 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Graph convolutions that can finally model local structure
Nov 30, 2020
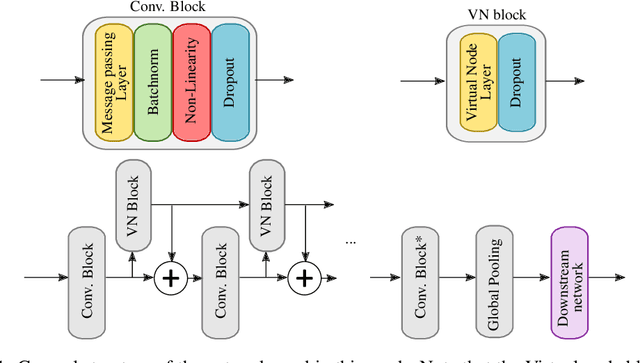

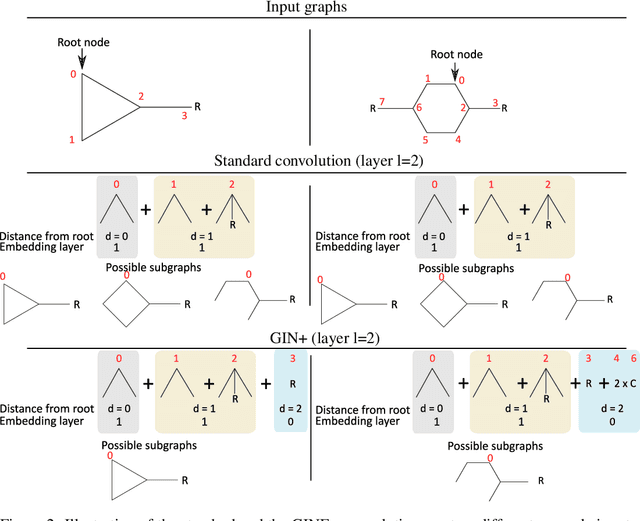
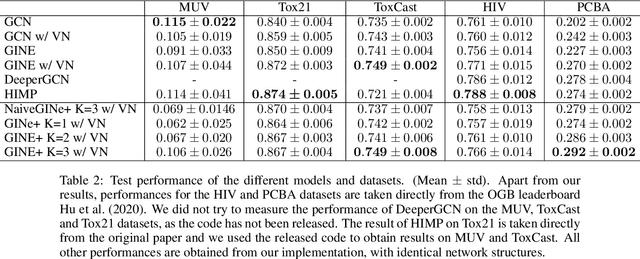
Despite quick progress in the last few years, recent studies have shown that modern graph neural networks can still fail at very simple tasks, like detecting small cycles. This hints at the fact that current networks fail to catch information about the local structure, which is problematic if the downstream task heavily relies on graph substructure analysis, as in the context of chemistry. We propose a very simple correction to the now standard GIN convolution that enables the network to detect small cycles with nearly no cost in terms of computation time and number of parameters. Tested on real life molecule property datasets, our model consistently improves performance on large multi-tasked datasets over all baselines, both globally and on a per-task setting.
Exchanging Lessons Between Algorithmic Fairness and Domain Generalization
Oct 14, 2020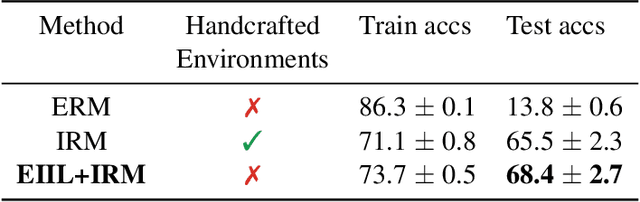
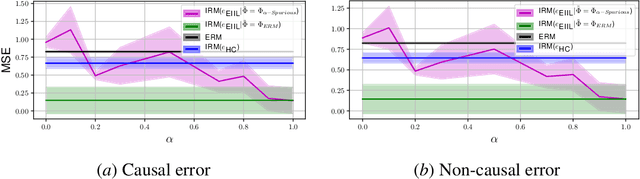
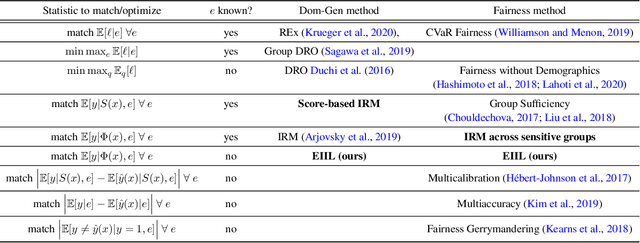

Standard learning approaches are designed to perform well on average for the data distribution available at training time. Developing learning approaches that are not overly sensitive to the training distribution is central to research on domain- or out-of-distribution generalization, robust optimization and fairness. In this work we focus on links between research on domain generalization and algorithmic fairness -- where performance under a distinct but related test distributions is studied -- and show how the two fields can be mutually beneficial. While domain generalization methods typically rely on knowledge of disjoint "domains" or "environments", "sensitive" label information indicating which demographic groups are at risk of discrimination is often used in the fairness literature. Drawing inspiration from recent fairness approaches that improve worst-case performance without knowledge of sensitive groups, we propose a novel domain generalization method that handles the more realistic scenario where environment partitions are not provided. We then show theoretically and empirically how different partitioning schemes can lead to increased or decreased generalization performance, enabling us to outperform Invariant Risk Minimization with handcrafted environments in multiple cases. We also show how a re-interpretation of IRMv1 allows us for the first time to directly optimize a common fairness criterion, group-sufficiency, and thereby improve performance on a fair prediction task.
Im2Vec: Synthesizing Vector Graphics without Vector Supervision
Feb 04, 2021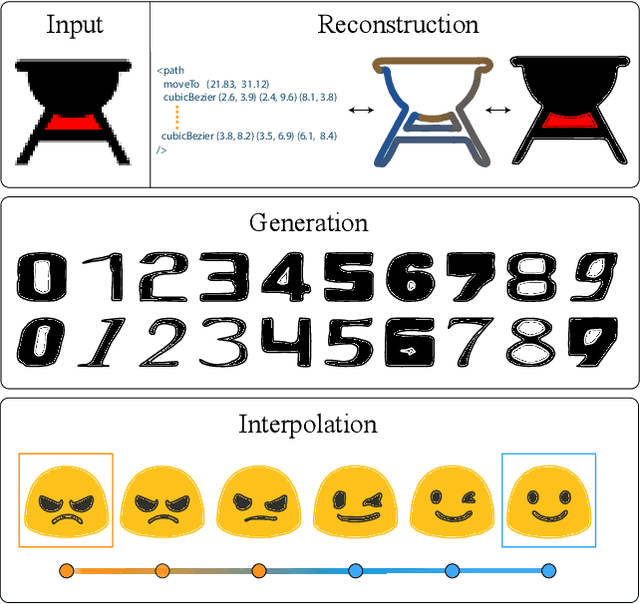
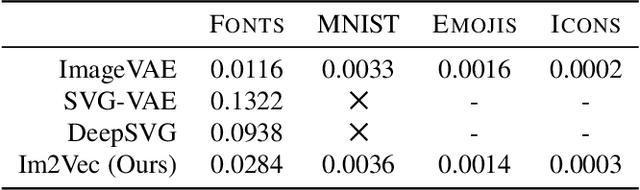

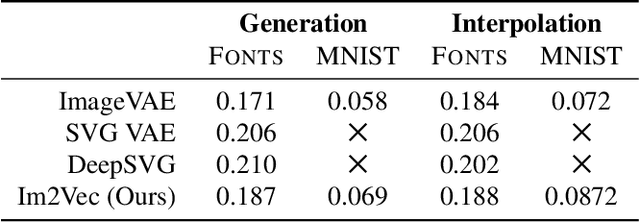
Vector graphics are widely used to represent fonts, logos, digital artworks, and graphic designs. But, while a vast body of work has focused on generative algorithms for raster images, only a handful of options exists for vector graphics. One can always rasterize the input graphic and resort to image-based generative approaches, but this negates the advantages of the vector representation. The current alternative is to use specialized models that require explicit supervision on the vector graphics representation at training time. This is not ideal because large-scale high quality vector-graphics datasets are difficult to obtain. Furthermore, the vector representation for a given design is not unique, so models that supervise on the vector representation are unnecessarily constrained. Instead, we propose a new neural network that can generate complex vector graphics with varying topologies, and only requires indirect supervision from readily-available raster training images (i.e., with no vector counterparts). To enable this, we use a differentiable rasterization pipeline that renders the generated vector shapes and composites them together onto a raster canvas. We demonstrate our method on a range of datasets, and provide comparison with state-of-the-art SVG-VAE and DeepSVG, both of which require explicit vector graphics supervision. Finally, we also demonstrate our approach on the MNIST dataset, for which no groundtruth vector representation is available. Source code, datasets, and more results are available at http://geometry.cs.ucl.ac.uk/projects/2020/Im2Vec/
Generating Coherent and Diverse Slogans with Sequence-to-Sequence Transformer
Feb 11, 2021
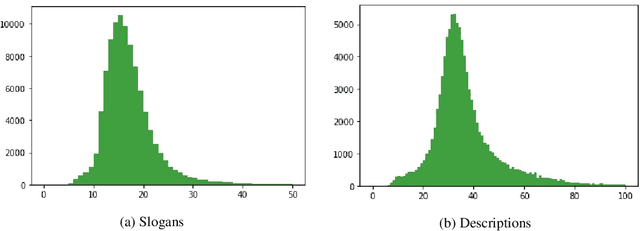

Previous work in slogan generation focused on generating novel slogans by utilising templates mined from real slogans. While some such slogans can be catchy, they are often not coherent with the company's focus or style across their marketing communications because the templates are mined from other companies' slogans. We propose a sequence-to-sequence transformer model to generate slogans from a brief company description. A naive sequence-to-sequence model fine-tuned for slogan generation is prone to introducing false information, especially unrelated company names appearing in the training data. We use delexicalisation to address this problem and improve the generated slogans' quality by a large margin. Furthermore, we apply two simple but effective approaches to generate more diverse slogans. Firstly, we train a slogan generator conditioned on the industry. During inference time, by changing the industry, we can obtain different "flavours" of slogans. Secondly, instead of using only the company description as the input sequence, we sample random paragraphs from the company's website. Surprisingly, the model can generate meaningful slogans, even if the input sequence does not resemble a company description. We validate the effectiveness of the proposed method with both quantitative evaluation and qualitative evaluation. Our best model achieved a ROUGE-1/-2/-L F1 score of 53.13/33.30/46.49. Besides, human evaluators assigned the generated slogans an average score of 3.39 on a scale of 1-5, indicating the system can generate plausible slogans with a quality close to human-written ones (average score 3.55).
Mixup Without Hesitation
Jan 12, 2021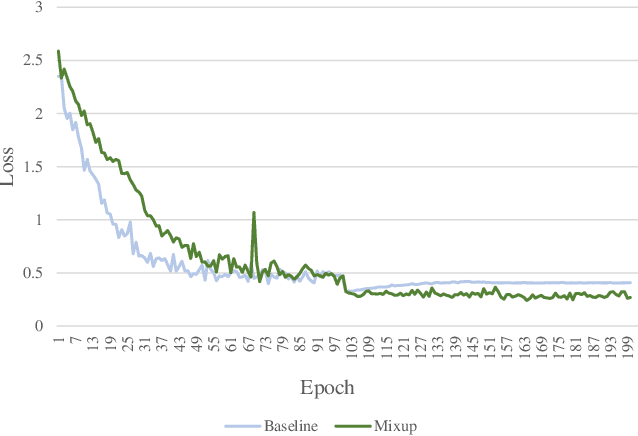
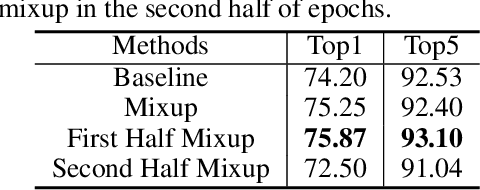


Mixup linearly interpolates pairs of examples to form new samples, which is easy to implement and has been shown to be effective in image classification tasks. However, there are two drawbacks in mixup: one is that more training epochs are needed to obtain a well-trained model; the other is that mixup requires tuning a hyper-parameter to gain appropriate capacity but that is a difficult task. In this paper, we find that mixup constantly explores the representation space, and inspired by the exploration-exploitation dilemma in reinforcement learning, we propose mixup Without hesitation (mWh), a concise, effective, and easy-to-use training algorithm. We show that mWh strikes a good balance between exploration and exploitation by gradually replacing mixup with basic data augmentation. It can achieve a strong baseline with less training time than original mixup and without searching for optimal hyper-parameter, i.e., mWh acts as mixup without hesitation. mWh can also transfer to CutMix, and gain consistent improvement on other machine learning and computer vision tasks such as object detection. Our code is open-source and available at https://github.com/yuhao318/mwh
Averaging Atmospheric Gas Concentration Data using Wasserstein Barycenters
Oct 06, 2020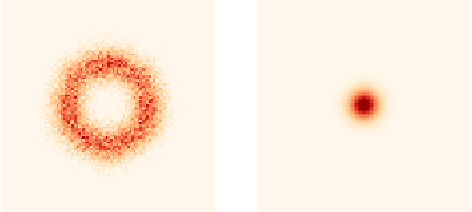
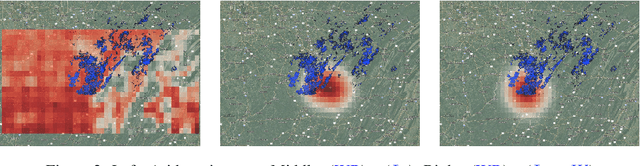
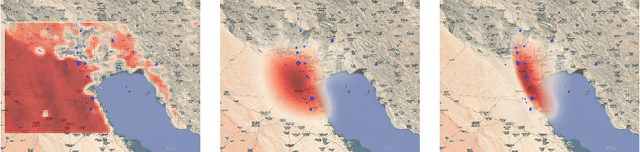
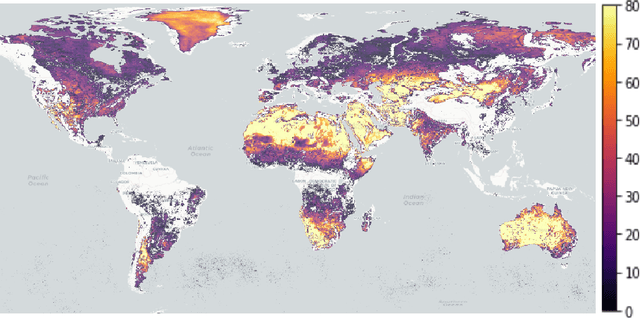
Hyperspectral satellite images report greenhouse gas concentrations worldwide on a daily basis. While taking simple averages of these images over time produces a rough estimate of relative emission rates, atmospheric transport means that simple averages fail to pinpoint the source of these emissions. We propose using Wasserstein barycenters coupled with weather data to average gas concentration data sets and better concentrate the mass around significant sources.
Knowledge-Assisted Deep Reinforcement Learning in 5G Scheduler Design: From Theoretical Framework to Implementation
Sep 17, 2020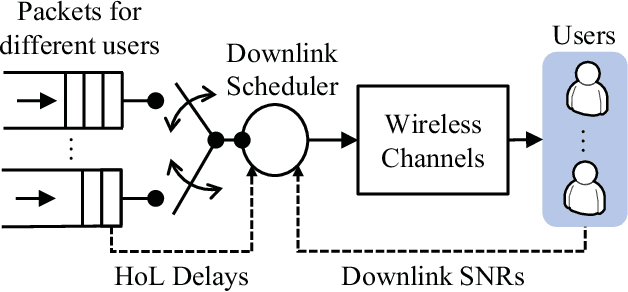
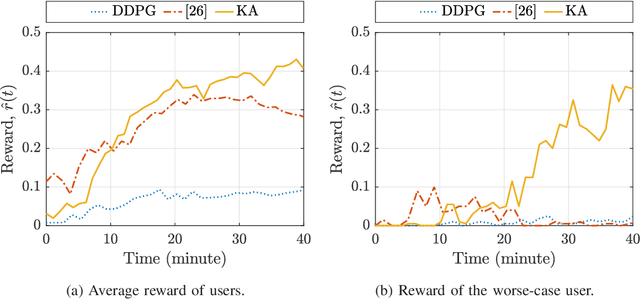
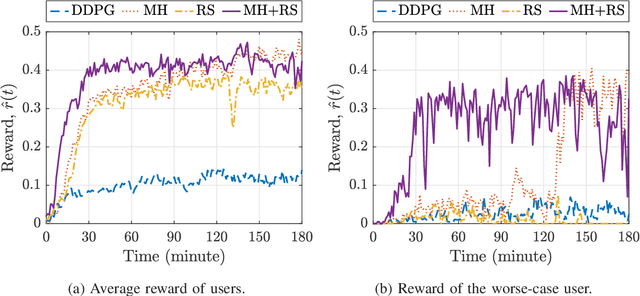
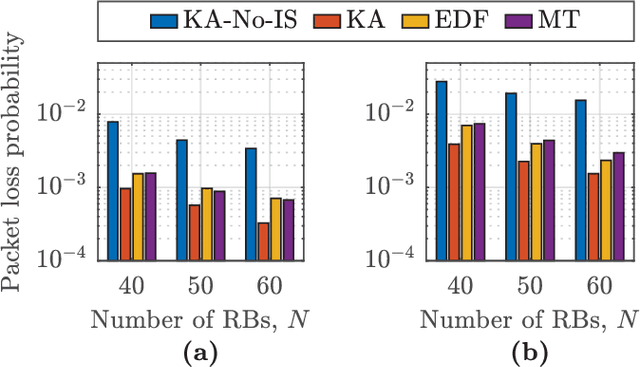
In this paper, we develop a knowledge-assisted deep reinforcement learning (DRL) algorithm to design wireless schedulers in the fifth-generation (5G) cellular networks with time-sensitive traffic. Since the scheduling policy is a deterministic mapping from channel and queue states to scheduling actions, it can be optimized by using deep deterministic policy gradient (DDPG). We show that a straightforward implementation of DDPG converges slowly, has a poor quality-of-service (QoS) performance, and cannot be implemented in real-world 5G systems, which are non-stationary in general. To address these issues, we propose a theoretical DRL framework, where theoretical models from wireless communications are used to formulate a Markov decision process in DRL. To reduce the convergence time and improve the QoS of each user, we design a knowledge-assisted DDPG (K-DDPG) that exploits expert knowledge of the scheduler deign problem, such as the knowledge of the QoS, the target scheduling policy, and the importance of each training sample, determined by the approximation error of the value function and the number of packet losses. Furthermore, we develop an architecture for online training and inference, where K-DDPG initializes the scheduler off-line and then fine-tunes the scheduler online to handle the mismatch between off-line simulations and non-stationary real-world systems. Simulation results show that our approach reduces the convergence time of DDPG significantly and achieves better QoS than existing schedulers (reducing 30% ~ 50% packet losses). Experimental results show that with off-line initialization, our approach achieves better initial QoS than random initialization and the online fine-tuning converges in few minutes.
Temporal Cascade and Structural Modelling of EHRs for Granular Readmission Prediction
Feb 04, 2021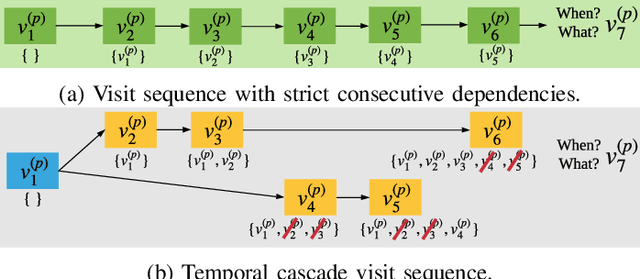
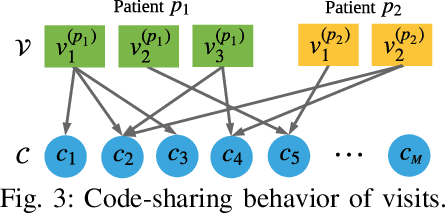
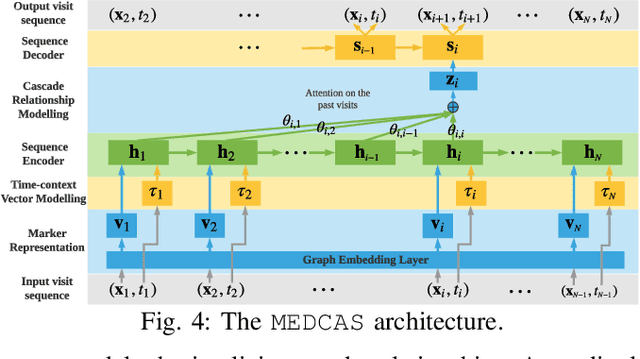
Predicting (1) when the next hospital admission occurs and (2) what will happen in the next admission about a patient by mining electronic health record (EHR) data can provide granular readmission predictions to assist clinical decision making. Recurrent neural network (RNN) and point process models are usually employed in modelling temporal sequential data. Simple RNN models assume that sequences of hospital visits follow strict causal dependencies between consecutive visits. However, in the real-world, a patient may have multiple co-existing chronic medical conditions, i.e., multimorbidity, which results in a cascade of visits where a non-immediate historical visit can be most influential to the next visit. Although a point process (e.g., Hawkes process) is able to model a cascade temporal relationship, it strongly relies on a prior generative process assumption. We propose a novel model, MEDCAS, to address these challenges. MEDCAS combines the strengths of RNN-based models and point processes by integrating point processes in modelling visit types and time gaps into an attention-based sequence-to-sequence learning model, which is able to capture the temporal cascade relationships. To supplement the patients with short visit sequences, a structural modelling technique with graph-based methods is used to construct the markers of the point process in MEDCAS. Extensive experiments on three real-world EHR datasets have been performed and the results demonstrate that \texttt{MEDCAS} outperforms state-of-the-art models in both tasks.
Learning to Augment for Data-Scarce Domain BERT Knowledge Distillation
Jan 20, 2021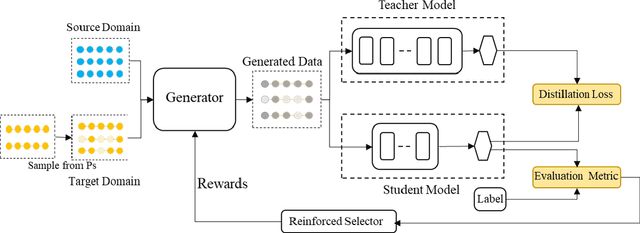
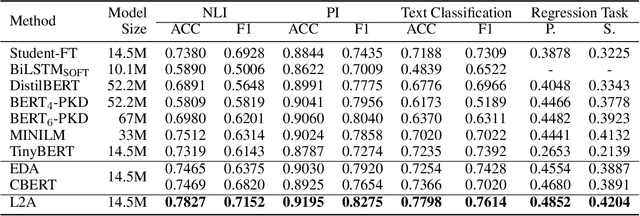
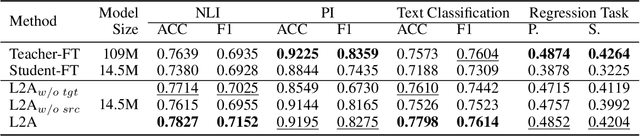
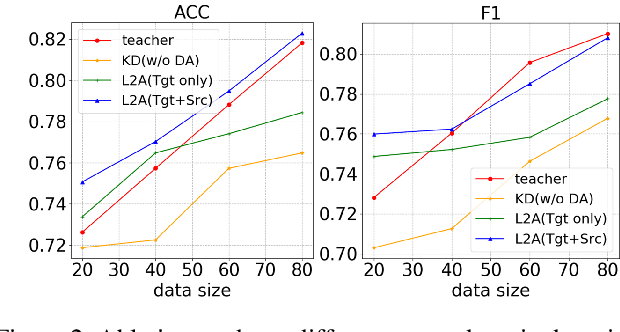
Despite pre-trained language models such as BERT have achieved appealing performance in a wide range of natural language processing tasks, they are computationally expensive to be deployed in real-time applications. A typical method is to adopt knowledge distillation to compress these large pre-trained models (teacher models) to small student models. However, for a target domain with scarce training data, the teacher can hardly pass useful knowledge to the student, which yields performance degradation for the student models. To tackle this problem, we propose a method to learn to augment for data-scarce domain BERT knowledge distillation, by learning a cross-domain manipulation scheme that automatically augments the target with the help of resource-rich source domains. Specifically, the proposed method generates samples acquired from a stationary distribution near the target data and adopts a reinforced selector to automatically refine the augmentation strategy according to the performance of the student. Extensive experiments demonstrate that the proposed method significantly outperforms state-of-the-art baselines on four different tasks, and for the data-scarce domains, the compressed student models even perform better than the original large teacher model, with much fewer parameters (only ${\sim}13.3\%$) when only a few labeled examples available.
Robust Sub-Gaussian Principal Component Analysis and Width-Independent Schatten Packing
Jun 12, 2020We develop two methods for the following fundamental statistical task: given an $\epsilon$-corrupted set of $n$ samples from a $d$-dimensional sub-Gaussian distribution, return an approximate top eigenvector of the covariance matrix. Our first robust PCA algorithm runs in polynomial time, returns a $1 - O(\epsilon\log\epsilon^{-1})$-approximate top eigenvector, and is based on a simple iterative filtering approach. Our second, which attains a slightly worse approximation factor, runs in nearly-linear time and sample complexity under a mild spectral gap assumption. These are the first polynomial-time algorithms yielding non-trivial information about the covariance of a corrupted sub-Gaussian distribution without requiring additional algebraic structure of moments. As a key technical tool, we develop the first width-independent solvers for Schatten-$p$ norm packing semidefinite programs, giving a $(1 + \epsilon)$-approximate solution in $O(p\log(\tfrac{nd}{\epsilon})\epsilon^{-1})$ input-sparsity time iterations (where $n$, $d$ are problem dimensions).