 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FC-GAGA: Fully Connected Gated Graph Architecture for Spatio-Temporal Traffic Forecasting
Jul 30, 2020
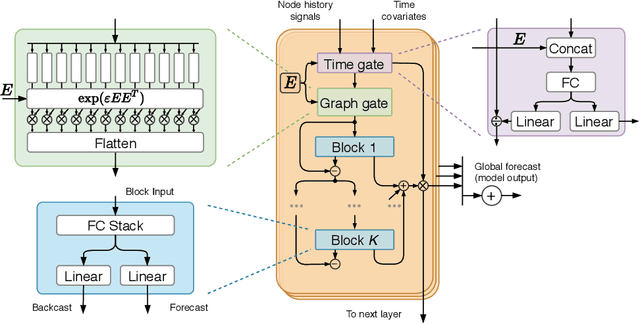
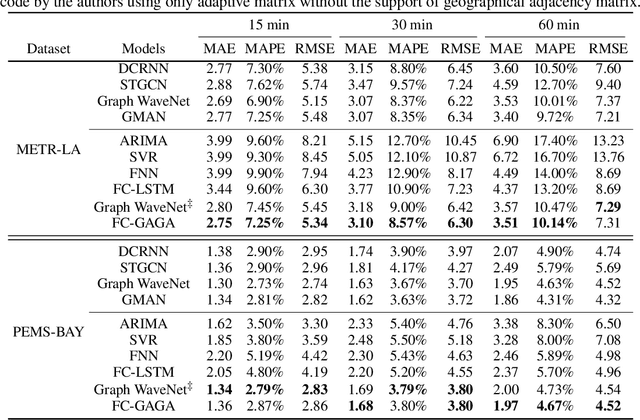
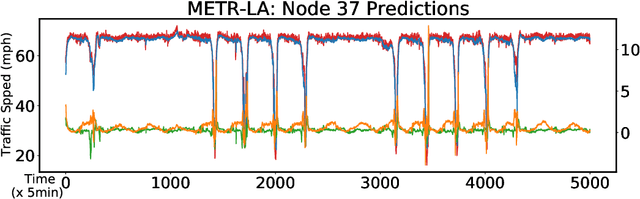
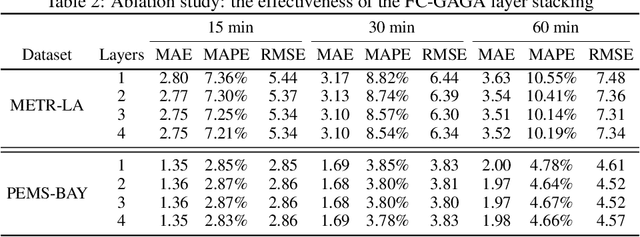
Forecasting of multivariate time-series is an important problem that has applications in many domains, including traffic management, cellular network configuration, and quantitative finance. In recent years, researchers have demonstrated the value of applying deep learning architectures for these problems. A special case of the problem arises when there is a graph available that captures the relationships between the time-series. In this paper we propose a novel learning architecture that achieves performance competitive with or better than the best existing algorithms, without requiring knowledge of the graph. The key elements of our proposed architecture are (i) jointly performing backcasting and forecasting with a deep fully-connected architecture; (ii) stacking multiple prediction modules that target successive residuals; and (iii) learning a separate causal relationship graph for each layer of the stack. We can view each layer as predicting a component of the time-series; the differing nature of the causal graphs at different layers can be interpreted as indicating that the multivariate predictive relationships differ for different components. Experimental results for two public traffic network datasets illustrate the value of our approach, and ablation studies confirm the importance of each element of the architecture.
Gestop : Customizable Gesture Control of Computer Systems
Oct 25, 2020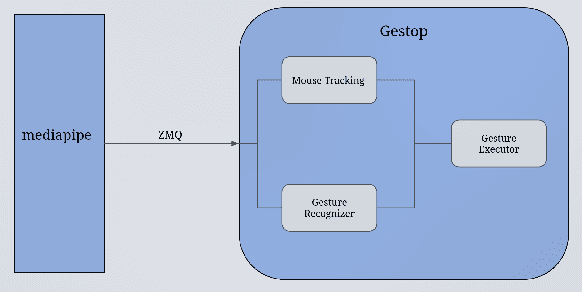

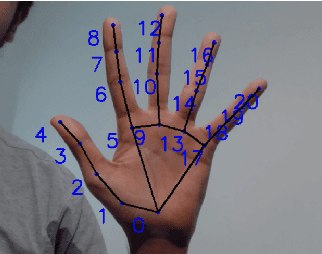
The established way of interfacing with most computer systems is a mouse and keyboard. Hand gestures are an intuitive and effective touchless way to interact with computer systems. However, hand gesture based systems have seen low adoption among end-users primarily due to numerous technical hurdles in detecting in-air gestures accurately. This paper presents Gestop, a framework developed to bridge this gap. The framework learns to detect gestures from demonstrations, is customizable by end-users and enables users to interact in real-time with computers having only RGB cameras, using gestures.
FabricNet: A Fiber Recognition Architecture Using Ensemble ConvNets
Jan 14, 2021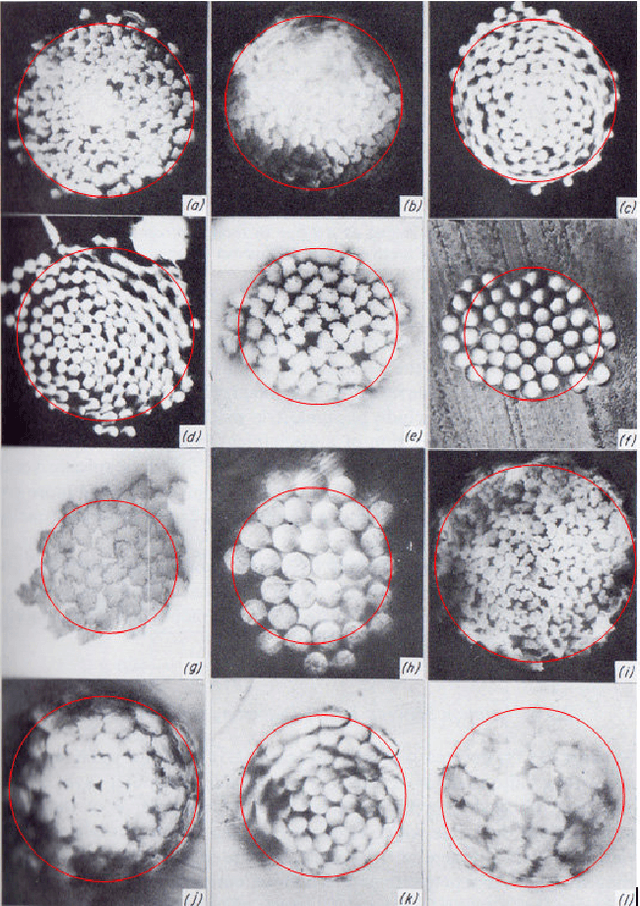
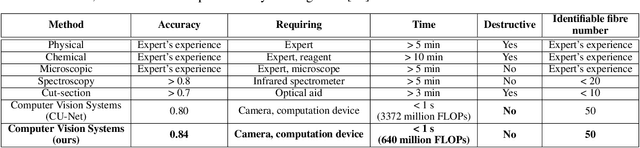

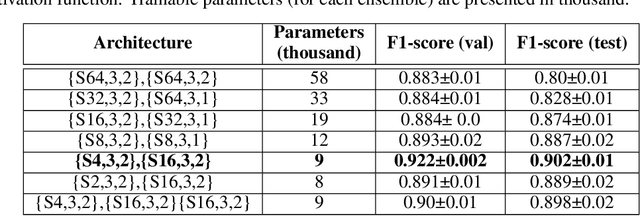
Fabric is a planar material composed of textile fibers. Textile fibers are generated from many natural sources; including plants, animals, minerals, and even, it can be synthetic. A particular fabric may contain different types of fibers that pass through a complex production process. Fiber identification is usually carried out through chemical tests and microscopic tests. However, these testing processes are complicated as well as time-consuming. We propose FabricNet, a pioneering approach for the image-based textile fiber recognition system, which may have a revolutionary impact from individual to the industrial fiber recognition process. The FabricNet can recognize a large scale of fibers by only utilizing a surface image of fabric. The recognition system is constructed using a distinct category of class-based ensemble convolutional neural network (CNN) architecture. The experiment is conducted on recognizing 50 different types of textile fibers. This experiment includes a significantly large number of unique textile fibers than previous research endeavors to the best of our knowledge. We experiment with popular CNN architectures that include Inception, ResNet, VGG, MobileNet, DenseNet, and Xception. Finally, the experimental results demonstrate that FabricNet outperforms the state-of-the-art popular CNN architectures by reaching an accuracy of 84% and F1-score of 90%.
Portfolio Optimization with 2D Relative-Attentional Gated Transformer
Dec 27, 2020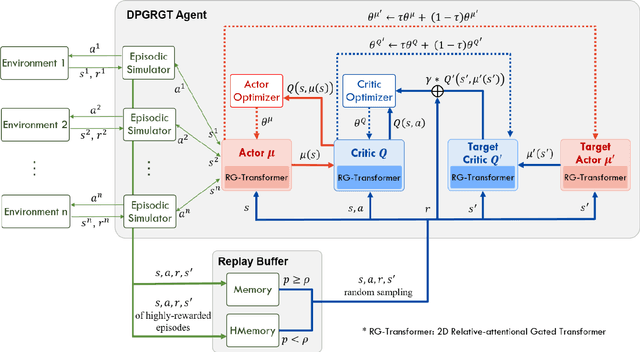
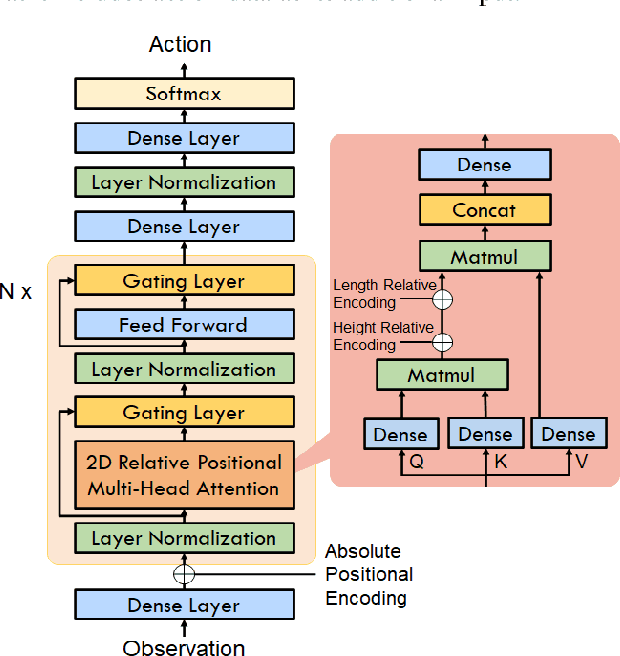
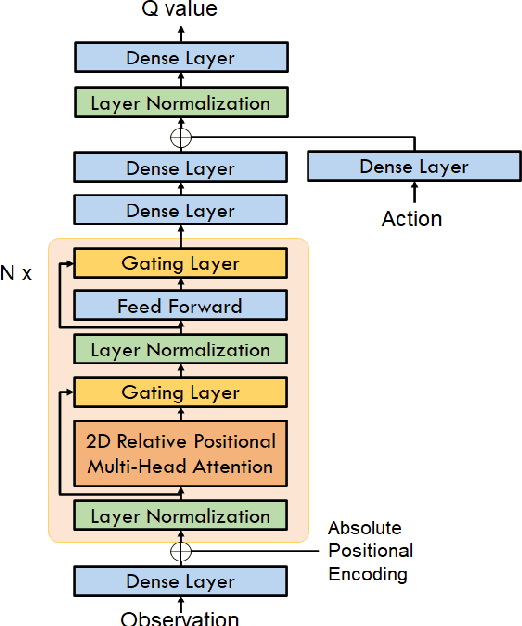
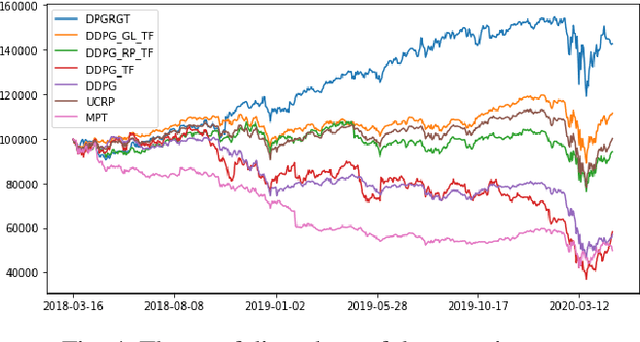
Portfolio optimization is one of the most attentive fields that have been researched with machine learning approaches. Many researchers attempted to solve this problem using deep reinforcement learning due to its efficient inherence that can handle the property of financial markets. However, most of them can hardly be applicable to real-world trading since they ignore or extremely simplify the realistic constraints of transaction costs. These constraints have a significantly negative impact on portfolio profitability. In our research, a conservative level of transaction fees and slippage are considered for the realistic experiment. To enhance the performance under those constraints, we propose a novel Deterministic Policy Gradient with 2D Relative-attentional Gated Transformer (DPGRGT) model. Applying learnable relative positional embeddings for the time and assets axes, the model better understands the peculiar structure of the financial data in the portfolio optimization domain. Also, gating layers and layer reordering are employed for stable convergence of Transformers in reinforcement learning. In our experiment using U.S. stock market data of 20 years, our model outperformed baseline models and demonstrated its effectiveness.
A Review on Deep Learning in UAV Remote Sensing
Jan 29, 2021

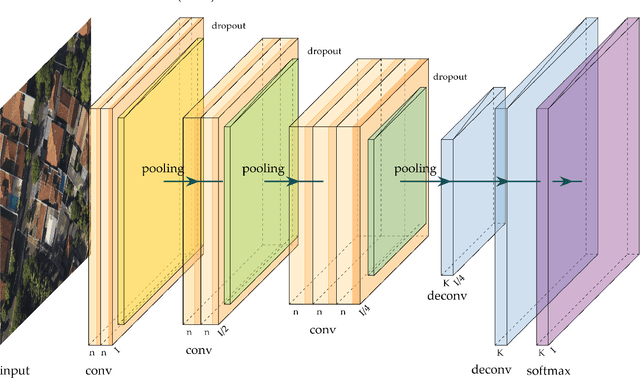
Deep Neural Networks (DNNs) learn representation from data with an impressive capability, and brought important breakthroughs for processing images, time-series, natural language, audio, video, and many others. In the remote sensing field, surveys and literature revisions specifically involving DNNs algorithms' applications have been conducted in an attempt to summarize the amount of information produced in its subfields. Recently, Unmanned Aerial Vehicles (UAV) based applications have dominated aerial sensing research. However, a literature revision that combines both "deep learning" and "UAV remote sensing" thematics has not yet been conducted. The motivation for our work was to present a comprehensive review of the fundamentals of Deep Learning (DL) applied in UAV-based imagery. We focused mainly on describing classification and regression techniques used in recent applications with UAV-acquired data. For that, a total of 232 papers published in international scientific journal databases was examined. We gathered the published material and evaluated their characteristics regarding application, sensor, and technique used. We relate how DL presents promising results and has the potential for processing tasks associated with UAV-based image data. Lastly, we project future perspectives, commentating on prominent DL paths to be explored in the UAV remote sensing field. Our revision consists of a friendly-approach to introduce, commentate, and summarize the state-of-the-art in UAV-based image applications with DNNs algorithms in diverse subfields of remote sensing, grouping it in the environmental, urban, and agricultural contexts.
Tradeoffs for Space, Time, Data and Risk in Unsupervised Learning
May 02, 2016
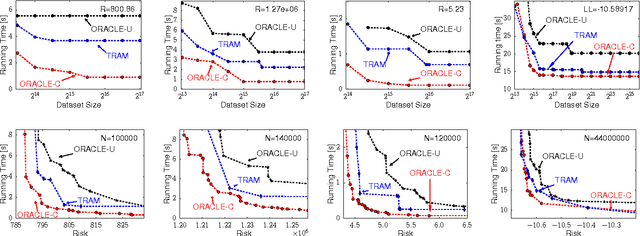
Faced with massive data, is it possible to trade off (statistical) risk, and (computational) space and time? This challenge lies at the heart of large-scale machine learning. Using k-means clustering as a prototypical unsupervised learning problem, we show how we can strategically summarize the data (control space) in order to trade off risk and time when data is generated by a probabilistic model. Our summarization is based on coreset constructions from computational geometry. We also develop an algorithm, TRAM, to navigate the space/time/data/risk tradeoff in practice. In particular, we show that for a fixed risk (or data size), as the data size increases (resp. risk increases) the running time of TRAM decreases. Our extensive experiments on real data sets demonstrate the existence and practical utility of such tradeoffs, not only for k-means but also for Gaussian Mixture Models.
Conceptual Design of LiFi Audio Transmission Using Pre-Programmed Modules
Jan 05, 2021
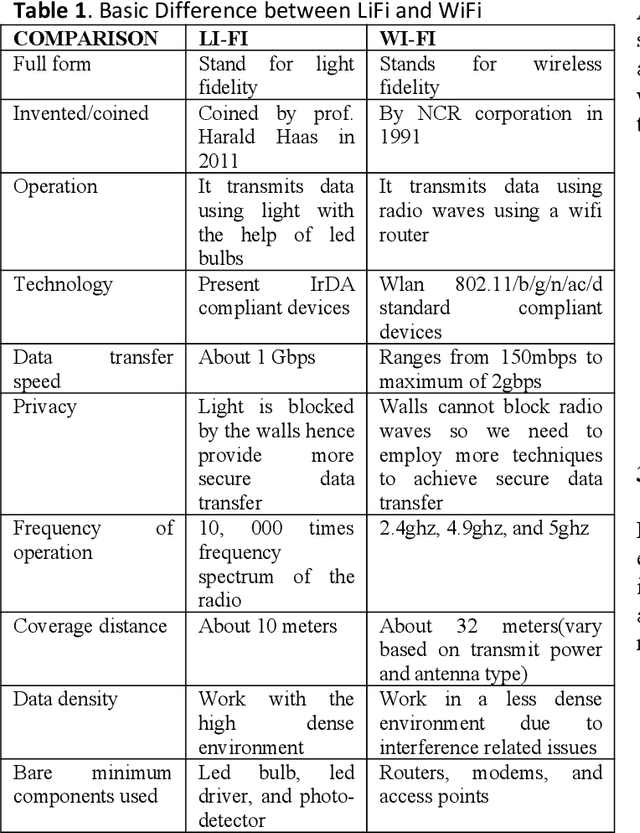
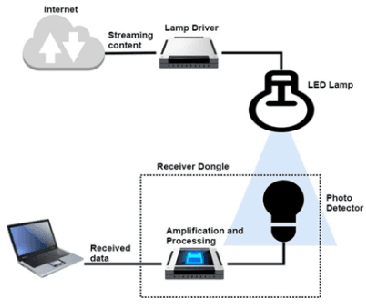
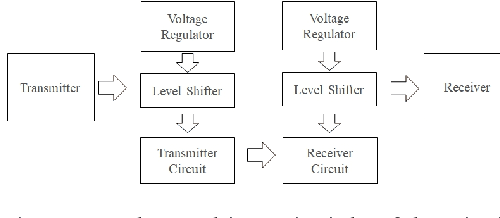
We all know that Wi-Fi is presently the most commonly used technology for data transmission and connecting devices to the Internet, at the same time due to much reasonable concern, (such as Wi-Fi can be vulnerable when it comes to hacking, health concern, and low latency, etc.) the concept of Li-Fi is becoming very popular as a new way of data transmission that use light waves to transmit data rather than radio waves. Light-emitting diodes LED are used when transmitting the data in the visible light spectrum. Li-fi uses visible light communication and it has a promising future. Unlike Wi-fi, Li-Fi has low latency, high efficiency, accessible spectrum, and high data can be achieved. It is highly secured so the data cannot be hacked. In this paper, we design a concept of Li-fi audio signal transmission by reusing and repurposing pre-programmed modules to simplify and discuss visible light communication (VLC) in other to give a new researcher the idea on how the concept of LiFi and VLC. In addition to designing the concept we experiment to test the concept and we illustrated the result within this paper.
Multi-Task Learning for Interpretable Weakly Labelled Sound Event Detection
Aug 17, 2020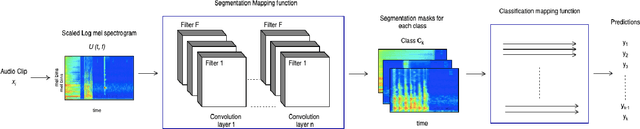
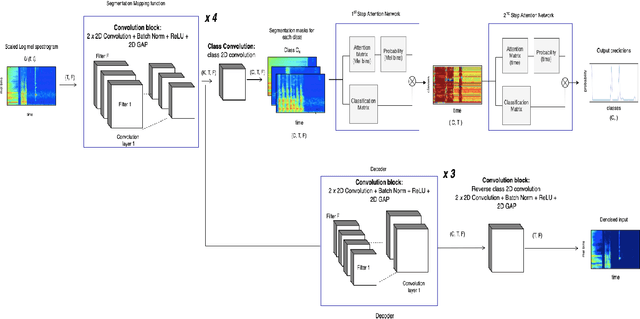
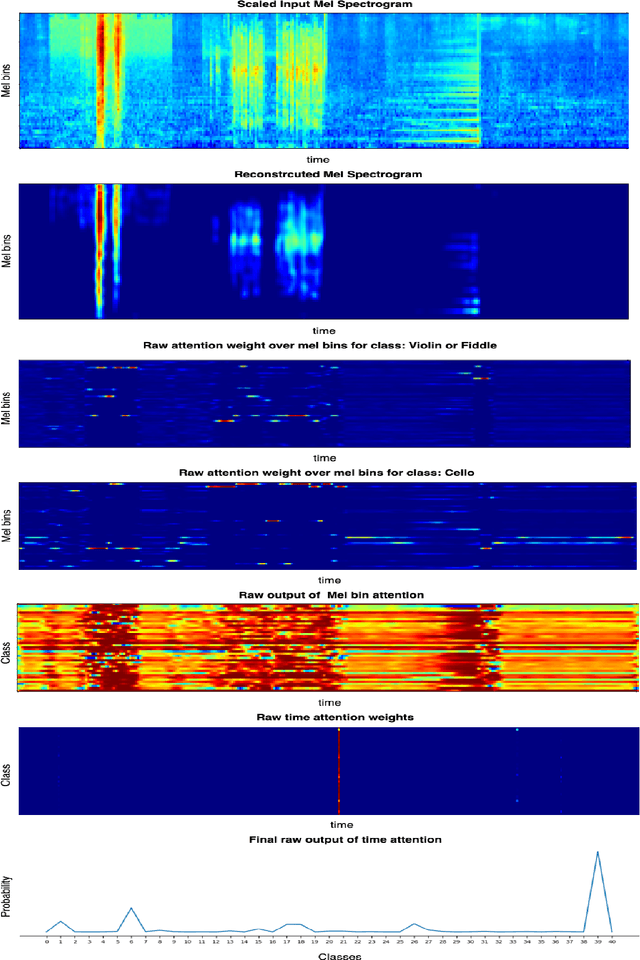

Weakly Labelled learning has garnered lot of attention in recent years due to its potential to scale Sound Event Detection (SED). The paper proposes a Multi-Task Learning (MTL) framework for learning from Weakly Labelled Audio data which encompasses the traditional Multiple Instance Learning (MIL) setup. The MTL framework uses two-step attention mechanism and reconstructs Time Frequency (T-F) representation of audio as the auxiliary task. By breaking the attention into two steps, the network retains better time level information without compromising classification performance. The auxiliary task uses an auto-encoder structure to encourage the network for retaining source specific information. This indirectly de-noises internal T- F representation and improves classification performance under noisy recordings. For evaluation of proposed methodology, we remix the DCASE 2019 task 1 acoustic scene data with DCASE 2018 Task 2 sounds event data under 0, 10 and 20 db SNR. The proposed network outperforms existing benchmark models over all SNRs, specifically 22.3 %, 12.8 %, 5.9 % improvement over benchmark model on 0, 10 and 20 dB SNR respectively. The results and ablation study performed demonstrates the usefulness of auto-encoder for auxiliary task and verifies that the output of decoder portion provides a cleaned Time Frequency (T-F) representation of audio/sources which can be further used for source separation. The code is publicly released.
Automatic Cardiac Disease Assessment on cine-MRI via Time-Series Segmentation and Domain Specific Features
Jan 25, 2018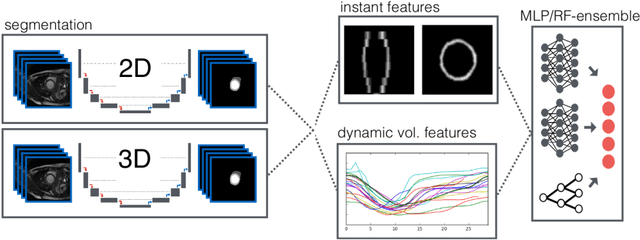
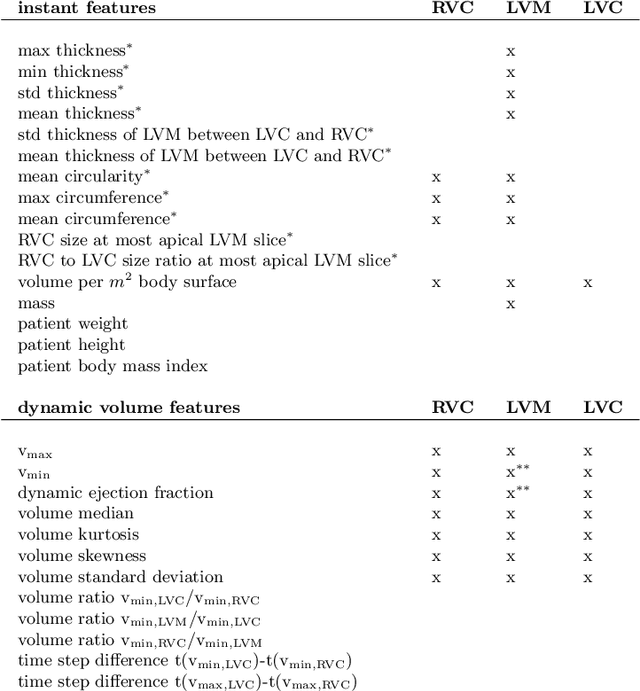
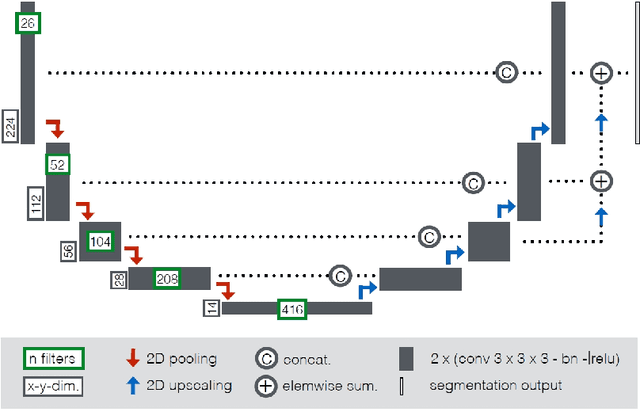
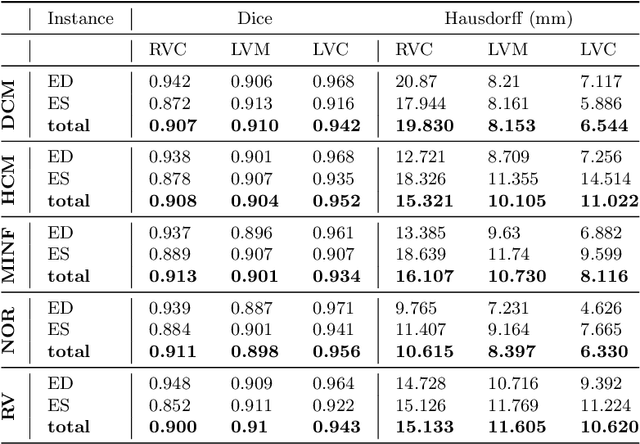
Cardiac magnetic resonance imaging improves on diagnosis of cardiovascular diseases by providing images at high spatiotemporal resolution. Manual evaluation of these time-series, however, is expensive and prone to biased and non-reproducible outcomes. In this paper, we present a method that addresses named limitations by integrating segmentation and disease classification into a fully automatic processing pipeline. We use an ensemble of UNet inspired architectures for segmentation of cardiac structures such as the left and right ventricular cavity (LVC, RVC) and the left ventricular myocardium (LVM) on each time instance of the cardiac cycle. For the classification task, information is extracted from the segmented time-series in form of comprehensive features handcrafted to reflect diagnostic clinical procedures. Based on these features we train an ensemble of heavily regularized multilayer perceptrons (MLP) and a random forest classifier to predict the pathologic target class. We evaluated our method on the ACDC dataset (4 pathology groups, 1 healthy group) and achieve dice scores of 0.945 (LVC), 0.908 (RVC) and 0.905 (LVM) in a cross-validation over the training set (100 cases) and 0.950 (LVC), 0.923 (RVC) and 0.911 (LVM) on the test set (50 cases). We report a classification accuracy of 94% on a training set cross-validation and 92% on the test set. Our results underpin the potential of machine learning methods for accurate, fast and reproducible segmentation and computer-assisted diagnosis (CAD).
PatentMatch: A Dataset for Matching Patent Claims & Prior Art
Dec 27, 2020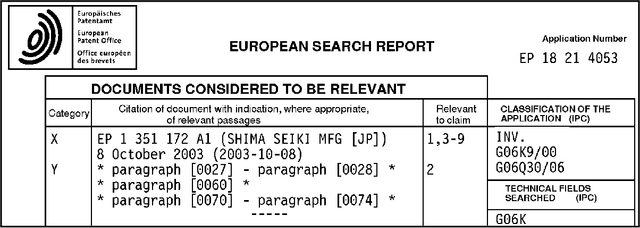
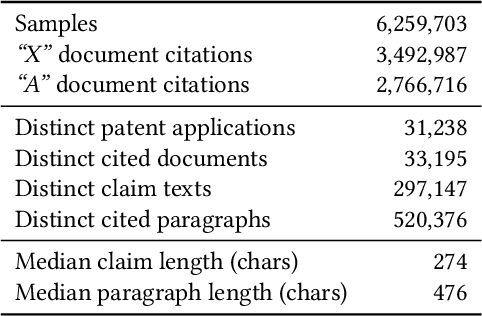
Patent examiners need to solve a complex information retrieval task when they assess the novelty and inventive step of claims made in a patent application. Given a claim, they search for prior art, which comprises all relevant publicly available information. This time-consuming task requires a deep understanding of the respective technical domain and the patent-domain-specific language. For these reasons, we address the computer-assisted search for prior art by creating a training dataset for supervised machine learning called PatentMatch. It contains pairs of claims from patent applications and semantically corresponding text passages of different degrees from cited patent documents. Each pair has been labeled by technically-skilled patent examiners from the European Patent Office. Accordingly, the label indicates the degree of semantic correspondence (matching), i.e., whether the text passage is prejudicial to the novelty of the claimed invention or not. Preliminary experiments using a baseline system show that PatentMatch can indeed be used for training a binary text pair classifier on this challenging information retrieval task. The dataset is available online: https://hpi.de/naumann/s/patentmatch.