 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Statistical Evaluation of Anomaly Detectors for Sequences
Aug 13, 2020
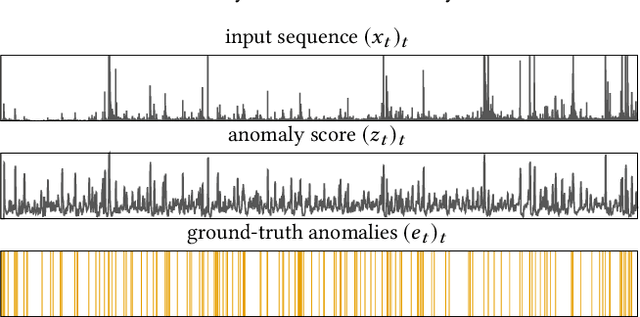

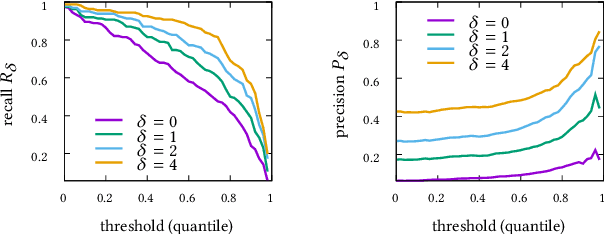

Although precision and recall are standard performance measures for anomaly detection, their statistical properties in sequential detection settings are poorly understood. In this work, we formalize a notion of precision and recall with temporal tolerance for point-based anomaly detection in sequential data. These measures are based on time-tolerant confusion matrices that may be used to compute time-tolerant variants of many other standard measures. However, care has to be taken to preserve interpretability. We perform a statistical simulation study to demonstrate that precision and recall may overestimate the performance of a detector, when computed with temporal tolerance. To alleviate this problem, we show how to obtain null distributions for the two measures to assess the statistical significance of reported results.
PatentMatch: A Dataset for Matching Patent Claims & Prior Art
Dec 27, 2020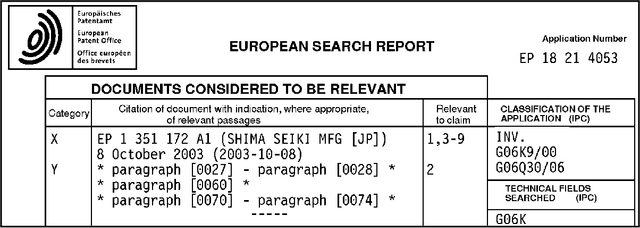
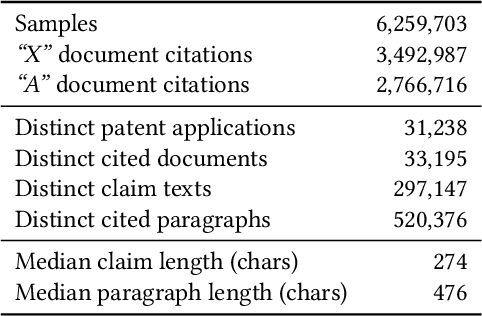
Patent examiners need to solve a complex information retrieval task when they assess the novelty and inventive step of claims made in a patent application. Given a claim, they search for prior art, which comprises all relevant publicly available information. This time-consuming task requires a deep understanding of the respective technical domain and the patent-domain-specific language. For these reasons, we address the computer-assisted search for prior art by creating a training dataset for supervised machine learning called PatentMatch. It contains pairs of claims from patent applications and semantically corresponding text passages of different degrees from cited patent documents. Each pair has been labeled by technically-skilled patent examiners from the European Patent Office. Accordingly, the label indicates the degree of semantic correspondence (matching), i.e., whether the text passage is prejudicial to the novelty of the claimed invention or not. Preliminary experiments using a baseline system show that PatentMatch can indeed be used for training a binary text pair classifier on this challenging information retrieval task. The dataset is available online: https://hpi.de/naumann/s/patentmatch.
The Benefit of the Doubt: Uncertainty Aware Sensing for Edge Computing Platforms
Feb 11, 2021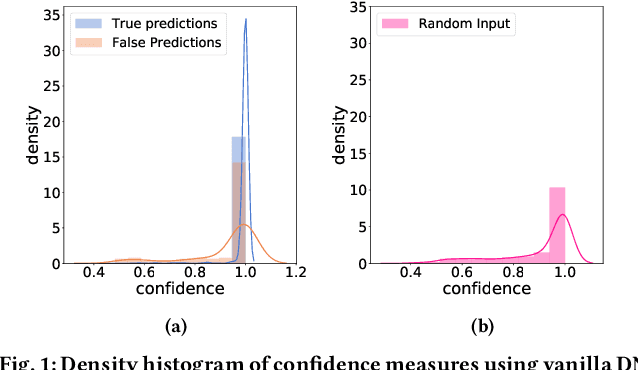

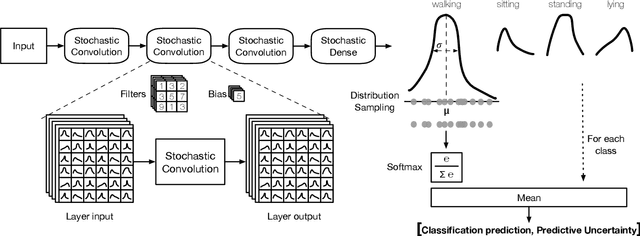
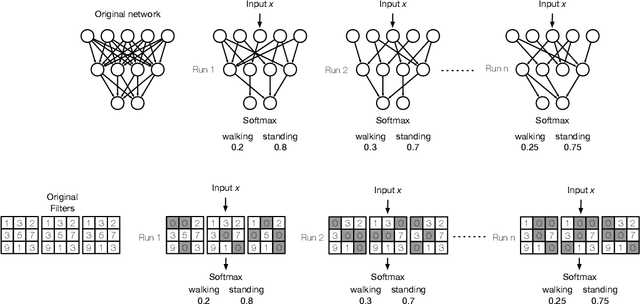
Neural networks (NNs) lack measures of "reliability" estimation that would enable reasoning over their predictions. Despite the vital importance, especially in areas of human well-being and health, state-of-the-art uncertainty estimation techniques are computationally expensive when applied to resource-constrained devices. We propose an efficient framework for predictive uncertainty estimation in NNs deployed on embedded edge systems with no need for fine-tuning or re-training strategies. To meet the energy and latency requirements of these embedded platforms the framework is built from the ground up to provide predictive uncertainty based only on one forward pass and a negligible amount of additional matrix multiplications with theoretically proven correctness. Our aim is to enable already trained deep learning models to generate uncertainty estimates on resource-limited devices at inference time focusing on classification tasks. This framework is founded on theoretical developments casting dropout training as approximate inference in Bayesian NNs. Our layerwise distribution approximation to the convolution layer cascades through the network, providing uncertainty estimates in one single run which ensures minimal overhead, especially compared with uncertainty techniques that require multiple forwards passes and an equal linear rise in energy and latency requirements making them unsuitable in practice. We demonstrate that it yields better performance and flexibility over previous work based on multilayer perceptrons to obtain uncertainty estimates. Our evaluation with mobile applications datasets shows that our approach not only obtains robust and accurate uncertainty estimations but also outperforms state-of-the-art methods in terms of systems performance, reducing energy consumption (up to 28x), keeping the memory overhead at a minimum while still improving accuracy (up to 16%).
Detection of Binary Square Fiducial Markers Using an Event Camera
Dec 11, 2020


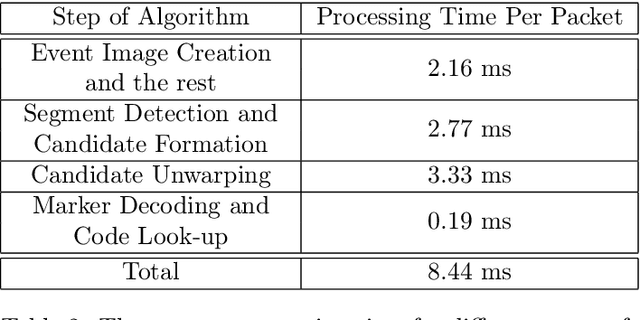
Event cameras are a new type of image sensors that output changes in light intensity (events) instead of absolute intensity values. They have a very high temporal resolution and a high dynamic range. In this paper, we propose a method to detect and decode binary square markers using an event camera. We detect the edges of the markers by detecting line segments in an image created from events in the current packet. The line segments are combined to form marker candidates. The bit value of marker cells is decoded using the events on their borders. To the best of our knowledge, no other approach exists for detecting square binary markers directly from an event camera. Experimental results show that the performance of our proposal is much superior to the one from the RGB ArUco marker detector. Additionally, the proposed method can run on a single CPU core in real-time.
Accurate Cell Segmentation in Digital Pathology Images via Attention Enforced Networks
Dec 27, 2020
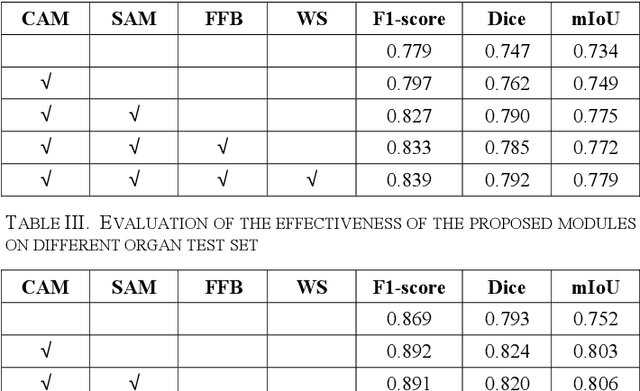
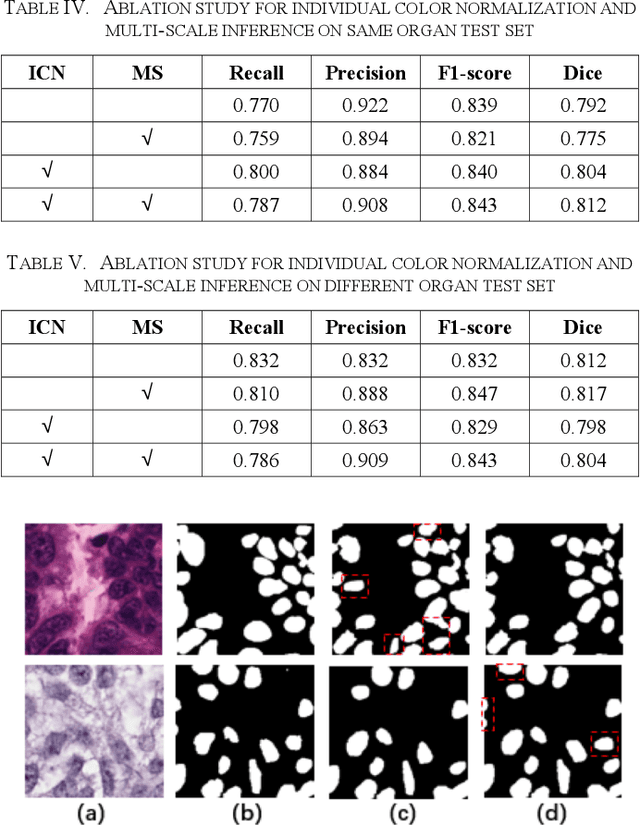

Automatic cell segmentation is an essential step in the pipeline of computer-aided diagnosis (CAD), such as the detection and grading of breast cancer. Accurate segmentation of cells can not only assist the pathologists to make a more precise diagnosis, but also save much time and labor. However, this task suffers from stain variation, cell inhomogeneous intensities, background clutters and cells from different tissues. To address these issues, we propose an Attention Enforced Network (AENet), which is built on spatial attention module and channel attention module, to integrate local features with global dependencies and weight effective channels adaptively. Besides, we introduce a feature fusion branch to bridge high-level and low-level features. Finally, the marker controlled watershed algorithm is applied to post-process the predicted segmentation maps for reducing the fragmented regions. In the test stage, we present an individual color normalization method to deal with the stain variation problem. We evaluate this model on the MoNuSeg dataset. The quantitative comparisons against several prior methods demonstrate the superiority of our approach.
MALCOM: Generating Malicious Comments to Attack Neural Fake News Detection Models
Sep 27, 2020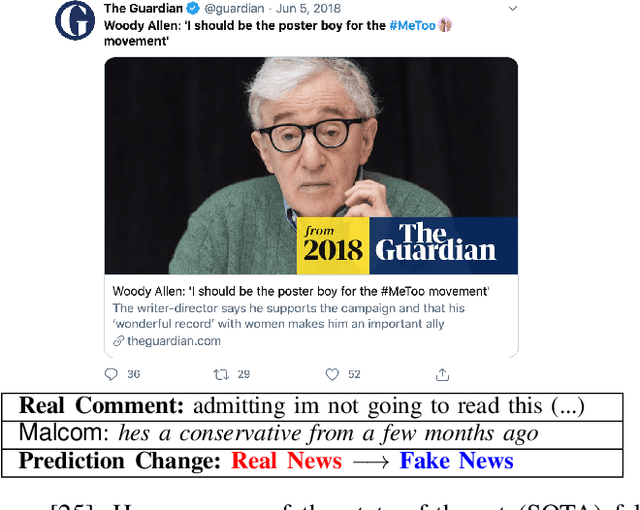

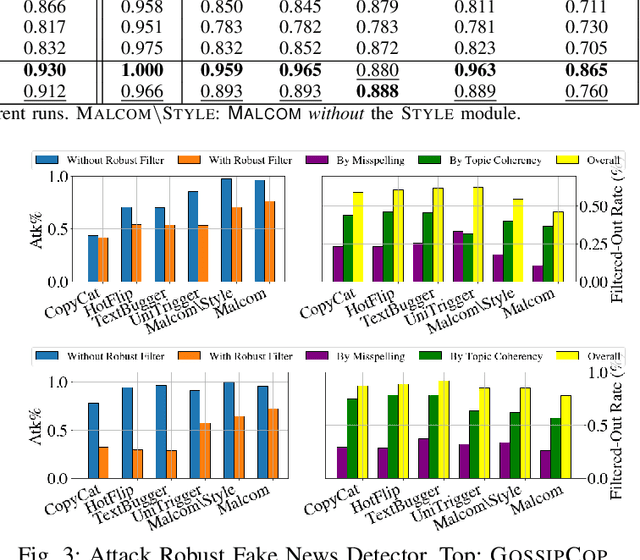

In recent years, the proliferation of so-called "fake news" has caused much disruptions in society and weakened the news ecosystem. Therefore, to mitigate such problems, researchers have developed state-of-the-art models to auto-detect fake news on social media using sophisticated data science and machine learning techniques. In this work, then, we ask "what if adversaries attempt to attack such detection models?" and investigate related issues by (i) proposing a novel threat model against fake news detectors, in which adversaries can post malicious comments toward news articles to mislead fake news detectors, and (ii) developing MALCOM, an end-to-end adversarial comment generation framework to achieve such an attack. Through a comprehensive evaluation, we demonstrate that about 94% and 93.5% of the time on average MALCOM can successfully mislead five of the latest neural detection models to always output targeted real and fake news labels. Furthermore, MALCOM can also fool black box fake news detectors to always output real news labels 90% of the time on average. We also compare our attack model with four baselines across two real-world datasets, not only on attack performance but also on generated quality, coherency, transferability, and robustness.
Split Computing for Complex Object Detectors: Challenges and Preliminary Results
Jul 30, 2020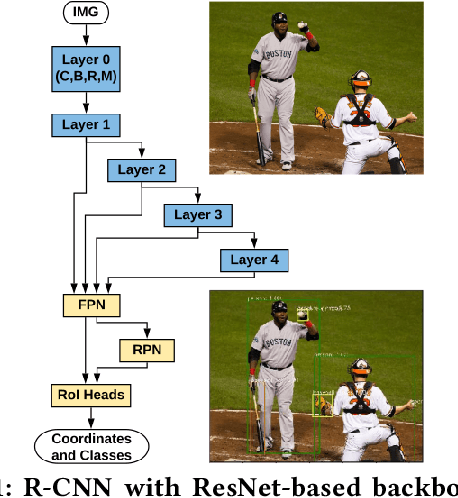
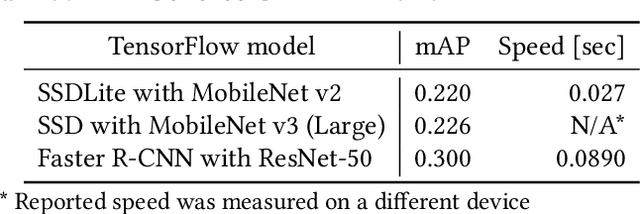
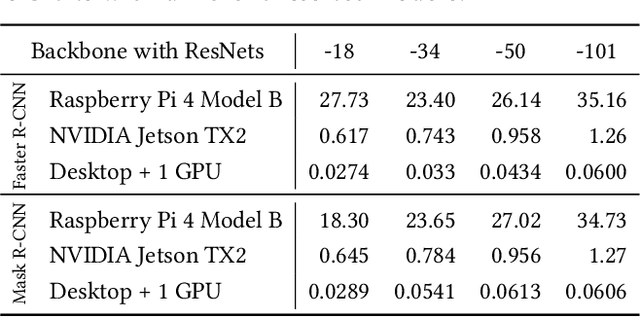
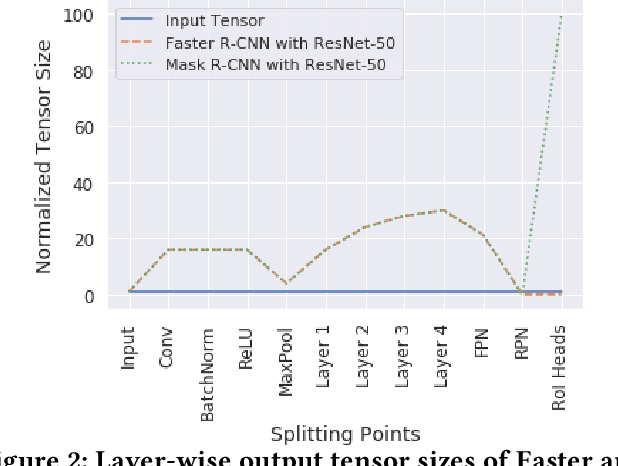
Following the trends of mobile and edge computing for DNN models, an intermediate option, split computing, has been attracting attentions from the research community. Previous studies empirically showed that while mobile and edge computing often would be the best options in terms of total inference time, there are some scenarios where split computing methods can achieve shorter inference time. All the proposed split computing approaches, however, focus on image classification tasks, and most are assessed with small datasets that are far from the practical scenarios. In this paper, we discuss the challenges in developing split computing methods for powerful R-CNN object detectors trained on a large dataset, COCO 2017. We extensively analyze the object detectors in terms of layer-wise tensor size and model size, and show that naive split computing methods would not reduce inference time. To the best of our knowledge, this is the first study to inject small bottlenecks to such object detectors and unveil the potential of a split computing approach. The source code and trained models' weights used in this study are available at https://github.com/yoshitomo-matsubara/hnd-ghnd-object-detectors .
Outlier-Robust Estimation: Hardness, Minimally-Tuned Algorithms, and Applications
Jul 29, 2020
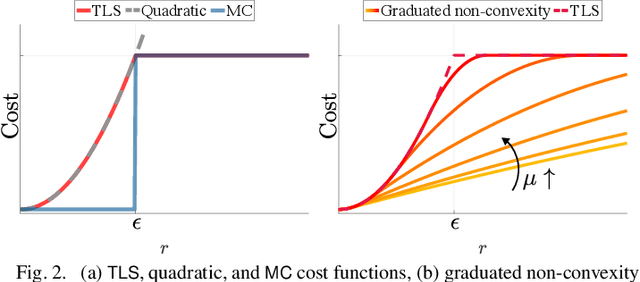
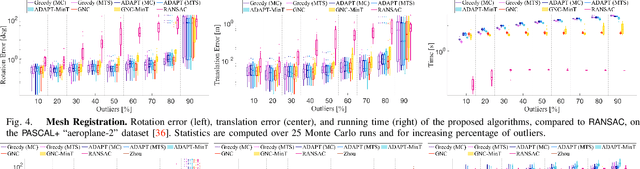
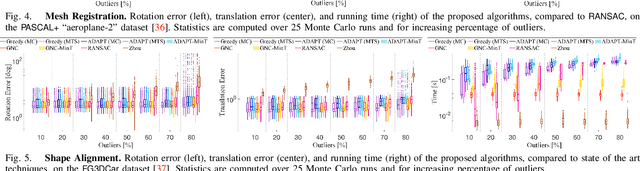
Nonlinear estimation in robotics and vision is typically plagued with outliers due to wrong data association, or to incorrect detections from signal processing and machine learning methods. This paper introduces two unifying formulations for outlier-robust estimation, Generalized Maximum Consensus (G- MC) and Generalized Truncated Least Squares (G-TLS), and investigates fundamental limits, practical algorithms, and applications. Our first contribution is a proof that outlier-robust estimation is inapproximable: in the worst case, it is impossible to (even approximately) find the set of outliers, even with slower-than-polynomial-time algorithms (particularly, algorithms running in quasi-polynomial time). As a second contribution, we review and extend two general-purpose algorithms. The first, Adaptive Trimming (ADAPT), is combinatorial, and is suitable for G-MC; the second, Graduated Non-Convexity (GNC), is based on homotopy methods, and is suitable for G-TLS. We extend ADAPT and GNC to the case where the user does not have prior knowledge of the inlier-noise statistics (or the statistics may vary over time) and is unable to guess a reasonable threshold to separate inliers from outliers (as the one commonly used in RANSAC). We propose the first minimally-tuned algorithms for outlier rejection, that dynamically decide how to separate inliers from outliers. Our third contribution is an evaluation of the proposed algorithms on robot perception problems: mesh registration, image-based object detection (shape alignment), and pose graph optimization. ADAPT and GNC execute in real-time, are deterministic, outperform RANSAC, and are robust to 70-90% outliers. Their minimally-tuned versions also compare favorably with the state of the art, even though they do not rely on a noise bound for the inliers.
Solar Coronal Magnetic Field Extrapolation from Synchronic Data with AI-generated Farside
Nov 01, 2020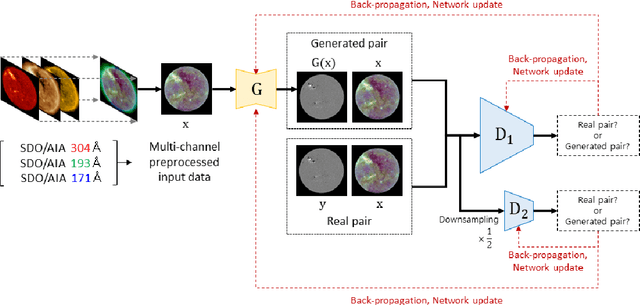
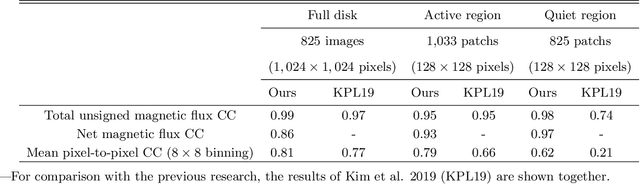
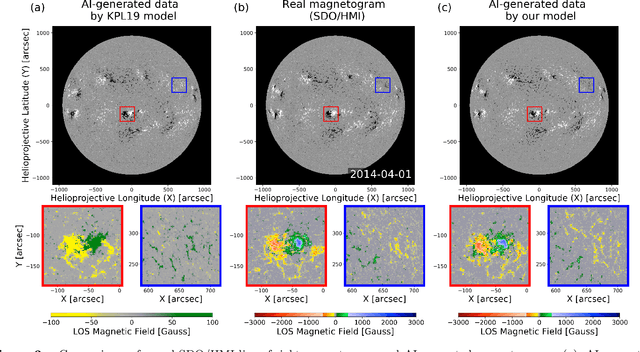
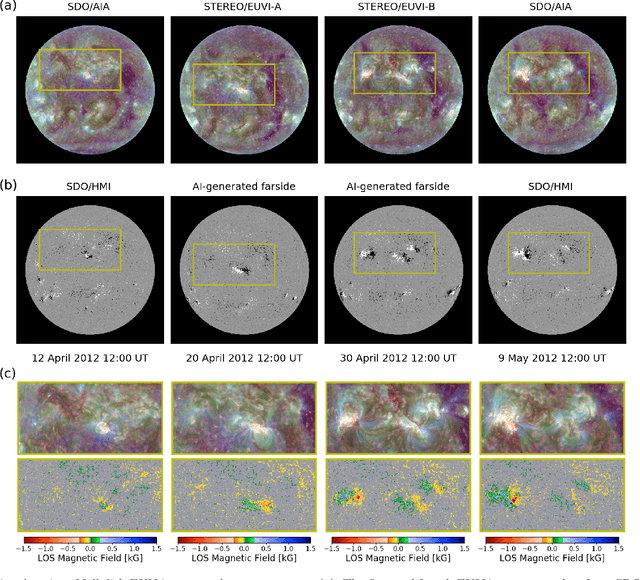
Solar magnetic fields play a key role in understanding the nature of the coronal phenomena. Global coronal magnetic fields are usually extrapolated from photospheric fields, for which farside data is taken when it was at the frontside, about two weeks earlier. For the first time we have constructed the extrapolations of global magnetic fields using frontside and artificial intelligence (AI)-generated farside magnetic fields at a near-real time basis. We generate the farside magnetograms from three channel farside observations of Solar Terrestrial Relations Observatory (STEREO) Ahead (A) and Behind (B) by our deep learning model trained with frontside Solar Dynamics Observatory extreme ultraviolet images and magnetograms. For frontside testing data sets, we demonstrate that the generated magnetic field distributions are consistent with the real ones; not only active regions (ARs), but also quiet regions of the Sun. We make global magnetic field synchronic maps in which conventional farside data are replaced by farside ones generated by our model. The synchronic maps show much better not only the appearance of ARs but also the disappearance of others on the solar surface than before. We use these synchronized magnetic data to extrapolate the global coronal fields using Potential Field Source Surface (PFSS) model. We show that our results are much more consistent with coronal observations than those of the conventional method in view of solar active regions and coronal holes. We present several positive prospects of our new methodology for the study of solar corona, heliosphere, and space weather.
MHT-X: Offline Multiple Hypothesis Tracking with Algorithm X
Dec 17, 2020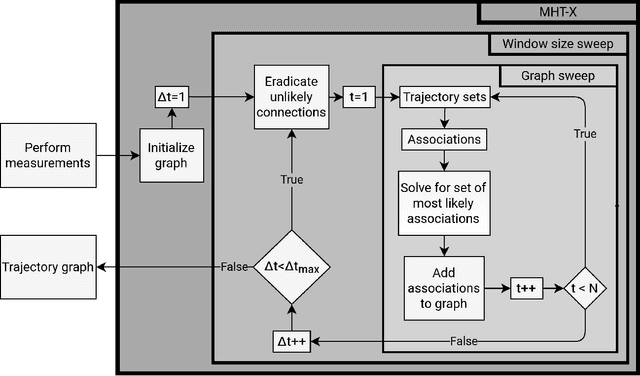
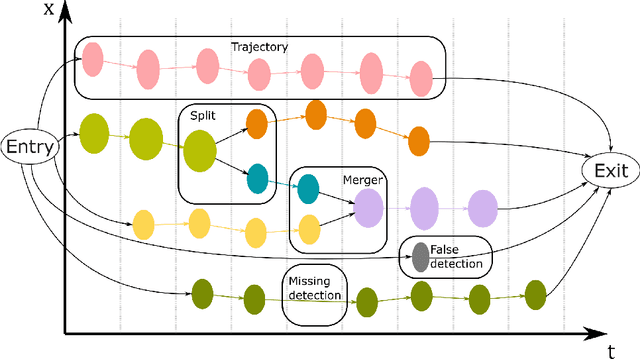

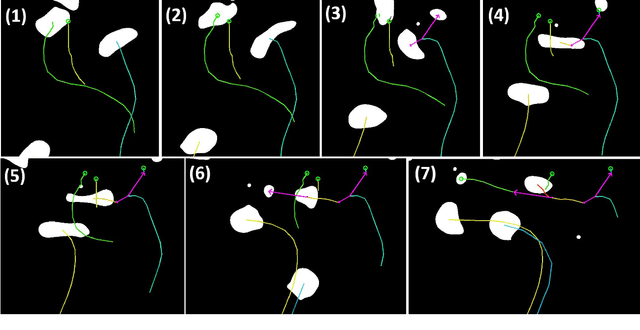
An efficient and versatile implementation of offline multiple hypothesis tracking with Algorithm X for optimal association search was developed using Python. The code is intended for scientific applications that do not require online processing. Directed graph framework is used and multiple scans with progressively increasing time window width are used for edge construction for maximum likelihood trajectories. The current version of the code was developed for applications in multiphase hydrodynamics, e.g. bubble and particle tracking, and is capable of resolving object motion, merges and splits. Feasible object associations and trajectory graph edge likelihoods are determined using weak mass and momentum conservation laws translated to statistical functions for object properties. The code is compatible with n-dimensional motion with arbitrarily many tracked object properties. This framework is easily extendable beyond the present application by replacing the currently used heuristics with ones more appropriate for the problem at hand. The code is open-source and will be continuously developed further.