 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fairness-Aware Job Scheduling for Multi-Job Federated Learning
Jan 08, 2024
Federated learning (FL) enables multiple data owners (a.k.a. FL clients) to collaboratively train machine learning models without disclosing sensitive private data. Existing FL research mostly focuses on the monopoly scenario in which a single FL server selects a subset of FL clients to update their local models in each round of training. In practice, there can be multiple FL servers simultaneously trying to select clients from the same pool. In this paper, we propose a first-of-its-kind Fairness-aware Federated Job Scheduling (FairFedJS) approach to bridge this gap. Based on Lyapunov optimization, it ensures fair allocation of high-demand FL client datasets to FL jobs in need of them, by jointly considering the current demand and the job payment bids, in order to prevent prolonged waiting. Extensive experiments comparing FairFedJS against four state-of-the-art approaches on two datasets demonstrate its significant advantages. It outperforms the best baseline by 31.9% and 1.0% on average in terms of scheduling fairness and convergence time, respectively, while achieving comparable test accuracy.
SENet: Visual Detection of Online Social Engineering Attack Campaigns
Jan 10, 2024Social engineering (SE) aims at deceiving users into performing actions that may compromise their security and privacy. These threats exploit weaknesses in human's decision making processes by using tactics such as pretext, baiting, impersonation, etc. On the web, SE attacks include attack classes such as scareware, tech support scams, survey scams, sweepstakes, etc., which can result in sensitive data leaks, malware infections, and monetary loss. For instance, US consumers lose billions of dollars annually due to various SE attacks. Unfortunately, generic social engineering attacks remain understudied, compared to other important threats, such as software vulnerabilities and exploitation, network intrusions, malicious software, and phishing. The few existing technical studies that focus on social engineering are limited in scope and mostly focus on measurements rather than developing a generic defense. To fill this gap, we present SEShield, a framework for in-browser detection of social engineering attacks. SEShield consists of three main components: (i) a custom security crawler, called SECrawler, that is dedicated to scouting the web to collect examples of in-the-wild SE attacks; (ii) SENet, a deep learning-based image classifier trained on data collected by SECrawler that aims to detect the often glaring visual traits of SE attack pages; and (iii) SEGuard, a proof-of-concept extension that embeds SENet into the web browser and enables real-time SE attack detection. We perform an extensive evaluation of our system and show that SENet is able to detect new instances of SE attacks with a detection rate of up to 99.6% at 1% false positive, thus providing an effective first defense against SE attacks on the web.
An exploratory study on automatic identification of assumptions in the development of deep learning frameworks
Jan 10, 2024Stakeholders constantly make assumptions in the development of deep learning (DL) frameworks. These assumptions are related to various types of software artifacts (e.g., requirements, design decisions, and technical debt) and can turn out to be invalid, leading to system failures. Existing approaches and tools for assumption management usually depend on manual identification of assumptions. However, assumptions are scattered in various sources (e.g., code comments, commits, pull requests, and issues) of DL framework development, and manually identifying assumptions has high costs (e.g., time and resources). To overcome the issues of manually identifying assumptions in DL framework development, we constructed a new and largest dataset (i.e., AssuEval) of assumptions collected from the TensorFlow and Keras repositories on GitHub; explored the performance of seven traditional machine learning models (e.g., Support Vector Machine, Classification and Regression Trees), a popular DL model (i.e., ALBERT), and a large language model (i.e., ChatGPT) of identifying assumptions on the AssuEval dataset. The experiment results show that: ALBERT achieves the best performance (f1-score: 0.9584) of identifying assumptions on the AssuEval dataset, which is much better than the other models (the 2nd best f1-score is 0.6211, achieved by ChatGPT). Though ChatGPT is the most popular large language model, we do not recommend using it to identify assumptions in DL framework development because of its low performance on the task. Fine-tuning ChatGPT specifically for assumption identification could improve the performance. This study provides researchers with the largest dataset of assumptions for further research (e.g., assumption classification, evaluation, and reasoning) and helps practitioners better understand assumptions and how to manage them in their projects.
Accurate Leukocyte Detection Based on Deformable-DETR and Multi-Level Feature Fusion for Aiding Diagnosis of Blood Diseases
Jan 10, 2024In standard hospital blood tests, the traditional process requires doctors to manually isolate leukocytes from microscopic images of patients' blood using microscopes. These isolated leukocytes are then categorized via automatic leukocyte classifiers to determine the proportion and volume of different types of leukocytes present in the blood samples, aiding disease diagnosis. This methodology is not only time-consuming and labor-intensive, but it also has a high propensity for errors due to factors such as image quality and environmental conditions, which could potentially lead to incorrect subsequent classifications and misdiagnosis. To address these issues, this paper proposes an innovative method of leukocyte detection: the Multi-level Feature Fusion and Deformable Self-attention DETR (MFDS-DETR). To tackle the issue of leukocyte scale disparity, we designed the High-level Screening-feature Fusion Pyramid (HS-FPN), enabling multi-level fusion. This model uses high-level features as weights to filter low-level feature information via a channel attention module and then merges the screened information with the high-level features, thus enhancing the model's feature expression capability. Further, we address the issue of leukocyte feature scarcity by incorporating a multi-scale deformable self-attention module in the encoder and using the self-attention and cross-deformable attention mechanisms in the decoder, which aids in the extraction of the global features of the leukocyte feature maps. The effectiveness, superiority, and generalizability of the proposed MFDS-DETR method are confirmed through comparisons with other cutting-edge leukocyte detection models using the private WBCDD, public LISC and BCCD datasets. Our source code and private WBCCD dataset are available at https://github.com/JustlfC03/MFDS-DETR.
* 15 pages, 11 figures, accept Computers in Biology and Medicine 2024
Take an Irregular Route: Enhance the Decoder of Time-Series Forecasting Transformer
Dec 10, 2023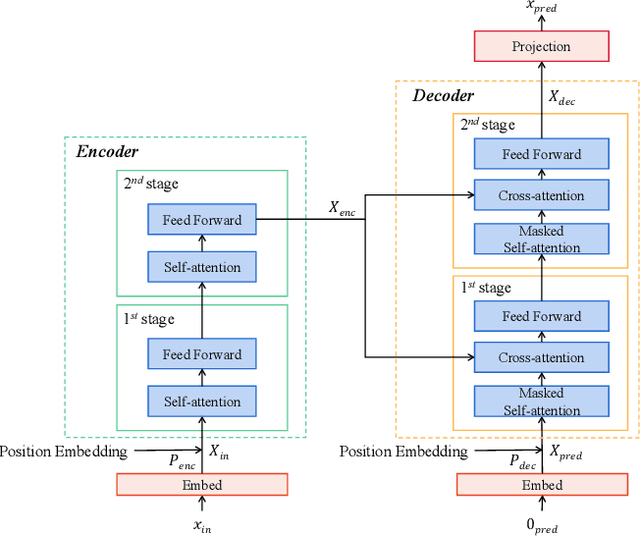
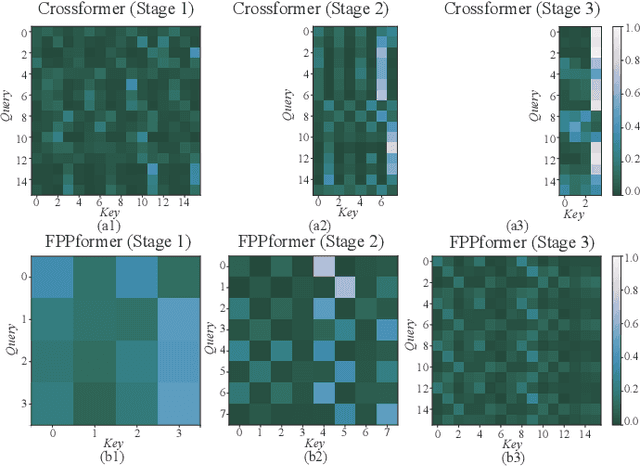
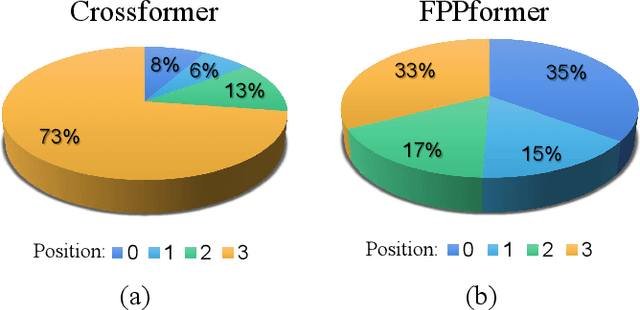
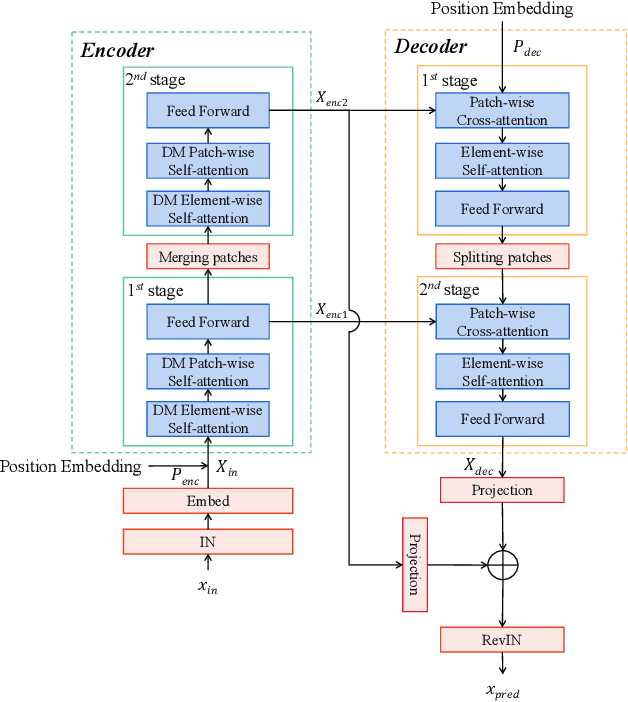
With the development of Internet of Things (IoT) systems, precise long-term forecasting method is requisite for decision makers to evaluate current statuses and formulate future policies. Currently, Transformer and MLP are two paradigms for deep time-series forecasting and the former one is more prevailing in virtue of its exquisite attention mechanism and encoder-decoder architecture. However, data scientists seem to be more willing to dive into the research of encoder, leaving decoder unconcerned. Some researchers even adopt linear projections in lieu of the decoder to reduce the complexity. We argue that both extracting the features of input sequence and seeking the relations of input and prediction sequence, which are respective functions of encoder and decoder, are of paramount significance. Motivated from the success of FPN in CV field, we propose FPPformer to utilize bottom-up and top-down architectures respectively in encoder and decoder to build the full and rational hierarchy. The cutting-edge patch-wise attention is exploited and further developed with the combination, whose format is also different in encoder and decoder, of revamped element-wise attention in this work. Extensive experiments with six state-of-the-art baselines on twelve benchmarks verify the promising performances of FPPformer and the importance of elaborately devising decoder in time-series forecasting Transformer. The source code is released in https://github.com/OrigamiSL/FPPformer.
HeadGaS: Real-Time Animatable Head Avatars via 3D Gaussian Splatting
Dec 05, 20233D head animation has seen major quality and runtime improvements over the last few years, particularly empowered by the advances in differentiable rendering and neural radiance fields. Real-time rendering is a highly desirable goal for real-world applications. We propose HeadGaS, the first model to use 3D Gaussian Splats (3DGS) for 3D head reconstruction and animation. In this paper we introduce a hybrid model that extends the explicit representation from 3DGS with a base of learnable latent features, which can be linearly blended with low-dimensional parameters from parametric head models to obtain expression-dependent final color and opacity values. We demonstrate that HeadGaS delivers state-of-the-art results in real-time inference frame rates, which surpasses baselines by up to ~2dB, while accelerating rendering speed by over x10.
TIDE: Test Time Few Shot Object Detection
Nov 30, 2023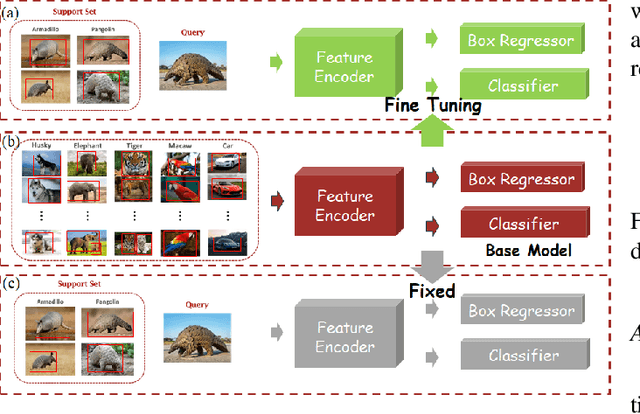
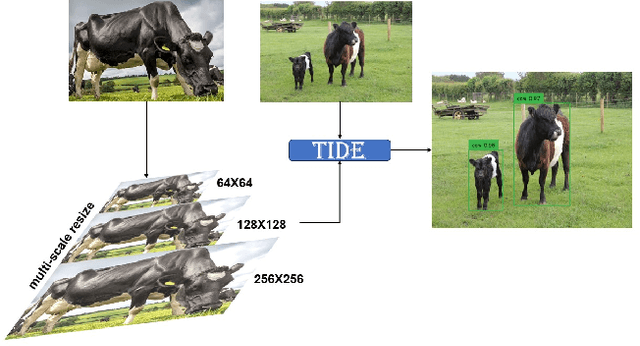
Few-shot object detection (FSOD) aims to extract semantic knowledge from limited object instances of novel categories within a target domain. Recent advances in FSOD focus on fine-tuning the base model based on a few objects via meta-learning or data augmentation. Despite their success, the majority of them are grounded with parametric readjustment to generalize on novel objects, which face considerable challenges in Industry 5.0, such as (i) a certain amount of fine-tuning time is required, and (ii) the parameters of the constructed model being unavailable due to the privilege protection, making the fine-tuning fail. Such constraints naturally limit its application in scenarios with real-time configuration requirements or within black-box settings. To tackle the challenges mentioned above, we formalize a novel FSOD task, referred to as Test TIme Few Shot DEtection (TIDE), where the model is un-tuned in the configuration procedure. To that end, we introduce an asymmetric architecture for learning a support-instance-guided dynamic category classifier. Further, a cross-attention module and a multi-scale resizer are provided to enhance the model performance. Experimental results on multiple few-shot object detection platforms reveal that the proposed TIDE significantly outperforms existing contemporary methods. The implementation codes are available at https://github.com/deku-0621/TIDE
DepressionEmo: A novel dataset for multilabel classification of depression emotions
Jan 09, 2024Emotions are integral to human social interactions, with diverse responses elicited by various situational contexts. Particularly, the prevalence of negative emotional states has been correlated with negative outcomes for mental health, necessitating a comprehensive analysis of their occurrence and impact on individuals. In this paper, we introduce a novel dataset named DepressionEmo designed to detect 8 emotions associated with depression by 6037 examples of long Reddit user posts. This dataset was created through a majority vote over inputs by zero-shot classifications from pre-trained models and validating the quality by annotators and ChatGPT, exhibiting an acceptable level of interrater reliability between annotators. The correlation between emotions, their distribution over time, and linguistic analysis are conducted on DepressionEmo. Besides, we provide several text classification methods classified into two groups: machine learning methods such as SVM, XGBoost, and Light GBM; and deep learning methods such as BERT, GAN-BERT, and BART. The pretrained BART model, bart-base allows us to obtain the highest F1- Macro of 0.76, showing its outperformance compared to other methods evaluated in our analysis. Across all emotions, the highest F1-Macro value is achieved by suicide intent, indicating a certain value of our dataset in identifying emotions in individuals with depression symptoms through text analysis. The curated dataset is publicly available at: https://github.com/abuBakarSiddiqurRahman/DepressionEmo.
Let's Go Shopping (LGS) -- Web-Scale Image-Text Dataset for Visual Concept Understanding
Jan 09, 2024Vision and vision-language applications of neural networks, such as image classification and captioning, rely on large-scale annotated datasets that require non-trivial data-collecting processes. This time-consuming endeavor hinders the emergence of large-scale datasets, limiting researchers and practitioners to a small number of choices. Therefore, we seek more efficient ways to collect and annotate images. Previous initiatives have gathered captions from HTML alt-texts and crawled social media postings, but these data sources suffer from noise, sparsity, or subjectivity. For this reason, we turn to commercial shopping websites whose data meet three criteria: cleanliness, informativeness, and fluency. We introduce the Let's Go Shopping (LGS) dataset, a large-scale public dataset with 15 million image-caption pairs from publicly available e-commerce websites. When compared with existing general-domain datasets, the LGS images focus on the foreground object and have less complex backgrounds. Our experiments on LGS show that the classifiers trained on existing benchmark datasets do not readily generalize to e-commerce data, while specific self-supervised visual feature extractors can better generalize. Furthermore, LGS's high-quality e-commerce-focused images and bimodal nature make it advantageous for vision-language bi-modal tasks: LGS enables image-captioning models to generate richer captions and helps text-to-image generation models achieve e-commerce style transfer.
Robust Imitation Learning for Automated Game Testing
Jan 09, 2024Game development is a long process that involves many stages before a product is ready for the market. Human play testing is among the most time consuming, as testers are required to repeatedly perform tasks in the search for errors in the code. Therefore, automated testing is seen as a key technology for the gaming industry, as it would dramatically improve development costs and efficiency. Toward this end, we propose EVOLUTE, a novel imitation learning-based architecture that combines behavioural cloning (BC) with energy based models (EBMs). EVOLUTE is a two-stream ensemble model that splits the action space of autonomous agents into continuous and discrete tasks. The EBM stream handles the continuous tasks, to have a more refined and adaptive control, while the BC stream handles discrete actions, to ease training. We evaluate the performance of EVOLUTE in a shooting-and-driving game, where the agent is required to navigate and continuously identify targets to attack. The proposed model has higher generalisation capabilities than standard BC approaches, showing a wider range of behaviours and higher performances. Also, EVOLUTE is easier to train than a pure end-to-end EBM model, as discrete tasks can be quite sparse in the dataset and cause model training to explore a much wider set of possible actions while training.