 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Reinforcement Learning Approach for Rebalancing Electric Vehicle Sharing Systems
Oct 05, 2020
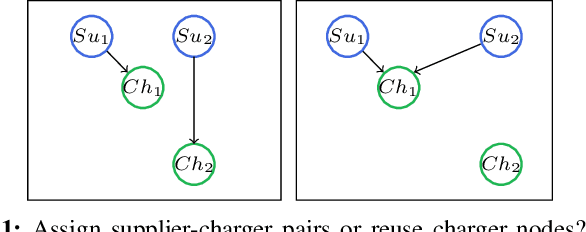
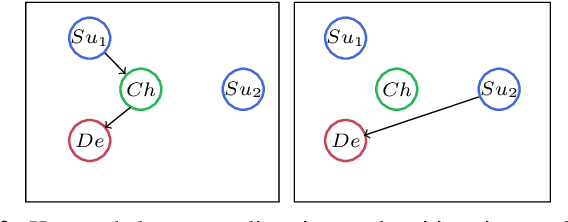
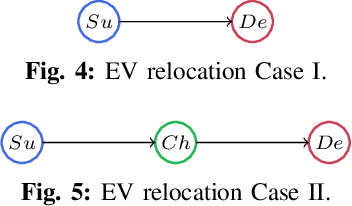
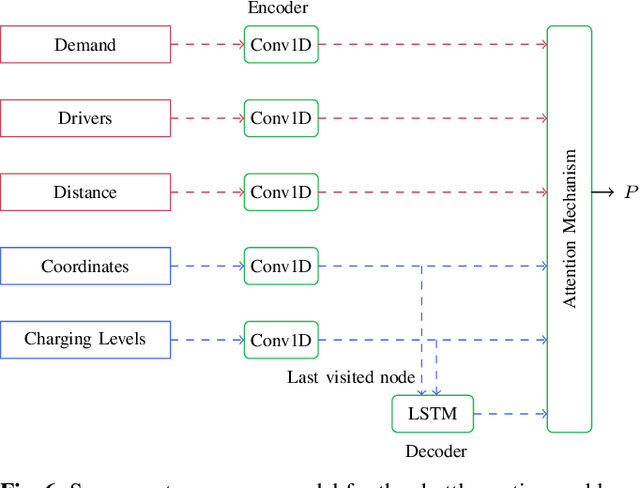
This paper proposes a reinforcement learning approach for nightly offline rebalancing operations in free-floating electric vehicle sharing systems (FFEVSS). Due to sparse demand in a network, FFEVSS require relocation of electrical vehicles (EVs) to charging stations and demander nodes, which is typically done by a group of drivers. A shuttle is used to pick up and drop off drivers throughout the network. The objective of this study is to solve the shuttle routing problem to finish the rebalancing work in the minimal time. We consider a reinforcement learning framework for the problem, in which a central controller determines the routing policies of a fleet of multiple shuttles. We deploy a policy gradient method for training recurrent neural networks and compare the obtained policy results with heuristic solutions. Our numerical studies show that unlike the existing solutions in the literature, the proposed methods allow to solve the general version of the problem with no restrictions on the urban EV network structure and charging requirements of EVs. Moreover, the learned policies offer a wide range of flexibility resulting in a significant reduction in the time needed to rebalance the network.
A multi-objective optimization framework for on-line ridesharing systems
Dec 07, 2020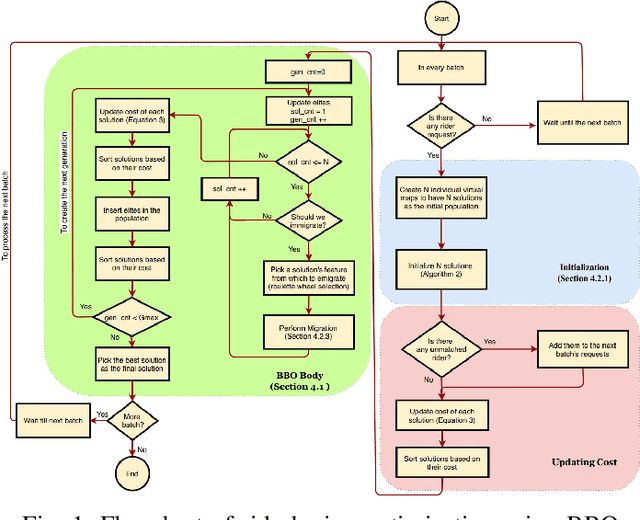
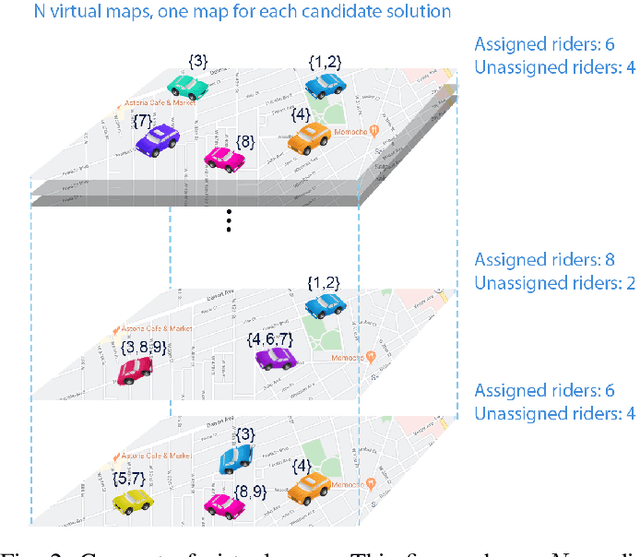
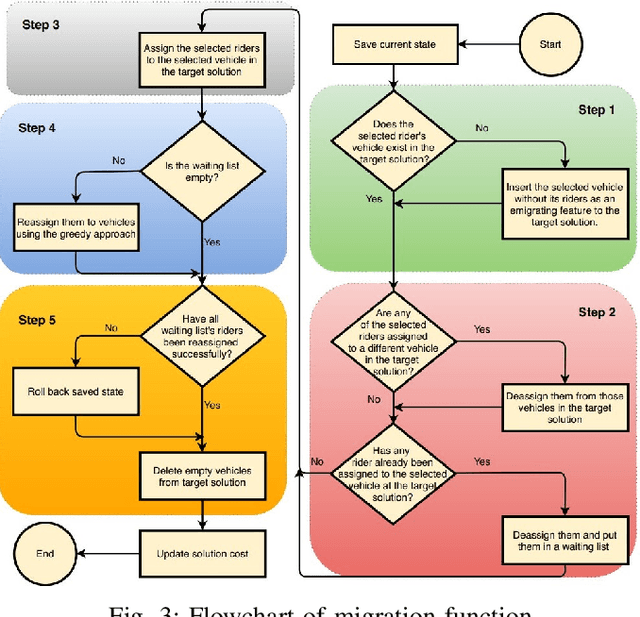
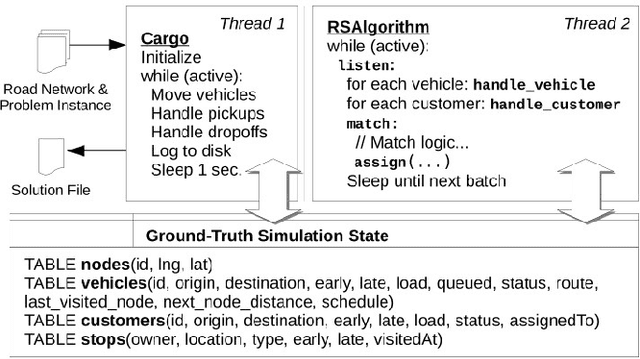
The ultimate goal of ridesharing systems is to matchtravelers who do not have a vehicle with those travelers whowant to share their vehicle. A good match can be found amongthose who have similar itineraries and time schedules. In thisway each rider can be served without any delay and also eachdriver can earn as much as possible without having too muchdeviation from their original route. We propose an algorithmthat leverages biogeography-based optimization to solve a multi-objective optimization problem for online ridesharing. It isnecessary to solve the ridesharing problem as a multi-objectiveproblem since there are some important objectives that must beconsidered simultaneously. We test our algorithm by evaluatingperformance on the Beijing ridesharing dataset. The simulationresults indicate that BBO provides competitive performancerelative to state-of-the-art ridesharing optimization algorithms.
An Active Learning Method for Diabetic Retinopathy Classification with Uncertainty Quantification
Dec 24, 2020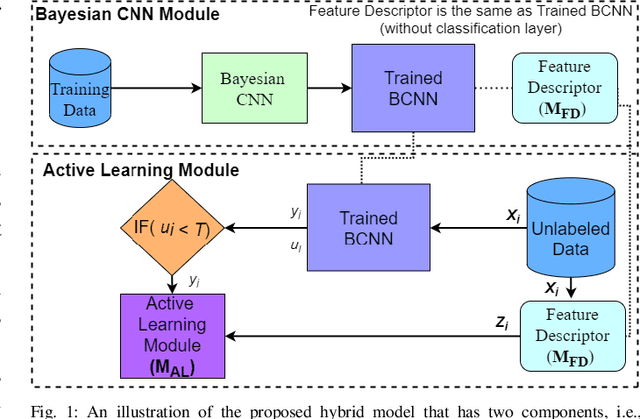
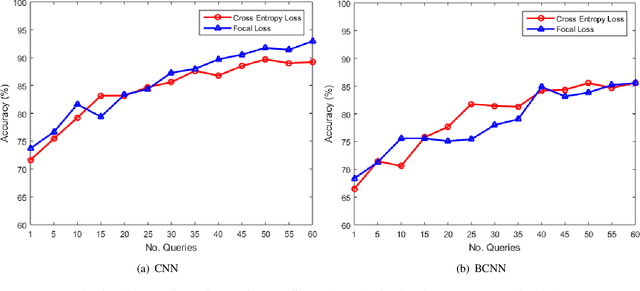
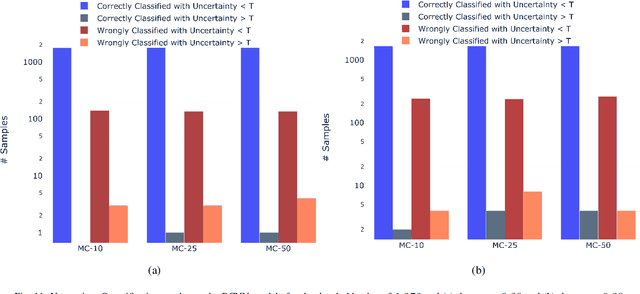

In recent years, deep learning (DL) techniques have provided state-of-the-art performance on different medical imaging tasks. However, the availability of good quality annotated medical data is very challenging due to involved time constraints and the availability of expert annotators, e.g., radiologists. In addition, DL is data-hungry and their training requires extensive computational resources. Another problem with DL is their black-box nature and lack of transparency on its inner working which inhibits causal understanding and reasoning. In this paper, we jointly address these challenges by proposing a hybrid model, which uses a Bayesian convolutional neural network (BCNN) for uncertainty quantification, and an active learning approach for annotating the unlabelled data. The BCNN is used as a feature descriptor and these features are then used for training a model, in an active learning setting. We evaluate the proposed framework for diabetic retinopathy classification problem and have achieved state-of-the-art performance in terms of different metrics.
Machine Learning a Molecular Hamiltonian for Predicting Electron Dynamics
Jul 19, 2020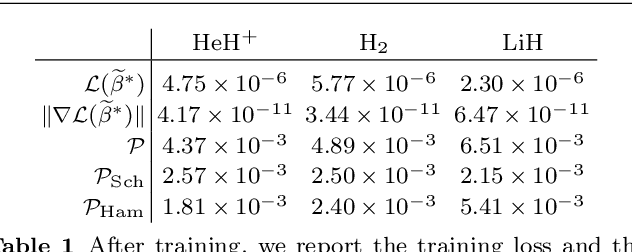
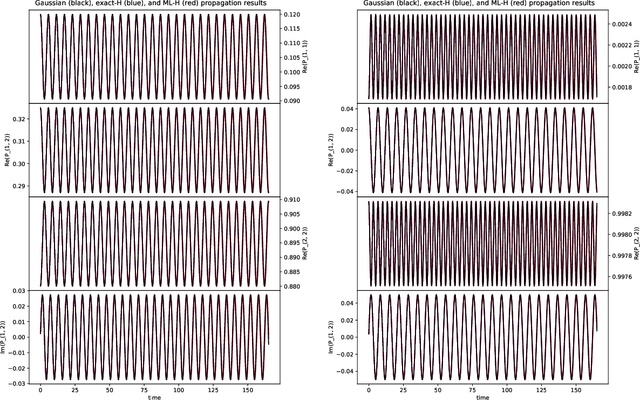
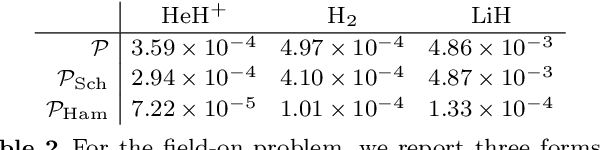
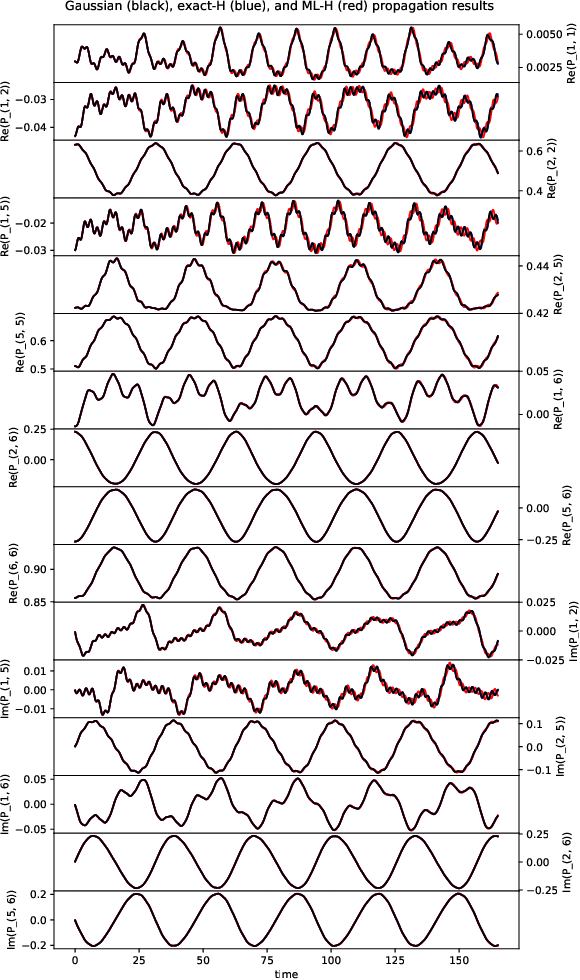
We develop a mathematical method to learn a molecular Hamiltonian from matrix-valued time series of the electron density. As we demonstrate for each of three small molecules, the resulting Hamiltonians can be used for electron density evolution, producing highly accurate results even when propagating 1000 time steps beyond the training data. As a more rigorous test, we use the learned Hamiltonians to simulate electron dynamics in the presence of an applied electric field, extrapolating to a problem that is beyond the field-free training data. The resulting electron dynamics predicted by our learned Hamiltonian are in close quantitative agreement with the ground truth. Our method relies on combining a reduced-dimensional, linear statistical model of the Hamiltonian with a time-discretization of the quantum Liouville equation. Ultimately, our model can be trained without recourse to numerous, CPU-intensive optimization steps. For all three molecules and both field-free and field-on problems, we quantify training and propagation errors, highlighting areas for future development.
Using previous acoustic context to improve Text-to-Speech synthesis
Dec 07, 2020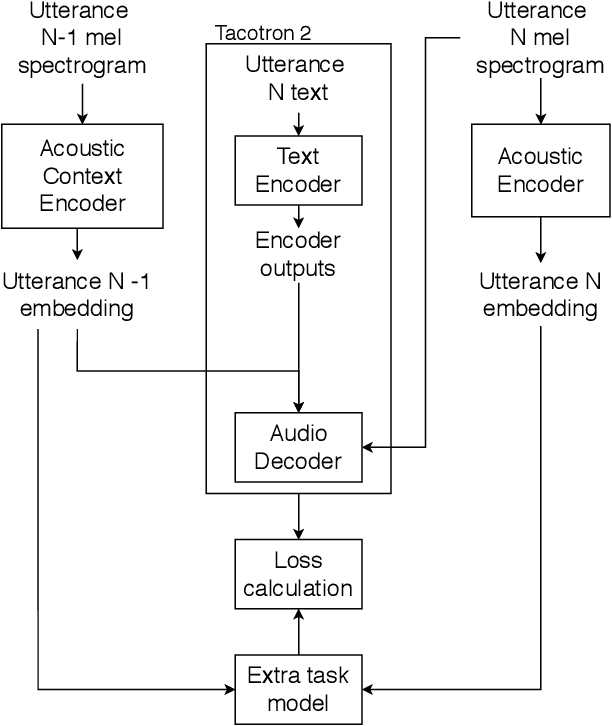
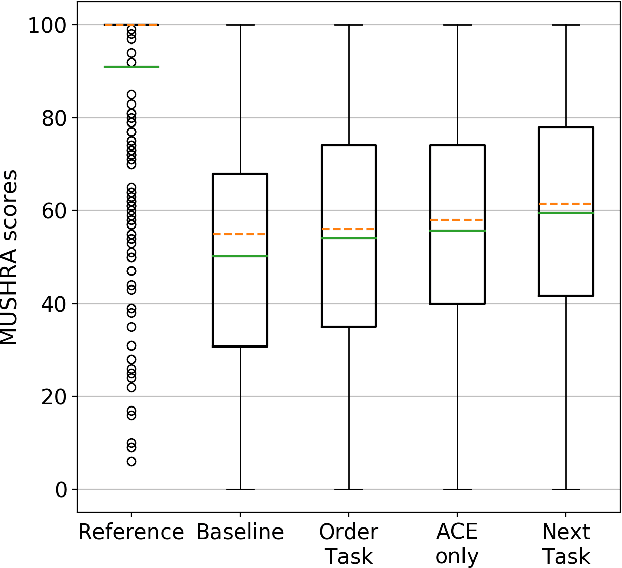
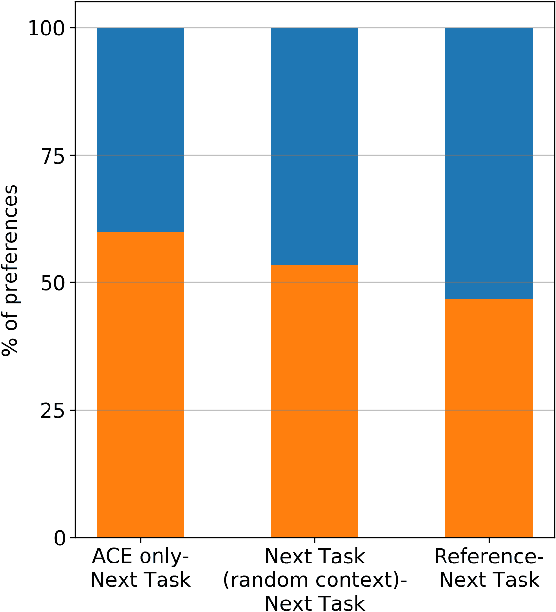
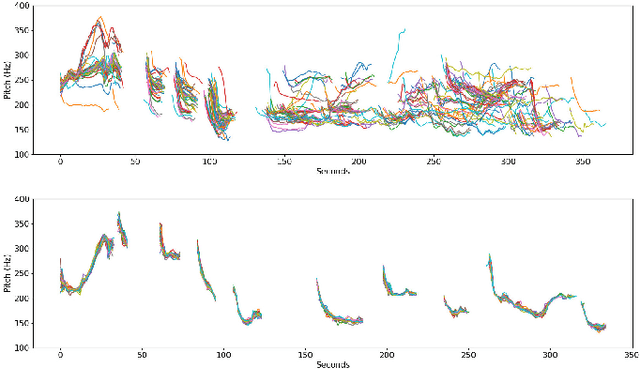
Many speech synthesis datasets, especially those derived from audiobooks, naturally comprise sequences of utterances. Nevertheless, such data are commonly treated as individual, unordered utterances both when training a model and at inference time. This discards important prosodic phenomena above the utterance level. In this paper, we leverage the sequential nature of the data using an acoustic context encoder that produces an embedding of the previous utterance audio. This is input to the decoder in a Tacotron 2 model. The embedding is also used for a secondary task, providing additional supervision. We compare two secondary tasks: predicting the ordering of utterance pairs, and predicting the embedding of the current utterance audio. Results show that the relation between consecutive utterances is informative: our proposed model significantly improves naturalness over a Tacotron 2 baseline.
Boost AI Power: Data Augmentation Strategies with unlabelled Data and Conformal Prediction, a Case in Alternative Herbal Medicine Discrimination with Electronic Nose
Feb 05, 2021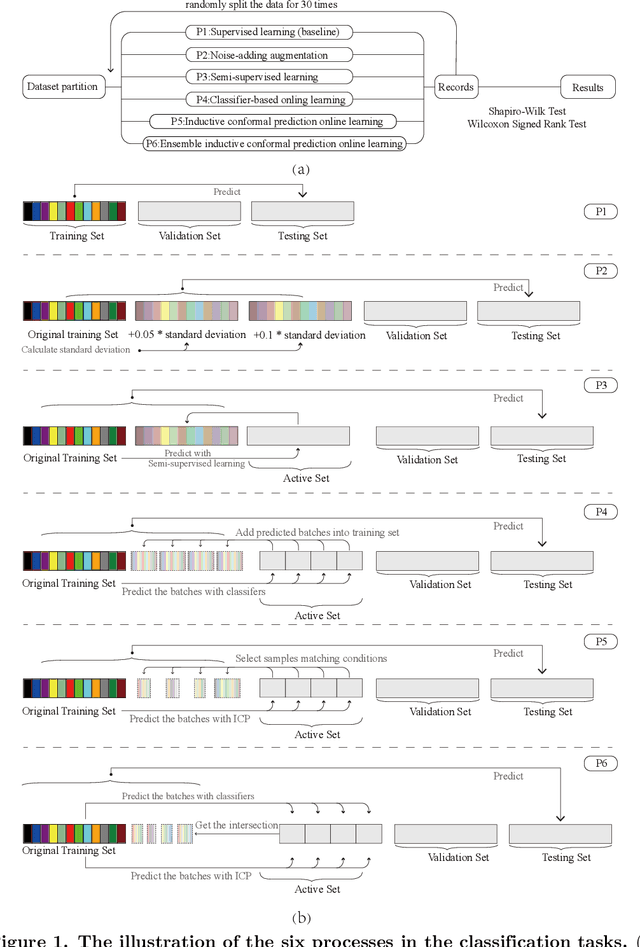
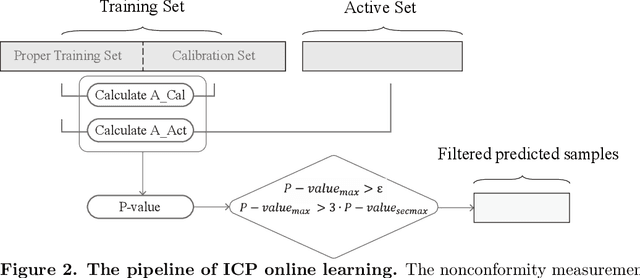
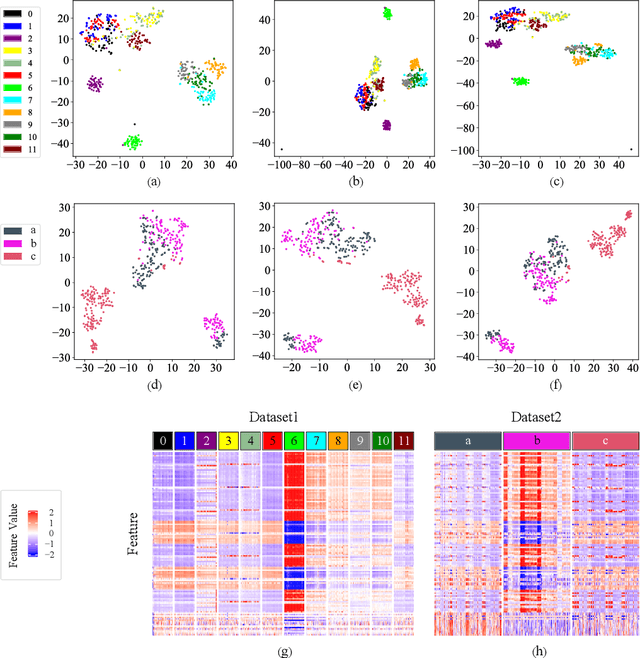
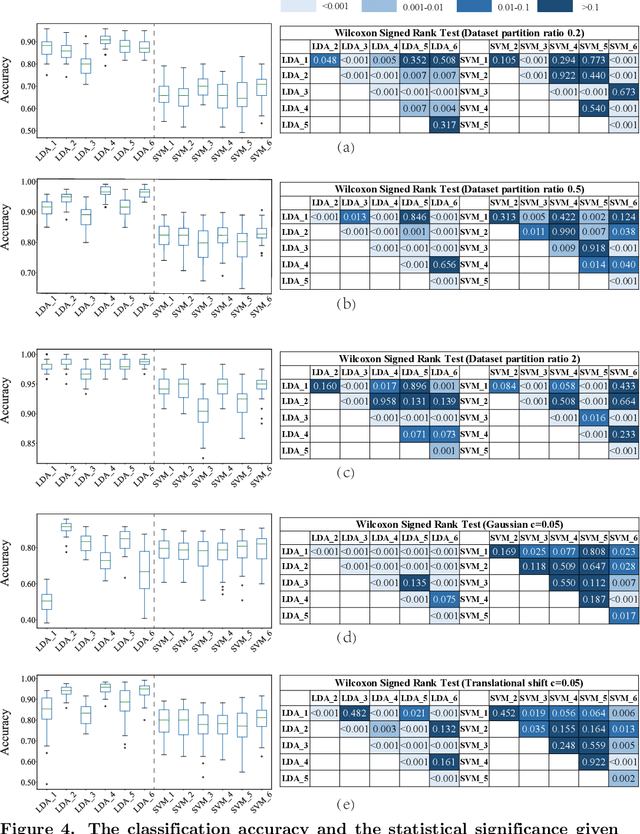
Electronic nose proves its effectiveness in alternativeherbal medicine classification, but due to the supervised learn-ing nature, previous research relies on the labelled training data,which are time-costly and labor-intensive to collect. Consideringthe training data inadequacy in real-world applications, this studyaims to improve classification accuracy via data augmentationstrategies. We stimulated two scenarios to investigate the effective-ness of five data augmentation strategies under different trainingdata inadequacy: in the noise-free scenario, different availability ofunlabelled data were simulated, and in the noisy scenario, differentlevels of Gaussian noises and translational shifts were added tosimulate sensor drifts. The augmentation strategies: noise-addingdata augmentation, semi-supervised learning, classifier-based online learning, inductive conformal prediction (ICP) onlinelearning and the novel ensemble ICP online learning proposed in this study, were compared against supervised learningbaseline, with Linear Discriminant Analysis (LDA) and Support Vector Machine (SVM) as the classifiers. We found thatat least one strategies significantly improved the classification accuracy with LDA(p<=0.05) and showed non-decreasingclassification accuracy with SVM in each tasks. Moreover, our novel strategy: ensemble ICP online learning outperformedthe others by showing non-decreasing classification accuracy on all tasks and significant improvement on most tasks(25/36 tasks,p<=0.05). This study provides a systematic analysis over augmentation strategies, and we provided userswith recommended strategies under specific circumstances. Furthermore, our newly proposed strategy showed botheffectiveness and robustness in boosting the classification model generalizability, which can also be further employed inother machine learning applications.
Alternating Direction Method of Multipliers for Constrained Iterative LQR in Autonomous Driving
Nov 01, 2020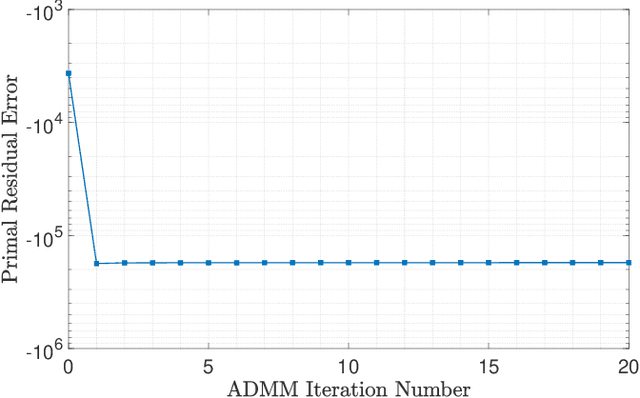
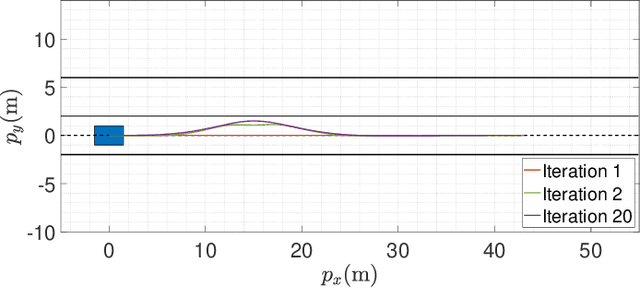
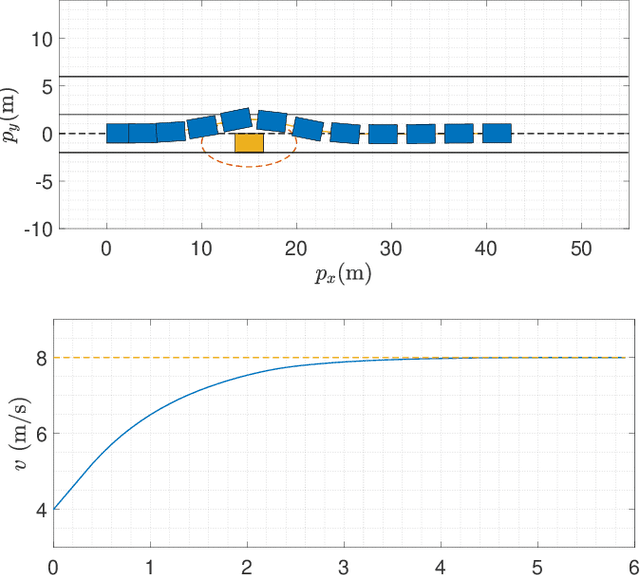
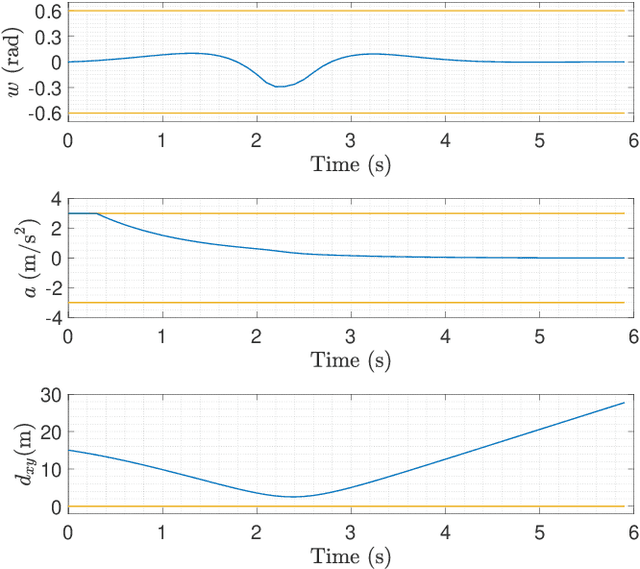
In the context of autonomous driving, the iterative linear quadratic regulator (iLQR) is known to be an efficient approach to deal with the nonlinear vehicle models in motion planning problems. Particularly, the constrained iLQR algorithm has shown noteworthy advantageous outcomes of computation efficiency in achieving motion planning tasks under general constraints of different types. However, the constrained iLQR methodology requires a feasible trajectory at the first iteration as a prerequisite. Also, the methodology leaves open the possibility for incorporation of fast, efficient, and effective optimization methods (i.e., fast-solvers) to further speed up the optimization process such that the requirements of real-time implementation can be successfully fulfilled. In this paper, a well-defined and commonly-encountered motion planning problem is formulated under nonlinear vehicle dynamics and various constraints, and an alternating direction method of multipliers (ADMM) is developed to determine the optimal control actions. With this development, the approach is able to circumvent the feasibility requirement of the trajectory at the first iteration. An illustrative example of motion planning in autonomous vehicles is then investigated with different driving scenarios taken into consideration. As clearly observed from the simulation results, the significance of this work in terms of obstacle avoidance is demonstrated. Furthermore, a noteworthy achievement of high computation efficiency is attained; and as a result, real-time computation and implementation can be realized through this framework, and thus it provides additional safety to the on-road driving tasks.
WaveFuse: A Unified Deep Framework for Image Fusion with Discrete Wavelet Transform
Sep 03, 2020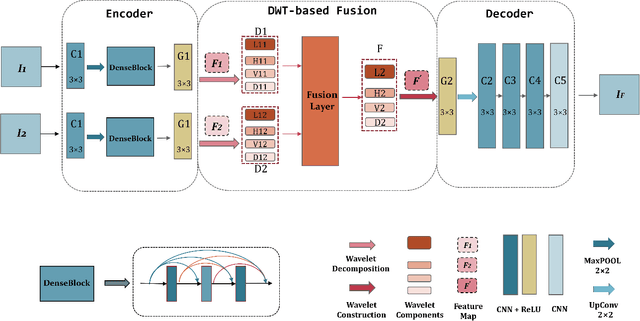
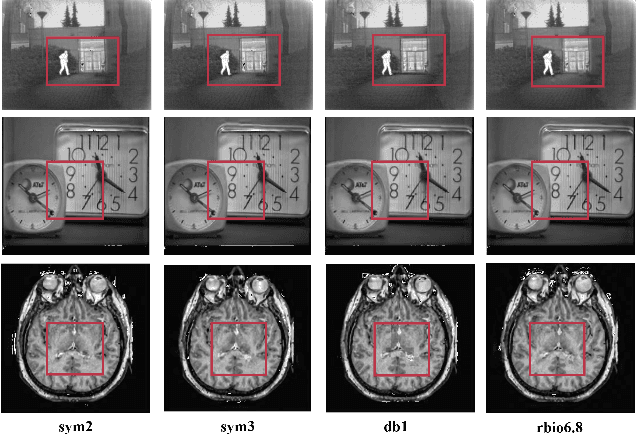
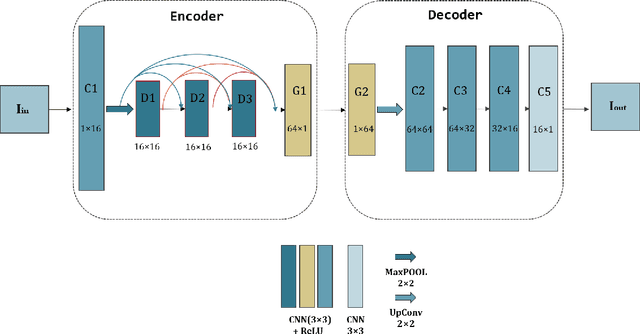
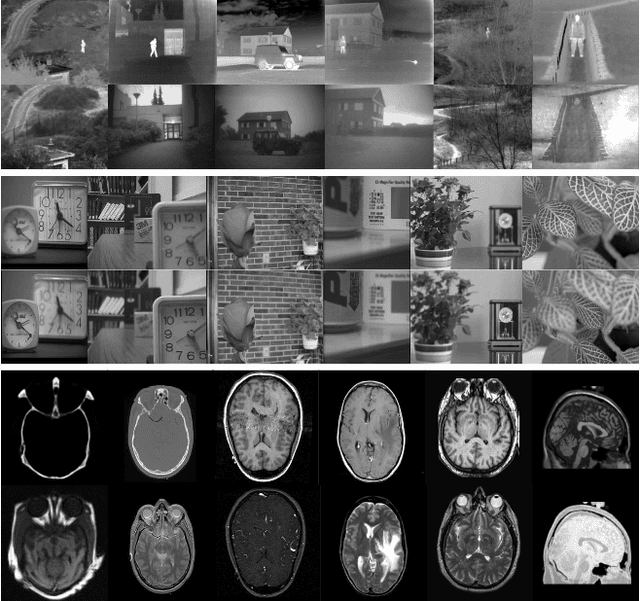
We propose an unsupervised image fusion architecture for multiple application scenarios based on the combination of multi-scale discrete wavelet transform through regional energy and deep learning. To our best knowledge, this is the first time the conventional image fusion method has been combined with deep learning. The useful information of feature maps can be utilized adequately through multi-scale discrete wavelet transform in our proposed method.Compared with other state-of-the-art fusion method, the proposed algorithm exhibits better fusion performance in both subjective and objective evaluation. Moreover, it's worth mentioning that comparable fusion performance trained in COCO dataset can be obtained by training with a much smaller dataset with only hundreds of images chosen randomly from COCO. Hence, the training time is shortened substantially, leading to the improvement of the model's performance both in practicality and training efficiency.
Benchmarking of eight recurrent neural network variants for breath phase and adventitious sound detection on a self-developed open-access lung sound database-HF_Lung_V1
Feb 05, 2021

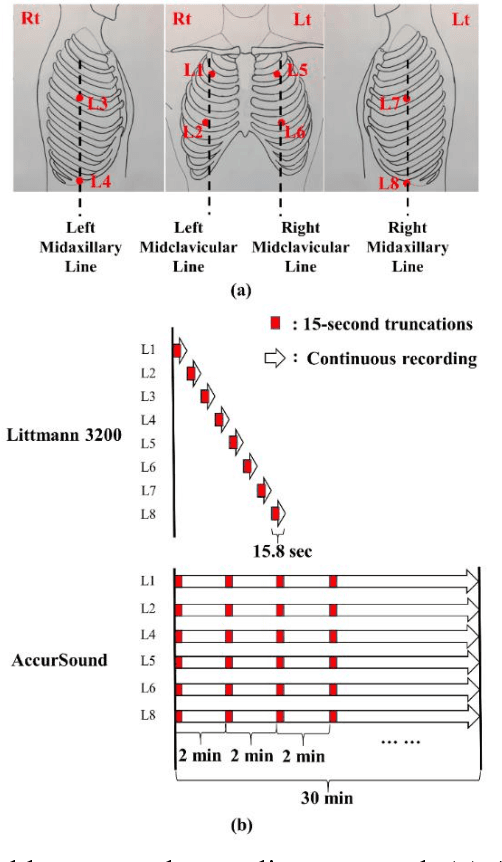
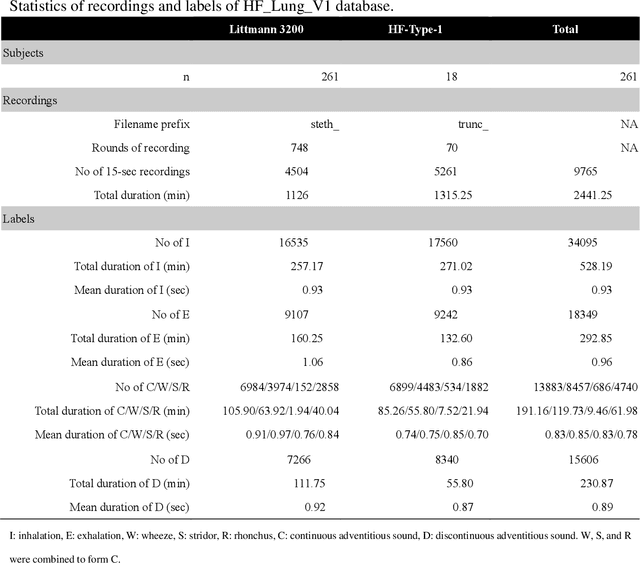
A reliable, remote, and continuous real-time respiratory sound monitor with automated respiratory sound analysis ability is urgently required in many clinical scenarios-such as in monitoring disease progression of coronavirus disease 2019-to replace conventional auscultation with a handheld stethoscope. However, a robust computerized respiratory sound analysis algorithm has not yet been validated in practical applications. In this study, we developed a lung sound database (HF_Lung_V1) comprising 9,765 audio files of lung sounds (duration of 15 s each), 34,095 inhalation labels, 18,349 exhalation labels, 13,883 continuous adventitious sound (CAS) labels (comprising 8,457 wheeze labels, 686 stridor labels, and 4,740 rhonchi labels), and 15,606 discontinuous adventitious sound labels (all crackles). We conducted benchmark tests for long short-term memory (LSTM), gated recurrent unit (GRU), bidirectional LSTM (BiLSTM), bidirectional GRU (BiGRU), convolutional neural network (CNN)-LSTM, CNN-GRU, CNN-BiLSTM, and CNN-BiGRU models for breath phase detection and adventitious sound detection. We also conducted a performance comparison between the LSTM-based and GRU-based models, between unidirectional and bidirectional models, and between models with and without a CNN. The results revealed that these models exhibited adequate performance in lung sound analysis. The GRU-based models outperformed, in terms of F1 scores and areas under the receiver operating characteristic curves, the LSTM-based models in most of the defined tasks. Furthermore, all bidirectional models outperformed their unidirectional counterparts. Finally, the addition of a CNN improved the accuracy of lung sound analysis, especially in the CAS detection tasks.
EEG-Based User Reaction Time Estimation Using Riemannian Geometry Features
Apr 27, 2017
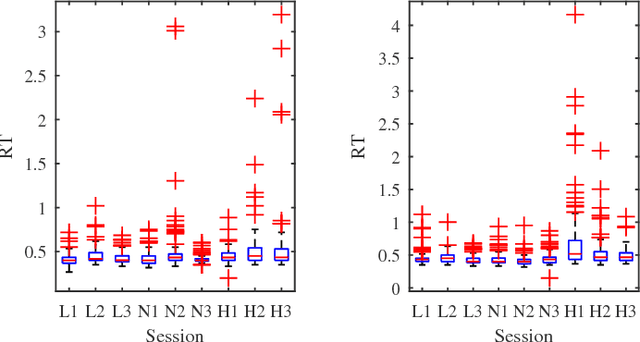
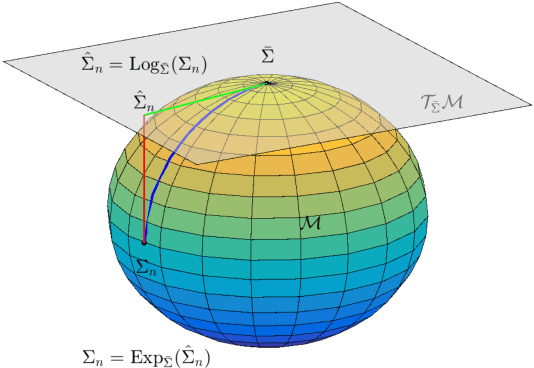
Riemannian geometry has been successfully used in many brain-computer interface (BCI) classification problems and demonstrated superior performance. In this paper, for the first time, it is applied to BCI regression problems, an important category of BCI applications. More specifically, we propose a new feature extraction approach for Electroencephalogram (EEG) based BCI regression problems: a spatial filter is first used to increase the signal quality of the EEG trials and also to reduce the dimensionality of the covariance matrices, and then Riemannian tangent space features are extracted. We validate the performance of the proposed approach in reaction time estimation from EEG signals measured in a large-scale sustained-attention psychomotor vigilance task, and show that compared with the traditional powerband features, the tangent space features can reduce the root mean square estimation error by 4.30-8.30%, and increase the estimation correlation coefficient by 6.59-11.13%.