 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Transforming India's Agricultural Sector using Ontology-based Tantra Framework
Jan 26, 2021
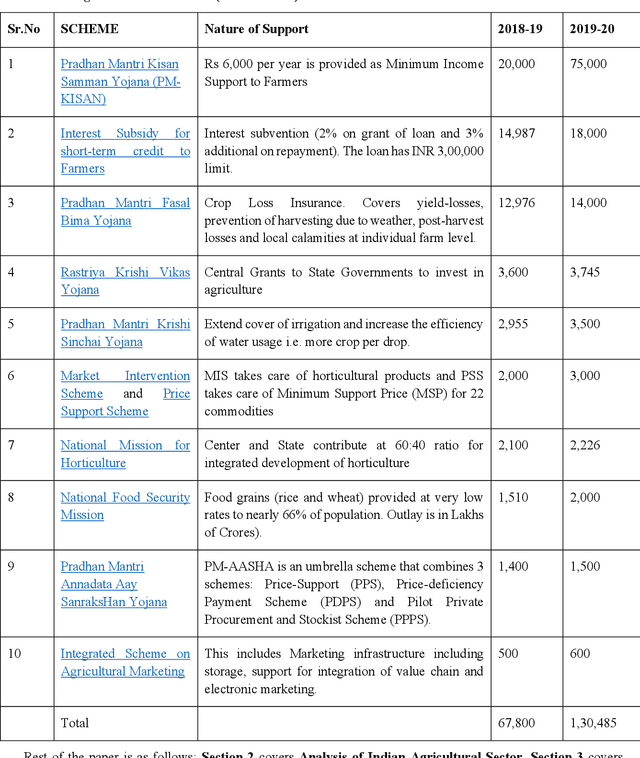
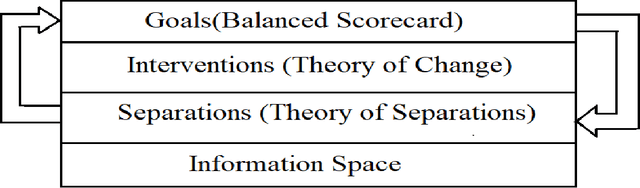
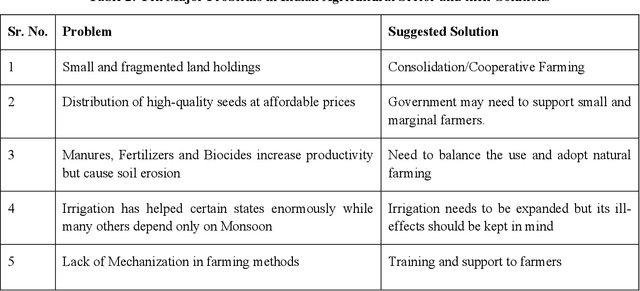
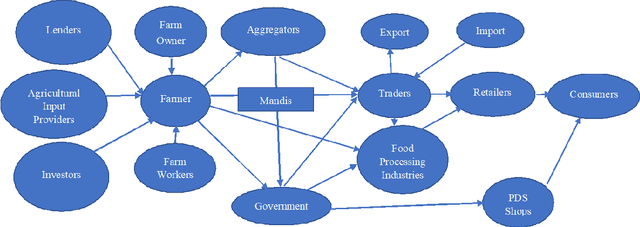
Food production is a critical activity in which every nation would like to be self-sufficient. India is one of the largest producers of food grains in the world. In India, nearly 70 percent of rural households still depend on agriculture for their livelihood. Keeping farmers happy is particularly important in India as farmers form a large vote bank which politicians dare not disappoint. At the same time, Governments need to balance the interest of farmers with consumers, intermediaries and society at large. The whole agriculture sector is highly information-intensive. Even with enormous collection of data and statistics from different arms of Government, there continue to be information gaps. In this paper we look at how Tantra Social Information Management Framework can help analyze the agricultural sector and transform the same using a holistic approach. Advantage of Tantra Framework approach is that it looks at societal information as a whole without limiting it to only the sector at hand. Tantra Framework makes use of concepts from Zachman Framework to manage aspects of social information through different perspectives and concepts from Unified Foundational Ontology (UFO) to represent interrelationships between aspects. Further, Tantra Framework interoperates with models such as Balanced Scorecard, Theory of Change and Theory of Separations. Finally, we model Indian Agricultural Sector as a business ecosystem and look at approaches to steer transformation from within.
VOLT: Improving Vocabularization via Optimal Transport for Machine Translation
Dec 31, 2020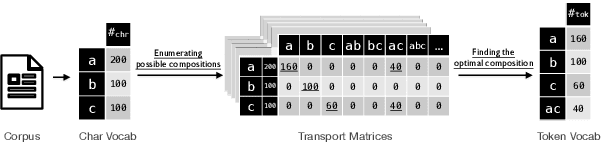
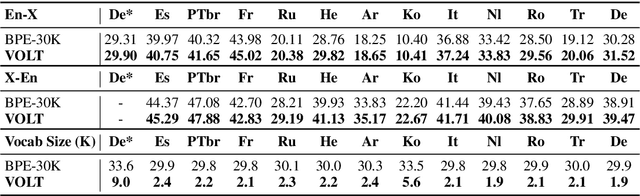
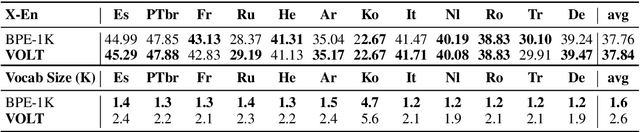
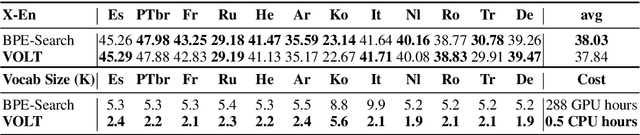
It is well accepted that the choice of token vocabulary largely affects the performance of machine translation. However, due to expensive trial costs, most studies only conduct simple trials with dominant approaches (e.g BPE) and commonly used vocabulary sizes. In this paper, we find an exciting relation between an information-theoretic feature and BLEU scores. With this observation, we formulate the quest of vocabularization -- finding the best token dictionary with a proper size -- as an optimal transport problem. We then propose VOLT, a simple and efficient vocabularization solution without the full and costly trial training. We evaluate our approach on multiple machine translation tasks, including WMT-14 English-German translation, TED bilingual translation, and TED multilingual translation. Empirical results show that VOLT beats widely-used vocabularies on diverse scenarios. For example, VOLT achieves 70% vocabulary size reduction and 0.6 BLEU gain on English-German translation. Also, one advantage of VOLT lies in its low resource consumption. Compared to naive BPE-search, VOLT reduces the search time from 288 GPU hours to 0.5 CPU hours.
Complex Vehicle Routing with Memory Augmented Neural Networks
Sep 22, 2020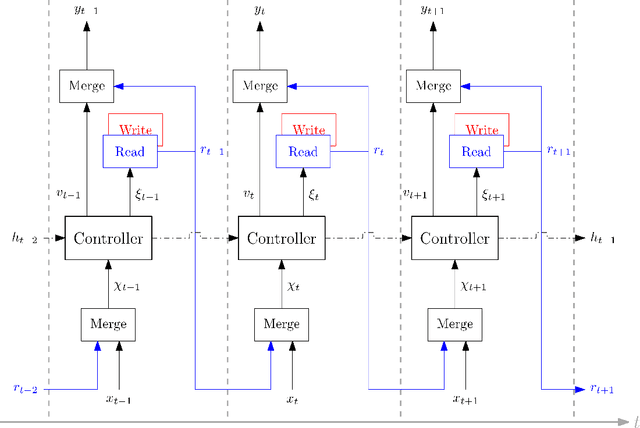
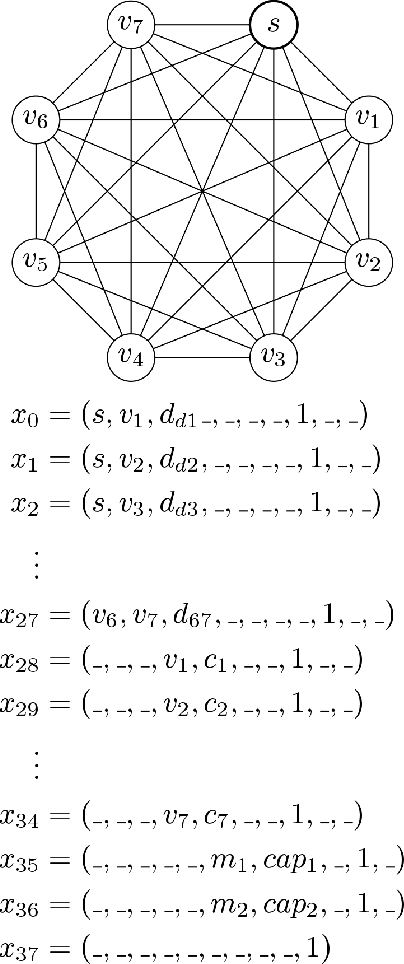
Complex real-life routing challenges can be modeled as variations of well-known combinatorial optimization problems. These routing problems have long been studied and are difficult to solve at scale. The particular setting may also make exact formulation difficult. Deep Learning offers an increasingly attractive alternative to traditional solutions, which mainly revolve around the use of various heuristics. Deep Learning may provide solutions which are less time-consuming and of higher quality at large scales, as it generally does not need to generate solutions in an iterative manner, and Deep Learning models have shown a surprising capacity for solving complex tasks in recent years. Here we consider a particular variation of the Capacitated Vehicle Routing (CVRP) problem and investigate the use of Deep Learning models with explicit memory components. Such memory components may help in gaining insight into the model's decisions as the memory and operations on it can be directly inspected at any time, and may assist in scaling the method to such a size that it becomes viable for industry settings.
Learning Power Control for Cellular Systems with Heterogeneous Graph Neural Network
Nov 06, 2020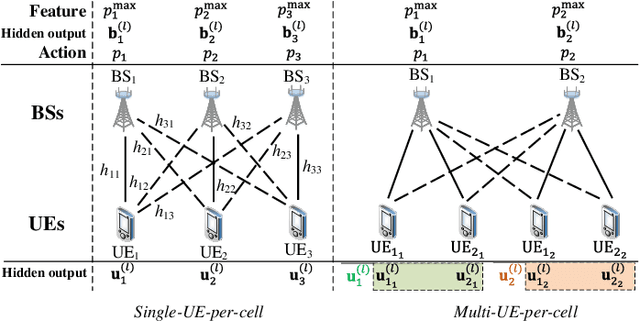
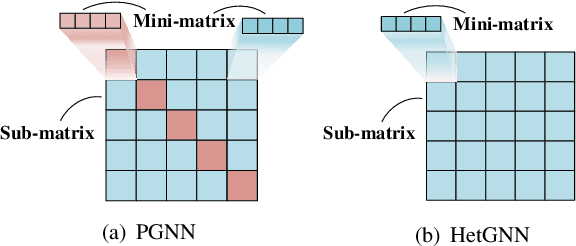
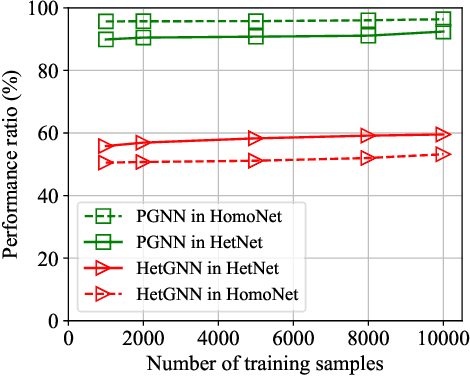
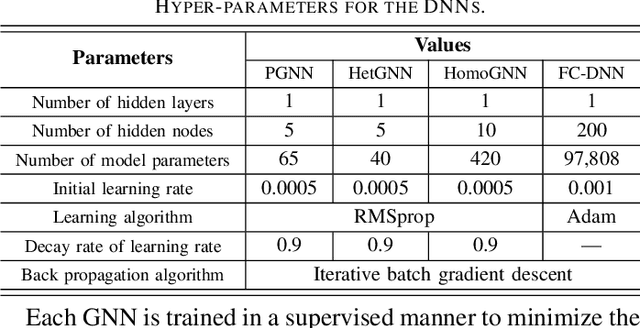
Optimizing power control in multi-cell cellular networks with deep learning enables such a non-convex problem to be implemented in real-time. When channels are time-varying, the deep neural networks (DNNs) need to be re-trained frequently, which calls for low training complexity. To reduce the number of training samples and the size of DNN required to achieve good performance, a promising approach is to embed the DNNs with priori knowledge. Since cellular networks can be modelled as a graph, it is natural to employ graph neural networks (GNNs) for learning, which exhibit permutation invariance (PI) and equivalence (PE) properties. Unlike the homogeneous GNNs that have been used for wireless problems, whose outputs are invariant or equivalent to arbitrary permutations of vertexes, heterogeneous GNNs (HetGNNs), which are more appropriate to model cellular networks, are only invariant or equivalent to some permutations. If the PI or PE properties of the HetGNN do not match the property of the task to be learned, the performance degrades dramatically. In this paper, we show that the power control policy has a combination of different PI and PE properties, and existing HetGNN does not satisfy these properties. We then design a parameter sharing scheme for HetGNN such that the learned relationship satisfies the desired properties. Simulation results show that the sample complexity and the size of designed GNN for learning the optimal power control policy in multi-user multi-cell networks are much lower than the existing DNNs, when achieving the same sum rate loss from the numerically obtained solutions.
Healthcare Cost Prediction: Leveraging Fine-grain Temporal Patterns
Sep 14, 2020
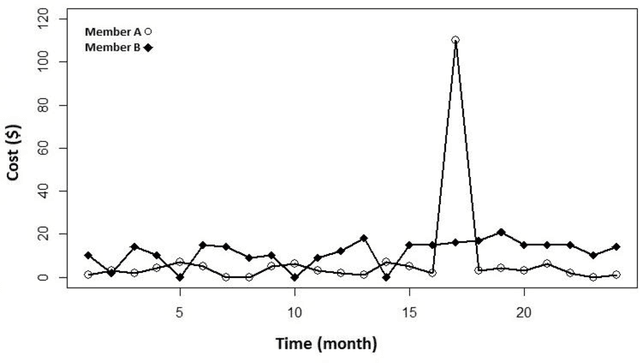

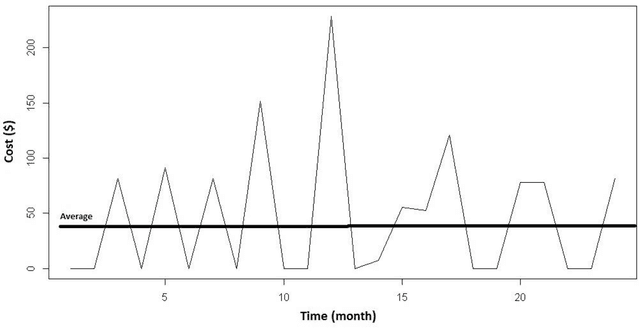
Objective: To design and assess a method to leverage individuals' temporal data for predicting their healthcare cost. To achieve this goal, we first used patients' temporal data in their fine-grain form as opposed to coarse-grain form. Second, we devised novel spike detection features to extract temporal patterns that improve the performance of cost prediction. Third, we evaluated the effectiveness of different types of temporal features based on cost information, visit information and medical information for the prediction task. Materials and methods: We used three years of medical and pharmacy claims data from 2013 to 2016 from a healthcare insurer, where the first two years were used to build the model to predict the costs in the third year. To prepare the data for modeling and prediction, the time series data of cost, visit and medical information were extracted in the form of fine-grain features (i.e., segmenting each time series into a sequence of consecutive windows and representing each window by various statistics such as sum). Then, temporal patterns of the time series were extracted and added to fine-grain features using a novel set of spike detection features (i.e., the fluctuation of data points). Gradient Boosting was applied on the final set of extracted features. Moreover, the contribution of each type of data (i.e., cost, visit and medical) was assessed. Conclusions: Leveraging fine-grain temporal patterns for healthcare cost prediction significantly improves prediction performance. Enhancing fine-grain features with extraction of temporal cost and visit patterns significantly improved the performance. However, medical features did not have a significant effect on prediction performance. Gradient Boosting outperformed all other prediction models.
TLU-Net: A Deep Learning Approach for Automatic Steel Surface Defect Detection
Jan 18, 2021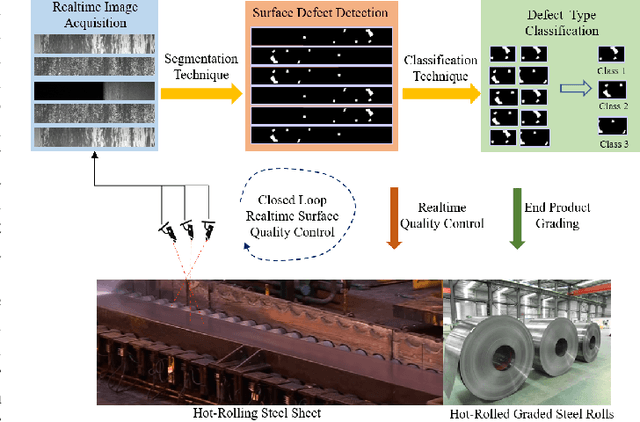
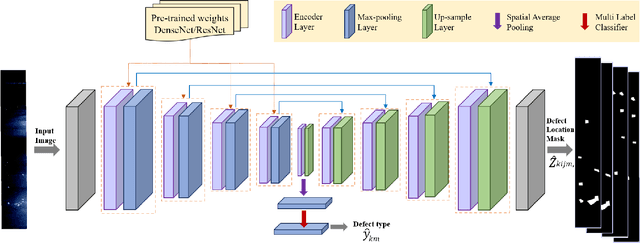
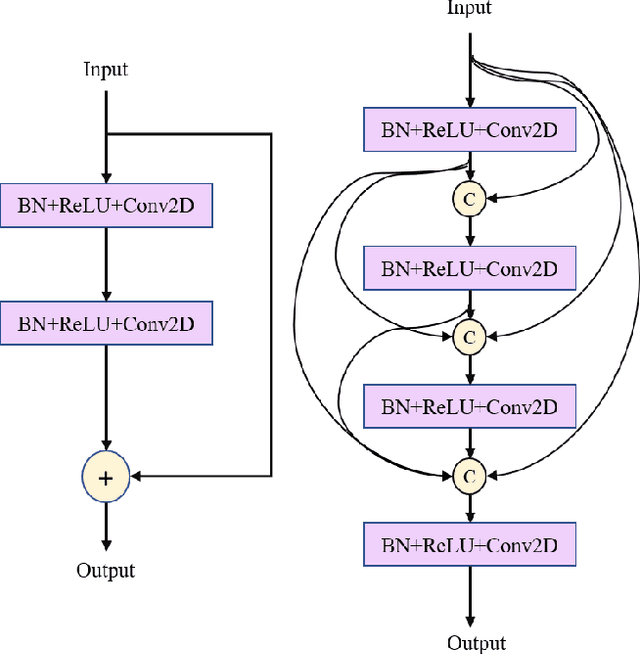
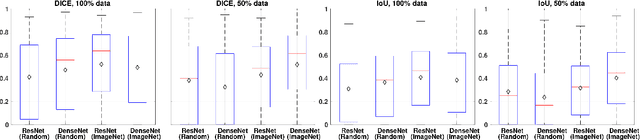
Visual steel surface defect detection is an essential step in steel sheet manufacturing. Several machine learning-based automated visual inspection (AVI) methods have been studied in recent years. However, most steel manufacturing industries still use manual visual inspection due to training time and inaccuracies involved with AVI methods. Automatic steel defect detection methods could be useful in less expensive and faster quality control and feedback. But preparing the annotated training data for segmentation and classification could be a costly process. In this work, we propose to use the Transfer Learning-based U-Net (TLU-Net) framework for steel surface defect detection. We use a U-Net architecture as the base and explore two kinds of encoders: ResNet and DenseNet. We compare these nets' performance using random initialization and the pre-trained networks trained using the ImageNet data set. The experiments are performed using Severstal data. The results demonstrate that the transfer learning performs 5% (absolute) better than that of the random initialization in defect classification. We found that the transfer learning performs 26% (relative) better than that of the random initialization in defect segmentation. We also found the gain of transfer learning increases as the training data decreases, and the convergence rate with transfer learning is better than that of the random initialization.
P-CRITICAL: A Reservoir Autoregulation Plasticity Rule for Neuromorphic Hardware
Sep 11, 2020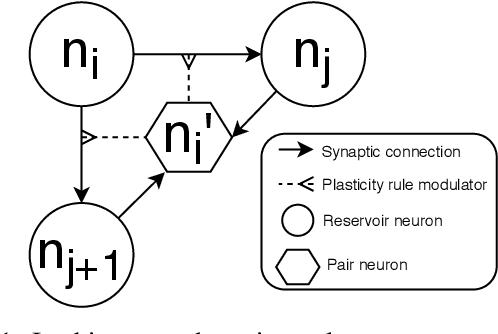
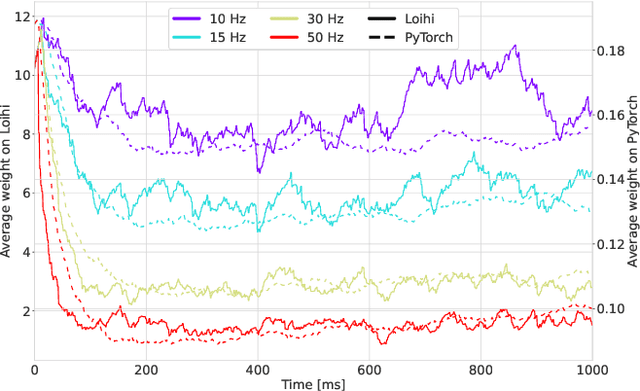
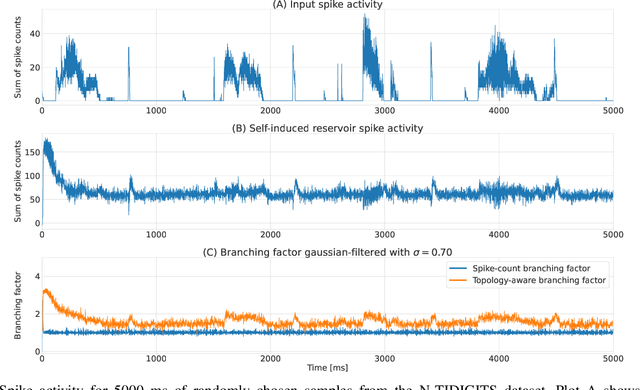
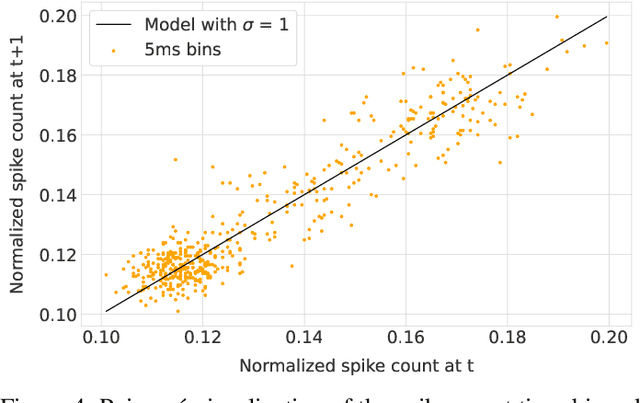
Backpropagation algorithms on recurrent artificial neural networks require an unfolding of accumulated states over time. These states must be kept in memory for an undefined period of time which is task-dependent. This paper uses the reservoir computing paradigm where an untrained recurrent neural network layer is used as a preprocessor stage to learn temporal and limited data. These so-called reservoirs require either extensive fine-tuning or neuroplasticity with unsupervised learning rules. We propose a new local plasticity rule named P-CRITICAL designed for automatic reservoir tuning that translates well to Intel's Loihi research chip, a recent neuromorphic processor. We compare our approach on well-known datasets from the machine learning community while using a spiking neuronal architecture. We observe an improved performance on tasks coming from various modalities without the need to tune parameters. Such algorithms could be a key to end-to-end energy-efficient neuromorphic-based machine learning on edge devices.
Statistical Estimation of High-Dimensional Vector Autoregressive Models
Jun 09, 2020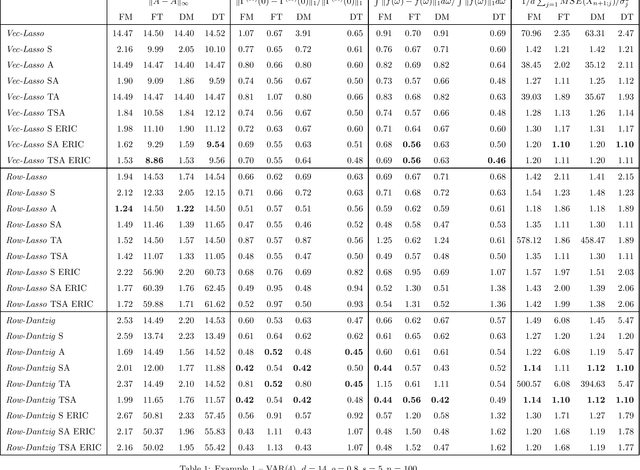
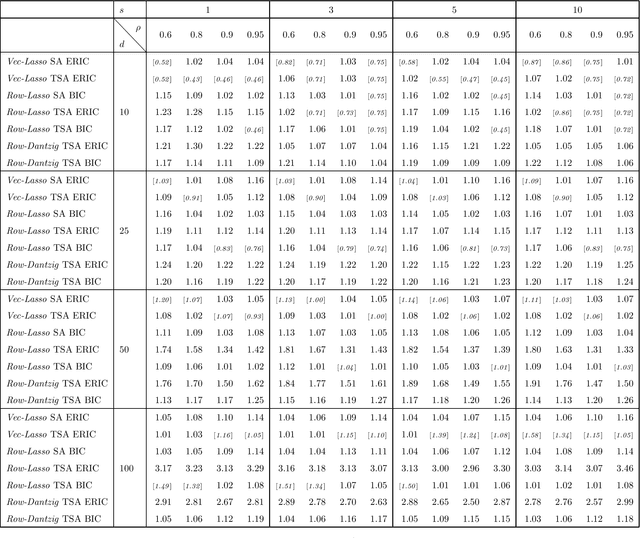
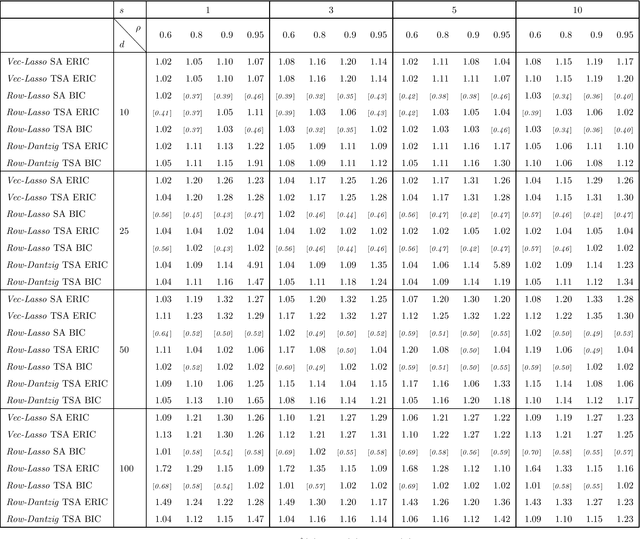
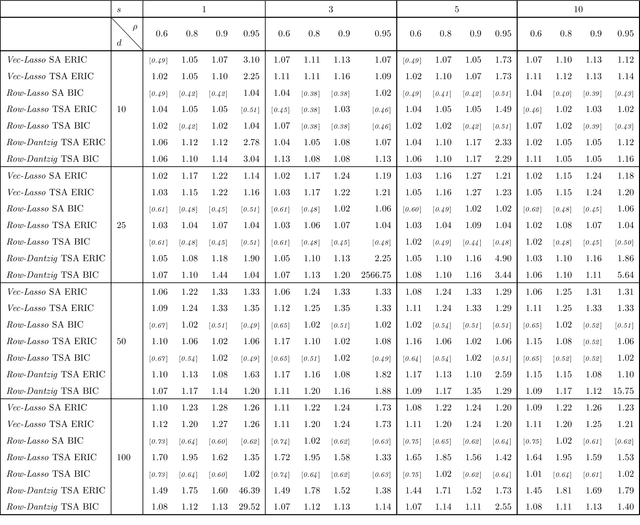
High-dimensional vector autoregressive (VAR) models are important tools for the analysis of multivariate time series. This paper focuses on high-dimensional time series and on the different regularized estimation procedures proposed for fitting sparse VAR models to such time series. Attention is paid to the different sparsity assumptions imposed on the VAR parameters and how these sparsity assumptions are related to the particular consistency properties of the estimators established. A sparsity scheme for high-dimensional VAR models is proposed which is found to be more appropriate for the time series setting considered. Furthermore, it is shown that, under this sparsity setting, threholding extents the consistency properties of regularized estimators to a wide range of matrix norms. Among other things, this enables application of the VAR parameters estimators to different inference problems, like forecasting or estimating the second-order characteristics of the underlying VAR process. Extensive simulations compare the finite sample behavior of the different regularized estimators proposed using a variety of performance criteria.
How Many Annotators Do We Need? -- A Study on the Influence of Inter-Observer Variability on the Reliability of Automatic Mitotic Figure Assessment
Dec 04, 2020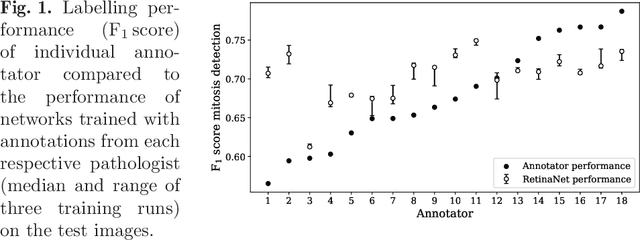
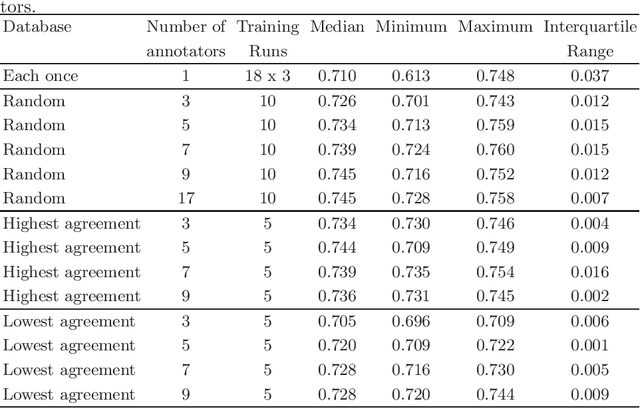
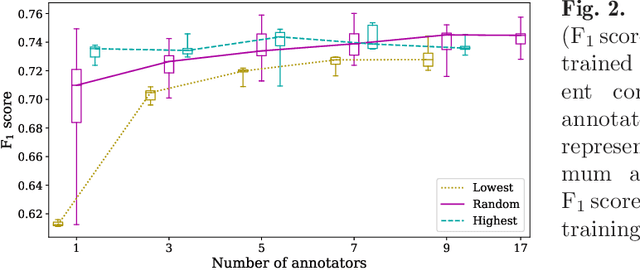
Density of mitotic figures in histologic sections is a prognostically relevant characteristic for many tumours. Due to high inter-pathologist variability, deep learning-based algorithms are a promising solution to improve tumour prognostication. Pathologists are the gold standard for database development, however, labelling errors may hamper development of accurate algorithms. In the present work we evaluated the benefit of multi-expert consensus (n = 3, 5, 7, 9, 17) on algorithmic performance. While training with individual databases resulted in highly variable F$_1$ scores, performance was notably increased and more consistent when using the consensus of three annotators. Adding more annotators only resulted in minor improvements. We conclude that databases by few pathologists with high label precision may be the best compromise between high algorithmic performance and time investment.
Alternating linear scheme in a Bayesian framework for low-rank tensor approximation
Dec 21, 2020

Multiway data often naturally occurs in a tensorial format which can be approximately represented by a low-rank tensor decomposition. This is useful because complexity can be significantly reduced and the treatment of large-scale data sets can be facilitated. In this paper, we find a low-rank representation for a given tensor by solving a Bayesian inference problem. This is achieved by dividing the overall inference problem into sub-problems where we sequentially infer the posterior distribution of one tensor decomposition component at a time. This leads to a probabilistic interpretation of the well-known iterative algorithm alternating linear scheme (ALS). In this way, the consideration of measurement noise is enabled, as well as the incorporation of application-specific prior knowledge and the uncertainty quantification of the low-rank tensor estimate. To compute the low-rank tensor estimate from the posterior distributions of the tensor decomposition components, we present an algorithm that performs the unscented transform in tensor train format.