 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Histopathological Stain Invariance by Unsupervised Domain Augmentation using Generative Adversarial Networks
Dec 22, 2020
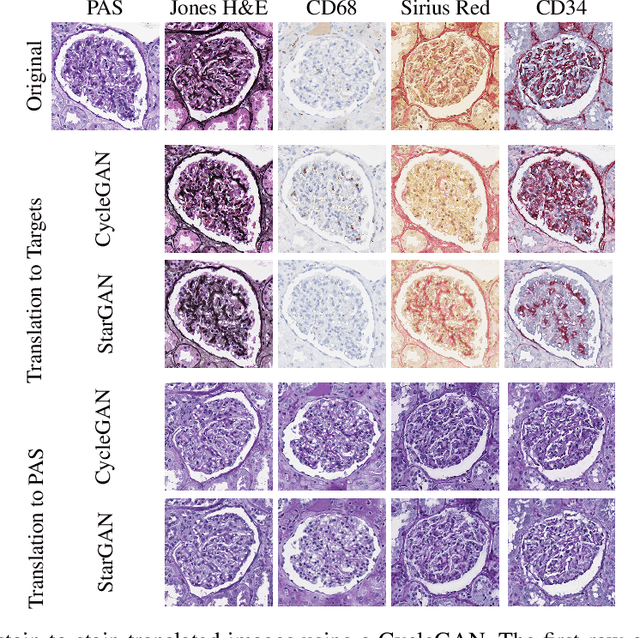
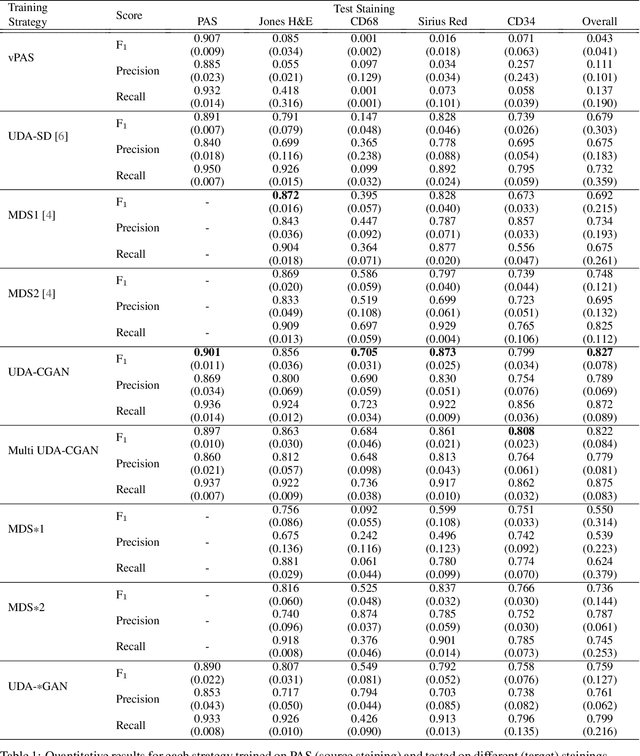
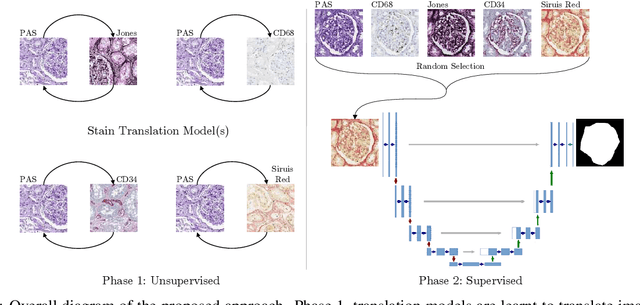
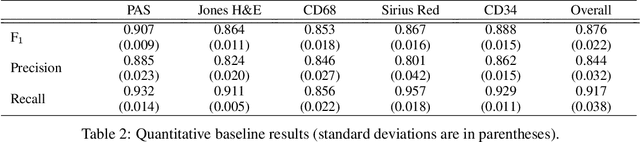
The application of supervised deep learning methods in digital pathology is limited due to their sensitivity to domain shift. Digital Pathology is an area prone to high variability due to many sources, including the common practice of evaluating several consecutive tissue sections stained with different staining protocols. Obtaining labels for each stain is very expensive and time consuming as it requires a high level of domain knowledge. In this article, we propose an unsupervised augmentation approach based on adversarial image-to-image translation, which facilitates the training of stain invariant supervised convolutional neural networks. By training the network on one commonly used staining modality and applying it to images that include corresponding, but differently stained, tissue structures, the presented method demonstrates significant improvements over other approaches. These benefits are illustrated in the problem of glomeruli segmentation in seven different staining modalities (PAS, Jones H&E, CD68, Sirius Red, CD34, H&E and CD3) and analysis of the learned representations demonstrate their stain invariance.
Knowledge Graph Driven Approach to Represent Video Streams for Spatiotemporal Event Pattern Matching in Complex Event Processing
Jul 13, 2020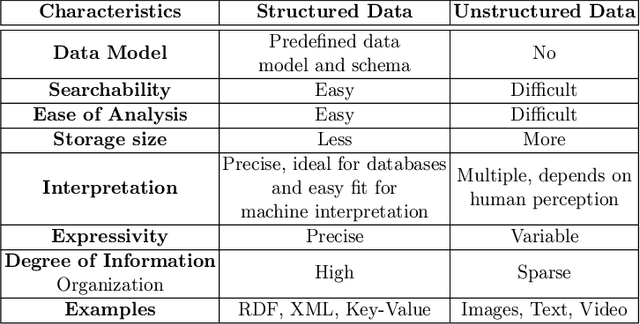
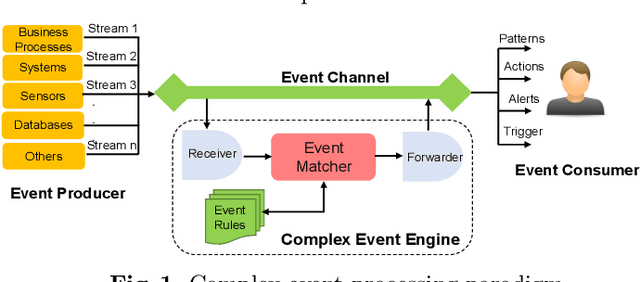
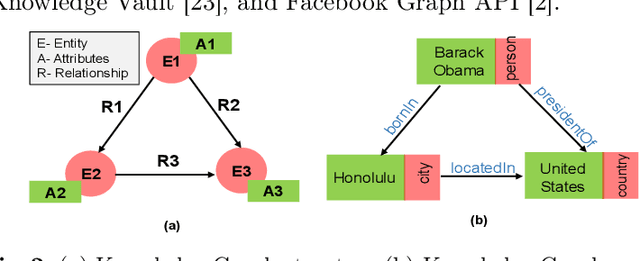
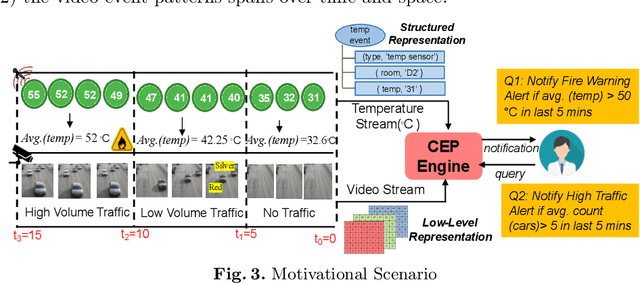
Complex Event Processing (CEP) is an event processing paradigm to perform real-time analytics over streaming data and match high-level event patterns. Presently, CEP is limited to process structured data stream. Video streams are complicated due to their unstructured data model and limit CEP systems to perform matching over them. This work introduces a graph-based structure for continuous evolving video streams, which enables the CEP system to query complex video event patterns. We propose the Video Event Knowledge Graph (VEKG), a graph driven representation of video data. VEKG models video objects as nodes and their relationship interaction as edges over time and space. It creates a semantic knowledge representation of video data derived from the detection of high-level semantic concepts from the video using an ensemble of deep learning models. A CEP-based state optimization - VEKG-Time Aggregated Graph (VEKG-TAG) is proposed over VEKG representation for faster event detection. VEKG-TAG is a spatiotemporal graph aggregation method that provides a summarized view of the VEKG graph over a given time length. We defined a set of nine event pattern rules for two domains (Activity Recognition and Traffic Management), which act as a query and applied over VEKG graphs to discover complex event patterns. To show the efficacy of our approach, we performed extensive experiments over 801 video clips across 10 datasets. The proposed VEKG approach was compared with other state-of-the-art methods and was able to detect complex event patterns over videos with F-Score ranging from 0.44 to 0.90. In the given experiments, the optimized VEKG-TAG was able to reduce 99% and 93% of VEKG nodes and edges, respectively, with 5.19X faster search time, achieving sub-second median latency of 4-20 milliseconds.
AgEBO-Tabular: Joint Neural Architecture and Hyperparameter Search with Autotuned Data-Parallel Training for Tabular Data
Oct 30, 2020
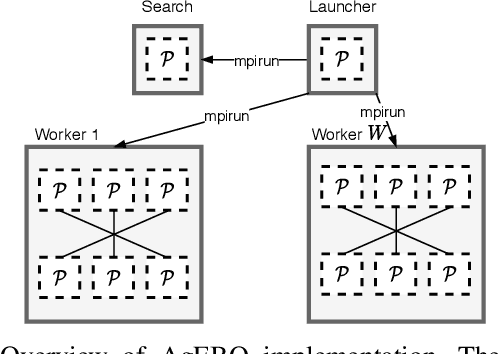
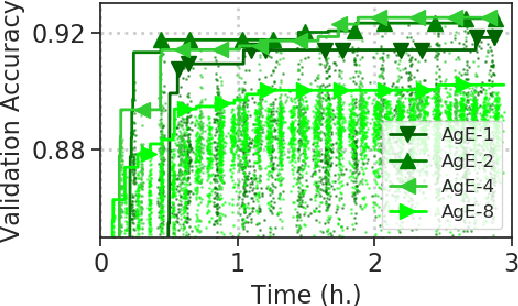
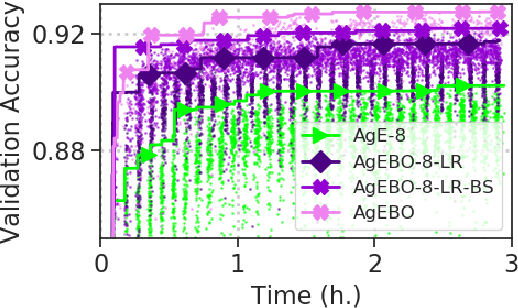
Developing high-performing predictive models for large tabular data sets is a challenging task. The state-of-the-art methods are based on expert-developed model ensembles from different supervised learning methods. Recently, automated machine learning (AutoML) is emerging as a promising approach to automate predictive model development. Neural architecture search (NAS) is an AutoML approach that generates and evaluates multiple neural network architectures concurrently and improves the accuracy of the generated models iteratively. A key issue in NAS, particularly for large data sets, is the large computation time required to evaluate each generated architecture. While data-parallel training is a promising approach that can address this issue, its use within NAS is difficult. For different data sets, the data-parallel training settings such as the number of parallel processes, learning rate, and batch size need to be adapted to achieve high accuracy and reduction in training time. To that end, we have developed AgEBO-Tabular, an approach to combine aging evolution (AgE), a parallel NAS method that searches over neural architecture space, and an asynchronous Bayesian optimization method for tuning the hyperparameters of the data-parallel training simultaneously. We demonstrate the efficacy of the proposed method to generate high-performing neural network models for large tabular benchmark data sets. Furthermore, we demonstrate that the automatically discovered neural network models using our method outperform the state-of-the-art AutoML ensemble models in inference speed by two orders of magnitude while reaching similar accuracy values.
Bayesian Nested Neural Networks for Uncertainty Calibration and Adaptive Compression
Jan 27, 2021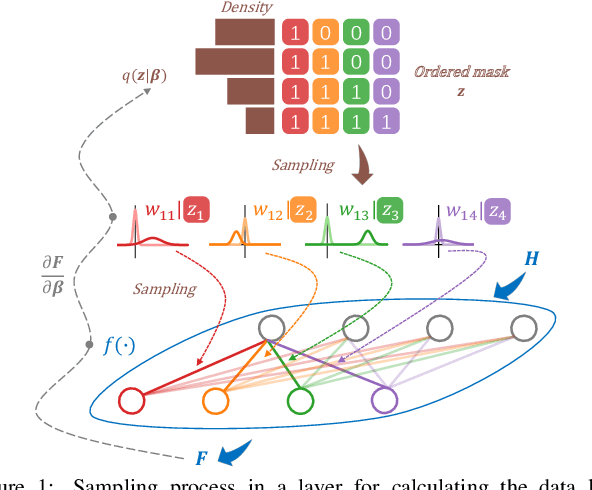
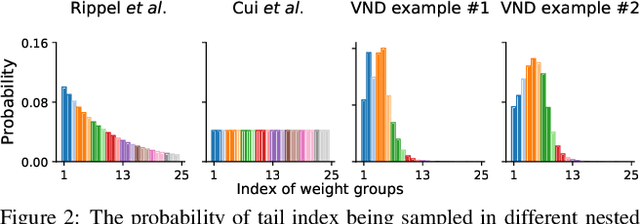
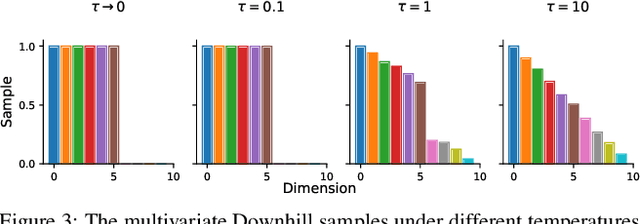
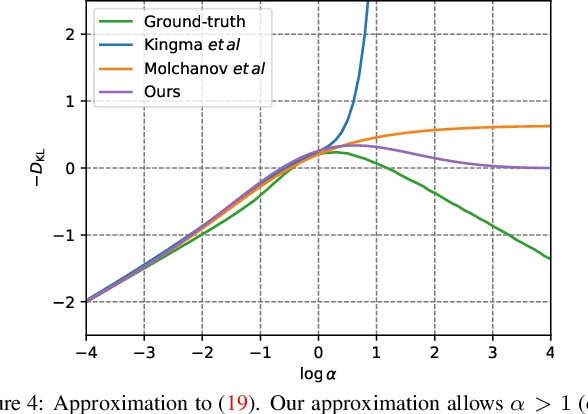
Nested networks or slimmable networks are neural networks whose architectures can be adjusted instantly during testing time, e.g., based on computational constraints. Recent studies have focused on a "nested dropout" layer, which is able to order the nodes of a layer by importance during training, thus generating a nested set of sub-networks that are optimal for different configurations of resources. However, the dropout rate is fixed as a hyper-parameter over different layers during the whole training process. Therefore, when nodes are removed, the performance decays in a human-specified trajectory rather than in a trajectory learned from data. Another drawback is the generated sub-networks are deterministic networks without well-calibrated uncertainty. To address these two problems, we develop a Bayesian approach to nested neural networks. We propose a variational ordering unit that draws samples for nested dropout at a low cost, from a proposed Downhill distribution, which provides useful gradients to the parameters of nested dropout. Based on this approach, we design a Bayesian nested neural network that learns the order knowledge of the node distributions. In experiments, we show that the proposed approach outperforms the nested network in terms of accuracy, calibration, and out-of-domain detection in classification tasks. It also outperforms the related approach on uncertainty-critical tasks in computer vision.
Learning Dense Representations of Phrases at Scale
Jan 02, 2021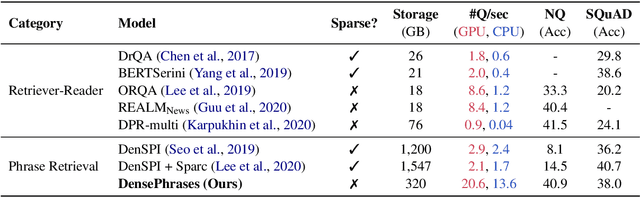
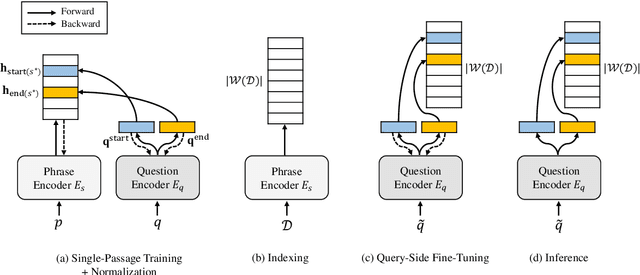
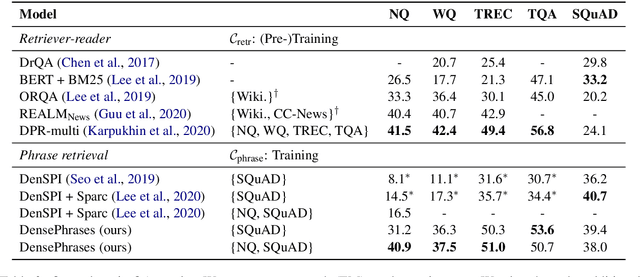
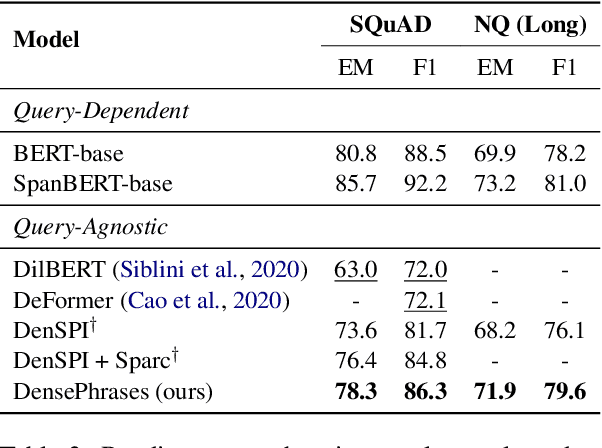
Open-domain question answering can be reformulated as a phrase retrieval problem, without the need for processing documents on-demand during inference (Seo et al., 2019). However, current phrase retrieval models heavily depend on their sparse representations while still underperforming retriever-reader approaches. In this work, we show for the first time that we can learn dense phrase representations alone that achieve much stronger performance in open-domain QA. Our approach includes (1) learning query-agnostic phrase representations via question generation and distillation; (2) novel negative-sampling methods for global normalization; (3) query-side fine-tuning for transfer learning. On five popular QA datasets, our model DensePhrases improves previous phrase retrieval models by 15%-25% absolute accuracy and matches the performance of state-of-the-art retriever-reader models. Our model is easy to parallelize due to pure dense representations and processes more than 10 questions per second on CPUs. Finally, we directly use our pre-indexed dense phrase representations for two slot filling tasks, showing the promise of utilizing DensePhrases as a dense knowledge base for downstream tasks.
On the Interpretability of Deep Learning Based Models for Knowledge Tracing
Jan 27, 2021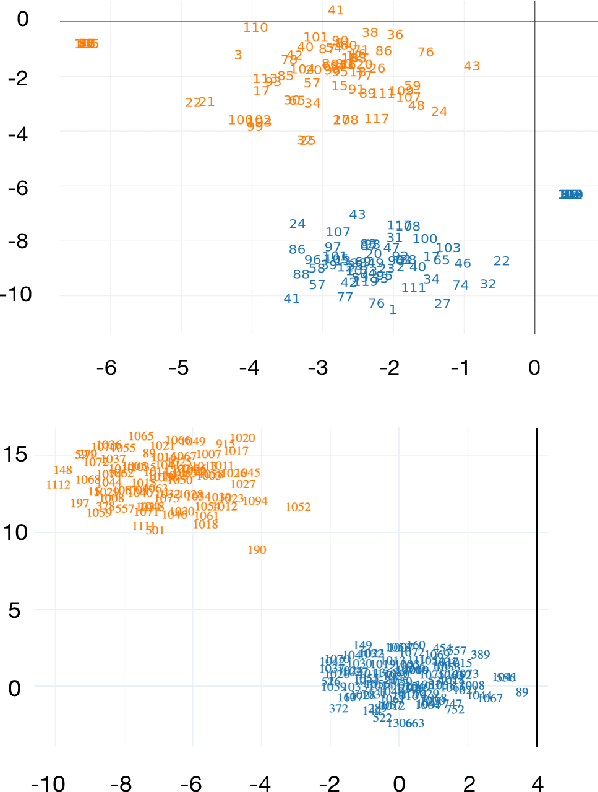
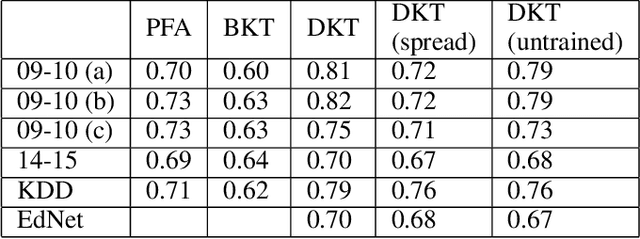
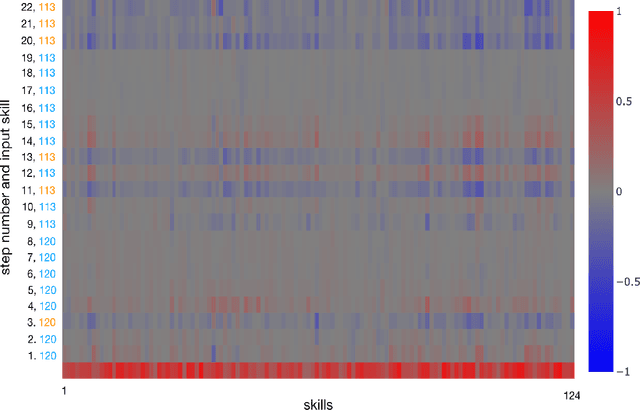
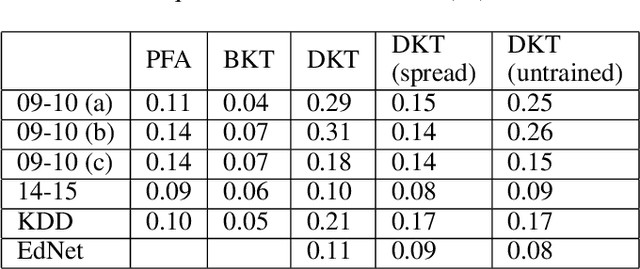
Knowledge tracing allows Intelligent Tutoring Systems to infer which topics or skills a student has mastered, thus adjusting curriculum accordingly. Deep Learning based models like Deep Knowledge Tracing (DKT) and Dynamic Key-Value Memory Network (DKVMN) have achieved significant improvements compared with models like Bayesian Knowledge Tracing (BKT) and Performance Factors Analysis (PFA). However, these deep learning based models are not as interpretable as other models because the decision-making process learned by deep neural networks is not wholly understood by the research community. In previous work, we critically examined the DKT model, visualizing and analyzing the behaviors of DKT in high dimensional space. In this work, we extend our original analyses with a much larger dataset and add discussions about the memory states of the DKVMN model. We discover that Deep Knowledge Tracing has some critical pitfalls: 1) instead of tracking each skill through time, DKT is more likely to learn an `ability' model; 2) the recurrent nature of DKT reinforces irrelevant information that it uses during the tracking task; 3) an untrained recurrent network can achieve similar results to a trained DKT model, supporting a conclusion that recurrence relations are not properly learned and, instead, improvements are simply a benefit of projection into a high dimensional, sparse vector space. Based on these observations, we propose improvements and future directions for conducting knowledge tracing research using deep neural network models.
Hyperdimensional computing as a framework for systematic aggregation of image descriptors
Jan 19, 2021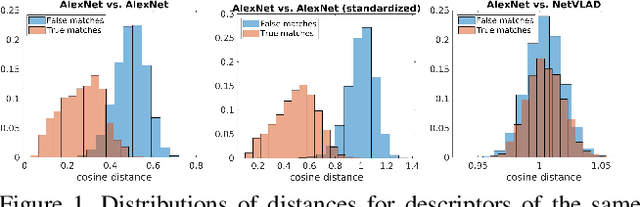
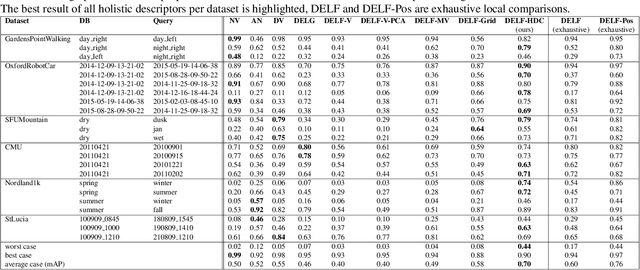
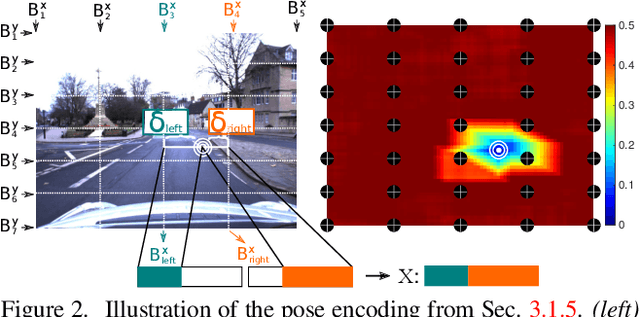
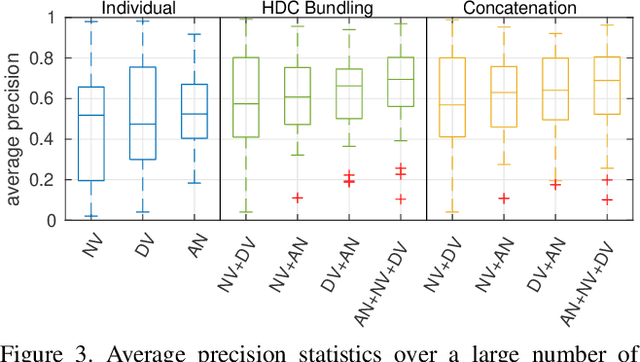
Image and video descriptors are an omnipresent tool in computer vision and its application fields like mobile robotics. Many hand-crafted and in particular learned image descriptors are numerical vectors with a potentially (very) large number of dimensions. Practical considerations like memory consumption or time for comparisons call for the creation of compact representations. In this paper, we use hyperdimensional computing (HDC) as an approach to systematically combine information from a set of vectors in a single vector of the same dimensionality. HDC is a known technique to perform symbolic processing with distributed representation in numerical vectors with thousands of dimensions. We present a HDC implementation that is suitable for processing the output of existing and future (deep-learning based) image descriptors. We discuss how this can be used as a framework to process descriptors together with additional knowledge by simple and fast vector operations. A concrete outcome is a novel HDC-based approach to aggregate a set of local image descriptors together with their image positions in a single holistic descriptor. The comparison to available holistic descriptors and aggregation methods on a series of standard mobile robotics place recognition experiments shows a 20% improvement in average performance compared to runner-up and 3.6x better worst-case performance.
Faithful Euclidean Distance Field from Log-Gaussian Process Implicit Surfaces
Oct 22, 2020
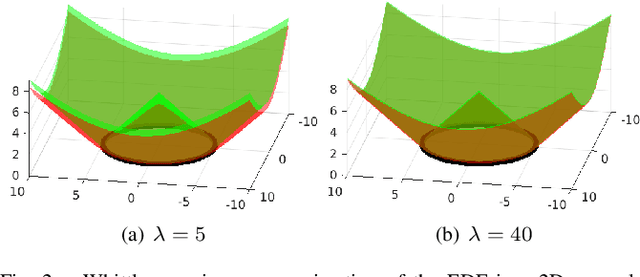
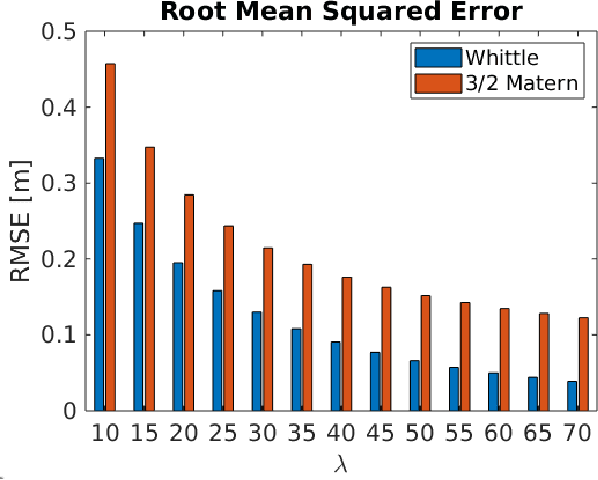
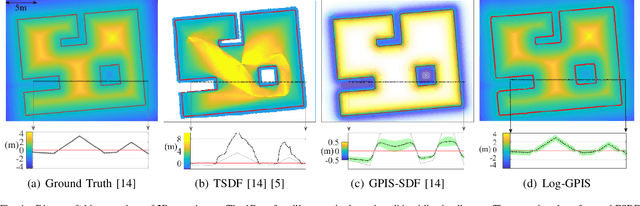
In this letter, we introduce the Log-Gaussian Process Implicit Surface (Log-GPIS), a novel continuous and probabilistic mapping representation suitable for surface reconstruction and local navigation. To derive the proposed representation, Varadhan's formula is exploited to approximate the non-linear Eikonal partial differential equation (PDE) of the Euclidean distance field~(EDF) by the logarithm of the screen Poisson equation that is linear. We show that members of the Matern covariance family directly satisfy this linear PDE. Thus, our key contribution is the realisation that the regularised Eikonal equation can be simply solved by applying the logarithmic function to a GPIS formulation to recover the accurate EDF and, at the same time, the implicit surface. The proposed approach does not require post-processing steps to recover the EDF. Moreover, unlike sampling-based methods, Log-GPIS does not use sample points inside and outside the surface as the derivative of the covariance allow direct estimation of the surface normals and distance gradients. We benchmarked the proposed method on simulated and real data against state-of-the-art mapping frameworks that also aim at recovering both the surface and a distance field. Our experiments show that Log-GPIS produces the most accurate results for the EDF and comparable results for surface reconstruction and its computation time still allows online operations.
Using hardware performance counters to speed up autotuning convergence on GPUs
Feb 10, 2021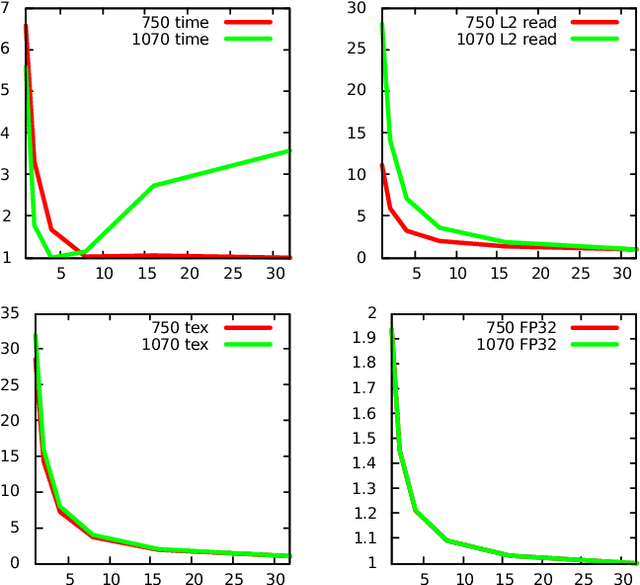

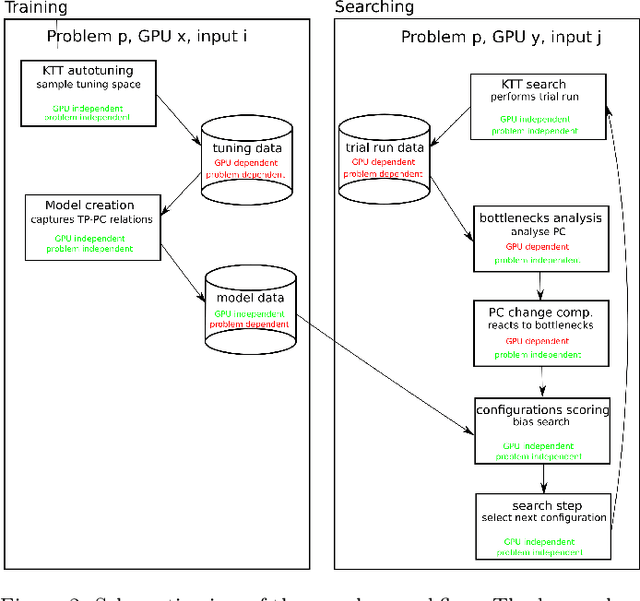
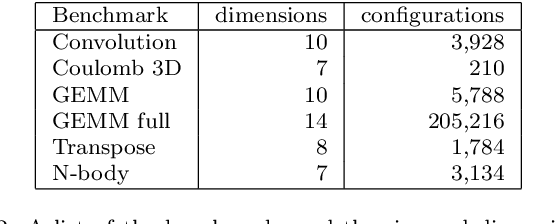
Nowadays, GPU accelerators are commonly used to speed up general-purpose computing tasks on a variety of hardware. However, due to the diversity of GPU architectures and processed data, optimization of codes for a particular type of hardware and specific data characteristics can be extremely challenging. The autotuning of performance-relevant source-code parameters allows for automatic optimization of applications and keeps their performance portable. Although the autotuning process typically results in code speed-up, searching the tuning space can bring unacceptable overhead if (i) the tuning space is vast and full of poorly-performing implementations, or (ii) the autotuning process has to be repeated frequently because of changes in processed data or migration to different hardware. In this paper, we introduce a novel method for searching tuning spaces. The method takes advantage of collecting hardware performance counters (also known as profiling counters) during empirical tuning. Those counters are used to navigate the searching process towards faster implementations. The method requires the tuning space to be sampled on any GPU. It builds a problem-specific model, which can be used during autotuning on various, even previously unseen inputs or GPUs. Using a set of five benchmarks, we experimentally demonstrate that our method can speed up autotuning when an application needs to be ported to different hardware or when it needs to process data with different characteristics. We also compared our method to state of the art and show that our method is superior in terms of the number of searching steps and typically outperforms other searches in terms of convergence time.
Improving Session Recommendation with Recurrent Neural Networks by Exploiting Dwell Time
Jun 30, 2017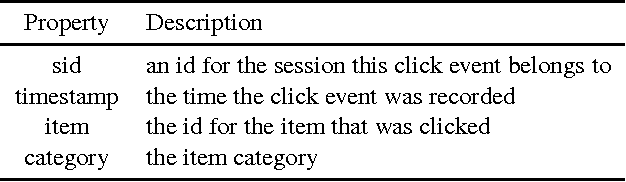
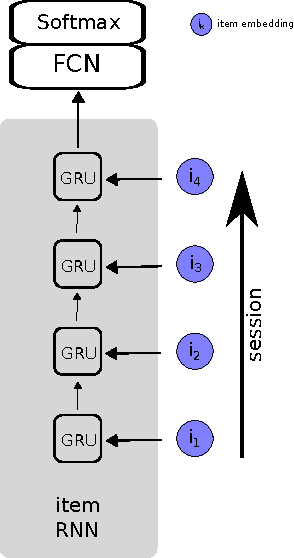
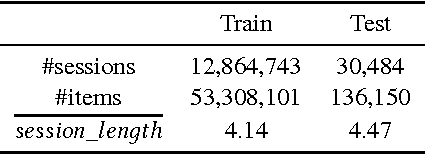
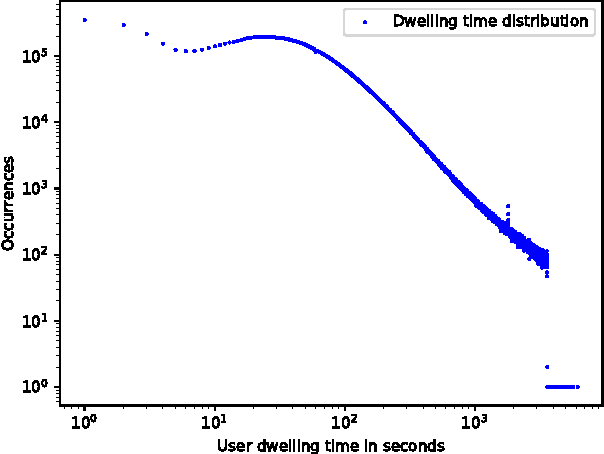
Recently, Recurrent Neural Networks (RNNs) have been applied to the task of session-based recommendation. These approaches use RNNs to predict the next item in a user session based on the previ- ously visited items. While some approaches consider additional item properties, we argue that item dwell time can be used as an implicit measure of user interest to improve session-based item recommen- dations. We propose an extension to existing RNN approaches that captures user dwell time in addition to the visited items and show that recommendation performance can be improved. Additionally, we investigate the usefulness of a single validation split for model selection in the case of minor improvements and find that in our case the best model is not selected and a fold-like study with different validation sets is necessary to ensure the selection of the best model.