 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spatial Contrastive Learning for Few-Shot Classification
Dec 26, 2020
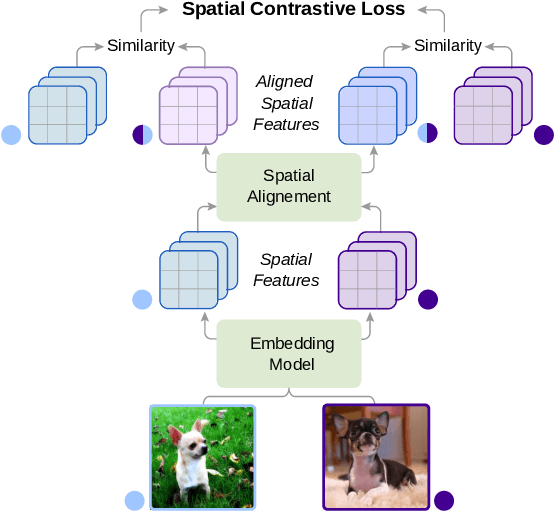
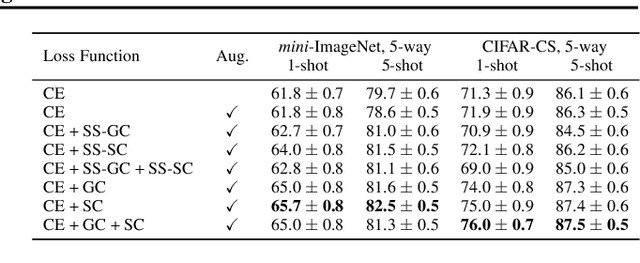
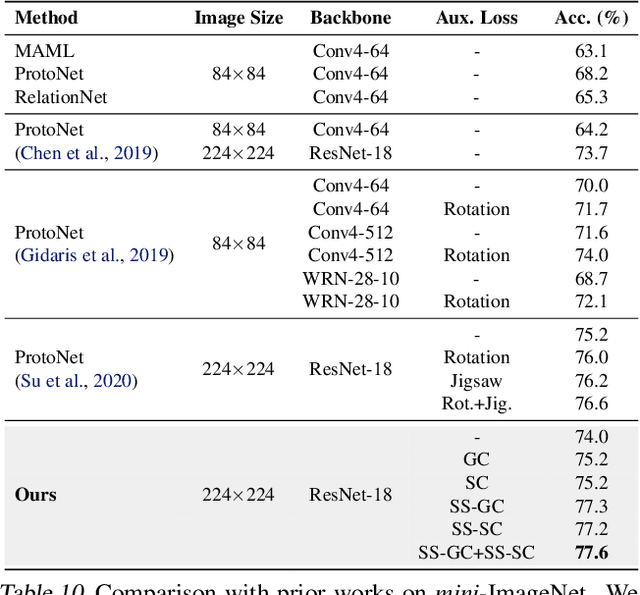

Existing few-shot classification methods rely to some degree on the cross-entropy (CE) loss to learn transferable representations that facilitate the test time adaptation to unseen classes with limited data. However, the CE loss has several shortcomings, e.g., inducing representations with excessive discrimination towards seen classes, which reduces their transferability to unseen classes and results in sub-optimal generalization. In this work, we explore contrastive learning as an additional auxiliary training objective, acting as a data-dependent regularizer to promote more general and transferable features. Instead of using the standard contrastive objective, which suppresses local discriminative features, we propose a novel attention-based spatial contrastive objective to learn locally discriminative and class-agnostic features. With extensive experiments, we show that the proposed method outperforms state-of-the-art approaches, confirming the importance of learning good and transferable embeddings for few-shot learning.
Diverse Complexity Measures for Dataset Curation in Self-driving
Jan 16, 2021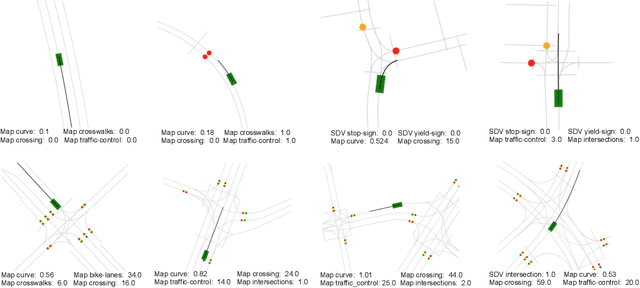
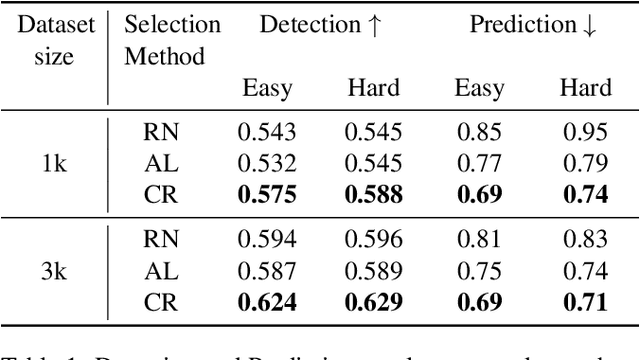

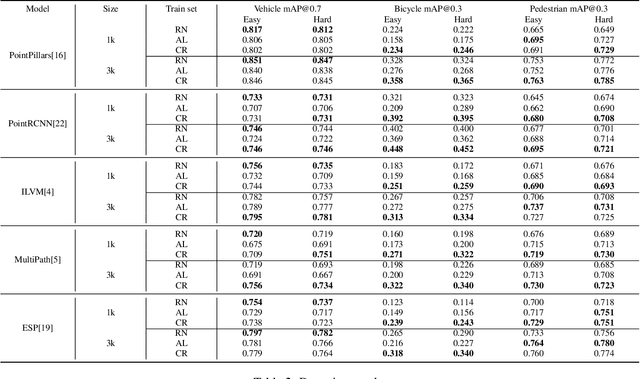
Modern self-driving autonomy systems heavily rely on deep learning. As a consequence, their performance is influenced significantly by the quality and richness of the training data. Data collecting platforms can generate many hours of raw data in a daily basis, however, it is not feasible to label everything. It is thus of key importance to have a mechanism to identify "what to label". Active learning approaches identify examples to label, but their interestingness is tied to a fixed model performing a particular task. These assumptions are not valid in self-driving, where we have to solve a diverse set of tasks (i.e., perception, and motion forecasting) and our models evolve over time frequently. In this paper we introduce a novel approach and propose a new data selection method that exploits a diverse set of criteria that quantize interestingness of traffic scenes. Our experiments on a wide range of tasks and models show that the proposed curation pipeline is able to select datasets that lead to better generalization and higher performance.
ConE: A Concurrent Edit Detection Tool for Large ScaleSoftware Development
Jan 16, 2021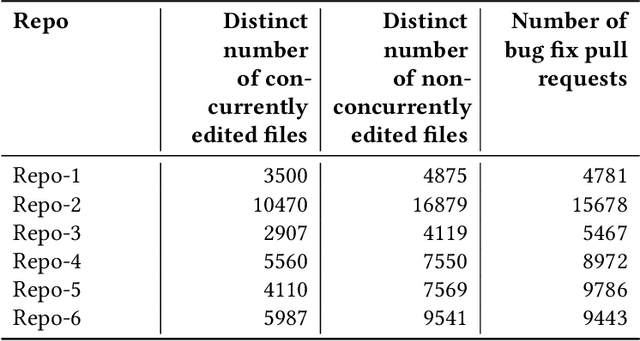
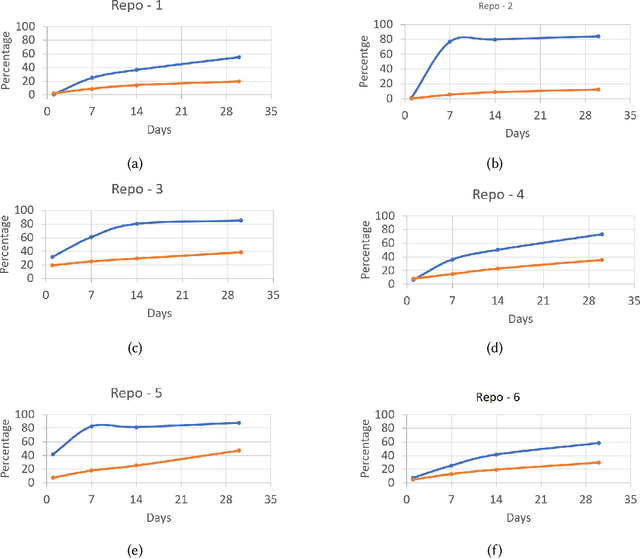

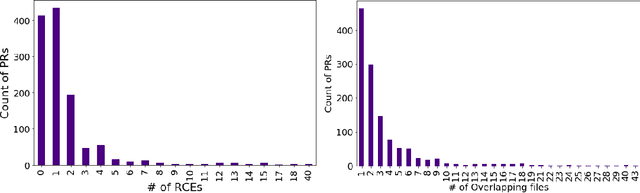
Developers from different teams or organizations, co-located or distributed, making changes to the same source code files or areas, through pull requests that are active in the same time period, is an essential part of developing complex software systems. With such a dynamically changing environment spanning several boundaries, geographic and organizational, there is little awareness about the changes that are flowing in through other active pull requests in the system leading to complex merge conflicts, hard-to-detect logical bugs or duplication of work and wasted developer productivity. In order to address this problem, we studied changes produced in eight very large repositories, in Microsoft to understand the extent of concurrent edits and their relation to subsequent bugs and bug fixes. Motivated by our findings, we developed a system called ConE (Concurrent Edit Detector) that proactively detects concurrent edits to help mitigate the problems caused by them. We present the results of ConE's deployment through early intervention techniques such as pull request notifications, by which ConE facilitates better communication among all the stakeholders participating in collaborative software development, helping avoid future problems.
Handling many conversions per click in modeling delayed feedback
Jan 06, 2021

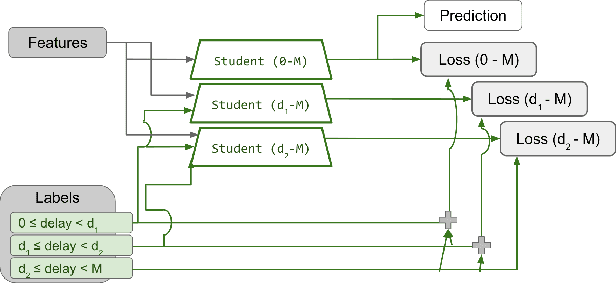
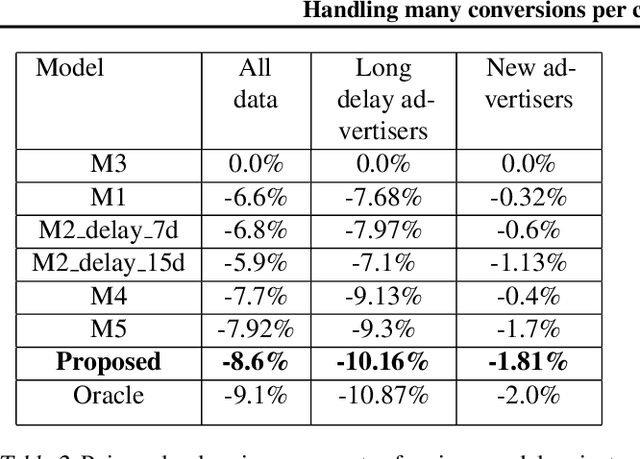
Predicting the expected value or number of post-click conversions (purchases or other events) is a key task in performance-based digital advertising. In training a conversion optimizer model, one of the most crucial aspects is handling delayed feedback with respect to conversions, which can happen multiple times with varying delay. This task is difficult, as the delay distribution is different for each advertiser, is long-tailed, often does not follow any particular class of parametric distributions, and can change over time. We tackle these challenges using an unbiased estimation model based on three core ideas. The first idea is to split the label as a sum of labels with different delay buckets, each of which trains only on mature label, the second is to use thermometer encoding to increase accuracy and reduce inference cost, and the third is to use auxiliary information to increase the stability of the model and to handle drift in the distribution.
Financial ticket intelligent recognition system based on deep learning
Oct 29, 2020

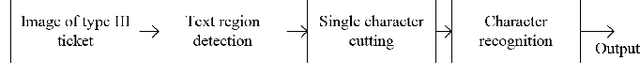

Facing the rapid growth in the issuance of financial tickets (or bills, invoices etc.), traditional manual invoice reimbursement and financial accounting system are imposing an increasing burden on financial accountants and consuming excessive manpower. To solve this problem, we proposes an iterative self-learning Framework of Financial Ticket intelligent Recognition System (FFTRS), which can support the fast iterative updating and extensibility of the algorithm model, which are the fundamental requirements for a practical financial accounting system. In addition, we designed a simple yet efficient Financial Ticket Faster Detection network (FTFDNet) and an intelligent data warehouse of financial ticket are designed to strengthen its efficiency and performance. At present, the system can recognize 194 kinds of financial tickets and has an automatic iterative optimization mechanism, which means, with the increase of application time, the types of tickets supported by the system will continue to increase, and the accuracy of recognition will continue to improve. Experimental results show that the average recognition accuracy of the system is 97.07%, and the average running time for a single ticket is 175.67ms. The practical value of the system has been tested in a commercial application, which makes a beneficial attempt for the deep learning technology in financial accounting work.
Irregular-Time Bayesian Networks
Mar 15, 2012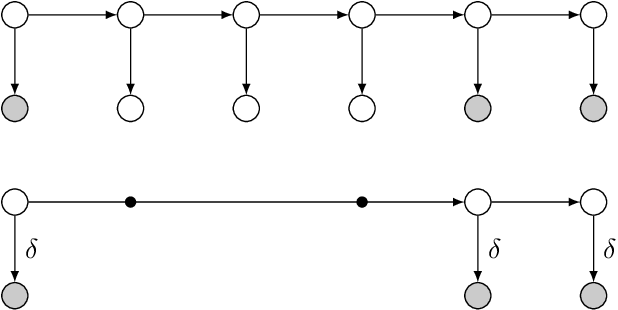
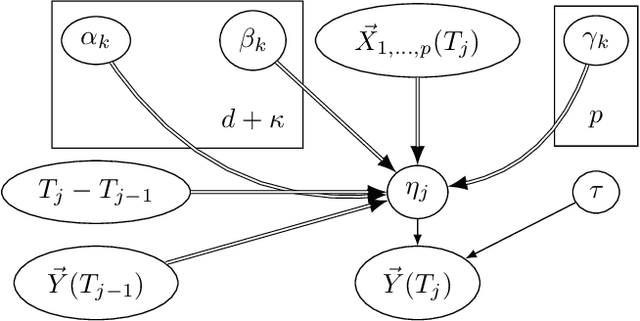
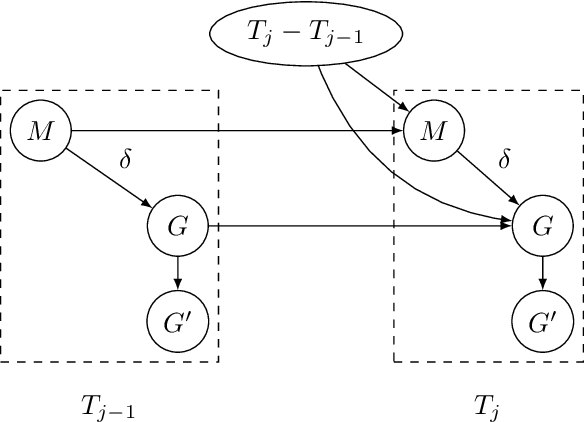
In many fields observations are performed irregularly along time, due to either measurement limitations or lack of a constant immanent rate. While discrete-time Markov models (as Dynamic Bayesian Networks) introduce either inefficient computation or an information loss to reasoning about such processes, continuous-time Markov models assume either a discrete state space (as Continuous-Time Bayesian Networks), or a flat continuous state space (as stochastic differential equations). To address these problems, we present a new modeling class called Irregular-Time Bayesian Networks (ITBNs), generalizing Dynamic Bayesian Networks, allowing substantially more compact representations, and increasing the expressivity of the temporal dynamics. In addition, a globally optimal solution is guaranteed when learning temporal systems, provided that they are fully observed at the same irregularly spaced time-points, and a semiparametric subclass of ITBNs is introduced to allow further adaptation to the irregular nature of the available data.
Big Data application in congestion detection and classification using Apache spark
Jan 16, 2021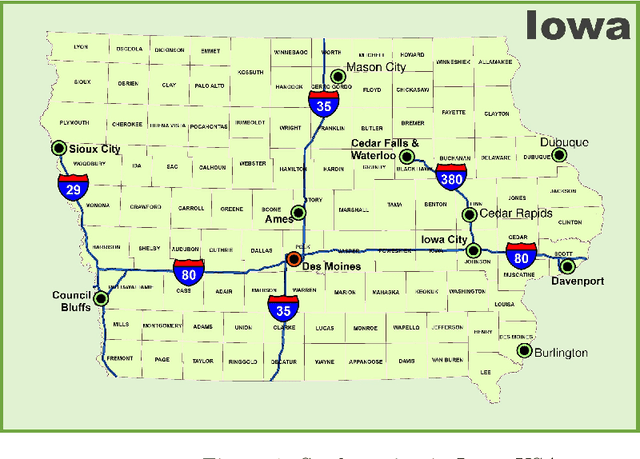

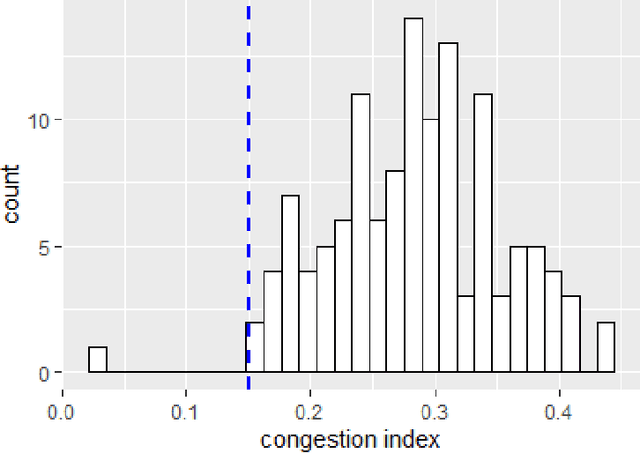
With the era of big data, an explosive amount of information is now available. This enormous increase of Big Data in both academia and industry requires large-scale data processing systems. A large body of research is behind optimizing Spark's performance to make it state of the art, a fast and general data processing system. Many science and engineering fields have advanced with Big Data analytics, such as Biology, finance, and transportation. Intelligent transportation systems (ITS) gain popularity and direct benefit from the richness of information. The objective is to improve the safety and management of transportation networks by reducing congestion and incidents. The first step toward the goal is better understanding, modeling, and detecting congestion across a network efficiently and effectively. In this study, we introduce an efficient congestion detection model. The underlying network consists of 3017 segments in I-35, I-80, I-29, and I-380 freeways with an overall length of 1570 miles and averaged (0.4-0.6) miles per segment. The result of congestion detection shows the proposed method is 90% accurate while has reduced computation time by 99.88%.
BSUV-Net 2.0: Spatio-Temporal Data Augmentations for Video-Agnostic Supervised Background Subtraction
Feb 24, 2021
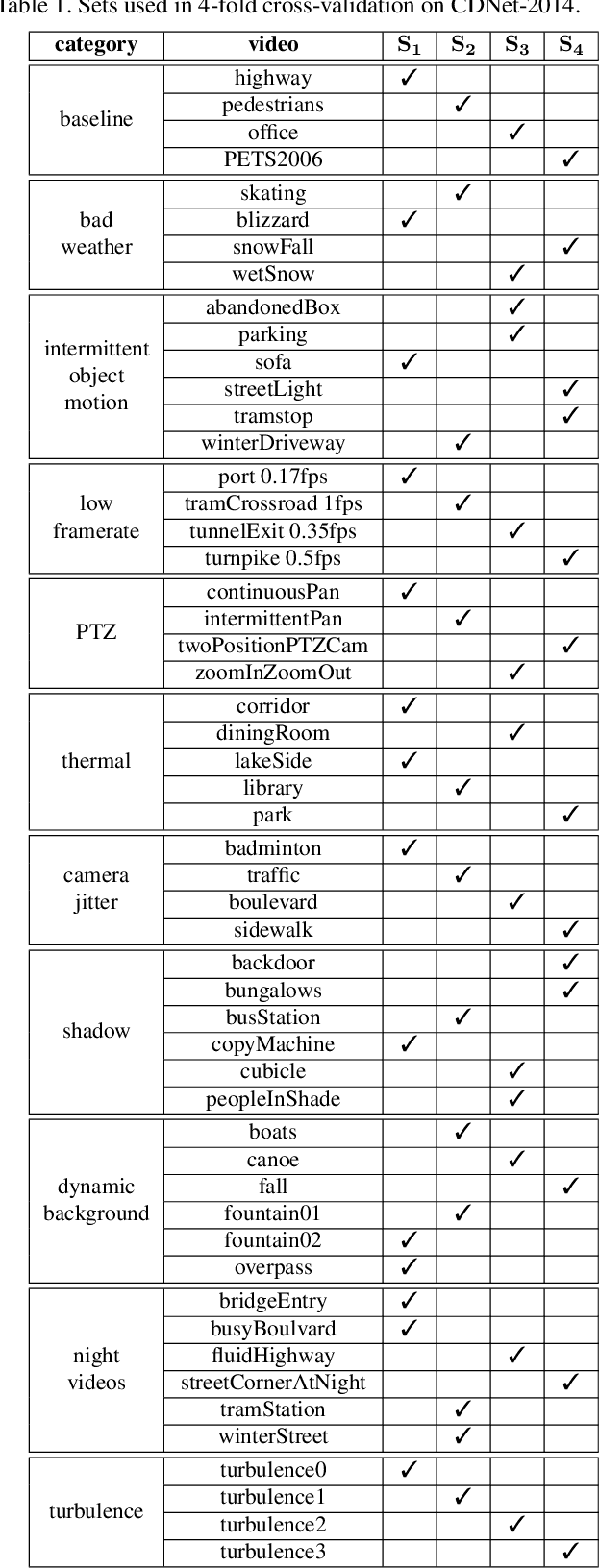
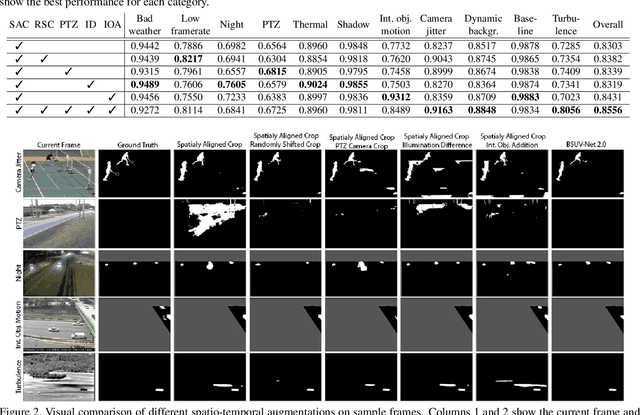
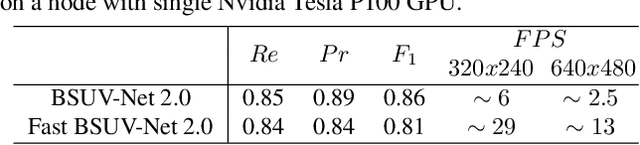
Background subtraction (BGS) is a fundamental video processing task which is a key component of many applications. Deep learning-based supervised algorithms achieve very good perforamnce in BGS, however, most of these algorithms are optimized for either a specific video or a group of videos, and their performance decreases dramatically when applied to unseen videos. Recently, several papers addressed this problem and proposed video-agnostic supervised BGS algorithms. However, nearly all of the data augmentations used in these algorithms are limited to the spatial domain and do not account for temporal variations that naturally occur in video data. In this work, we introduce spatio-temporal data augmentations and apply them to one of the leading video-agnostic BGS algorithms, BSUV-Net. We also introduce a new cross-validation training and evaluation strategy for the CDNet-2014 dataset that makes it possible to fairly and easily compare the performance of various video-agnostic supervised BGS algorithms. Our new model trained using the proposed data augmentations, named BSUV-Net 2.0, significantly outperforms state-of-the-art algorithms evaluated on unseen videos of CDNet-2014. We also evaluate the cross-dataset generalization capacity of BSUV-Net 2.0 by training it solely on CDNet-2014 videos and evaluating its performance on LASIESTA dataset. Overall, BSUV-Net 2.0 provides a ~5% improvement in the F-score over state-of-the-art methods on unseen videos of CDNet-2014 and LASIESTA datasets. Furthermore, we develop a real-time variant of our model, that we call Fast BSUV-Net 2.0, whose performance is close to the state of the art.
Sequential Place Learning: Heuristic-Free High-Performance Long-Term Place Recognition
Mar 02, 2021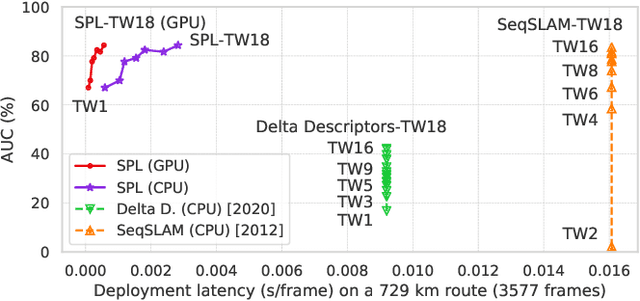
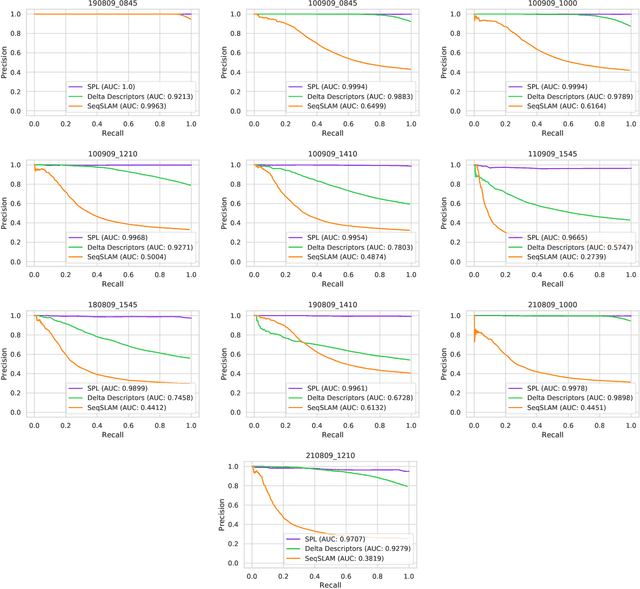
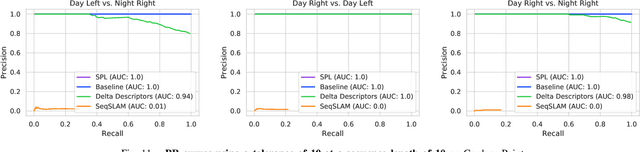
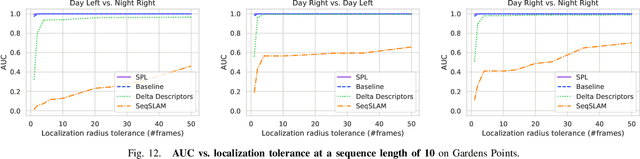
Sequential matching using hand-crafted heuristics has been standard practice in route-based place recognition for enhancing pairwise similarity results for nearly a decade. However, precision-recall performance of these algorithms dramatically degrades when searching on short temporal window (TW) lengths, while demanding high compute and storage costs on large robotic datasets for autonomous navigation research. Here, influenced by biological systems that robustly navigate spacetime scales even without vision, we develop a joint visual and positional representation learning technique, via a sequential process, and design a learning-based CNN+LSTM architecture, trainable via backpropagation through time, for viewpoint- and appearance-invariant place recognition. Our approach, Sequential Place Learning (SPL), is based on a CNN function that visually encodes an environment from a single traversal, thus reducing storage capacity, while an LSTM temporally fuses each visual embedding with corresponding positional data -- obtained from any source of motion estimation -- for direct sequential inference. Contrary to classical two-stage pipelines, e.g., match-then-temporally-filter, our network directly eliminates false-positive rates while jointly learning sequence matching from a single monocular image sequence, even using short TWs. Hence, we demonstrate that our model outperforms 15 classical methods while setting new state-of-the-art performance standards on 4 challenging benchmark datasets, where one of them can be considered solved with recall rates of 100% at 100% precision, correctly matching all places under extreme sunlight-darkness changes. In addition, we show that SPL can be up to 70x faster to deploy than classical methods on a 729 km route comprising 35,768 consecutive frames. Extensive experiments demonstrate the... Baseline code available at https://github.com/mchancan/deepseqslam
Procode: the Swiss Multilingual Solution for Automatic Coding and Recoding of Occupations and Economic Activities
Nov 30, 2020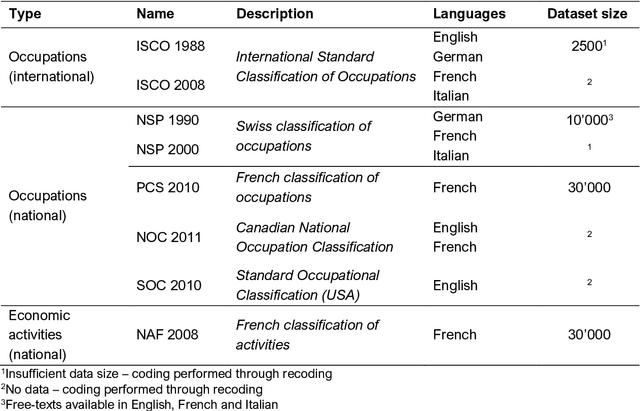
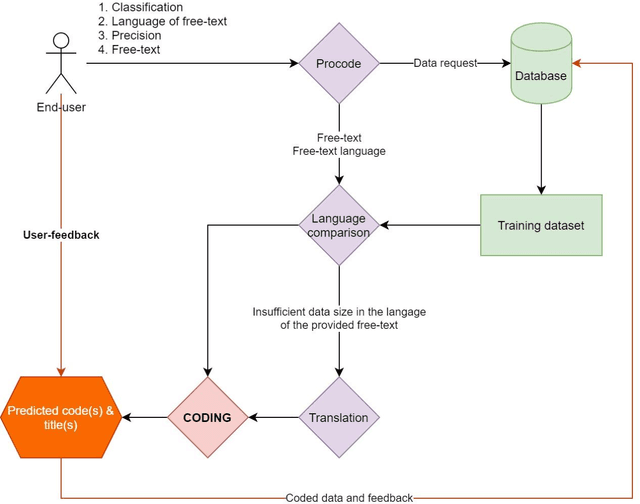
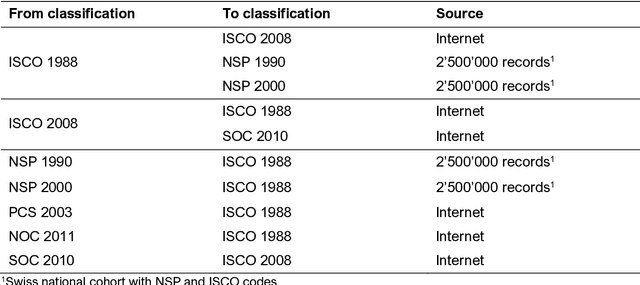
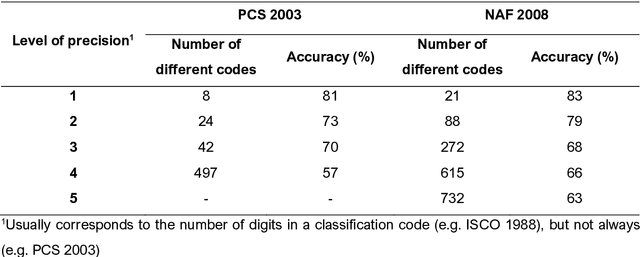
Objective. Epidemiological studies require data that are in alignment with the classifications established for occupations or economic activities. The classifications usually include hundreds of codes and titles. Manual coding of raw data may result in misclassification and be time consuming. The goal was to develop and test a web-tool, named Procode, for coding of free-texts against classifications and recoding between different classifications. Methods. Three text classifiers, i.e. Complement Naive Bayes (CNB), Support Vector Machine (SVM) and Random Forest Classifier (RFC), were investigated using a k-fold cross-validation. 30 000 free-texts with manually assigned classification codes of French classification of occupations (PCS) and French classification of activities (NAF) were available. For recoding, Procode integrated a workflow that converts codes of one classification to another according to existing crosswalks. Since this is a straightforward operation, only the recoding time was measured. Results. Among the three investigated text classifiers, CNB resulted in the best performance, where the classifier predicted accurately 57-81% and 63-83% classification codes for PCS and NAF, respectively. SVM lead to somewhat lower results (by 1-2%), while RFC coded accurately up to 30% of the data. The coding operation required one minute per 10 000 records, while the recoding was faster, i.e. 5-10 seconds. Conclusion. The algorithm integrated in Procode showed satisfactory performance, since the tool had to assign the right code by choosing between 500-700 different choices. Based on the results, the authors decided to implement CNB in Procode. In future, if another classifier shows a superior performance, an update will include the required modifications.