 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Panarchy: ripples of a boundary concept
Dec 28, 2020
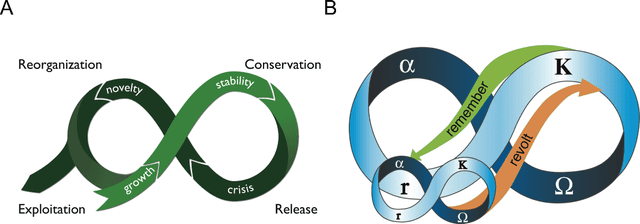
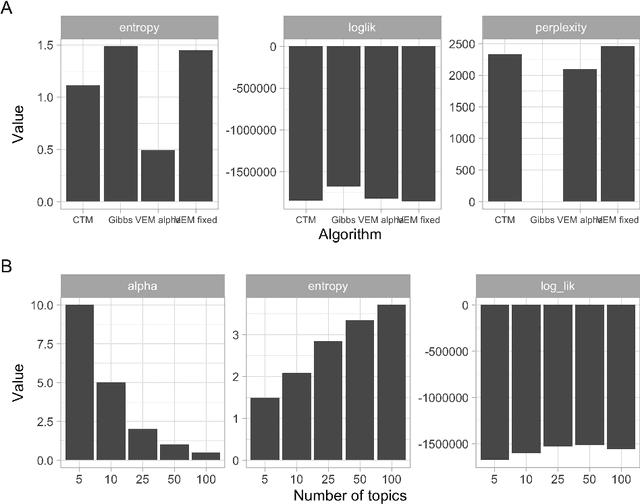
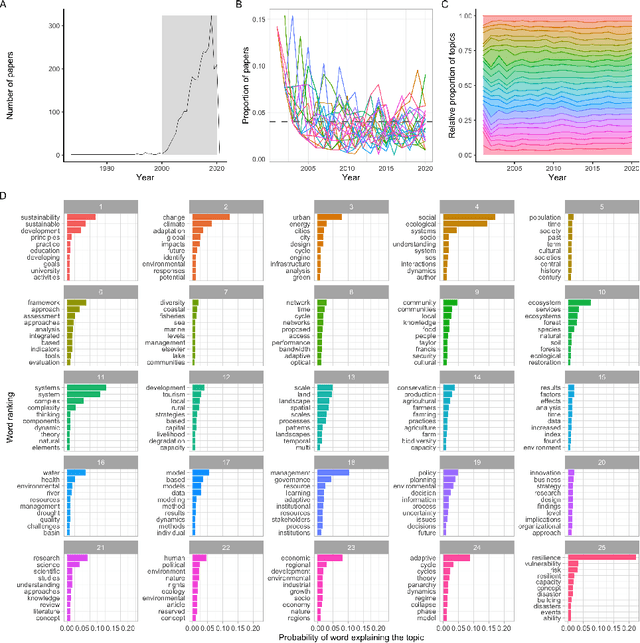
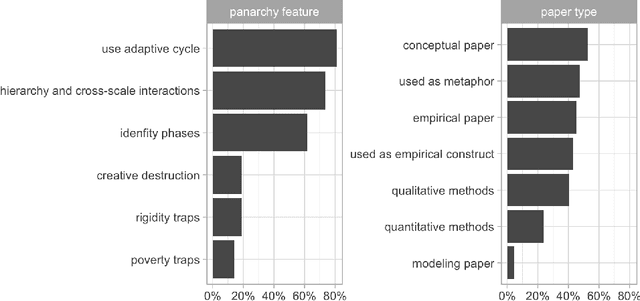
How do social-ecological systems change over time? In 2002 Holling and colleagues proposed the concept of Panarchy, which presented social-ecological systems as an interacting set of adaptive cycles, each of which is produced by the dynamic tensions between novelty and efficiency at multiple scales. Initially introduced as a conceptual framework and set of metaphors, panarchy has gained the attention of scholars across many disciplines and its ideas continue to inspire further conceptual developments. Almost twenty years after this concept was introduced we review how it has been used, tested, extended and revised. We do this by combining qualitative methods and machine learning. Document analysis was used to code panarchy features that are commonly used in the scientific literature (N = 42), a qualitative analysis that was complemented with topic modeling of 2177 documents. We find that the adaptive cycle is the feature of panarchy that has attracted the most attention. Challenges remain in empirically grounding the metaphor, but recent theoretical and empirical work offers some avenues for future research.
FC-GAGA: Fully Connected Gated Graph Architecture for Spatio-Temporal Traffic Forecasting
Jul 30, 2020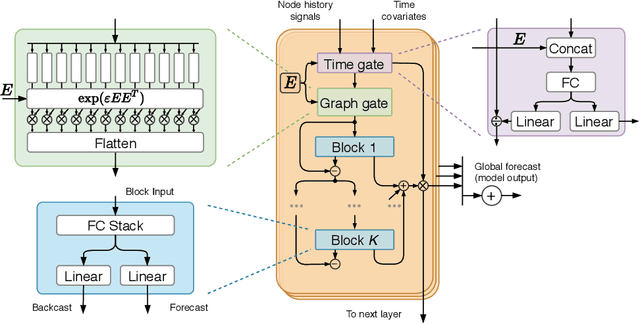
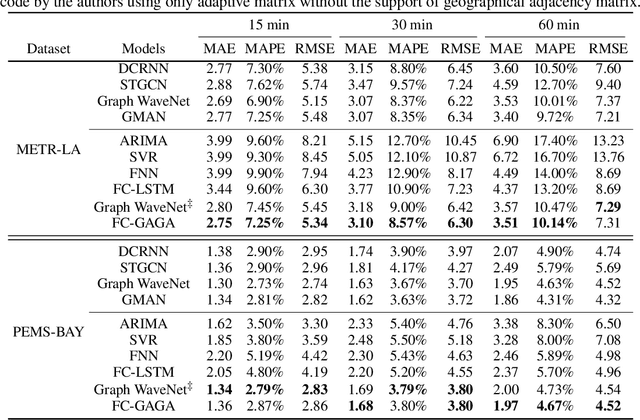
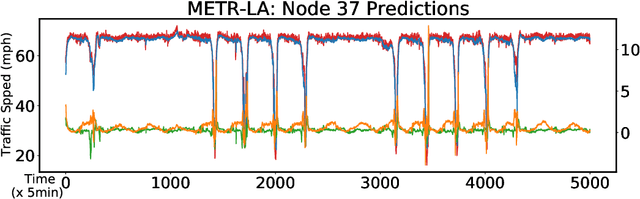
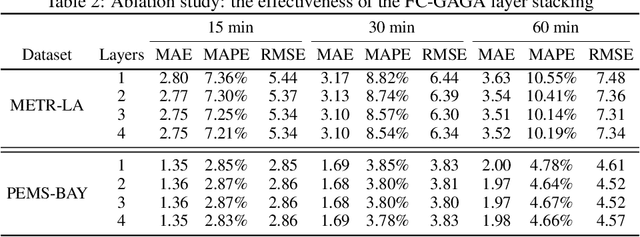
Forecasting of multivariate time-series is an important problem that has applications in many domains, including traffic management, cellular network configuration, and quantitative finance. In recent years, researchers have demonstrated the value of applying deep learning architectures for these problems. A special case of the problem arises when there is a graph available that captures the relationships between the time-series. In this paper we propose a novel learning architecture that achieves performance competitive with or better than the best existing algorithms, without requiring knowledge of the graph. The key elements of our proposed architecture are (i) jointly performing backcasting and forecasting with a deep fully-connected architecture; (ii) stacking multiple prediction modules that target successive residuals; and (iii) learning a separate causal relationship graph for each layer of the stack. We can view each layer as predicting a component of the time-series; the differing nature of the causal graphs at different layers can be interpreted as indicating that the multivariate predictive relationships differ for different components. Experimental results for two public traffic network datasets illustrate the value of our approach, and ablation studies confirm the importance of each element of the architecture.
A Unified Lottery Ticket Hypothesis for Graph Neural Networks
Feb 12, 2021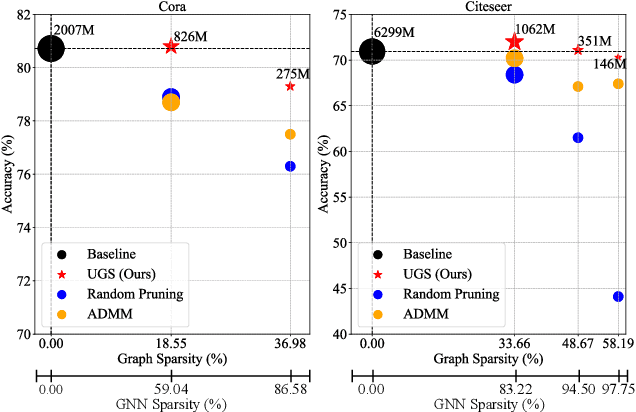
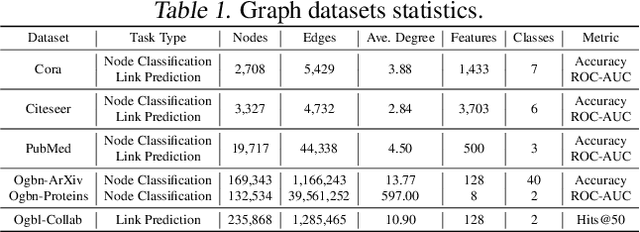
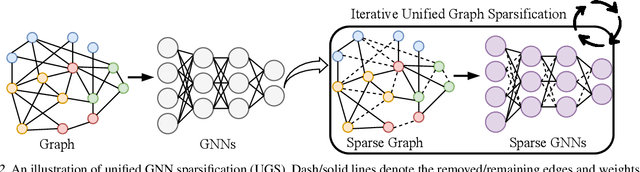
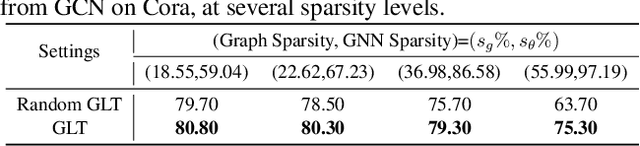
With graphs rapidly growing in size and deeper graph neural networks (GNNs) emerging, the training and inference of GNNs become increasingly expensive. Existing network weight pruning algorithms cannot address the main space and computational bottleneck in GNNs, caused by the size and connectivity of the graph. To this end, this paper first presents a unified GNN sparsification (UGS) framework that simultaneously prunes the graph adjacency matrix and the model weights, for effectively accelerating GNN inference on large-scale graphs. Leveraging this new tool, we further generalize the recently popular lottery ticket hypothesis to GNNs for the first time, by defining a graph lottery ticket (GLT) as a pair of core sub-dataset and sparse sub-network, which can be jointly identified from the original GNN and the full dense graph by iteratively applying UGS. Like its counterpart in convolutional neural networks, GLT can be trained in isolation to match the performance of training with the full model and graph, and can be drawn from both randomly initialized and self-supervised pre-trained GNNs. Our proposal has been experimentally verified across various GNN architectures and diverse tasks, on both small-scale graph datasets (Cora, Citeseer and PubMed), and large-scale datasets from the challenging Open Graph Benchmark (OGB). Specifically, for node classification, our found GLTs achieve the same accuracies with 20%~98% MACs saving on small graphs and 25%~85% MACs saving on large ones. For link prediction, GLTs lead to 48%~97% and 70% MACs saving on small and large graph datasets, respectively, without compromising predictive performance. Codes available at https://github.com/VITA-Group/Unified-LTH-GNN.
Expert Selection in High-Dimensional Markov Decision Processes
Oct 26, 2020
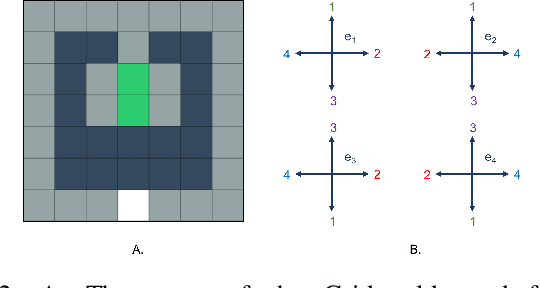
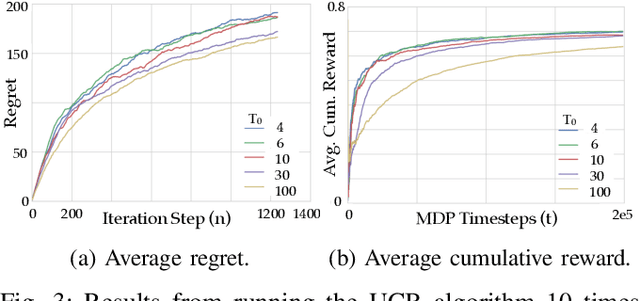
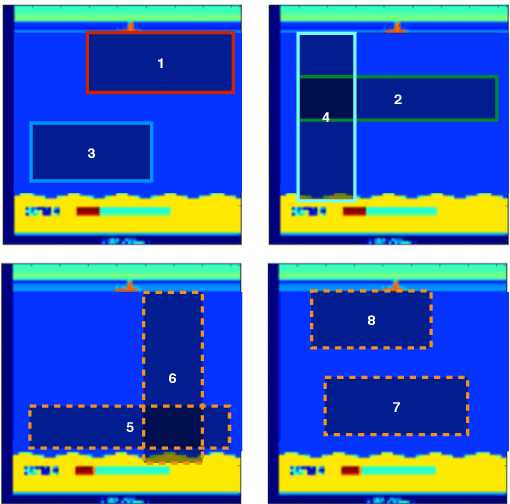
In this work we present a multi-armed bandit framework for online expert selection in Markov decision processes and demonstrate its use in high-dimensional settings. Our method takes a set of candidate expert policies and switches between them to rapidly identify the best performing expert using a variant of the classical upper confidence bound algorithm, thus ensuring low regret in the overall performance of the system. This is useful in applications where several expert policies may be available, and one needs to be selected at run-time for the underlying environment.
Time-Contrastive Networks: Self-Supervised Learning from Video
Mar 20, 2018

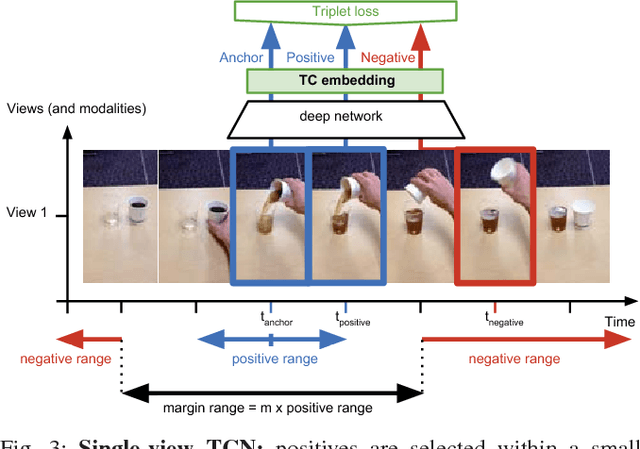
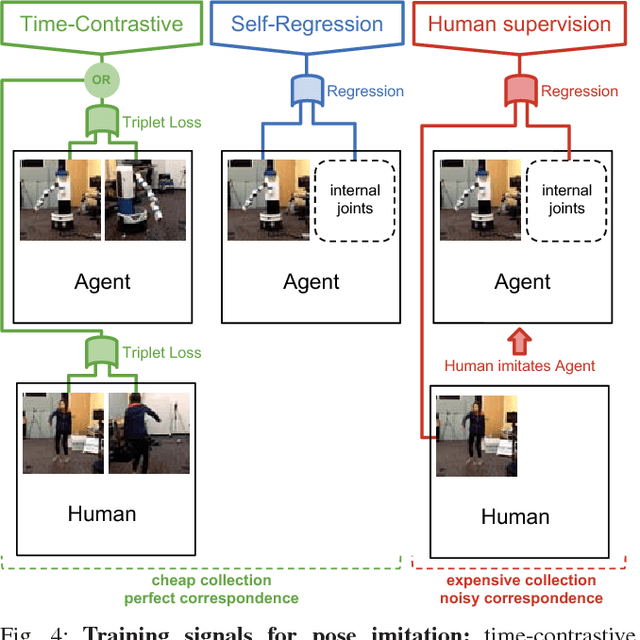
We propose a self-supervised approach for learning representations and robotic behaviors entirely from unlabeled videos recorded from multiple viewpoints, and study how this representation can be used in two robotic imitation settings: imitating object interactions from videos of humans, and imitating human poses. Imitation of human behavior requires a viewpoint-invariant representation that captures the relationships between end-effectors (hands or robot grippers) and the environment, object attributes, and body pose. We train our representations using a metric learning loss, where multiple simultaneous viewpoints of the same observation are attracted in the embedding space, while being repelled from temporal neighbors which are often visually similar but functionally different. In other words, the model simultaneously learns to recognize what is common between different-looking images, and what is different between similar-looking images. This signal causes our model to discover attributes that do not change across viewpoint, but do change across time, while ignoring nuisance variables such as occlusions, motion blur, lighting and background. We demonstrate that this representation can be used by a robot to directly mimic human poses without an explicit correspondence, and that it can be used as a reward function within a reinforcement learning algorithm. While representations are learned from an unlabeled collection of task-related videos, robot behaviors such as pouring are learned by watching a single 3rd-person demonstration by a human. Reward functions obtained by following the human demonstrations under the learned representation enable efficient reinforcement learning that is practical for real-world robotic systems. Video results, open-source code and dataset are available at https://sermanet.github.io/imitate
Trajectory Representation and Landmark Projection for Continuous-Time Structure from Motion
May 07, 2018

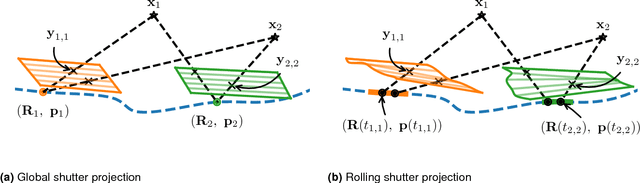
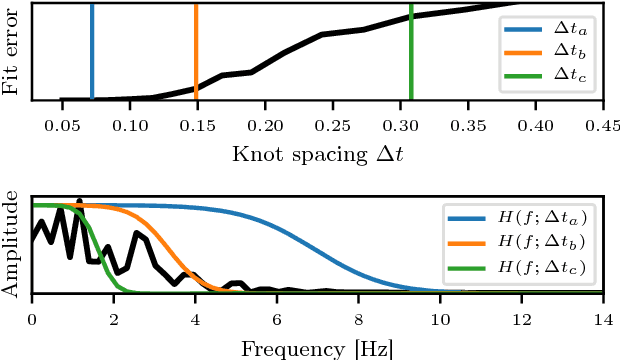
This paper revisits the problem of continuous-time structure from motion, and introduces a number of extensions that improve convergence and efficiency. The formulation with a $\mathcal{C}^2$-continuous spline for the trajectory naturally incorporates inertial measurements, as derivatives of the sought trajectory. We analyse the behaviour of split interpolation on $\mathbb{SO}(3)$ and on $\mathbb{R}^3$, and a joint interpolation on $\mathbb{SE}(3)$, and show that the latter implicitly couples the direction of translation and rotation. Such an assumption can make good sense for a camera mounted on a robot arm, but not for hand-held or body-mounted cameras. Our experiments show that split interpolation on $\mathbb{SO}(3)$ and on $\mathbb{R}^3$ is preferable over $\mathbb{SE}(3)$ interpolation in all tested cases. Finally, we investigate the problem of landmark reprojection on rolling shutter cameras, and show that the tested reprojection methods give similar quality, while their computational load varies by a factor of 2.
Achieving the time of $1$-NN, but the accuracy of $k$-NN
Dec 22, 2017
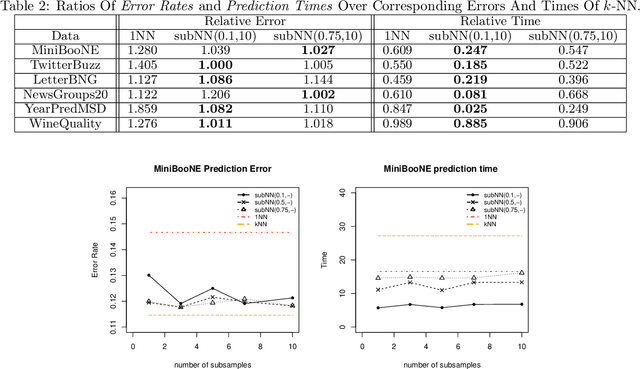
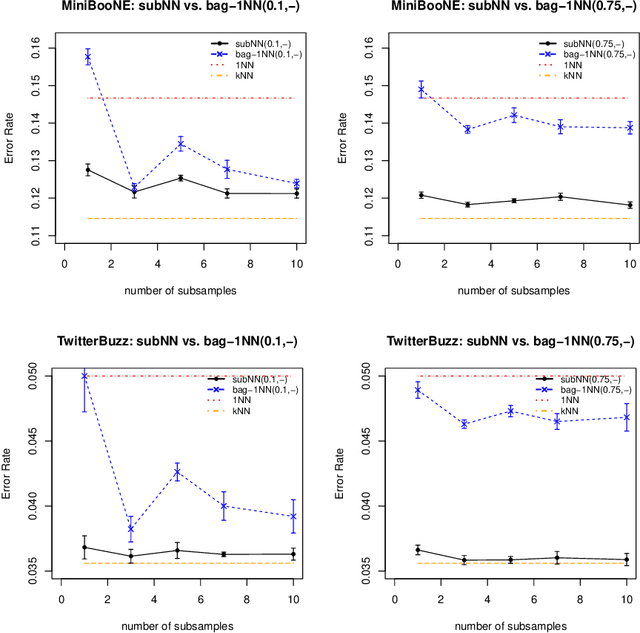
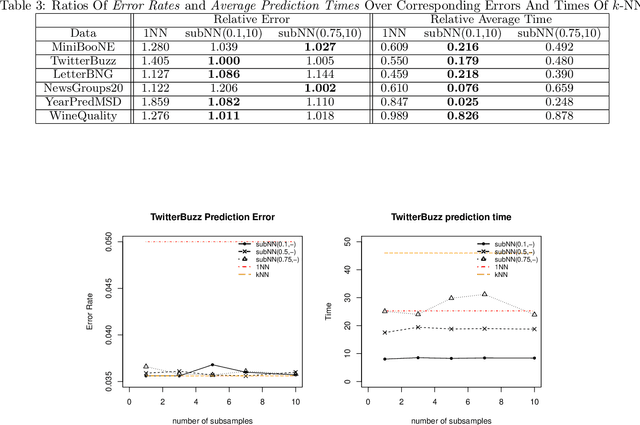
We propose a simple approach which, given distributed computing resources, can nearly achieve the accuracy of $k$-NN prediction, while matching (or improving) the faster prediction time of $1$-NN. The approach consists of aggregating denoised $1$-NN predictors over a small number of distributed subsamples. We show, both theoretically and experimentally, that small subsample sizes suffice to attain similar performance as $k$-NN, without sacrificing the computational efficiency of $1$-NN.
Statistical Evaluation of Anomaly Detectors for Sequences
Aug 13, 2020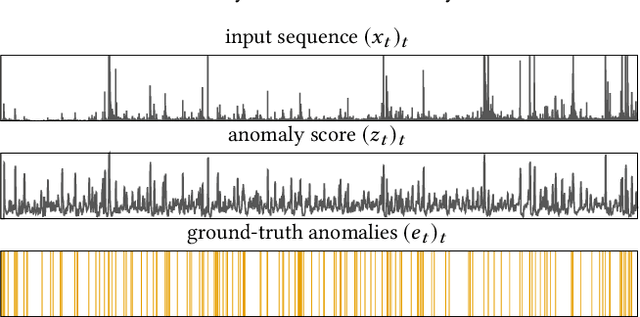

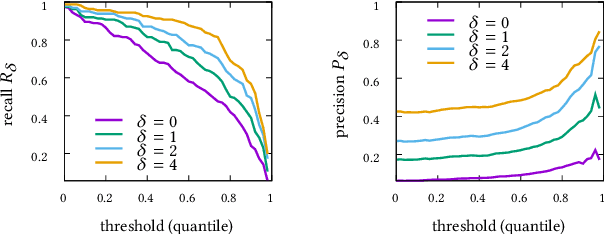

Although precision and recall are standard performance measures for anomaly detection, their statistical properties in sequential detection settings are poorly understood. In this work, we formalize a notion of precision and recall with temporal tolerance for point-based anomaly detection in sequential data. These measures are based on time-tolerant confusion matrices that may be used to compute time-tolerant variants of many other standard measures. However, care has to be taken to preserve interpretability. We perform a statistical simulation study to demonstrate that precision and recall may overestimate the performance of a detector, when computed with temporal tolerance. To alleviate this problem, we show how to obtain null distributions for the two measures to assess the statistical significance of reported results.
Neural Architecture Search with an Efficient Multiobjective Evolutionary Framework
Nov 09, 2020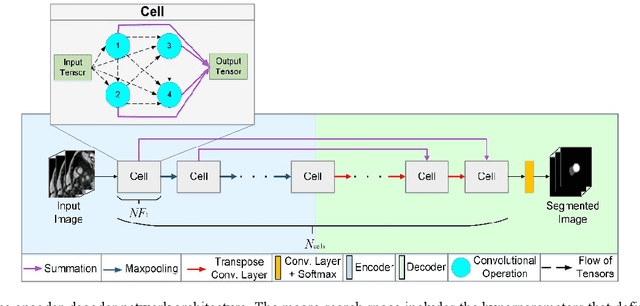

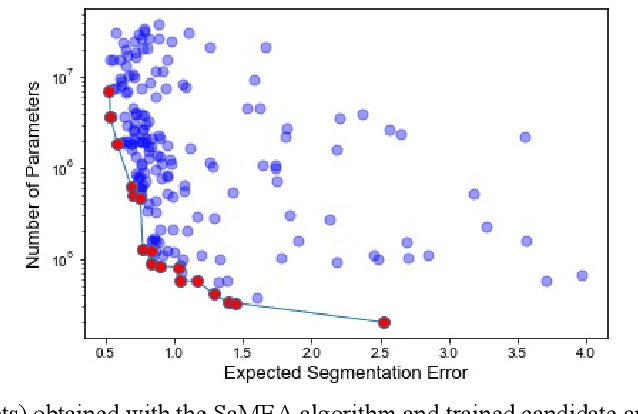
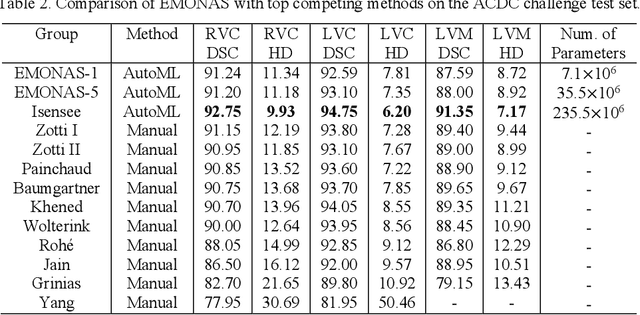
Deep learning methods have become very successful at solving many complex tasks such as image classification and segmentation, speech recognition and machine translation. Nevertheless, manually designing a neural network for a specific problem is very difficult and time-consuming due to the massive hyperparameter search space, long training times, and lack of technical guidelines for the hyperparameter selection. Moreover, most networks are highly complex, task specific and over-parametrized. Recently, multiobjective neural architecture search (NAS) methods have been proposed to automate the design of accurate and efficient architectures. However, they only optimize either the macro- or micro-structure of the architecture requiring the unset hyperparameters to be manually defined, and do not use the information produced during the optimization process to increase the efficiency of the search. In this work, we propose EMONAS, an Efficient MultiObjective Neural Architecture Search framework for the automatic design of neural architectures while optimizing the network's accuracy and size. EMONAS is composed of a search space that considers both the macro- and micro-structure of the architecture, and a surrogate-assisted multiobjective evolutionary based algorithm that efficiently searches for the best hyperparameters using a Random Forest surrogate and guiding selection probabilities. EMONAS is evaluated on the task of 3D cardiac segmentation from the MICCAI ACDC challenge, which is crucial for disease diagnosis, risk evaluation, and therapy decision. The architecture found with EMONAS is ranked within the top 10 submissions of the challenge in all evaluation metrics, performing better or comparable to other approaches while reducing the search time by more than 50% and having considerably fewer number of parameters.
Multi-Task Learning for Interpretable Weakly Labelled Sound Event Detection
Aug 17, 2020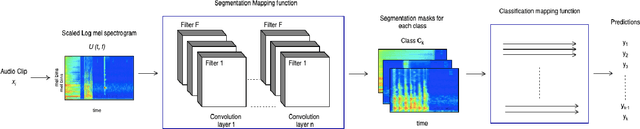
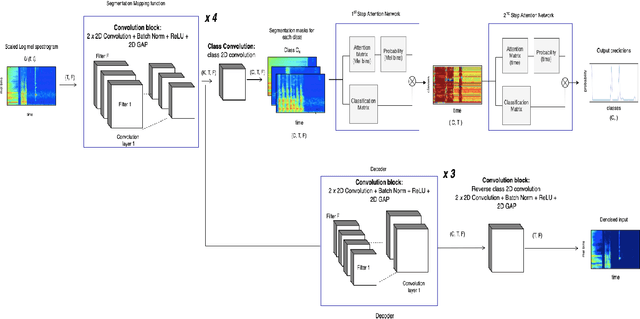
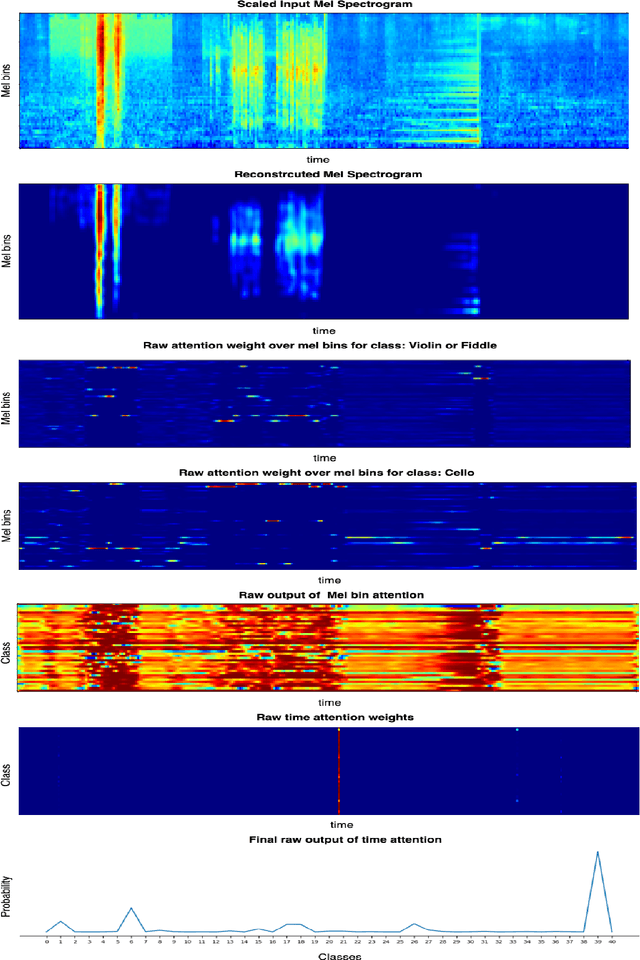

Weakly Labelled learning has garnered lot of attention in recent years due to its potential to scale Sound Event Detection (SED). The paper proposes a Multi-Task Learning (MTL) framework for learning from Weakly Labelled Audio data which encompasses the traditional Multiple Instance Learning (MIL) setup. The MTL framework uses two-step attention mechanism and reconstructs Time Frequency (T-F) representation of audio as the auxiliary task. By breaking the attention into two steps, the network retains better time level information without compromising classification performance. The auxiliary task uses an auto-encoder structure to encourage the network for retaining source specific information. This indirectly de-noises internal T- F representation and improves classification performance under noisy recordings. For evaluation of proposed methodology, we remix the DCASE 2019 task 1 acoustic scene data with DCASE 2018 Task 2 sounds event data under 0, 10 and 20 db SNR. The proposed network outperforms existing benchmark models over all SNRs, specifically 22.3 %, 12.8 %, 5.9 % improvement over benchmark model on 0, 10 and 20 dB SNR respectively. The results and ablation study performed demonstrates the usefulness of auto-encoder for auxiliary task and verifies that the output of decoder portion provides a cleaned Time Frequency (T-F) representation of audio/sources which can be further used for source separation. The code is publicly released.