 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Non-Parallel Voice Conversion with Augmented Classifier Star Generative Adversarial Networks
Sep 11, 2020
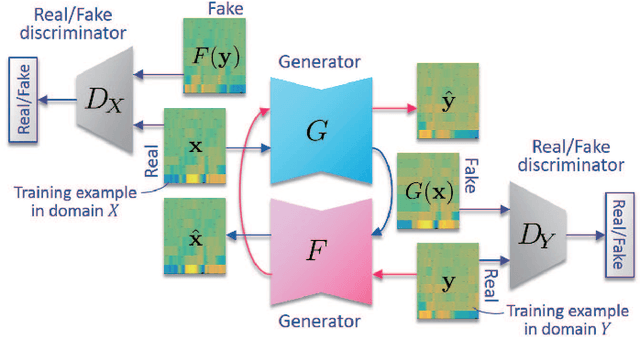
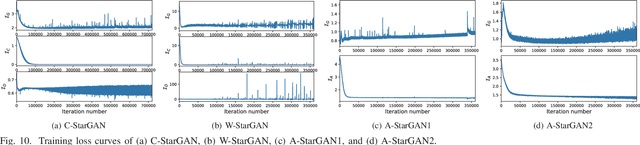
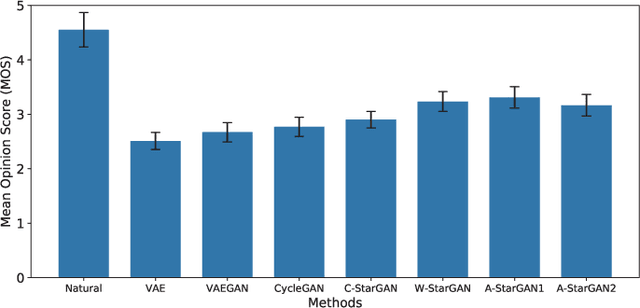
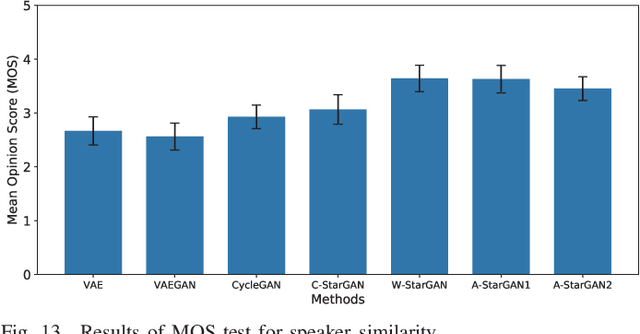
We previously proposed a method that allows for non-parallel voice conversion (VC) by using a variant of generative adversarial networks (GANs) called StarGAN. The main features of our method, called StarGAN-VC, are as follows: First, it requires no parallel utterances, transcriptions, or time alignment procedures for speech generator training. Second, it can simultaneously learn mappings across multiple domains using a single generator network so that it can fully exploit available training data collected from multiple domains to capture latent features that are common to all the domains. Third, it is able to generate converted speech signals quickly enough to allow real-time implementations and requires only several minutes of training examples to generate reasonably realistic-sounding speech. In this paper, we describe three formulations of StarGAN, including a newly introduced novel StarGAN variant called "Augmented classifier StarGAN (A-StarGAN)", and compare them in a non-parallel VC task. We also compare them with several baseline methods.
EmpLite: A Lightweight Sequence Labeling Model for Emphasis Selection of Short Texts
Dec 15, 2020
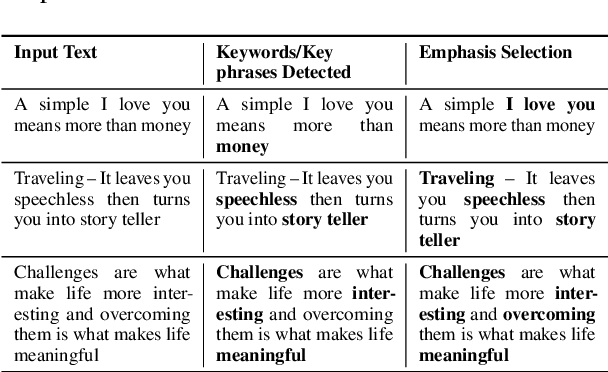

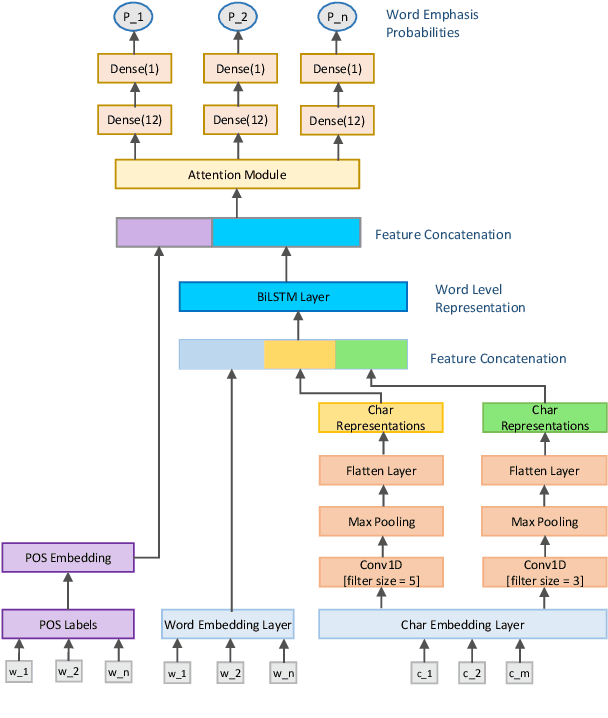
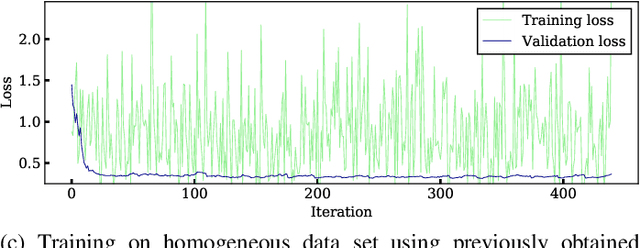
Word emphasis in textual content aims at conveying the desired intention by changing the size, color, typeface, style (bold, italic, etc.), and other typographical features. The emphasized words are extremely helpful in drawing the readers' attention to specific information that the authors wish to emphasize. However, performing such emphasis using a soft keyboard for social media interactions is time-consuming and has an associated learning curve. In this paper, we propose a novel approach to automate the emphasis word detection on short written texts. To the best of our knowledge, this work presents the first lightweight deep learning approach for smartphone deployment of emphasis selection. Experimental results show that our approach achieves comparable accuracy at a much lower model size than existing models. Our best lightweight model has a memory footprint of 2.82 MB with a matching score of 0.716 on SemEval-2020 public benchmark dataset.
Segmentation and Defect Classification of the Power Line Insulators: A Deep Learning-based Approach
Sep 21, 2020

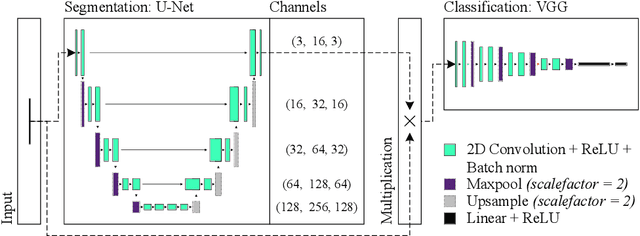
Power transmission network physically connects the power generators to the electric consumers extending over hundreds of kilometers. There are many components in the transmission infrastructure that requires a proper inspection to guarantee flawless performance and reliable delivery, which, if done manually, can be very costly and time taking. One of the essential components is the insulator, where its failure could cause the interruption of the entire transmission line or widespread power failure. Automated fault detection of insulators could significantly decrease inspection time and its related cost. Recently, several works have been proposed based on convolutional neural networks to deal with the issue mentioned above. However, the existing studies in the literature focus on specific types of fault for insulators. Thus, in this study, we introduce a two-stage model in which we first segment insulators from the background images and then classify its state into four different categories, namely: healthy, broken, burned, and missing cap. The test results show that the proposed approach can realize the effective segmentation of insulators and achieve high accuracy in detecting several types of faults.
An Efficient K-means Clustering Algorithm for Analysing COVID-19
Dec 21, 2020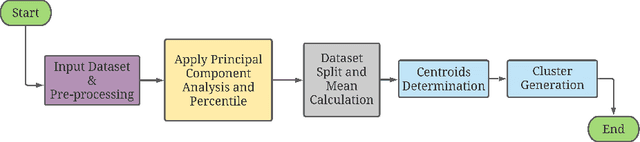
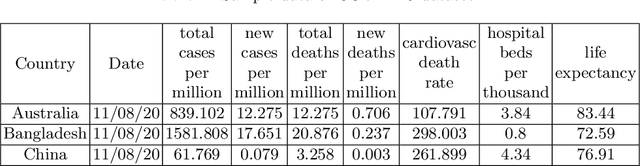
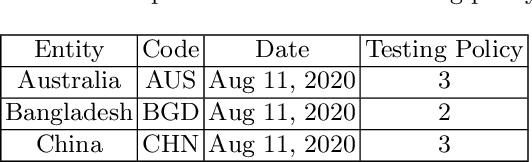
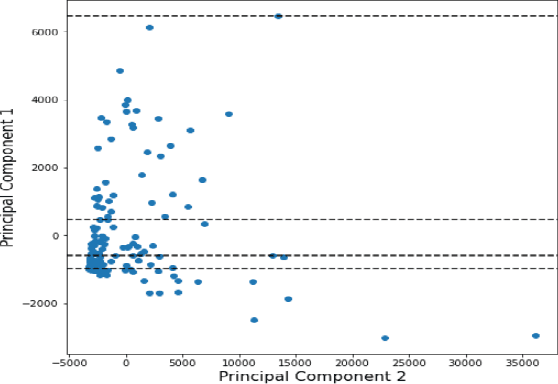
COVID-19 hits the world like a storm by arising pandemic situations for most of the countries around the world. The whole world is trying to overcome this pandemic situation. A better health care quality may help a country to tackle the pandemic. Making clusters of countries with similar types of health care quality provides an insight into the quality of health care in different countries. In the area of machine learning and data science, the K-means clustering algorithm is typically used to create clusters based on similarity. In this paper, we propose an efficient K-means clustering method that determines the initial centroids of the clusters efficiently. Based on this proposed method, we have determined health care quality clusters of countries utilizing the COVID-19 datasets. Experimental results show that our proposed method reduces the number of iterations and execution time to analyze COVID-19 while comparing with the traditional k-means clustering algorithm.
A Sparse Sampling-based framework for Semantic Fast-Forward of First-Person Videos
Sep 21, 2020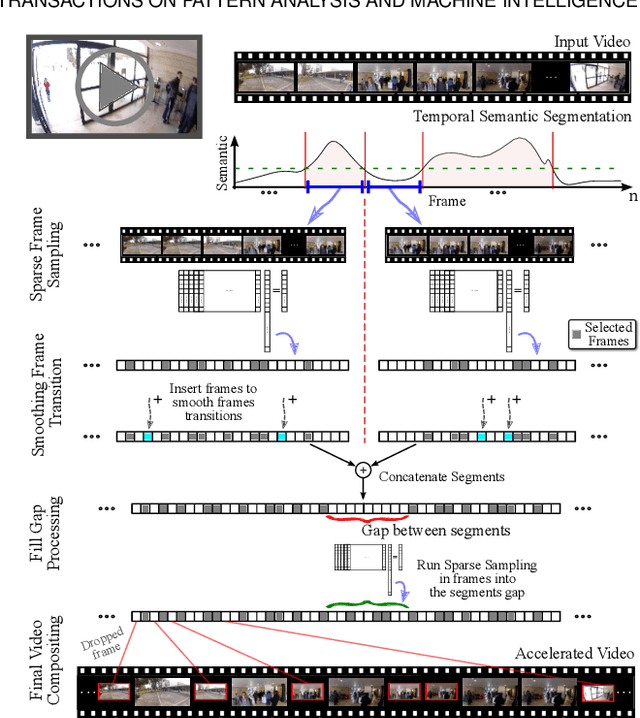
Technological advances in sensors have paved the way for digital cameras to become increasingly ubiquitous, which, in turn, led to the popularity of the self-recording culture. As a result, the amount of visual data on the Internet is moving in the opposite direction of the available time and patience of the users. Thus, most of the uploaded videos are doomed to be forgotten and unwatched stashed away in some computer folder or website. In this paper, we address the problem of creating smooth fast-forward videos without losing the relevant content. We present a new adaptive frame selection formulated as a weighted minimum reconstruction problem. Using a smoothing frame transition and filling visual gaps between segments, our approach accelerates first-person videos emphasizing the relevant segments and avoids visual discontinuities. Experiments conducted on controlled videos and also on an unconstrained dataset of First-Person Videos (FPVs) show that, when creating fast-forward videos, our method is able to retain as much relevant information and smoothness as the state-of-the-art techniques, but in less processing time.
Finite-Time Stabilization of Longitudinal Control for Autonomous Vehicles via a Model-Free Approach
Apr 05, 2017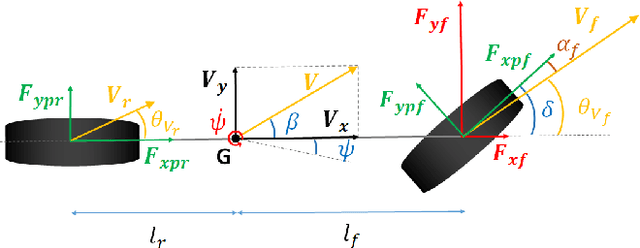

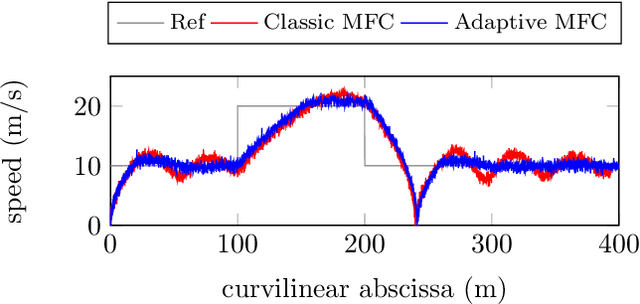
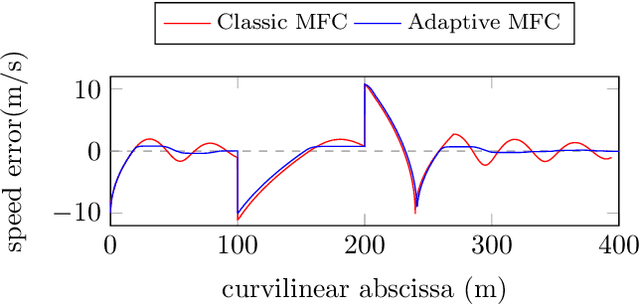
This communication presents a longitudinal model-free control approach for computing the wheel torque command to be applied on a vehicle. This setting enables us to overcome the problem of unknown vehicle parameters for generating a suitable control law. An important parameter in this control setting is made time-varying for ensuring finite-time stability. Several convincing computer simulations are displayed and discussed. Overshoots become therefore smaller. The driving comfort is increased and the robustness to time-delays is improved.
Predicting respondent difficulty in web surveys: A machine-learning approach based on mouse movement features
Nov 05, 2020
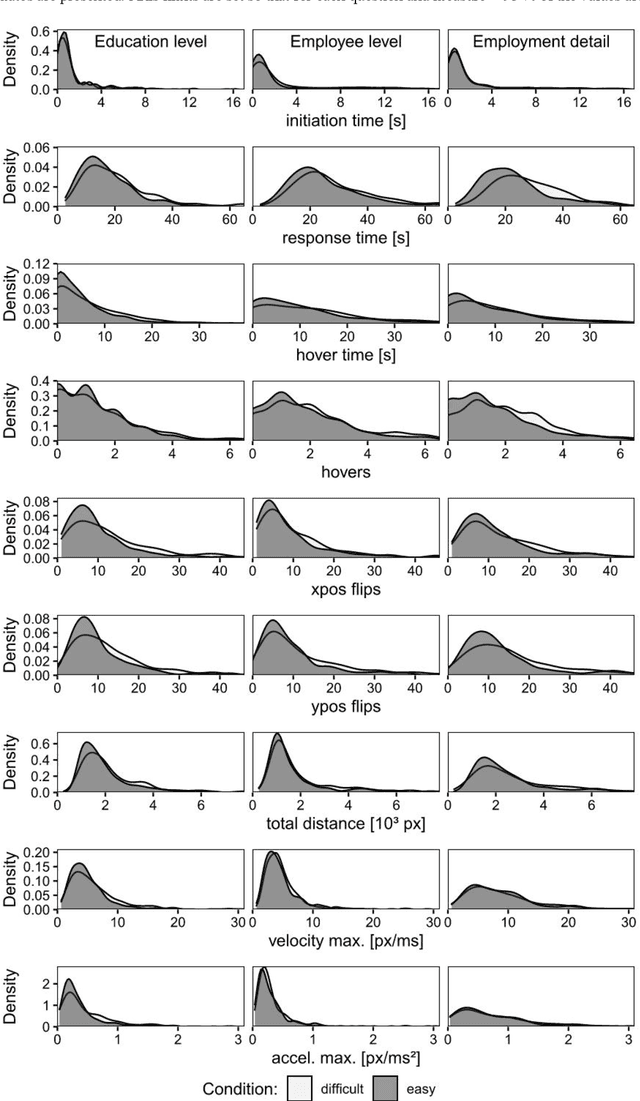
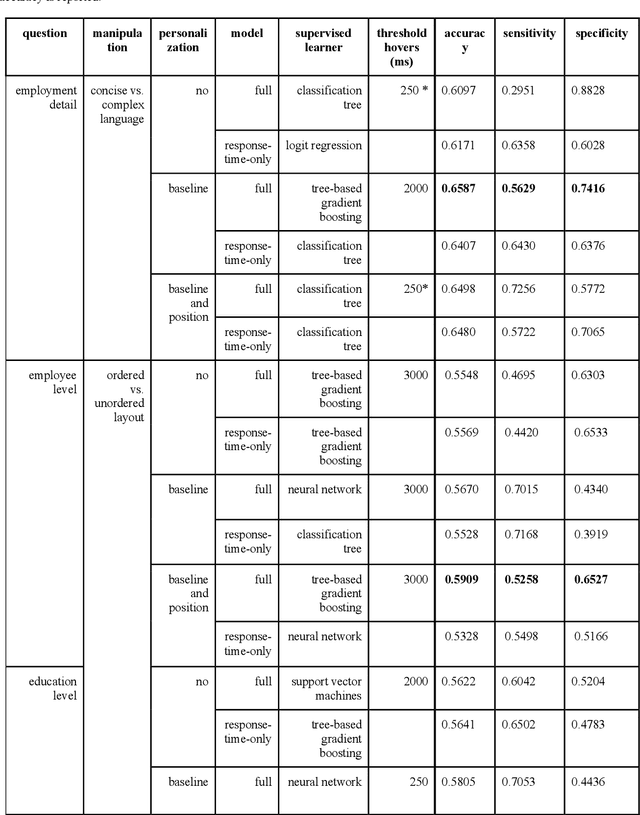
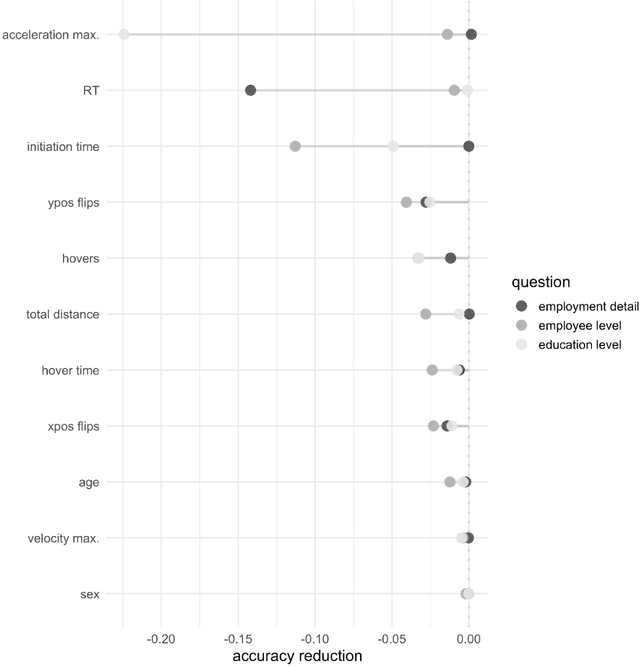
A central goal of survey research is to collect robust and reliable data from respondents. However, despite researchers' best efforts in designing questionnaires, respondents may experience difficulty understanding questions' intent and therefore may struggle to respond appropriately. If it were possible to detect such difficulty, this knowledge could be used to inform real-time interventions through responsive questionnaire design, or to indicate and correct measurement error after the fact. Previous research in the context of web surveys has used paradata, specifically response times, to detect difficulties and to help improve user experience and data quality. However, richer data sources are now available, in the form of the movements respondents make with the mouse, as an additional and far more detailed indicator for the respondent-survey interaction. This paper uses machine learning techniques to explore the predictive value of mouse-tracking data with regard to respondents' difficulty. We use data from a survey on respondents' employment history and demographic information, in which we experimentally manipulate the difficulty of several questions. Using features derived from the cursor movements, we predict whether respondents answered the easy or difficult version of a question, using and comparing several state-of-the-art supervised learning methods. In addition, we develop a personalization method that adjusts for respondents' baseline mouse behavior and evaluate its performance. For all three manipulated survey questions, we find that including the full set of mouse movement features improved prediction performance over response-time-only models in nested cross-validation. Accounting for individual differences in mouse movements led to further improvements.
Real-time Teaching Cues for Automated Surgical Coaching
Apr 24, 2017
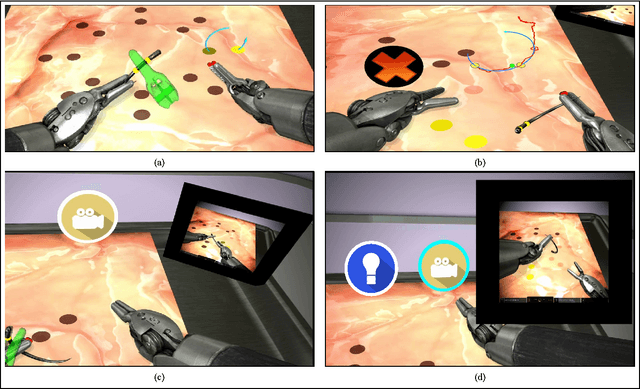
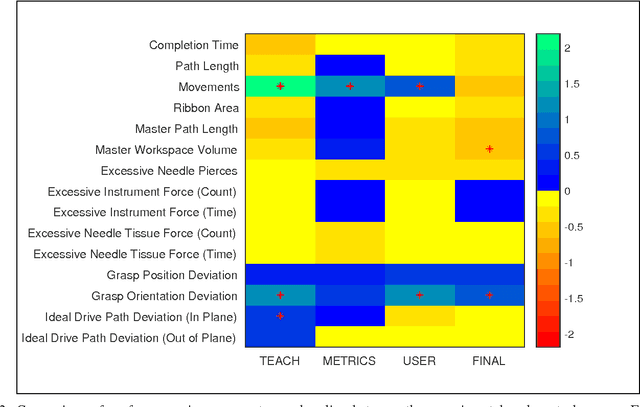
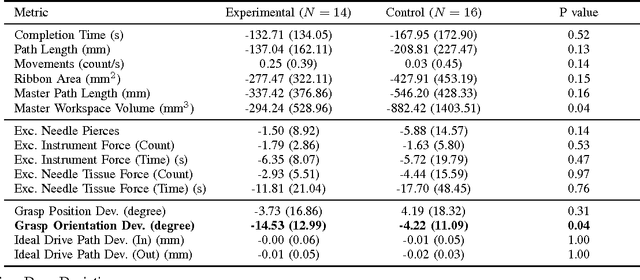
With introduction of new technologies in the operating room like the da Vinci Surgical System, training surgeons to use them effectively and efficiently is crucial in the delivery of better patient care. Coaching by an expert surgeon is effective in teaching relevant technical skills, but current methods to deliver effective coaching are limited and not scalable. We present a virtual reality simulation-based framework for automated virtual coaching in surgical education. We implement our framework within the da Vinci Skills Simulator. We provide three coaching modes ranging from a hands-on teacher (continuous guidance) to a handsoff guide (assistance upon request). We present six teaching cues targeted at critical learning elements of a needle passing task, which are shown to the user based on the coaching mode. These cues are graphical overlays which guide the user, inform them about sub-par performance, and show relevant video demonstrations. We evaluated our framework in a pilot randomized controlled trial with 16 subjects in each arm. In a post-study questionnaire, participants reported high comprehension of feedback, and perceived improvement in performance. After three practice repetitions of the task, the control arm (independent learning) showed better motion efficiency whereas the experimental arm (received real-time coaching) had better performance of learning elements (as per the ACS Resident Skills Curriculum). We observed statistically higher improvement in the experimental group based on one of the metrics (related to needle grasp orientation). In conclusion, we developed an automated coach that provides real-time cues for surgical training and demonstrated its feasibility.
Fire Risk Analysis By Using Sentinel-2 Data: The Case Study Of The Vesuvius In Campania, Italy
Jan 25, 2021
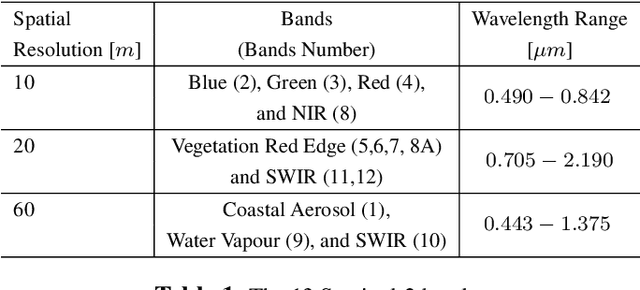
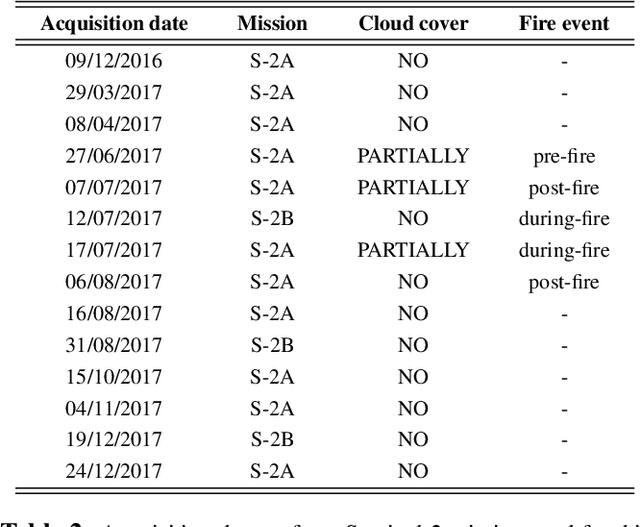
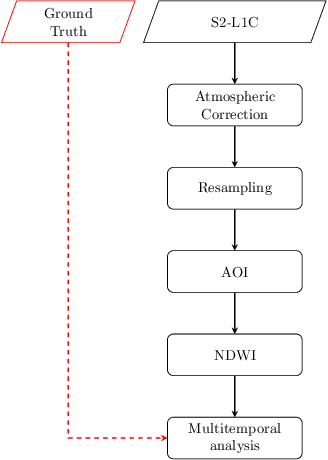
As sadly known, forest fires are part of a set of natural disasters that have always affected regions of the world typically characterized by a tropical climate with long periods of drought. However, due to climate changes of the recent years, other regions of our planet that were not affected by this plague have also had to deal with this phenomenon. One of them is certainly the Italian peninsula, and especially the regions of southern Italy. For this reason, the scientific community, and in particular that one of the remote sensing, plays an important role in the development of reliable techniques to provide useful support to the competent authorities. Therefore, in this work, the capability of the Normalized Differential Water Index (NDWI), derived from spaceborne remote sensing (RS) data, is assessed to monitor the forest fires occurred on a specific study area during the summer of 2017: the volcano Vesuvius, near Naples (in Campania, Italy). In particular, the index is obtained from Sentinel-2 multispectral images of the European Space Agency (ESA), which are free of charge and open accessible. Moreover, the twin Sentinel-2 (S-2) sensors allows to overcome some restrictions on time delivery and high frequency observation. These requirements are goodly matched by other spaceborne sensors, such as MODIS and VIIRS satellites, but at the expense of a lower spatial resolution.
Rethinking Road Surface 3D Reconstruction and Pothole Detection: From Perspective Transformation to Disparity Map Segmentation
Dec 31, 2020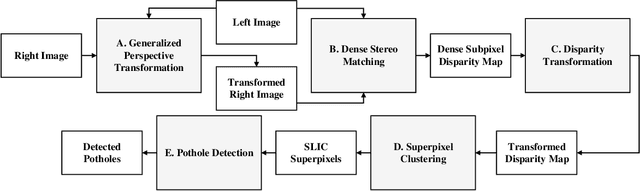

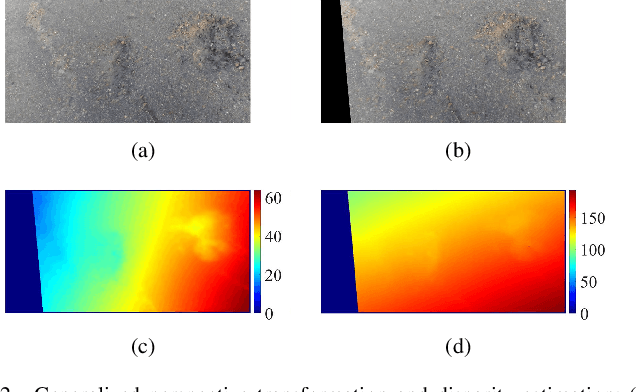
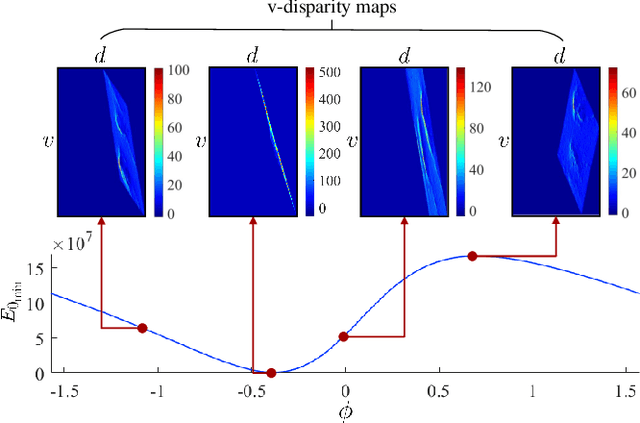
Potholes are one of the most common forms of road damage, which can severely affect driving comfort, road safety and vehicle condition. Pothole detection is typically performed by either structural engineers or certified inspectors. This task is, however, not only hazardous for the personnel but also extremely time-consuming. This paper presents an efficient pothole detection algorithm based on road disparity map estimation and segmentation. We first generalize the perspective transformation by incorporating the stereo rig roll angle. The road disparities are then estimated using semi-global matching. A disparity map transformation algorithm is then performed to better distinguish the damaged road areas. Finally, we utilize simple linear iterative clustering to group the transformed disparities into a collection of superpixels. The potholes are then detected by finding the superpixels, whose values are lower than an adaptively determined threshold. The proposed algorithm is implemented on an NVIDIA RTX 2080 Ti GPU in CUDA. The experiments demonstrate the accuracy and efficiency of our proposed road pothole detection algorithm, where an accuracy of 99.6% and an F-score of 89.4% are achieved.