 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Classification of Periodic Variable Stars with Novel Cyclic-Permutation Invariant Neural Networks
Nov 02, 2020
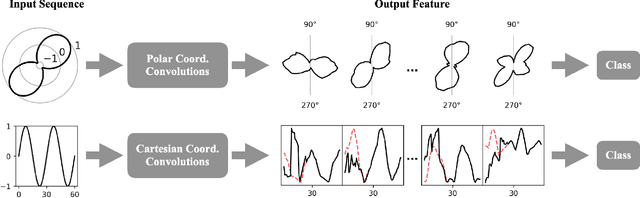
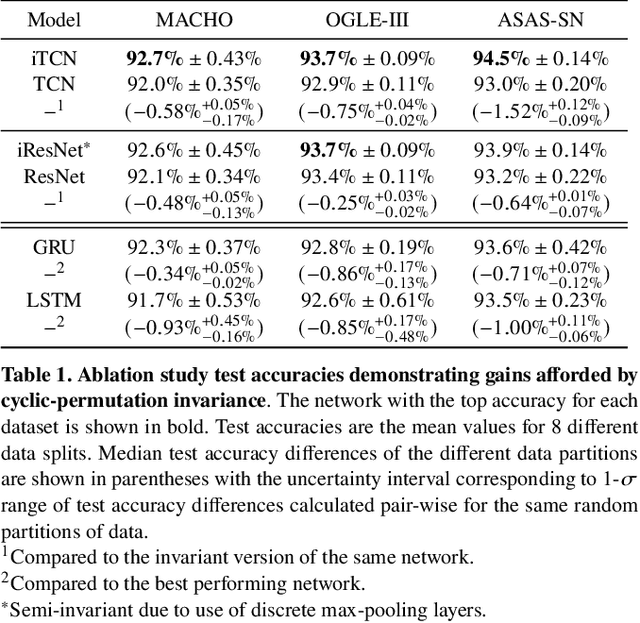
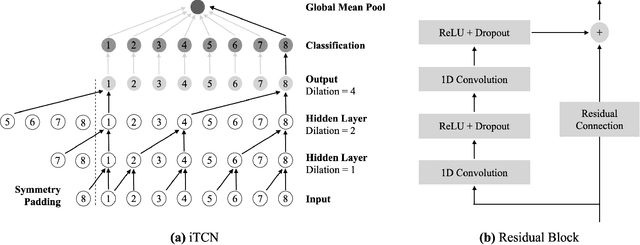
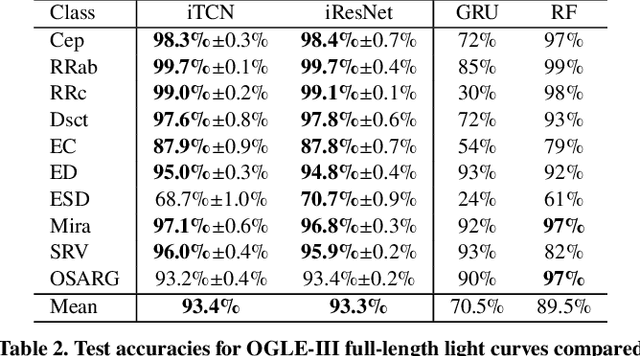
Neural networks (NNs) have been shown to be competitive against state-of-the-art feature engineering and random forest (RF) classification of periodic variable stars. Although previous work utilising NNs has made use of periodicity by period folding multiple-cycle time-series into a single cycle---from time-space to phase-space---no approach to date has taken advantage of the fact that network predictions should be invariant to the initial phase of the period-folded sequence. Initial phase is exogenous to the physical origin of the variability and should thus be factored out. Here, we present cyclic-permutation invariant networks, a novel class of NNs for which invariance to phase shifts is guaranteed through polar coordinate convolutions, which we implement by means of "Symmetry Padding." Across three different datasets of variable star light curves, we show that two implementations of the cyclic-permutation invariant network: the iTCN and the iResNet, consistently outperform non-invariant baselines and reduce overall error rates by between 4% to 22%. Over a 10-class OGLE-III sample, the iTCN/iResNet achieves an average per-class accuracy of 93.4%/93.3%, compared to RNN/RF accuracies of 70.5%/89.5% in a recent study using the same data. Finding improvement on a non-astronomy benchmark, we suggest that the methodology introduced here should also be applicable to a wide range of science domains where periodic data abounds due to physical symmetries.
Joint Resource Block and Beamforming Optimization for Cellular-Connected UAV Networks: A Hybrid D3QN-DDPG Approach
Feb 25, 2021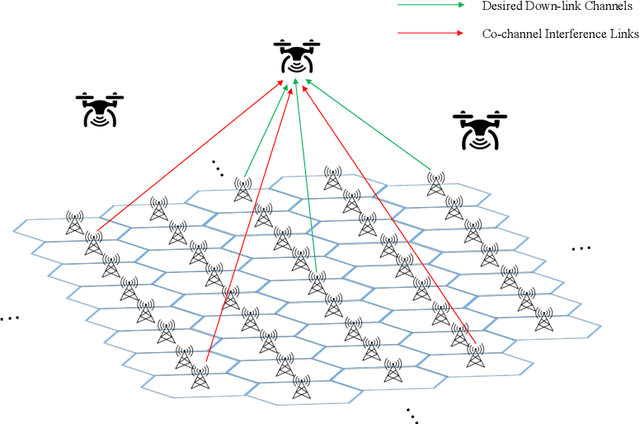
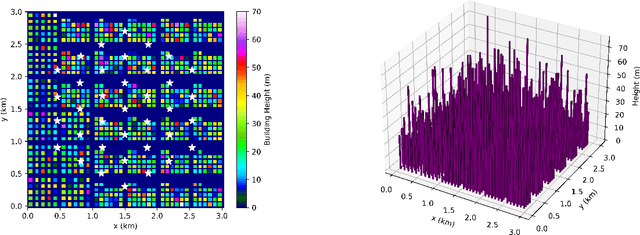
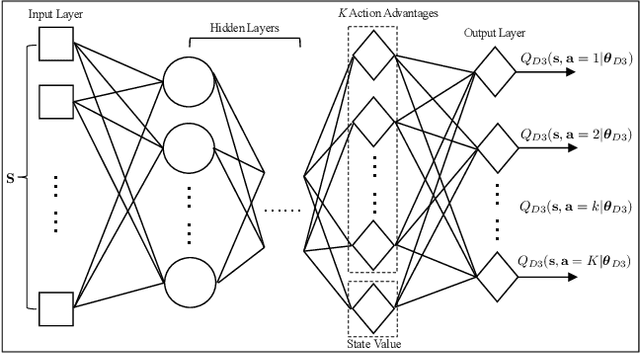
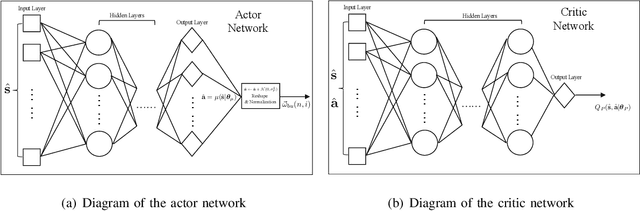
Integrating unmanned aerial vehicle (UAV) into the existing cellular networks that are delicately designed for terrestrial transmissions faces lots of challenges, in which one of the most striking concerns is how to adopt UAV into the cellular networks with less (or even without) adverse effects to ground users. In this paper, a cellular-connected UAV network is considered, in which multiple UAVs receive messages from terrestrial base stations (BSs) in the down-link, while BSs are serving ground users in their cells. Besides, the line-of-sight (LoS) wireless links are more likely to be established in ground-to-air (G2A) transmission scenarios. On one hand, UAVs may potentially get access to more BSs. On the other hand, more co-channel interferences could be involved. To enhance wireless transmission quality between UAVs and BSs while protecting the ground users from being interfered by the G2A communications, a joint time-frequency resource block (RB) and beamforming optimization problem is proposed and investigated in this paper. Specifically, with given flying trajectory, the ergodic outage duration (EOD) of UAV is minimized with the aid of RB resource allocation and beamforming design. Unfortunately, the proposed optimization problem is hard to be solved via standard optimization techniques, if not impossible. To crack this nut, a deep reinforcement learning (DRL) solution is proposed, where deep double duelling Q network (D3QN) and deep deterministic policy gradient (DDPG) are invoked to deal with RB allocation in discrete action domain and beamforming design in continuous action regime, respectively. The hybrid D3QN-DDPG solution is applied to solve the outer Markov decision process (MDP) and the inner MDP interactively so that it can achieve the sub-optimal result for the considered optimization problem.
Generating coherent spontaneous speech and gesture from text
Jan 14, 2021
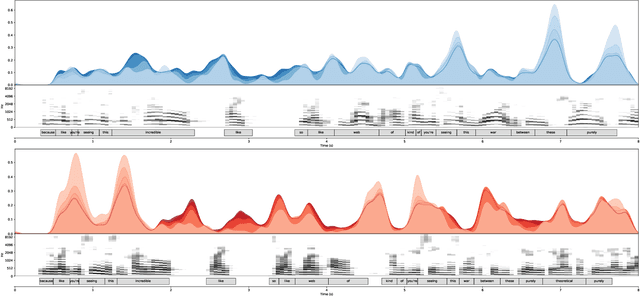
Embodied human communication encompasses both verbal (speech) and non-verbal information (e.g., gesture and head movements). Recent advances in machine learning have substantially improved the technologies for generating synthetic versions of both of these types of data: On the speech side, text-to-speech systems are now able to generate highly convincing, spontaneous-sounding speech using unscripted speech audio as the source material. On the motion side, probabilistic motion-generation methods can now synthesise vivid and lifelike speech-driven 3D gesticulation. In this paper, we put these two state-of-the-art technologies together in a coherent fashion for the first time. Concretely, we demonstrate a proof-of-concept system trained on a single-speaker audio and motion-capture dataset, that is able to generate both speech and full-body gestures together from text input. In contrast to previous approaches for joint speech-and-gesture generation, we generate full-body gestures from speech synthesis trained on recordings of spontaneous speech from the same person as the motion-capture data. We illustrate our results by visualising gesture spaces and text-speech-gesture alignments, and through a demonstration video at https://simonalexanderson.github.io/IVA2020 .
* 3 pages, 2 figures, published at the ACM International Conference on Intelligent Virtual Agents (IVA) 2020
Machine Learning for Temporal Data in Finance: Challenges and Opportunities
Sep 11, 2020
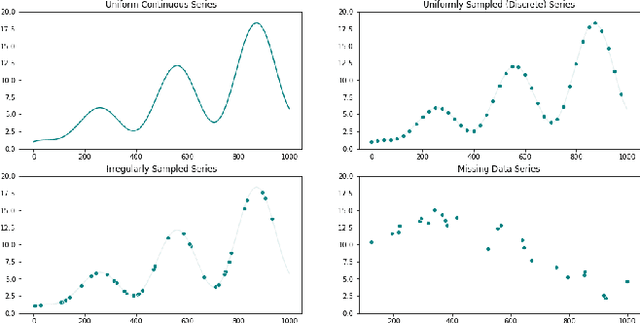
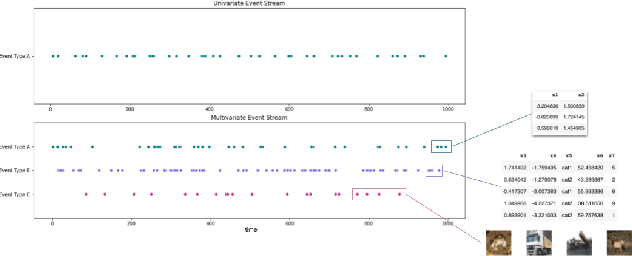
Temporal data are ubiquitous in the financial services (FS) industry -- traditional data like economic indicators, operational data such as bank account transactions, and modern data sources like website clickstreams -- all of these occur as a time-indexed sequence. But machine learning efforts in FS often fail to account for the temporal richness of these data, even in cases where domain knowledge suggests that the precise temporal patterns between events should contain valuable information. At best, such data are often treated as uniform time series, where there is a sequence but no sense of exact timing. At worst, rough aggregate features are computed over a pre-selected window so that static sample-based approaches can be applied (e.g. number of open lines of credit in the previous year or maximum credit utilization over the previous month). Such approaches are at odds with the deep learning paradigm which advocates for building models that act directly on raw or lightly processed data and for leveraging modern optimization techniques to discover optimal feature transformations en route to solving the modeling task at hand. Furthermore, a full picture of the entity being modeled (customer, company, etc.) might only be attainable by examining multiple data streams that unfold across potentially vastly different time scales. In this paper, we examine the different types of temporal data found in common FS use cases, review the current machine learning approaches in this area, and finally assess challenges and opportunities for researchers working at the intersection of machine learning for temporal data and applications in FS.
Refining activation downsampling with SoftPool
Jan 05, 2021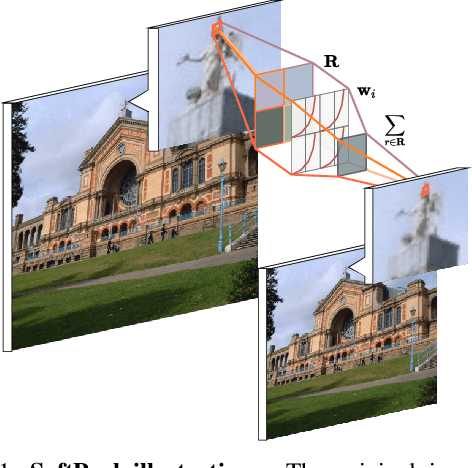
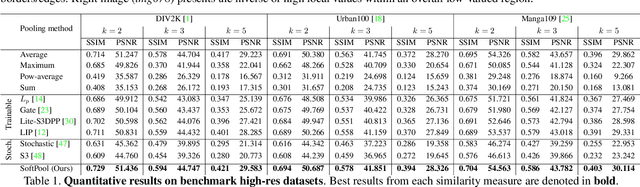
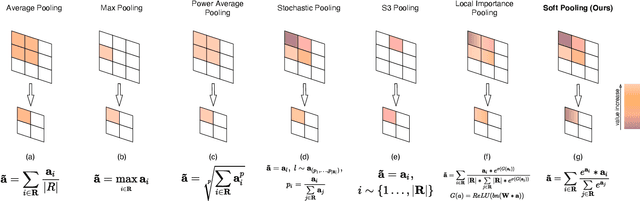
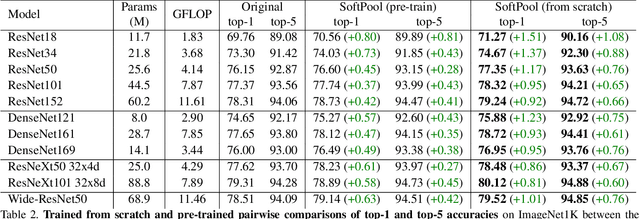
Convolutional Neural Networks (CNNs) use pooling to decrease the size of activation maps. This process is crucial to locally achieve spatial invariance and to increase the receptive field of subsequent convolutions. Pooling operations should minimize the loss of information in the activation maps. At the same time, the computation and memory overhead should be limited. To meet these requirements, we propose SoftPool: a fast and efficient method that sums exponentially weighted activations. Compared to a range of other pooling methods, SoftPool retains more information in the downsampled activation maps. More refined downsampling leads to better classification accuracy. On ImageNet1K, for a range of popular CNN architectures, replacing the original pooling operations with SoftPool leads to consistent accuracy improvements in the order of 1-2%. We also test SoftPool on video datasets for action recognition. Again, replacing only the pooling layers consistently increases accuracy while computational load and memory remain limited. These favorable properties make SoftPool an excellent replacement for current pooling operations, including max-pool and average-pool
EfficientQA : a RoBERTa Based Phrase-Indexed Question-Answering System
Jan 30, 2021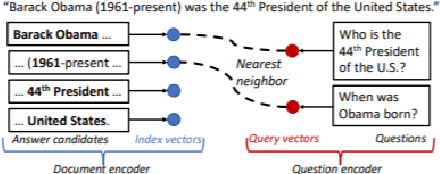
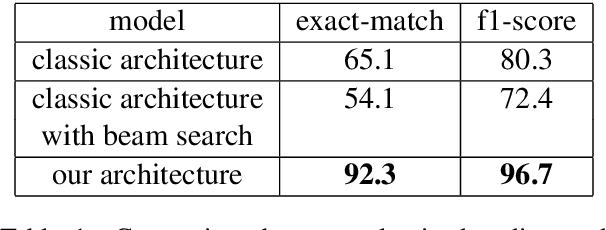
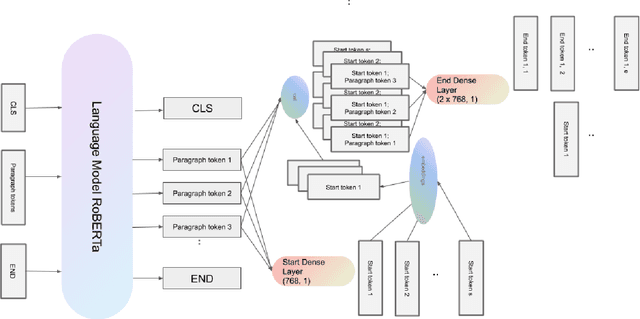
State-of-the-art extractive question answering models achieve superhuman performances on the SQuAD benchmark. Yet, they are unreasonably heavy and need expensive GPU computing to answer questions in a reasonable time. Thus, they cannot be used for real-world queries on hundreds of thousands of documents in the open-domain question answering paradigm. In this paper, we explore the possibility to transfer the natural language understanding of language models into dense vectors representing questions and answer candidates, in order to make the task of question-answering compatible with a simple nearest neighbor search task. This new model, that we call EfficientQA, takes advantage from the pair of sequences kind of input of BERT-based models to build meaningful dense representations of candidate answers. These latter are extracted from the context in a question-agnostic fashion. Our model achieves state-of-the-art results in Phrase-Indexed Question Answering (PIQA) beating the previous state-of-art by 1.3 points in exact-match and 1.4 points in f1-score. These results show that dense vectors are able to embed very rich semantic representations of sequences, although these ones were built from language models not originally trained for the use-case. Thus, in order to build more resource efficient NLP systems in the future, training language models that are better adapted to build dense representations of phrases is one of the possibilities.
An Analysis of Frame-skipping in Reinforcement Learning
Feb 07, 2021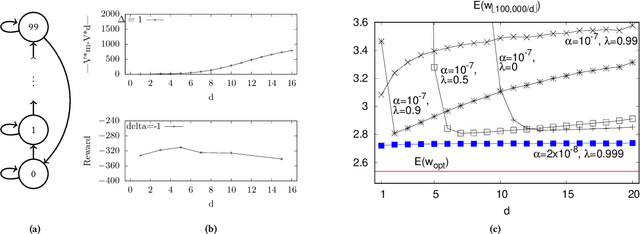
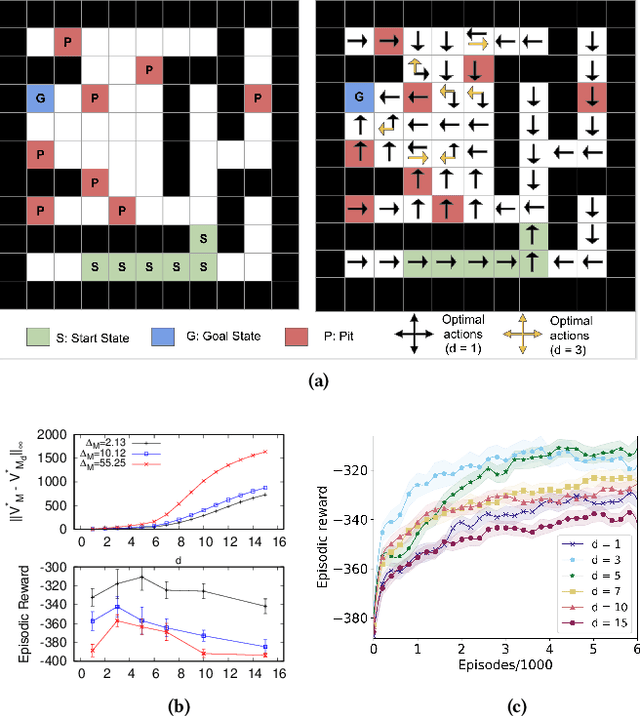
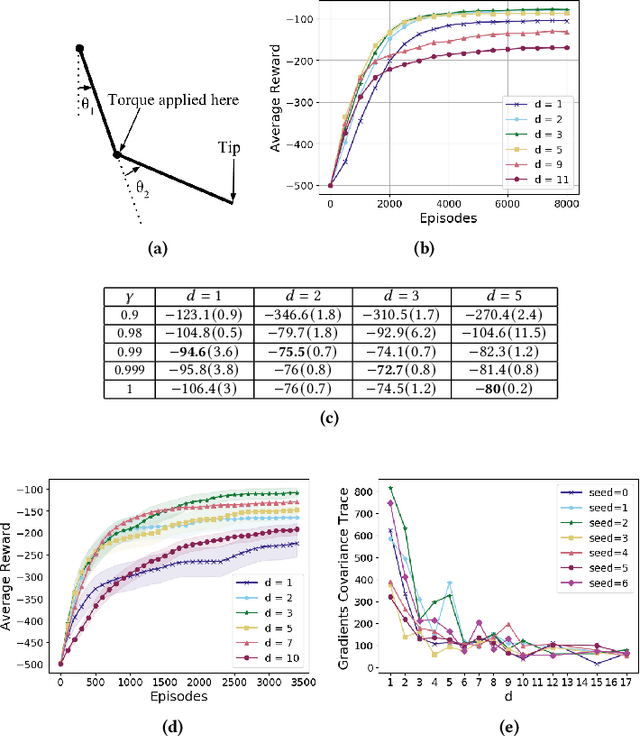
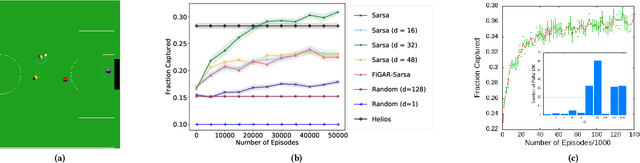
In the practice of sequential decision making, agents are often designed to sense state at regular intervals of $d$ time steps, $d > 1$, ignoring state information in between sensing steps. While it is clear that this practice can reduce sensing and compute costs, recent results indicate a further benefit. On many Atari console games, reinforcement learning (RL) algorithms deliver substantially better policies when run with $d > 1$ -- in fact with $d$ even as high as $180$. In this paper, we investigate the role of the parameter $d$ in RL; $d$ is called the "frame-skip" parameter, since states in the Atari domain are images. For evaluating a fixed policy, we observe that under standard conditions, frame-skipping does not affect asymptotic consistency. Depending on other parameters, it can possibly even benefit learning. To use $d > 1$ in the control setting, one must first specify which $d$-step open-loop action sequences can be executed in between sensing steps. We focus on "action-repetition", the common restriction of this choice to $d$-length sequences of the same action. We define a task-dependent quantity called the "price of inertia", in terms of which we upper-bound the loss incurred by action-repetition. We show that this loss may be offset by the gain brought to learning by a smaller task horizon. Our analysis is supported by experiments on different tasks and learning algorithms.
StainNet: a fast and robust stain normalization network
Jan 05, 2021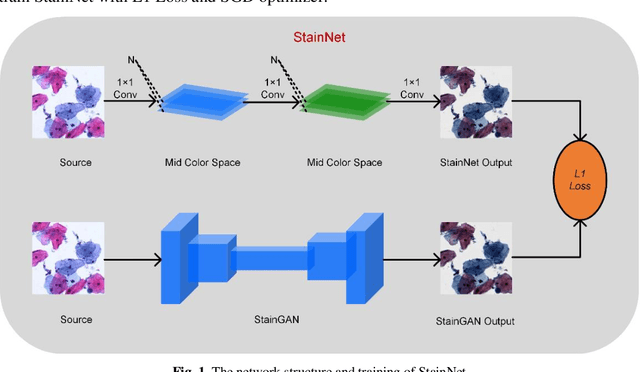
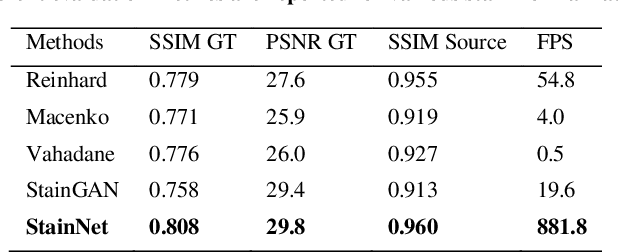
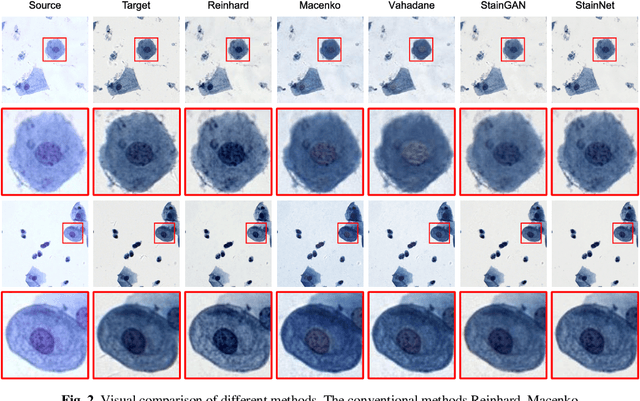
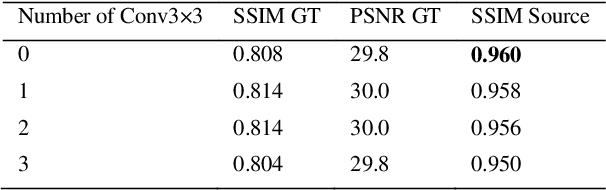
Pathological images have large color variabilities due to various factors. These variations hamper the performance of computer-aided diagnosis (CAD) systems. Stain normalization has been used to reduce the color variability and increase the prediction accuracy. Among these algorithms, the conventional methods perform stain normalization on a pixel-by-pixel basis, but estimate stain parameters just relying on one single reference image and thus would incur some inaccurate normalization results. As for the current deep learning-based methods, the color distribution extraction can be automatically extracted and need not pick a representative reference image. At the same time, the network of deep learning-based methods has a complex structure with millions of parameters, so they have a low computational efficiency and risk to introduce artifacts. In this paper, a fast and robust stain normalization network with only 1.28K parameters named StainNet is proposed. StainNet can learn the color mapping relationship from a whole dataset and adjust the color value in a pixel-to-pixel manner. The proposed method performs well in stain normalization and achieves a better accuracy and image quality.
MeInGame: Create a Game Character Face from a Single Portrait
Feb 07, 2021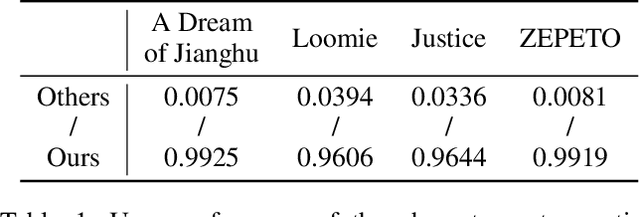
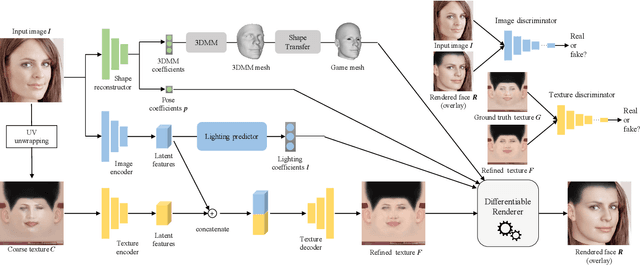
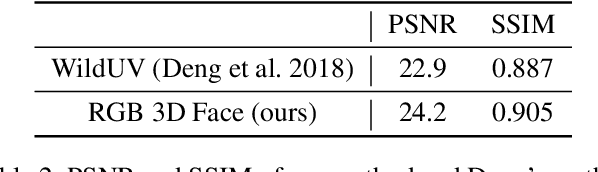

Many deep learning based 3D face reconstruction methods have been proposed recently, however, few of them have applications in games. Current game character customization systems either require players to manually adjust considerable face attributes to obtain the desired face, or have limited freedom of facial shape and texture. In this paper, we propose an automatic character face creation method that predicts both facial shape and texture from a single portrait, and it can be integrated into most existing 3D games. Although 3D Morphable Face Model (3DMM) based methods can restore accurate 3D faces from single images, the topology of 3DMM mesh is different from the meshes used in most games. To acquire fidelity texture, existing methods require a large amount of face texture data for training, while building such datasets is time-consuming and laborious. Besides, such a dataset collected under laboratory conditions may not generalized well to in-the-wild situations. To tackle these problems, we propose 1) a low-cost facial texture acquisition method, 2) a shape transfer algorithm that can transform the shape of a 3DMM mesh to games, and 3) a new pipeline for training 3D game face reconstruction networks. The proposed method not only can produce detailed and vivid game characters similar to the input portrait, but can also eliminate the influence of lighting and occlusions. Experiments show that our method outperforms state-of-the-art methods used in games.
HiPPO: Recurrent Memory with Optimal Polynomial Projections
Aug 17, 2020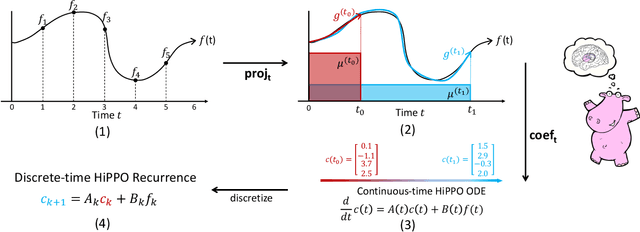

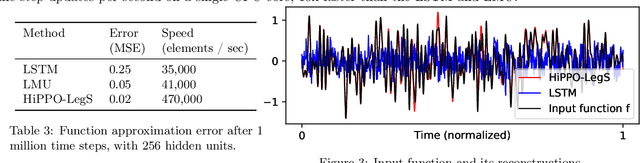
A central problem in learning from sequential data is representing cumulative history in an incremental fashion as more data is processed. We introduce a general framework (HiPPO) for the online compression of continuous signals and discrete time series by projection onto polynomial bases. Given a measure that specifies the importance of each time step in the past, HiPPO produces an optimal solution to a natural online function approximation problem. As special cases, our framework yields a short derivation of the recent Legendre Memory Unit (LMU) from first principles, and generalizes the ubiquitous gating mechanism of recurrent neural networks such as GRUs. This formal framework yields a new memory update mechanism (HiPPO-LegS) that scales through time to remember all history, avoiding priors on the timescale. HiPPO-LegS enjoys the theoretical benefits of timescale robustness, fast updates, and bounded gradients. By incorporating the memory dynamics into recurrent neural networks, HiPPO RNNs can empirically capture complex temporal dependencies. On the benchmark permuted MNIST dataset, HiPPO-LegS sets a new state-of-the-art accuracy of 98.3%. Finally, on a novel trajectory classification task testing robustness to out-of-distribution timescales and missing data, HiPPO-LegS outperforms RNN and neural ODE baselines by 25-40% accuracy.