 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Understanding and Exploiting Dependent Variables with Deep Metric Learning
Sep 08, 2020
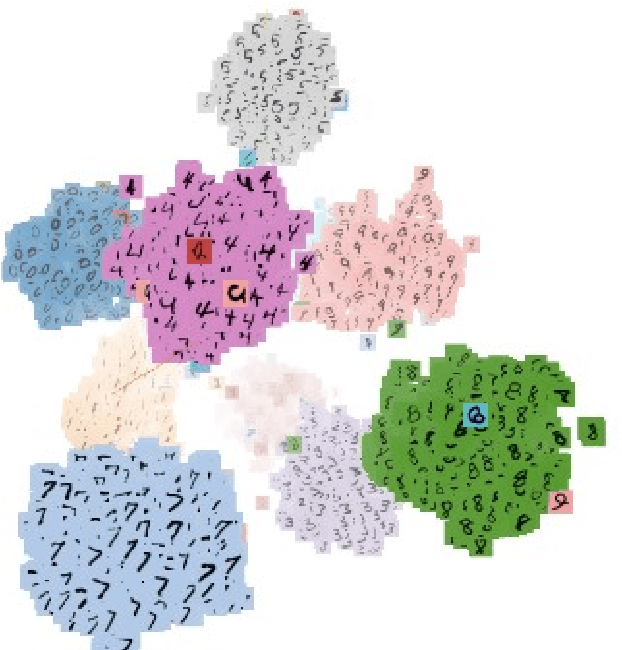

Deep Metric Learning (DML) approaches learn to represent inputs to a lower-dimensional latent space such that the distance between representations in this space corresponds with a predefined notion of similarity. This paper investigates how the mapping element of DML may be exploited in situations where the salient features in arbitrary classification problems vary over time or due to changing underlying variables. Examples of such variable features include seasonal and time-of-day variations in outdoor scenes in place recognition tasks for autonomous navigation and age/gender variations in human/animal subjects in classification tasks for medical/ethological studies. Through the use of visualisation tools for observing the distribution of DML representations per each query variable for which prior information is available, the influence of each variable on the classification task may be better understood. Based on these relationships, prior information on these salient background variables may be exploited at the inference stage of the DML approach by using a clustering algorithm to improve classification performance. This research proposes such a methodology establishing the saliency of query background variables and formulating clustering algorithms for better separating latent-space representations at run-time. The paper also discusses online management strategies to preserve the quality and diversity of data and the representation of each class in the gallery of embeddings in the DML approach. We also discuss latent works towards understanding the relevance of underlying/multiple variables with DML.
xERTE: Explainable Reasoning on Temporal Knowledge Graphs for Forecasting Future Links
Jan 18, 2021
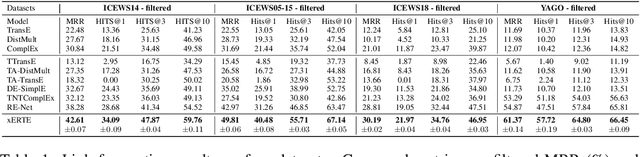
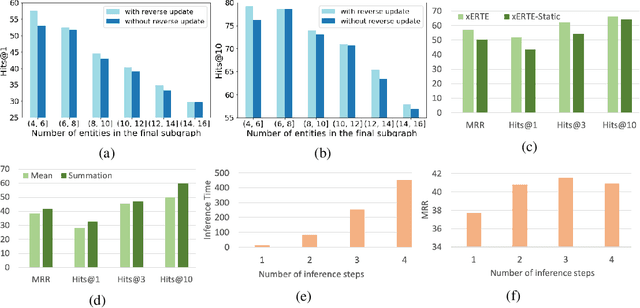
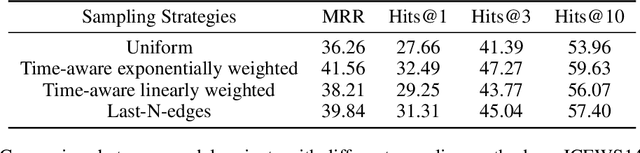
Interest has been rising lately towards modeling time-evolving knowledge graphs (KGs). Recently, graph representation learning approaches have become the dominant paradigm for link prediction on temporal KGs. However, the embedding-based approaches largely operate in a black-box fashion, lacking the ability to judge the results' reliability. This paper provides a future link forecasting framework that reasons over query-relevant subgraphs of temporal KGs and jointly models the graph structures and the temporal context information. Especially, we propose a temporal relational attention mechanism and a novel reverse representation update scheme to guide the extraction of an enclosing subgraph around the query. The subgraph is expanded by an iterative sampling of temporal neighbors and attention propagation. As a result, our approach provides human-understandable arguments for the prediction. We evaluate our model on four benchmark temporal knowledge graphs for the link forecasting task. While being more explainable, our model also obtains a relative improvement of up to 17.7 $\%$ on MRR compared to the previous best KG forecasting methods. We also conduct a survey with 53 respondents, and the results show that the reasoning arguments extracted by the model for link forecasting are aligned with human understanding.
Factorization of Fact-Checks for Low Resource Indian Languages
Feb 23, 2021
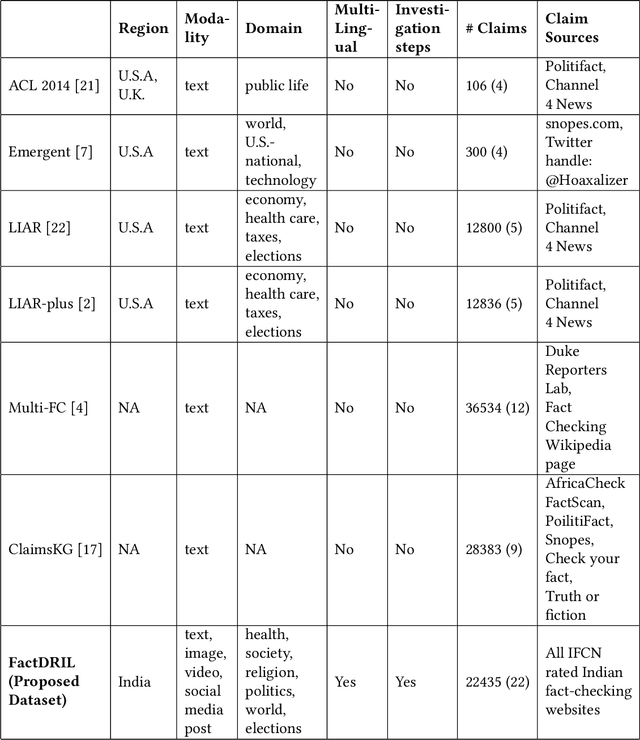

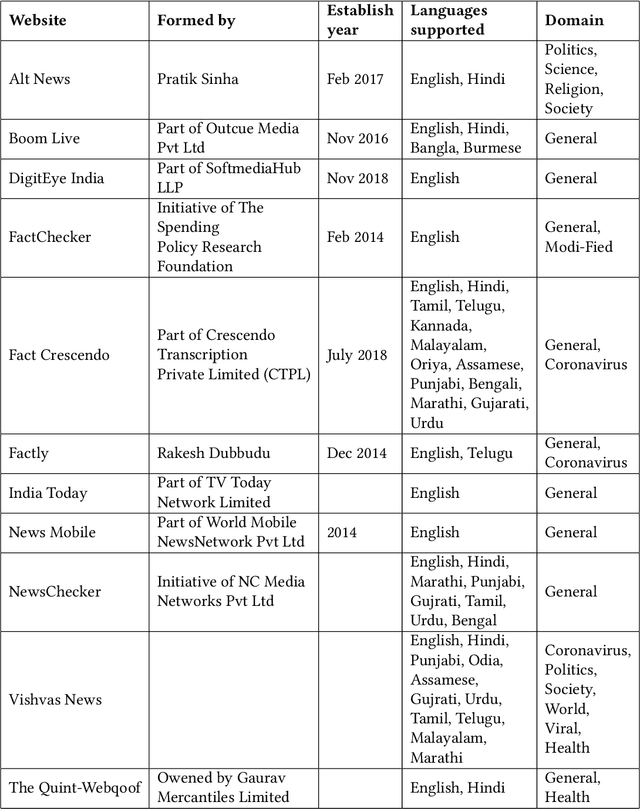
The advancement in technology and accessibility of internet to each individual is revolutionizing the real time information. The liberty to express your thoughts without passing through any credibility check is leading to dissemination of fake content in the ecosystem. It can have disastrous effects on both individuals and society as a whole. The amplification of fake news is becoming rampant in India too. Debunked information often gets republished with a replacement description, claiming it to depict some different incidence. To curb such fabricated stories, it is necessary to investigate such deduplicates and false claims made in public. The majority of studies on automatic fact-checking and fake news detection is restricted to English only. But for a country like India where only 10% of the literate population speak English, role of regional languages in spreading falsity cannot be undermined. In this paper, we introduce FactDRIL: the first large scale multilingual Fact-checking Dataset for Regional Indian Languages. We collect an exhaustive dataset across 7 months covering 11 low-resource languages. Our propose dataset consists of 9,058 samples belonging to English, 5,155 samples to Hindi and remaining 8,222 samples are distributed across various regional languages, i.e. Bangla, Marathi, Malayalam, Telugu, Tamil, Oriya, Assamese, Punjabi, Urdu, Sinhala and Burmese. We also present the detailed characterization of three M's (multi-lingual, multi-media, multi-domain) in the FactDRIL accompanied with the complete list of other varied attributes making it a unique dataset to study. Lastly, we present some potential use cases of the dataset. We expect this dataset will be a valuable resource and serve as a starting point to fight proliferation of fake news in low resource languages.
The Effect of Class Definitions on the Transferability of Adversarial Attacks Against Forensic CNNs
Jan 26, 2021
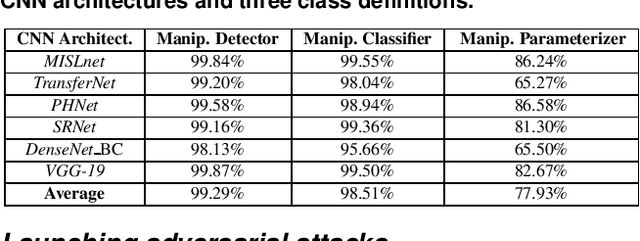
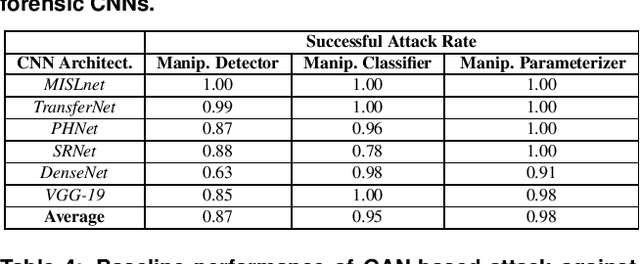
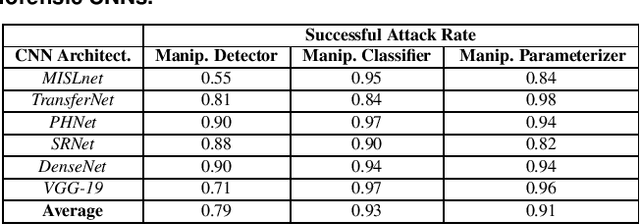
In recent years, convolutional neural networks (CNNs) have been widely used by researchers to perform forensic tasks such as image tampering detection. At the same time, adversarial attacks have been developed that are capable of fooling CNN-based classifiers. Understanding the transferability of adversarial attacks, i.e. an attacks ability to attack a different CNN than the one it was trained against, has important implications for designing CNNs that are resistant to attacks. While attacks on object recognition CNNs are believed to be transferrable, recent work by Barni et al. has shown that attacks on forensic CNNs have difficulty transferring to other CNN architectures or CNNs trained using different datasets. In this paper, we demonstrate that adversarial attacks on forensic CNNs are even less transferrable than previously thought even between virtually identical CNN architectures! We show that several common adversarial attacks against CNNs trained to identify image manipulation fail to transfer to CNNs whose only difference is in the class definitions (i.e. the same CNN architectures trained using the same data). We note that all formulations of class definitions contain the unaltered class. This has important implications for the future design of forensic CNNs that are robust to adversarial and anti-forensic attacks.
Learning Adaptive Language Interfaces through Decomposition
Oct 11, 2020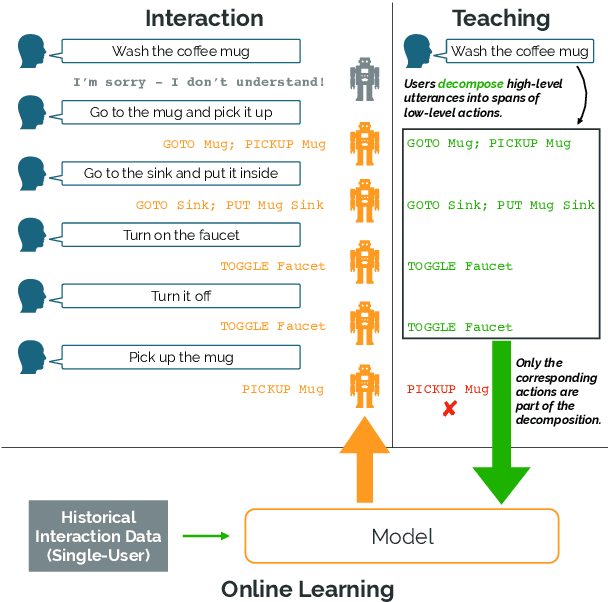

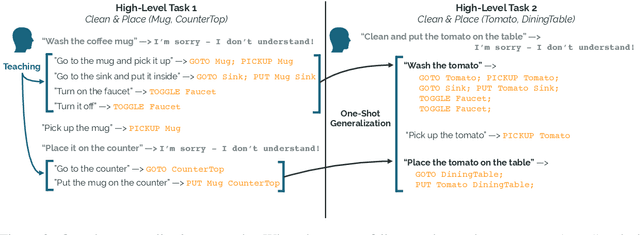
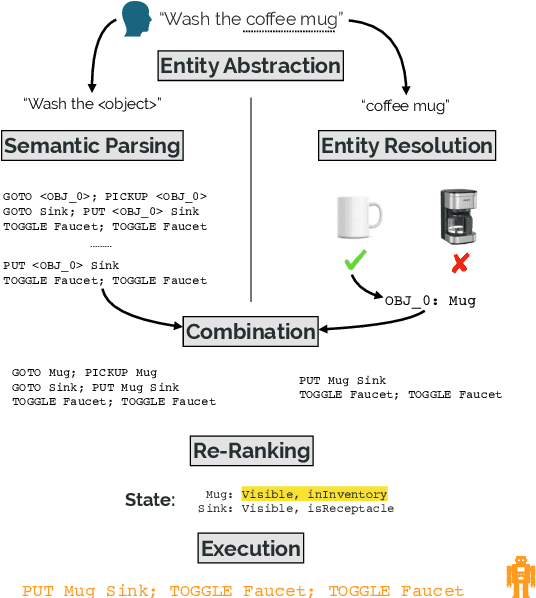
Our goal is to create an interactive natural language interface that efficiently and reliably learns from users to complete tasks in simulated robotics settings. We introduce a neural semantic parsing system that learns new high-level abstractions through decomposition: users interactively teach the system by breaking down high-level utterances describing novel behavior into low-level steps that it can understand. Unfortunately, existing methods either rely on grammars which parse sentences with limited flexibility, or neural sequence-to-sequence models that do not learn efficiently or reliably from individual examples. Our approach bridges this gap, demonstrating the flexibility of modern neural systems, as well as the one-shot reliable generalization of grammar-based methods. Our crowdsourced interactive experiments suggest that over time, users complete complex tasks more efficiently while using our system by leveraging what they just taught. At the same time, getting users to trust the system enough to be incentivized to teach high-level utterances is still an ongoing challenge. We end with a discussion of some of the obstacles we need to overcome to fully realize the potential of the interactive paradigm.
Optimal $\ell_1$ Column Subset Selection and a Fast PTAS for Low Rank Approximation
Jul 20, 2020

We study the problem of entrywise $\ell_1$ low rank approximation. We give the first polynomial time column subset selection-based $\ell_1$ low rank approximation algorithm sampling $\tilde{O}(k)$ columns and achieving an $\tilde{O}(k^{1/2})$-approximation for any $k$, improving upon the previous best $\tilde{O}(k)$-approximation and matching a prior lower bound for column subset selection-based $\ell_1$-low rank approximation which holds for any $\text{poly}(k)$ number of columns. We extend our results to obtain tight upper and lower bounds for column subset selection-based $\ell_p$ low rank approximation for any $1 < p < 2$, closing a long line of work on this problem. We next give a $(1 + \varepsilon)$-approximation algorithm for entrywise $\ell_p$ low rank approximation, for $1 \leq p < 2$, that is not a column subset selection algorithm. First, we obtain an algorithm which, given a matrix $A \in \mathbb{R}^{n \times d}$, returns a rank-$k$ matrix $\hat{A}$ in $2^{\text{poly}(k/\varepsilon)} + \text{poly}(nd)$ running time such that: $$\|A - \hat{A}\|_p \leq (1 + \varepsilon) \cdot OPT + \frac{\varepsilon}{\text{poly}(k)}\|A\|_p$$ where $OPT = \min_{A_k \text{ rank }k} \|A - A_k\|_p$. Using this algorithm, in the same running time we give an algorithm which obtains error at most $(1 + \varepsilon) \cdot OPT$ and outputs a matrix of rank at most $3k$ --- these algorithms significantly improve upon all previous $(1 + \varepsilon)$- and $O(1)$-approximation algorithms for the $\ell_p$ low rank approximation problem, which required at least $n^{\text{poly}(k/\varepsilon)}$ or $n^{\text{poly}(k)}$ running time, and either required strong bit complexity assumptions (our algorithms do not) or had bicriteria rank $3k$. Finally, we show hardness results which nearly match our $2^{\text{poly}(k)} + \text{poly}(nd)$ running time and the above additive error guarantee.
Identification of complex mixtures for Raman spectroscopy using a novel scheme based on a new multi-label deep neural network
Oct 29, 2020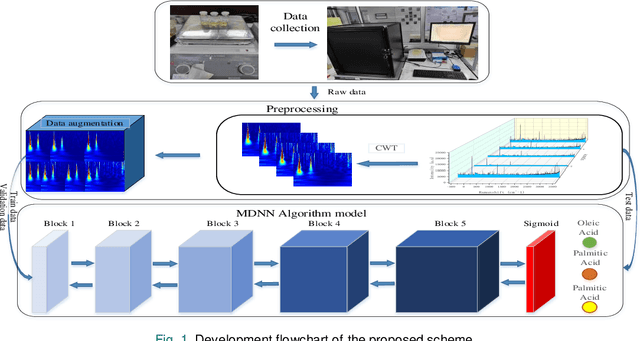
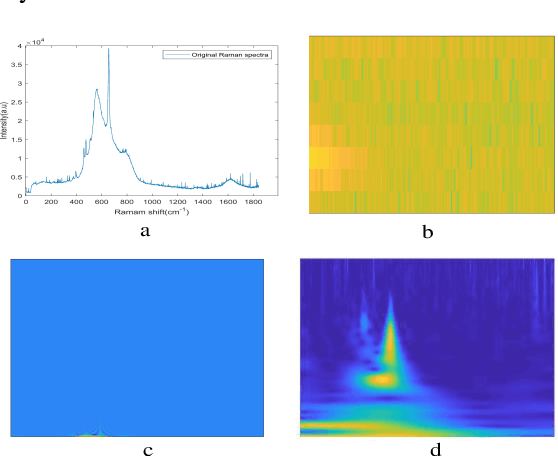
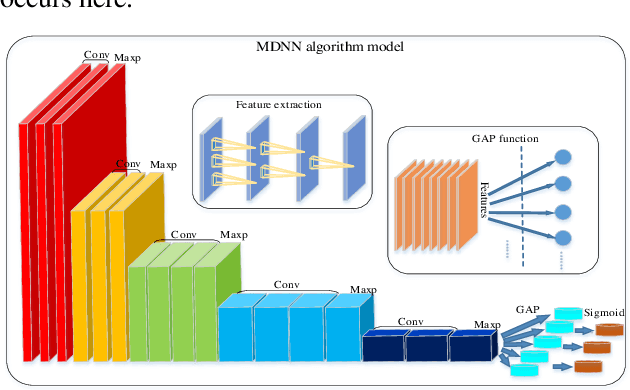
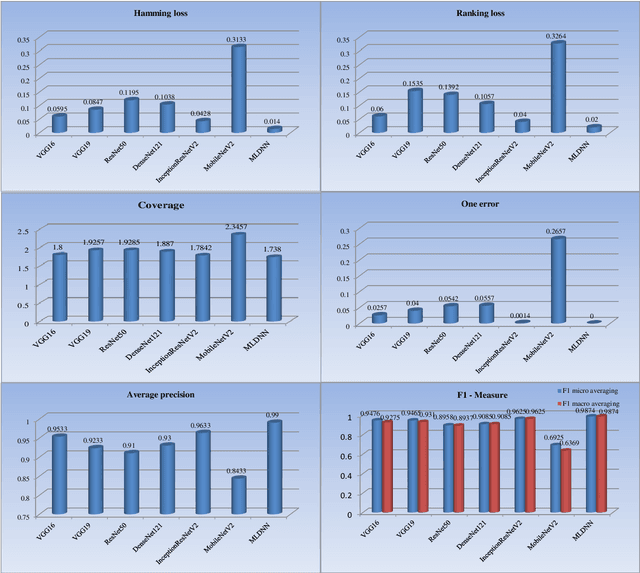
With noisy environment caused by fluoresence and additive white noise as well as complicated spectrum fingerprints, the identification of complex mixture materials remains a major challenge in Raman spectroscopy application. In this paper, we propose a new scheme based on a constant wavelet transform (CWT) and a deep network for classifying complex mixture. The scheme first transforms the noisy Raman spectrum to a two-dimensional scale map using CWT. A multi-label deep neural network model (MDNN) is then applied for classifying material. The proposed model accelerates the feature extraction and expands the feature graph using the global averaging pooling layer. The Sigmoid function is implemented in the last layer of the model. The MDNN model was trained, validated and tested with data collected from the samples prepared from substances in palm oil. During training and validating process, data augmentation is applied to overcome the imbalance of data and enrich the diversity of Raman spectra. From the test results, it is found that the MDNN model outperforms previously proposed deep neural network models in terms of Hamming loss, one error, coverage, ranking loss, average precision, F1 macro averaging and F1 micro averaging, respectively. The average detection time obtained from our model is 5.31 s, which is much faster than the detection time of the previously proposed models.
SCA-Net: A Self-Correcting Two-Layer Autoencoder for Hyper-spectral Unmixing
Feb 10, 2021
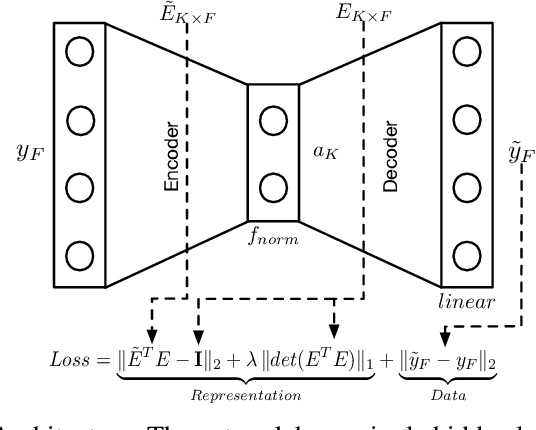
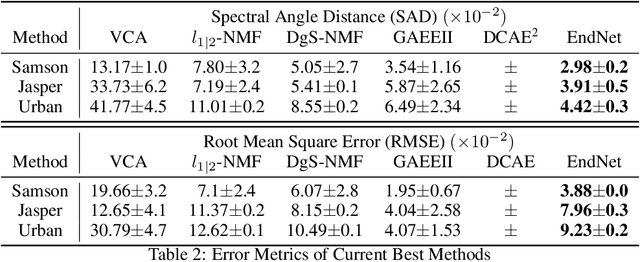
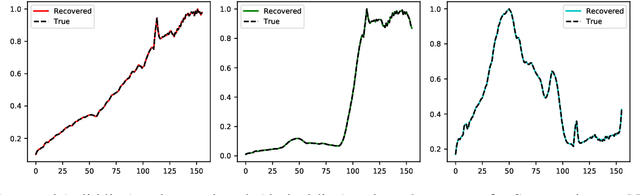
Linear Mixture Model for hyperspectral datasets involves separating a mixed pixel as a linear combination of its constituent endmembers and corresponding fractional abundances. Both optimization and neural methods have attempted to tackle this problem, with the current state of the art results achieved by neural models on benchmark datasets. However, our review of these neural models show that these networks are severely over-parameterized and consequently the invariant endmember spectra extracted as decoder weights has a high variance over multiple runs. All of these approaches require substantial post-processing to satisfy LMM constraints. Furthermore, they also require an exact specification of the number of endmembers and specialized initialization of weights from other algorithms like VCA. Our work shows for the first time that a two-layer autoencoder (SCA-Net), with $2FK$ parameters ($F$ features, $K$ endmembers), achieves error metrics that are scales apart ($10^{-5})$ from previously reported values $(10^{-2})$. SCA-Net converges to this low error solution starting from a random initialization of weights. We also show that SCA-Net, based upon a bi-orthogonal representation, performs a self-correction when the the number of endmembers are over-specified. We show that our network formulation extracts a low-rank representation that is bounded below by a tail-energy and can be computationally verified. Our numerical experiments on Samson, Jasper, and Urban datasets demonstrate that SCA-Net outperforms previously reported error metrics for all the cases while being robust to noise and outliers.
Robust Real-Time Multi-View Eye Tracking
Jan 03, 2018

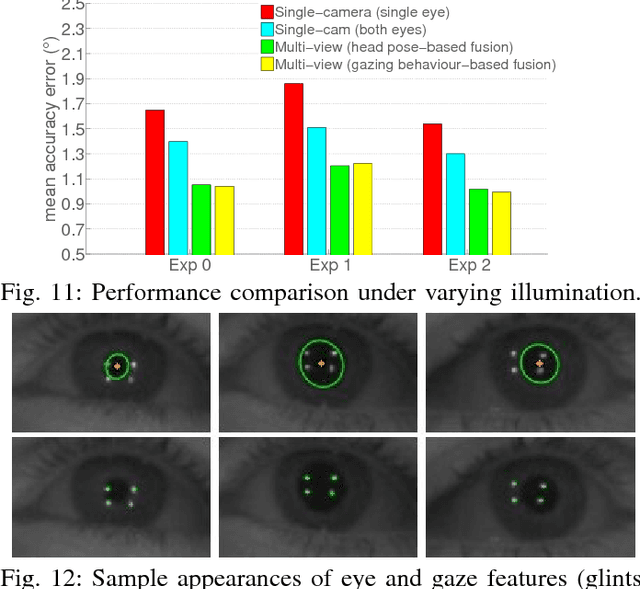
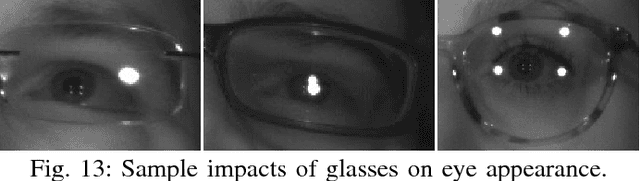
Despite significant advances in improving the gaze tracking accuracy under controlled conditions, the tracking robustness under real-world conditions, such as large head pose and movements, use of eyeglasses, illumination and eye type variations, remains a major challenge in eye tracking. In this paper, we revisit this challenge and introduce a real-time multi-camera eye tracking framework to improve the tracking robustness. First, differently from previous work, we design a multi-view tracking setup that allows for acquiring multiple eye appearances simultaneously. Leveraging multi-view appearances enables to more reliably detect gaze features under challenging conditions, particularly when they are obstructed in conventional single-view appearance due to large head movements or eyewear effects. The features extracted on various appearances are then used for estimating multiple gaze outputs. Second, we propose to combine estimated gaze outputs through an adaptive fusion mechanism to compute user's overall point of regard. The proposed mechanism firstly determines the estimation reliability of each gaze output according to user's momentary head pose and predicted gazing behavior, and then performs a reliability-based weighted fusion. We demonstrate the efficacy of our framework with extensive simulations and user experiments on a collected dataset featuring 20 subjects. Our results show that in comparison with state-of-the-art eye trackers, the proposed framework provides not only a significant enhancement in accuracy but also a notable robustness. Our prototype system runs at 30 frames-per-second (fps) and achieves 1 degree accuracy under challenging experimental scenarios, which makes it suitable for applications demanding high accuracy and robustness.
GEBT: Drawing Early-Bird Tickets in Graph Convolutional Network Training
Mar 01, 2021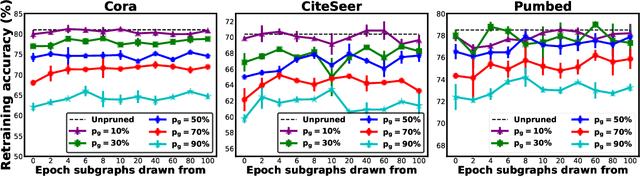
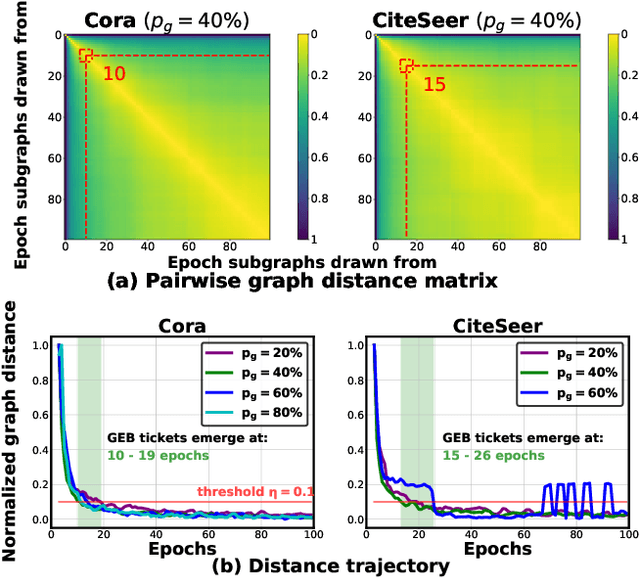
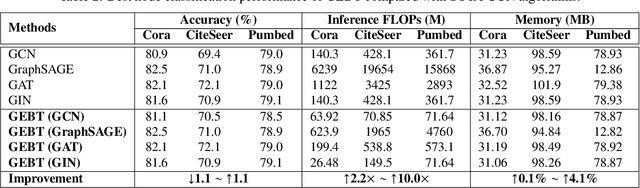
Graph Convolutional Networks (GCNs) have emerged as the state-of-the-art deep learning model for representation learning on graphs. However, it remains notoriously challenging to train and inference GCNs over large graph datasets, limiting their application to large real-world graphs and hindering the exploration of deeper and more sophisticated GCN graphs. This is because as the graph size grows, the sheer number of node features and the large adjacency matrix can easily explode the required memory and data movements. To tackle the aforementioned challenge, we explore the possibility of drawing lottery tickets when sparsifying GCN graphs, i.e., subgraphs that largely shrink the adjacency matrix yet are capable of achieving accuracy comparable to or even better than their corresponding full graphs. Specifically, we for the first time discover the existence of graph early-bird (GEB) tickets that emerge at the very early stage when sparsifying GCN graphs, and propose a simple yet effective detector to automatically identify the emergence of such GEB tickets. Furthermore, we develop a generic efficient GCN training framework dubbed GEBT that can significantly boost the efficiency of GCN training by (1) drawing joint early-bird tickets between the GCN graphs and models and (2) enabling simultaneously sparsifying both GCN graphs and models, paving the way for training and inferencing large GCN graphs to handle real-world graph datasets. Experiments on various GCN models and datasets consistently validate our GEB finding and the effectiveness of our GEBT, e.g., our GEBT achieves up to 80.2% ~ 85.6% and 84.6% ~ 87.5% savings of GCN training and inference costs while leading to a comparable or even better accuracy as compared to state-of-the-art methods. Code available at https://github.com/RICE-EIC/GEBT