 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Point Cloud Registration Framework Based on Deep Graph Matching
Mar 07, 2021
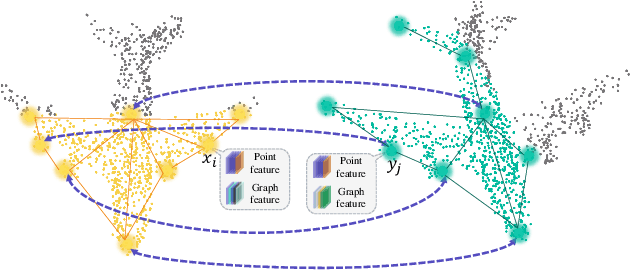
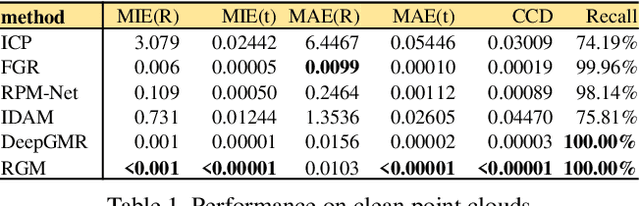
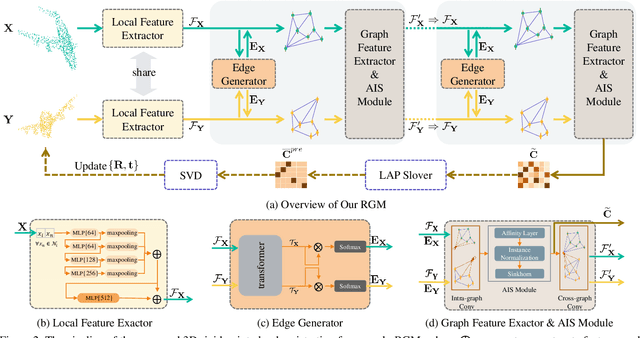
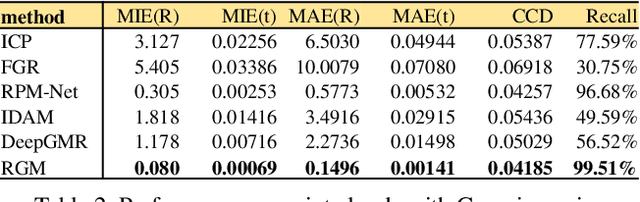
3D point cloud registration is a fundamental problem in computer vision and robotics. There has been extensive research in this area, but existing methods meet great challenges in situations with a large proportion of outliers and time constraints, but without good transformation initialization. Recently, a series of learning-based algorithms have been introduced and show advantages in speed. Many of them are based on correspondences between the two point clouds, so they do not rely on transformation initialization. However, these learning-based methods are sensitive to outliers, which lead to more incorrect correspondences. In this paper, we propose a novel deep graph matchingbased framework for point cloud registration. Specifically, we first transform point clouds into graphs and extract deep features for each point. Then, we develop a module based on deep graph matching to calculate a soft correspondence matrix. By using graph matching, not only the local geometry of each point but also its structure and topology in a larger range are considered in establishing correspondences, so that more correct correspondences are found. We train the network with a loss directly defined on the correspondences, and in the test stage the soft correspondences are transformed into hard one-to-one correspondences so that registration can be performed by singular value decomposition. Furthermore, we introduce a transformer-based method to generate edges for graph construction, which further improves the quality of the correspondences. Extensive experiments on registering clean, noisy, partial-to-partial and unseen category point clouds show that the proposed method achieves state-of-the-art performance. The code will be made publicly available at https://github.com/fukexue/RGM.
Semantically Meaningful Class Prototype Learning for One-Shot Image Semantic Segmentation
Feb 22, 2021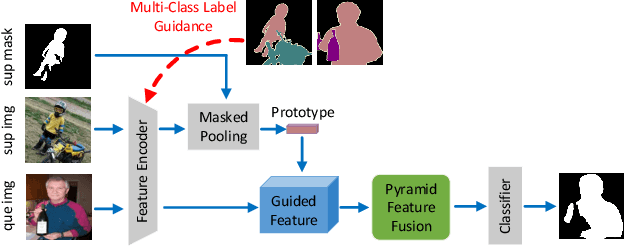
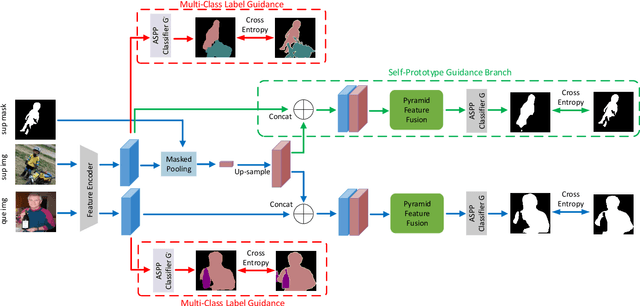
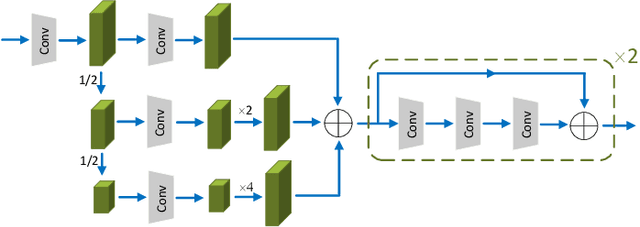
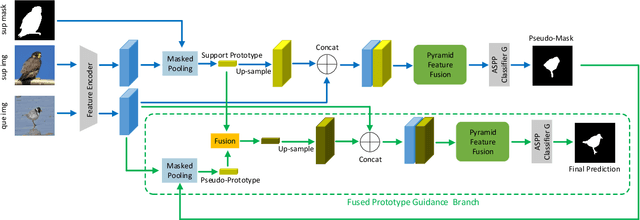
One-shot semantic image segmentation aims to segment the object regions for the novel class with only one annotated image. Recent works adopt the episodic training strategy to mimic the expected situation at testing time. However, these existing approaches simulate the test conditions too strictly during the training process, and thus cannot make full use of the given label information. Besides, these approaches mainly focus on the foreground-background target class segmentation setting. They only utilize binary mask labels for training. In this paper, we propose to leverage the multi-class label information during the episodic training. It will encourage the network to generate more semantically meaningful features for each category. After integrating the target class cues into the query features, we then propose a pyramid feature fusion module to mine the fused features for the final classifier. Furthermore, to take more advantage of the support image-mask pair, we propose a self-prototype guidance branch to support image segmentation. It can constrain the network for generating more compact features and a robust prototype for each semantic class. For inference, we propose a fused prototype guidance branch for the segmentation of the query image. Specifically, we leverage the prediction of the query image to extract the pseudo-prototype and combine it with the initial prototype. Then we utilize the fused prototype to guide the final segmentation of the query image. Extensive experiments demonstrate the superiority of our proposed approach.
Coupling innovation method and feasibility analysis of garbage classification
Jan 30, 2021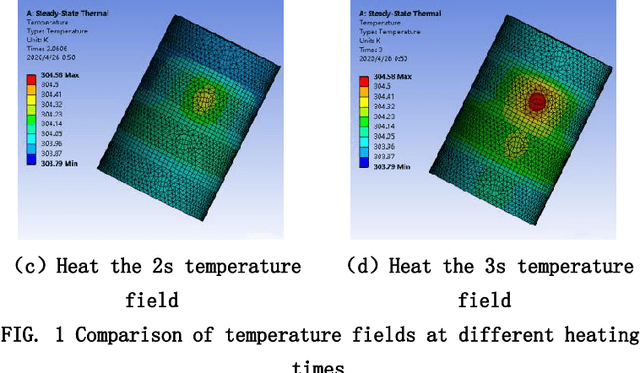
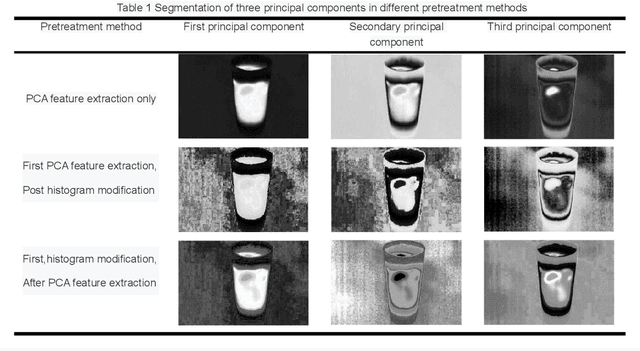
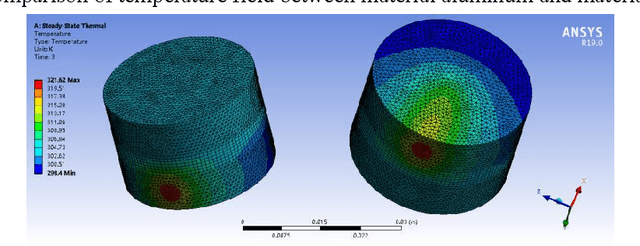
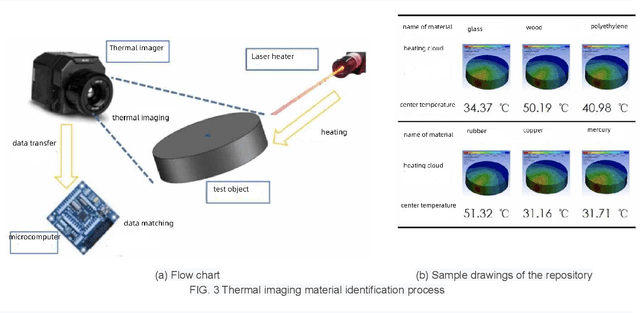
In order to solve the recent defect in garbage classification - including low level of intelligence, low accuracy and high cost of equipment, this paper presents a series of methods in identification and judgment in intelligent garbage classification, including a material identification based on thermal principle and non-destructive laser irradiation, another material identification based on optical diffraction and phase analysis, a profile identification which utilizes a scenery thermal image after PCA and histogram correction, another profile identification which utilizes computer vision with innovated data sets and algorithms. Combining AHP and Bayesian formula, the paper innovates a coupling algorithm which helps to make a comprehensive judgment of the garbage sort, based on the material and profile identification. This paper also proposes a method for real-time space measurement of garbage cans, which based on the characteristics of air as fluid, and analyses the functions of air cleaning and particle disposing. Instead of the single use of garbage image recognition, this paper provides a comprehensive method to judge the garbage sort by material and profile identifications, which greatly enhancing the accuracy and intelligence in garbage classification.
Noisy intermediate-scale quantum (NISQ) algorithms
Jan 21, 2021
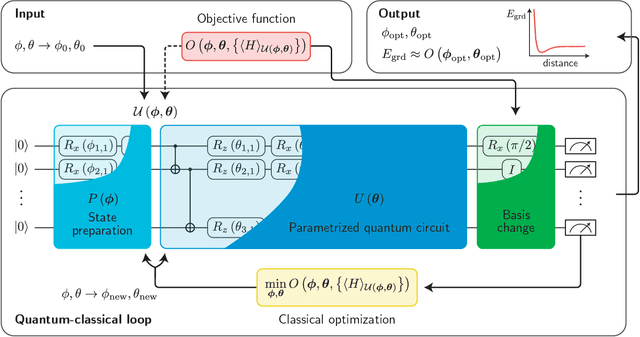
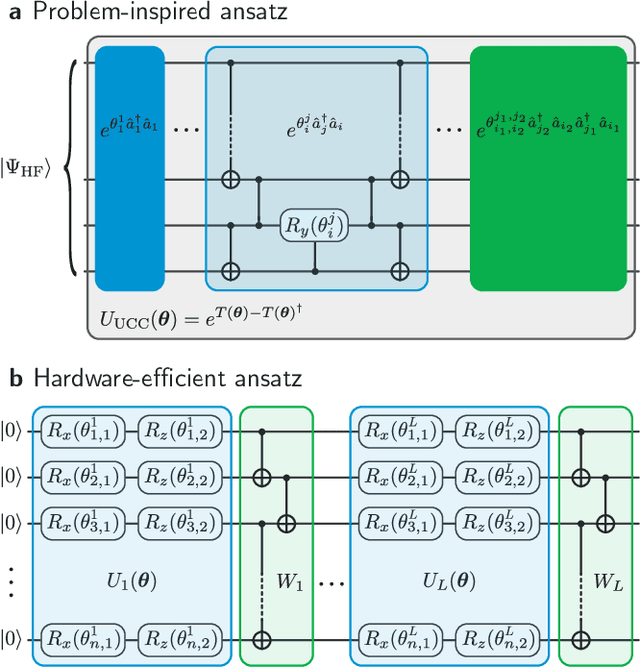
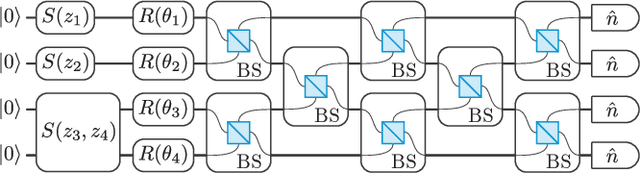
A universal fault-tolerant quantum computer that can solve efficiently problems such as integer factorization and unstructured database search requires millions of qubits with low error rates and long coherence times. While the experimental advancement towards realizing such devices will potentially take decades of research, noisy intermediate-scale quantum (NISQ) computers already exist. These computers are composed of hundreds of noisy qubits, i.e. qubits that are not error-corrected, and therefore perform imperfect operations in a limited coherence time. In the search for quantum advantage with these devices, algorithms have been proposed for applications in various disciplines spanning physics, machine learning, quantum chemistry and combinatorial optimization. The goal of such algorithms is to leverage the limited available resources to perform classically challenging tasks. In this review, we provide a thorough summary of NISQ computational paradigms and algorithms. We discuss the key structure of these algorithms, their limitations, and advantages. We additionally provide a comprehensive overview of various benchmarking and software tools useful for programming and testing NISQ devices.
MIN2Net: End-to-End Multi-Task Learning for Subject-Independent Motor Imagery EEG Classification
Feb 07, 2021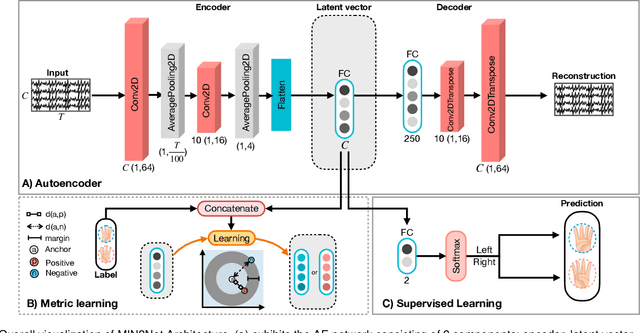
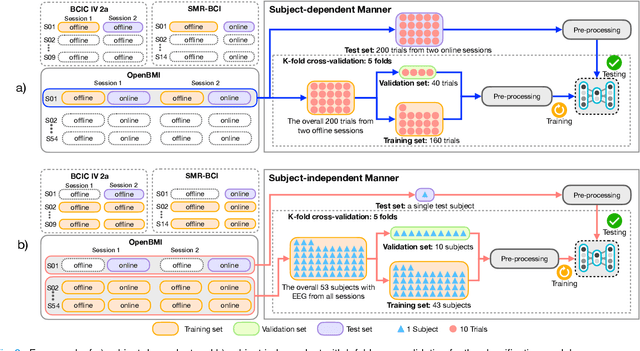
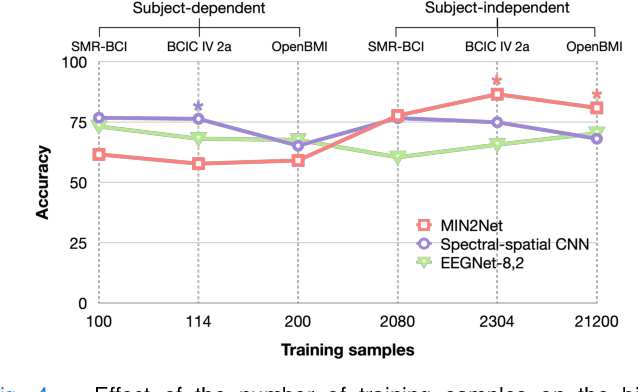
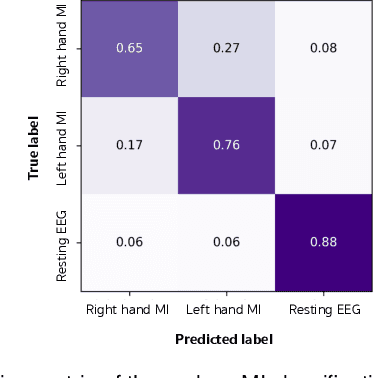
Advances in the motor imagery (MI)-based brain-computer interfaces (BCIs) allow control of several applications by decoding neurophysiological phenomena, which are usually recorded by electroencephalography (EEG) using a non-invasive technique. Despite great advances in MI-based BCI, EEG rhythms are specific to a subject and various changes over time. These issues point to significant challenges to enhance the classification performance, especially in a subject-independent manner. To overcome these challenges, we propose MIN2Net, a novel end-to-end multi-task learning to tackle this task. We integrate deep metric learning into a multi-task autoencoder to learn a compact and discriminative latent representation from EEG and perform classification simultaneously. This approach reduces the complexity in pre-processing, results in significant performance improvement on EEG classification. Experimental results in a subject-independent manner show that MIN2Net outperforms the state-of-the-art techniques, achieving an accuracy improvement of 11.65%, 1.03%, and 10.53% on the BCI competition IV 2a, SMR-BCI, and OpenBMI datasets, respectively. We demonstrate that MIN2Net improves discriminative information in the latent representation. This study indicates the possibility and practicality of using this model to develop MI-based BCI applications for new users without the need for calibration.
Maximizing Joint Entropy for Batch-Mode Active Learning of Perceptual Metrics
Feb 15, 2021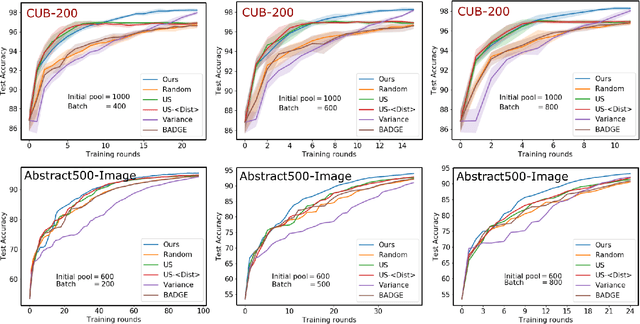
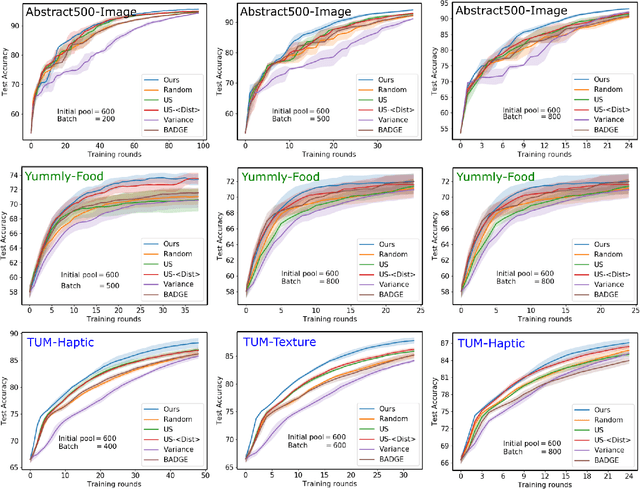
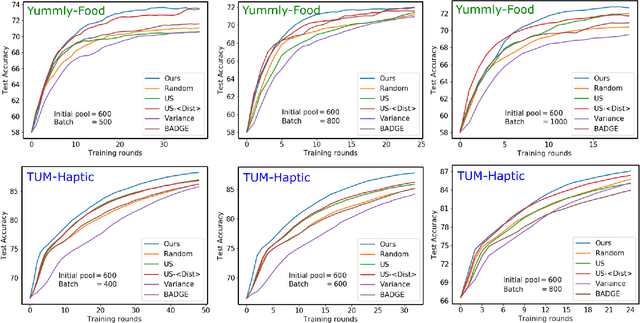
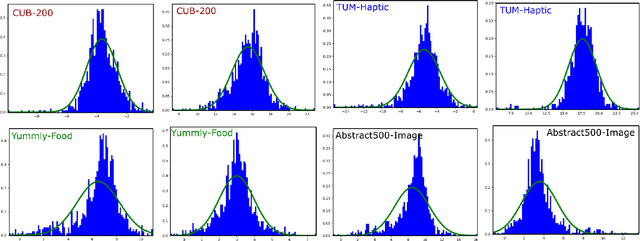
Active metric learning is the problem of incrementally selecting batches of training data (typically, ordered triplets) to annotate, in order to progressively improve a learned model of a metric over some input domain as rapidly as possible. Standard approaches, which independently select each triplet in a batch, are susceptible to highly correlated batches with many redundant triplets and hence low overall utility. While there has been recent work on selecting decorrelated batches for metric learning \cite{kumari2020batch}, these methods rely on ad hoc heuristics to estimate the correlation between two triplets at a time. We present a novel approach for batch mode active metric learning using the Maximum Entropy Principle that seeks to collectively select batches with maximum joint entropy, which captures both the informativeness and the diversity of the triplets. The entropy is derived from the second-order statistics estimated by dropout. We take advantage of the monotonically increasing submodular entropy function to construct an efficient greedy algorithm based on Gram-Schmidt orthogonalization that is provably $\left( 1 - \frac{1}{e} \right)$-optimal. Our approach is the first batch-mode active metric learning method to define a unified score that balances informativeness and diversity for an entire batch of triplets. Experiments with several real-world datasets demonstrate that our algorithm is robust and consistently outperforms the state-of-the-art.
Learning to Segment Rigid Motions from Two Frames
Jan 11, 2021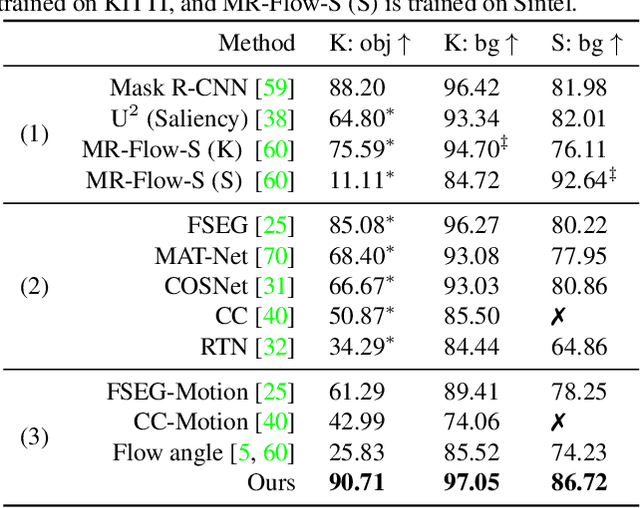

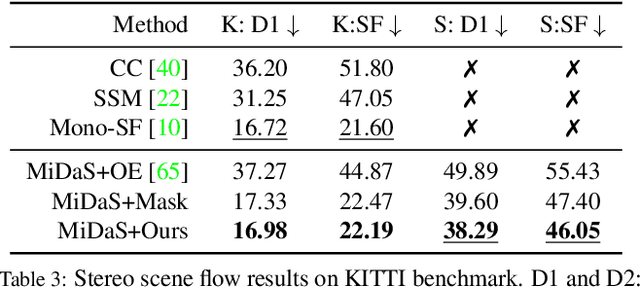

Appearance-based detectors achieve remarkable performance on common scenes, but tend to fail for scenarios lack of training data. Geometric motion segmentation algorithms, however, generalize to novel scenes, but have yet to achieve comparable performance to appearance-based ones, due to noisy motion estimations and degenerate motion configurations. To combine the best of both worlds, we propose a modular network, whose architecture is motivated by a geometric analysis of what independent object motions can be recovered from an egomotion field. It takes two consecutive frames as input and predicts segmentation masks for the background and multiple rigidly moving objects, which are then parameterized by 3D rigid transformations. Our method achieves state-of-the-art performance for rigid motion segmentation on KITTI and Sintel. The inferred rigid motions lead to a significant improvement for depth and scene flow estimation. At the time of submission, our method ranked 1st on KITTI scene flow leaderboard, out-performing the best published method (scene flow error: 4.89% vs 6.31%).
TriFinger: An Open-Source Robot for Learning Dexterity
Aug 08, 2020



Dexterous object manipulation remains an open problem in robotics, despite the rapid progress in machine learning during the past decade. We argue that a hindrance is the high cost of experimentation on real systems, in terms of both time and money. We address this problem by proposing an open-source robotic platform which can safely operate without human supervision. The hardware is inexpensive (about \SI{5000}[\$]{}) yet highly dynamic, robust, and capable of complex interaction with external objects. The software operates at 1-kilohertz and performs safety checks to prevent the hardware from breaking. The easy-to-use front-end (in C++ and Python) is suitable for real-time control as well as deep reinforcement learning. In addition, the software framework is largely robot-agnostic and can hence be used independently of the hardware proposed herein. Finally, we illustrate the potential of the proposed platform through a number of experiments, including real-time optimal control, deep reinforcement learning from scratch, throwing, and writing.
Local Memory Attention for Fast Video Semantic Segmentation
Jan 05, 2021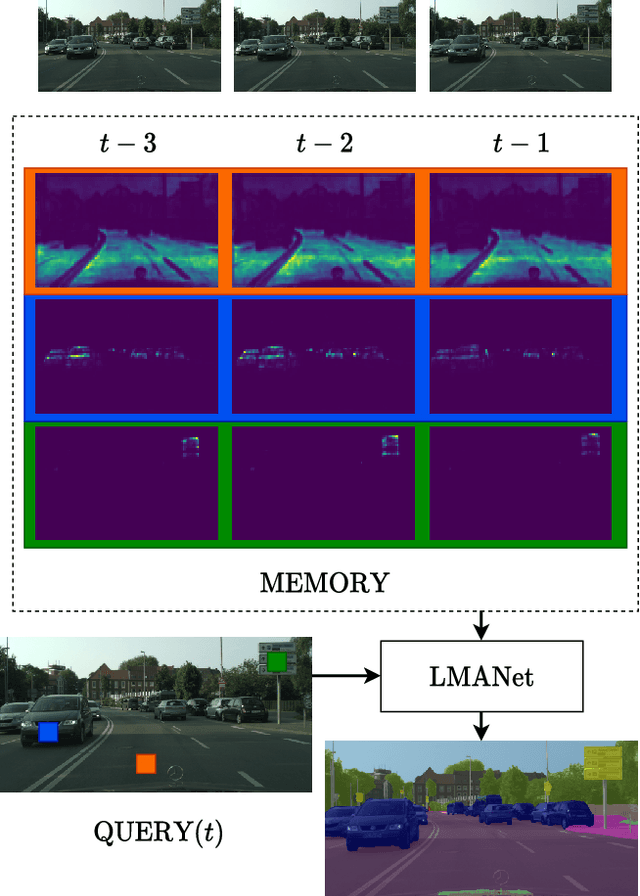
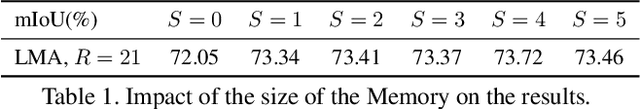
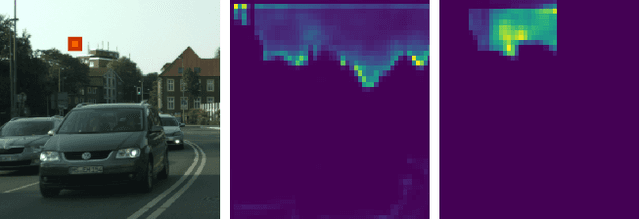

We propose a novel neural network module that transforms an existing single-frame semantic segmentation model into a video semantic segmentation pipeline. In contrast to prior works, we strive towards a simple and general module that can be integrated into virtually any single-frame architecture. Our approach aggregates a rich representation of the semantic information in past frames into a memory module. Information stored in the memory is then accessed through an attention mechanism. This provides temporal appearance cues from prior frames, which are then fused with an encoding of the current frame through a second attention-based module. The segmentation decoder processes the fused representation to predict the final semantic segmentation. We integrate our approach into two popular semantic segmentation networks: ERFNet and PSPNet. We observe an improvement in segmentation performance on Cityscapes by 1.7% and 2.1% in mIoU respectively, while increasing inference time of ERFNet by only 1.5ms.
Design of Dynamic Experiments for Black-Box Model Discrimination
Feb 07, 2021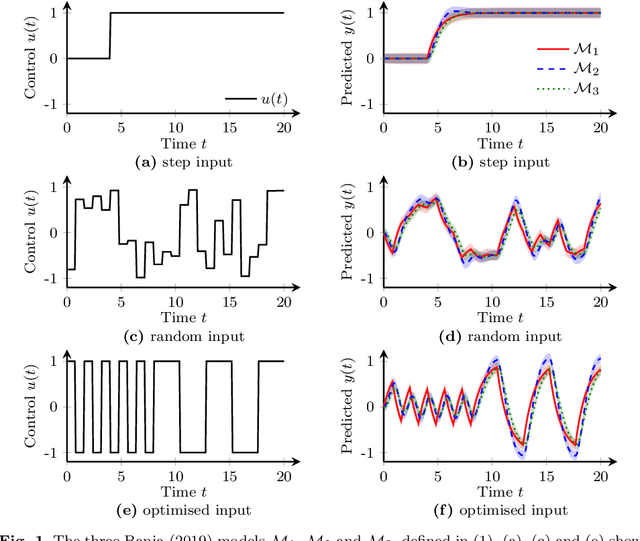
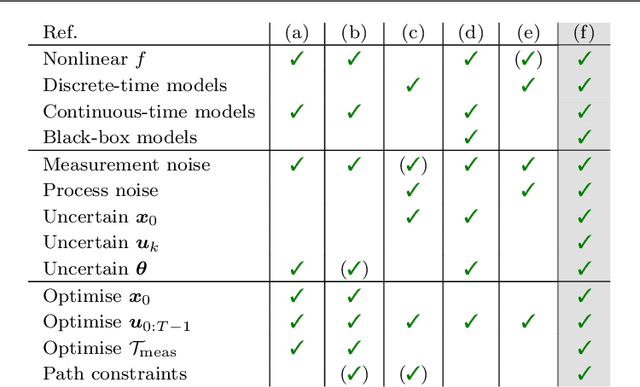
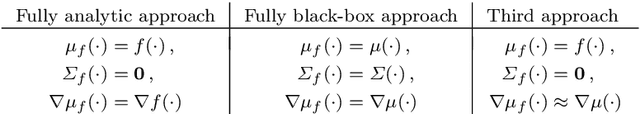
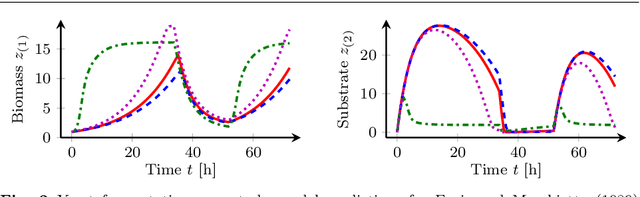
Diverse domains of science and engineering require and use mechanistic mathematical models, e.g. systems of differential algebraic equations. Such models often contain uncertain parameters to be estimated from data. Consider a dynamic model discrimination setting where we wish to chose: (i) what is the best mechanistic, time-varying model and (ii) what are the best model parameter estimates. These tasks are often termed model discrimination/selection/validation/verification. Typically, several rival mechanistic models can explain data, so we incorporate available data and also run new experiments to gather more data. Design of dynamic experiments for model discrimination helps optimally collect data. For rival mechanistic models where we have access to gradient information, we extend existing methods to incorporate a wider range of problem uncertainty and show that our proposed approach is equivalent to historical approaches when limiting the types of considered uncertainty. We also consider rival mechanistic models as dynamic black boxes that we can evaluate, e.g. by running legacy code, but where gradient or other advanced information is unavailable. We replace these black-box models with Gaussian process surrogate models and thereby extend the model discrimination setting to additionally incorporate rival black-box model. We also explore the consequences of using Gaussian process surrogates to approximate gradient-based methods.