 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Psychoacoustic Calibration of Loss Functions for Efficient End-to-End Neural Audio Coding
Dec 31, 2020
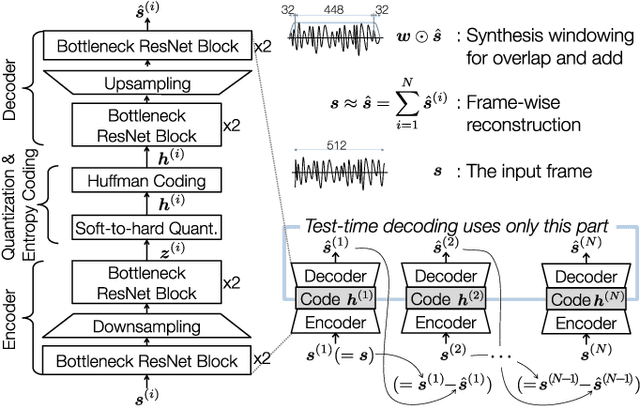
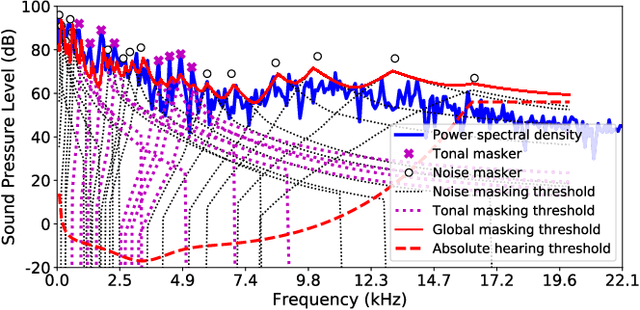
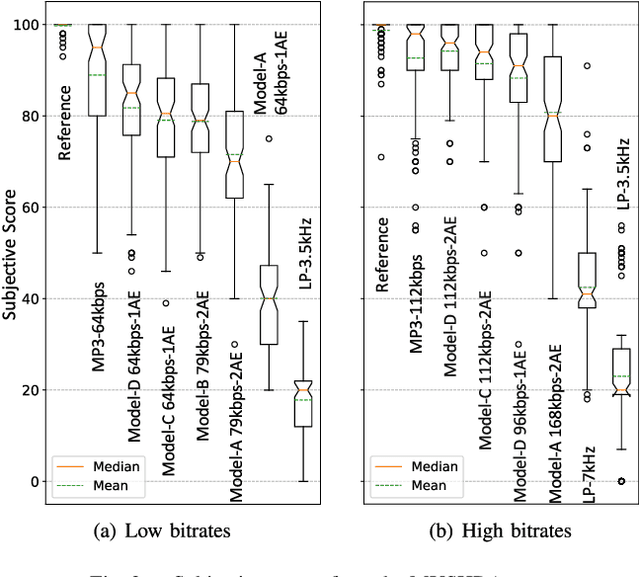
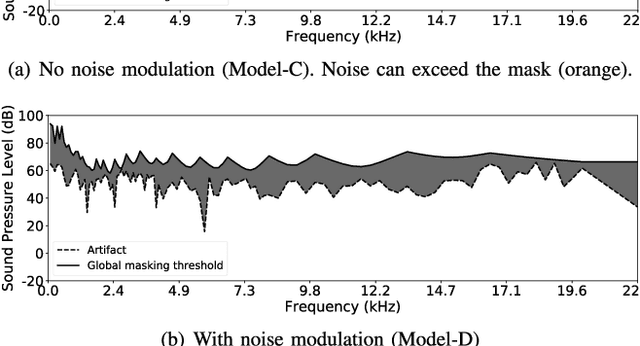
Conventional audio coding technologies commonly leverage human perception of sound, or psychoacoustics, to reduce the bitrate while preserving the perceptual quality of the decoded audio signals. For neural audio codecs, however, the objective nature of the loss function usually leads to suboptimal sound quality as well as high run-time complexity due to the large model size. In this work, we present a psychoacoustic calibration scheme to re-define the loss functions of neural audio coding systems so that it can decode signals more perceptually similar to the reference, yet with a much lower model complexity. The proposed loss function incorporates the global masking threshold, allowing the reconstruction error that corresponds to inaudible artifacts. Experimental results show that the proposed model outperforms the baseline neural codec twice as large and consuming 23.4% more bits per second. With the proposed method, a lightweight neural codec, with only 0.9 million parameters, performs near-transparent audio coding comparable with the commercial MPEG-1 Audio Layer III codec at 112 kbps.
Hybrid and Non-Uniform quantization methods using retro synthesis data for efficient inference
Dec 26, 2020
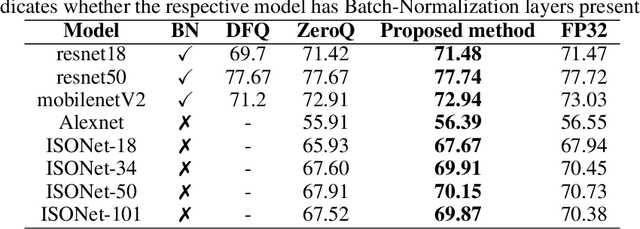
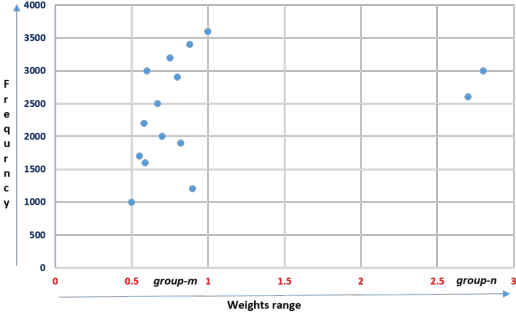

Existing quantization aware training methods attempt to compensate for the quantization loss by leveraging on training data, like most of the post-training quantization methods, and are also time consuming. Both these methods are not effective for privacy constraint applications as they are tightly coupled with training data. In contrast, this paper proposes a data-independent post-training quantization scheme that eliminates the need for training data. This is achieved by generating a faux dataset, hereafter referred to as Retro-Synthesis Data, from the FP32 model layer statistics and further using it for quantization. This approach outperformed state-of-the-art methods including, but not limited to, ZeroQ and DFQ on models with and without Batch-Normalization layers for 8, 6, and 4 bit precisions on ImageNet and CIFAR-10 datasets. We also introduced two futuristic variants of post-training quantization methods namely Hybrid Quantization and Non-Uniform Quantization
Fully Non-autoregressive Neural Machine Translation: Tricks of the Trade
Dec 31, 2020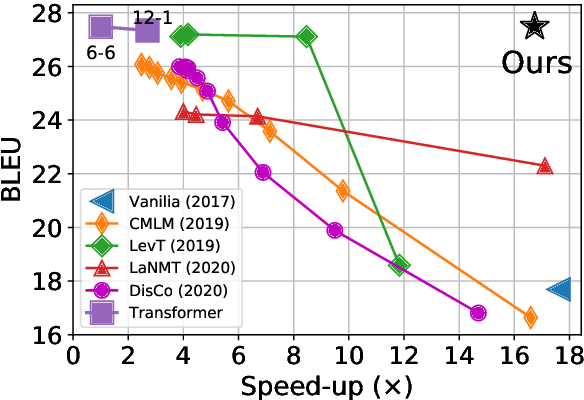
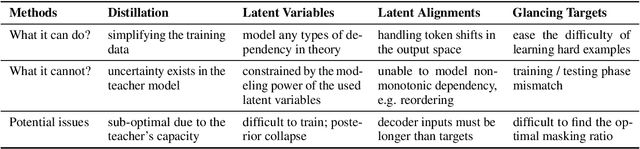

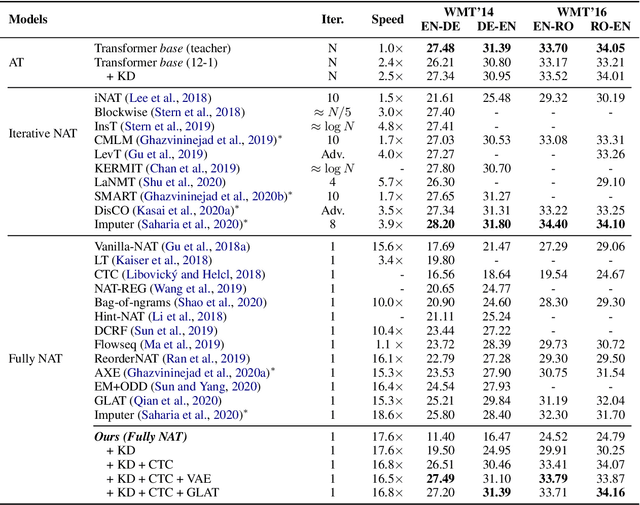
Fully non-autoregressive neural machine translation (NAT) is proposed to simultaneously predict tokens with single forward of neural networks, which significantly reduces the inference latency at the expense of quality drop compared to the Transformer baseline. In this work, we target on closing the performance gap while maintaining the latency advantage. We first inspect the fundamental issues of fully NAT models, and adopt dependency reduction in the learning space of output tokens as the basic guidance. Then, we revisit methods in four different aspects that have been proven effective for improving NAT models, and carefully combine these techniques with necessary modifications. Our extensive experiments on three translation benchmarks show that the proposed system achieves the new state-of-the-art results for fully NAT models, and obtains comparable performance with the autoregressive and iterative NAT systems. For instance, one of the proposed models achieves 27.49 BLEU points on WMT14 En-De with approximately 16.5X speed up at inference time.
Beyond 4D Tracking: Using Cluster Shapes for Track Seeding
Dec 08, 2020



Tracking is one of the most time consuming aspects of event reconstruction at the Large Hadron Collider (LHC) and its high-luminosity upgrade (HL-LHC). Innovative detector technologies extend tracking to four-dimensions by including timing in the pattern recognition and parameter estimation. However, present and future hardware already have additional information that is largely unused by existing track seeding algorithms. The shape of clusters provides an additional dimension for track seeding that can significantly reduce the combinatorial challenge of track finding. We use neural networks to show that cluster shapes can reduce significantly the rate of fake combinatorical backgrounds while preserving a high efficiency. We demonstrate this using the information in cluster singlets, doublets and triplets. Numerical results are presented with simulations from the TrackML challenge.
ERNIE-DOC: The Retrospective Long-Document Modeling Transformer
Dec 31, 2020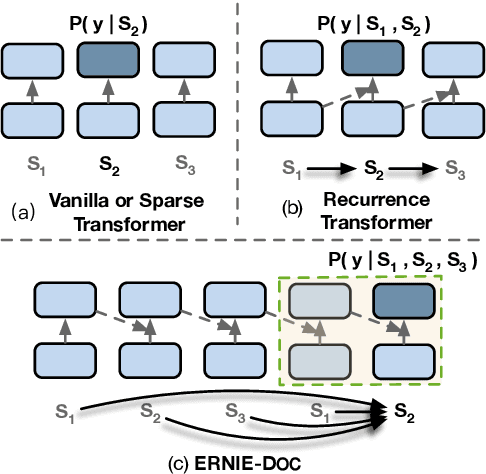
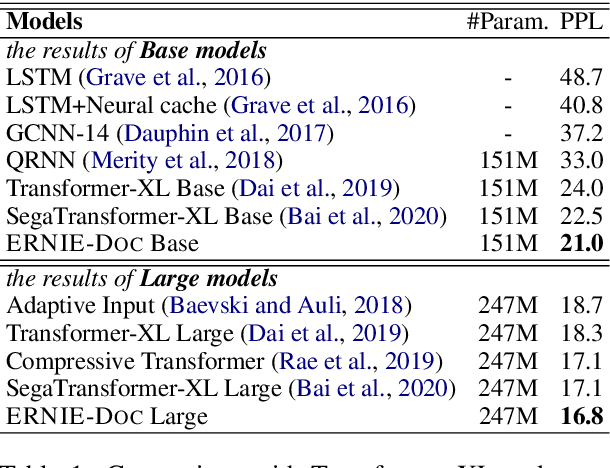
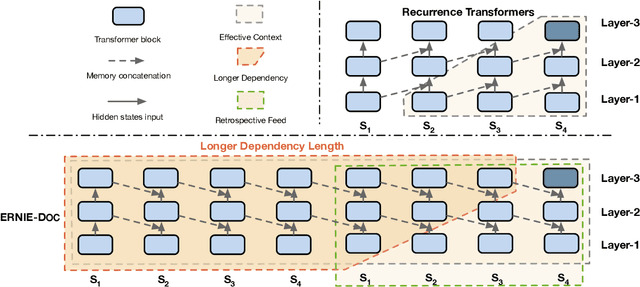
Transformers are not suited for processing long document input due to its quadratically increasing memory and time consumption. Simply truncating a long document or applying the sparse attention mechanism will incur the context fragmentation problem or inferior modeling capability with comparable model size. In this paper, we propose ERNIE-DOC, a document-level language pretraining model based on Recurrence Transformers. Two well-designed techniques, namely the retrospective feed mechanism and the enhanced recurrence mechanism enable ERNIE-DOC with much longer effective context length to capture the contextual information of a whole document. We pretrain ERNIE-DOC to explicitly learn the relationship among segments with an additional document-aware segment reordering objective. Various experiments on both English and Chinese document-level tasks are conducted. ERNIE-DOC achieves SOTA language modeling result of 16.8 ppl on WikiText-103 and outperforms competitive pretraining models on most language understanding tasks such as text classification, question answering by a large margin.
Deep Dynamic Factor Models
Jul 23, 2020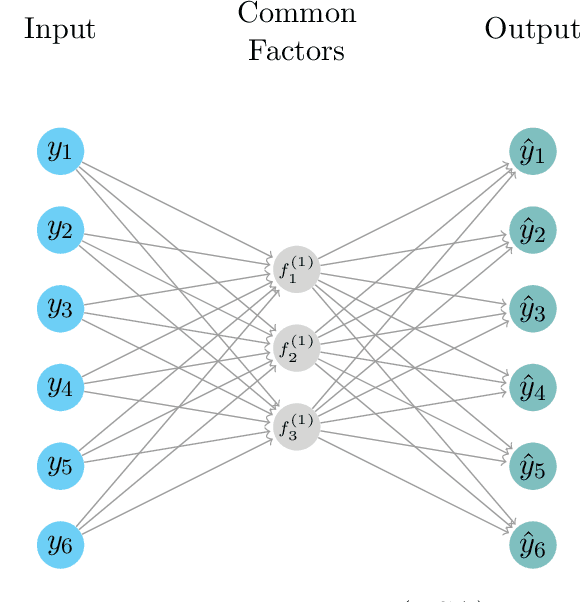

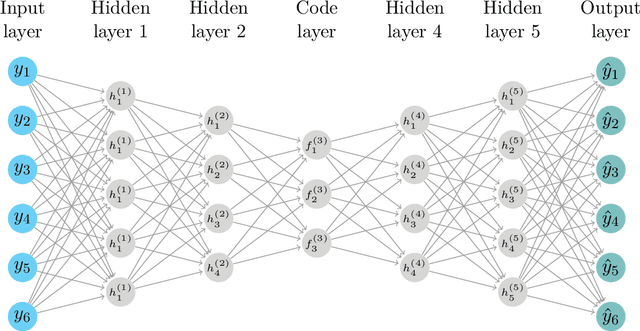
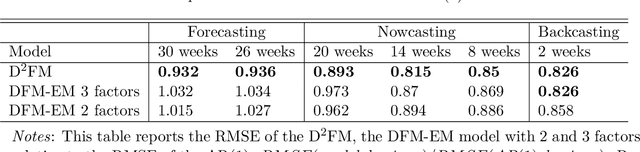
We propose a novel deep neural net framework - that we refer to as Deep Dynamic Factor Model (D2FM) -, to encode the information available, from hundreds of macroeconomic and financial time-series into a handful of unobserved latent states. While similar in spirit to traditional dynamic factor models (DFMs), differently from those, this new class of models allows for nonlinearities between factors and observables due to the deep neural net structure. However, by design, the latent states of the model can still be interpreted as in a standard factor model. In an empirical application to the forecast and nowcast of economic conditions in the US, we show the potential of this framework in dealing with high dimensional, mixed frequencies and asynchronously published time series data. In a fully real-time out-of-sample exercise with US data, the D2FM improves over the performances of a state-of-the-art DFM.
Nonlinear Invariant Risk Minimization: A Causal Approach
Feb 24, 2021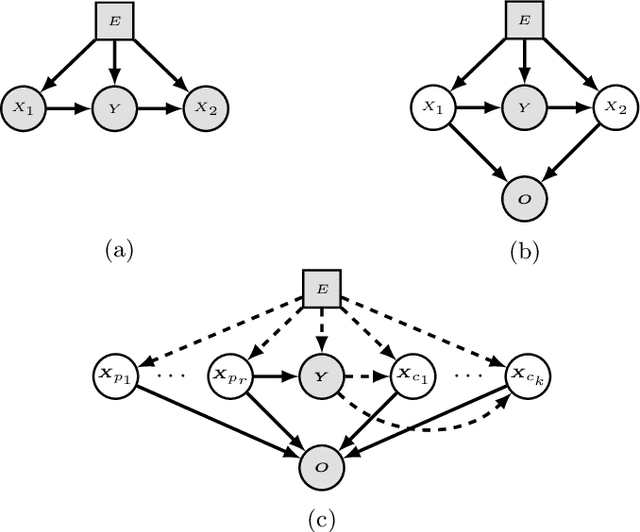
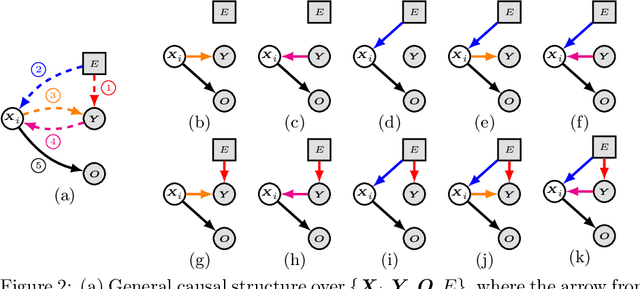
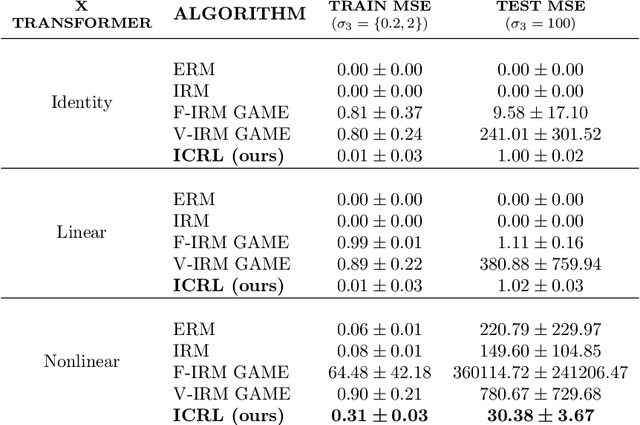
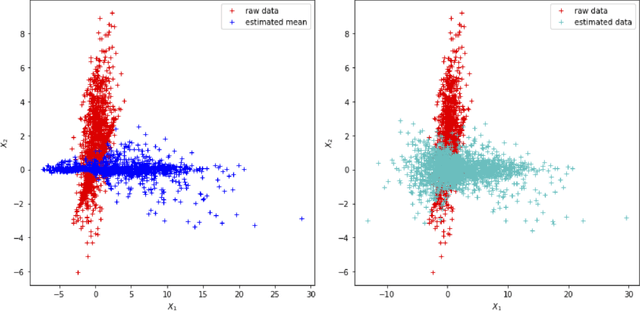
Due to spurious correlations, machine learning systems often fail to generalize to environments whose distributions differ from the ones used at training time. Prior work addressing this, either explicitly or implicitly, attempted to find a data representation that has an invariant causal relationship with the target. This is done by leveraging a diverse set of training environments to reduce the effect of spurious features and build an invariant predictor. However, these methods have generalization guarantees only when both data representation and classifiers come from a linear model class. We propose Invariant Causal Representation Learning (ICRL), a learning paradigm that enables out-of-distribution (OOD) generalization in the nonlinear setting (i.e., nonlinear representations and nonlinear classifiers). It builds upon a practical and general assumption: the prior over the data representation factorizes when conditioning on the target and the environment. Based on this, we show identifiability of the data representation up to very simple transformations. We also prove that all direct causes of the target can be fully discovered, which further enables us to obtain generalization guarantees in the nonlinear setting. Extensive experiments on both synthetic and real-world datasets show that our approach significantly outperforms a variety of baseline methods. Finally, in the concluding discussion, we further explore the aforementioned assumption and propose a general view, called the Agnostic Hypothesis: there exist a set of hidden causal factors affecting both inputs and outcomes. The Agnostic Hypothesis can provide a unifying view of machine learning in terms of representation learning. More importantly, it can inspire a new direction to explore the general theory for identifying hidden causal factors, which is key to enabling the OOD generalization guarantees in machine learning.
Shortening Time Required for Adaptive Structural Learning Method of Deep Belief Network with Multi-Modal Data Arrangement
Jul 11, 2018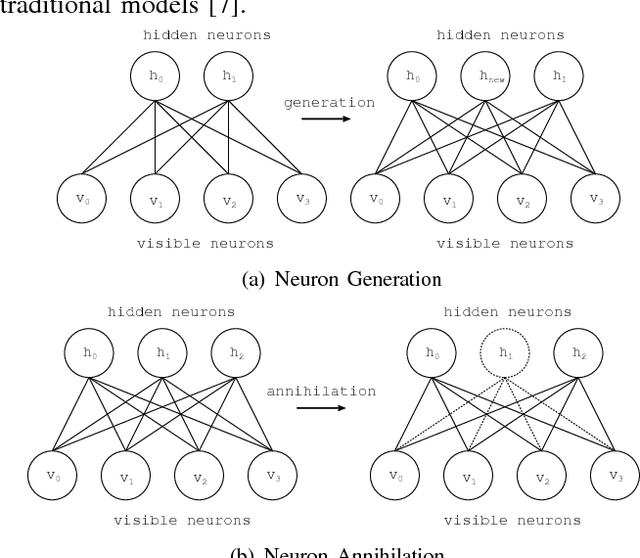
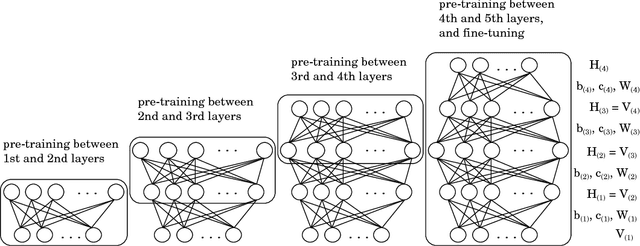
Recently, Deep Learning has been applied in the techniques of artificial intelligence. Especially, Deep Learning performed good results in the field of image recognition. Most new Deep Learning architectures are naturally developed in image recognition. For this reason, not only the numerical data and text data but also the time-series data are transformed to the image data format. Multi-modal data consists of two or more kinds of data such as picture and text. The arrangement in a general method is formed in the squared array with no specific aim. In this paper, the data arrangement are modified according to the similarity of input-output pattern in Adaptive Structural Learning method of Deep Belief Network. The similarity of output signals of hidden neurons is made by the order rearrangement of hidden neurons. The experimental results for the data rearrangement in squared array showed the shortening time required for DBN learning.
Corrupted Contextual Bandits with Action Order Constraints
Nov 16, 2020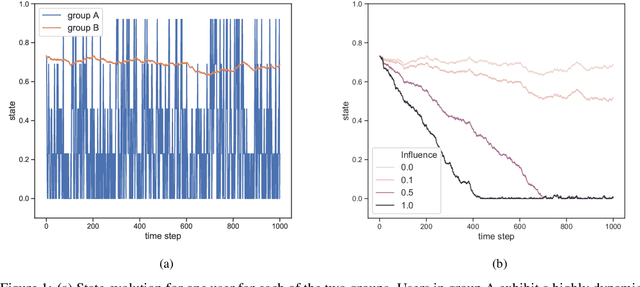
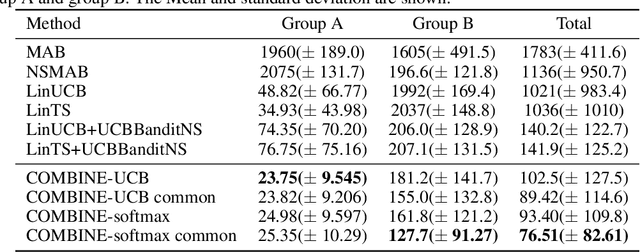
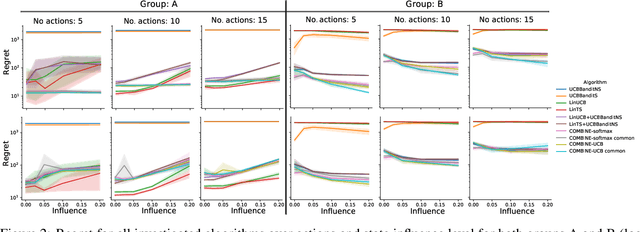
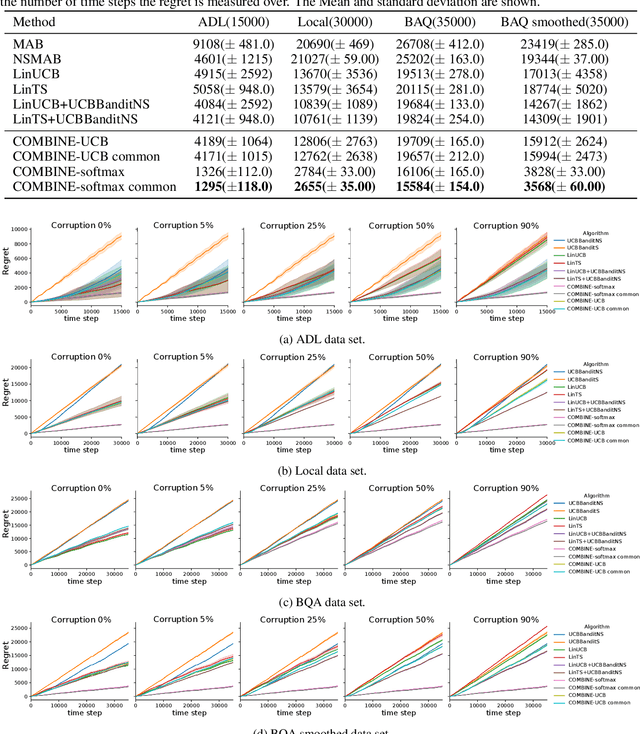
We consider a variant of the novel contextual bandit problem with corrupted context, which we call the contextual bandit problem with corrupted context and action correlation, where actions exhibit a relationship structure that can be exploited to guide the exploration of viable next decisions. Our setting is primarily motivated by adaptive mobile health interventions and related applications, where users might transitions through different stages requiring more targeted action selection approaches. In such settings, keeping user engagement is paramount for the success of interventions and therefore it is vital to provide relevant recommendations in a timely manner. The context provided by users might not always be informative at every decision point and standard contextual approaches to action selection will incur high regret. We propose a meta-algorithm using a referee that dynamically combines the policies of a contextual bandit and multi-armed bandit, similar to previous work, as wells as a simple correlation mechanism that captures action to action transition probabilities allowing for more efficient exploration of time-correlated actions. We evaluate empirically the performance of said algorithm on a simulation where the sequence of best actions is determined by a hidden state that evolves in a Markovian manner. We show that the proposed meta-algorithm improves upon regret in situations where the performance of both policies varies such that one is strictly superior to the other for a given time period. To demonstrate that our setting has relevant practical applicability, we evaluate our method on several real world data sets, clearly showing better empirical performance compared to a set of simple algorithms.
Deep learning in magnetic resonance prostate segmentation: A review and a new perspective
Nov 16, 2020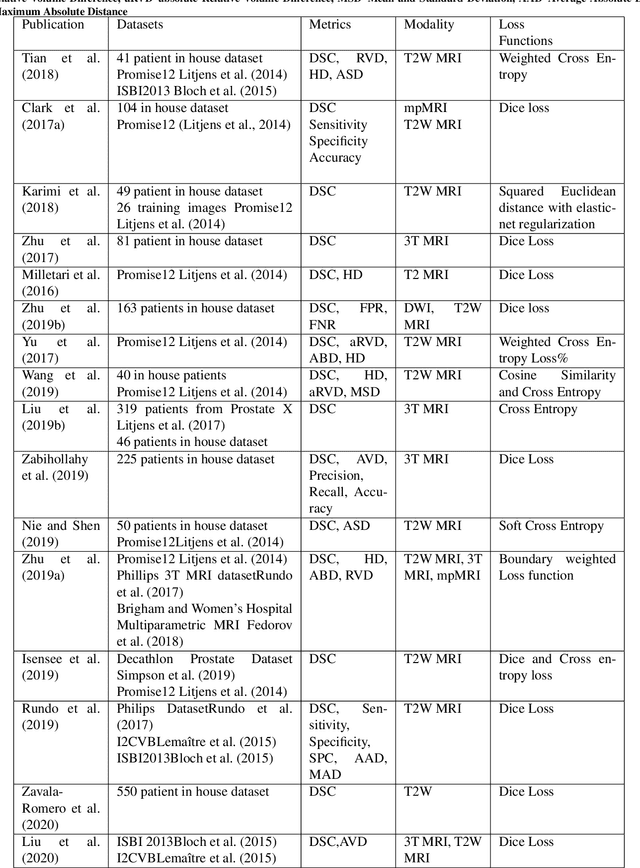
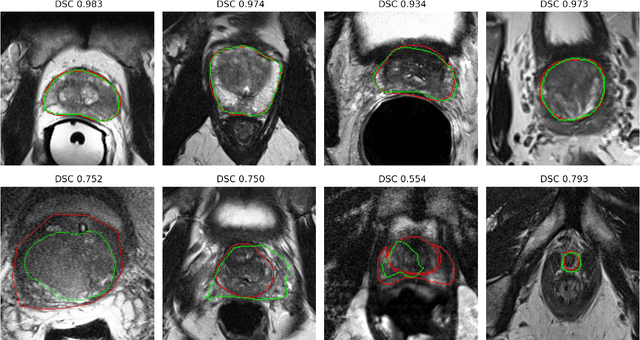
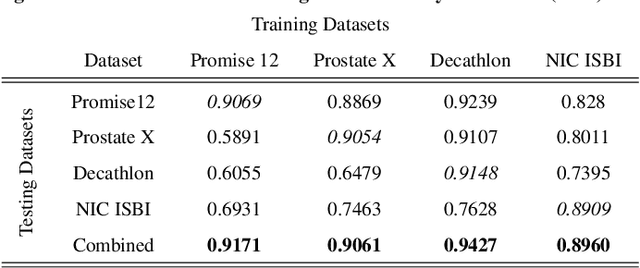
Prostate radiotherapy is a well established curative oncology modality, which in future will use Magnetic Resonance Imaging (MRI)-based radiotherapy for daily adaptive radiotherapy target definition. However the time needed to delineate the prostate from MRI data accurately is a time consuming process. Deep learning has been identified as a potential new technology for the delivery of precision radiotherapy in prostate cancer, where accurate prostate segmentation helps in cancer detection and therapy. However, the trained models can be limited in their application to clinical setting due to different acquisition protocols, limited publicly available datasets, where the size of the datasets are relatively small. Therefore, to explore the field of prostate segmentation and to discover a generalisable solution, we review the state-of-the-art deep learning algorithms in MR prostate segmentation; provide insights to the field by discussing their limitations and strengths; and propose an optimised 2D U-Net for MR prostate segmentation. We evaluate the performance on four publicly available datasets using Dice Similarity Coefficient (DSC) as performance metric. Our experiments include within dataset evaluation and cross-dataset evaluation. The best result is achieved by composite evaluation (DSC of 0.9427 on Decathlon test set) and the poorest result is achieved by cross-dataset evaluation (DSC of 0.5892, Prostate X training set, Promise 12 testing set). We outline the challenges and provide recommendations for future work. Our research provides a new perspective to MR prostate segmentation and more importantly, we provide standardised experiment settings for researchers to evaluate their algorithms. Our code is available at https://github.com/AIEMMU/MRI\_Prostate.