 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Temporal Cascade and Structural Modelling of EHRs for Granular Readmission Prediction
Feb 04, 2021
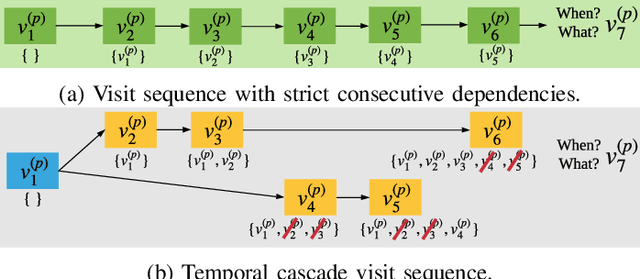
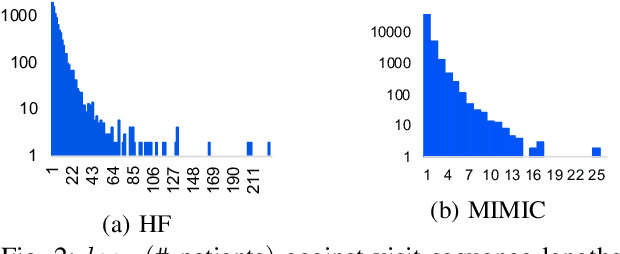
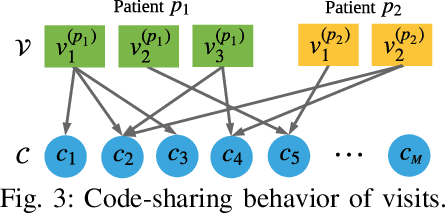
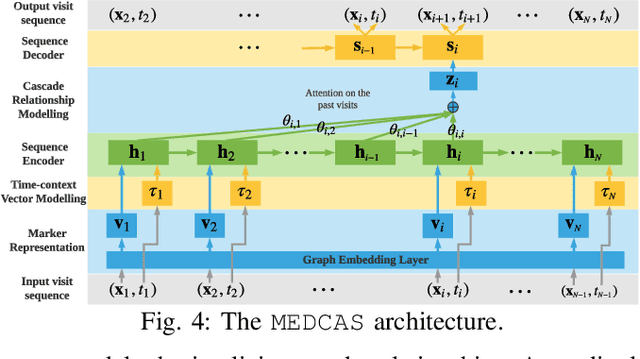
Predicting (1) when the next hospital admission occurs and (2) what will happen in the next admission about a patient by mining electronic health record (EHR) data can provide granular readmission predictions to assist clinical decision making. Recurrent neural network (RNN) and point process models are usually employed in modelling temporal sequential data. Simple RNN models assume that sequences of hospital visits follow strict causal dependencies between consecutive visits. However, in the real-world, a patient may have multiple co-existing chronic medical conditions, i.e., multimorbidity, which results in a cascade of visits where a non-immediate historical visit can be most influential to the next visit. Although a point process (e.g., Hawkes process) is able to model a cascade temporal relationship, it strongly relies on a prior generative process assumption. We propose a novel model, MEDCAS, to address these challenges. MEDCAS combines the strengths of RNN-based models and point processes by integrating point processes in modelling visit types and time gaps into an attention-based sequence-to-sequence learning model, which is able to capture the temporal cascade relationships. To supplement the patients with short visit sequences, a structural modelling technique with graph-based methods is used to construct the markers of the point process in MEDCAS. Extensive experiments on three real-world EHR datasets have been performed and the results demonstrate that \texttt{MEDCAS} outperforms state-of-the-art models in both tasks.
Improving Session Recommendation with Recurrent Neural Networks by Exploiting Dwell Time
Jun 30, 2017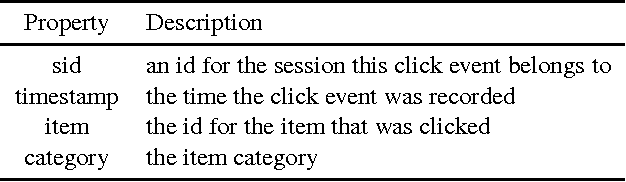
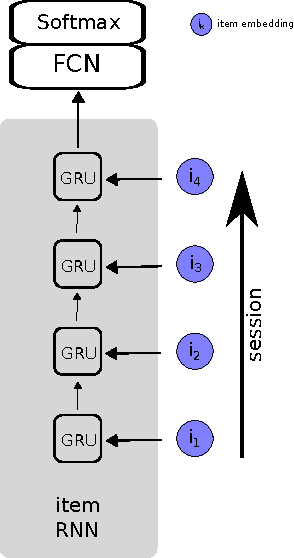
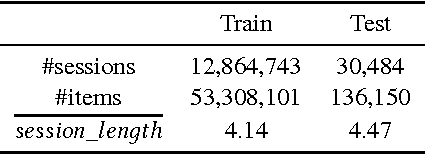
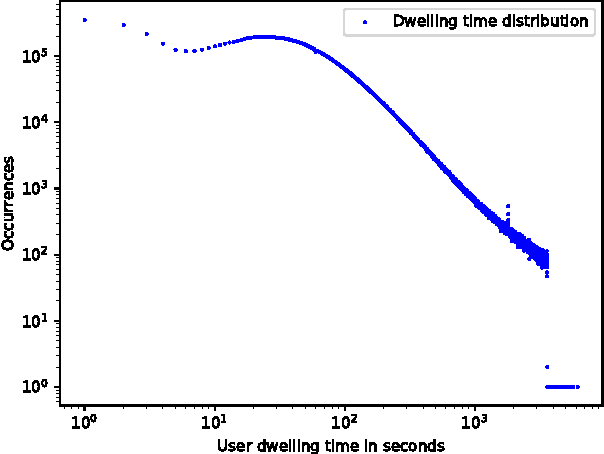
Recently, Recurrent Neural Networks (RNNs) have been applied to the task of session-based recommendation. These approaches use RNNs to predict the next item in a user session based on the previ- ously visited items. While some approaches consider additional item properties, we argue that item dwell time can be used as an implicit measure of user interest to improve session-based item recommen- dations. We propose an extension to existing RNN approaches that captures user dwell time in addition to the visited items and show that recommendation performance can be improved. Additionally, we investigate the usefulness of a single validation split for model selection in the case of minor improvements and find that in our case the best model is not selected and a fold-like study with different validation sets is necessary to ensure the selection of the best model.
Reinforcement Learning for Control of Valves
Feb 04, 2021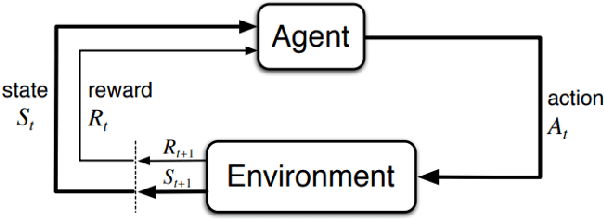
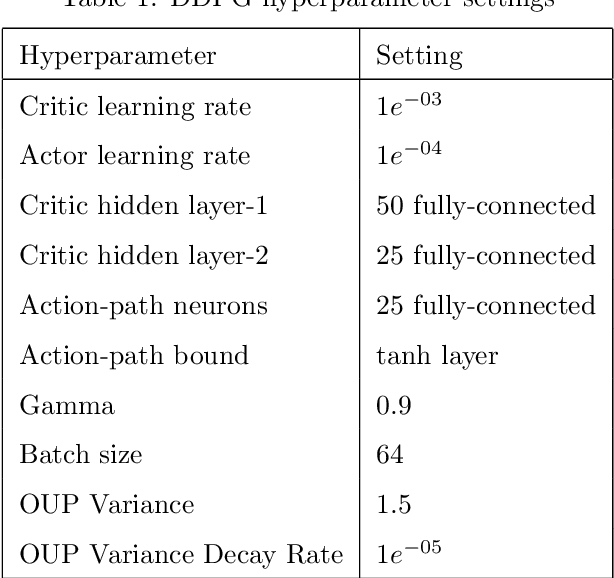
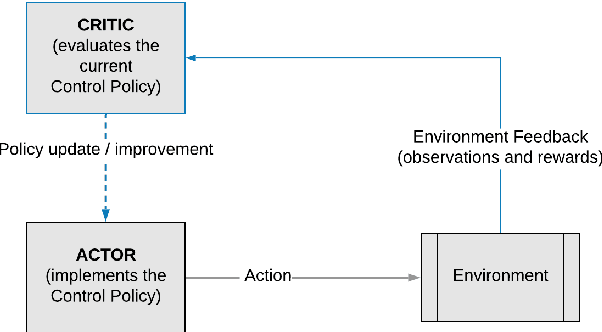
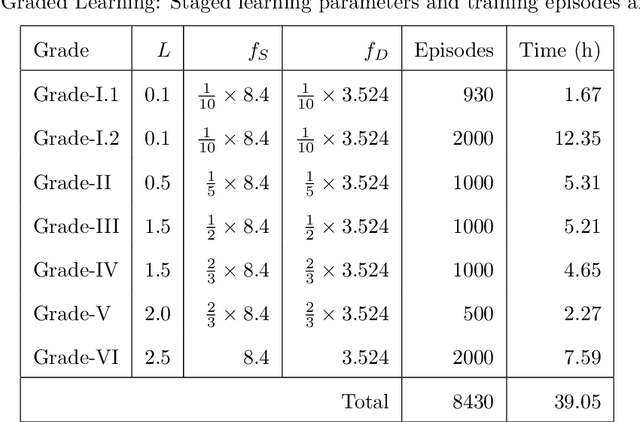
This paper is a study of reinforcement learning (RL) as an optimal-control strategy for control of nonlinear valves. It is evaluated against the PID (proportional-integral-derivative) strategy, using a unified framework. RL is an autonomous learning mechanism that learns by interacting with its environment. It is gaining increasing attention in the world of control systems as a means of building optimal-controllers for challenging dynamic and nonlinear processes. Published RL research often uses open-source tools (Python and OpenAI Gym environments). We use MATLAB's recently launched (R2019a) Reinforcement Learning Toolbox to develop the valve controller; trained using the DDPG (Deep Deterministic Policy-Gradient) algorithm and Simulink to simulate the nonlinear valve and create the experimental test-bench for evaluation. Simulink allows industrial engineers to quickly adapt and experiment with other systems of their choice. Results indicate that the RL controller is extremely good at tracking the signal with speed and produces a lower error with respect to the reference signal. The PID, however, is better at disturbance rejection and hence provides a longer life for the valves. Successful machine learning involves tuning many hyperparameters requiring significant investment of time and efforts. We introduce "Graded Learning" as a simplified, application oriented adaptation of the more formal and algorithmic "Curriculum for Reinforcement Learning". It is shown via experiments that it helps converge the learning task of complex non-linear real world systems. Finally, experiential learnings gained from this research are corroborated against published research.
NB-IoT Random Access for Non-Terrestrial Networks
Jan 20, 2021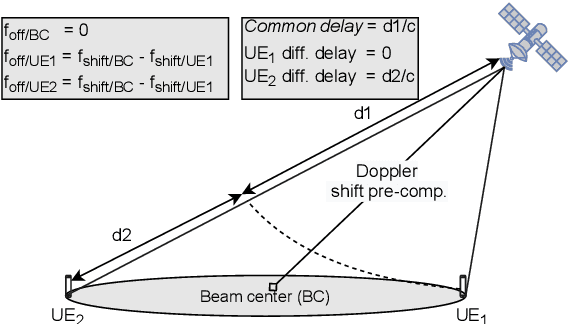
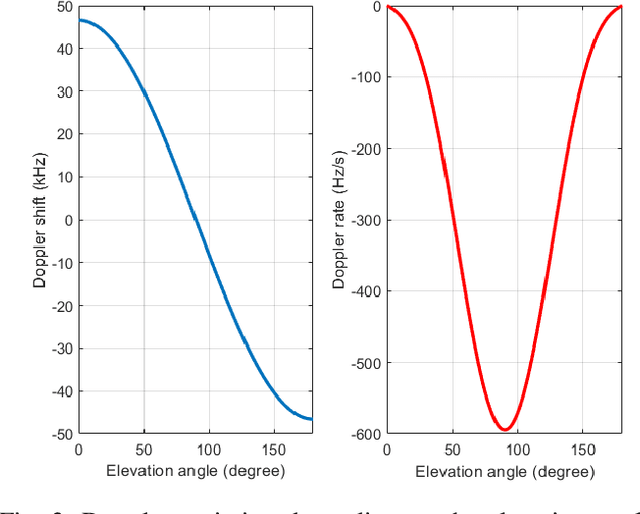
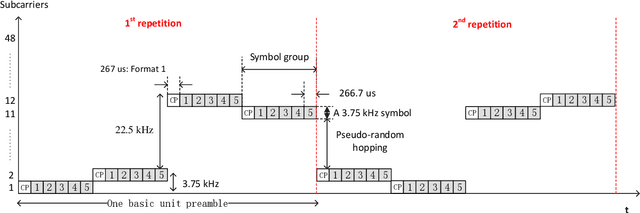
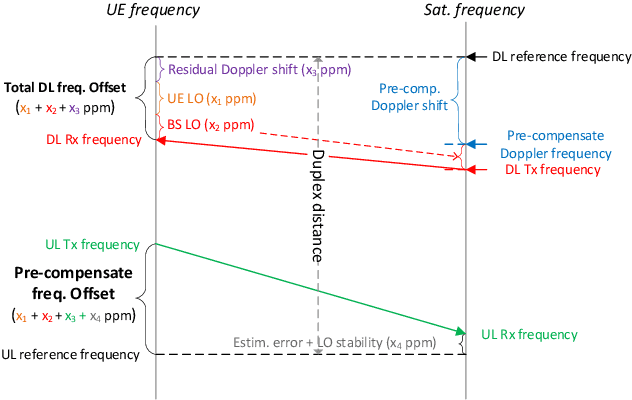
The satellite component is recognized as a promising solution to complement and extend the coverage of future Internet of things (IoT) terrestrial networks (TNs). In this context, a study item to integrate satellites into narrowband IoT (NB-IoT) systems has been approved within the 3rd Generation Partnership Project (3GPP) standardization body. However, as NB-IoT systems were initially conceived for TNs, their basic design principles and operation might require some key modifications when incorporating the satellite component. These changes in NB-IoT systems, therefore, need to be carefully implemented in order to guarantee a seamless integration of both TN and non-terrestrial network (NTN) for a global coverage. This paper addresses this adaptation for the random access (RA) step in NB-IoT systems, which is in fact the most challenging aspect in the NTN context, for it deals with multi-user time-frequency synchronization and timing advance for data scheduling. In particular, we propose an RA technique which is robust to typical satellite channel impairments, including long delays, significant Doppler effects, and wide beams, without requiring any modification to the current NBIoT RA waveform. Performance evaluations demonstrate the proposal's capability of addressing different NTN configurations recently defined by 3GPP for the 5G new radio system.
Anomaly Detection through Transfer Learning in Agriculture and Manufacturing IoT Systems
Feb 11, 2021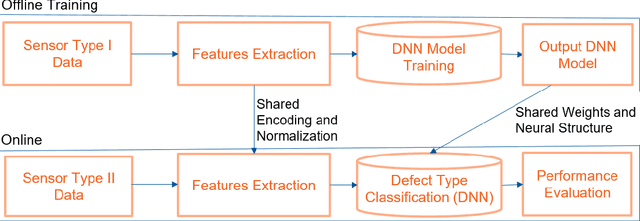
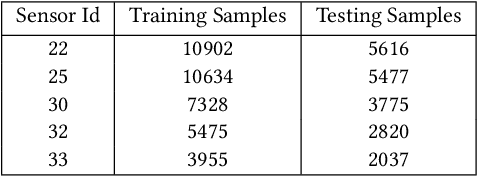
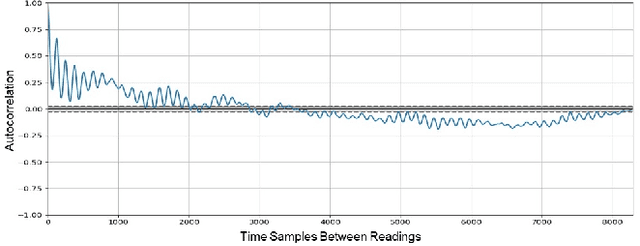
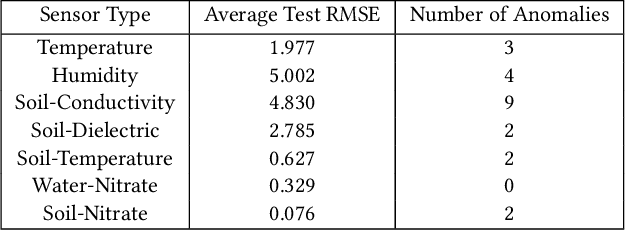
IoT systems have been facing increasingly sophisticated technical problems due to the growing complexity of these systems and their fast deployment practices. Consequently, IoT managers have to judiciously detect failures (anomalies) in order to reduce their cyber risk and operational cost. While there is a rich literature on anomaly detection in many IoT-based systems, there is no existing work that documents the use of ML models for anomaly detection in digital agriculture and in smart manufacturing systems. These two application domains pose certain salient technical challenges. In agriculture the data is often sparse, due to the vast areas of farms and the requirement to keep the cost of monitoring low. Second, in both domains, there are multiple types of sensors with varying capabilities and costs. The sensor data characteristics change with the operating point of the environment or machines, such as, the RPM of the motor. The inferencing and the anomaly detection processes therefore have to be calibrated for the operating point. In this paper, we analyze data from sensors deployed in an agricultural farm with data from seven different kinds of sensors, and from an advanced manufacturing testbed with vibration sensors. We evaluate the performance of ARIMA and LSTM models for predicting the time series of sensor data. Then, considering the sparse data from one kind of sensor, we perform transfer learning from a high data rate sensor. We then perform anomaly detection using the predicted sensor data. Taken together, we show how in these two application domains, predictive failure classification can be achieved, thus paving the way for predictive maintenance.
Anchor-Assisted Channel Estimation for Intelligent Reflecting Surface Aided Multiuser Communication
Feb 23, 2021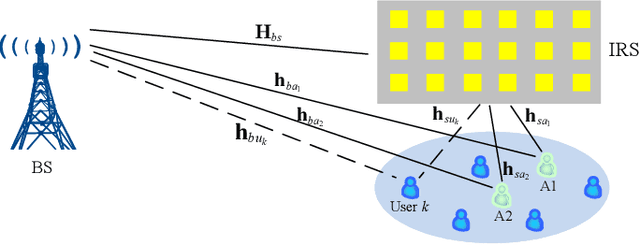
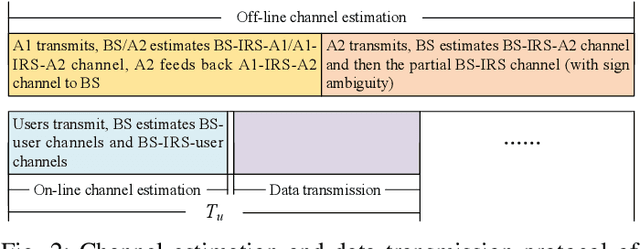
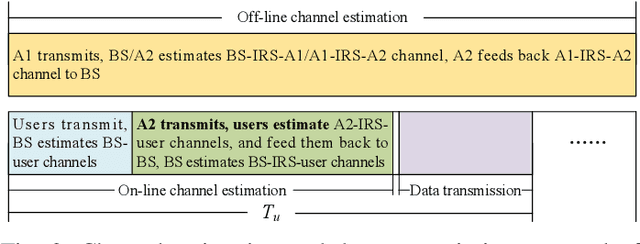
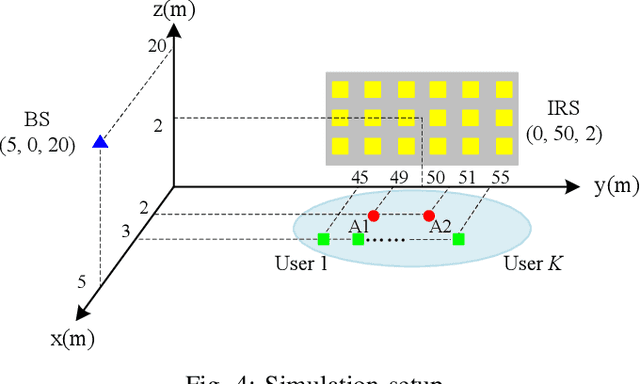
Channel estimation is a practical challenge for intelligent reflecting surface (IRS) aided wireless communication. As the number of IRS reflecting elements or IRS-aided users increases, the channel training overhead becomes excessively high, which results in long delay and low throughput in data transmission. To tackle this challenge, we propose in this paper a new anchor-assisted channel estimation approach, where two anchor nodes, namely A1 and A2, are deployed near the IRS for facilitating its aided base station (BS) in acquiring the cascaded BS-IRS-user channels required for data transmission. Specifically, in the first scheme, the partial channel state information (CSI) on the element-wise channel gain square of the common BS-IRS link for all users is first obtained at the BS via the anchor-assisted training and feedback. Then, by leveraging such partial CSI, the cascaded BS-IRS-user channels are efficiently resolved at the BS with additional training by the users. While in the second scheme, the BS-IRS-A1 and A1-IRS-A2 channels are first estimated via the training by A1. Then, with additional training by A2, all users estimate their individual cascaded A2-IRS-user channels simultaneously. Based on the CSI fed back from A2 and all users, the BS resolves the cascaded BS-IRS-user channels efficiently. In both schemes, the quasi-static channels among the fixed BS, IRS, and two anchors are estimated off-line only, which greatly reduces the real-time training overhead. Simulation results demonstrate that our proposed anchor-assisted channel estimation schemes achieve superior performance as compared to existing IRS channel estimation schemes, under various practical setups. In addition, the first proposed scheme outperforms the second one when the number of antennas at the BS is sufficiently large, and vice versa.
Binomial Tails for Community Analysis
Dec 17, 2020

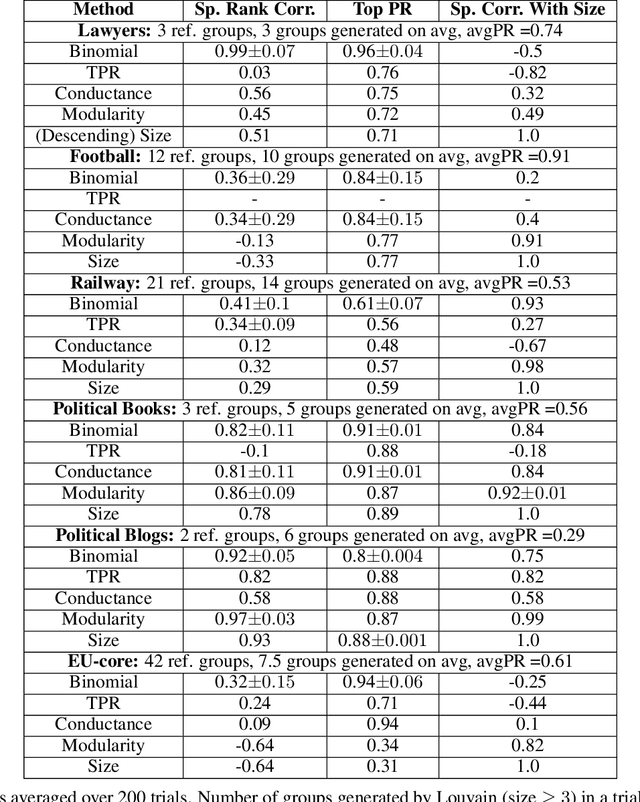
An important task of community discovery in networks is assessing significance of the results and robust ranking of the generated candidate groups. Often in practice, numerous candidate communities are discovered, and focusing the analyst's time on the most salient and promising findings is crucial. We develop simple efficient group scoring functions derived from tail probabilities using binomial models. Experiments on synthetic and numerous real-world data provides evidence that binomial scoring leads to a more robust ranking than other inexpensive scoring functions, such as conductance. Furthermore, we obtain confidence values ($p$-values) that can be used for filtering and labeling the discovered groups. Our analyses shed light on various properties of the approach. The binomial tail is simple and versatile, and we describe two other applications for community analysis: degree of community membership (which in turn yields group-scoring functions), and the discovery of significant edges in the community-induced graph.
Context- and Sequence-Aware Convolutional Recurrent Encoder for Neural Machine Translation
Jan 11, 2021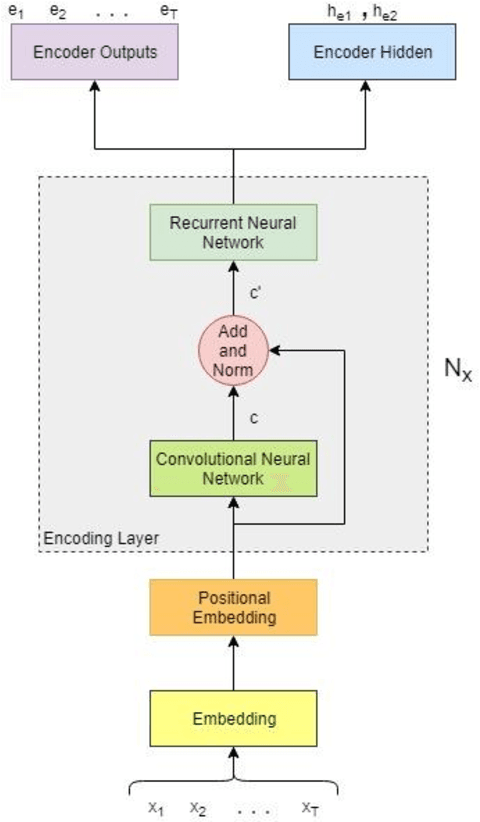
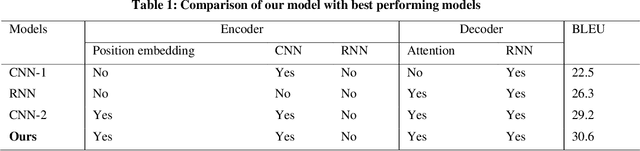
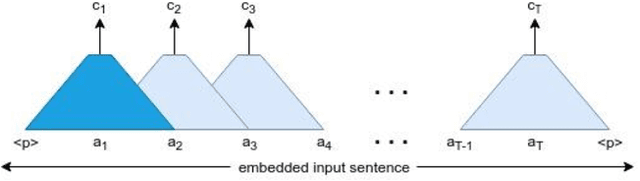
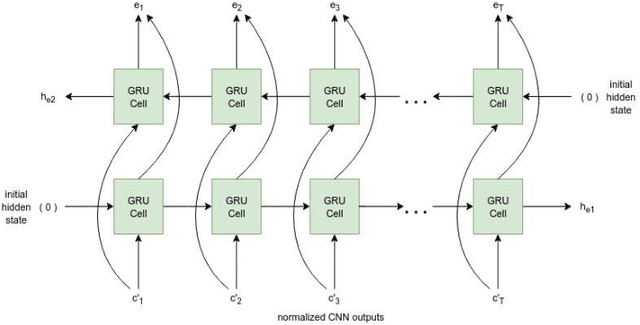
Neural Machine Translation model is a sequence-to-sequence converter based on neural networks. Existing models use recurrent neural networks to construct both the encoder and decoder modules. In alternative research, the recurrent networks were substituted by convolutional neural networks for capturing the syntactic structure in the input sentence and decreasing the processing time. We incorporate the goodness of both approaches by proposing a convolutional-recurrent encoder for capturing the context information as well as the sequential information from the source sentence. Word embedding and position embedding of the source sentence is performed prior to the convolutional encoding layer which is basically a n-gram feature extractor capturing phrase-level context information. The rectified output of the convolutional encoding layer is added to the original embedding vector, and the sum is normalized by layer normalization. The normalized output is given as a sequential input to the recurrent encoding layer that captures the temporal information in the sequence. For the decoder, we use the attention-based recurrent neural network. Translation task on the German-English dataset verifies the efficacy of the proposed approach from the higher BLEU scores achieved as compared to the state of the art.
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Jan 11, 2021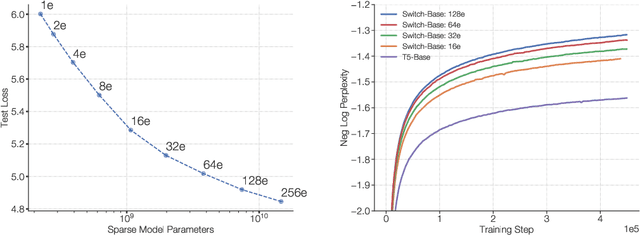
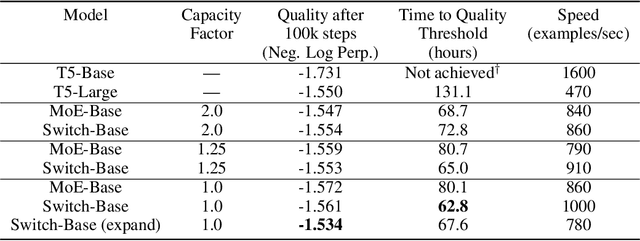
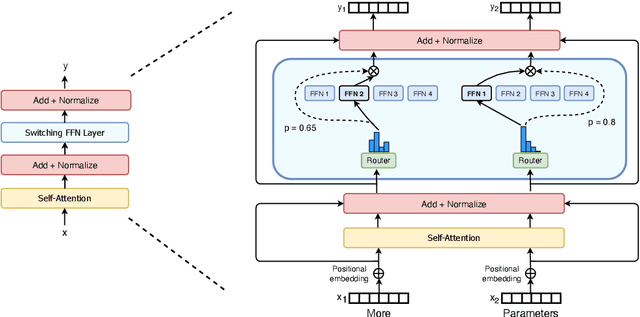
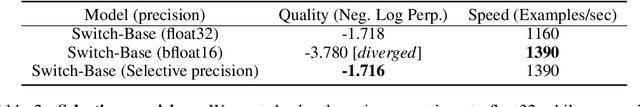
In deep learning, models typically reuse the same parameters for all inputs. Mixture of Experts (MoE) defies this and instead selects different parameters for each incoming example. The result is a sparsely-activated model -- with outrageous numbers of parameters -- but a constant computational cost. However, despite several notable successes of MoE, widespread adoption has been hindered by complexity, communication costs and training instability -- we address these with the Switch Transformer. We simplify the MoE routing algorithm and design intuitive improved models with reduced communication and computational costs. Our proposed training techniques help wrangle the instabilities and we show large sparse models may be trained, for the first time, with lower precision (bfloat16) formats. We design models based off T5-Base and T5-Large to obtain up to 7x increases in pre-training speed with the same computational resources. These improvements extend into multilingual settings where we measure gains over the mT5-Base version across all 101 languages. Finally, we advance the current scale of language models by pre-training up to trillion parameter models on the "Colossal Clean Crawled Corpus" and achieve a 4x speedup over the T5-XXL model.
Individual Mobility Prediction: An Interpretable Activity-based Hidden Markov Approach
Jan 11, 2021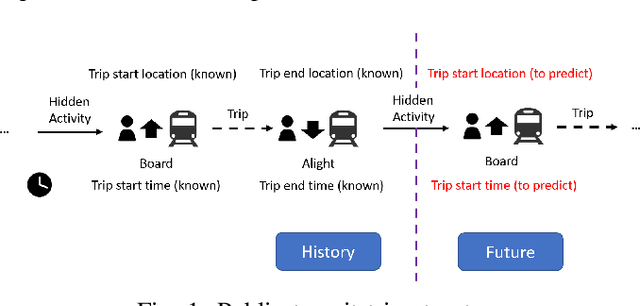
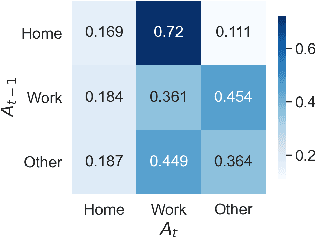
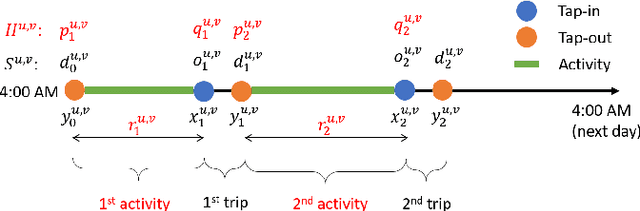
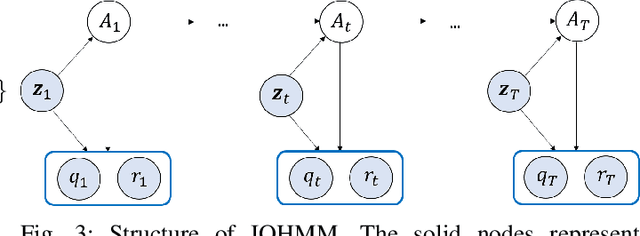
Individual mobility is driven by demand for activities with diverse spatiotemporal patterns, but existing methods for mobility prediction often overlook the underlying activity patterns. To address this issue, this study develops an activity-based modeling framework for individual mobility prediction. Specifically, an input-output hidden Markov model (IOHMM) framework is proposed to simultaneously predict the (continuous) time and (discrete) location of an individual's next trip using transit smart card data. The prediction task can be transformed into predicting the hidden activity duration and end location. Based on a case study of Hong Kong's metro system, we show that the proposed model can achieve similar prediction performance as the state-of-the-art long short-term memory (LSTM) model. Unlike LSTM, the proposed IOHMM model can also be used to analyze hidden activity patterns, which provides meaningful behavioral interpretation for why an individual makes a certain trip. Therefore, the activity-based prediction framework offers a way to preserve the predictive power of advanced machine learning methods while enhancing our ability to generate insightful behavioral explanations, which is useful for enhancing situational awareness in user-centric transportation applications such as personalized traveler information.