 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PhotoApp: Photorealistic Appearance Editing of Head Portraits
Mar 13, 2021

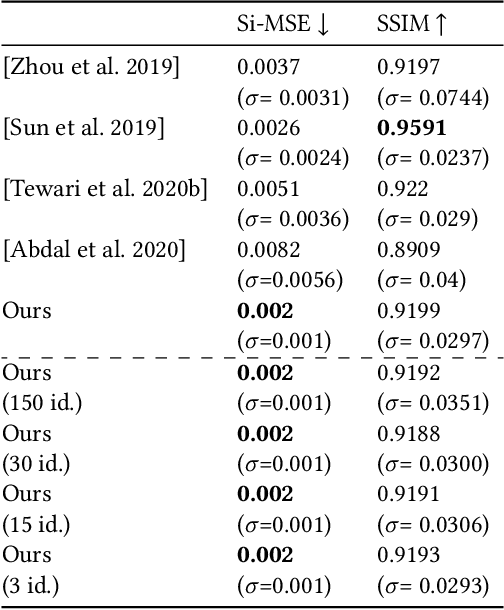
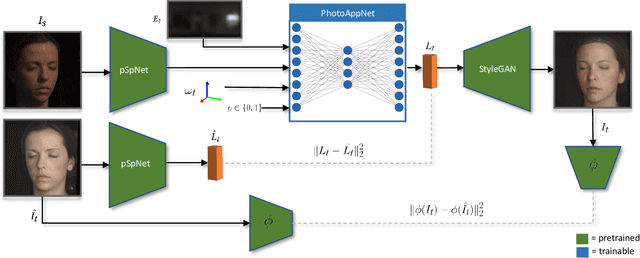
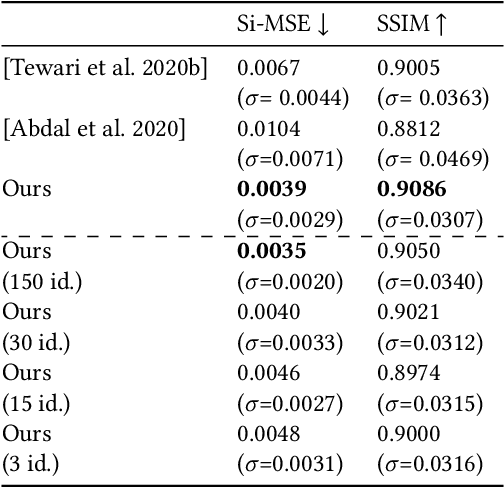
Photorealistic editing of portraits is a challenging task as humans are very sensitive to inconsistencies in faces. We present an approach for high-quality intuitive editing of the camera viewpoint and scene illumination in a portrait image. This requires our method to capture and control the full reflectance field of the person in the image. Most editing approaches rely on supervised learning using training data captured with setups such as light and camera stages. Such datasets are expensive to acquire, not readily available and do not capture all the rich variations of in-the-wild portrait images. In addition, most supervised approaches only focus on relighting, and do not allow camera viewpoint editing. Thus, they only capture and control a subset of the reflectance field. Recently, portrait editing has been demonstrated by operating in the generative model space of StyleGAN. While such approaches do not require direct supervision, there is a significant loss of quality when compared to the supervised approaches. In this paper, we present a method which learns from limited supervised training data. The training images only include people in a fixed neutral expression with eyes closed, without much hair or background variations. Each person is captured under 150 one-light-at-a-time conditions and under 8 camera poses. Instead of training directly in the image space, we design a supervised problem which learns transformations in the latent space of StyleGAN. This combines the best of supervised learning and generative adversarial modeling. We show that the StyleGAN prior allows for generalisation to different expressions, hairstyles and backgrounds. This produces high-quality photorealistic results for in-the-wild images and significantly outperforms existing methods. Our approach can edit the illumination and pose simultaneously, and runs at interactive rates.
Randomized fast no-loss expert system to play tic tac toe like a human
Sep 23, 2020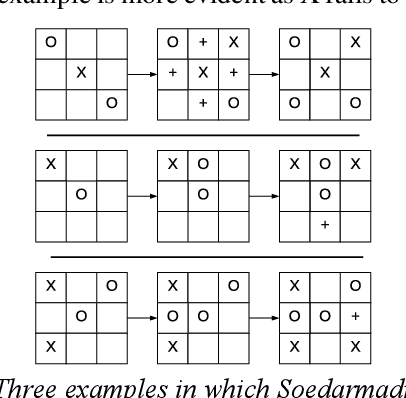
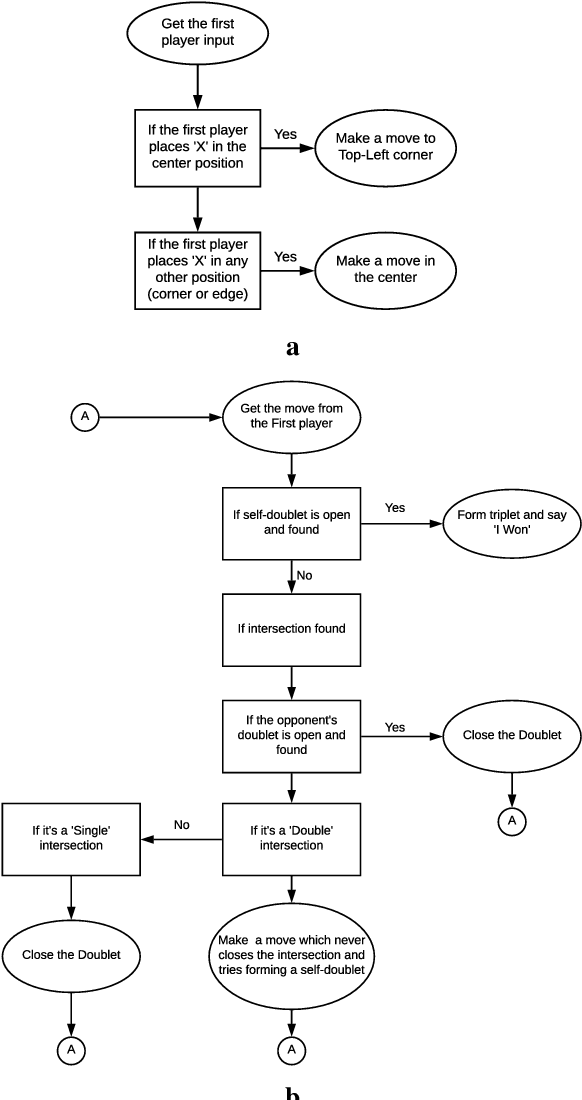
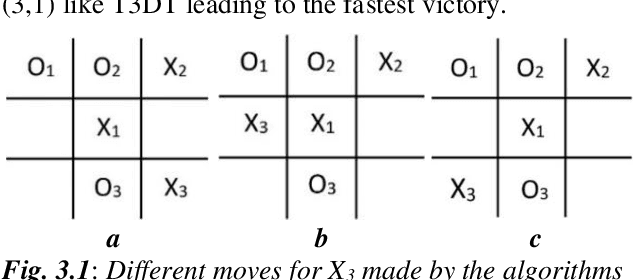
This paper introduces a blazingly fast, no-loss expert system for Tic Tac Toe using Decision Trees called T3DT, that tries to emulate human gameplay as closely as possible. It does not make use of any brute force, minimax or evolutionary techniques, but is still always unbeatable. In order to make the gameplay more human-like, randomization is prioritized and T3DT randomly chooses one of the multiple optimal moves at each step. Since it does not need to analyse the complete game tree at any point, T3DT is exceptionally faster than any brute force or minimax algorithm, this has been shown theoretically as well as empirically from clock-time analyses in this paper. T3DT also doesn't need the data sets or the time to train an evolutionary model, making it a practical no-loss approach to play Tic Tac Toe.
Hierarchical Symbolic Dynamic Filtering of Streaming Non-stationary Time Series Data
Feb 06, 2017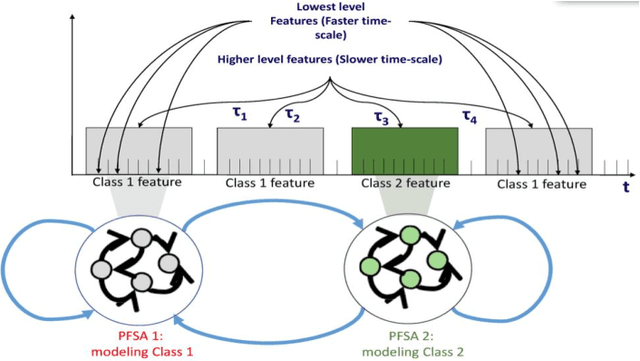
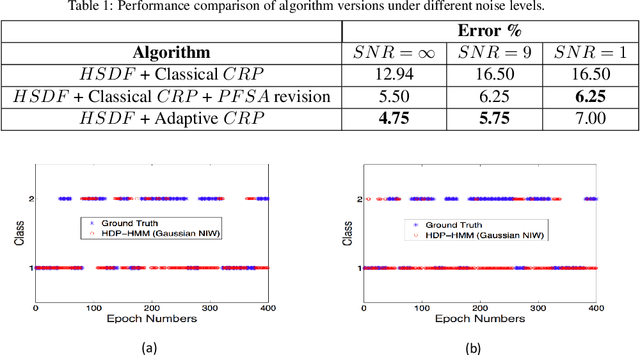
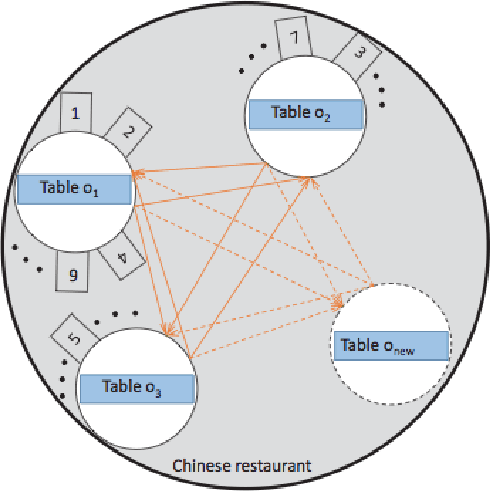
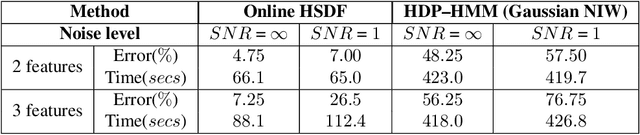
This paper proposes a hierarchical feature extractor for non-stationary streaming time series based on the concept of switching observable Markov chain models. The slow time-scale non-stationary behaviors are considered to be a mixture of quasi-stationary fast time-scale segments that are exhibited by complex dynamical systems. The idea is to model each unique stationary characteristic without a priori knowledge (e.g., number of possible unique characteristics) at a lower logical level, and capture the transitions from one low-level model to another at a higher level. In this context, the concepts in the recently developed Symbolic Dynamic Filtering (SDF) is extended, to build an online algorithm suited for handling quasi-stationary data at a lower level and a non-stationary behavior at a higher level without a priori knowledge. A key observation made in this study is that the rate of change of data likelihood seems to be a better indicator of change in data characteristics compared to the traditional methods that mostly consider data likelihood for change detection. The algorithm minimizes model complexity and captures data likelihood. Efficacy demonstration and comparative evaluation of the proposed algorithm are performed using time series data simulated from systems that exhibit nonlinear dynamics. We discuss results that show that the proposed hierarchical SDF algorithm can identify underlying features with significantly high degree of accuracy, even under very noisy conditions. Algorithm is demonstrated to perform better than the baseline Hierarchical Dirichlet Process-Hidden Markov Models (HDP-HMM). The low computational complexity of algorithm makes it suitable for on-board, real time operations.
Cascaded Continuous Regression for Real-time Incremental Face Tracking
Aug 06, 2016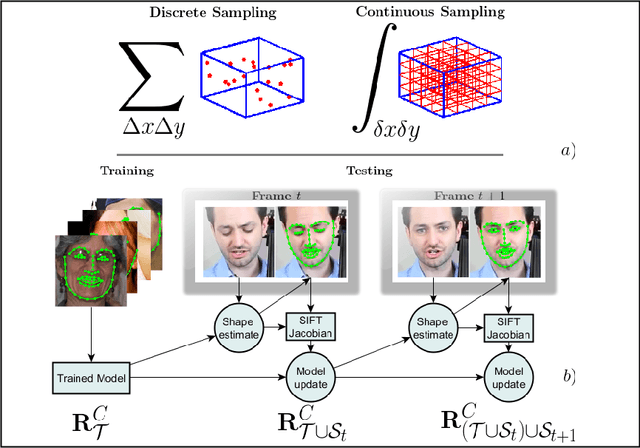
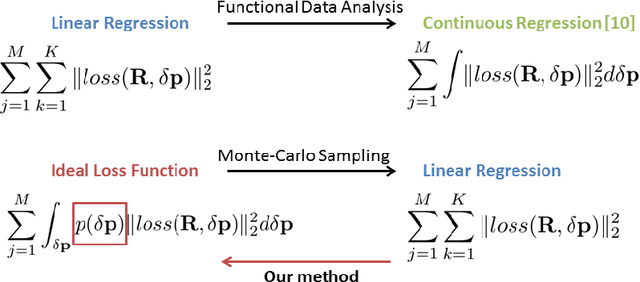
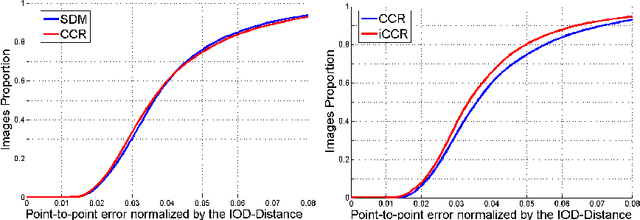
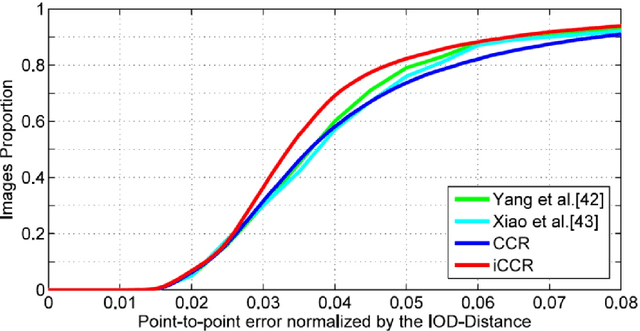
This paper introduces a novel real-time algorithm for facial landmark tracking. Compared to detection, tracking has both additional challenges and opportunities. Arguably the most important aspect in this domain is updating a tracker's models as tracking progresses, also known as incremental (face) tracking. While this should result in more accurate localisation, how to do this online and in real time without causing a tracker to drift is still an important open research question. We address this question in the cascaded regression framework, the state-of-the-art approach for facial landmark localisation. Because incremental learning for cascaded regression is costly, we propose a much more efficient yet equally accurate alternative using continuous regression. More specifically, we first propose cascaded continuous regression (CCR) and show its accuracy is equivalent to the Supervised Descent Method. We then derive the incremental learning updates for CCR (iCCR) and show that it is an order of magnitude faster than standard incremental learning for cascaded regression, bringing the time required for the update from seconds down to a fraction of a second, thus enabling real-time tracking. Finally, we evaluate iCCR and show the importance of incremental learning in achieving state-of-the-art performance. Code for our iCCR is available from http://www.cs.nott.ac.uk/~psxes1
Home and destination attachment: study of cultural integration on Twitter
Feb 22, 2021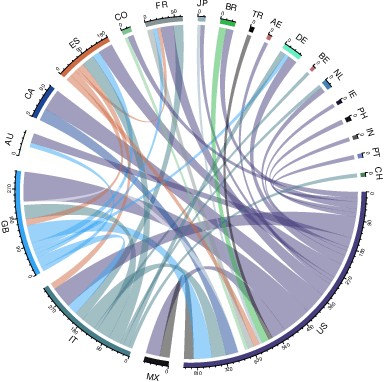
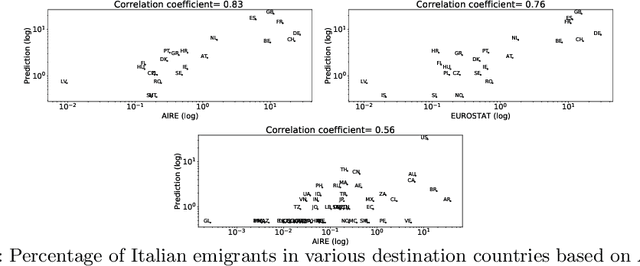
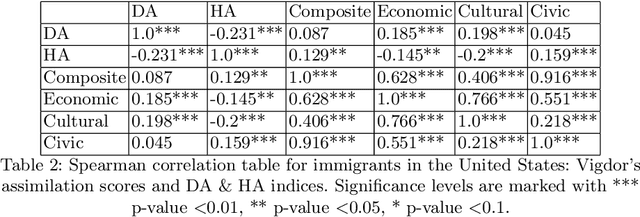
The cultural integration of immigrants conditions their overall socio-economic integration as well as natives' attitudes towards globalisation in general and immigration in particular. At the same time, excessive integration -- or acculturation -- can be detrimental in that it implies forfeiting one's ties to the home country and eventually translates into a loss of diversity (from the viewpoint of host countries) and of global connections (from the viewpoint of both host and home countries). Cultural integration can be described using two dimensions: the preservation of links to the home country and culture, which we call home attachment, and the creation of new links together with the adoption of cultural traits from the new residence country, which we call destination attachment. In this paper we introduce a means to quantify these two aspects based on Twitter data. We build home and destination attachment indexes and analyse their possible determinants (e.g., language proximity, distance between countries), also in relation to Hofstede's cultural dimension scores. The results stress the importance of host language proficiency to explain destination attachment, but also the link between language and home attachment. In particular, the common language between home and destination countries corresponds to increased home attachment, as does low proficiency in the host language. Common geographical borders also seem to increase both home and destination attachment. Regarding cultural dimensions, larger differences among home and destination country in terms of Individualism, Masculinity and Uncertainty appear to correspond to larger destination attachment and lower home attachment.
Learning Complete 3D Morphable Face Models from Images and Videos
Oct 04, 2020

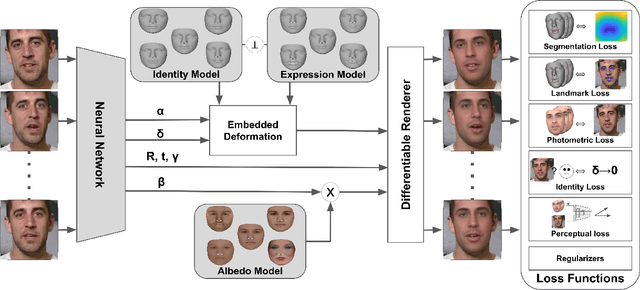

Most 3D face reconstruction methods rely on 3D morphable models, which disentangle the space of facial deformations into identity geometry, expressions and skin reflectance. These models are typically learned from a limited number of 3D scans and thus do not generalize well across different identities and expressions. We present the first approach to learn complete 3D models of face identity geometry, albedo and expression just from images and videos. The virtually endless collection of such data, in combination with our self-supervised learning-based approach allows for learning face models that generalize beyond the span of existing approaches. Our network design and loss functions ensure a disentangled parameterization of not only identity and albedo, but also, for the first time, an expression basis. Our method also allows for in-the-wild monocular reconstruction at test time. We show that our learned models better generalize and lead to higher quality image-based reconstructions than existing approaches.
Continuous-time Discounted Mirror-Descent Dynamics in Monotone Concave Games
Dec 07, 2019
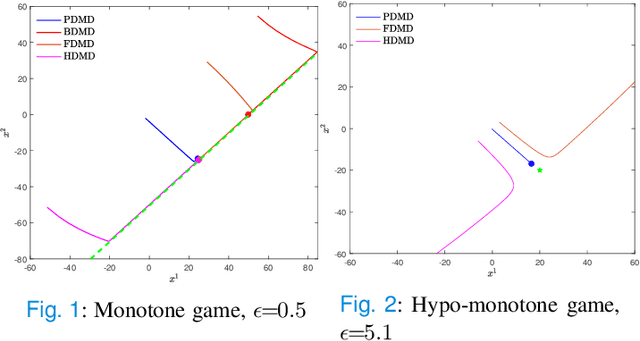
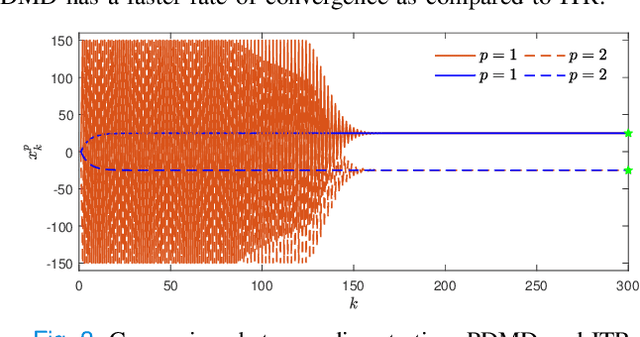
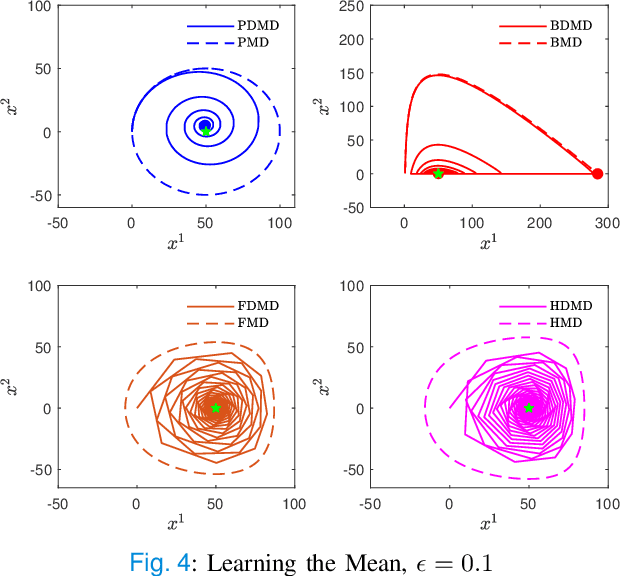
In this paper, we consider concave continuous-kernel games characterized by monotonicity properties and propose discounted mirror descent-type dynamics. We introduce two classes of dynamics whereby the associated mirror map is constructed based on a strongly convex or a Legendre regularizer. Depending on the properties of the regularizer we show that these new dynamics can converge asymptotically in concave games with monotone (negative) pseudo-gradient. Furthermore, we show that when the regularizer enjoys strong convexity, the resulting dynamics can converge even in games with hypo-monotone (negative) pseudo-gradient, which corresponds to a shortage of monotonicity.
Detecting Pulmonary Coccidioidomycosis (Valley fever) with Deep Convolutional Neural Networks
Jan 30, 2021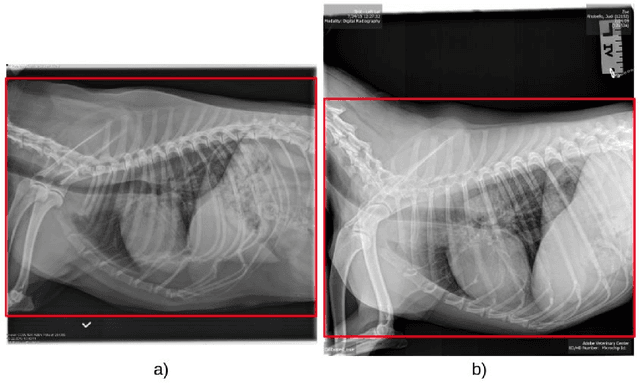

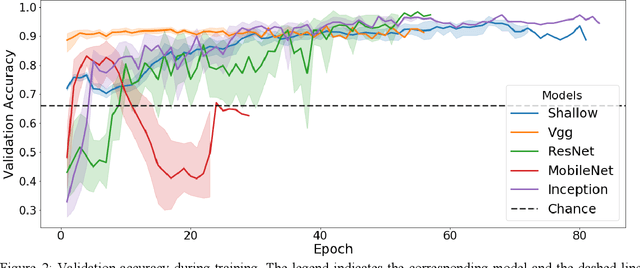
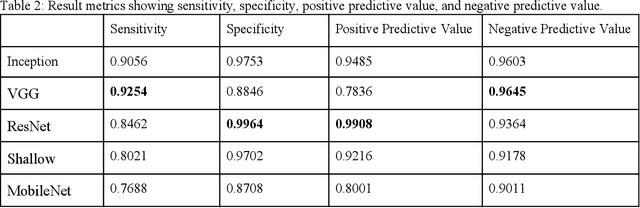
Coccidioidomycosis is the most common systemic mycosis in dogs in the southwestern United States. With warming climates, affected areas and number of cases are expected to increase in the coming years, escalating also the chances of transmission to humans. As a result, developing methods for automating the detection of the disease is important, as this will help doctors and veterinarians more easily identify and diagnose positive cases. We apply machine learning models to provide accurate and interpretable predictions of Coccidioidomycosis. We assemble a set of radiographic images and use it to train and test state-of-the-art convolutional neural networks to detect Coccidioidomycosis. These methods are relatively inexpensive to train and very fast at inference time. We demonstrate the successful application of this approach to detect the disease with an Area Under the Curve (AUC) above 0.99 using 10-fold cross validation. We also use the classification model to identify regions of interest and localize the disease in the radiographic images, as illustrated through visual heatmaps. This proof-of-concept study establishes the feasibility of very accurate and rapid automated detection of Valley Fever in radiographic images.
Shortformer: Better Language Modeling using Shorter Inputs
Dec 31, 2020
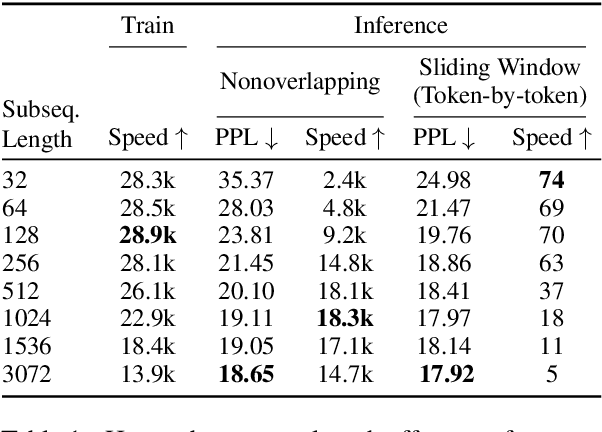
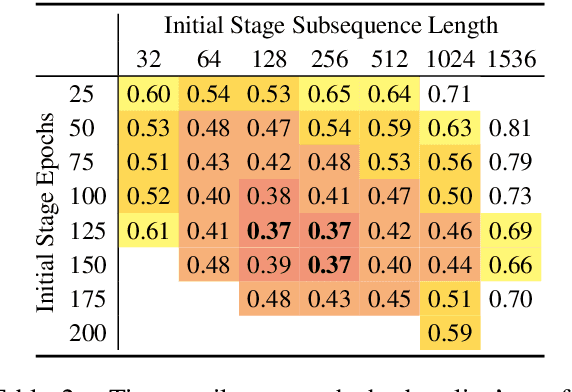
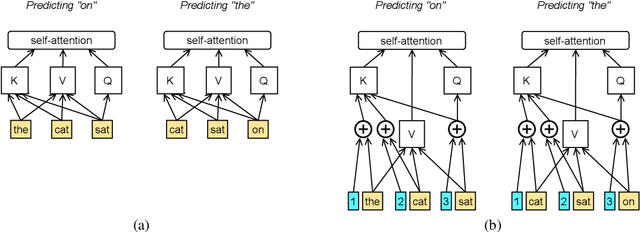
We explore the benefits of decreasing the input length of transformers. First, we show that initially training the model on short subsequences, before moving on to longer ones, both reduces overall training time and, surprisingly, gives a large improvement in perplexity. We then show how to improve the efficiency of recurrence methods in transformers, which let models condition on previously processed tokens (when generating sequences that are larger than the maximal length that the transformer can handle at once). Existing methods require computationally expensive relative position embeddings; we introduce a simple alternative of adding absolute position embeddings to queries and keys instead of to word embeddings, which efficiently produces superior results. By combining these techniques, we increase training speed by 65%, make generation nine times faster, and substantially improve perplexity on WikiText-103, without adding any parameters.
An Empirical Evaluation of Time-Aware LSTM Autoencoder on Chronic Kidney Disease
Oct 01, 2018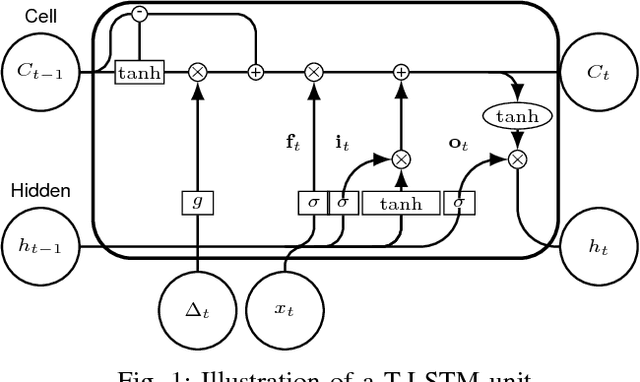
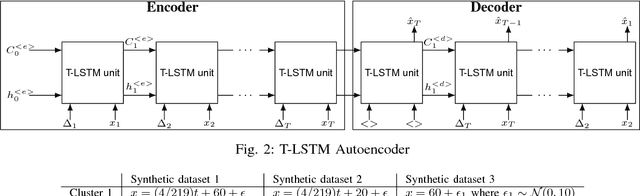
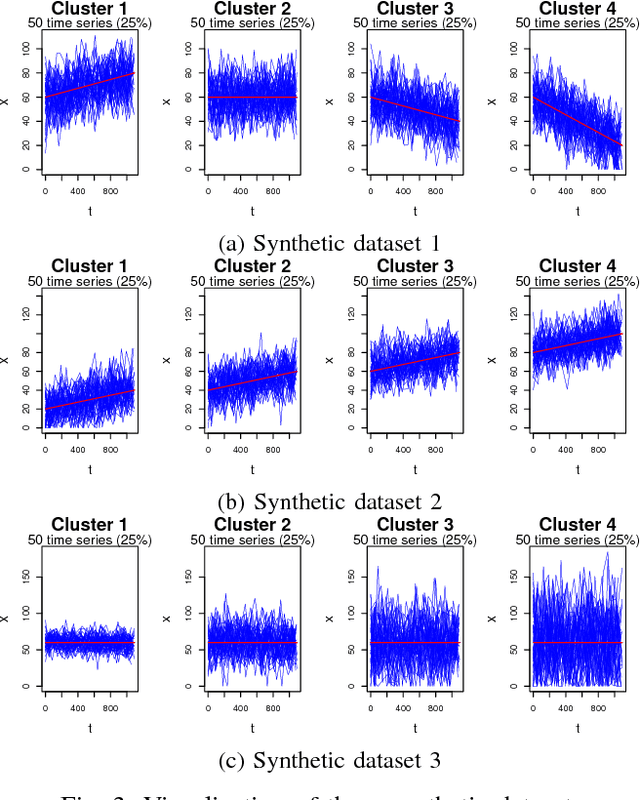
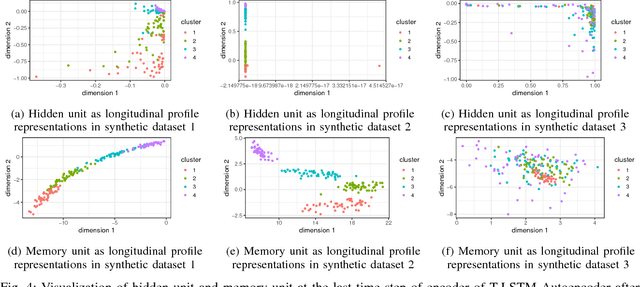
In this paper, we perform an empirical analysis on T-LSTM Auto-encoder - a model that can analyze a large dataset of irregularly sampled time series and project them into an embedded space. In particular, with three different synthetic datasets, we show that both memory unit and hidden unit of the last step in the encoder should be used as representation for a longitudinal profile. In addition, we perform a cross-validation to determine the dimension of the embedded representation - an important hyper-parameter of the model - when apply T-LSTM Auto-encoder into the real-world clinical datasets of patients having Chronic Kidney Disease (CKD). The analysis of the decoder outputs from the model shows that they not only capture well the long-term trends in the original data but also reduce the noise or fluctuation in the input data. Finally, we demonstrate that we can use the embedded representations of CKD patients learnt from T-LSTM Auto-encoder to identify interesting and unusual longitudinal profiles in CKD datasets.