 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning causal Bayes networks using interventional path queries in polynomial time and sample complexity
Feb 22, 2018

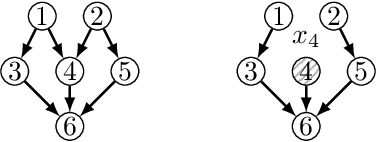
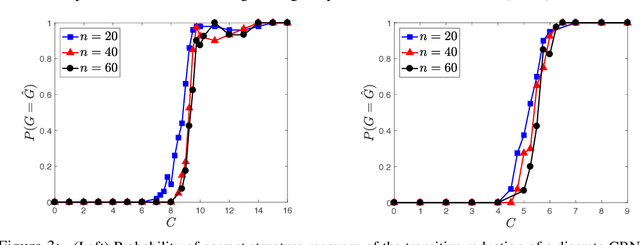
Causal discovery from empirical data is a fundamental problem in many scientific domains. Observational data allows for identifiability only up to Markov equivalence class. In this paper we first propose a polynomial time algorithm for learning the exact correctly-oriented structure of the transitive reduction of any causal Bayesian networks with high probability, by using interventional path queries. Each path query takes as input an origin node and a target node, and answers whether there is a directed path from the origin to the target. This is done by intervening the origin node and observing samples from the target node. We theoretically show the logarithmic sample complexity for the size of interventional data per path query, for continuous and discrete networks. We further extend our work to learn the transitive edges using logarithmic sample complexity (albeit in time exponential in the maximum number of parents for discrete networks). This allows us to learn the full network. We also provide an analysis of imperfect interventions.
Machine Learning for Temporal Data in Finance: Challenges and Opportunities
Sep 11, 2020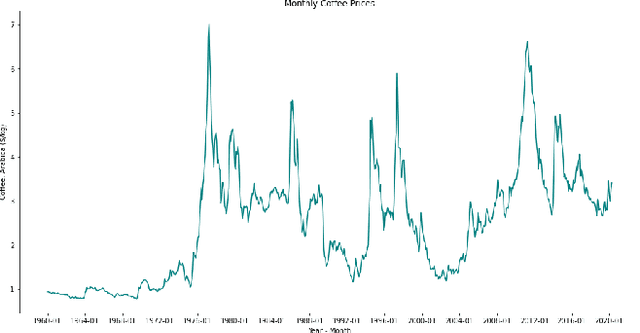
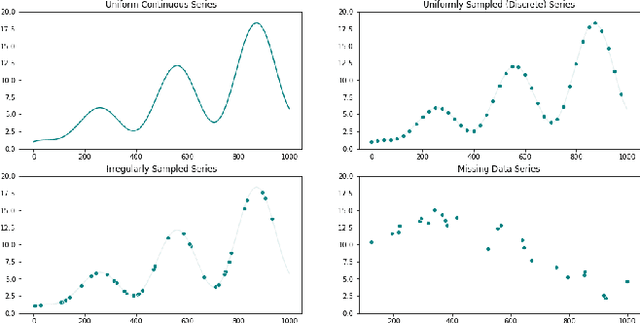
Temporal data are ubiquitous in the financial services (FS) industry -- traditional data like economic indicators, operational data such as bank account transactions, and modern data sources like website clickstreams -- all of these occur as a time-indexed sequence. But machine learning efforts in FS often fail to account for the temporal richness of these data, even in cases where domain knowledge suggests that the precise temporal patterns between events should contain valuable information. At best, such data are often treated as uniform time series, where there is a sequence but no sense of exact timing. At worst, rough aggregate features are computed over a pre-selected window so that static sample-based approaches can be applied (e.g. number of open lines of credit in the previous year or maximum credit utilization over the previous month). Such approaches are at odds with the deep learning paradigm which advocates for building models that act directly on raw or lightly processed data and for leveraging modern optimization techniques to discover optimal feature transformations en route to solving the modeling task at hand. Furthermore, a full picture of the entity being modeled (customer, company, etc.) might only be attainable by examining multiple data streams that unfold across potentially vastly different time scales. In this paper, we examine the different types of temporal data found in common FS use cases, review the current machine learning approaches in this area, and finally assess challenges and opportunities for researchers working at the intersection of machine learning for temporal data and applications in FS.
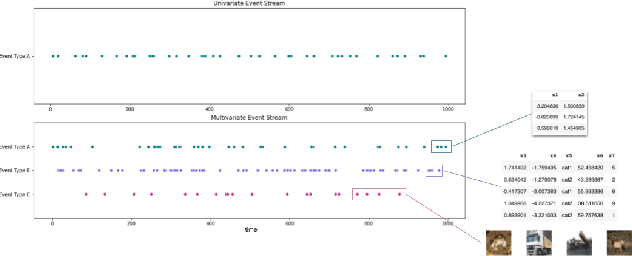
Distributional Ground Truth: Non-Redundant Crowdsourcing Data Quality Control in UI Labeling Tasks
Dec 25, 2020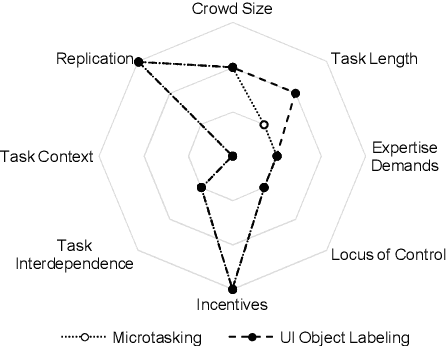
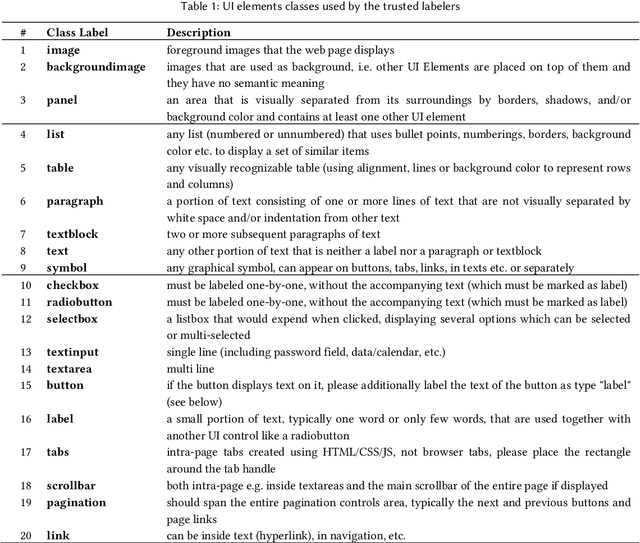

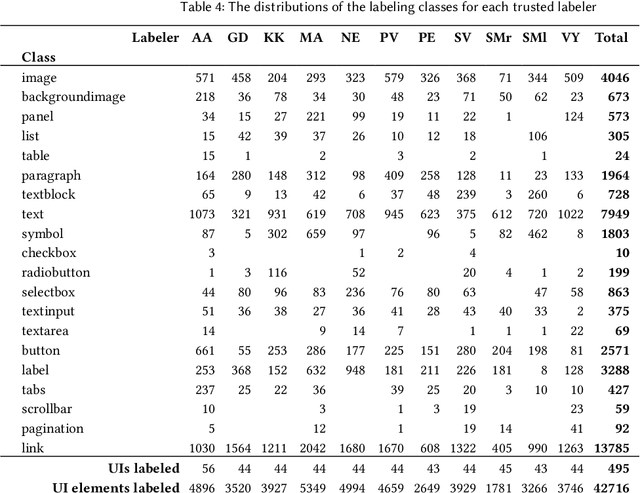
HCI increasingly employs Machine Learning and Image Recognition, in particular for visual analysis of user interfaces (UIs). A popular way for obtaining human-labeled training data is Crowdsourcing, typically using the quality control methods ground truth and majority consensus, which necessitate redundancy in the outcome. In our paper we propose a non-redundant method for prediction of crowdworkers' output quality in web UI labeling tasks, based on homogeneity of distributions assessed with two-sample Kolmogorov-Smirnov test. Using a dataset of about 500 screenshots with over 74,000 UI elements located and classified by 11 trusted labelers and 298 Amazon Mechanical Turk crowdworkers, we demonstrate the advantage of our approach over the baseline model based on mean Time-on-Task. Exploring different dataset partitions, we show that with the trusted set size of 17-27% UIs our "distributional ground truth" model can achieve R2s of over 0.8 and help to obviate the ancillary work effort and expenses.
Scalable representation learning and retrieval for display advertising
Jan 04, 2021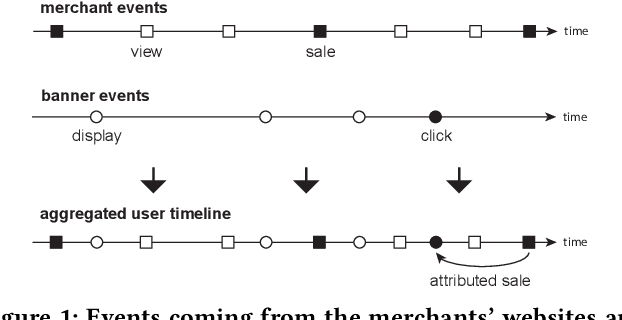

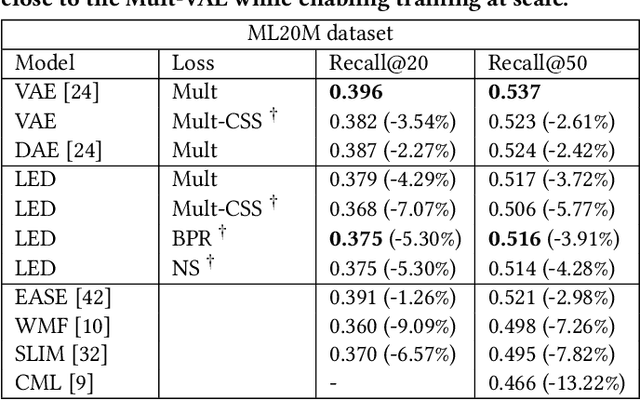
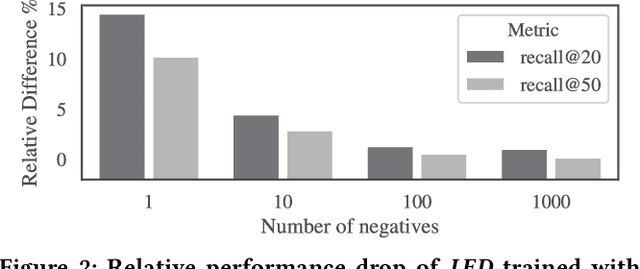
Over the past decades, recommendation has become a critical component of many online services such as media streaming and e-commerce. Recent advances in algorithms, evaluation methods and datasets have led to continuous improvements of the state-of-the-art. However, much work remains to be done to make these methods scale to the size of the internet. Online advertising offers a unique testbed for recommendation at scale. Every day, billions of users interact with millions of products in real-time. Systems addressing this scenario must work reliably at scale. We propose an efficient model (LED, for Lightweight Encoder-Decoder) reaching a new trade-off between complexity, scale and performance. Specifically, we show that combining large-scale matrix factorization with lightweight embedding fine-tuning unlocks state-of-the-art performance at scale. We further provide the detailed description of a system architecture and demonstrate its operation over two months at the scale of the internet. Our design allows serving billions of users across hundreds of millions of items in a few milliseconds using standard hardware.
A GCICA Grant-Free Random Access Scheme for M2M Communications in Crowded Massive MIMO Systems
Dec 25, 2020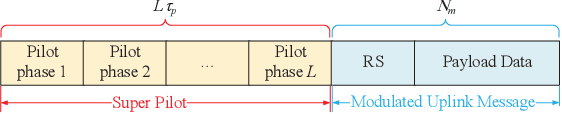
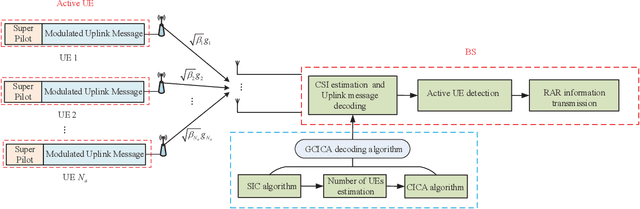
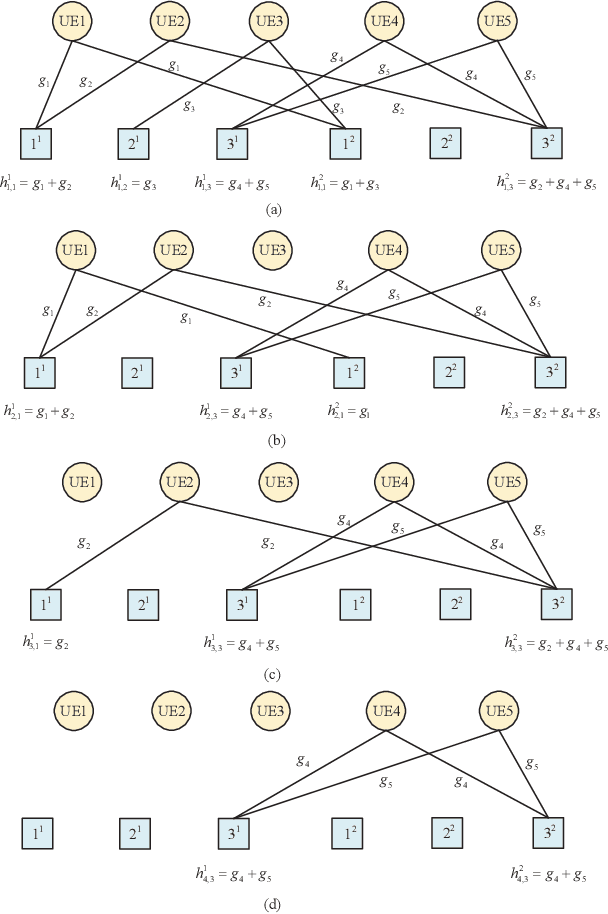
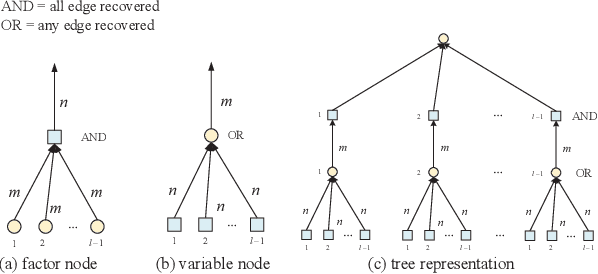
A high success rate of grant-free random access scheme is proposed to support massive access for machine-to-machine communications in massive multipleinput multiple-output systems. This scheme allows active user equipments (UEs) to transmit their modulated uplink messages along with super pilots consisting of multiple sub-pilots to a base station (BS). Then, the BS performs channel state information (CSI) estimation and uplink message decoding by utilizing a proposed graph combined clustering independent component analysis (GCICA) decoding algorithm, and then employs the estimated CSIs to detect active UEs by utilizing the characteristic of asymptotic favorable propagation of massive MIMO channel. We call this proposed scheme as GCICA based random access (GCICA-RA) scheme. We analyze the successful access probability, missed detection probability, and uplink throughput of the GCICA-RA scheme. Numerical results show that, the GCICA-RA scheme significantly improves the successful access probability and uplink throughput, decreases missed detection probability, and provides low CSI estimation error at the same time.
Boosted Convolutional Neural Networks for Motor Imagery EEG Decoding with Multiwavelet-based Time-Frequency Conditional Granger Causality Analysis
Oct 22, 2018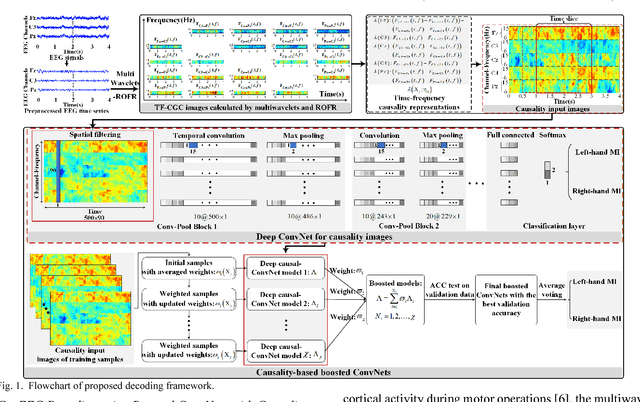
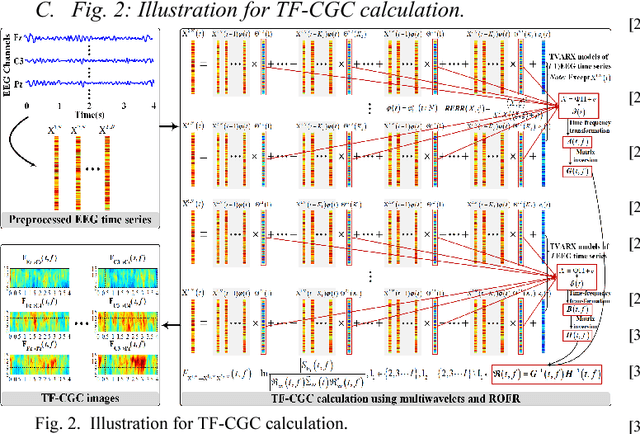
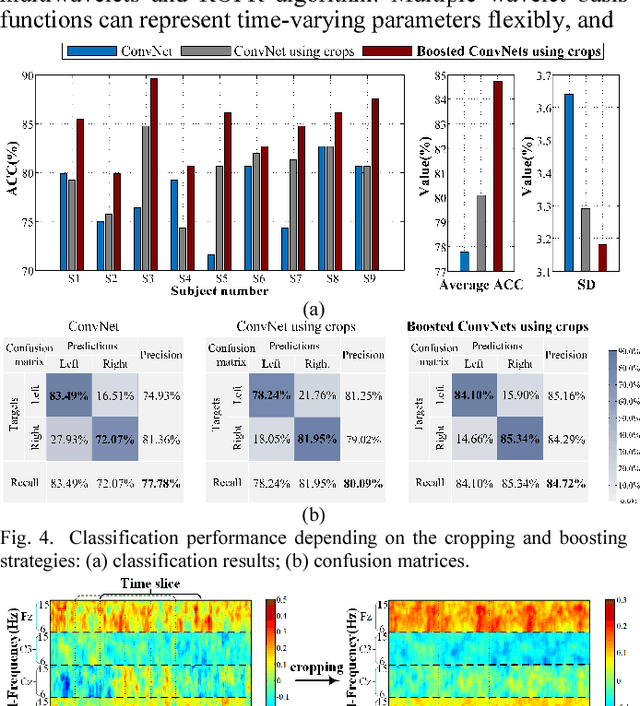
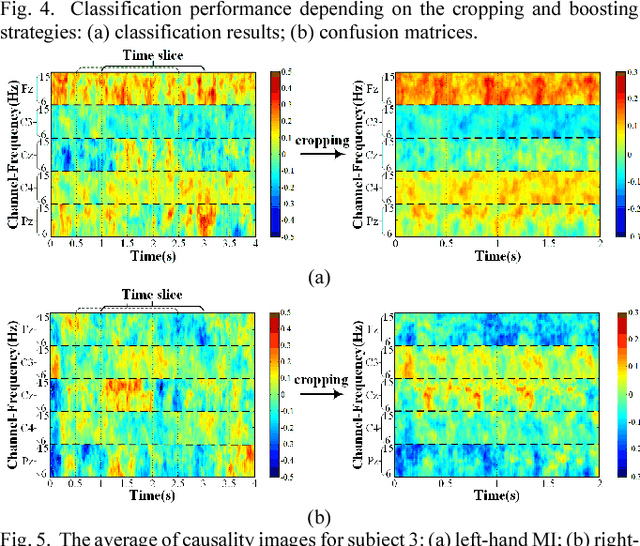
Decoding EEG signals of different mental states is a challenging task for brain-computer interfaces (BCIs) due to nonstationarity of perceptual decision processes. This paper presents a novel boosted convolutional neural networks (ConvNets) decoding scheme for motor imagery (MI) EEG signals assisted by the multiwavelet-based time-frequency (TF) causality analysis. Specifically, multiwavelet basis functions are first combined with Geweke spectral measure to obtain high-resolution TF-conditional Granger causality (CGC) representations, where a regularized orthogonal forward regression (ROFR) algorithm is adopted to detect a parsimonious model with good generalization performance. The causality images for network input preserving time, frequency and location information of connectivity are then designed based on the TF-CGC distributions of alpha band multichannel EEG signals. Further constructed boosted ConvNets by using spatio-temporal convolutions as well as advances in deep learning including cropping and boosting methods, to extract discriminative causality features and classify MI tasks. Our proposed approach outperforms the competition winner algorithm with 12.15% increase in average accuracy and 74.02% decrease in associated inter subject standard deviation for the same binary classification on BCI competition-IV dataset-IIa. Experiment results indicate that the boosted ConvNets with causality images works well in decoding MI-EEG signals and provides a promising framework for developing MI-BCI systems.
Householder Dice: A Matrix-Free Algorithm for Simulating Dynamics on Gaussian and Random Orthogonal Ensembles
Jan 22, 2021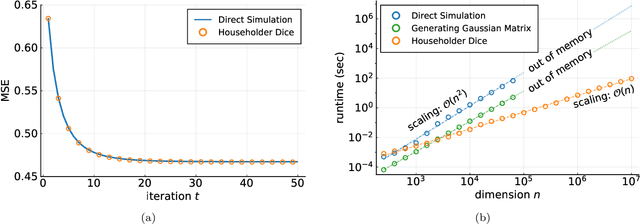
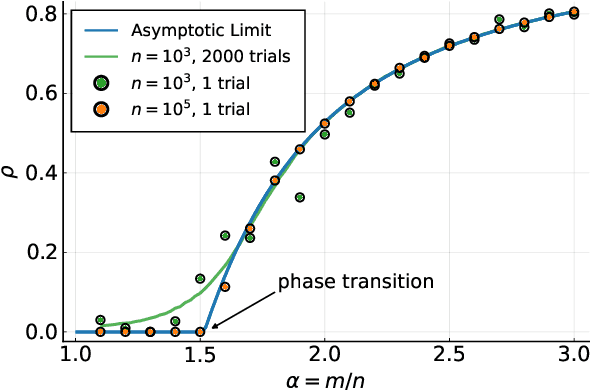
This paper proposes a new algorithm, named Householder Dice (HD), for simulating dynamics on dense random matrix ensembles with translation-invariant properties. Examples include the Gaussian ensemble, the Haar-distributed random orthogonal ensemble, and their complex-valued counterparts. A "direct" approach to the simulation, where one first generates a dense $n \times n$ matrix from the ensemble, requires at least $\mathcal{O}(n^2)$ resource in space and time. The HD algorithm overcomes this $\mathcal{O}(n^2)$ bottleneck by using the principle of deferred decisions: rather than fixing the entire random matrix in advance, it lets the randomness unfold with the dynamics. At the heart of this matrix-free algorithm is an adaptive and recursive construction of (random) Householder reflectors. These orthogonal transformations exploit the group symmetry of the matrix ensembles, while simultaneously maintaining the statistical correlations induced by the dynamics. The memory and computation costs of the HD algorithm are $\mathcal{O}(nT)$ and $\mathcal{O}(nT^2)$, respectively, with $T$ being the number of iterations. When $T \ll n$, which is nearly always the case in practice, the new algorithm leads to significant reductions in runtime and memory footprint. Numerical results demonstrate the promise of the HD algorithm as a new computational tool in the study of high-dimensional random systems.
Reservoir Computing with Thin-film Ferromagnetic Devices
Jan 29, 2021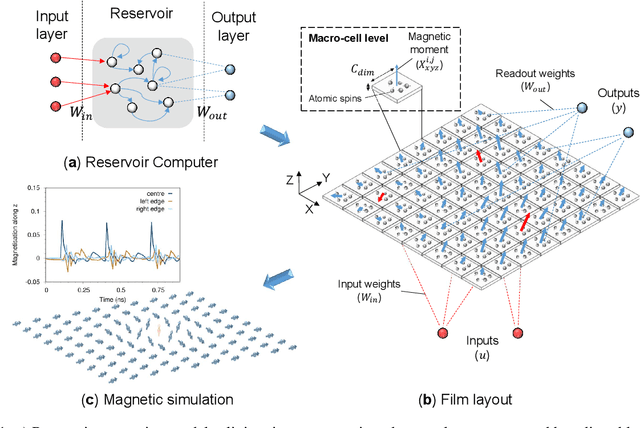
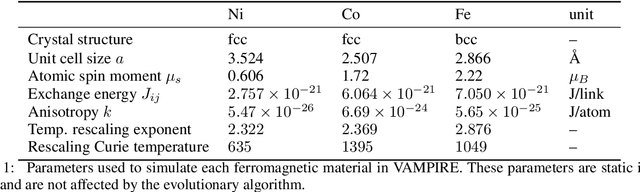
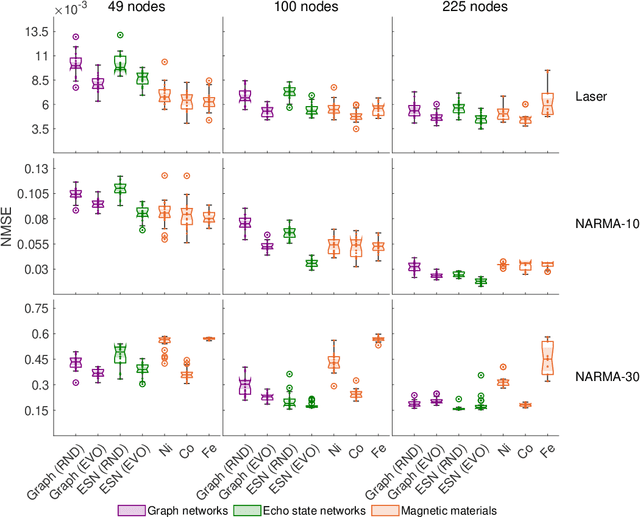
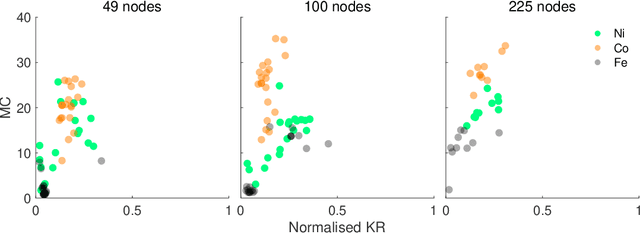
Advances in artificial intelligence are driven by technologies inspired by the brain, but these technologies are orders of magnitude less powerful and energy efficient than biological systems. Inspired by the nonlinear dynamics of neural networks, new unconventional computing hardware has emerged with the potential for extreme parallelism and ultra-low power consumption. Physical reservoir computing demonstrates this with a variety of unconventional systems from optical-based to spintronic. Reservoir computers provide a nonlinear projection of the task input into a high-dimensional feature space by exploiting the system's internal dynamics. A trained readout layer then combines features to perform tasks, such as pattern recognition and time-series analysis. Despite progress, achieving state-of-the-art performance without external signal processing to the reservoir remains challenging. Here we show, through simulation, that magnetic materials in thin-film geometries can realise reservoir computers with greater than or similar accuracy to digital recurrent neural networks. Our results reveal that basic spin properties of magnetic films generate the required nonlinear dynamics and memory to solve machine learning tasks. Furthermore, we show that neuromorphic hardware can be reduced in size by removing the need for discrete neural components and external processing. The natural dynamics and nanoscale size of magnetic thin-films present a new path towards fast energy-efficient computing with the potential to innovate portable smart devices, self driving vehicles, and robotics.
Data-Aware Device Scheduling for Federated Edge Learning
Feb 18, 2021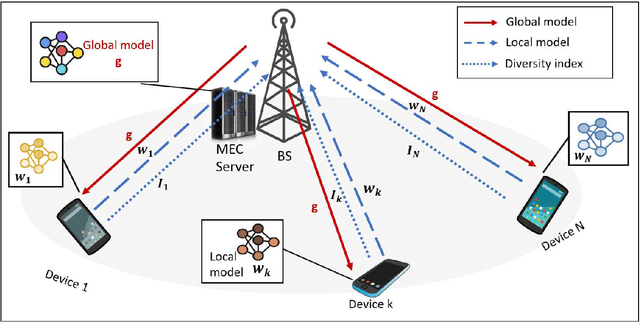
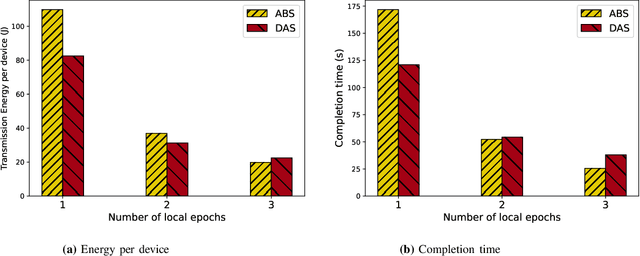
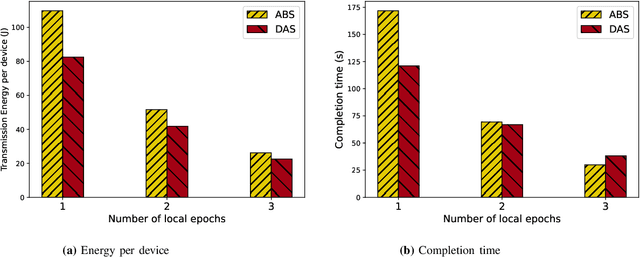
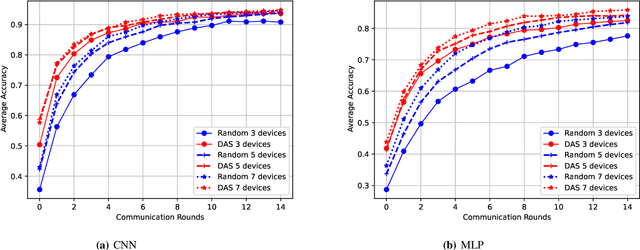
Federated Edge Learning (FEEL) involves the collaborative training of machine learning models among edge devices, with the orchestration of a server in a wireless edge network. Due to frequent model updates, FEEL needs to be adapted to the limited communication bandwidth, scarce energy of edge devices, and the statistical heterogeneity of edge devices' data distributions. Therefore, a careful scheduling of a subset of devices for training and uploading models is necessary. In contrast to previous work in FEEL where the data aspects are under-explored, we consider data properties at the heart of the proposed scheduling algorithm. To this end, we propose a new scheduling scheme for non-independent and-identically-distributed (non-IID) and unbalanced datasets in FEEL. As the data is the key component of the learning, we propose a new set of considerations for data characteristics in wireless scheduling algorithms in FEEL. In fact, the data collected by the devices depends on the local environment and usage pattern. Thus, the datasets vary in size and distributions among the devices. In the proposed algorithm, we consider both data and resource perspectives. In addition to minimizing the completion time of FEEL as well as the transmission energy of the participating devices, the algorithm prioritizes devices with rich and diverse datasets. We first define a general framework for the data-aware scheduling and the main axes and requirements for diversity evaluation. Then, we discuss diversity aspects and some exploitable techniques and metrics. Next, we formulate the problem and present our FEEL scheduling algorithm. Evaluations in different scenarios show that our proposed FEEL scheduling algorithm can help achieve high accuracy in few rounds with a reduced cost.
Machine learning methods for the detection of polar lows in satellite mosaics: major issues and their solutions
Nov 09, 2020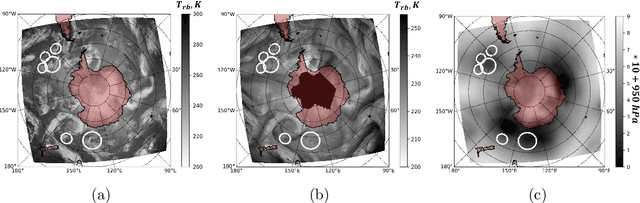
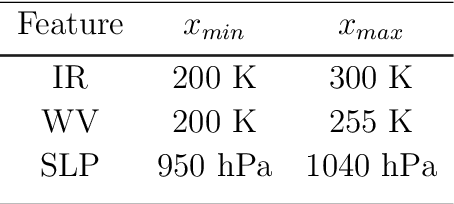

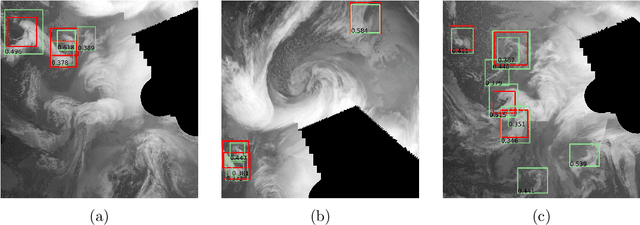
Polar mesocyclones (PMCs) and their intense subclass polar lows (PLs) are relatively small atmospheric vortices that form mostly over the ocean in high latitudes. PLs can strongly influence deep ocean water formation since they are associated with strong surface winds and heat fluxes. Detection and tracking of PLs are crucial for understanding the climatological dynamics of PLs and for the analysis of their impacts on other components of the climatic system. At the same time, visual tracking of PLs is a highly time-consuming procedure that requires expert knowledge and extensive examination of source data. There are known procedures involving deep convolutional neural networks (DCNNs) for the detection of large-scale atmospheric phenomena in reanalysis data that demonstrate a high quality of detection. However, one cannot apply these procedures to satellite data directly since, unlike reanalyses, satellite products register all the scales of atmospheric vortices. It is also known that DCNNs were originally designed to be scale-invariant. This leads to the problem of filtering the scale of detected phenomena. There are other problems to be solved, such as a low signal-to-noise ratio of satellite data and an unbalanced number of negative (without PLs) and positive (where a PL is presented) classes in a satellite dataset. In our study, we propose a deep learning approach for the detection of PLs and PMCs in remote sensing data, which addresses class imbalance and scale filtering problems. We also outline potential solutions for other problems, along with promising improvements to the presented approach.