 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On a Bernoulli Autoregression Framework for Link Discovery and Prediction
Jul 23, 2020
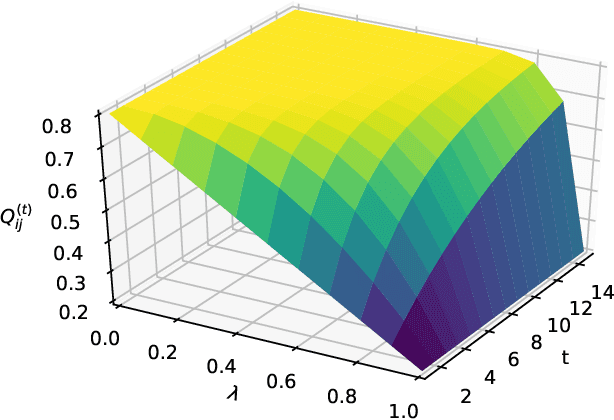

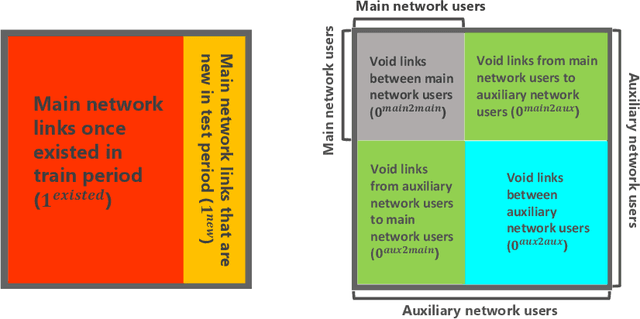

We present a dynamic prediction framework for binary sequences that is based on a Bernoulli generalization of the auto-regressive process. Our approach lends itself easily to variants of the standard link prediction problem for a sequence of time dependent networks. Focusing on this dynamic network link prediction/recommendation task, we propose a novel problem that exploits additional information via a much larger sequence of auxiliary networks and has important real-world relevance. To allow discovery of links that do not exist in the available data, our model estimation framework introduces a regularization term that presents a trade-off between the conventional link prediction and this discovery task. In contrast to existing work our stochastic gradient based estimation approach is highly efficient and can scale to networks with millions of nodes. We show extensive empirical results on both actual product-usage based time dependent networks and also present results on a Reddit based data set of time dependent sentiment sequences.
Learning causal Bayes networks using interventional path queries in polynomial time and sample complexity
Feb 22, 2018
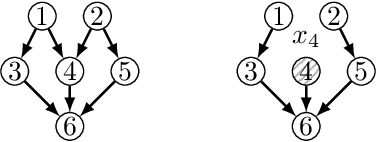
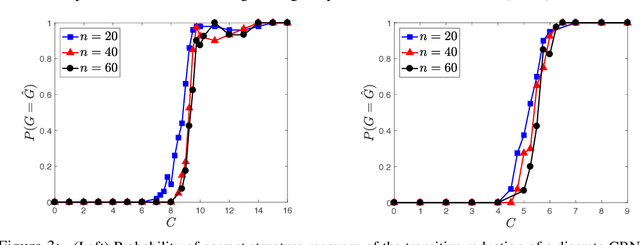
Causal discovery from empirical data is a fundamental problem in many scientific domains. Observational data allows for identifiability only up to Markov equivalence class. In this paper we first propose a polynomial time algorithm for learning the exact correctly-oriented structure of the transitive reduction of any causal Bayesian networks with high probability, by using interventional path queries. Each path query takes as input an origin node and a target node, and answers whether there is a directed path from the origin to the target. This is done by intervening the origin node and observing samples from the target node. We theoretically show the logarithmic sample complexity for the size of interventional data per path query, for continuous and discrete networks. We further extend our work to learn the transitive edges using logarithmic sample complexity (albeit in time exponential in the maximum number of parents for discrete networks). This allows us to learn the full network. We also provide an analysis of imperfect interventions.
Compliant Fins for Locomotion in Granular Media
Jan 16, 2021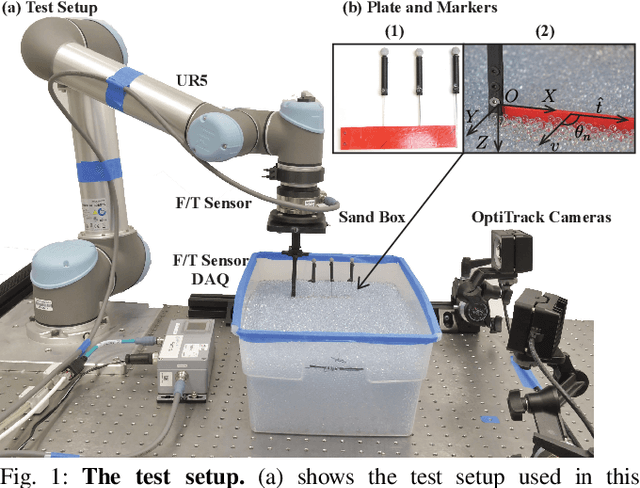
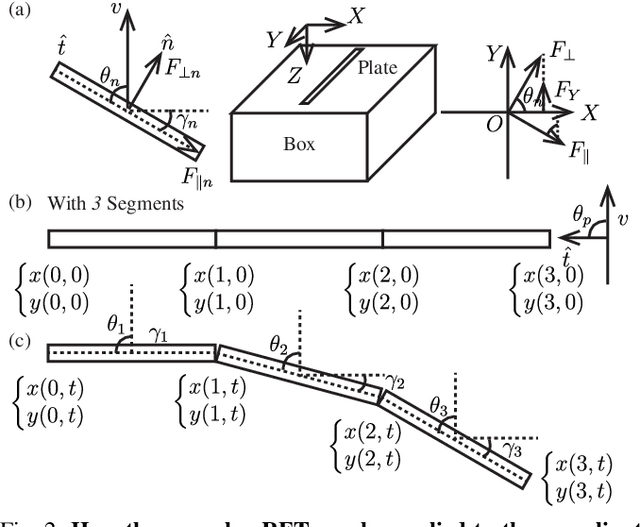
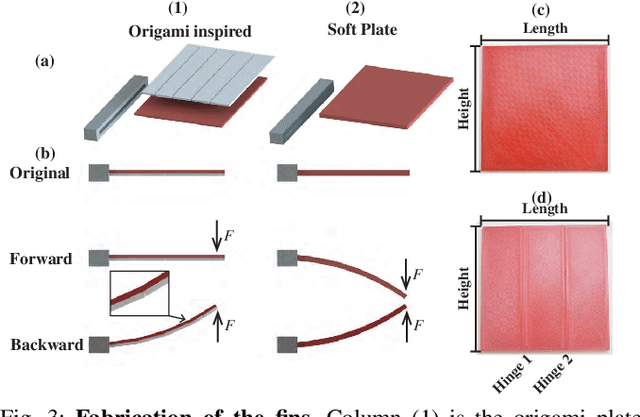
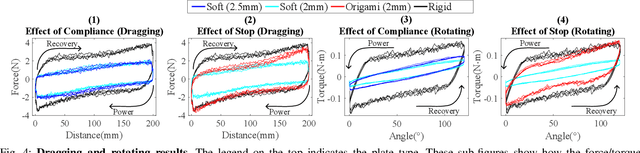
In this paper, we present an approach to study the behavior of compliant plates in granular media and optimize the performance of a robot that utilizes this technique for mobility. From previous work and fundamental tests on thin plate force generation inside granular media, we introduce an origami-inspired mechanism with non-linear compliance in the joints that can be used in granular propulsion. This concept utilizes one-sided joint limits to create an asymmetric gait cycle that avoids more complicated alternatives often found in other swimming/digging robots. To analyze its locomotion as well as its shape and propulsive force, we utilize granular Resistive Force Theory (RFT) as a starting point. Adding compliance to this theory enables us to predict the time-based evolution of compliant plates when they are dragged and rotated. It also permits more rational design of swimming robots where fin design variables may be optimized against the characteristics of the granular medium. This is done using a Python-based dynamic simulation library to model the deformation of the plates and optimize aspects of the robot's gait. Finally, we prototype and test robot with a gait optimized using the modelling techniques mentioned above.
Exact Tests for Offline Changepoint Detection in Multichannel Binary and Count Data with Application to Networks
Aug 20, 2020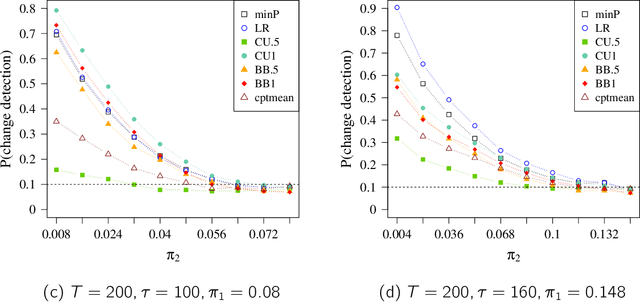
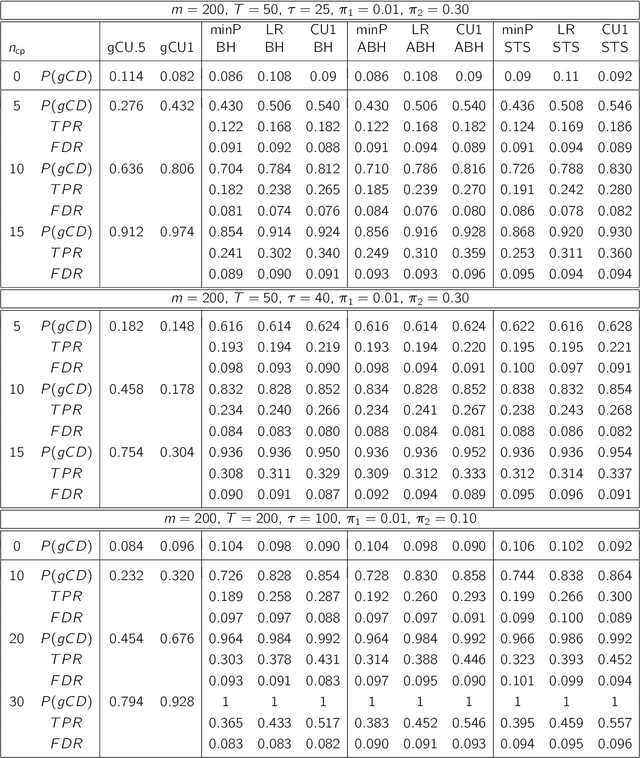
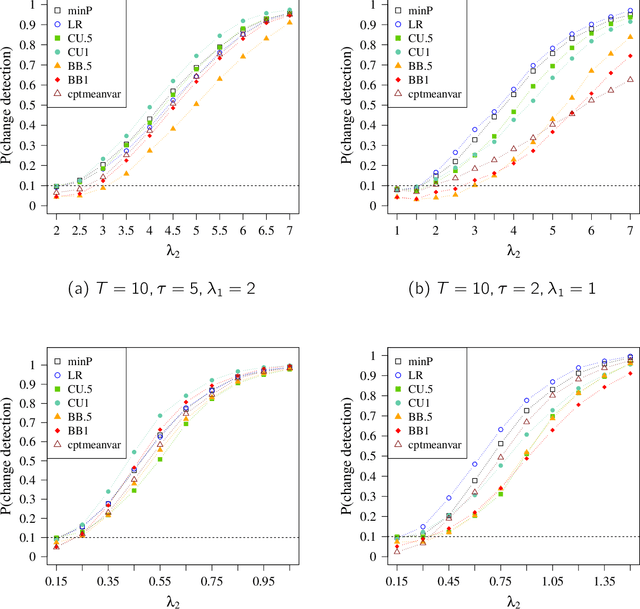
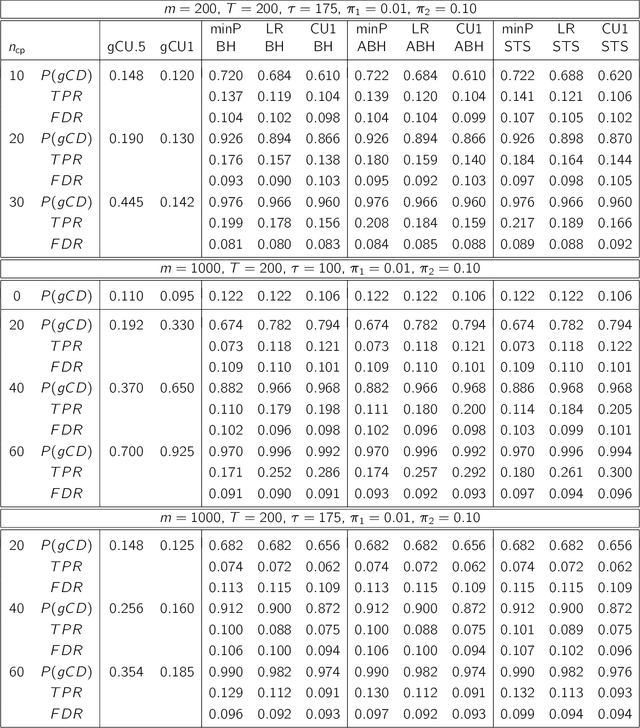
We consider offline detection of a single changepoint in binary and count time-series. We compare exact tests based on the cumulative sum (CUSUM) and the likelihood ratio (LR) statistics, and a new proposal that combines exact two-sample conditional tests with multiplicity correction, against standard asymptotic tests based on the Brownian bridge approximation to the CUSUM statistic. We see empirically that the exact tests are much more powerful in situations where normal approximations driving asymptotic tests are not trustworthy: (i) small sample settings; (ii) sparse parametric settings; (iii) time-series with changepoint near the boundary. We also consider a multichannel version of the problem, where channels can have different changepoints. Controlling the False Discovery Rate (FDR), we simultaneously detect changes in multiple channels. This "local" approach is shown to be more advantageous than multivariate global testing approaches when the number of channels with changepoints is much smaller than the total number of channels. As a natural application, we consider network-valued time-series and use our approach with (a) edges as binary channels and (b) node-degrees or other local subgraph statistics as count channels. The local testing approach is seen to be much more informative than global network changepoint algorithms.
Rule-Based Approach for Party-Based Sentiment Analysis in Legal Opinion Texts
Nov 13, 2020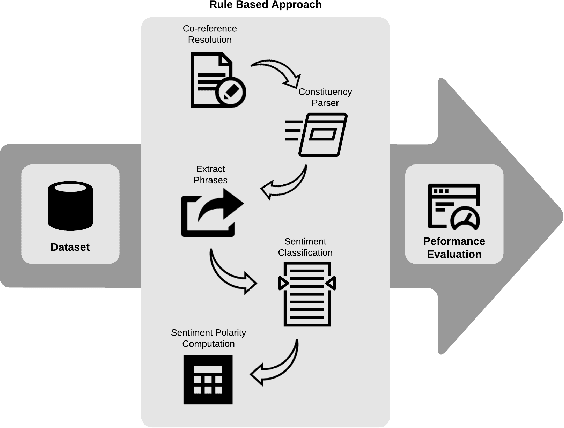
A document which elaborates opinions and arguments related to the previous court cases is known as a legal opinion text. Lawyers and legal officials have to spend considerable effort and time to obtain the required information manually from those documents when dealing with new legal cases. Hence, it provides much convenience to those individuals if there is a way to automate the process of extracting information from legal opinion texts. Party-based sentiment analysis will play a key role in the automation system by identifying opinion values with respect to each legal parties in legal texts.
"Is depression related to cannabis?": A knowledge-infused model for Entity and Relation Extraction with Limited Supervision
Feb 01, 2021
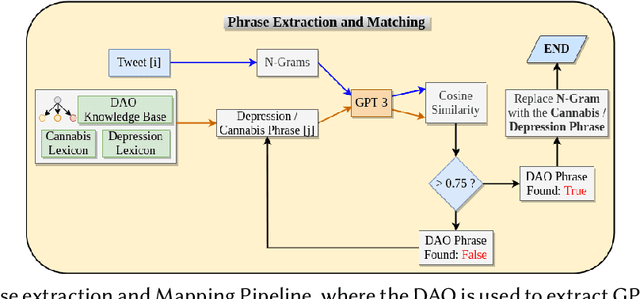
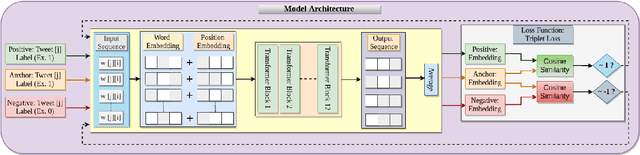
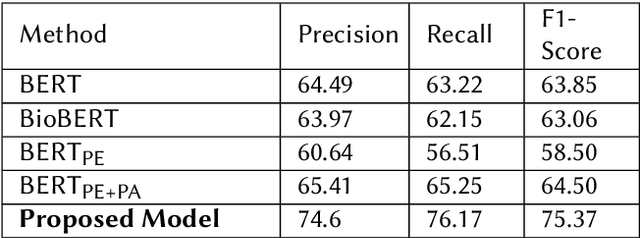
With strong marketing advocacy of the benefits of cannabis use for improved mental health, cannabis legalization is a priority among legislators. However, preliminary scientific research does not conclusively associate cannabis with improved mental health. In this study, we explore the relationship between depression and consumption of cannabis in a targeted social media corpus involving personal use of cannabis with the intent to derive its potential mental health benefit. We use tweets that contain an association among three categories annotated by domain experts - Reason, Effect, and Addiction. The state-of-the-art Natural Langauge Processing techniques fall short in extracting these relationships between cannabis phrases and the depression indicators. We seek to address the limitation by using domain knowledge; specifically, the Drug Abuse Ontology for addiction augmented with Diagnostic and Statistical Manual of Mental Disorders lexicons for mental health. Because of the lack of annotations due to the limited availability of the domain experts' time, we use supervised contrastive learning in conjunction with GPT-3 trained on a vast corpus to achieve improved performance even with limited supervision. Experimental results show that our method can significantly extract cannabis-depression relationships better than the state-of-the-art relation extractor. High-quality annotations can be provided using a nearest neighbor approach using the learned representations that can be used by the scientific community to understand the association between cannabis and depression better.
A Style-Aware Content Loss for Real-time HD Style Transfer
Jul 28, 2018
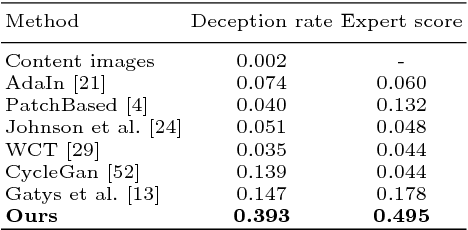


Recently, style transfer has received a lot of attention. While much of this research has aimed at speeding up processing, the approaches are still lacking from a principled, art historical standpoint: a style is more than just a single image or an artist, but previous work is limited to only a single instance of a style or shows no benefit from more images. Moreover, previous work has relied on a direct comparison of art in the domain of RGB images or on CNNs pre-trained on ImageNet, which requires millions of labeled object bounding boxes and can introduce an extra bias, since it has been assembled without artistic consideration. To circumvent these issues, we propose a style-aware content loss, which is trained jointly with a deep encoder-decoder network for real-time, high-resolution stylization of images and videos. We propose a quantitative measure for evaluating the quality of a stylized image and also have art historians rank patches from our approach against those from previous work. These and our qualitative results ranging from small image patches to megapixel stylistic images and videos show that our approach better captures the subtle nature in which a style affects content.
A Tiny CNN Architecture for Medical Face Mask Detection for Resource-Constrained Endpoints
Dec 22, 2020
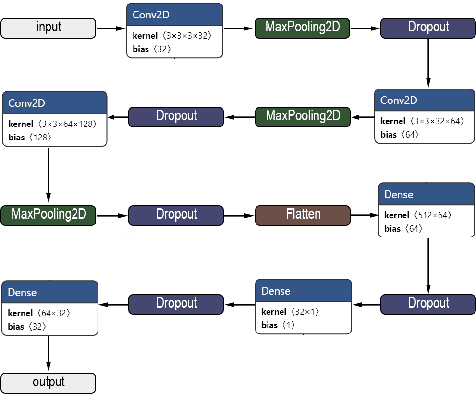

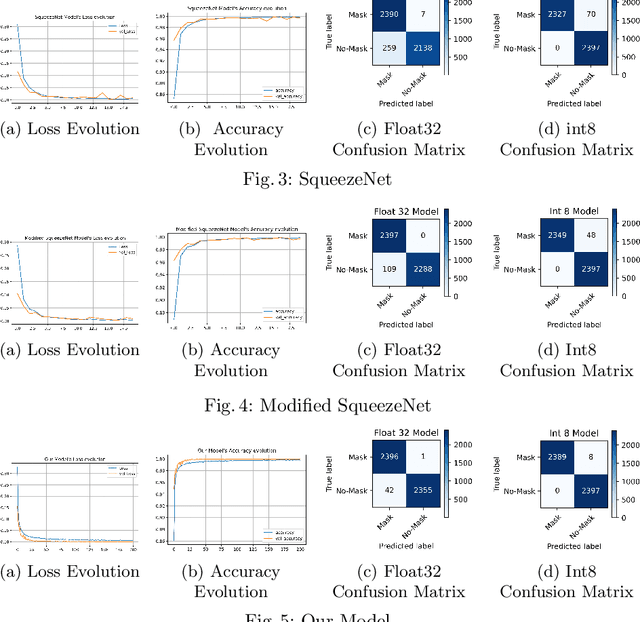
The world is going through one of the most dangerous pandemics of all time with the rapid spread of the novel coronavirus (COVID-19). According to the World Health Organisation, the most effective way to thwart the transmission of coronavirus is to wear medical face masks. Monitoring the use of face masks in public places has been a challenge because manual monitoring could be unsafe. This paper proposes an architecture for detecting medical face masks for deployment on resource-constrained endpoints having extremely low memory footprints. A small development board with an ARM Cortex-M7 microcontroller clocked at 480 Mhz and having just 496 KB of framebuffer RAM, has been used for the deployment of the model. Using the TensorFlow Lite framework, the model is quantized to further reduce its size. The proposed model is 138 KB post quantization and runs at the inference speed of 30 FPS.
An anatomically-informed 3D CNN for brain aneurysm classification with weak labels
Nov 27, 2020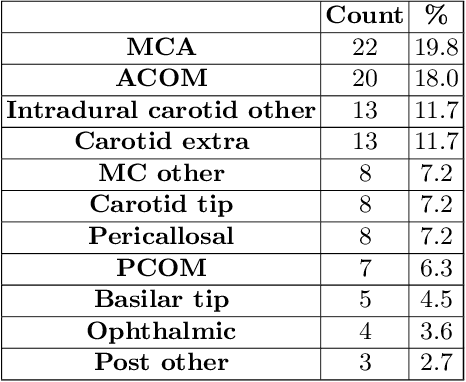
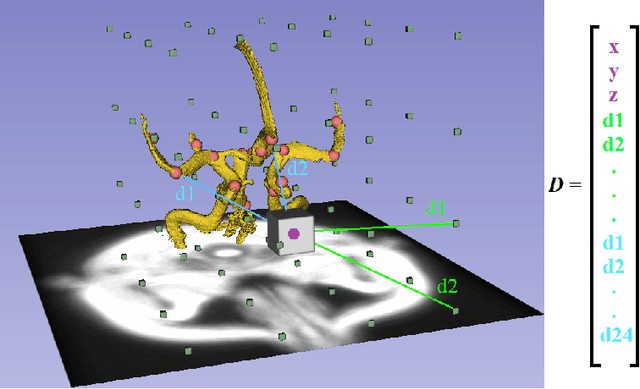
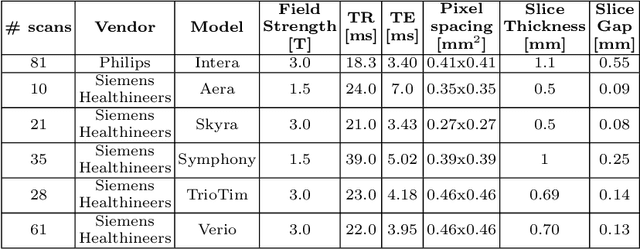
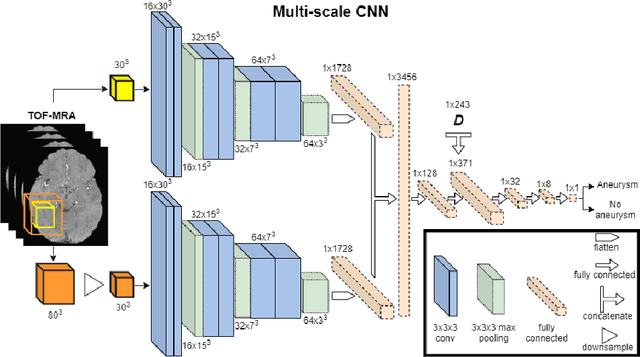
A commonly adopted approach to carry out detection tasks in medical imaging is to rely on an initial segmentation. However, this approach strongly depends on voxel-wise annotations which are repetitive and time-consuming to draw for medical experts. An interesting alternative to voxel-wise masks are so-called "weak" labels: these can either be coarse or oversized annotations that are less precise, but noticeably faster to create. In this work, we address the task of brain aneurysm detection as a patch-wise binary classification with weak labels, in contrast to related studies that rather use supervised segmentation methods and voxel-wise delineations. Our approach comes with the non-trivial challenge of the data set creation: as for most focal diseases, anomalous patches (with aneurysm) are outnumbered by those showing no anomaly, and the two classes usually have different spatial distributions. To tackle this frequent scenario of inherently imbalanced, spatially skewed data sets, we propose a novel, anatomically-driven approach by using a multi-scale and multi-input 3D Convolutional Neural Network (CNN). We apply our model to 214 subjects (83 patients, 131 controls) who underwent Time-Of-Flight Magnetic Resonance Angiography (TOF-MRA) and presented a total of 111 unruptured cerebral aneurysms. We compare two strategies for negative patch sampling that have an increasing level of difficulty for the network and we show how this choice can strongly affect the results. To assess whether the added spatial information helps improving performances, we compare our anatomically-informed CNN with a baseline, spatially-agnostic CNN. When considering the more realistic and challenging scenario including vessel-like negative patches, the former model attains the highest classification results (accuracy$\simeq$95\%, AUROC$\simeq$0.95, AUPR$\simeq$0.71), thus outperforming the baseline.
Once Quantized for All: Progressively Searching for Quantized Efficient Models
Oct 09, 2020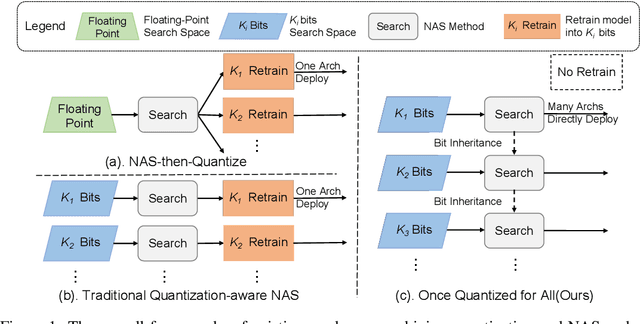

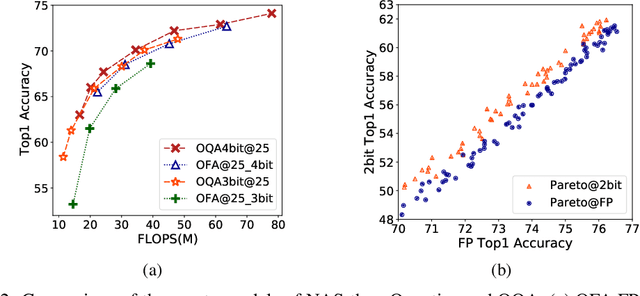
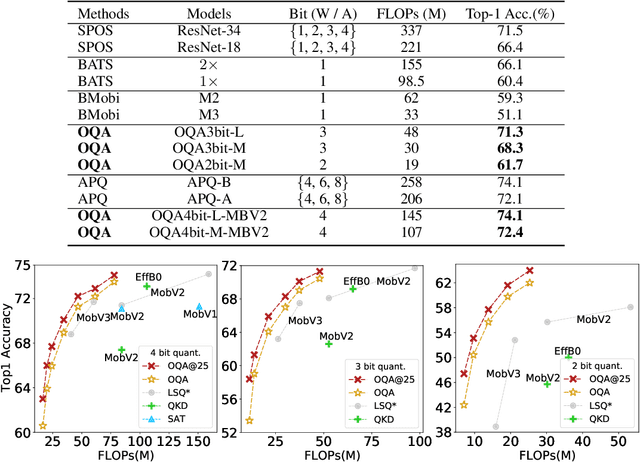
Automatic search of Quantized Neural Networks has attracted a lot of attention. However, the existing quantization aware Neural Architecture Search (NAS) approaches inherit a two-stage search-retrain schema, which is not only time-consuming but also adversely affected by the unreliable ranking of architectures during the search. To avoid the undesirable effect of the search-retrain schema, we present Once Quantized for All (OQA), a novel framework that searches for quantized efficient models and deploys their quantized weights at the same time without additional post-process. While supporting a huge architecture search space, our OQA can produce a series of ultra-low bit-width(e.g. 4/3/2 bit) quantized efficient models. A progressive bit inheritance procedure is introduced to support ultra-low bit-width. Our discovered model family, OQANets, achieves a new state-of-the-art (SOTA) on quantized efficient models compared with various quantization methods and bit-widths. In particular, OQA2bit-L achieves 64.0% ImageNet Top-1 accuracy, outperforming its 2-bit counterpart EfficientNet-B0@QKD by a large margin of 14% using 30% less computation budget. Code is available at https://github.com/LaVieEnRoseSMZ/OQA.