 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Top-$k$ Ranking Bayesian Optimization
Dec 19, 2020
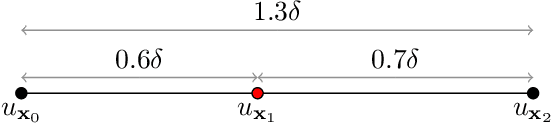
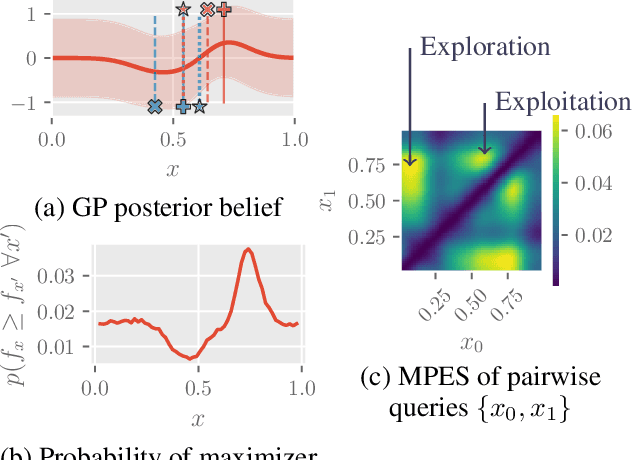
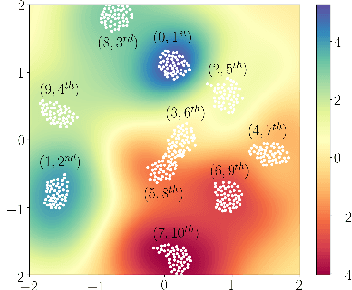
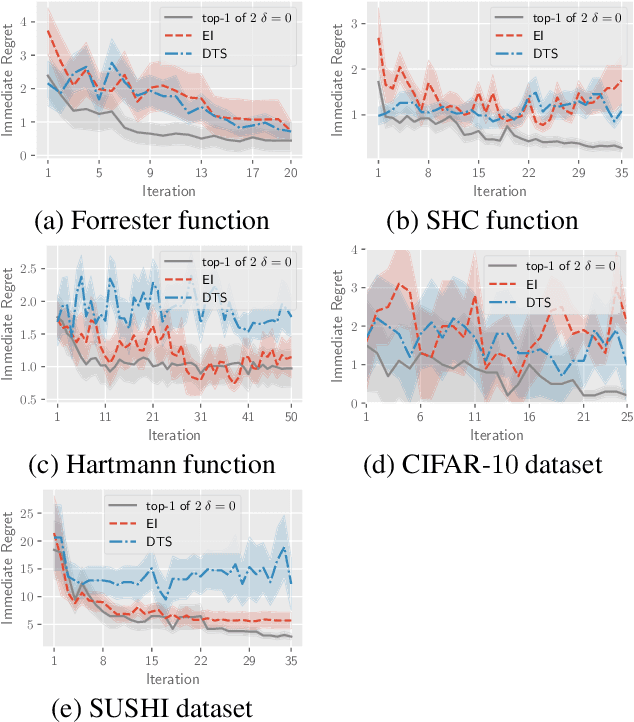
This paper presents a novel approach to top-$k$ ranking Bayesian optimization (top-$k$ ranking BO) which is a practical and significant generalization of preferential BO to handle top-$k$ ranking and tie/indifference observations. We first design a surrogate model that is not only capable of catering to the above observations, but is also supported by a classic random utility model. Another equally important contribution is the introduction of the first information-theoretic acquisition function in BO with preferential observation called multinomial predictive entropy search (MPES) which is flexible in handling these observations and optimized for all inputs of a query jointly. MPES possesses superior performance compared with existing acquisition functions that select the inputs of a query one at a time greedily. We empirically evaluate the performance of MPES using several synthetic benchmark functions, CIFAR-$10$ dataset, and SUSHI preference dataset.
Exploring multi-task multi-lingual learning of transformer models for hate speech and offensive speech identification in social media
Jan 27, 2021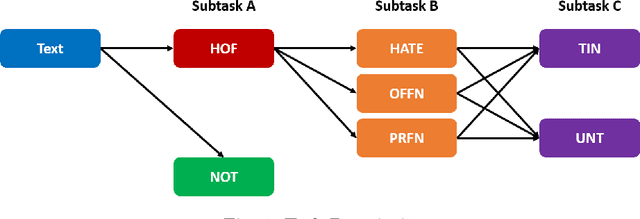
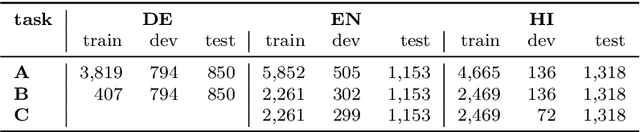
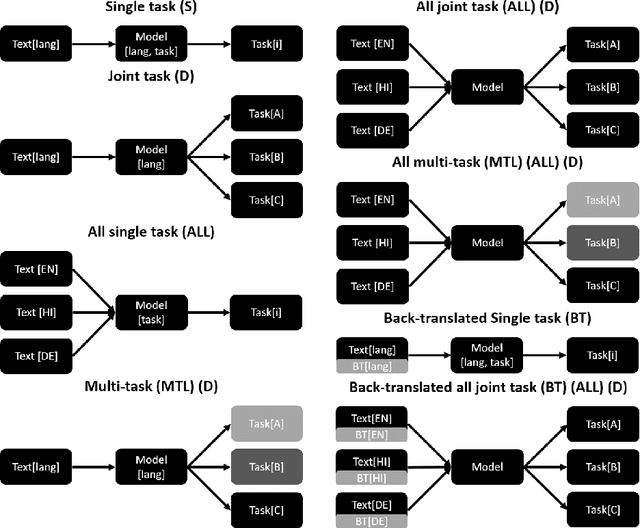
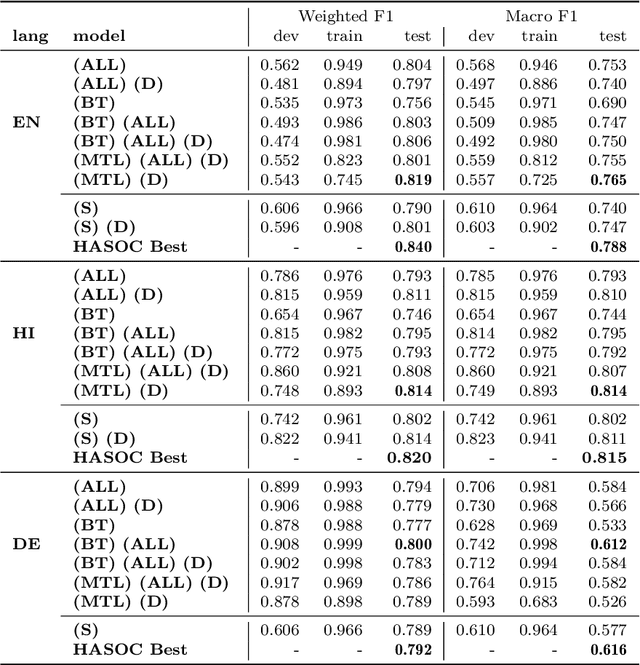
Hate Speech has become a major content moderation issue for online social media platforms. Given the volume and velocity of online content production, it is impossible to manually moderate hate speech related content on any platform. In this paper we utilize a multi-task and multi-lingual approach based on recently proposed Transformer Neural Networks to solve three sub-tasks for hate speech. These sub-tasks were part of the 2019 shared task on hate speech and offensive content (HASOC) identification in Indo-European languages. We expand on our submission to that competition by utilizing multi-task models which are trained using three approaches, a) multi-task learning with separate task heads, b) back-translation, and c) multi-lingual training. Finally, we investigate the performance of various models and identify instances where the Transformer based models perform differently and better. We show that it is possible to to utilize different combined approaches to obtain models that can generalize easily on different languages and tasks, while trading off slight accuracy (in some cases) for a much reduced inference time compute cost. We open source an updated version of our HASOC 2019 code with the new improvements at https://github.com/socialmediaie/MTML_HateSpeech.
SCA-Net: A Self-Correcting Two-Layer Autoencoder for Hyper-spectral Unmixing
Feb 10, 2021
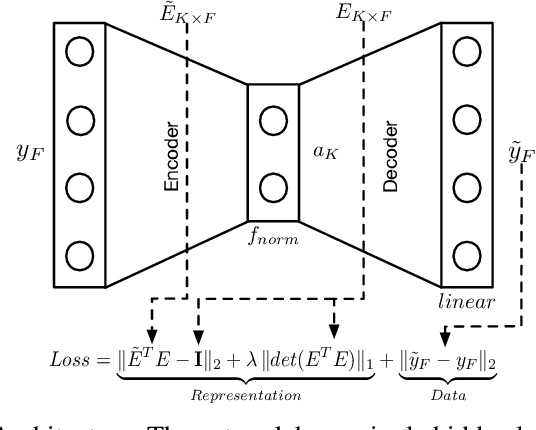
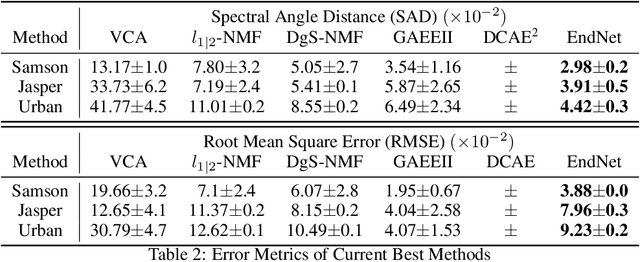
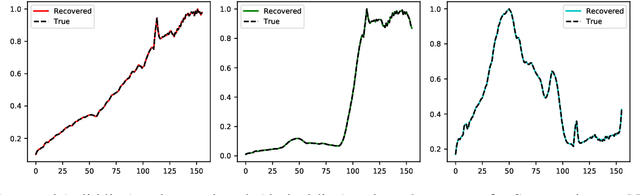
Linear Mixture Model for hyperspectral datasets involves separating a mixed pixel as a linear combination of its constituent endmembers and corresponding fractional abundances. Both optimization and neural methods have attempted to tackle this problem, with the current state of the art results achieved by neural models on benchmark datasets. However, our review of these neural models show that these networks are severely over-parameterized and consequently the invariant endmember spectra extracted as decoder weights has a high variance over multiple runs. All of these approaches require substantial post-processing to satisfy LMM constraints. Furthermore, they also require an exact specification of the number of endmembers and specialized initialization of weights from other algorithms like VCA. Our work shows for the first time that a two-layer autoencoder (SCA-Net), with $2FK$ parameters ($F$ features, $K$ endmembers), achieves error metrics that are scales apart ($10^{-5})$ from previously reported values $(10^{-2})$. SCA-Net converges to this low error solution starting from a random initialization of weights. We also show that SCA-Net, based upon a bi-orthogonal representation, performs a self-correction when the the number of endmembers are over-specified. We show that our network formulation extracts a low-rank representation that is bounded below by a tail-energy and can be computationally verified. Our numerical experiments on Samson, Jasper, and Urban datasets demonstrate that SCA-Net outperforms previously reported error metrics for all the cases while being robust to noise and outliers.
GEBT: Drawing Early-Bird Tickets in Graph Convolutional Network Training
Mar 01, 2021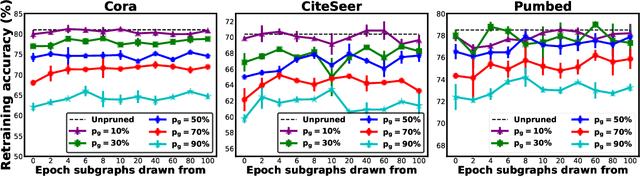
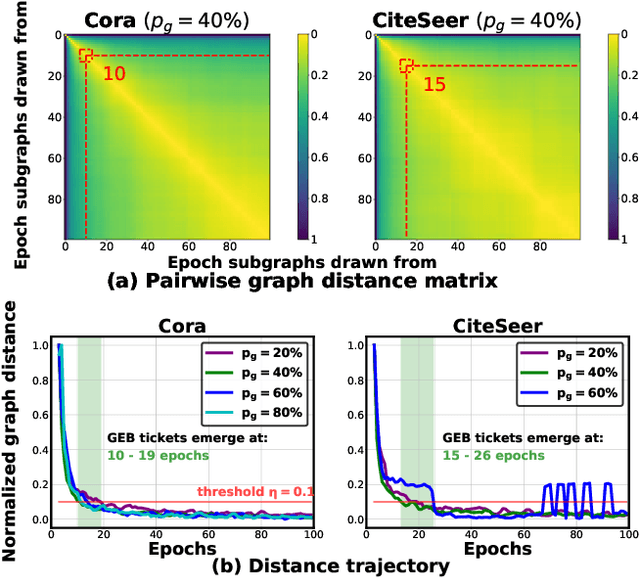
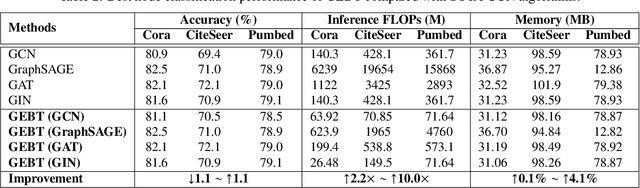
Graph Convolutional Networks (GCNs) have emerged as the state-of-the-art deep learning model for representation learning on graphs. However, it remains notoriously challenging to train and inference GCNs over large graph datasets, limiting their application to large real-world graphs and hindering the exploration of deeper and more sophisticated GCN graphs. This is because as the graph size grows, the sheer number of node features and the large adjacency matrix can easily explode the required memory and data movements. To tackle the aforementioned challenge, we explore the possibility of drawing lottery tickets when sparsifying GCN graphs, i.e., subgraphs that largely shrink the adjacency matrix yet are capable of achieving accuracy comparable to or even better than their corresponding full graphs. Specifically, we for the first time discover the existence of graph early-bird (GEB) tickets that emerge at the very early stage when sparsifying GCN graphs, and propose a simple yet effective detector to automatically identify the emergence of such GEB tickets. Furthermore, we develop a generic efficient GCN training framework dubbed GEBT that can significantly boost the efficiency of GCN training by (1) drawing joint early-bird tickets between the GCN graphs and models and (2) enabling simultaneously sparsifying both GCN graphs and models, paving the way for training and inferencing large GCN graphs to handle real-world graph datasets. Experiments on various GCN models and datasets consistently validate our GEB finding and the effectiveness of our GEBT, e.g., our GEBT achieves up to 80.2% ~ 85.6% and 84.6% ~ 87.5% savings of GCN training and inference costs while leading to a comparable or even better accuracy as compared to state-of-the-art methods. Code available at https://github.com/RICE-EIC/GEBT
Named Entity Recognition in the Style of Object Detection
Jan 26, 2021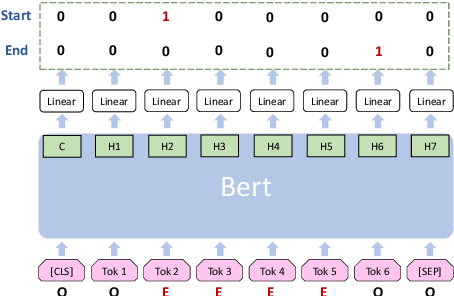
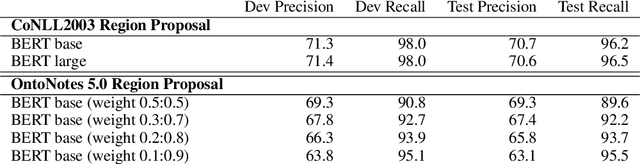
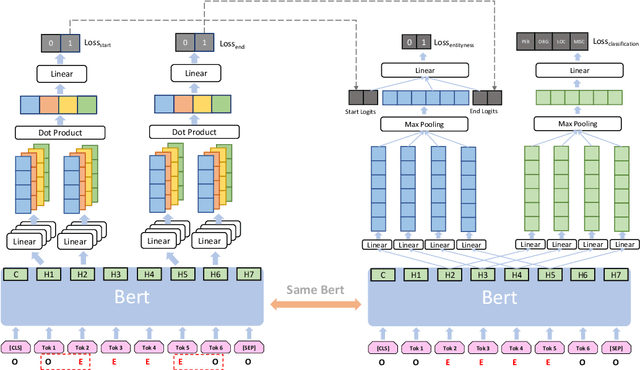

In this work, we propose a two-stage method for named entity recognition (NER), especially for nested NER. We borrowed the idea from the two-stage Object Detection in computer vision and the way how they construct the loss function. First, a region proposal network generates region candidates and then a second-stage model discriminates and classifies the entity and makes the final prediction. We also designed a special loss function for the second-stage training that predicts the entityness and entity type at the same time. The model is built on top of pretrained BERT encoders, and we tried both BERT base and BERT large models. For experiments, we first applied it to flat NER tasks such as CoNLL2003 and OntoNotes 5.0 and got comparable results with traditional NER models using sequence labeling methodology. We then tested the model on the nested named entity recognition task ACE2005 and Genia, and got F1 score of 85.6$\%$ and 76.8$\%$ respectively. In terms of the second-stage training, we found that adding extra randomly selected regions plays an important role in improving the precision. We also did error profiling to better evaluate the performance of the model in different circumstances for potential improvements in the future.
A Passive Online Technique for Learning Hybrid Automata from Input/Output Traces
Jan 18, 2021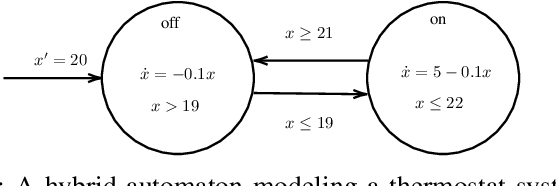
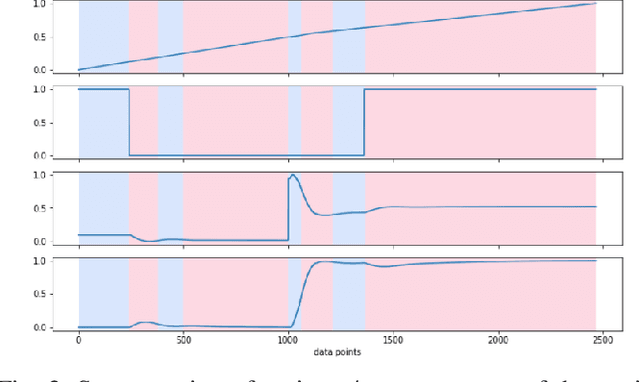
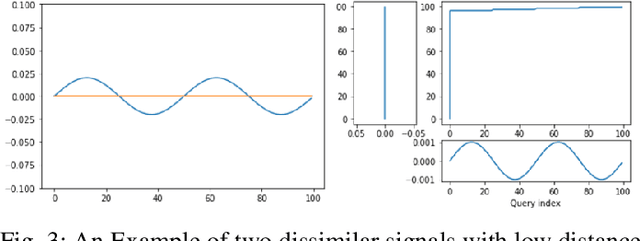
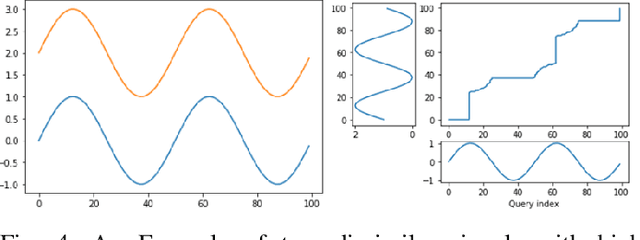
Specification synthesis is the process of deriving a model from the input-output traces of a system. It is used extensively in test design, reverse engineering, and system identification. One type of the resulting artifact of this process for cyber-physical systems is hybrid automata. They are intuitive, precise, tool independent, and at a high level of abstraction, and can model systems with both discrete and continuous variables. In this paper, we propose a new technique for synthesizing hybrid automaton from the input-output traces of a non-linear cyber-physical system. Similarity detection in non-linear behaviors is the main challenge for extracting such models. We address this problem by utilizing the Dynamic Time Warping technique. Our approach is passive, meaning that it does not need interaction with the system during automata synthesis from the logged traces; and online, which means that each input/output trace is used only once in the procedure. In other words, each new trace can be used to improve the already synthesized automaton. We evaluated our algorithm in two industrial and simulated case studies. The accuracy of the derived automata show promising results.
Interpreting LSTM Prediction on Solar Flare Eruption with Time-series Clustering
Dec 27, 2019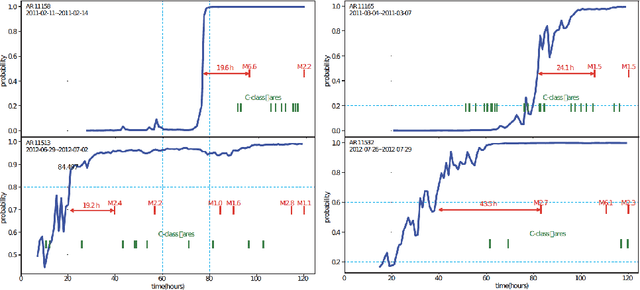

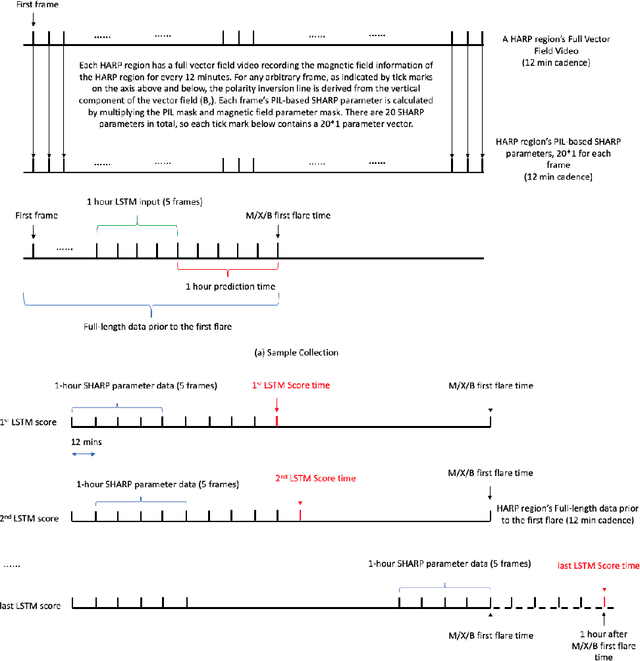
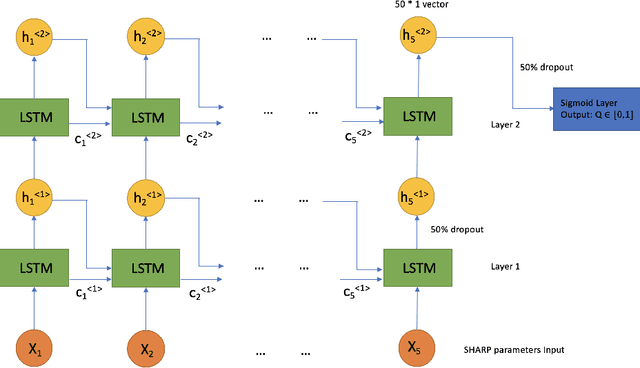
We conduct a post hoc analysis of solar flare predictions made by a Long Short Term Memory (LSTM) model employing data in the form of Space-weather HMI Active Region Patches (SHARP) parameters. These data are distinguished in that the parameters are calculated from data in proximity to the magnetic polarity inversion line where the flares originate. We train the the LSTM model for binary classification to provide a prediction score for the probability of M/X class flares to occur in next hour. We then develop a dimension-reduction technique to reduce the dimensions of SHARP parameter (LSTM inputs) and demonstrate the different patterns of SHARP parameters corresponding to the transition from low to high prediction score. Our work shows that a subset of SHARP parameters contain the key signals that strong solar flare eruptions are imminent. The dynamics of these parameters have a highly uniform trajectory for many events whose LSTM prediction scores for M/X class flares transition from very low to very high. The results suggest that there exist a few threshold values of a subset of SHARP parameters when surpassed could indicate a high probability of strong flare eruption. Our method has distilled the knowledge of solar flare eruption learnt by deep learning model and provides a more interpretable approximation where more physics related insights could be derived.
The Effect of Class Definitions on the Transferability of Adversarial Attacks Against Forensic CNNs
Jan 26, 2021
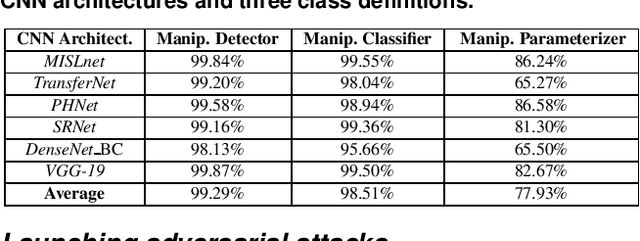
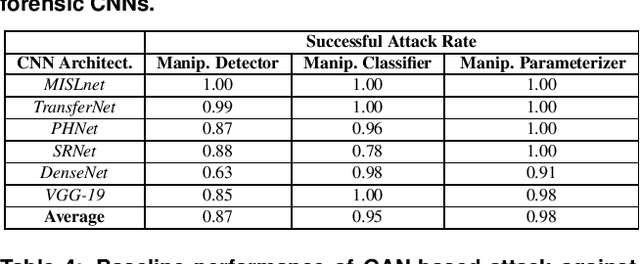
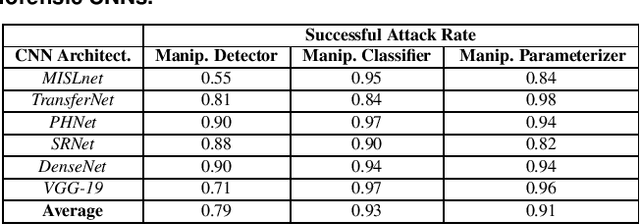
In recent years, convolutional neural networks (CNNs) have been widely used by researchers to perform forensic tasks such as image tampering detection. At the same time, adversarial attacks have been developed that are capable of fooling CNN-based classifiers. Understanding the transferability of adversarial attacks, i.e. an attacks ability to attack a different CNN than the one it was trained against, has important implications for designing CNNs that are resistant to attacks. While attacks on object recognition CNNs are believed to be transferrable, recent work by Barni et al. has shown that attacks on forensic CNNs have difficulty transferring to other CNN architectures or CNNs trained using different datasets. In this paper, we demonstrate that adversarial attacks on forensic CNNs are even less transferrable than previously thought even between virtually identical CNN architectures! We show that several common adversarial attacks against CNNs trained to identify image manipulation fail to transfer to CNNs whose only difference is in the class definitions (i.e. the same CNN architectures trained using the same data). We note that all formulations of class definitions contain the unaltered class. This has important implications for the future design of forensic CNNs that are robust to adversarial and anti-forensic attacks.
Prediction of the onset of cardiovascular diseases from electronic health records using multi-task gated recurrent units
Jul 16, 2020
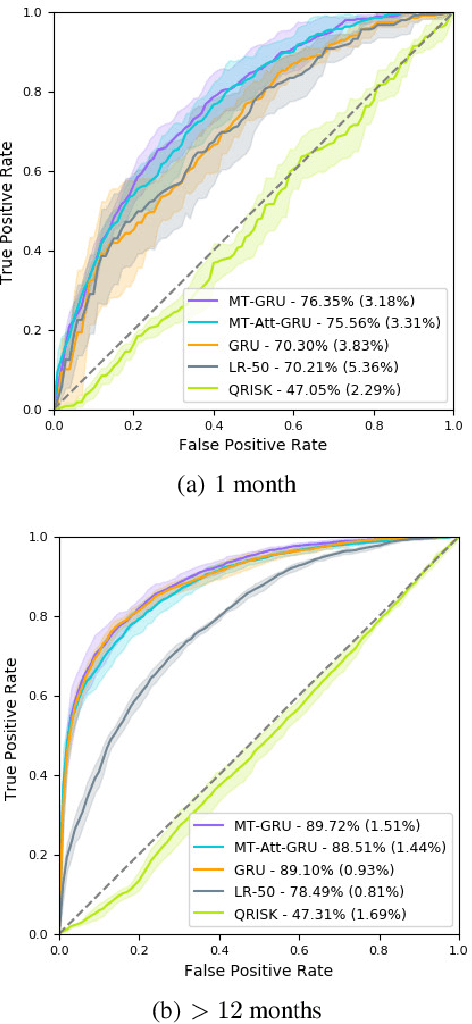
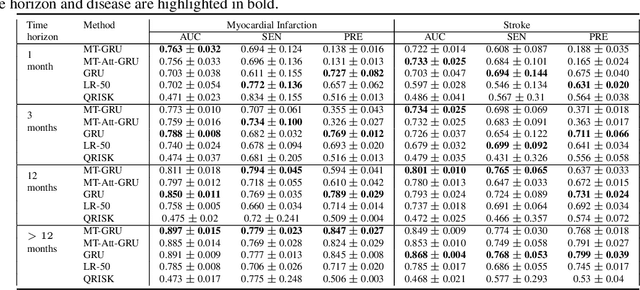
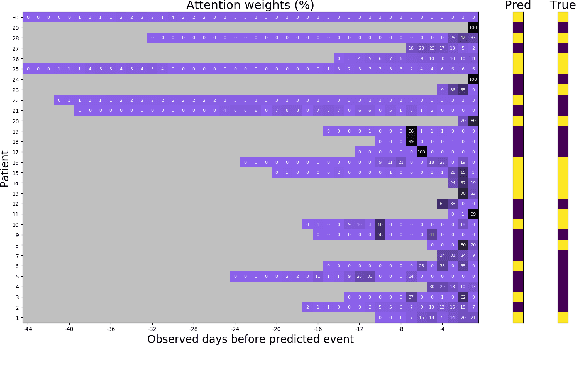
In this work, we propose a multi-task recurrent neural network with attention mechanism for predicting cardiovascular events from electronic health records (EHRs) at different time horizons. The proposed approach is compared to a standard clinical risk predictor (QRISK) and machine learning alternatives using 5-year data from a NHS Foundation Trust. The proposed model outperforms standard clinical risk scores in predicting stroke (AUC=0.85) and myocardial infarction (AUC=0.89), considering the largest time horizon. Benefit of using an \gls{mt} setting becomes visible for very short time horizons, which results in an AUC increase between 2-6%. Further, we explored the importance of individual features and attention weights in predicting cardiovascular events. Our results indicate that the recurrent neural network approach benefits from the hospital longitudinal information and demonstrates how machine learning techniques can be applied to secondary care.
Discriminative Noise Robust Sparse Orthogonal Label Regression-based Domain Adaptation
Jan 09, 2021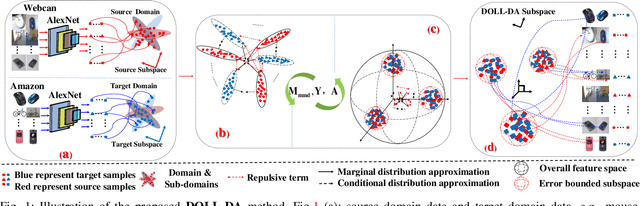

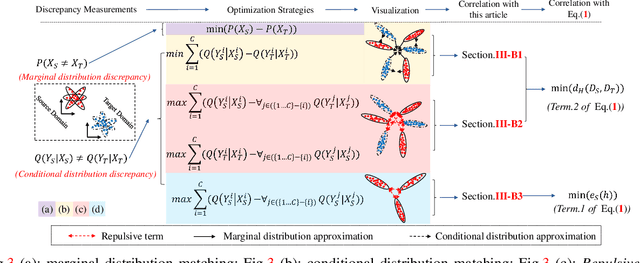
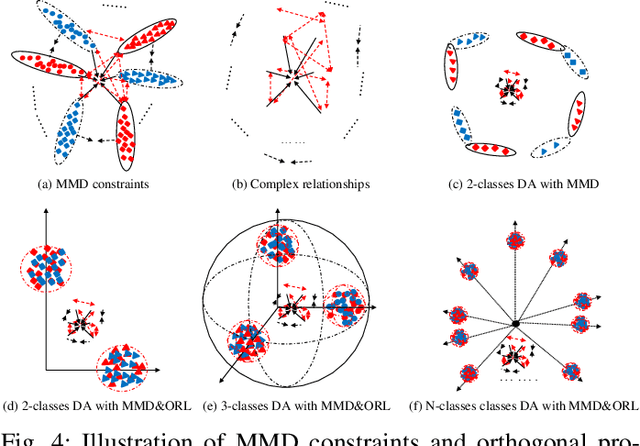
Domain adaptation (DA) aims to enable a learning model trained from a source domain to generalize well on a target domain, despite the mismatch of data distributions between the two domains. State-of-the-art DA methods have so far focused on the search of a latent shared feature space where source and target domain data can be aligned either statistically and/or geometrically. In this paper, we propose a novel unsupervised DA method, namely Discriminative Noise Robust Sparse Orthogonal Label Regression-based Domain Adaptation (DOLL-DA). The proposed DOLL-DA derives from a novel integrated model which searches a shared feature subspace where source and target domain data are, through optimization of some repulse force terms, discriminatively aligned statistically, while at same time regresses orthogonally data labels thereof using a label embedding trick. Furthermore, in minimizing a novel Noise Robust Sparse Orthogonal Label Regression(NRS_OLR) term, the proposed model explicitly accounts for data outliers to avoid negative transfer and introduces the property of sparsity when regressing data labels. Due to the character restriction. Please read our detailed abstract in our paper.