 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Psychoacoustic Calibration of Loss Functions for Efficient End-to-End Neural Audio Coding
Dec 31, 2020
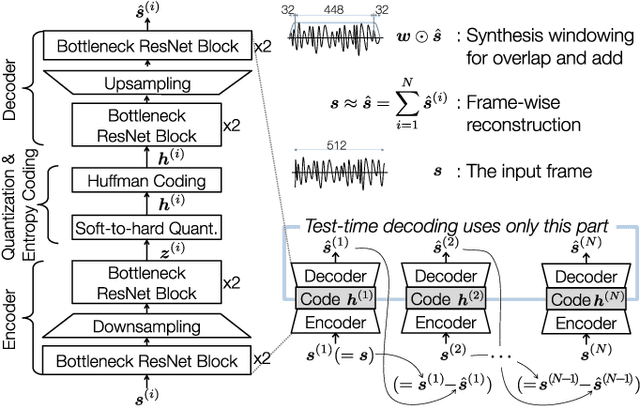
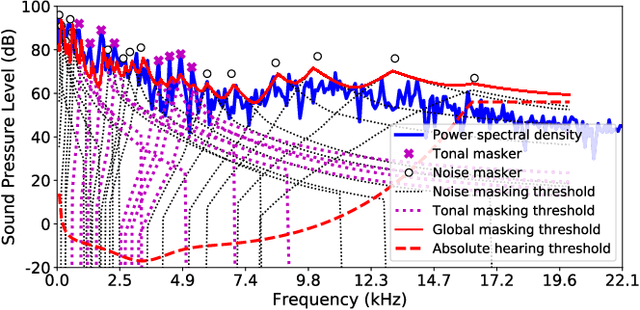
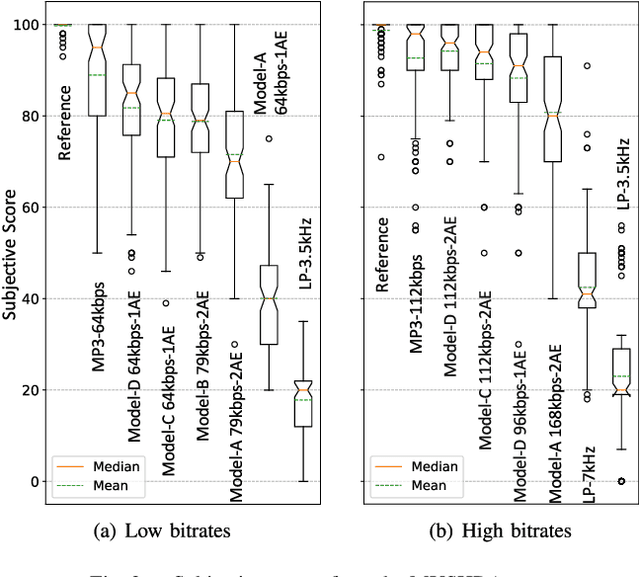
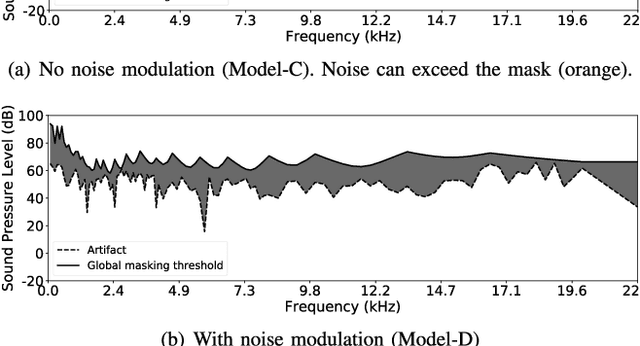
Conventional audio coding technologies commonly leverage human perception of sound, or psychoacoustics, to reduce the bitrate while preserving the perceptual quality of the decoded audio signals. For neural audio codecs, however, the objective nature of the loss function usually leads to suboptimal sound quality as well as high run-time complexity due to the large model size. In this work, we present a psychoacoustic calibration scheme to re-define the loss functions of neural audio coding systems so that it can decode signals more perceptually similar to the reference, yet with a much lower model complexity. The proposed loss function incorporates the global masking threshold, allowing the reconstruction error that corresponds to inaudible artifacts. Experimental results show that the proposed model outperforms the baseline neural codec twice as large and consuming 23.4% more bits per second. With the proposed method, a lightweight neural codec, with only 0.9 million parameters, performs near-transparent audio coding comparable with the commercial MPEG-1 Audio Layer III codec at 112 kbps.
Fully Non-autoregressive Neural Machine Translation: Tricks of the Trade
Dec 31, 2020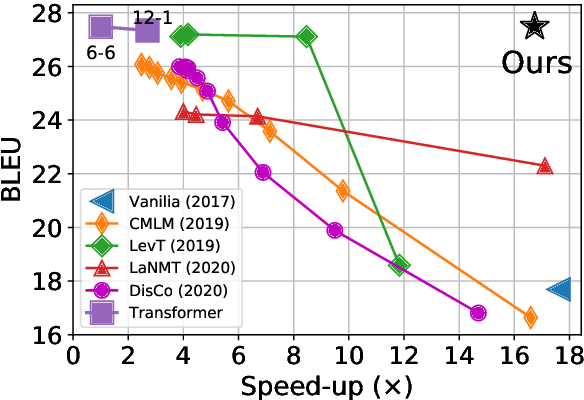
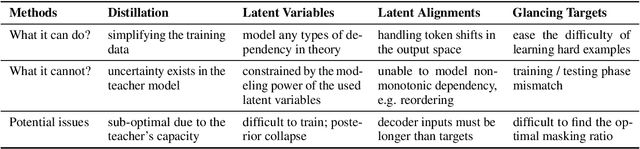

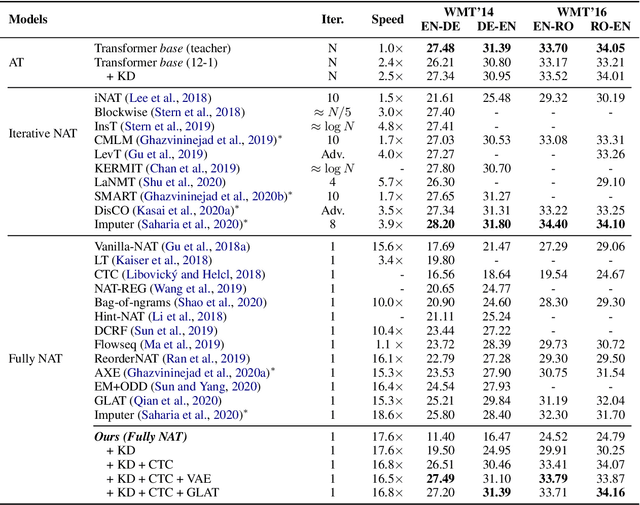
Fully non-autoregressive neural machine translation (NAT) is proposed to simultaneously predict tokens with single forward of neural networks, which significantly reduces the inference latency at the expense of quality drop compared to the Transformer baseline. In this work, we target on closing the performance gap while maintaining the latency advantage. We first inspect the fundamental issues of fully NAT models, and adopt dependency reduction in the learning space of output tokens as the basic guidance. Then, we revisit methods in four different aspects that have been proven effective for improving NAT models, and carefully combine these techniques with necessary modifications. Our extensive experiments on three translation benchmarks show that the proposed system achieves the new state-of-the-art results for fully NAT models, and obtains comparable performance with the autoregressive and iterative NAT systems. For instance, one of the proposed models achieves 27.49 BLEU points on WMT14 En-De with approximately 16.5X speed up at inference time.
Supervised training of spiking neural networks for robust deployment on mixed-signal neuromorphic processors
Feb 12, 2021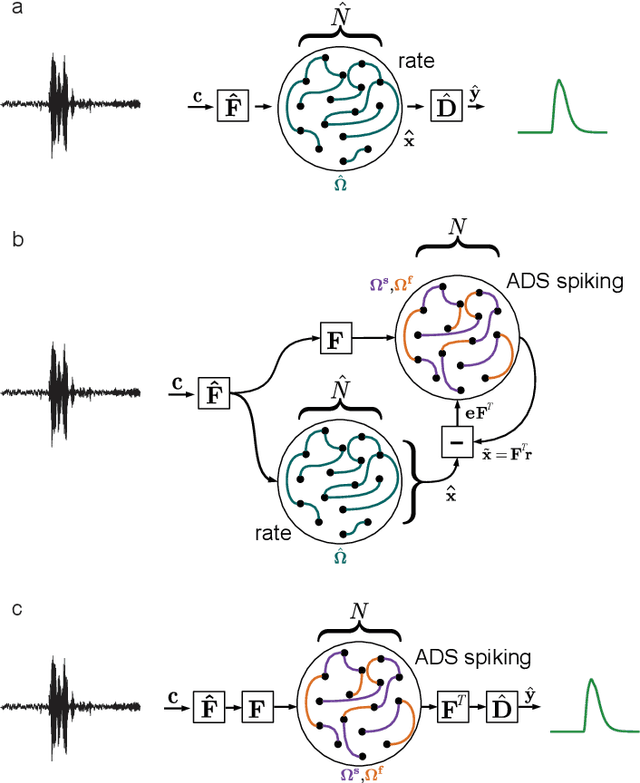
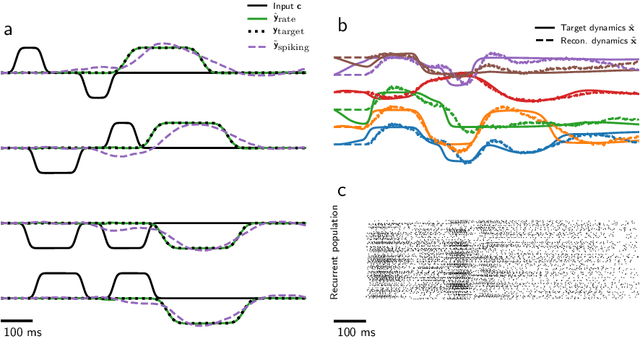
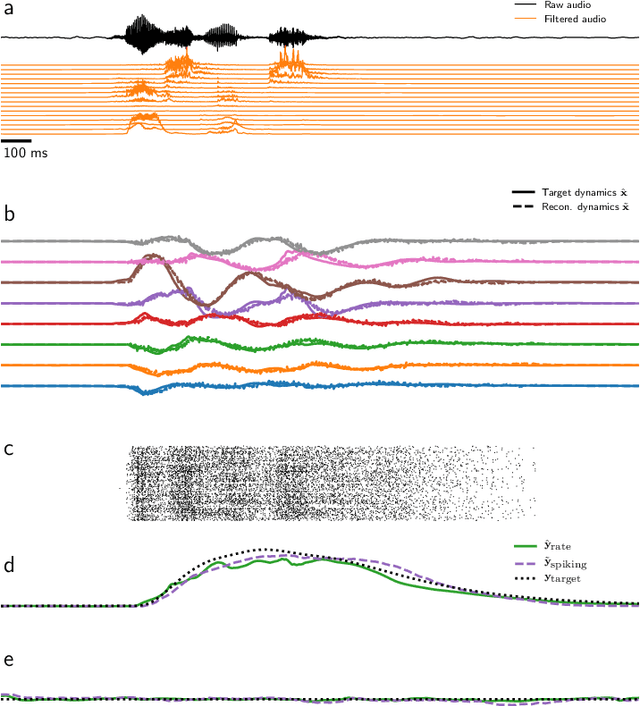
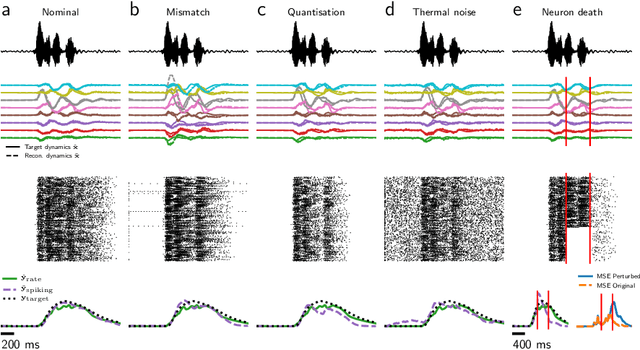
Mixed-signal analog/digital electronic circuits can emulate spiking neurons and synapses with extremely high energy efficiency, following an approach known as "neuromorphic engineering". However, analog circuits are sensitive to variation in fabrication among transistors in a chip ("device mismatch"). In the case of neuromorphic implementation of Spiking Neural Networks (SNNs), mismatch is expressed as differences in effective parameters between identically-configured neurons and synapses. Each fabricated chip therefore provides a different distribution of parameters such as time constants or synaptic weights. Without the expensive overhead in terms of area and power of extra on-chip learning or calibration circuits, device mismatch and other noise sources represent a critical challenge for the deployment of pre-trained neural network chips. Here we present a supervised learning approach that addresses this challenge by maximizing robustness to mismatch and other common sources of noise. The proposed method trains (SNNs) to perform temporal classification tasks by mimicking a pre-trained dynamical system, using a local learning rule adapted from non-linear control theory. We demonstrate the functionality of our model on two tasks that require memory to perform successfully, and measure the robustness of our approach to several forms of noise and variability present in the network. We show that our approach is more robust than several common alternative approaches for training SNNs. Our method provides a viable way to robustly deploy pre-trained networks on mixed-signal neuromorphic hardware, without requiring per-device training or calibration.
Interpreting LSTM Prediction on Solar Flare Eruption with Time-series Clustering
Dec 27, 2019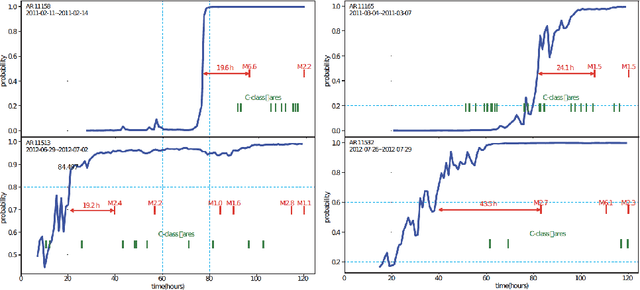

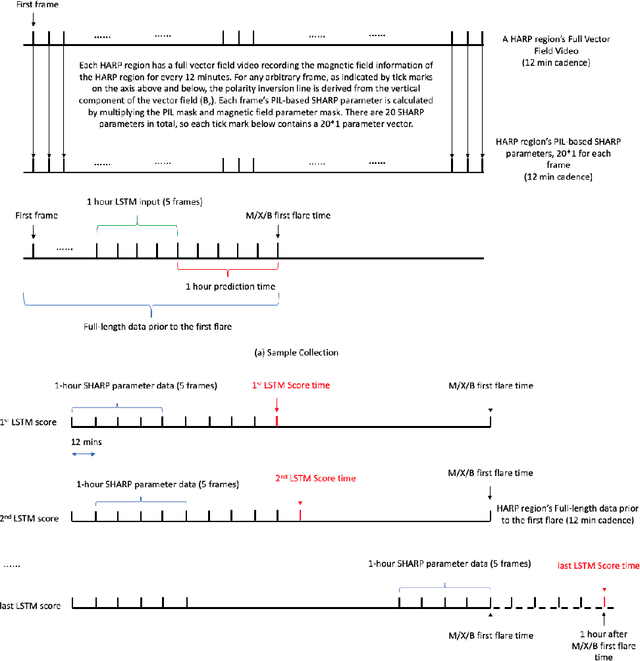
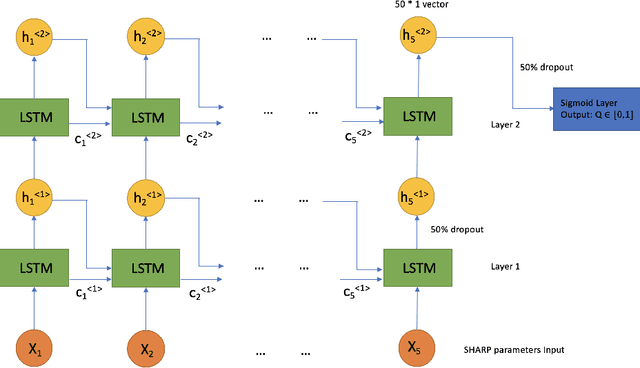
We conduct a post hoc analysis of solar flare predictions made by a Long Short Term Memory (LSTM) model employing data in the form of Space-weather HMI Active Region Patches (SHARP) parameters. These data are distinguished in that the parameters are calculated from data in proximity to the magnetic polarity inversion line where the flares originate. We train the the LSTM model for binary classification to provide a prediction score for the probability of M/X class flares to occur in next hour. We then develop a dimension-reduction technique to reduce the dimensions of SHARP parameter (LSTM inputs) and demonstrate the different patterns of SHARP parameters corresponding to the transition from low to high prediction score. Our work shows that a subset of SHARP parameters contain the key signals that strong solar flare eruptions are imminent. The dynamics of these parameters have a highly uniform trajectory for many events whose LSTM prediction scores for M/X class flares transition from very low to very high. The results suggest that there exist a few threshold values of a subset of SHARP parameters when surpassed could indicate a high probability of strong flare eruption. Our method has distilled the knowledge of solar flare eruption learnt by deep learning model and provides a more interpretable approximation where more physics related insights could be derived.
Corrupted Contextual Bandits with Action Order Constraints
Nov 16, 2020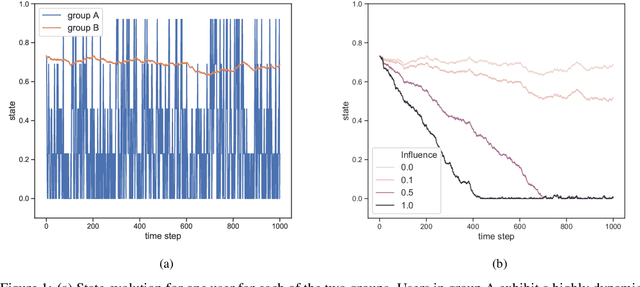
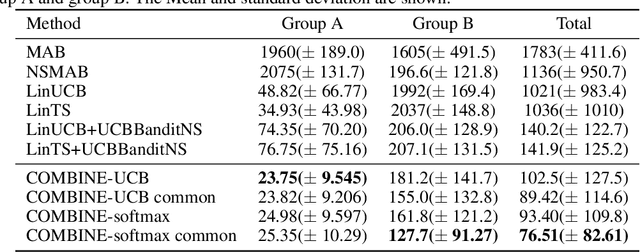
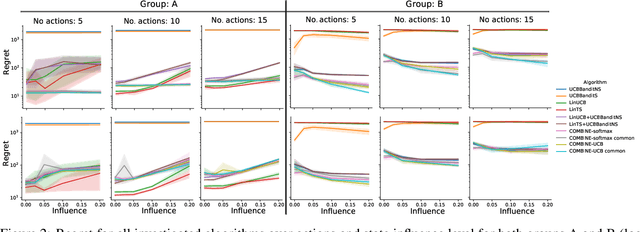
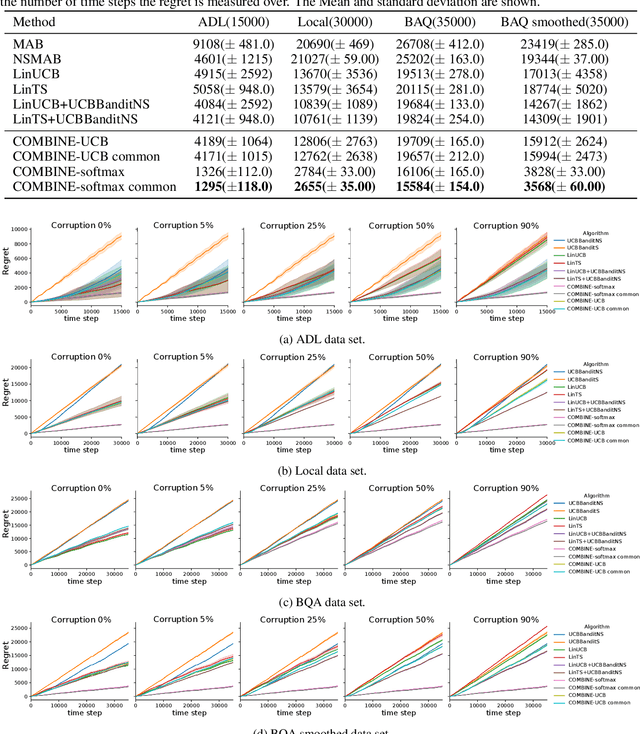
We consider a variant of the novel contextual bandit problem with corrupted context, which we call the contextual bandit problem with corrupted context and action correlation, where actions exhibit a relationship structure that can be exploited to guide the exploration of viable next decisions. Our setting is primarily motivated by adaptive mobile health interventions and related applications, where users might transitions through different stages requiring more targeted action selection approaches. In such settings, keeping user engagement is paramount for the success of interventions and therefore it is vital to provide relevant recommendations in a timely manner. The context provided by users might not always be informative at every decision point and standard contextual approaches to action selection will incur high regret. We propose a meta-algorithm using a referee that dynamically combines the policies of a contextual bandit and multi-armed bandit, similar to previous work, as wells as a simple correlation mechanism that captures action to action transition probabilities allowing for more efficient exploration of time-correlated actions. We evaluate empirically the performance of said algorithm on a simulation where the sequence of best actions is determined by a hidden state that evolves in a Markovian manner. We show that the proposed meta-algorithm improves upon regret in situations where the performance of both policies varies such that one is strictly superior to the other for a given time period. To demonstrate that our setting has relevant practical applicability, we evaluate our method on several real world data sets, clearly showing better empirical performance compared to a set of simple algorithms.
ERNIE-DOC: The Retrospective Long-Document Modeling Transformer
Dec 31, 2020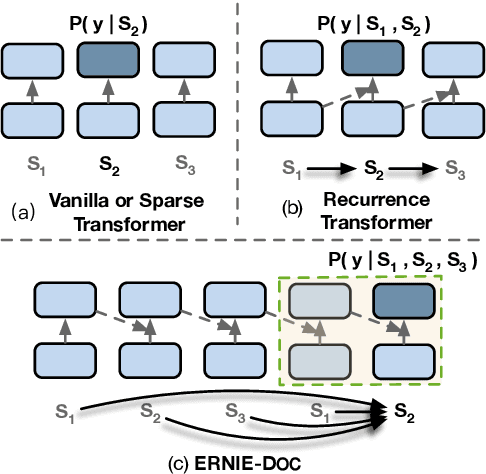
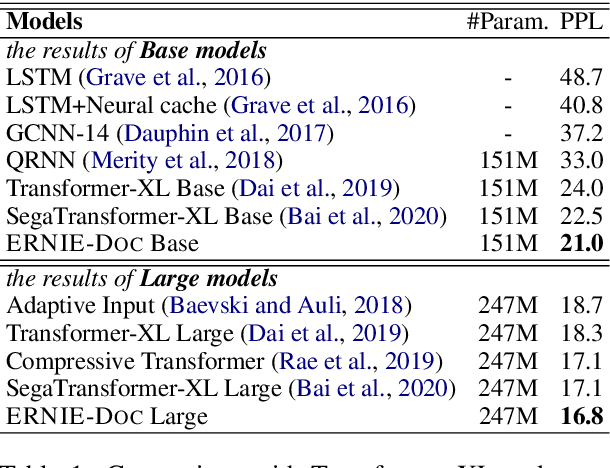
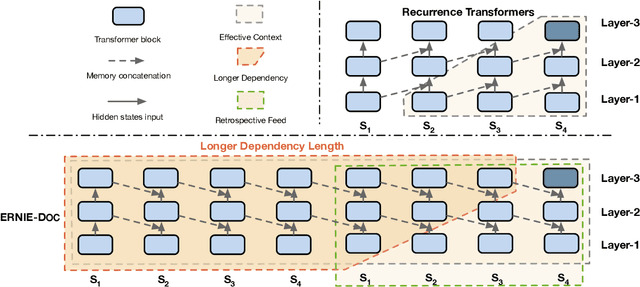
Transformers are not suited for processing long document input due to its quadratically increasing memory and time consumption. Simply truncating a long document or applying the sparse attention mechanism will incur the context fragmentation problem or inferior modeling capability with comparable model size. In this paper, we propose ERNIE-DOC, a document-level language pretraining model based on Recurrence Transformers. Two well-designed techniques, namely the retrospective feed mechanism and the enhanced recurrence mechanism enable ERNIE-DOC with much longer effective context length to capture the contextual information of a whole document. We pretrain ERNIE-DOC to explicitly learn the relationship among segments with an additional document-aware segment reordering objective. Various experiments on both English and Chinese document-level tasks are conducted. ERNIE-DOC achieves SOTA language modeling result of 16.8 ppl on WikiText-103 and outperforms competitive pretraining models on most language understanding tasks such as text classification, question answering by a large margin.
Pretraining and Fine-Tuning Strategies for Sentiment Analysis of Latvian Tweets
Oct 23, 2020
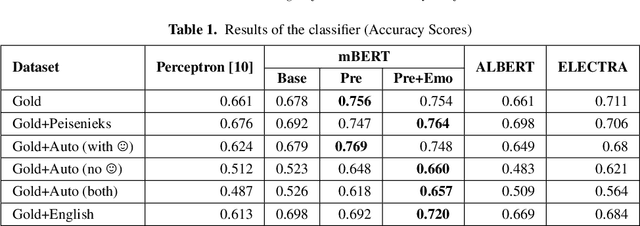

In this paper, we present various pre-training strategies that aid in im-proving the accuracy of the sentiment classification task. We, at first, pre-trainlanguage representation models using these strategies and then fine-tune them onthe downstream task. Experimental results on a time-balanced tweet evaluation setshow the improvement over the previous technique. We achieve 76% accuracy forsentiment analysis on Latvian tweets, which is a substantial improvement over pre-vious work
Asking Crowdworkers to Write Entailment Examples: The Best of Bad Options
Oct 13, 2020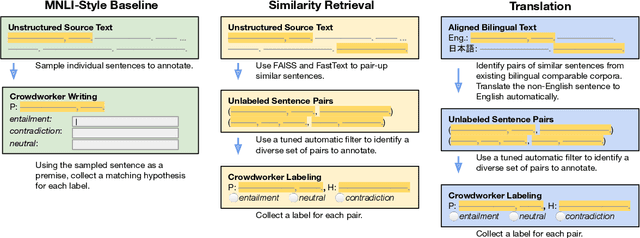

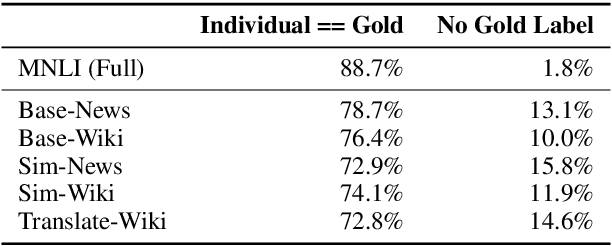

Large-scale natural language inference (NLI) datasets such as SNLI or MNLI have been created by asking crowdworkers to read a premise and write three new hypotheses, one for each possible semantic relationships (entailment, contradiction, and neutral). While this protocol has been used to create useful benchmark data, it remains unclear whether the writing-based annotation protocol is optimal for any purpose, since it has not been evaluated directly. Furthermore, there is ample evidence that crowdworker writing can introduce artifacts in the data. We investigate two alternative protocols which automatically create candidate (premise, hypothesis) pairs for annotators to label. Using these protocols and a writing-based baseline, we collect several new English NLI datasets of over 3k examples each, each using a fixed amount of annotator time, but a varying number of examples to fit that time budget. Our experiments on NLI and transfer learning show negative results: None of the alternative protocols outperforms the baseline in evaluations of generalization within NLI or on transfer to outside target tasks. We conclude that crowdworker writing still the best known option for entailment data, highlighting the need for further data collection work to focus on improving writing-based annotation processes.
Zeus: A System Description of the Two-Time Winner of the Collegiate SAE AutoDrive Competition
Apr 19, 2020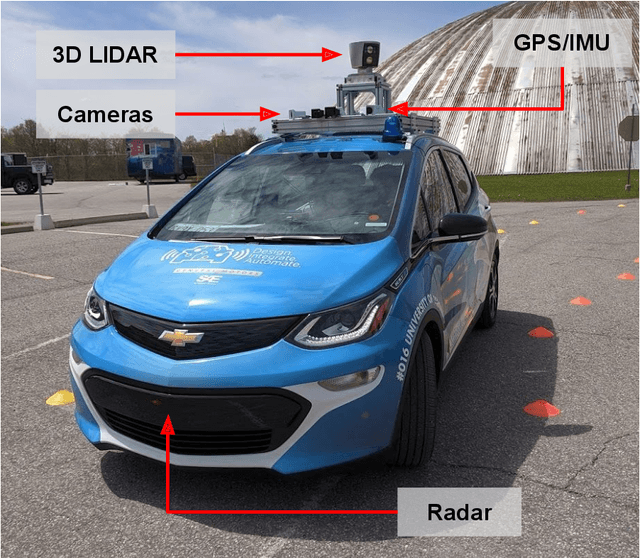


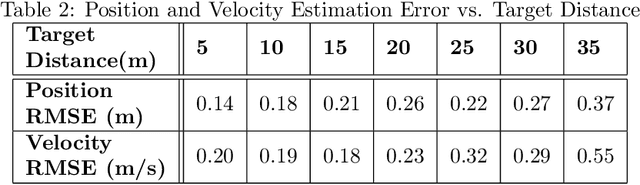
The SAE AutoDrive Challenge is a three-year collegiate competition to develop a self-driving car by 2020. The second year of the competition was held in June 2019 at MCity, a mock town built for self-driving car testing at the University of Michigan. Teams were required to autonomously navigate a series of intersections while handling pedestrians, traffic lights, and traffic signs. Zeus is aUToronto's winning entry in the AutoDrive Challenge. This article describes the system design and development of Zeus as well as many of the lessons learned along the way. This includes details on the team's organizational structure, sensor suite, software components, and performance at the Year 2 competition. With a team of mostly undergraduates and minimal resources, aUToronto has made progress towards a functioning self-driving vehicle, in just two years. This article may prove valuable to researchers looking to develop their own self-driving platform.
Prediction of the onset of cardiovascular diseases from electronic health records using multi-task gated recurrent units
Jul 16, 2020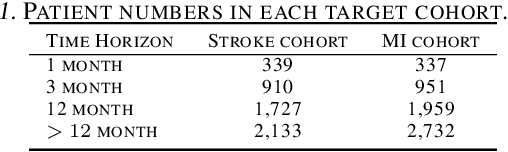
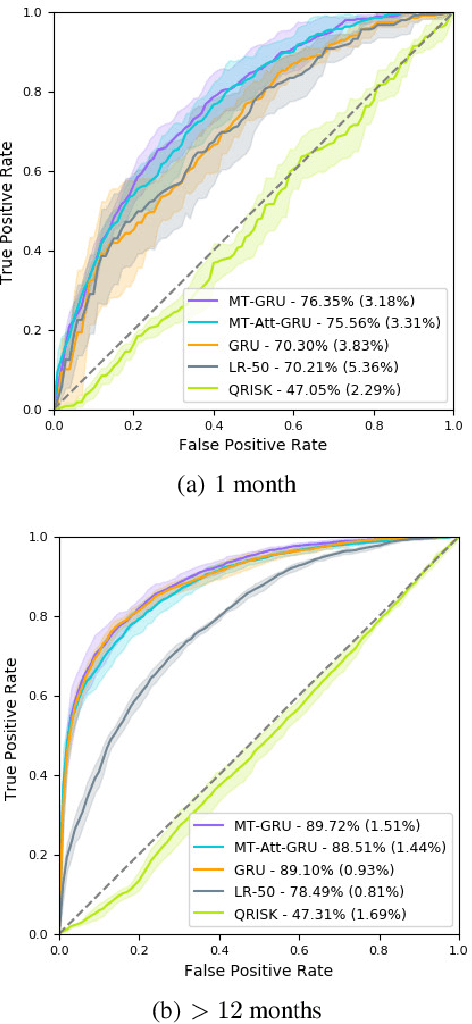
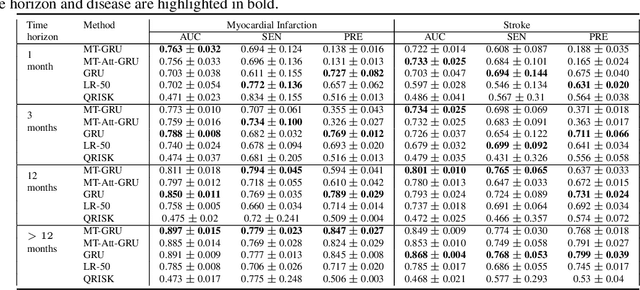
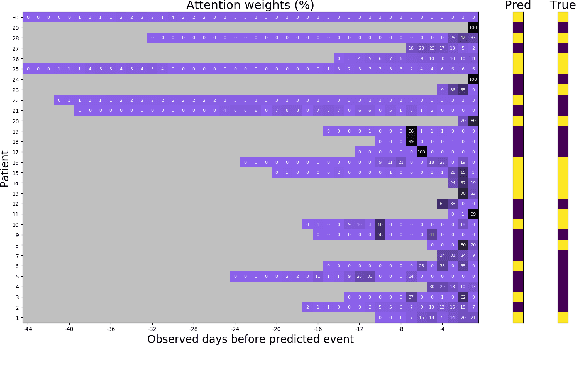
In this work, we propose a multi-task recurrent neural network with attention mechanism for predicting cardiovascular events from electronic health records (EHRs) at different time horizons. The proposed approach is compared to a standard clinical risk predictor (QRISK) and machine learning alternatives using 5-year data from a NHS Foundation Trust. The proposed model outperforms standard clinical risk scores in predicting stroke (AUC=0.85) and myocardial infarction (AUC=0.89), considering the largest time horizon. Benefit of using an \gls{mt} setting becomes visible for very short time horizons, which results in an AUC increase between 2-6%. Further, we explored the importance of individual features and attention weights in predicting cardiovascular events. Our results indicate that the recurrent neural network approach benefits from the hospital longitudinal information and demonstrates how machine learning techniques can be applied to secondary care.