 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Attention-based Representation Learning for Heart Sound Classification
Jan 13, 2021
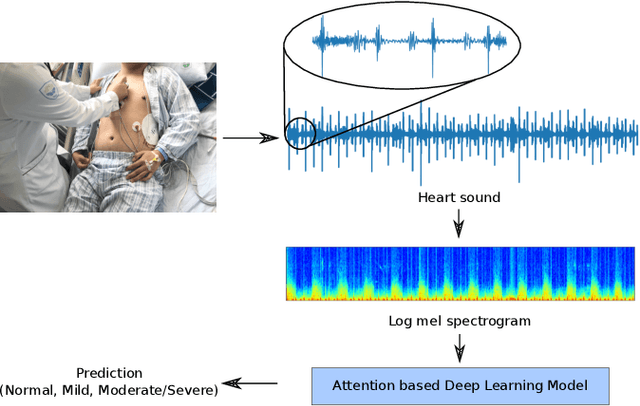
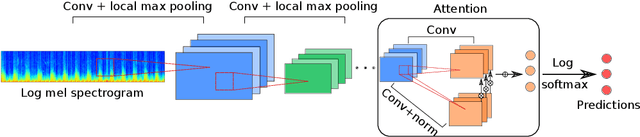

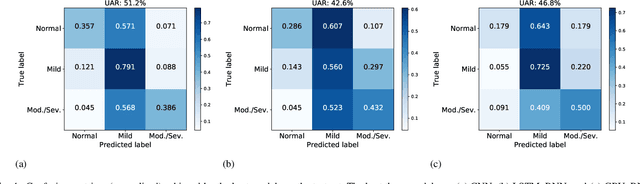
Cardiovascular diseases are the leading cause of deaths and severely threaten human health in daily life. On the one hand, there have been dramatically increasing demands from both the clinical practice and the smart home application for monitoring the heart status of subjects suffering from chronic cardiovascular diseases. On the other hand, experienced physicians who can perform an efficient auscultation are still lacking in terms of number. Automatic heart sound classification leveraging the power of advanced signal processing and machine learning technologies has shown encouraging results. Nevertheless, human hand-crafted features are expensive and time-consuming. To this end, we propose a novel deep representation learning method with an attention mechanism for heart sound classification. In this paradigm, high-level representations are learnt automatically from the recorded heart sound data. Particularly, a global attention pooling layer improves the performance of the learnt representations by estimating the contribution of each unit in feature maps. The Heart Sounds Shenzhen (HSS) corpus (170 subjects involved) is used to validate the proposed method. Experimental results validate that, our approach can achieve an unweighted average recall of 51.2% for classifying three categories of heart sounds, i. e., normal, mild, and moderate/severe annotated by cardiologists with the help of Echocardiography.
A Regret Analysis of Bilateral Trade
Feb 16, 2021
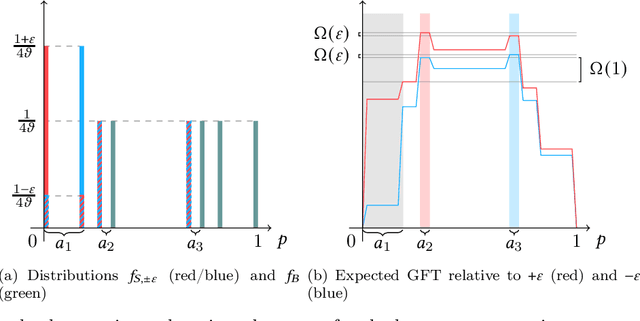
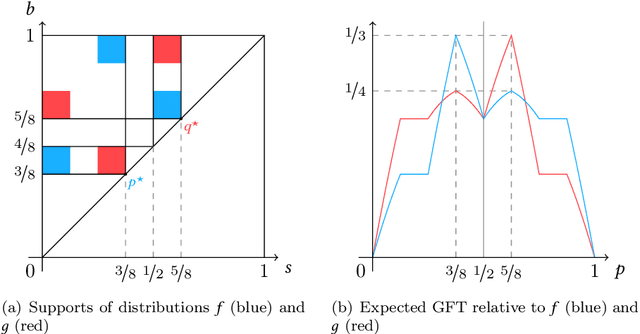
Bilateral trade, a fundamental topic in economics, models the problem of intermediating between two strategic agents, a seller and a buyer, willing to trade a good for which they hold private valuations. Despite the simplicity of this problem, a classical result by Myerson and Satterthwaite (1983) affirms the impossibility of designing a mechanism which is simultaneously efficient, incentive compatible, individually rational, and budget balanced. This impossibility result fostered an intense investigation of meaningful trade-offs between these desired properties. Much work has focused on approximately efficient fixed-price mechanisms, i.e., Blumrosen and Dobzinski (2014; 2016), Colini-Baldeschi et al. (2016), which have been shown to fully characterize strong budget balanced and ex-post individually rational direct revelation mechanisms. All these results, however, either assume some knowledge on the priors of the seller/buyer valuations, or a black box access to some samples of the distributions, as in D{\"u}tting et al. (2021). In this paper, we cast for the first time the bilateral trade problem in a regret minimization framework over rounds of seller/buyer interactions, with no prior knowledge on the private seller/buyer valuations. Our main contribution is a complete characterization of the regret regimes for fixed-price mechanisms with different models of feedback and private valuations, using as benchmark the best fixed price in hindsight. More precisely, we prove the following bounds on the regret: $\bullet$ $\widetilde{\Theta}(\sqrt{T})$ for full-feedback (i.e., direct revelation mechanisms); $\bullet$ $\widetilde{\Theta}(T^{2/3})$ for realistic feedback (i.e., posted-price mechanisms) and independent seller/buyer valuations with bounded densities; $\bullet$ $\Theta(T)$ for realistic feedback and seller/buyer valuations with bounded densities; $\bullet$ $\Theta(T)$ for realistic feedback and independent seller/buyer valuations; $\bullet$ $\Theta(T)$ for the adversarial setting.
Multimodal Memorability: Modeling Effects of Semantics and Decay on Video Memorability
Sep 05, 2020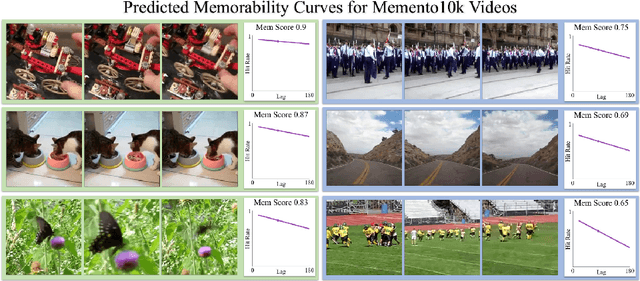
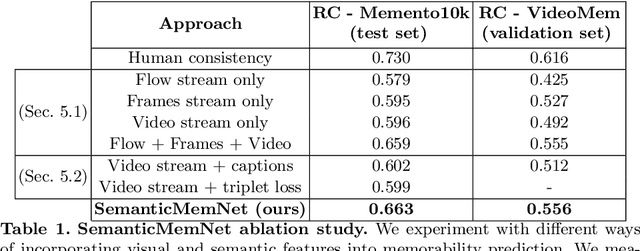


A key capability of an intelligent system is deciding when events from past experience must be remembered and when they can be forgotten. Towards this goal, we develop a predictive model of human visual event memory and how those memories decay over time. We introduce Memento10k, a new, dynamic video memorability dataset containing human annotations at different viewing delays. Based on our findings we propose a new mathematical formulation of memorability decay, resulting in a model that is able to produce the first quantitative estimation of how a video decays in memory over time. In contrast with previous work, our model can predict the probability that a video will be remembered at an arbitrary delay. Importantly, our approach combines visual and semantic information (in the form of textual captions) to fully represent the meaning of events. Our experiments on two video memorability benchmarks, including Memento10k, show that our model significantly improves upon the best prior approach (by 12% on average).
A One-Size-Fits-All Solution to Conservative Bandit Problems
Dec 16, 2020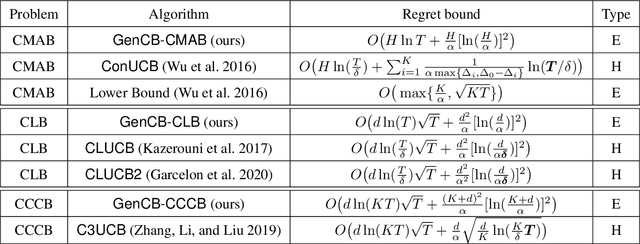
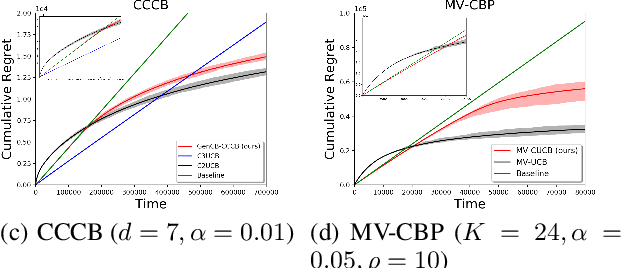
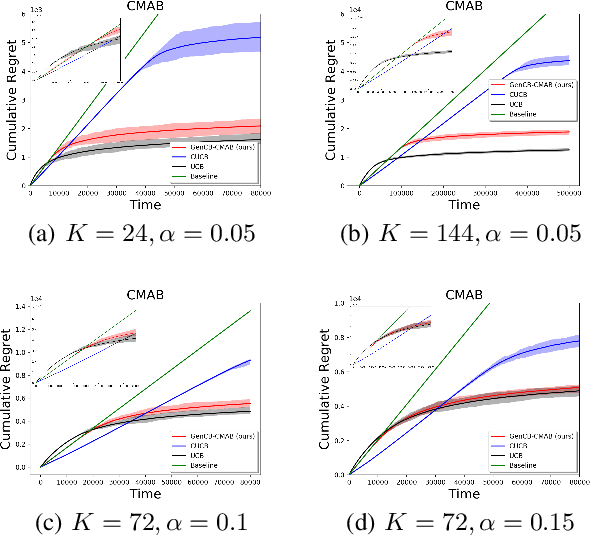
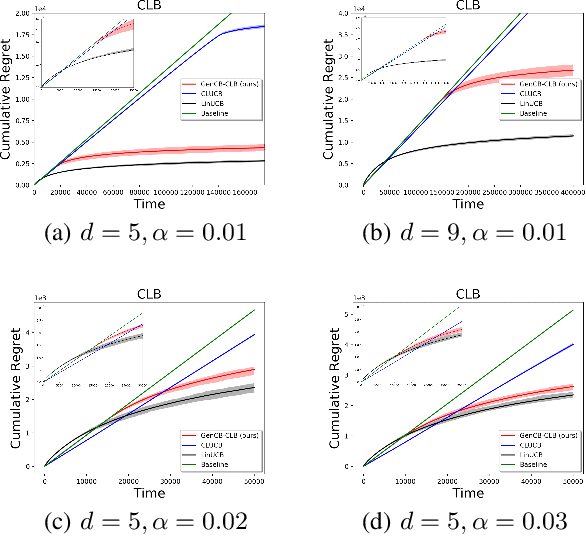
In this paper, we study a family of conservative bandit problems (CBPs) with sample-path reward constraints, i.e., the learner's reward performance must be at least as well as a given baseline at any time. We propose a One-Size-Fits-All solution to CBPs and present its applications to three encompassed problems, i.e. conservative multi-armed bandits (CMAB), conservative linear bandits (CLB) and conservative contextual combinatorial bandits (CCCB). Different from previous works which consider high probability constraints on the expected reward, we focus on a sample-path constraint on the actually received reward, and achieve better theoretical guarantees ($T$-independent additive regrets instead of $T$-dependent) and empirical performance. Furthermore, we extend the results and consider a novel conservative mean-variance bandit problem (MV-CBP), which measures the learning performance with both the expected reward and variability. For this extended problem, we provide a novel algorithm with $O(1/T)$ normalized additive regrets ($T$-independent in the cumulative form) and validate this result through empirical evaluation.
Automatic Cardiac Disease Assessment on cine-MRI via Time-Series Segmentation and Domain Specific Features
Jan 25, 2018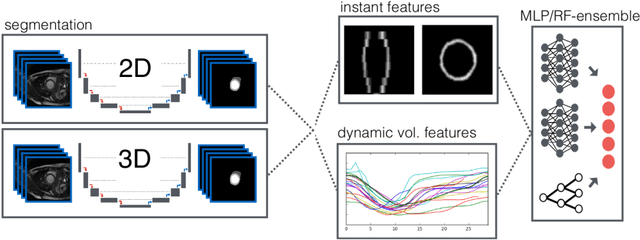
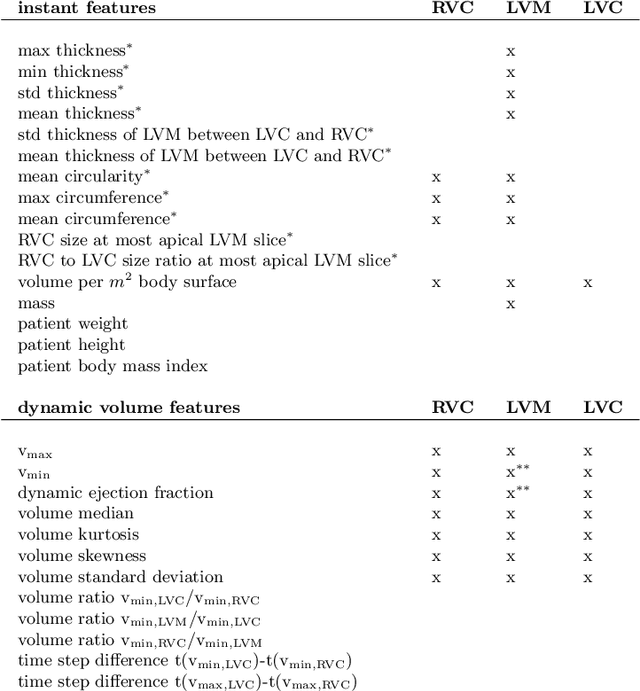
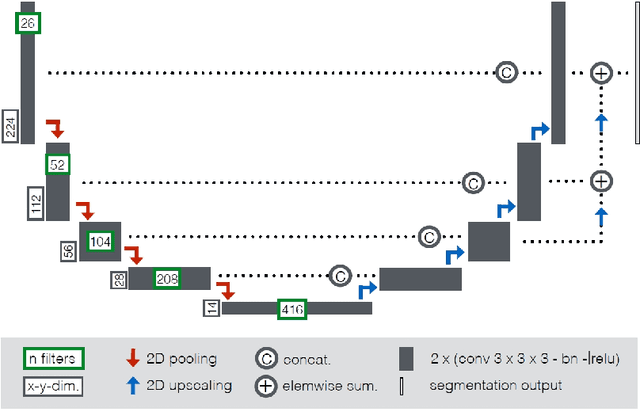
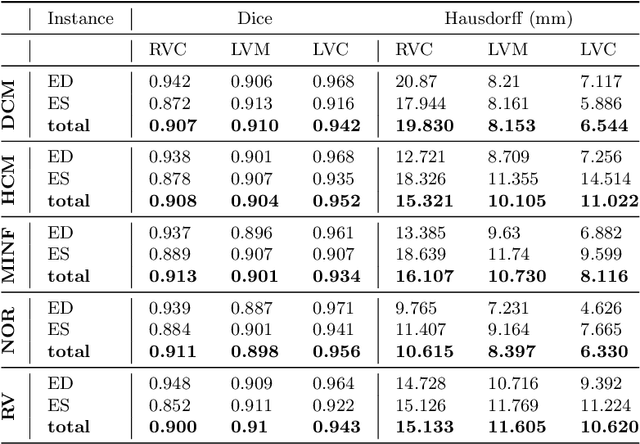
Cardiac magnetic resonance imaging improves on diagnosis of cardiovascular diseases by providing images at high spatiotemporal resolution. Manual evaluation of these time-series, however, is expensive and prone to biased and non-reproducible outcomes. In this paper, we present a method that addresses named limitations by integrating segmentation and disease classification into a fully automatic processing pipeline. We use an ensemble of UNet inspired architectures for segmentation of cardiac structures such as the left and right ventricular cavity (LVC, RVC) and the left ventricular myocardium (LVM) on each time instance of the cardiac cycle. For the classification task, information is extracted from the segmented time-series in form of comprehensive features handcrafted to reflect diagnostic clinical procedures. Based on these features we train an ensemble of heavily regularized multilayer perceptrons (MLP) and a random forest classifier to predict the pathologic target class. We evaluated our method on the ACDC dataset (4 pathology groups, 1 healthy group) and achieve dice scores of 0.945 (LVC), 0.908 (RVC) and 0.905 (LVM) in a cross-validation over the training set (100 cases) and 0.950 (LVC), 0.923 (RVC) and 0.911 (LVM) on the test set (50 cases). We report a classification accuracy of 94% on a training set cross-validation and 92% on the test set. Our results underpin the potential of machine learning methods for accurate, fast and reproducible segmentation and computer-assisted diagnosis (CAD).
Recovery of underdrawings and ghost-paintings via style transfer by deep convolutional neural networks: A digital tool for art scholars
Jan 04, 2021

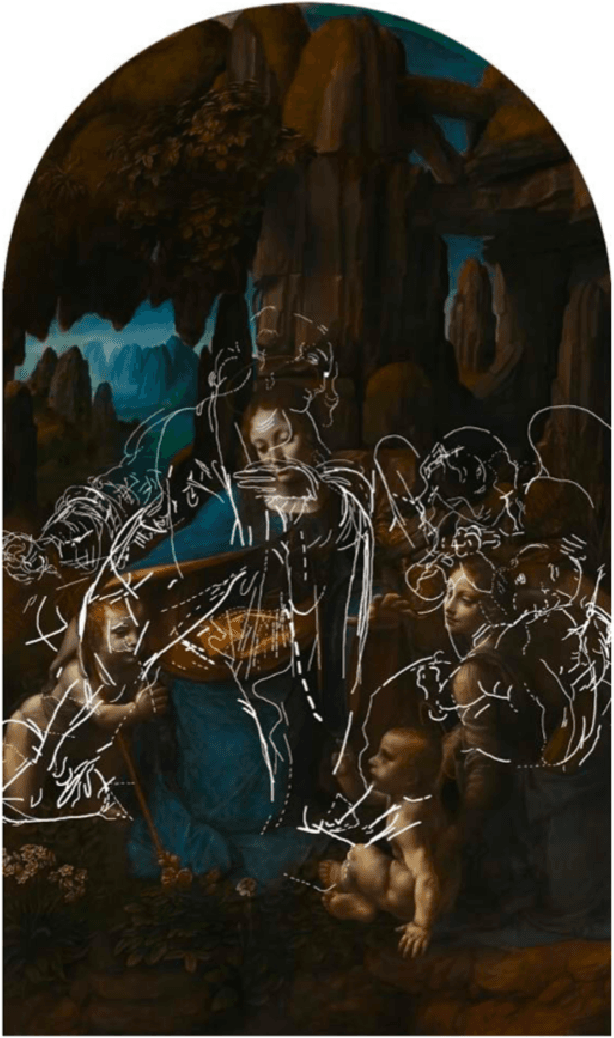

We describe the application of convolutional neural network style transfer to the problem of improved visualization of underdrawings and ghost-paintings in fine art oil paintings. Such underdrawings and hidden paintings are typically revealed by x-ray or infrared techniques which yield images that are grayscale, and thus devoid of color and full style information. Past methods for inferring color in underdrawings have been based on physical x-ray fluorescence spectral imaging of pigments in ghost-paintings and are thus expensive, time consuming, and require equipment not available in most conservation studios. Our algorithmic methods do not need such expensive physical imaging devices. Our proof-of-concept system, applied to works by Pablo Picasso and Leonardo, reveal colors and designs that respect the natural segmentation in the ghost-painting. We believe the computed images provide insight into the artist and associated oeuvre not available by other means. Our results strongly suggest that future applications based on larger corpora of paintings for training will display color schemes and designs that even more closely resemble works of the artist. For these reasons refinements to our methods should find wide use in art conservation, connoisseurship, and art analysis.
BlockFLA: Accountable Federated Learning via Hybrid Blockchain Architecture
Oct 14, 2020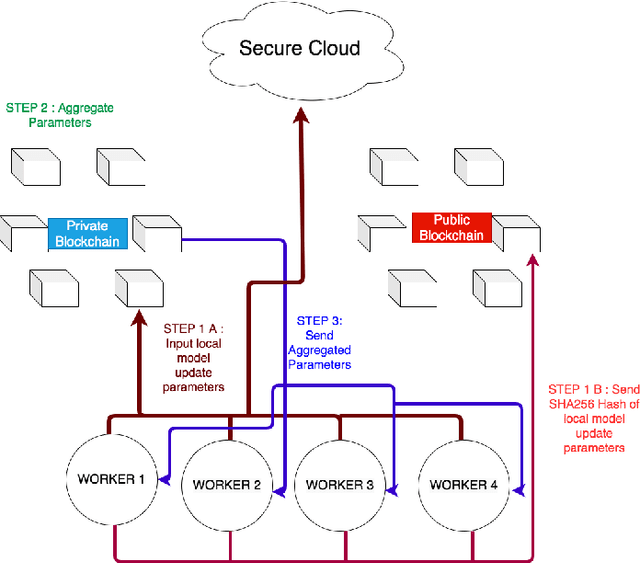
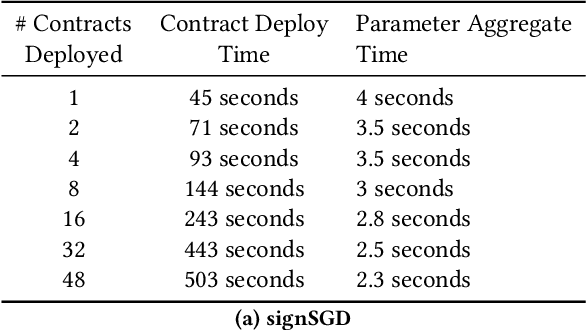
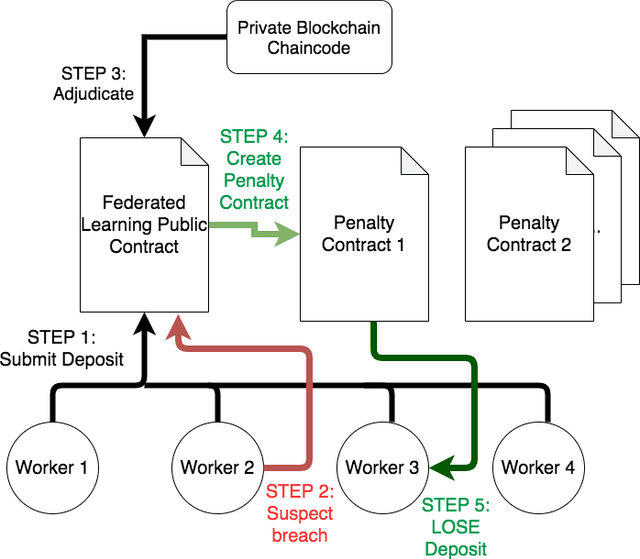
Federated Learning (FL) is a distributed, and decentralized machine learning protocol. By executing FL, a set of agents can jointly train a model without sharing their datasets with each other, or a third-party. This makes FL particularly suitable for settings where data privacy is desired. At the same time, concealing training data gives attackers an opportunity to inject backdoors into the trained model. It has been shown that an attacker can inject backdoors to the trained model during FL, and then can leverage the backdoor to make the model misclassify later. Several works tried to alleviate this threat by designing robust aggregation functions. However, given more sophisticated attacks are developed over time, which by-pass the existing defenses, we approach this problem from a complementary angle in this work. Particularly, we aim to discourage backdoor attacks by detecting, and punishing the attackers, possibly after the end of training phase. To this end, we develop a hybrid blockchain-based FL framework that uses smart contracts to automatically detect, and punish the attackers via monetary penalties. Our framework is general in the sense that, any aggregation function, and any attacker detection algorithm can be plugged into it. We conduct experiments to demonstrate that our framework preserves the communication-efficient nature of FL, and provide empirical results to illustrate that it can successfully penalize attackers by leveraging our novel attacker detection algorithm.
Tradeoffs for Space, Time, Data and Risk in Unsupervised Learning
May 02, 2016
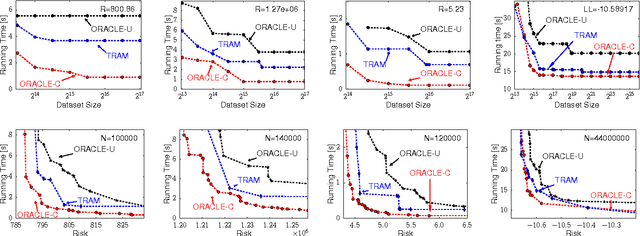
Faced with massive data, is it possible to trade off (statistical) risk, and (computational) space and time? This challenge lies at the heart of large-scale machine learning. Using k-means clustering as a prototypical unsupervised learning problem, we show how we can strategically summarize the data (control space) in order to trade off risk and time when data is generated by a probabilistic model. Our summarization is based on coreset constructions from computational geometry. We also develop an algorithm, TRAM, to navigate the space/time/data/risk tradeoff in practice. In particular, we show that for a fixed risk (or data size), as the data size increases (resp. risk increases) the running time of TRAM decreases. Our extensive experiments on real data sets demonstrate the existence and practical utility of such tradeoffs, not only for k-means but also for Gaussian Mixture Models.
TIME: A Transparent, Interpretable, Model-Adaptive and Explainable Neural Network for Dynamic Physical Processes
Mar 05, 2020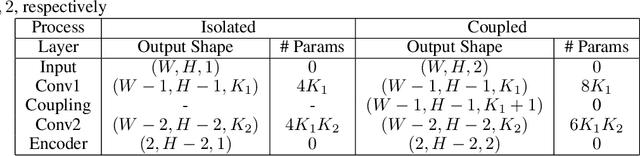

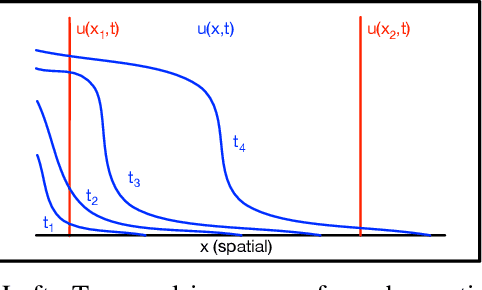
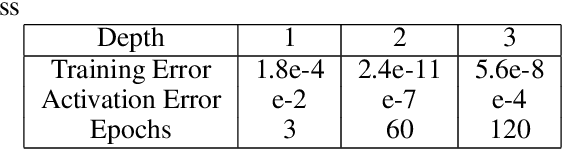
Partial Differential Equations are infinite dimensional encoded representations of physical processes. However, imbibing multiple observation data towards a coupled representation presents significant challenges. We present a fully convolutional architecture that captures the invariant structure of the domain to reconstruct the observable system. The proposed architecture is significantly low-weight compared to other networks for such problems. Our intent is to learn coupled dynamic processes interpreted as deviations from true kernels representing isolated processes for model-adaptivity. Experimental analysis shows that our architecture is robust and transparent in capturing process kernels and system anomalies. We also show that high weights representation is not only redundant but also impacts network interpretability. Our design is guided by domain knowledge, with isolated process representations serving as ground truths for verification. These allow us to identify redundant kernels and their manifestations in activation maps to guide better designs that are both interpretable and explainable unlike traditional deep-nets.
Scaling down Deep Learning
Dec 04, 2020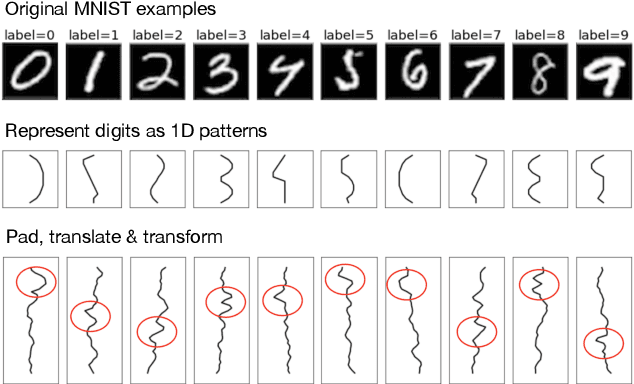

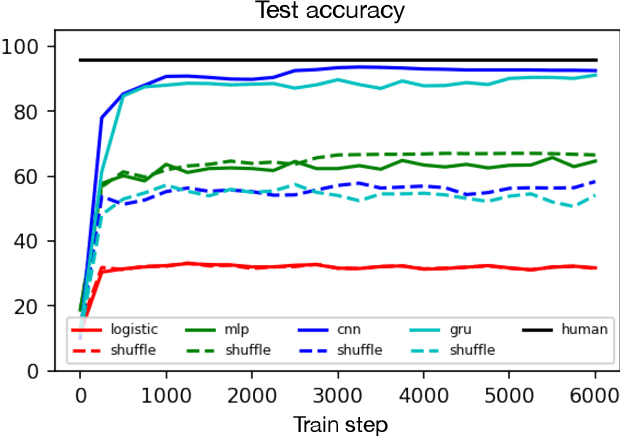
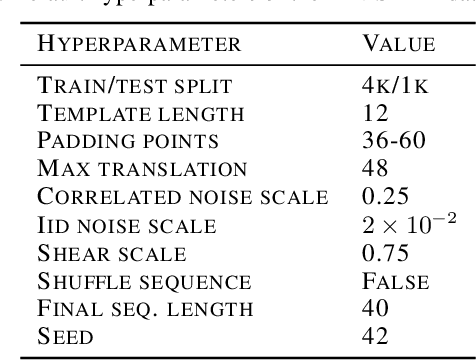
Though deep learning models have taken on commercial and political relevance, many aspects of their training and operation remain poorly understood. This has sparked interest in "science of deep learning" projects, many of which are run at scale and require enormous amounts of time, money, and electricity. But how much of this research really needs to occur at scale? In this paper, we introduce MNIST-1D: a minimalist, low-memory, and low-compute alternative to classic deep learning benchmarks. The training examples are 20 times smaller than MNIST examples yet they differentiate more clearly between linear, nonlinear, and convolutional models which attain 32, 68, and 94% accuracy respectively (these models obtain 94, 99+, and 99+% on MNIST). Then we present example use cases which include measuring the spatial inductive biases of lottery tickets, observing deep double descent, and metalearning an activation function.