 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamic Hybrid Relation Network for Cross-Domain Context-Dependent Semantic Parsing
Jan 05, 2021
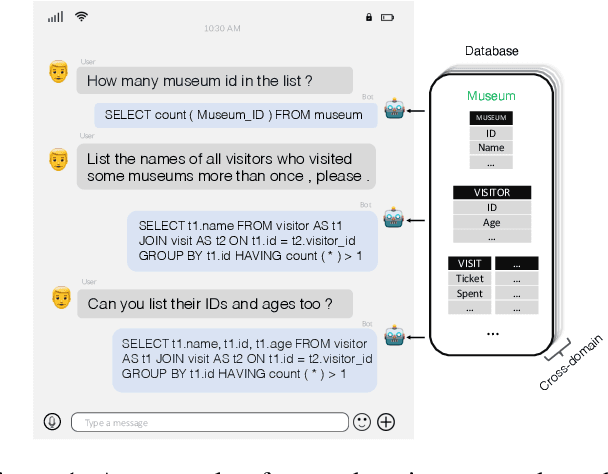

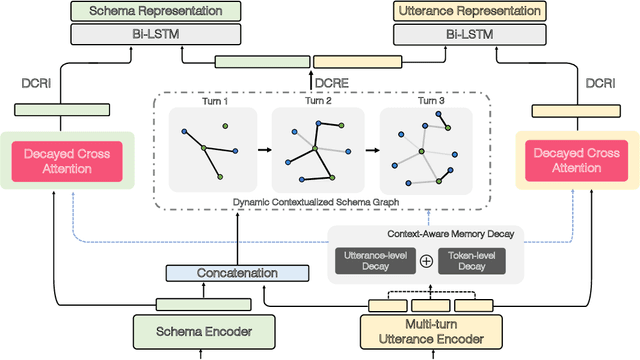
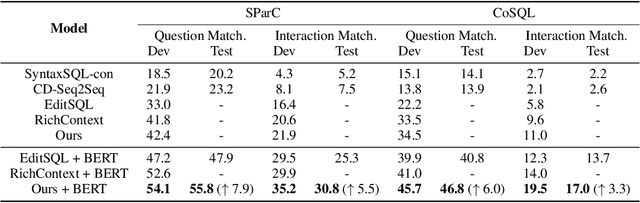
Semantic parsing has long been a fundamental problem in natural language processing. Recently, cross-domain context-dependent semantic parsing has become a new focus of research. Central to the problem is the challenge of leveraging contextual information of both natural language utterance and database schemas in the interaction history. In this paper, we present a dynamic graph framework that is capable of effectively modelling contextual utterances, tokens, database schemas, and their complicated interaction as the conversation proceeds. The framework employs a dynamic memory decay mechanism that incorporates inductive bias to integrate enriched contextual relation representation, which is further enhanced with a powerful reranking model. At the time of writing, we demonstrate that the proposed framework outperforms all existing models by large margins, achieving new state-of-the-art performance on two large-scale benchmarks, the SParC and CoSQL datasets. Specifically, the model attains a 55.8% question-match and 30.8% interaction-match accuracy on SParC, and a 46.8% question-match and 17.0% interaction-match accuracy on CoSQL.
Can We Detect Mastitis earlier than Farmers?
Nov 05, 2020
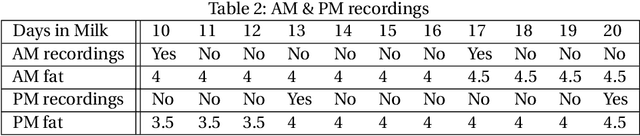
The aim of this study was to build a modelling framework that would allow us to be able to detect mastitis infections before they would normally be found by farmers through the introduction of machine learning techniques. In the making of this we created two different modelling framework's, one that works on the premise of detecting Sub Clinical mastitis infections at one Somatic Cell Count recording in advance called SMA and the other tries to detect both Sub Clinical mastitis infections aswell as Clinical mastitis infections at any time the cow is milked called AMA. We also introduce the idea of two different feature sets for our study, these represent different characteristics that should be taken into account when detecting infections, these were the idea of a cow differing to a farm mean and also trends in the lactation. We reported that the results for SMA are better than those created by AMA for Sub Clinical infections yet it has the significant disadvantage of only being able to classify Sub Clinical infections due to how we recorded Sub Clinical infections as being any time a Somatic Cell Count measurement went above a certain threshold where as CM could appear at any stage of lactation. Thus in some cases the lower accuracy values for AMA might in fact be more beneficial to farmers.
An Explainable Artificial Intelligence Approach for Unsupervised Fault Detection and Diagnosis in Rotating Machinery
Feb 23, 2021

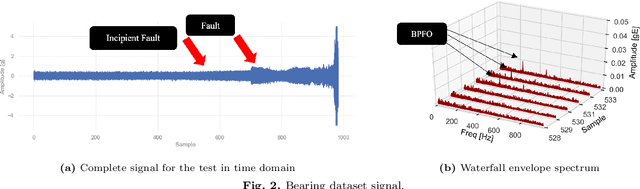
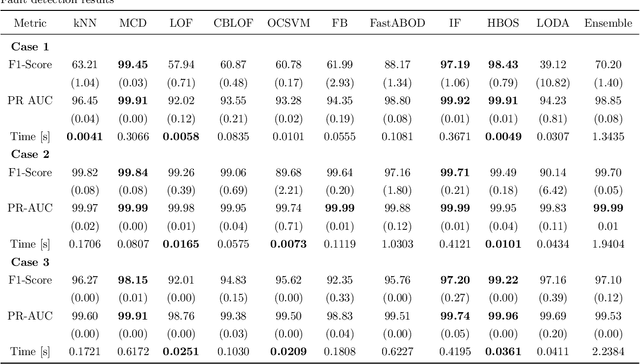
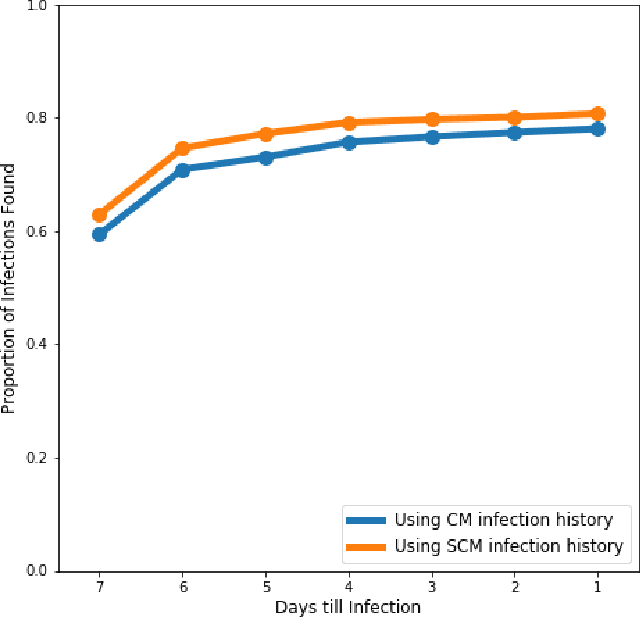
The monitoring of rotating machinery is an essential task in today's production processes. Currently, several machine learning and deep learning-based modules have achieved excellent results in fault detection and diagnosis. Nevertheless, to further increase user adoption and diffusion of such technologies, users and human experts must be provided with explanations and insights by the modules. Another issue is related, in most cases, with the unavailability of labeled historical data that makes the use of supervised models unfeasible. Therefore, a new approach for fault detection and diagnosis in rotating machinery is here proposed. The methodology consists of three parts: feature extraction, fault detection and fault diagnosis. In the first part, the vibration features in the time and frequency domains are extracted. Secondly, in the fault detection, the presence of fault is verified in an unsupervised manner based on anomaly detection algorithms. The modularity of the methodology allows different algorithms to be implemented. Finally, in fault diagnosis, Shapley Additive Explanations (SHAP), a technique to interpret black-box models, is used. Through the feature importance ranking obtained by the model explainability, the fault diagnosis is performed. Two tools for diagnosis are proposed, namely: unsupervised classification and root cause analysis. The effectiveness of the proposed approach is shown on three datasets containing different mechanical faults in rotating machinery. The study also presents a comparison between models used in machine learning explainability: SHAP and Local Depth-based Feature Importance for the Isolation Forest (Local- DIFFI). Lastly, an analysis of several state-of-art anomaly detection algorithms in rotating machinery is included.
FIXME: Enhance Software Reliability with Hybrid Approaches in Cloud
Feb 17, 2021

With the promise of reliability in cloud, more enterprises are migrating to cloud. The process of continuous integration/deployment (CICD) in cloud connects developers who need to deliver value faster and more transparently with site reliability engineers (SREs) who need to manage applications reliably. SREs feed back development issues to developers, and developers commit fixes and trigger CICD to redeploy. The release cycle is more continuous than ever, thus the code to production is faster and more automated. To provide this higher level agility, the cloud platforms become more complex in the face of flexibility with deeper layers of virtualization. However, reliability does not come for free with all these complexities. Software engineers and SREs need to deal with wider information spectrum from virtualized layers. Therefore, providing correlated information with true positive evidences is critical to identify the root cause of issues quickly in order to reduce mean time to recover (MTTR), performance metrics for SREs. Similarity, knowledge, or statistics driven approaches have been effective, but with increasing data volume and types, an individual approach is limited to correlate semantic relations of different data sources. In this paper, we introduce FIXME to enhance software reliability with hybrid diagnosis approaches for enterprises. Our evaluation results show using hybrid diagnosis approach is about 17% better in precision. The results are helpful for both practitioners and researchers to develop hybrid diagnosis in the highly dynamic cloud environment.
A Survey on Advancing the DBMS Query Optimizer: Cardinality Estimation, Cost Model, and Plan Enumeration
Jan 05, 2021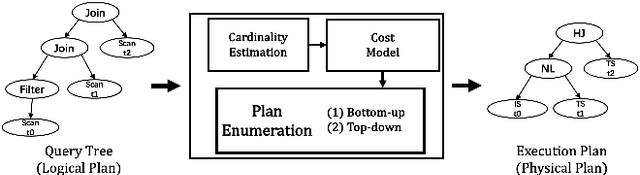
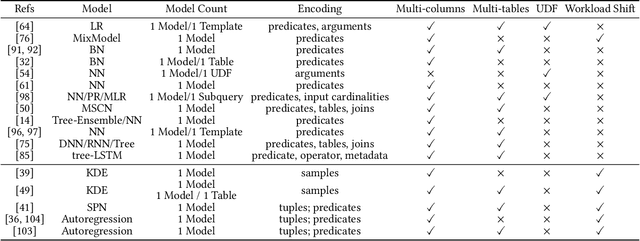
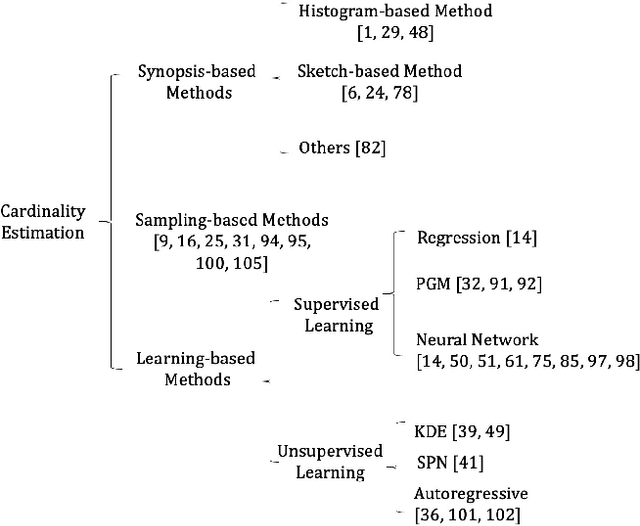

Query optimizer is at the heart of the database systems. Cost-based optimizer studied in this paper is adopted in almost all current database systems. A cost-based optimizer introduces a plan enumeration algorithm to find a (sub)plan, and then uses a cost model to obtain the cost of that plan, and selects the plan with the lowest cost. In the cost model, cardinality, the number of tuples through an operator, plays a crucial role. Due to the inaccuracy in cardinality estimation, errors in cost model, and the huge plan space, the optimizer cannot find the optimal execution plan for a complex query in a reasonable time. In this paper, we first deeply study the causes behind the limitations above. Next, we review the techniques used to improve the quality of the three key components in the cost-based optimizer, cardinality estimation, cost model, and plan enumeration. We also provide our insights on the future directions for each of the above aspects.
An Empirical Study on Model-agnostic Debiasing Strategies for Robust Natural Language Inference
Oct 08, 2020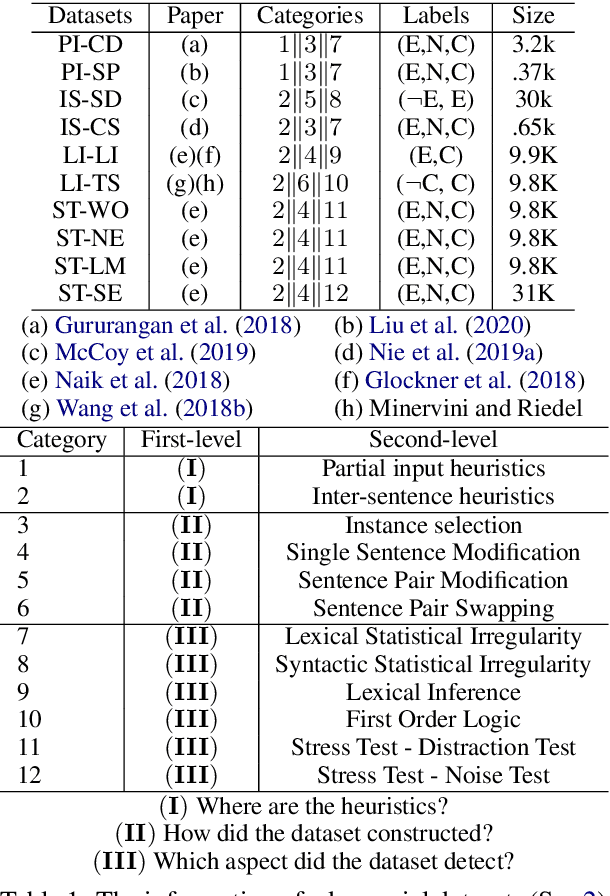
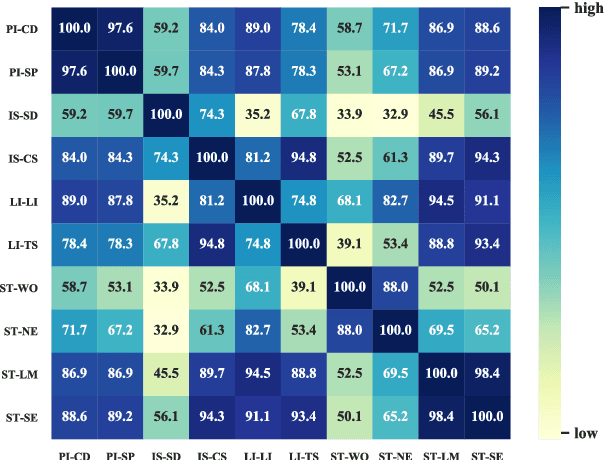
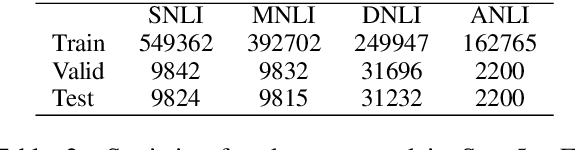
The prior work on natural language inference (NLI) debiasing mainly targets at one or few known biases while not necessarily making the models more robust. In this paper, we focus on the model-agnostic debiasing strategies and explore how to (or is it possible to) make the NLI models robust to multiple distinct adversarial attacks while keeping or even strengthening the models' generalization power. We firstly benchmark prevailing neural NLI models including pretrained ones on various adversarial datasets. We then try to combat distinct known biases by modifying a mixture of experts (MoE) ensemble method and show that it's nontrivial to mitigate multiple NLI biases at the same time, and that model-level ensemble method outperforms MoE ensemble method. We also perform data augmentation including text swap, word substitution and paraphrase and prove its efficiency in combating various (though not all) adversarial attacks at the same time. Finally, we investigate several methods to merge heterogeneous training data (1.35M) and perform model ensembling, which are straightforward but effective to strengthen NLI models.
Real Time Emulation of Parametric Guitar Tube Amplifier With Long Short Term Memory Neural Network
Apr 19, 2018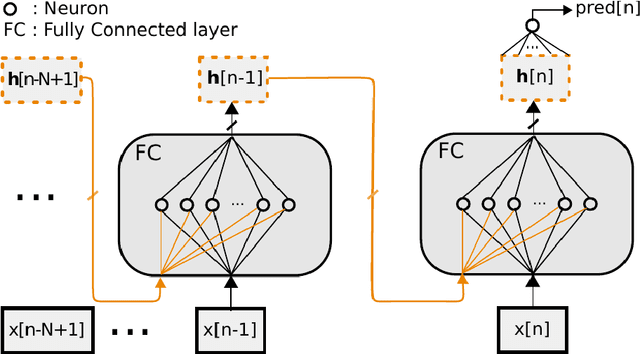
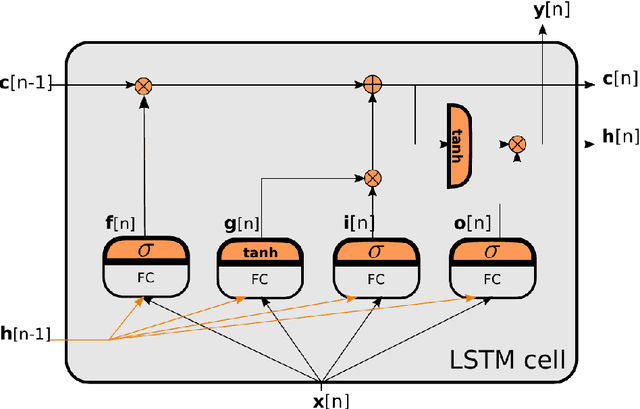
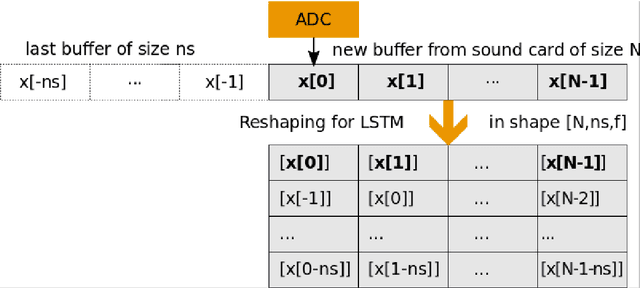
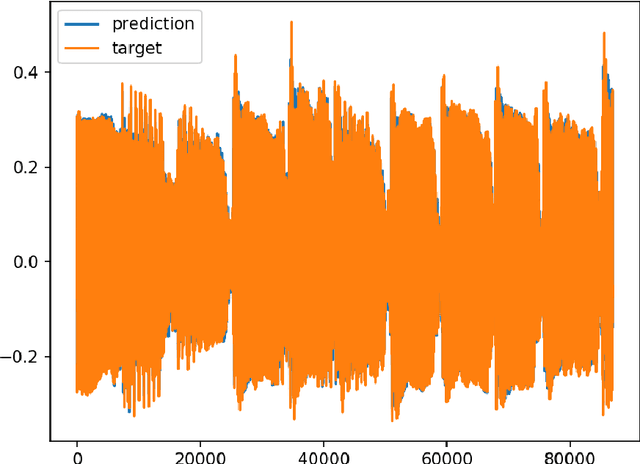
Numerous audio systems for musicians are expensive and bulky. Therefore, it could be advantageous to model them and to replace them by computer emulation. In guitar players' world, audio systems could have a desirable nonlinear behavior (distortion effects). It is thus difficult to find a simple model to emulate them in real time. Volterra series model and its subclass are usual ways to model nonlinear systems. Unfortunately, these systems are difficult to identify in an analytic way. In this paper we propose to take advantage of the new progress made in neural networks to emulate them in real time. We show that an accurate emulation can be reached with less than 1% of root mean square error between the signal coming from a tube amplifier and the output of the neural network. Moreover, the research has been extended to model the Gain parameter of the amplifier.
Full and Reduced Order Observers for Image-based Depth Estimation using Concurrent Learning
Aug 11, 2020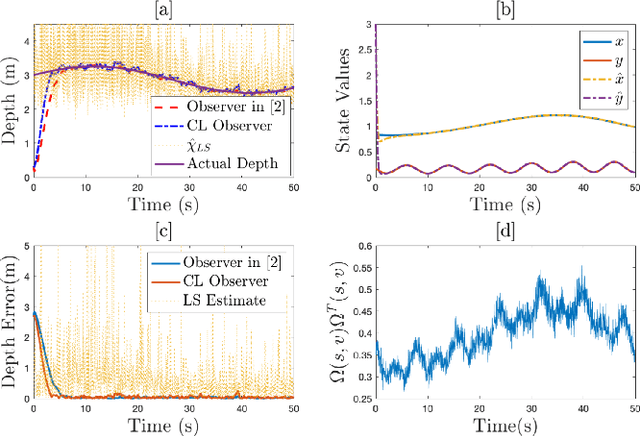
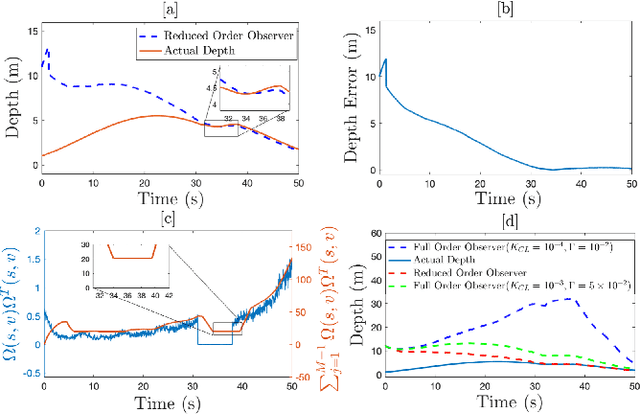
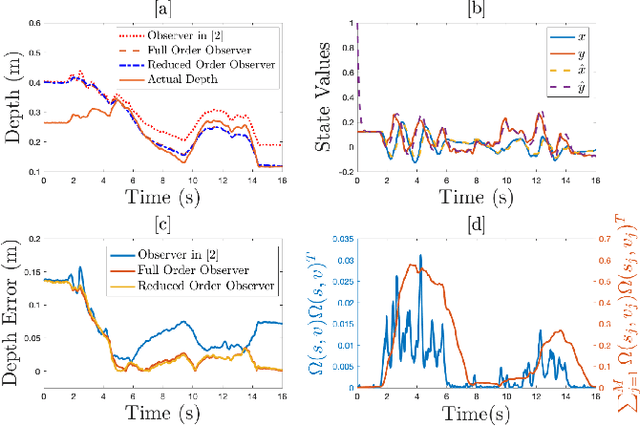
In this paper concurrent learning (CL)-based full and reduced order observers for a perspective dynamical system (PDS) are developed. The PDS is a widely used model for estimating the depth of a feature point from a sequence of camera images. Building on the current progress of CL for parameter estimation in adaptive control, a state observer is developed for the PDS model where the inverse depth appears as a time-varying parameter in the dynamics. The data recorded over a sliding time window in the near past is used in the CL term to design the full and the reduced order state observers. A Lyapunov-based stability analysis is carried out to prove the uniformly ultimately bounded (UUB) stability of the developed observers. Simulation results are presented to validate the accuracy and convergence of the developed observers in terms of convergence time, root mean square error (RMSE) and mean absolute percentage error (MAPE) metrics. Real world depth estimation experiments are performed to demonstrate the performance of the observers using aforementioned metrics on a 7-DoF manipulator with an eye-in-hand configuration.
Physics-aware, deep probabilistic modeling of multiscale dynamics in the Small Data regime
Feb 09, 2021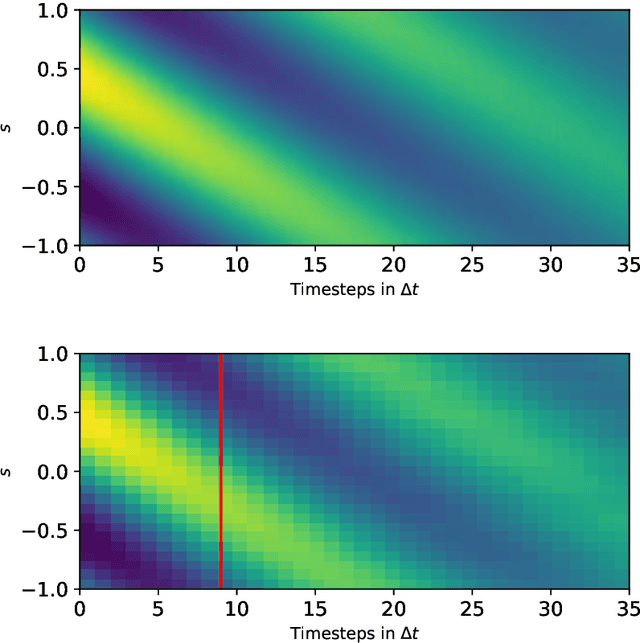
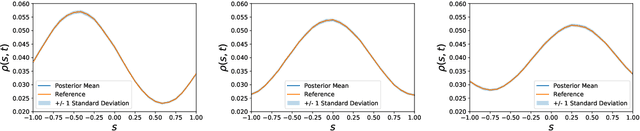
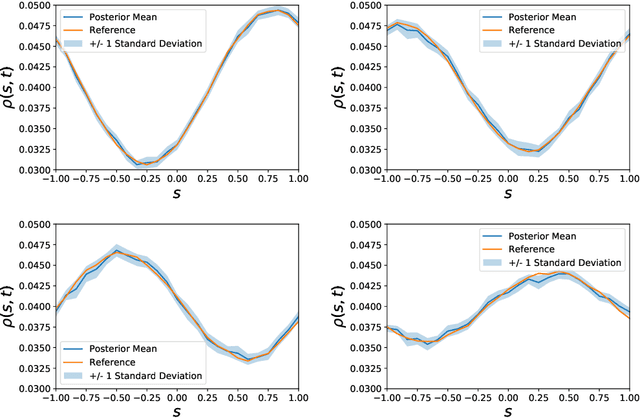
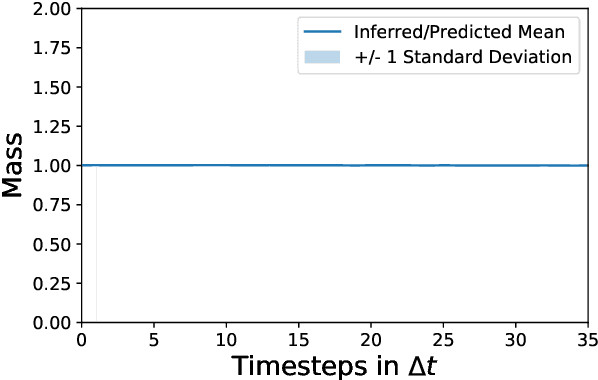
The data-based discovery of effective, coarse-grained (CG) models of high-dimensional dynamical systems presents a unique challenge in computational physics and particularly in the context of multiscale problems. The present paper offers a probabilistic perspective that simultaneously identifies predictive, lower-dimensional coarse-grained (CG) variables as well as their dynamics. We make use of the expressive ability of deep neural networks in order to represent the right-hand side of the CG evolution law. Furthermore, we demonstrate how domain knowledge that is very often available in the form of physical constraints (e.g. conservation laws) can be incorporated with the novel concept of virtual observables. Such constraints, apart from leading to physically realistic predictions, can significantly reduce the requisite amount of training data which enables reducing the amount of required, computationally expensive multiscale simulations (Small Data regime). The proposed state-space model is trained using probabilistic inference tools and, in contrast to several other techniques, does not require the prescription of a fine-to-coarse (restriction) projection nor time-derivatives of the state variables. The formulation adopted is capable of quantifying the predictive uncertainty as well as of reconstructing the evolution of the full, fine-scale system which allows to select the quantities of interest a posteriori. We demonstrate the efficacy of the proposed framework in a high-dimensional system of moving particles.
Understanding the Ability of Deep Neural Networks to Count Connected Components in Images
Jan 05, 2021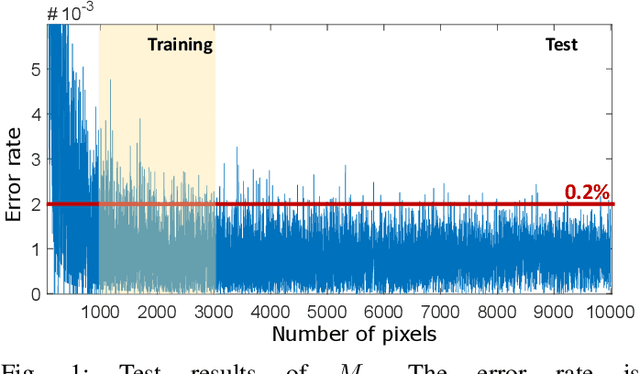
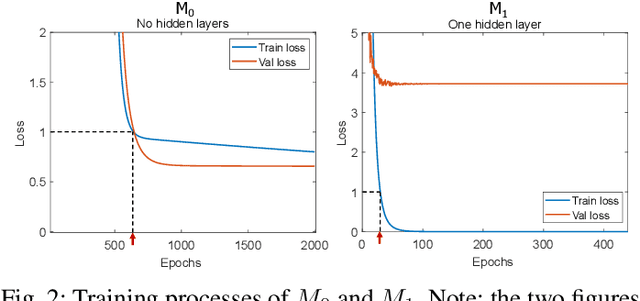
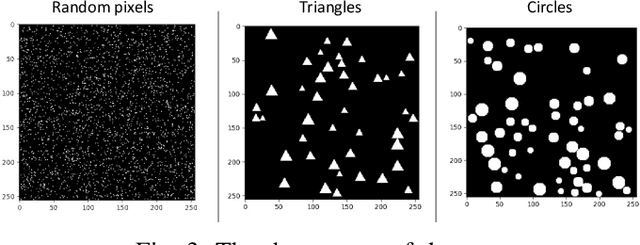
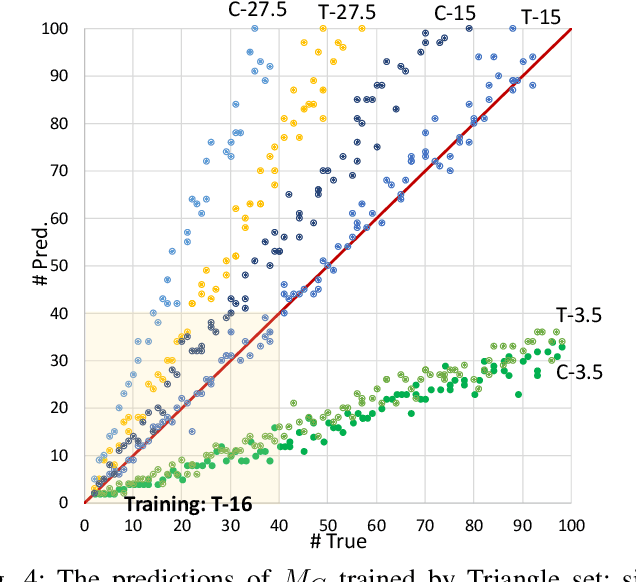
Humans can count very fast by subitizing, but slow substantially as the number of objects increases. Previous studies have shown a trained deep neural network (DNN) detector can count the number of objects in an amount of time that increases slowly with the number of objects. Such a phenomenon suggests the subitizing ability of DNNs, and unlike humans, it works equally well for large numbers. Many existing studies have successfully applied DNNs to object counting, but few studies have studied the subitizing ability of DNNs and its interpretation. In this paper, we found DNNs do not have the ability to generally count connected components. We provided experiments to support our conclusions and explanations to understand the results and phenomena of these experiments. We proposed three ML-learnable characteristics to verify learnable problems for ML models, such as DNNs, and explain why DNNs work for specific counting problems but cannot generally count connected components.