 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Using Restricted Boltzmann Machines to Model Molecular Geometries
Dec 13, 2020
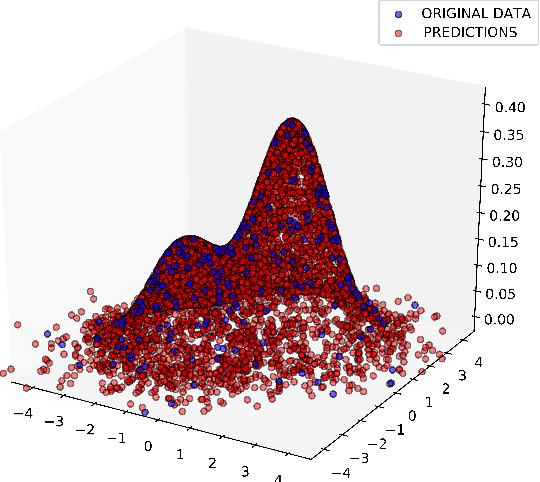

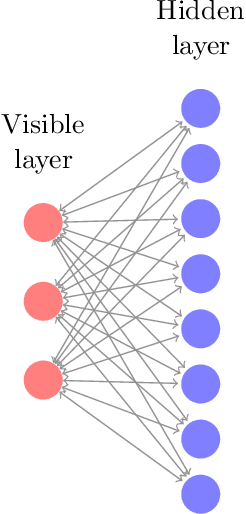
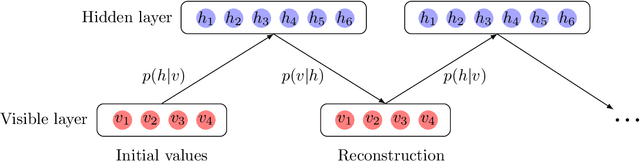
Precise physical descriptions of molecules can be obtained by solving the Schrodinger equation; however, these calculations are intractable and even approximations can be cumbersome. Force fields, which estimate interatomic potentials based on empirical data, are also time-consuming. This paper proposes a new methodology for modeling a set of physical parameters by taking advantage of the restricted Boltzmann machine's fast learning capacity and representational power. By training the machine on ab initio data, we can predict new data in the distribution of molecular configurations matching the ab initio distribution. In this paper we introduce a new RBM based on the Tanh activation function, and conduct a comparison of RBMs with different activation functions, including sigmoid, Gaussian, and (Leaky) ReLU. Finally we demonstrate the ability of Gaussian RBMs to model small molecules such as water and ethane.
Averaging Atmospheric Gas Concentration Data using Wasserstein Barycenters
Oct 06, 2020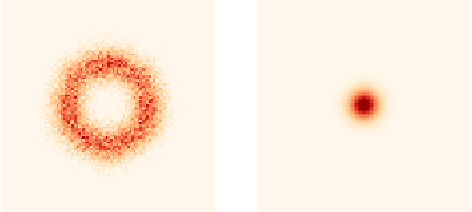
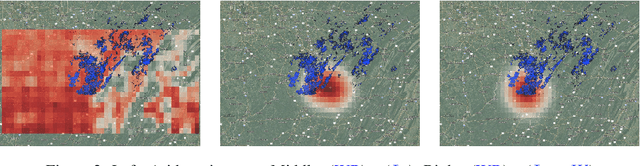
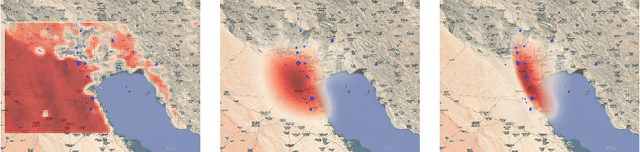
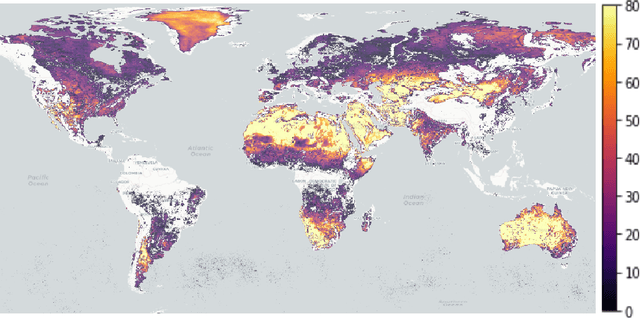
Hyperspectral satellite images report greenhouse gas concentrations worldwide on a daily basis. While taking simple averages of these images over time produces a rough estimate of relative emission rates, atmospheric transport means that simple averages fail to pinpoint the source of these emissions. We propose using Wasserstein barycenters coupled with weather data to average gas concentration data sets and better concentrate the mass around significant sources.
Robust Sub-Gaussian Principal Component Analysis and Width-Independent Schatten Packing
Jun 12, 2020We develop two methods for the following fundamental statistical task: given an $\epsilon$-corrupted set of $n$ samples from a $d$-dimensional sub-Gaussian distribution, return an approximate top eigenvector of the covariance matrix. Our first robust PCA algorithm runs in polynomial time, returns a $1 - O(\epsilon\log\epsilon^{-1})$-approximate top eigenvector, and is based on a simple iterative filtering approach. Our second, which attains a slightly worse approximation factor, runs in nearly-linear time and sample complexity under a mild spectral gap assumption. These are the first polynomial-time algorithms yielding non-trivial information about the covariance of a corrupted sub-Gaussian distribution without requiring additional algebraic structure of moments. As a key technical tool, we develop the first width-independent solvers for Schatten-$p$ norm packing semidefinite programs, giving a $(1 + \epsilon)$-approximate solution in $O(p\log(\tfrac{nd}{\epsilon})\epsilon^{-1})$ input-sparsity time iterations (where $n$, $d$ are problem dimensions).
Data-Driven Reachability Analysis Using Matrix Zonotopes
Nov 17, 2020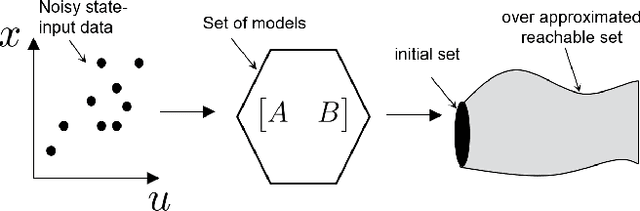
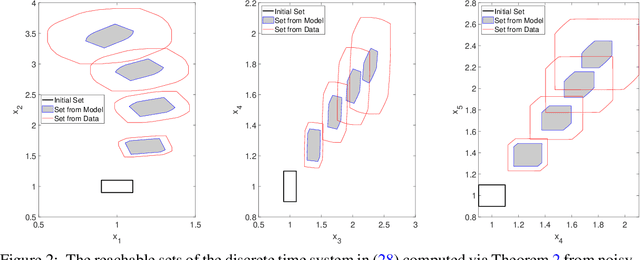
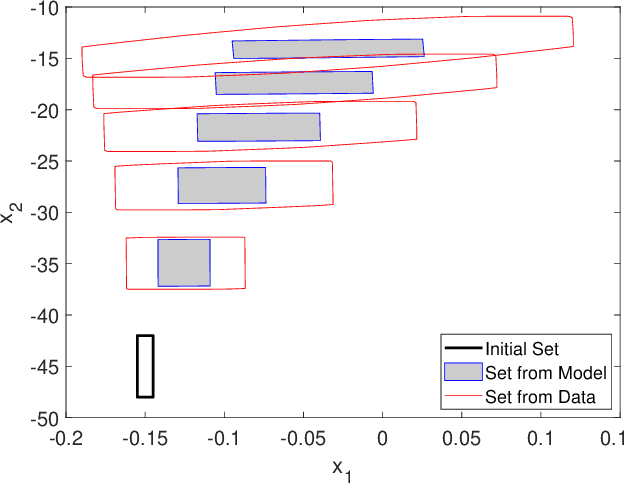
In this paper, we propose a data-driven reachability analysis approach for an unknown control system. Reachability analysis is an essential tool for guaranteeing safety properties. However, most current reachability analysis heavily relies on the existence of a suitable system model, which is often not directly available in practice. We instead propose a reachability analysis approach based on noisy data. More specifically, we first provide an algorithm for over-approximating the reachable set of a linear time-invariant system using matrix zonotopes. Then we introduce an extension for nonlinear systems. We provide theoretical guarantees in both cases. Numerical examples show the potential and applicability of the introduced methods.
On Radiation-Based Thermal Servoing: New Models, Controls and Experiments
Dec 24, 2020
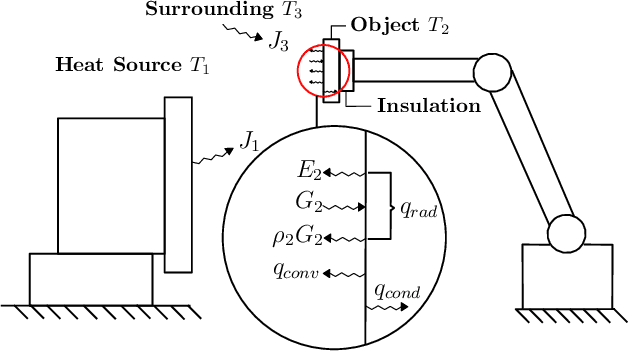
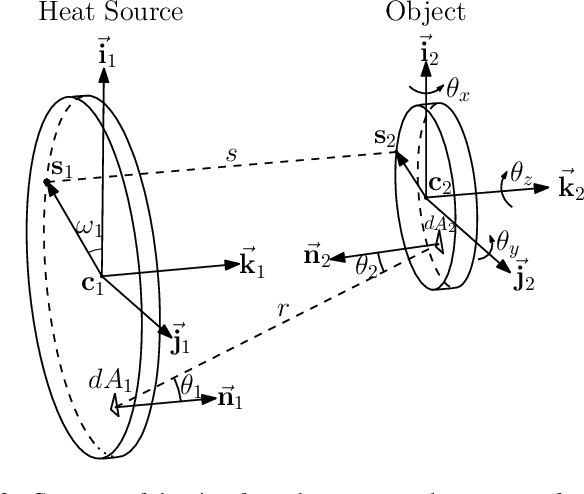
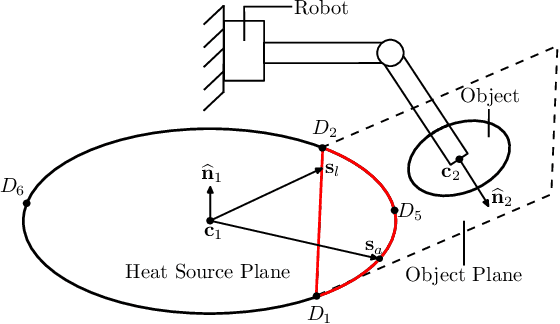
In this paper, we introduce a new sensor-based control method that regulates (by means of robot motions) the heat transfer between a radiative source and an object of interest. This valuable sensorimotor capability is needed in many industrial, dermatology and field robot applications, and it is an essential component for creating machines with advanced thermo-motor intelligence. To this end, we derive a geometric-thermal-motor model which describes the relationship between the robot's active configuration and the produced dynamic thermal response. We then use the model to guide the design of two new thermal servoing controllers (one model-based and one adaptive), and analyze their stability with Lyapunov theory. To validate our method, we report a detailed experimental study with a robotic manipulator conducting autonomous thermal servoing tasks. To the best of the authors' knowledge, this is the first time that temperature regulation has been formulated as a motion control problem for robots.
Reinforcement Learning based Multi-Robot Classification via Scalable Communication Structure
Dec 18, 2020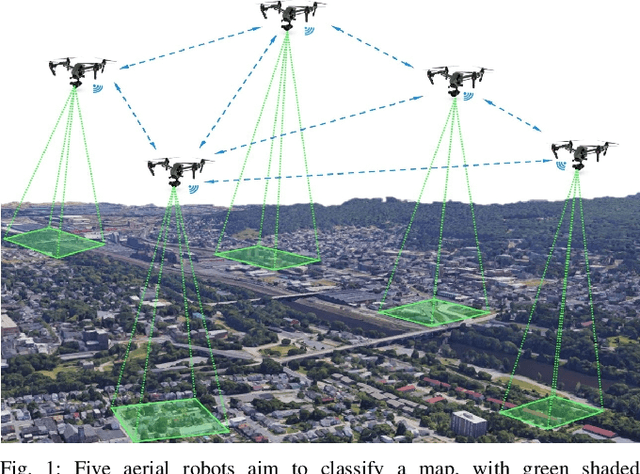
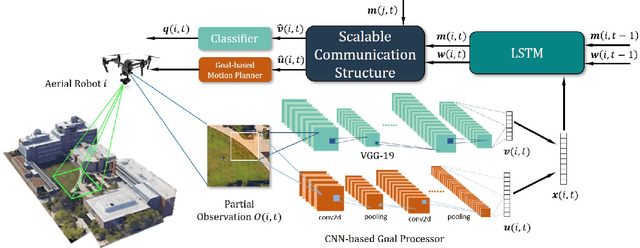
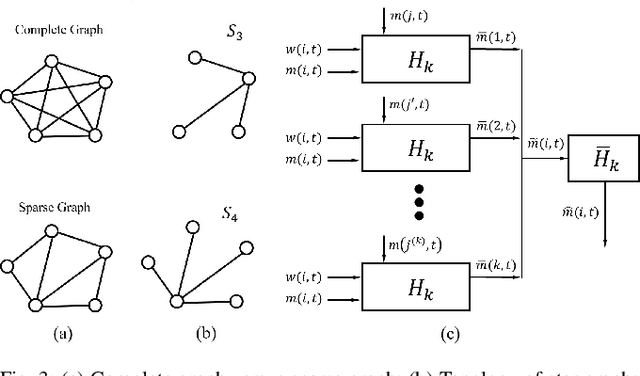

In the multi-robot collaboration domain, training with Reinforcement Learning (RL) can become intractable, and performance starts to deteriorate drastically as the number of robots increases. In this work, we proposed a distributed multi-robot learning architecture with a scalable communication structure capable of learning a robust communication policy for time-varying communication topology. We construct the communication structure with Long-Short Term Memory (LSTM) cells and star graphs, in which the computational complexity of the proposed learning algorithm scales linearly with the number of robots and suitable for application with a large number of robots. The proposed methodology is validated with a map classification problem in the simulated environment. It is shown that the proposed architecture achieves a comparable classification accuracy with the centralized methods, maintains high performance with various numbers of robots without additional training cost, and robust to hacking and loss of the robots in the network.
Exchanging Lessons Between Algorithmic Fairness and Domain Generalization
Oct 14, 2020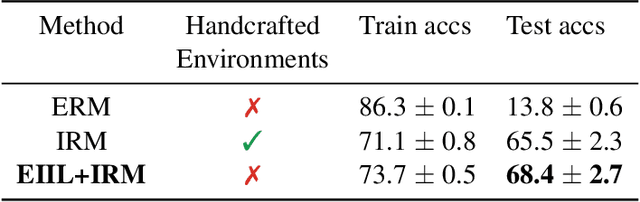
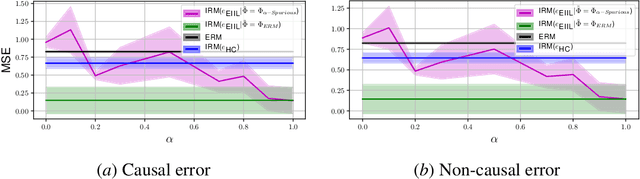
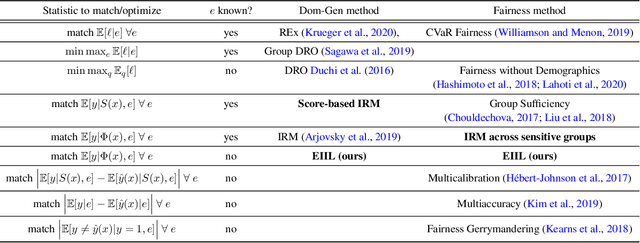

Standard learning approaches are designed to perform well on average for the data distribution available at training time. Developing learning approaches that are not overly sensitive to the training distribution is central to research on domain- or out-of-distribution generalization, robust optimization and fairness. In this work we focus on links between research on domain generalization and algorithmic fairness -- where performance under a distinct but related test distributions is studied -- and show how the two fields can be mutually beneficial. While domain generalization methods typically rely on knowledge of disjoint "domains" or "environments", "sensitive" label information indicating which demographic groups are at risk of discrimination is often used in the fairness literature. Drawing inspiration from recent fairness approaches that improve worst-case performance without knowledge of sensitive groups, we propose a novel domain generalization method that handles the more realistic scenario where environment partitions are not provided. We then show theoretically and empirically how different partitioning schemes can lead to increased or decreased generalization performance, enabling us to outperform Invariant Risk Minimization with handcrafted environments in multiple cases. We also show how a re-interpretation of IRMv1 allows us for the first time to directly optimize a common fairness criterion, group-sufficiency, and thereby improve performance on a fair prediction task.
EDN: Salient Object Detection via Extremely-Downsampled Network
Dec 24, 2020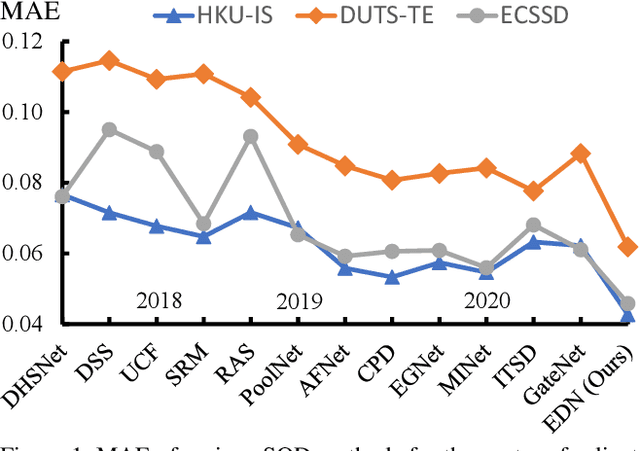
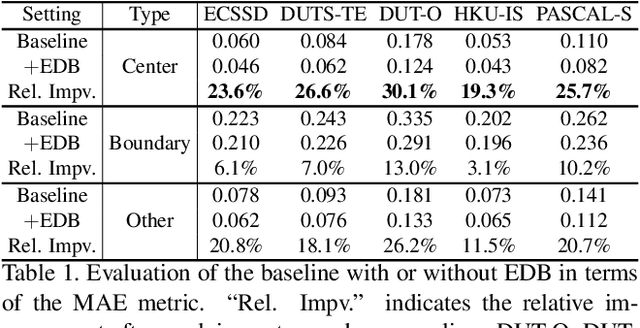
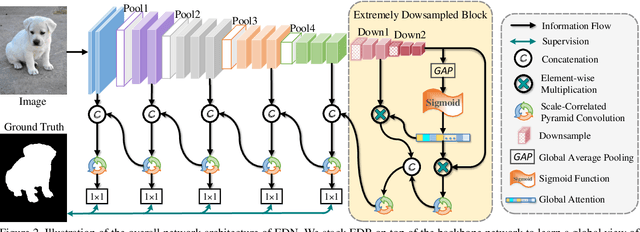
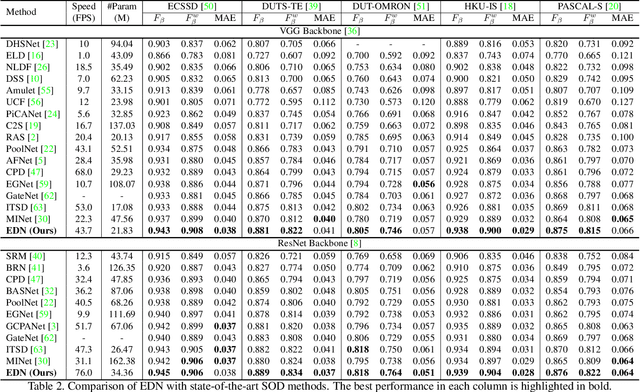
Recent progress on salient object detection (SOD) mainly benefits from multi-scale learning, where the high-level and low-level features work collaboratively in locating salient objects and discovering fine details, respectively. However, most efforts are devoted to low-level feature learning by fusing multi-scale features or enhancing boundary representations. In this paper, we show another direction that improving high-level feature learning is essential for SOD as well. To verify this, we introduce an Extremely-Downsampled Network (EDN), which employs an extreme downsampling technique to effectively learn a global view of the whole image, leading to accurate salient object localization. A novel Scale-Correlated Pyramid Convolution (SCPC) is also designed to build an elegant decoder for recovering object details from the above extreme downsampling. Extensive experiments demonstrate that EDN achieves \sArt performance with real-time speed. Hence, this work is expected to spark some new thinking in SOD. The code will be released.
Knowledge-Assisted Deep Reinforcement Learning in 5G Scheduler Design: From Theoretical Framework to Implementation
Sep 17, 2020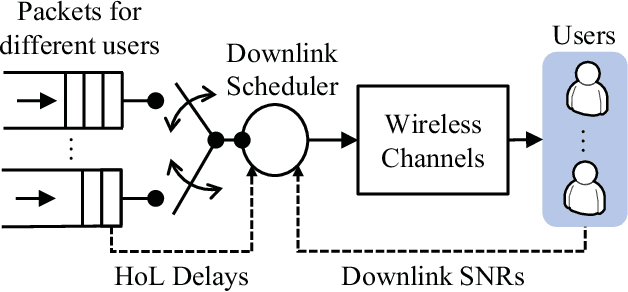
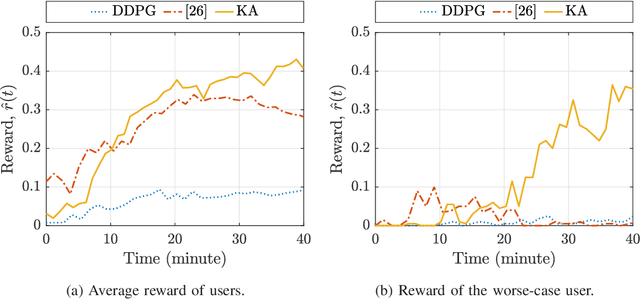
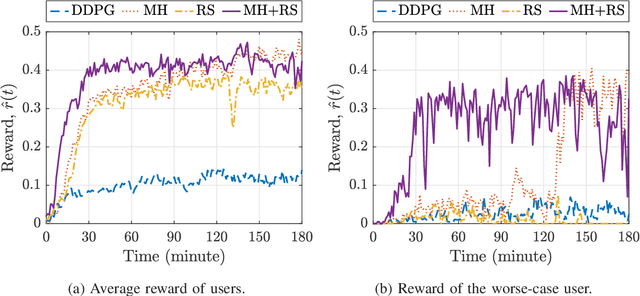
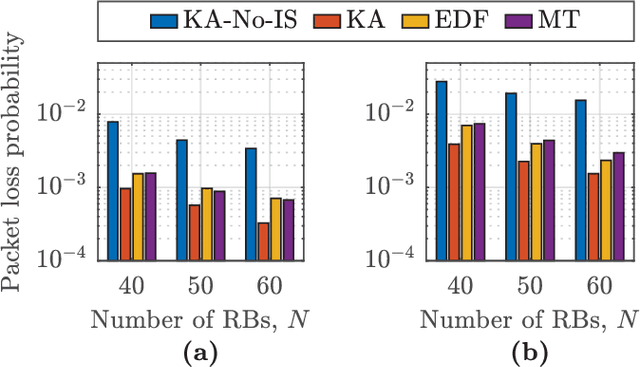
In this paper, we develop a knowledge-assisted deep reinforcement learning (DRL) algorithm to design wireless schedulers in the fifth-generation (5G) cellular networks with time-sensitive traffic. Since the scheduling policy is a deterministic mapping from channel and queue states to scheduling actions, it can be optimized by using deep deterministic policy gradient (DDPG). We show that a straightforward implementation of DDPG converges slowly, has a poor quality-of-service (QoS) performance, and cannot be implemented in real-world 5G systems, which are non-stationary in general. To address these issues, we propose a theoretical DRL framework, where theoretical models from wireless communications are used to formulate a Markov decision process in DRL. To reduce the convergence time and improve the QoS of each user, we design a knowledge-assisted DDPG (K-DDPG) that exploits expert knowledge of the scheduler deign problem, such as the knowledge of the QoS, the target scheduling policy, and the importance of each training sample, determined by the approximation error of the value function and the number of packet losses. Furthermore, we develop an architecture for online training and inference, where K-DDPG initializes the scheduler off-line and then fine-tunes the scheduler online to handle the mismatch between off-line simulations and non-stationary real-world systems. Simulation results show that our approach reduces the convergence time of DDPG significantly and achieves better QoS than existing schedulers (reducing 30% ~ 50% packet losses). Experimental results show that with off-line initialization, our approach achieves better initial QoS than random initialization and the online fine-tuning converges in few minutes.
Graph convolutions that can finally model local structure
Nov 30, 2020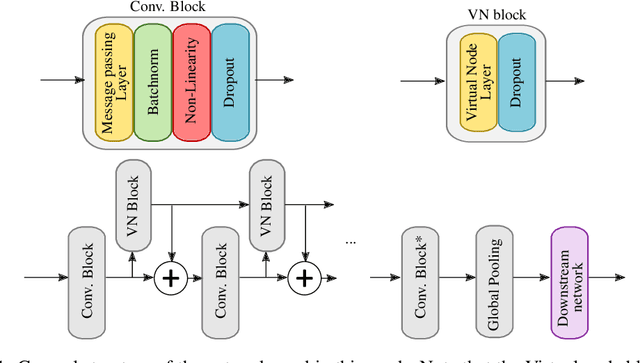

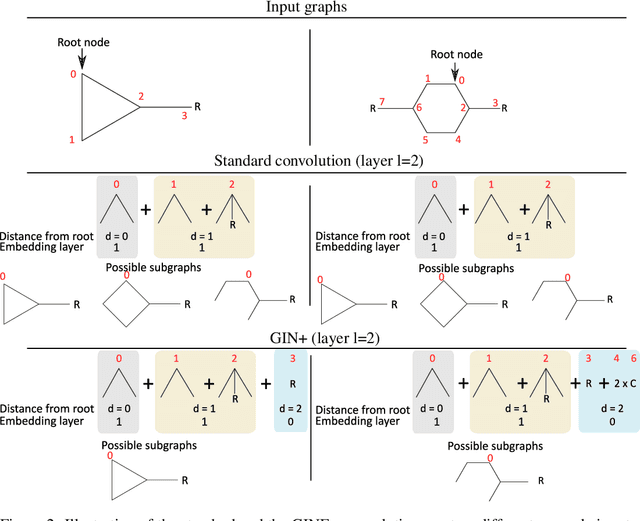
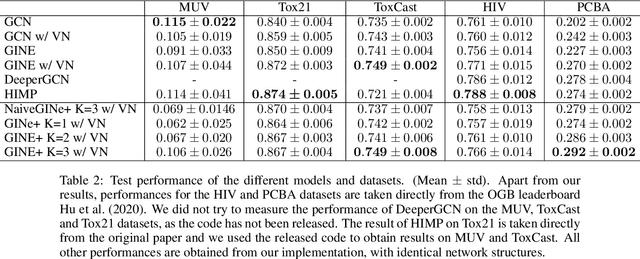
Despite quick progress in the last few years, recent studies have shown that modern graph neural networks can still fail at very simple tasks, like detecting small cycles. This hints at the fact that current networks fail to catch information about the local structure, which is problematic if the downstream task heavily relies on graph substructure analysis, as in the context of chemistry. We propose a very simple correction to the now standard GIN convolution that enables the network to detect small cycles with nearly no cost in terms of computation time and number of parameters. Tested on real life molecule property datasets, our model consistently improves performance on large multi-tasked datasets over all baselines, both globally and on a per-task setting.