 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Examining Deep Learning Models with Multiple Data Sources for COVID-19 Forecasting
Oct 27, 2020
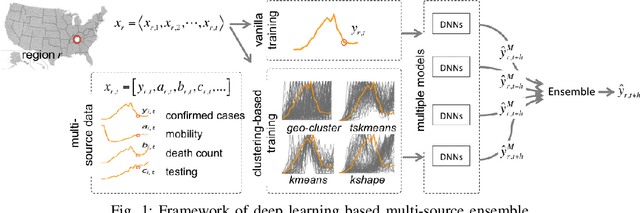
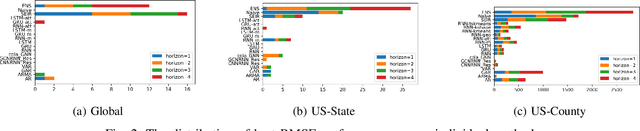
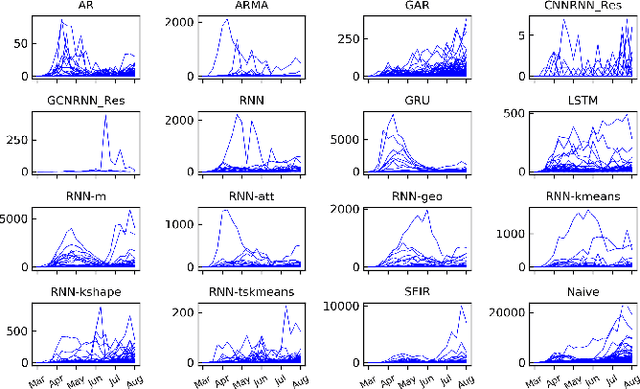
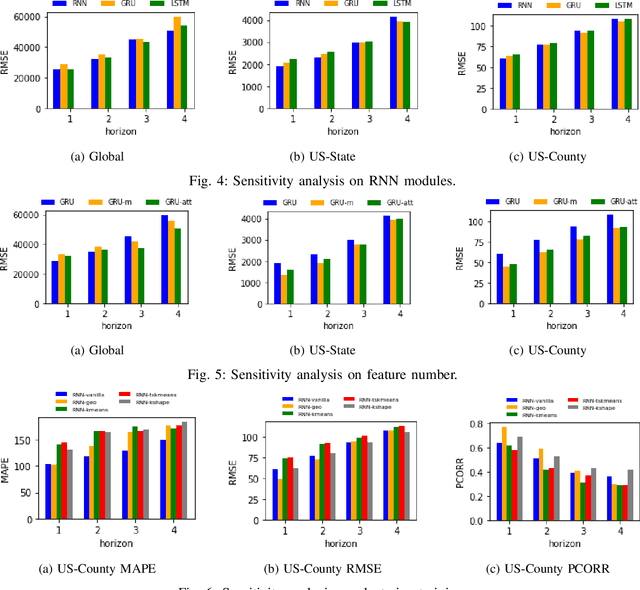
The COVID-19 pandemic represents the most significant public health disaster since the 1918 influenza pandemic. During pandemics such as COVID-19, timely and reliable spatio-temporal forecasting of epidemic dynamics is crucial. Deep learning-based time series models for forecasting have recently gained popularity and have been successfully used for epidemic forecasting. Here we focus on the design and analysis of deep learning-based models for COVID-19 forecasting. We implement multiple recurrent neural network-based deep learning models and combine them using the stacking ensemble technique. In order to incorporate the effects of multiple factors in COVID-19 spread, we consider multiple sources such as COVID-19 testing data and human mobility data for better predictions. To overcome the sparsity of training data and to address the dynamic correlation of the disease, we propose clustering-based training for high-resolution forecasting. The methods help us to identify the similar trends of certain groups of regions due to various spatio-temporal effects. We examine the proposed method for forecasting weekly COVID-19 new confirmed cases at county-, state-, and country-level. A comprehensive comparison between different time series models in COVID-19 context is conducted and analyzed. The results show that simple deep learning models can achieve comparable or better performance when compared with more complicated models. We are currently integrating our methods as a part of our weekly forecasts that we provide state and federal authorities.
Federated Intrusion Detection for IoT with Heterogeneous Cohort Privacy
Jan 25, 2021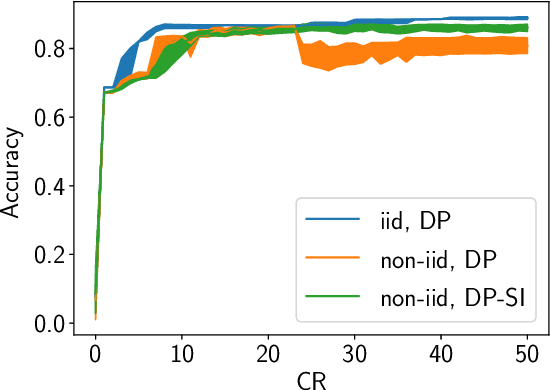
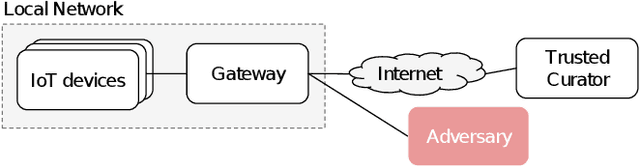
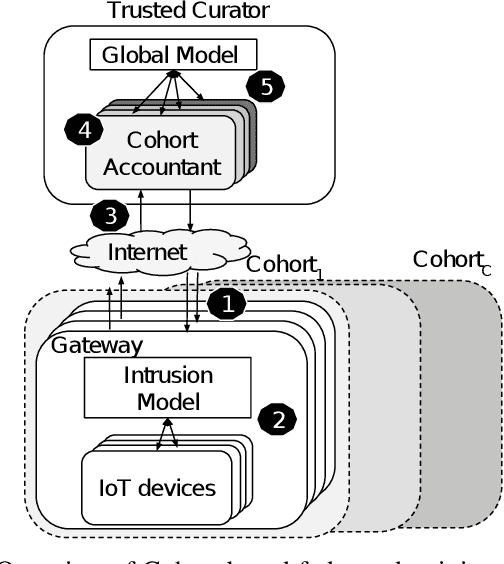
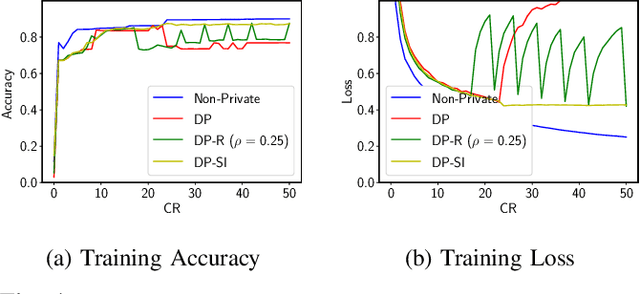
Internet of Things (IoT) devices are becoming increasingly popular and are influencing many application domains such as healthcare and transportation. These devices are used for real-world applications such as sensor monitoring, real-time control. In this work, we look at differentially private (DP) neural network (NN) based network intrusion detection systems (NIDS) to detect intrusion attacks on networks of such IoT devices. Existing NN training solutions in this domain either ignore privacy considerations or assume that the privacy requirements are homogeneous across all users. We show that the performance of existing differentially private stochastic methods degrade for clients with non-identical data distributions when clients' privacy requirements are heterogeneous. We define a cohort-based $(\epsilon,\delta)$-DP framework that models the more practical setting of IoT device cohorts with non-identical clients and heterogeneous privacy requirements. We propose two novel continual-learning based DP training methods that are designed to improve model performance in the aforementioned setting. To the best of our knowledge, ours is the first system that employs a continual learning-based approach to handle heterogeneity in client privacy requirements. We evaluate our approach on real datasets and show that our techniques outperform the baselines. We also show that our methods are robust to hyperparameter changes. Lastly, we show that one of our proposed methods can easily adapt to post-hoc relaxations of client privacy requirements.
Network Automatic Pruning: Start NAP and Take a Nap
Jan 17, 2021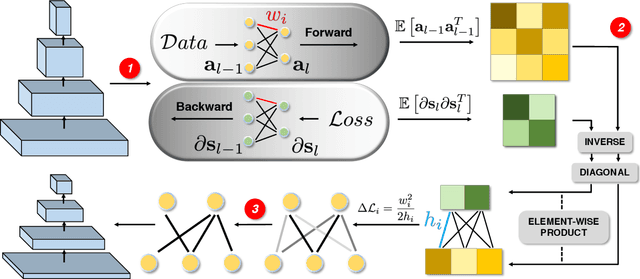
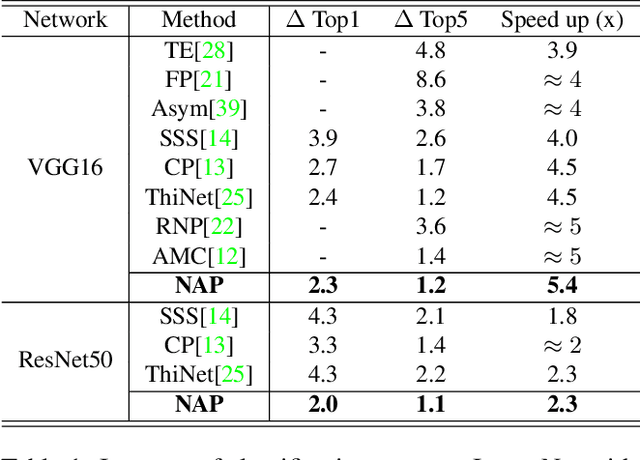
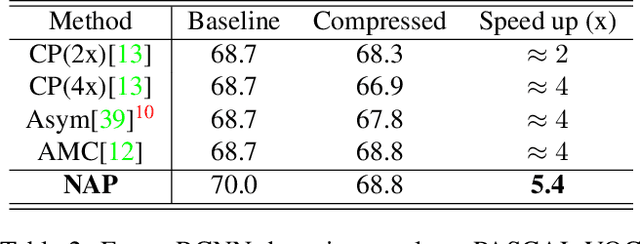
Network pruning can significantly reduce the computation and memory footprint of large neural networks. To achieve a good trade-off between model size and performance, popular pruning techniques usually rely on hand-crafted heuristics and require manually setting the compression ratio for each layer. This process is typically time-consuming and requires expert knowledge to achieve good results. In this paper, we propose NAP, a unified and automatic pruning framework for both fine-grained and structured pruning. It can find out unimportant components of a network and automatically decide appropriate compression ratios for different layers, based on a theoretically sound criterion. Towards this goal, NAP uses an efficient approximation of the Hessian for evaluating the importances of components, based on a Kronecker-factored Approximate Curvature method. Despite its simpleness to use, NAP outperforms previous pruning methods by large margins. For fine-grained pruning, NAP can compress AlexNet and VGG16 by 25x, and ResNet-50 by 6.7x without loss in accuracy on ImageNet. For structured pruning (e.g. channel pruning), it can reduce flops of VGG16 by 5.4x and ResNet-50 by 2.3x with only 1% accuracy drop. More importantly, this method is almost free from hyper-parameter tuning and requires no expert knowledge. You can start NAP and then take a nap!
Simulating SQL Injection Vulnerability Exploitation Using Q-Learning Reinforcement Learning Agents
Jan 08, 2021
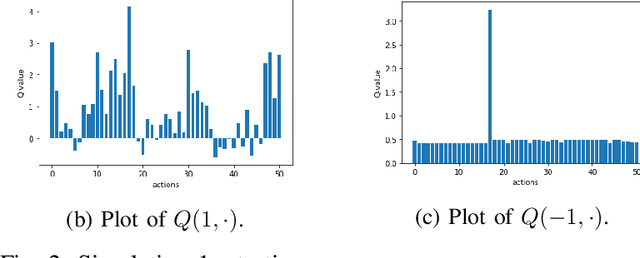
In this paper, we propose a first formalization of the process of exploitation of SQL injection vulnerabilities. We consider a simplification of the dynamics of SQL injection attacks by casting this problem as a security capture-the-flag challenge. We model it as a Markov decision process, and we implement it as a reinforcement learning problem. We then deploy different reinforcement learning agents tasked with learning an effective policy to perform SQL injection; we design our training in such a way that the agent learns not just a specific strategy to solve an individual challenge but a more generic policy that may be applied to perform SQL injection attacks against any system instantiated randomly by our problem generator. We analyze the results in terms of the quality of the learned policy and in terms of convergence time as a function of the complexity of the challenge and the learning agent's complexity. Our work fits in the wider research on the development of intelligent agents for autonomous penetration testing and white-hat hacking, and our results aim to contribute to understanding the potential and the limits of reinforcement learning in a security environment.
Unsupervised learning for economic risk evaluation in the context of Covid-19 pandemic
Nov 26, 2020

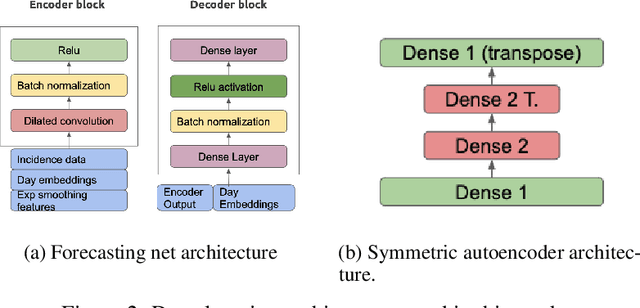
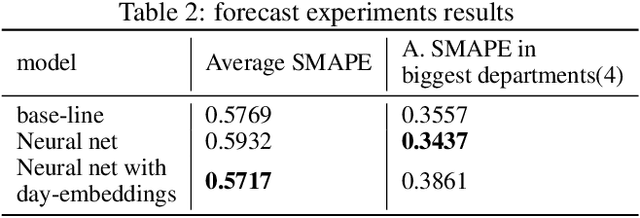
Justifying draconian measures during the Covid-19 pandemic was difficult not only because of the restriction of individual rights, but also because of its economic impact. The objective of this work is to present a machine learning approach to identify regions that should implement similar health policies. For that end, we successfully developed a system that gives a notion of economic impact given the prediction of new incidental cases through unsupervised learning and time series forecasting. This system was built taking into account computational restrictions and low maintenance requirements in order to improve the system's resilience. Finally this system was deployed as part of a web application for simulation and data analysis of COVID-19, in Colombia, available at (https://covid19.dis.eafit.edu.co).
TSEC: a framework for online experimentation under experimental constraints
Jan 17, 2021



Thompson sampling is a popular algorithm for solving multi-armed bandit problems, and has been applied in a wide range of applications, from website design to portfolio optimization. In such applications, however, the number of choices (or arms) $N$ can be large, and the data needed to make adaptive decisions require expensive experimentation. One is then faced with the constraint of experimenting on only a small subset of $K \ll N$ arms within each time period, which poses a problem for traditional Thompson sampling. We propose a new Thompson Sampling under Experimental Constraints (TSEC) method, which addresses this so-called "arm budget constraint". TSEC makes use of a Bayesian interaction model with effect hierarchy priors, to model correlations between rewards on different arms. This fitted model is then integrated within Thompson sampling, to jointly identify a good subset of arms for experimentation and to allocate resources over these arms. We demonstrate the effectiveness of TSEC in two problems with arm budget constraints. The first is a simulated website optimization study, where TSEC shows noticeable improvements over industry benchmarks. The second is a portfolio optimization application on industry-based exchange-traded funds, where TSEC provides more consistent and greater wealth accumulation over standard investment strategies.
Inferring Symbolic Automata
Nov 12, 2020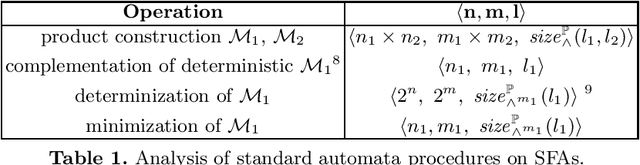

We study the learnability of {symbolic finite state automata}, a model shown useful in many applications in software verification. The state-of-the-art literature on this topic follows the {query learning} paradigm, and so far all obtained results are positive. We provide a necessary condition for efficient learnability of SFAs in this paradigm, from which we obtain the first negative result. Most of this work studies learnability of SFAs under the paradigm of {identification in the limit using polynomial time and data}. We provide a sufficient condition for efficient learnability of SFAs in this paradigm, as well as a necessary condition, and provide several positive and negative results.
Rethinking Attention with Performers
Sep 30, 2020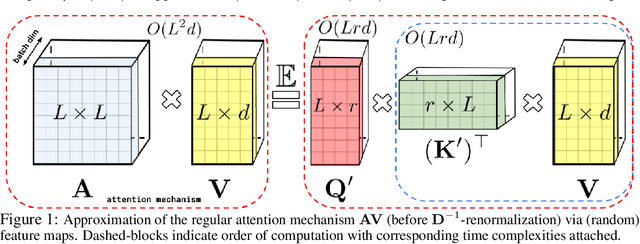
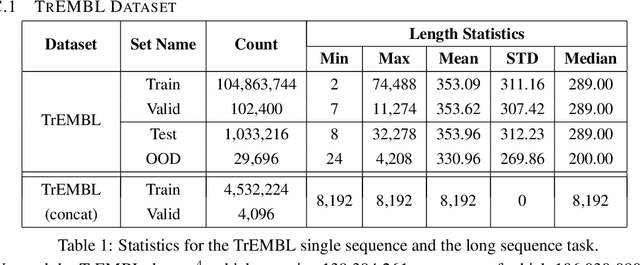
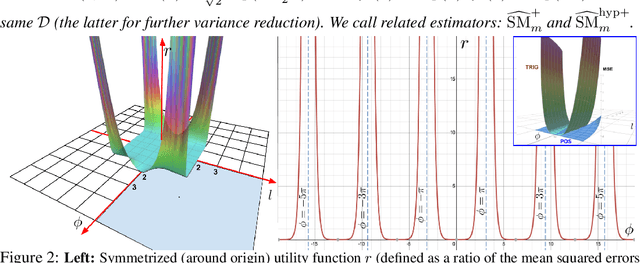
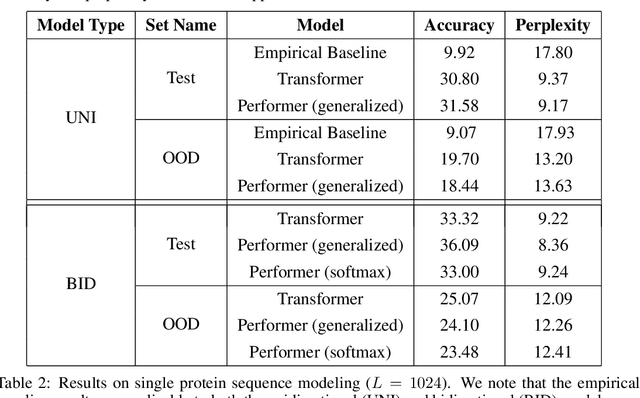
We introduce Performers, Transformer architectures which can estimate regular (softmax) full-rank-attention Transformers with provable accuracy, but using only linear (as opposed to quadratic) space and time complexity, without relying on any priors such as sparsity or low-rankness. To approximate softmax attention-kernels, Performers use a novel Fast Attention Via positive Orthogonal Random features approach (FAVOR+), which may be of independent interest for scalable kernel methods. FAVOR+ can be also used to efficiently model kernelizable attention mechanisms beyond softmax. This representational power is crucial to accurately compare softmax with other kernels for the first time on large-scale tasks, beyond the reach of regular Transformers, and investigate optimal attention-kernels. Performers are linear architectures fully compatible with regular Transformers and with strong theoretical guarantees: unbiased or nearly-unbiased estimation of the attention matrix, uniform convergence and low estimation variance. We tested Performers on a rich set of tasks stretching from pixel-prediction through text models to protein sequence modeling. We demonstrate competitive results with other examined efficient sparse and dense attention methods, showcasing effectiveness of the novel attention-learning paradigm leveraged by Performers.
Real-time Teaching Cues for Automated Surgical Coaching
Apr 24, 2017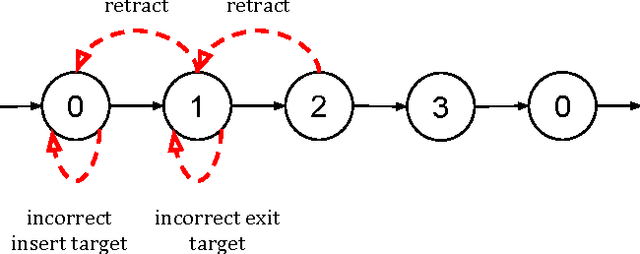
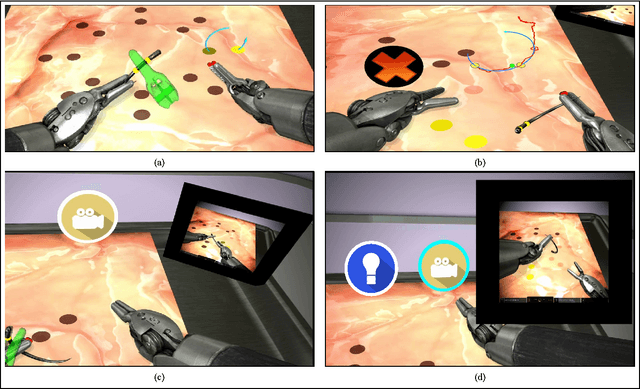
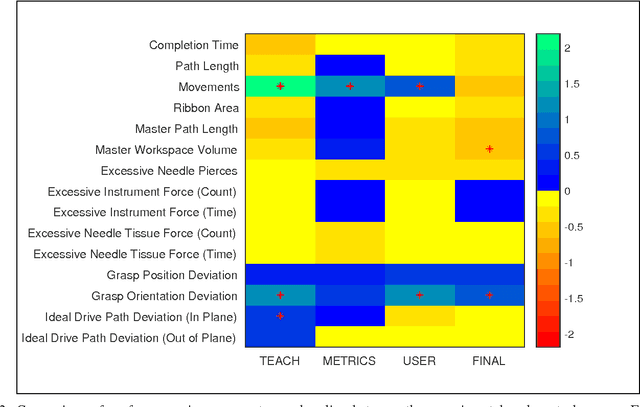
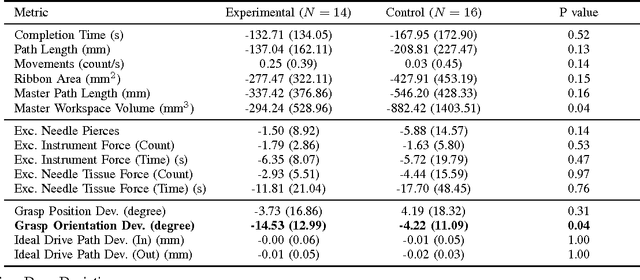
With introduction of new technologies in the operating room like the da Vinci Surgical System, training surgeons to use them effectively and efficiently is crucial in the delivery of better patient care. Coaching by an expert surgeon is effective in teaching relevant technical skills, but current methods to deliver effective coaching are limited and not scalable. We present a virtual reality simulation-based framework for automated virtual coaching in surgical education. We implement our framework within the da Vinci Skills Simulator. We provide three coaching modes ranging from a hands-on teacher (continuous guidance) to a handsoff guide (assistance upon request). We present six teaching cues targeted at critical learning elements of a needle passing task, which are shown to the user based on the coaching mode. These cues are graphical overlays which guide the user, inform them about sub-par performance, and show relevant video demonstrations. We evaluated our framework in a pilot randomized controlled trial with 16 subjects in each arm. In a post-study questionnaire, participants reported high comprehension of feedback, and perceived improvement in performance. After three practice repetitions of the task, the control arm (independent learning) showed better motion efficiency whereas the experimental arm (received real-time coaching) had better performance of learning elements (as per the ACS Resident Skills Curriculum). We observed statistically higher improvement in the experimental group based on one of the metrics (related to needle grasp orientation). In conclusion, we developed an automated coach that provides real-time cues for surgical training and demonstrated its feasibility.
Single-partition adaptive Q-learning
Jul 14, 2020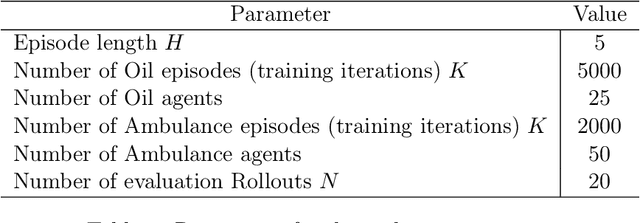
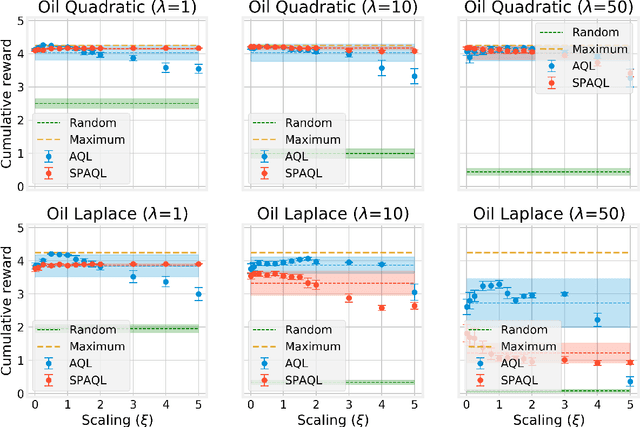
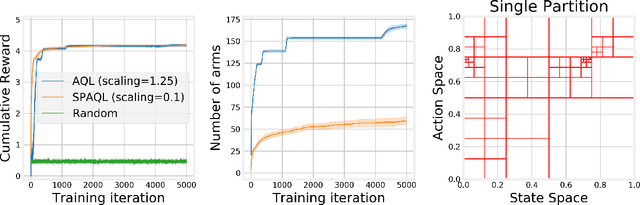
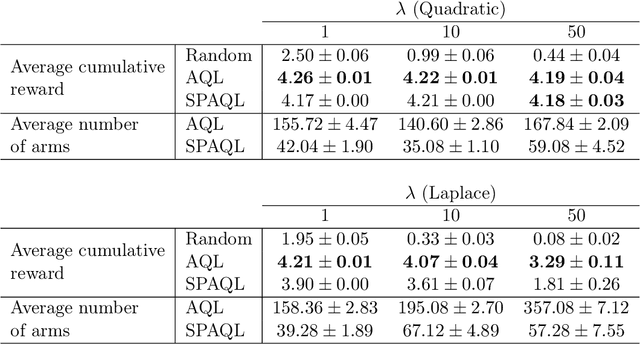
This paper introduces single-partition adaptive Q-learning (SPAQL), an algorithm for model-free episodic reinforcement learning (RL), which adaptively partitions the state-action space of a Markov decision process (MDP), while simultaneously learning a time-invariant policy (i. e., the mapping from states to actions does not depend explicitly on the episode time step) for maximizing the cumulative reward. The trade-off between exploration and exploitation is handled by using a mixture of upper confidence bounds (UCB) and Boltzmann exploration during training, with a temperature parameter that is automatically tuned as training progresses. The algorithm is an improvement over adaptive Q-learning (AQL). It converges faster to the optimal solution, while also using fewer arms. Tests on episodes with a large number of time steps show that SPAQL has no problems scaling, unlike AQL. Based on this empirical evidence, we claim that SPAQL may have a higher sample efficiency than AQL, thus being a relevant contribution to the field of efficient model-free RL methods.