 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Accelerated Sim-to-Real Deep Reinforcement Learning: Learning Collision Avoidance from Human Player
Feb 23, 2021
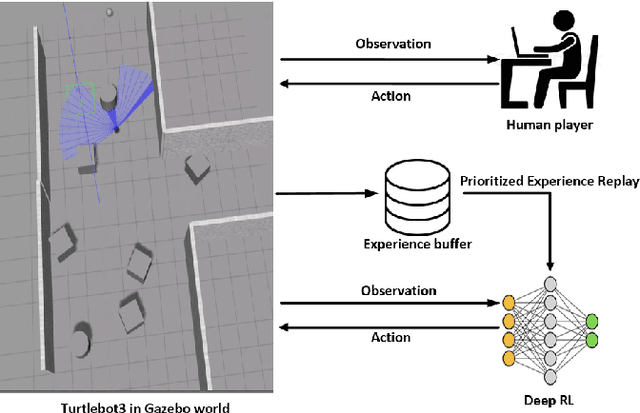
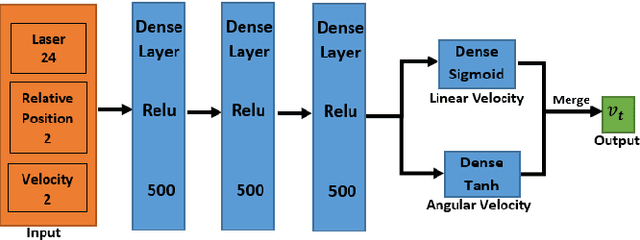
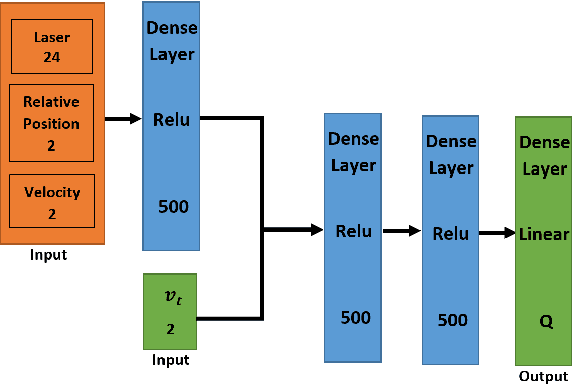
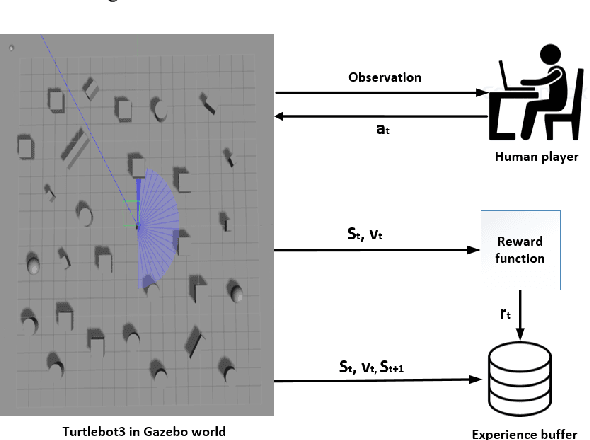
This paper presents a sensor-level mapless collision avoidance algorithm for use in mobile robots that map raw sensor data to linear and angular velocities and navigate in an unknown environment without a map. An efficient training strategy is proposed to allow a robot to learn from both human experience data and self-exploratory data. A game format simulation framework is designed to allow the human player to tele-operate the mobile robot to a goal and human action is also scored using the reward function. Both human player data and self-playing data are sampled using prioritized experience replay algorithm. The proposed algorithm and training strategy have been evaluated in two different experimental configurations: \textit{Environment 1}, a simulated cluttered environment, and \textit{Environment 2}, a simulated corridor environment, to investigate the performance. It was demonstrated that the proposed method achieved the same level of reward using only 16\% of the training steps required by the standard Deep Deterministic Policy Gradient (DDPG) method in Environment 1 and 20\% of that in Environment 2. In the evaluation of 20 random missions, the proposed method achieved no collision in less than 2~h and 2.5~h of training time in the two Gazebo environments respectively. The method also generated smoother trajectories than DDPG. The proposed method has also been implemented on a real robot in the real-world environment for performance evaluation. We can confirm that the trained model with the simulation software can be directly applied into the real-world scenario without further fine-tuning, further demonstrating its higher robustness than DDPG. The video and code are available: https://youtu.be/BmwxevgsdGc https://github.com/hanlinniu/turtlebot3_ddpg_collision_avoidance
Binary Segmentation of Seismic Facies Using Encoder-Decoder Neural Networks
Nov 15, 2020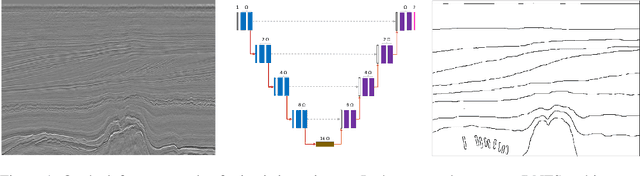
The interpretation of seismic data is vital for characterizing sediments' shape in areas of geological study. In seismic interpretation, deep learning becomes useful for reducing the dependence on handcrafted facies segmentation geometry and the time required to study geological areas. This work presents a Deep Neural Network for Facies Segmentation (DNFS) to obtain state-of-the-art results for seismic facies segmentation. DNFS is trained using a combination of cross-entropy and Jaccard loss functions. Our results show that DNFS obtains highly detailed predictions for seismic facies segmentation using fewer parameters than StNet and U-Net.
A Generic Object Re-identification System for Short Videos
Feb 10, 2021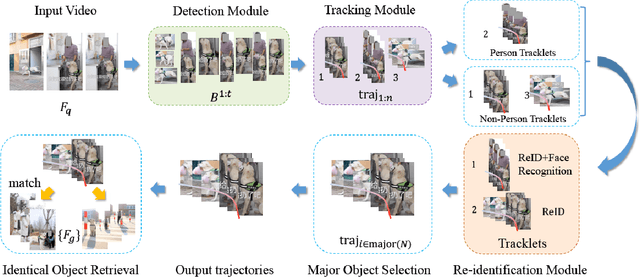
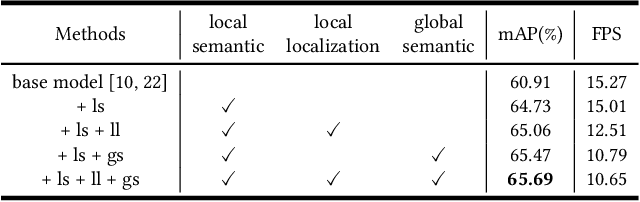
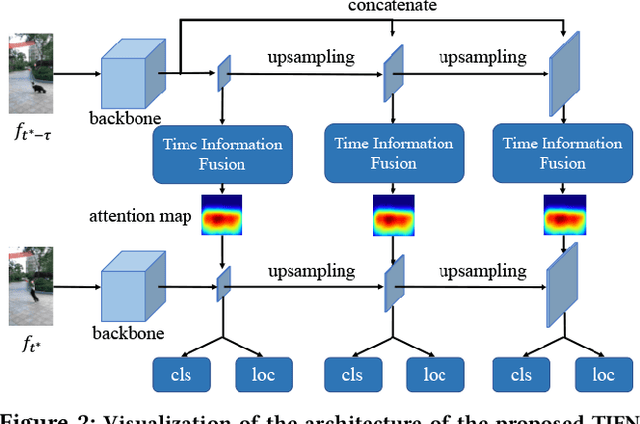

Short video applications like TikTok and Kwai have been a great hit recently. In order to meet the increasing demands and take full advantage of visual information in short videos, objects in each short video need to be located and analyzed as an upstream task. A question is thus raised -- how to improve the accuracy and robustness of object detection, tracking, and re-identification across tons of short videos with hundreds of categories and complicated visual effects (VFX). To this end, a system composed of a detection module, a tracking module and a generic object re-identification module, is proposed in this paper, which captures features of major objects from short videos. In particular, towards the high efficiency demands in practical short video application, a Temporal Information Fusion Network (TIFN) is proposed in the object detection module, which shows comparable accuracy and improved time efficiency to the state-of-the-art video object detector. Furthermore, in order to mitigate the fragmented issue of tracklets in short videos, a Cross-Layer Pointwise Siamese Network (CPSN) is proposed in the tracking module to enhance the robustness of the appearance model. Moreover, in order to evaluate the proposed system, two challenge datasets containing real-world short videos are built for video object trajectory extraction and generic object re-identification respectively. Overall, extensive experiments for each module and the whole system demonstrate the effectiveness and efficiency of our system.
Ensemble Prediction of Time to Event Outcomes with Competing Risks: A Case Study of Surgical Complications in Crohn's Disease
Feb 07, 2019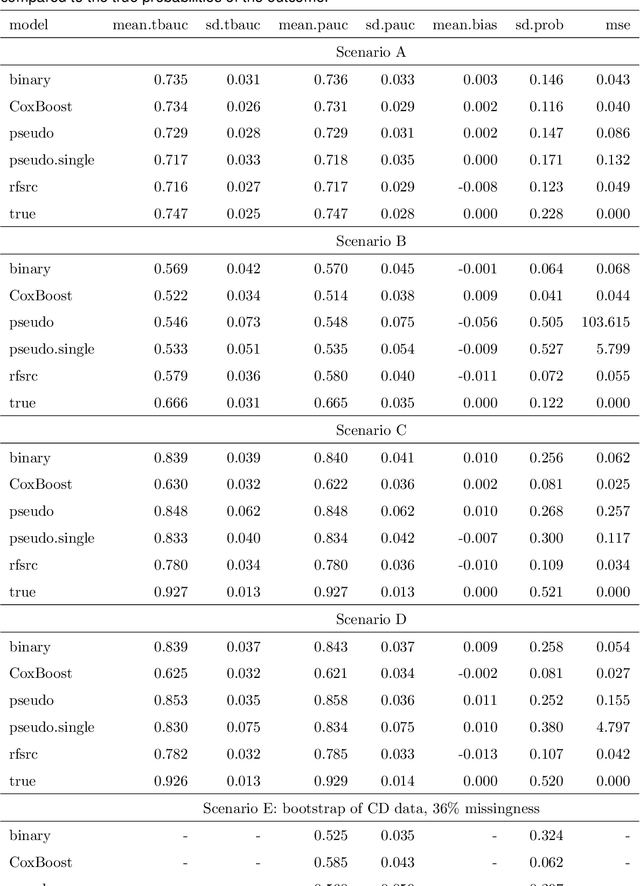
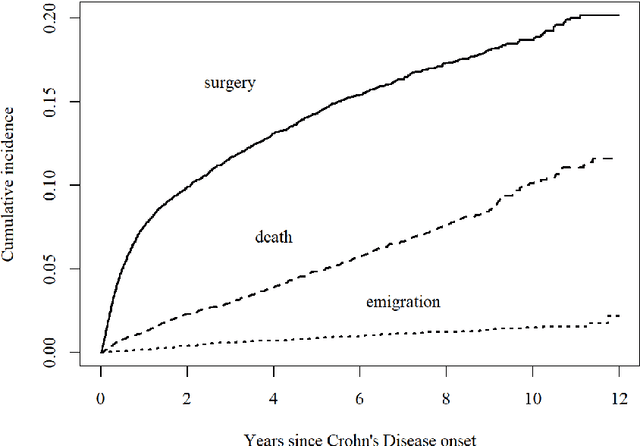
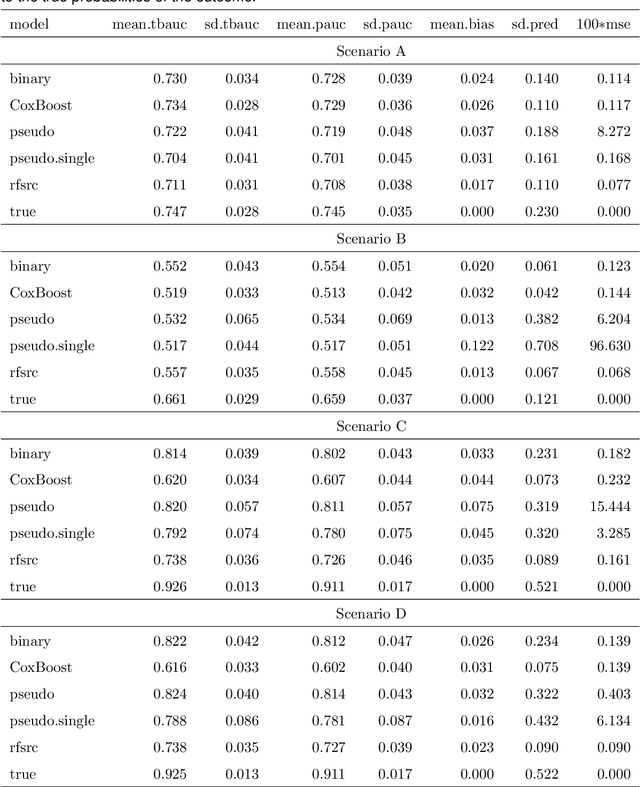
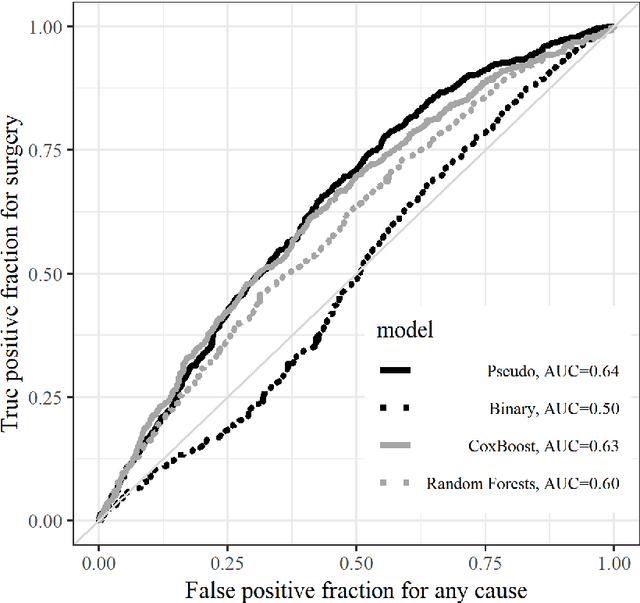
We develop a novel algorithm to predict the occurrence of major abdominal surgery within 5 years following Crohn's disease diagnosis using a panel of 29 baseline covariates from the Swedish population registers. We model pseudo-observations based on the Aalen-Johansen estimator of the cause-specific cumulative incidence with an ensemble of modern machine learning approaches. Pseudo-observation pre-processing easily extends all existing or new machine learning procedures to right-censored event history data. We propose pseudo-observation based estimators for the area under the time varying ROC curve, for optimizing the ensemble, and the predictiveness curve, for evaluating and summarizing predictive performance.
A new automatic approach to seed image analysis: From acquisition to segmentation
Dec 11, 2020



Image Analysis offers a new tool for classifying vascular plant species based on the morphological and colorimetric features of the seeds, and has made significant contributions in systematic studies. However, in order to extract the morphological and colorimetric features, it is necessary to segment the image containing the samples to be analysed. This stage represents one of the most challenging steps in image processing, as it is difficult to separate uniform and homogeneous objects from the background. In this paper, we present a new, open source plugin for the automatic segmentation of an image of a seed sample. This plugin was written in Java to allow it to work with ImageJ open source software. The new plugin was tested on a total of 3,386 seed samples from 120 species belonging to the Fabaceae family. Digital images were acquired using a flatbed scanner. In order to test the efficacy of this approach in terms of identifying the edges of objects and separating them from the background, each sample was scanned using four different hues of blue for the background, and a total of 480 digital images were elaborated. The performance of the new plugin was compared with a method based on double image acquisition (with a black and white background) using the same seed samples, in which images were manually segmented using the Core ImageJ plugin. The results showed that the new plugin was able to segment all of the digital images without generating any object detection errors. In addition, the new plugin was able to segment images within an average of 0.02 s, while the average time for execution with the manual method was 63 s. This new open source plugin is proven to be able to work on a single image, and to be highly efficient in terms of time and segmentation when working with large numbers of images and a wide diversity of shapes.
Reinforcement Learning for Optimized Beam Training in Multi-Hop Terahertz Communications
Feb 10, 2021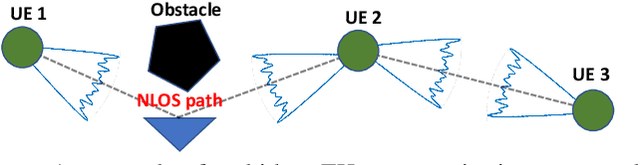
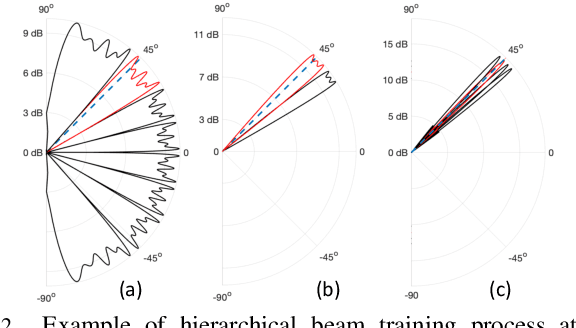
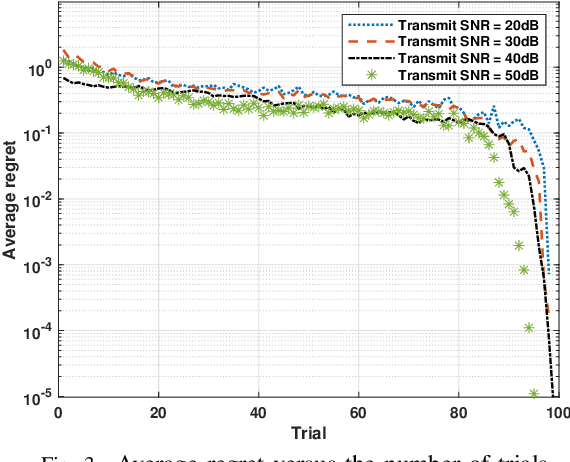
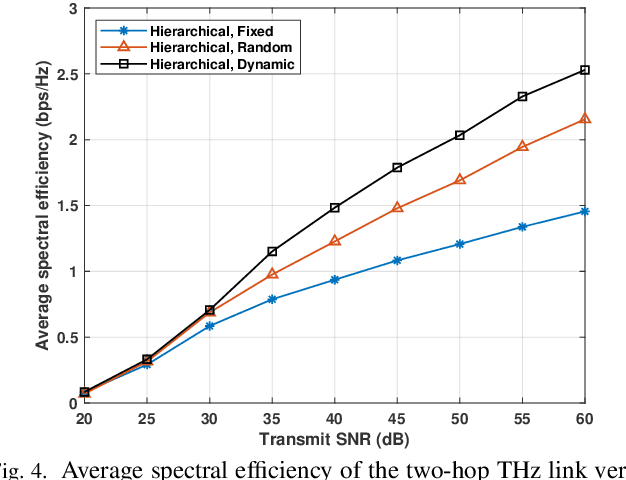
Communication at terahertz (THz) frequency bands is a promising solution for achieving extremely high data rates in next-generation wireless networks. While the THz communication is conventionally envisioned for short-range wireless applications due to the high atmospheric absorption at THz frequencies, multi-hop directional transmissions can be enabled to extend the communication range. However, to realize multi-hop THz communications, conventional beam training schemes, such as exhaustive search or hierarchical methods with a fixed number of training levels, can lead to a very large time overhead. To address this challenge, in this paper, a novel hierarchical beam training scheme with dynamic training levels is proposed to optimize the performance of multi-hop THz links. In fact, an optimization problem is formulated to maximize the overall spectral efficiency of the multi-hop THz link by dynamically and jointly selecting the number of beam training levels across all the constituent single-hop links. To solve this problem in presence of unknown channel state information, noise, and path loss, a new reinforcement learning solution based on the multi-armed bandit (MAB) is developed. Simulation results show the fast convergence of the proposed scheme in presence of random channels and noise. The results also show that the proposed scheme can yield up to 75% performance gain, in terms of spectral efficiency, compared to the conventional hierarchical beam training with a fixed number of training levels.
A General Framework Combining Generative Adversarial Networks and Mixture Density Networks for Inverse Modeling in Microstructural Materials Design
Jan 26, 2021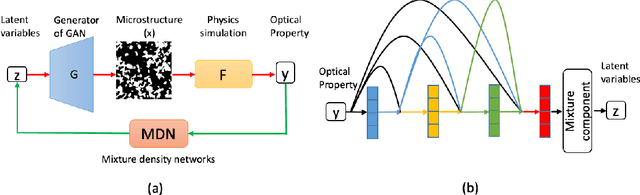
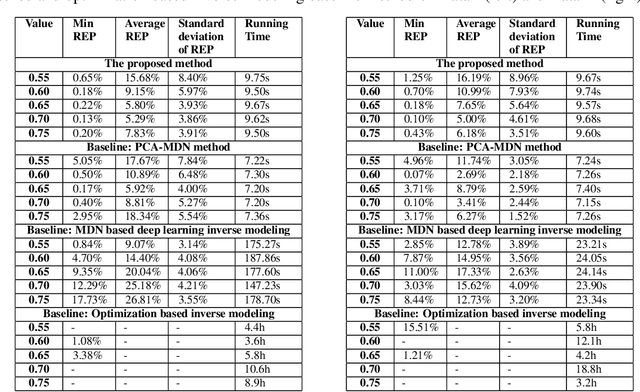

Microstructural materials design is one of the most important applications of inverse modeling in materials science. Generally speaking, there are two broad modeling paradigms in scientific applications: forward and inverse. While the forward modeling estimates the observations based on known parameters, the inverse modeling attempts to infer the parameters given the observations. Inverse problems are usually more critical as well as difficult in scientific applications as they seek to explore the parameters that cannot be directly observed. Inverse problems are used extensively in various scientific fields, such as geophysics, healthcare and materials science. However, it is challenging to solve inverse problems, because they usually need to learn a one-to-many non-linear mapping, and also require significant computing time, especially for high-dimensional parameter space. Further, inverse problems become even more difficult to solve when the dimension of input (i.e. observation) is much lower than that of output (i.e. parameters). In this work, we propose a framework consisting of generative adversarial networks and mixture density networks for inverse modeling, and it is evaluated on a materials science dataset for microstructural materials design. Compared with baseline methods, the results demonstrate that the proposed framework can overcome the above-mentioned challenges and produce multiple promising solutions in an efficient manner.
Rosella: A Self-Driving Distributed Scheduler for Heterogeneous Clusters
Oct 28, 2020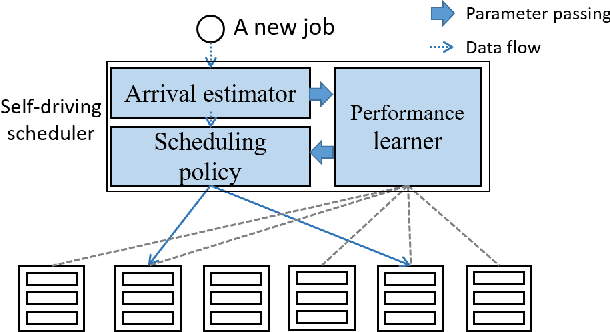
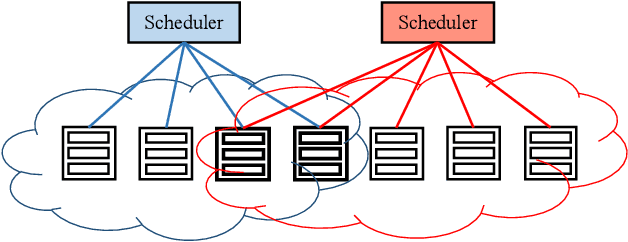
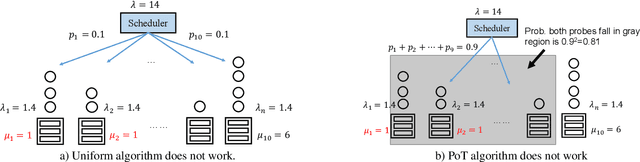
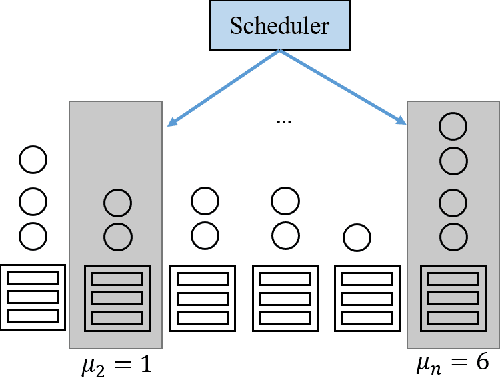
Large-scale interactive web services and advanced AI applications make sophisticated decisions in real-time, based on executing a massive amount of computation tasks on thousands of servers. Task schedulers, which often operate in heterogeneous and volatile environments, require high throughput, i.e., scheduling millions of tasks per second, and low latency, i.e., incurring minimal scheduling delays for millisecond-level tasks. Scheduling is further complicated by other users' workloads in a shared system, other background activities, and the diverse hardware configurations inside datacenters. We present Rosella, a new self-driving, distributed approach for task scheduling in heterogeneous clusters. Our system automatically learns the compute environment and adjust its scheduling policy in real-time. The solution provides high throughput and low latency simultaneously, because it runs in parallel on multiple machines with minimum coordination and only performs simple operations for each scheduling decision. Our learning module monitors total system load, and uses the information to dynamically determine optimal estimation strategy for the backends' compute-power. Our scheduling policy generalizes power-of-two-choice algorithms to handle heterogeneous workers, reducing the max queue length of $O(\log n)$ obtained by prior algorithms to $O(\log \log n)$. We implement a Rosella prototype and evaluate it with a variety of workloads. Experimental results show that Rosella significantly reduces task response times, and adapts to environment changes quickly.
Analysis of feature learning in weight-tied autoencoders via the mean field lens
Feb 16, 2021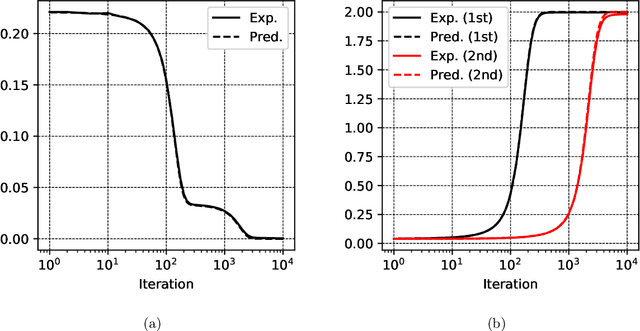
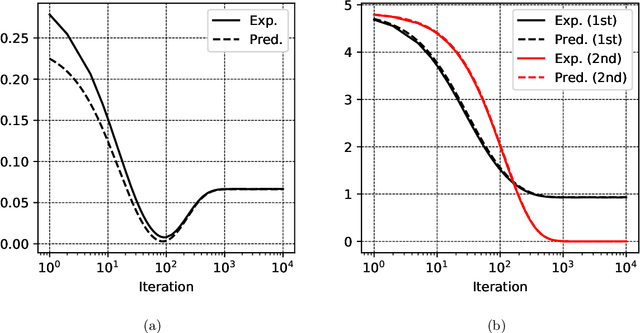
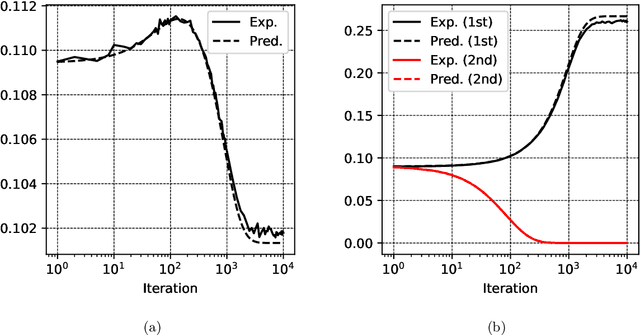
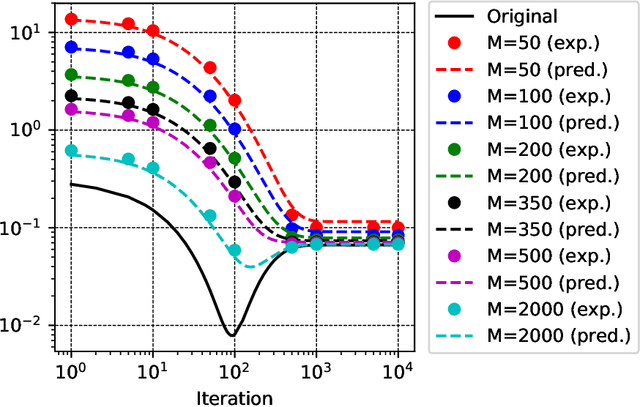
Autoencoders are among the earliest introduced nonlinear models for unsupervised learning. Although they are widely adopted beyond research, it has been a longstanding open problem to understand mathematically the feature extraction mechanism that trained nonlinear autoencoders provide. In this work, we make progress in this problem by analyzing a class of two-layer weight-tied nonlinear autoencoders in the mean field framework. Upon a suitable scaling, in the regime of a large number of neurons, the models trained with stochastic gradient descent are shown to admit a mean field limiting dynamics. This limiting description reveals an asymptotically precise picture of feature learning by these models: their training dynamics exhibit different phases that correspond to the learning of different principal subspaces of the data, with varying degrees of nonlinear shrinkage dependent on the $\ell_{2}$-regularization and stopping time. While we prove these results under an idealized assumption of (correlated) Gaussian data, experiments on real-life data demonstrate an interesting match with the theory. The autoencoder setup of interests poses a nontrivial mathematical challenge to proving these results. In this setup, the "Lipschitz" constants of the models grow with the data dimension $d$. Consequently an adaptation of previous analyses requires a number of neurons $N$ that is at least exponential in $d$. Our main technical contribution is a new argument which proves that the required $N$ is only polynomial in $d$. We conjecture that $N\gg d$ is sufficient and that $N$ is necessarily larger than a data-dependent intrinsic dimension, a behavior that is fundamentally different from previously studied setups.
RL-GAN-Net: A Reinforcement Learning Agent Controlled GAN Network for Real-Time Point Cloud Shape Completion
Apr 28, 2019

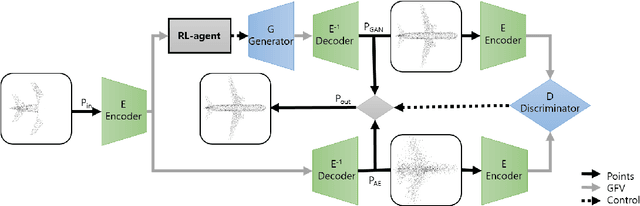
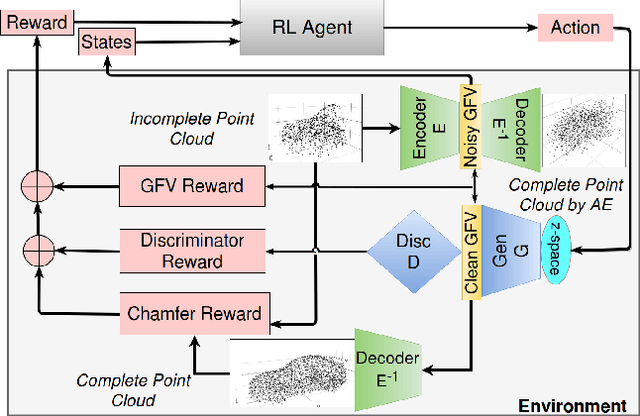
We present RL-GAN-Net, where a reinforcement learning (RL) agent provides fast and robust control of a generative adversarial network (GAN). Our framework is applied to point cloud shape completion that converts noisy, partial point cloud data into a high-fidelity completed shape by controlling the GAN. While a GAN is unstable and hard to train, we circumvent the problem by (1) training the GAN on the latent space representation whose dimension is reduced compared to the raw point cloud input and (2) using an RL agent to find the correct input to the GAN to generate the latent space representation of the shape that best fits the current input of incomplete point cloud. The suggested pipeline robustly completes point cloud with large missing regions. To the best of our knowledge, this is the first attempt to train an RL agent to control the GAN, which effectively learns the highly nonlinear mapping from the input noise of the GAN to the latent space of point cloud. The RL agent replaces the need for complex optimization and consequently makes our technique real time. Additionally, we demonstrate that our pipelines can be used to enhance the classification accuracy of point cloud with missing data.