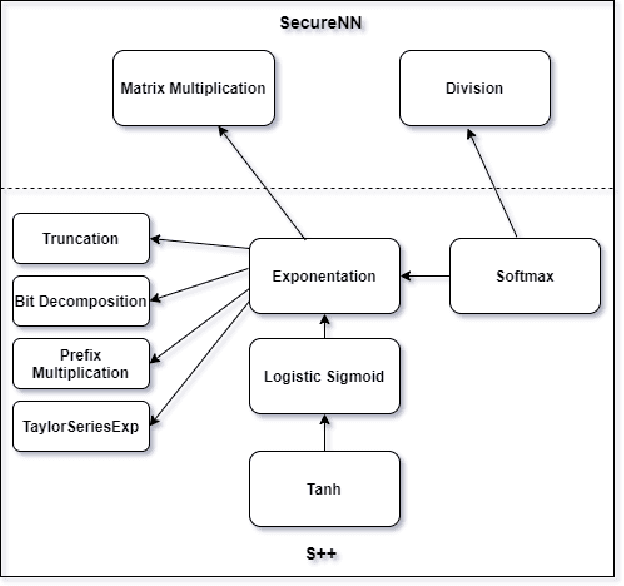
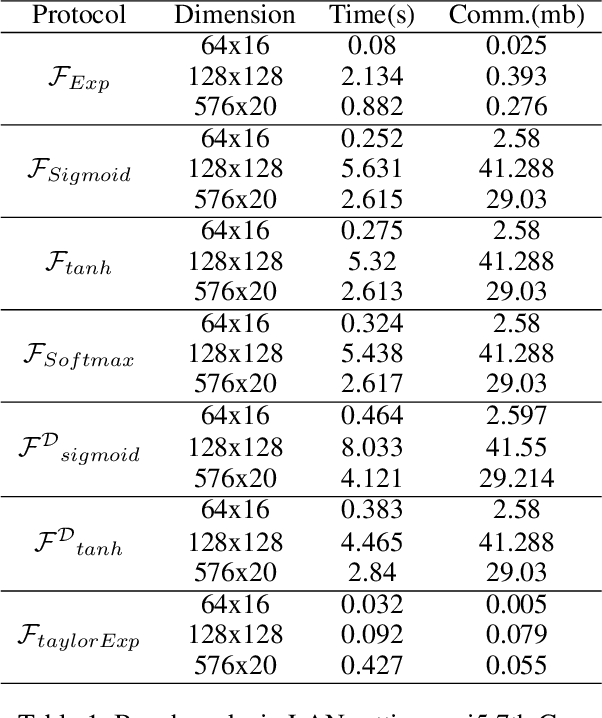
We introduce S++, a simple, robust, and deployable framework for training a neural network (NN) using private data from multiple sources, using secret-shared secure function evaluation. In short, consider a virtual third party to whom every data-holder sends their inputs, and which computes the neural network: in our case, this virtual third party is actually a set of servers which individually learn nothing, even with a malicious (but non-colluding) adversary. Previous work in this area has been limited to just one specific activation function: ReLU, rendering the approach impractical for many use-cases. For the first time, we provide fast and verifiable protocols for all common activation functions and optimize them for running in a secret-shared manner. The ability to quickly, verifiably, and robustly compute exponentiation, softmax, sigmoid, etc., allows us to use previously written NNs without modification, vastly reducing developer effort and complexity of code. In recent times, ReLU has been found to converge much faster and be more computationally efficient as compared to non-linear functions like sigmoid or tanh. However, we argue that it would be remiss not to extend the mechanism to non-linear functions such as the logistic sigmoid, tanh, and softmax that are fundamental due to their ability to express outputs as probabilities and their universal approximation property. Their contribution in RNNs and a few recent advancements also makes them more relevant.
Deep Attention-based Representation Learning for Heart Sound Classification
Jan 13, 2021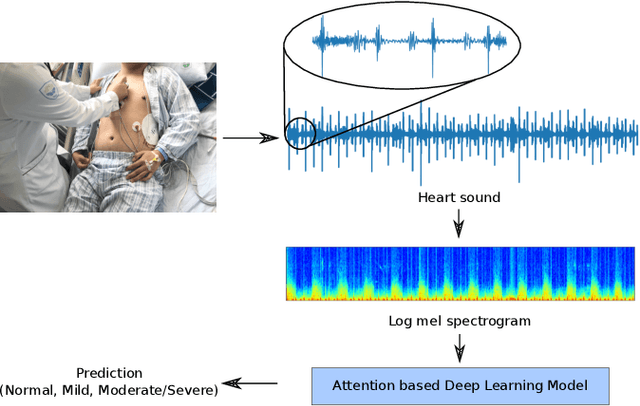
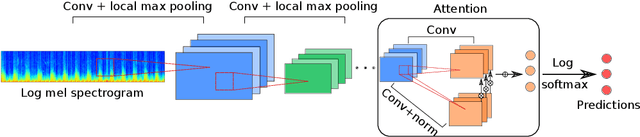

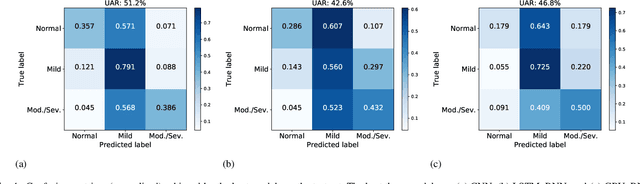
Cardiovascular diseases are the leading cause of deaths and severely threaten human health in daily life. On the one hand, there have been dramatically increasing demands from both the clinical practice and the smart home application for monitoring the heart status of subjects suffering from chronic cardiovascular diseases. On the other hand, experienced physicians who can perform an efficient auscultation are still lacking in terms of number. Automatic heart sound classification leveraging the power of advanced signal processing and machine learning technologies has shown encouraging results. Nevertheless, human hand-crafted features are expensive and time-consuming. To this end, we propose a novel deep representation learning method with an attention mechanism for heart sound classification. In this paradigm, high-level representations are learnt automatically from the recorded heart sound data. Particularly, a global attention pooling layer improves the performance of the learnt representations by estimating the contribution of each unit in feature maps. The Heart Sounds Shenzhen (HSS) corpus (170 subjects involved) is used to validate the proposed method. Experimental results validate that, our approach can achieve an unweighted average recall of 51.2% for classifying three categories of heart sounds, i. e., normal, mild, and moderate/severe annotated by cardiologists with the help of Echocardiography.
Recovery of underdrawings and ghost-paintings via style transfer by deep convolutional neural networks: A digital tool for art scholars
Jan 04, 2021

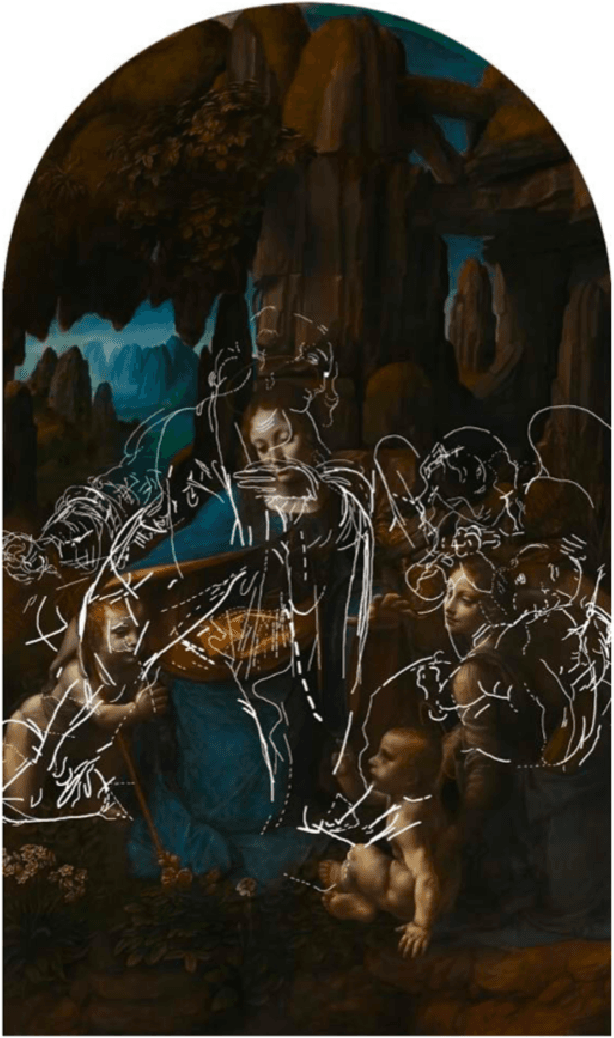

We describe the application of convolutional neural network style transfer to the problem of improved visualization of underdrawings and ghost-paintings in fine art oil paintings. Such underdrawings and hidden paintings are typically revealed by x-ray or infrared techniques which yield images that are grayscale, and thus devoid of color and full style information. Past methods for inferring color in underdrawings have been based on physical x-ray fluorescence spectral imaging of pigments in ghost-paintings and are thus expensive, time consuming, and require equipment not available in most conservation studios. Our algorithmic methods do not need such expensive physical imaging devices. Our proof-of-concept system, applied to works by Pablo Picasso and Leonardo, reveal colors and designs that respect the natural segmentation in the ghost-painting. We believe the computed images provide insight into the artist and associated oeuvre not available by other means. Our results strongly suggest that future applications based on larger corpora of paintings for training will display color schemes and designs that even more closely resemble works of the artist. For these reasons refinements to our methods should find wide use in art conservation, connoisseurship, and art analysis.
Scaling down Deep Learning
Dec 04, 2020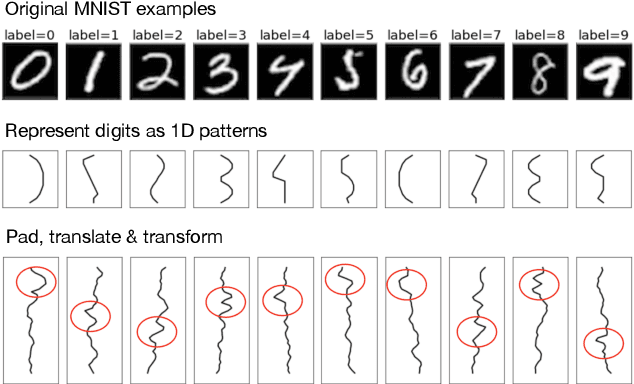

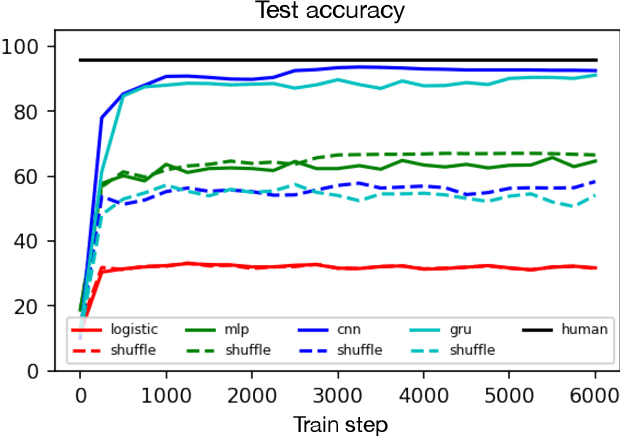
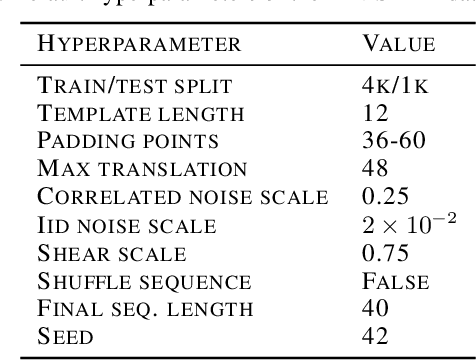
Though deep learning models have taken on commercial and political relevance, many aspects of their training and operation remain poorly understood. This has sparked interest in "science of deep learning" projects, many of which are run at scale and require enormous amounts of time, money, and electricity. But how much of this research really needs to occur at scale? In this paper, we introduce MNIST-1D: a minimalist, low-memory, and low-compute alternative to classic deep learning benchmarks. The training examples are 20 times smaller than MNIST examples yet they differentiate more clearly between linear, nonlinear, and convolutional models which attain 32, 68, and 94% accuracy respectively (these models obtain 94, 99+, and 99+% on MNIST). Then we present example use cases which include measuring the spatial inductive biases of lottery tickets, observing deep double descent, and metalearning an activation function.
Time-Contrastive Networks: Self-Supervised Learning from Video
Mar 20, 2018

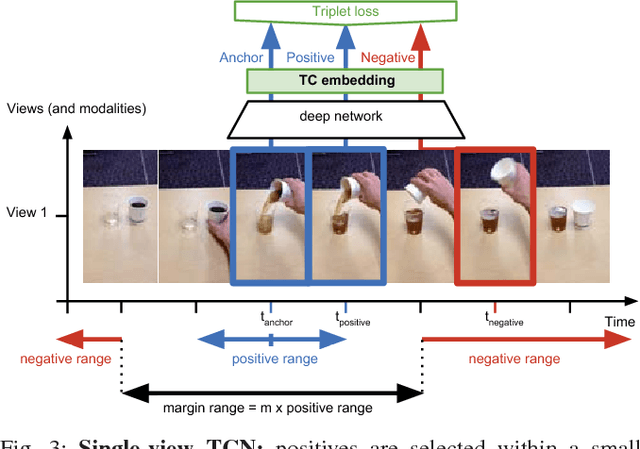
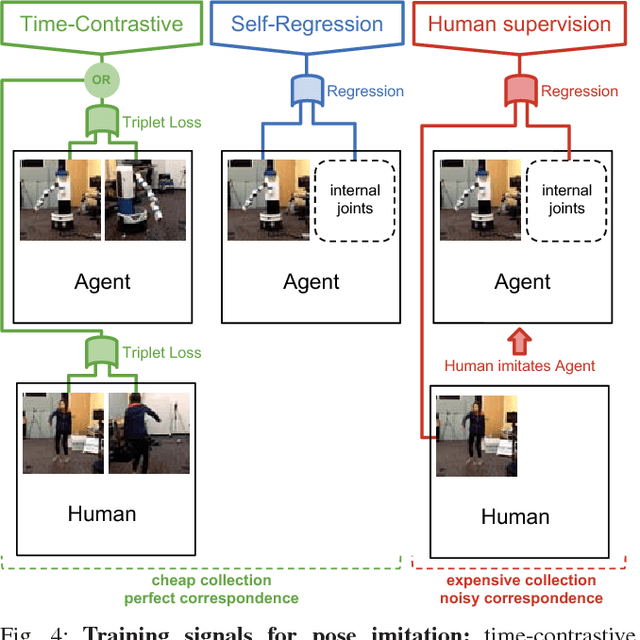
We propose a self-supervised approach for learning representations and robotic behaviors entirely from unlabeled videos recorded from multiple viewpoints, and study how this representation can be used in two robotic imitation settings: imitating object interactions from videos of humans, and imitating human poses. Imitation of human behavior requires a viewpoint-invariant representation that captures the relationships between end-effectors (hands or robot grippers) and the environment, object attributes, and body pose. We train our representations using a metric learning loss, where multiple simultaneous viewpoints of the same observation are attracted in the embedding space, while being repelled from temporal neighbors which are often visually similar but functionally different. In other words, the model simultaneously learns to recognize what is common between different-looking images, and what is different between similar-looking images. This signal causes our model to discover attributes that do not change across viewpoint, but do change across time, while ignoring nuisance variables such as occlusions, motion blur, lighting and background. We demonstrate that this representation can be used by a robot to directly mimic human poses without an explicit correspondence, and that it can be used as a reward function within a reinforcement learning algorithm. While representations are learned from an unlabeled collection of task-related videos, robot behaviors such as pouring are learned by watching a single 3rd-person demonstration by a human. Reward functions obtained by following the human demonstrations under the learned representation enable efficient reinforcement learning that is practical for real-world robotic systems. Video results, open-source code and dataset are available at https://sermanet.github.io/imitate
Trajectory Representation and Landmark Projection for Continuous-Time Structure from Motion
May 07, 2018

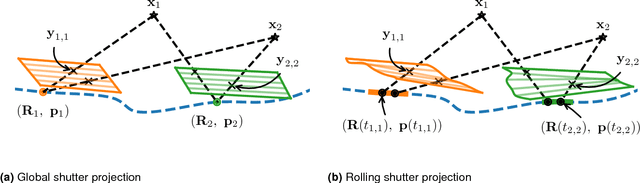
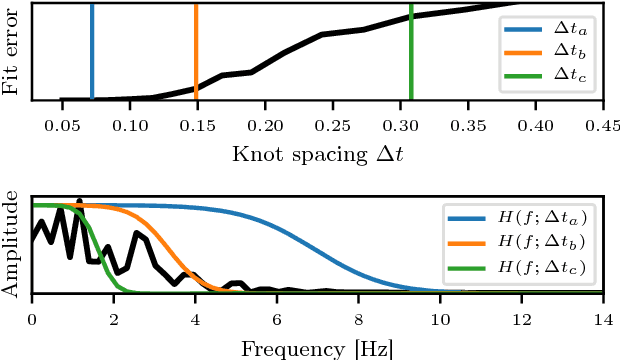
This paper revisits the problem of continuous-time structure from motion, and introduces a number of extensions that improve convergence and efficiency. The formulation with a $\mathcal{C}^2$-continuous spline for the trajectory naturally incorporates inertial measurements, as derivatives of the sought trajectory. We analyse the behaviour of split interpolation on $\mathbb{SO}(3)$ and on $\mathbb{R}^3$, and a joint interpolation on $\mathbb{SE}(3)$, and show that the latter implicitly couples the direction of translation and rotation. Such an assumption can make good sense for a camera mounted on a robot arm, but not for hand-held or body-mounted cameras. Our experiments show that split interpolation on $\mathbb{SO}(3)$ and on $\mathbb{R}^3$ is preferable over $\mathbb{SE}(3)$ interpolation in all tested cases. Finally, we investigate the problem of landmark reprojection on rolling shutter cameras, and show that the tested reprojection methods give similar quality, while their computational load varies by a factor of 2.
Slimmable Generative Adversarial Networks
Dec 10, 2020
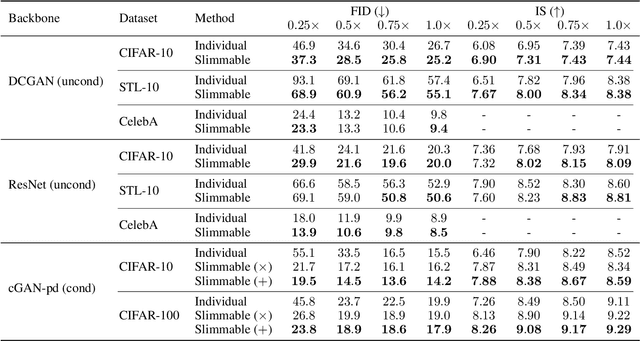


Generative adversarial networks (GANs) have achieved remarkable progress in recent years, but the continuously growing scale of models makes them challenging to deploy widely in practical applications. In particular, for real-time tasks, different devices require models of different sizes due to varying computing power. In this paper, we introduce slimmable GANs (SlimGANs), which can flexibly switch the width (channels of layers) of the generator to accommodate various quality-efficiency trade-offs at runtime. Specifically, we leverage multiple partial parameter-shared discriminators to train the slimmable generator. To facilitate the \textit{consistency} between generators of different widths, we present a stepwise inplace distillation technique that encourages narrow generators to learn from wide ones. As for class-conditional generation, we propose a sliceable conditional batch normalization that incorporates the label information into different widths. Our methods are validated, both quantitatively and qualitatively, by extensive experiments and a detailed ablation study.
A Regret Analysis of Bilateral Trade
Feb 16, 2021
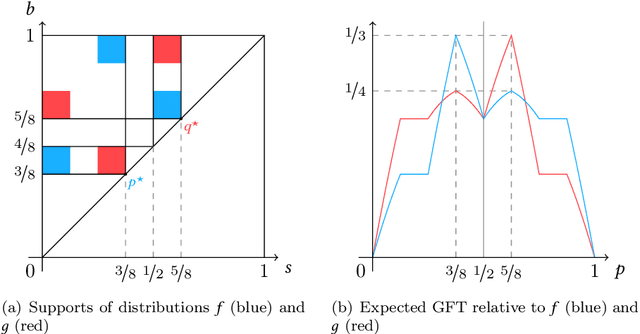
Bilateral trade, a fundamental topic in economics, models the problem of intermediating between two strategic agents, a seller and a buyer, willing to trade a good for which they hold private valuations. Despite the simplicity of this problem, a classical result by Myerson and Satterthwaite (1983) affirms the impossibility of designing a mechanism which is simultaneously efficient, incentive compatible, individually rational, and budget balanced. This impossibility result fostered an intense investigation of meaningful trade-offs between these desired properties. Much work has focused on approximately efficient fixed-price mechanisms, i.e., Blumrosen and Dobzinski (2014; 2016), Colini-Baldeschi et al. (2016), which have been shown to fully characterize strong budget balanced and ex-post individually rational direct revelation mechanisms. All these results, however, either assume some knowledge on the priors of the seller/buyer valuations, or a black box access to some samples of the distributions, as in D{\"u}tting et al. (2021). In this paper, we cast for the first time the bilateral trade problem in a regret minimization framework over rounds of seller/buyer interactions, with no prior knowledge on the private seller/buyer valuations. Our main contribution is a complete characterization of the regret regimes for fixed-price mechanisms with different models of feedback and private valuations, using as benchmark the best fixed price in hindsight. More precisely, we prove the following bounds on the regret: $\bullet$ $\widetilde{\Theta}(\sqrt{T})$ for full-feedback (i.e., direct revelation mechanisms); $\bullet$ $\widetilde{\Theta}(T^{2/3})$ for realistic feedback (i.e., posted-price mechanisms) and independent seller/buyer valuations with bounded densities; $\bullet$ $\Theta(T)$ for realistic feedback and seller/buyer valuations with bounded densities; $\bullet$ $\Theta(T)$ for realistic feedback and independent seller/buyer valuations; $\bullet$ $\Theta(T)$ for the adversarial setting.
Learning Quantities of Interest from Dynamical Systems for Observation-Consistent Inversion
Sep 15, 2020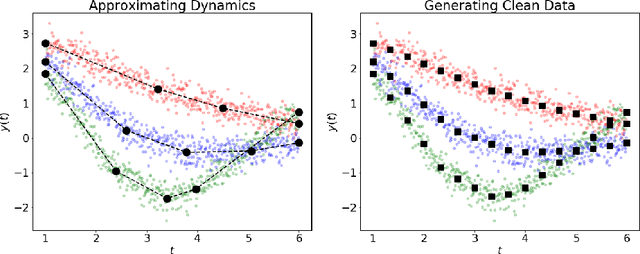

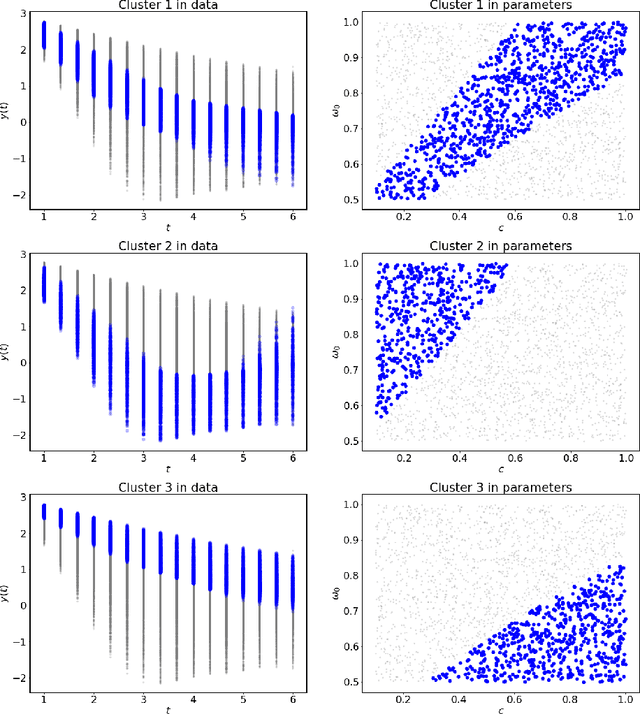

Dynamical systems arise in a wide variety of mathematical models from science and engineering. A common challenge is to quantify uncertainties on model inputs (parameters) that correspond to a quantitative characterization of uncertainties on observable Quantities of Interest (QoI). To this end, we consider a stochastic inverse problem (SIP) with a solution described by a pullback probability measure. We call this an observation-consistent solution, as its subsequent push-forward through the QoI map matches the observed probability distribution on model outputs. A distinction is made between QoI useful for solving the SIP and arbitrary model output data. In dynamical systems, model output data are often given as a series of state variable responses recorded over a particular time window. Consequently, the dimension of output data can easily exceed $\mathcal{O}(1E4)$ or more due to the frequency of observations, and the correct choice or construction of a QoI from this data is not self-evident. We present a new framework, Learning Uncertain Quantities (LUQ), that facilitates the tractable solution of SIPs for dynamical systems. Given ensembles of predicted (simulated) time series and (noisy) observed data, LUQ provides routines for filtering data, unsupervised learning of the underlying dynamics, classifying observations, and feature extraction to learn the QoI map. Subsequently, time series data are transformed into samples of the underlying predicted and observed distributions associated with the QoI so that solutions to the SIP are computable. Following the introduction and demonstration of LUQ, numerical results from several SIPs are presented for a variety of dynamical systems arising in the life and physical sciences. For scientific reproducibility, we provide links to our Python implementation of LUQ and to all data and scripts required to reproduce the results in this manuscript.