 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Self-Supervised Representation Learning for RGB-D Salient Object Detection
Jan 29, 2021

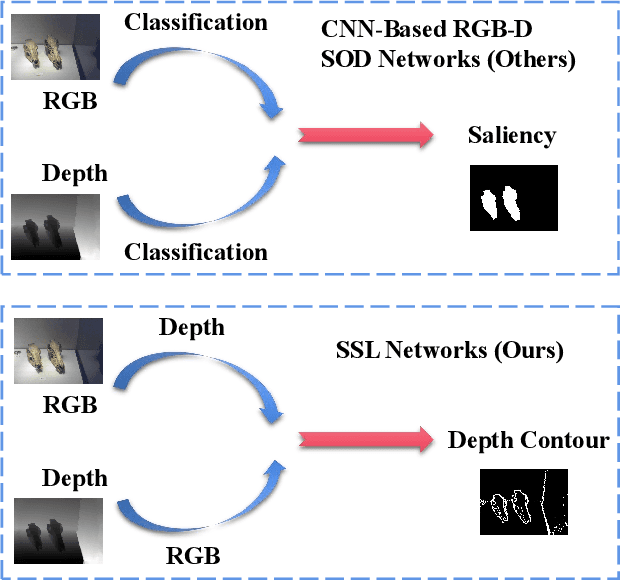
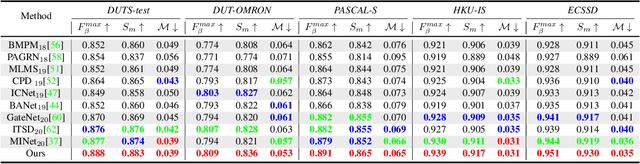
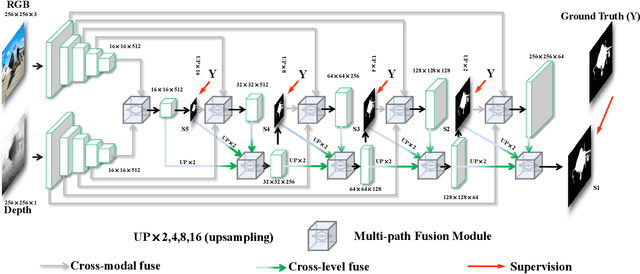
Existing CNNs-Based RGB-D Salient Object Detection (SOD) networks are all required to be pre-trained on the ImageNet to learn the hierarchy features which can help to provide a good initialization. However, the collection and annotation of large-scale datasets are time-consuming and expensive. In this paper, we utilize Self-Supervised Representation Learning (SSL) to design two pretext tasks: the cross-modal auto-encoder and the depth-contour estimation. Our pretext tasks require only a few and unlabeled RGB-D datasets to perform pre-training, which make the network capture rich semantic contexts as well as reduce the gap between two modalities, thereby providing an effective initialization for the downstream task. In addition, for the inherent problem of cross-modal fusion in RGB-D SOD, we propose a multi-path fusion (MPF) module that splits a single feature fusion into multi-path fusion to achieve an adequate perception of consistent and differential information. The MPF module is general and suitable for both cross-modal and cross-level feature fusion. Extensive experiments on six benchmark RGB-D SOD datasets, our model pre-trained on the RGB-D dataset ($6,335$ without any annotations) can perform favorably against most state-of-the-art RGB-D methods pre-trained on ImageNet ($1,280,000$ with image-level annotations).
A Three-Stage Algorithm for the Large Scale Dynamic Vehicle Routing Problem with an Industry 4.0 Approach
Oct 04, 2020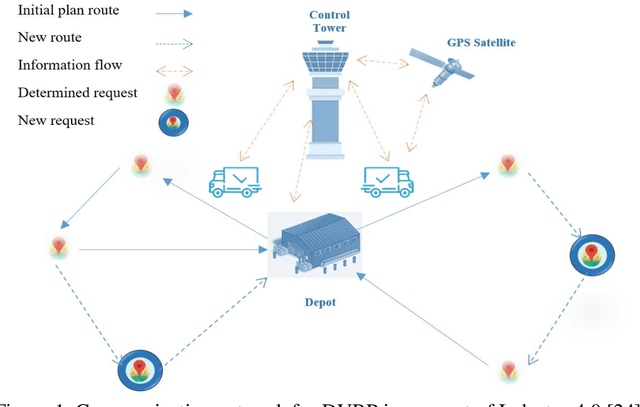

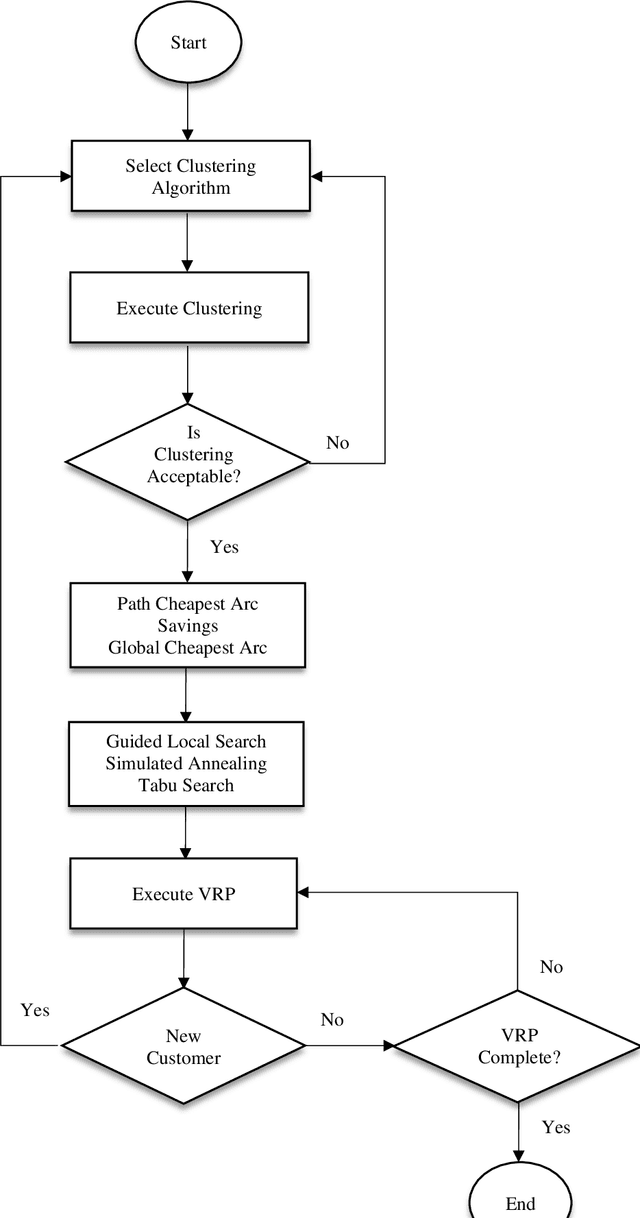
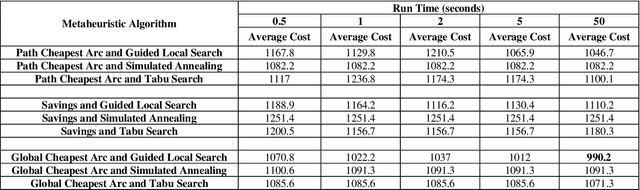
Industry 4.0 is a concept which helps companies to have a smart supply chain system when they are faced with a dynamic process. As Industry 4.0 focuses on mobility and real-time integration, it is a good framework for a Dynamic Vehicle Routing problem (DVRP). The main objective of this research is to solve the DVRP on a large-scale size. The aim of this study is to show that the delivery vehicles must serve customer demands from a common depot to have a minimum transit cost without exceeding the capacity constraint of each vehicle. In VRP, to reach an exact solution is quite difficult, and in large-size real world problems it is often impossible. Also, the computational time complexity of this type of problem grows exponentially. In order to find optimal answers for this problem in medium and large dimensions, using a heuristic approach is recommended as the best approach. A hierarchical approach consisting of three stages as cluster-first, route-construction second, route-improvement third is proposed. In the first stage, customers are clustered based on the number of vehicles with different clustering algorithms (i.e., K-mean, GMM, and BIRCH algorithms). In the second stage, the DVRP is solved using construction algorithms and in the third stage improvement algorithms are applied. The second stage is solved using construction algorithms (i.e. Savings algorithm, path cheapest arc algorithm, etc.). In the third stage, improvement algorithms such as Guided Local Search, Simulated Annealing and Tabu Search are applied. One of the main contributions of this paper is that the proposed approach can deal with large-size real world problems to decrease the computational time complexity. The results of this approach confirmed that the proposed methodology is applicable.
Cross-domain Activity Recognition via Substructural Optimal Transport
Jan 29, 2021

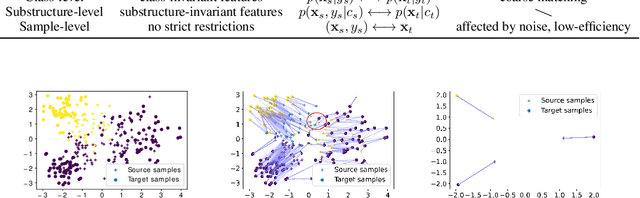

It is expensive and time-consuming to collect sufficient labeled data for human activity recognition (HAR). Recently, lots of work solves the problem via domain adaptation which leverages the labeled samples from the source domain to annotate the target domain. Existing domain adaptation methods mainly focus on adapting cross-domain representations via domain-level, class-level, or sample-level distribution matching. However, the domain- and class-level matching are too coarse that may result in under-adaptation, while sample-level matching may be affected by the noise seriously and eventually cause over-adaptation. In this paper, we propose substructure-level matching for domain adaptation (SSDA) to utilize the internal substructures of the domain to perform accurate and efficient knowledge transfer. Based on SSDA, we propose an optimal transport-based implementation, Substructural Optimal Transport (SOT), for cross-domain HAR. We obtain the substructures of activities via clustering methods and seeks the coupling of the weighted substructures between different domains. We conduct comprehensive experiments on four large public activity recognition datasets (i.e. UCI-DSADS, UCI-HAR, USC-HAD, PAMAP2), which demonstrates that SOT significantly outperforms other state-of-the-art methods w.r.t classification accuracy (10%+ improvement). In addition, SOT is much faster than comparison methods.
Sparsity Based Autoencoders for Denoising Cluttered Radar Signatures
Jan 29, 2021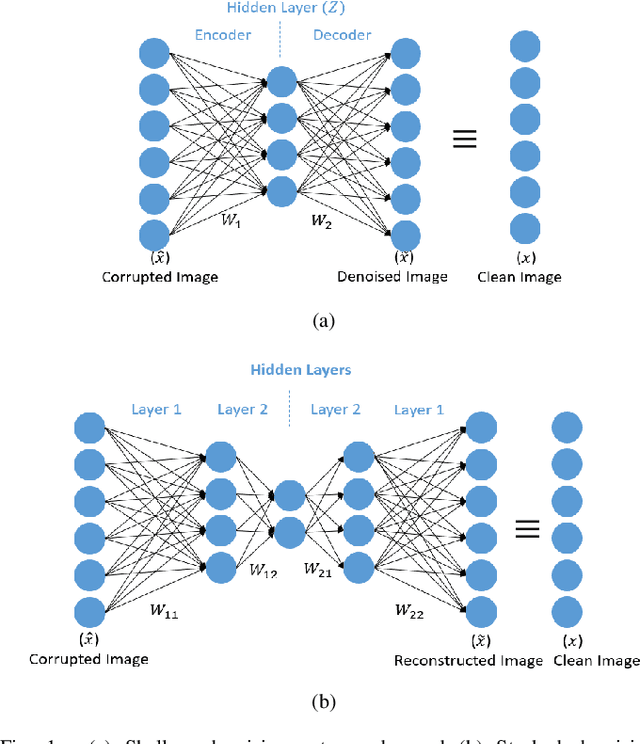
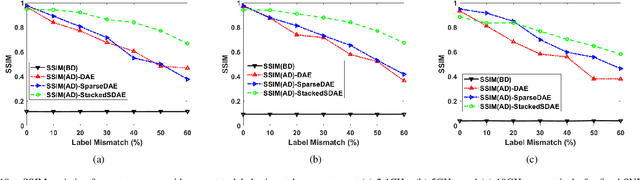
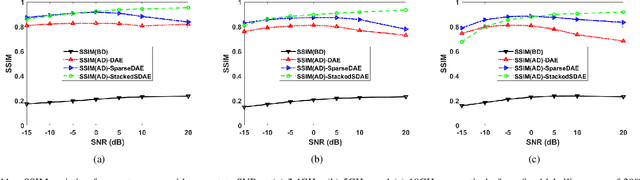
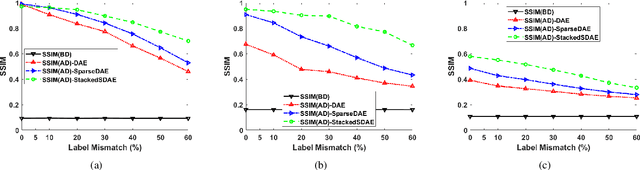
Narrowband and broadband indoor radar images significantly deteriorate in the presence of target dependent and independent static and dynamic clutter arising from walls. A stacked and sparse denoising autoencoder (StackedSDAE) is proposed for mitigating wall clutter in indoor radar images. The algorithm relies on the availability of clean images and corresponding noisy images during training and requires no additional information regarding the wall characteristics. The algorithm is evaluated on simulated Doppler-time spectrograms and high range resolution profiles generated for diverse radar frequencies and wall characteristics in around-the-corner radar (ACR) scenarios. Additional experiments are performed on range-enhanced frontal images generated from measurements gathered from a wideband RF imaging sensor. The results from the experiments show that the StackedSDAE successfully reconstructs images that closely resemble those that would be obtained in free space conditions. Further, the incorporation of sparsity and depth in the hidden layer representations within the autoencoder makes the algorithm more robust to low signal to noise ratio (SNR) and label mismatch between clean and corrupt data during training than the conventional single layer DAE. For example, the denoised ACR signatures show a structural similarity above 0.75 to clean free space images at SNR of -10dB and label mismatch error of 50%.
Learning to Ignore: Fair and Task Independent Representations
Jan 11, 2021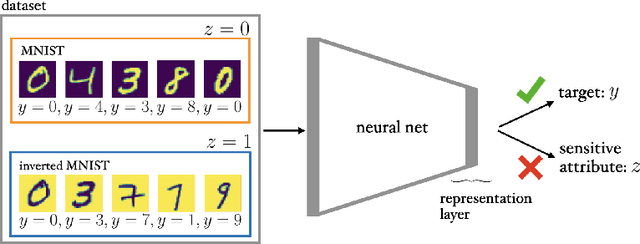

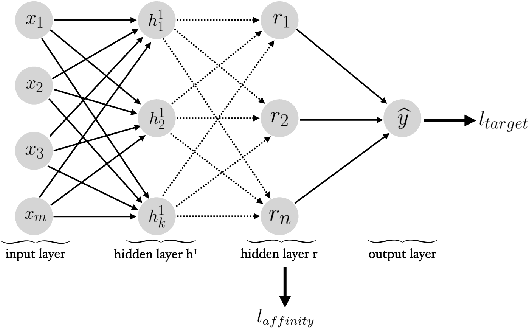

Training fair machine learning models, aiming for their interpretability and solving the problem of domain shift has gained a lot of interest in the last years. There is a vast amount of work addressing these topics, mostly in separation. In this work we show that they can be seen as a common framework of learning invariant representations. The representations should allow to predict the target while at the same time being invariant to sensitive attributes which split the dataset into subgroups. Our approach is based on the simple observation that it is impossible for any learning algorithm to differentiate samples if they have the same feature representation. This is formulated as an additional loss (regularizer) enforcing a common feature representation across subgroups. We apply it to learn fair models and interpret the influence of the sensitive attribute. Furthermore it can be used for domain adaptation, transferring knowledge and learning effectively from very few examples. In all applications it is essential not only to learn to predict the target, but also to learn what to ignore.
Vision-model-based Real-time Localization of Unmanned Aerial Vehicle for Autonomous Structure Inspection under GPS-denied Environment
Apr 10, 2019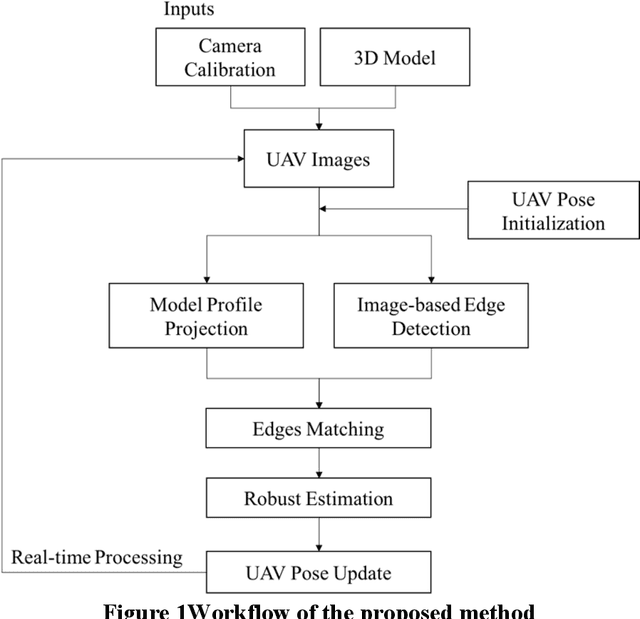



UAVs have been widely used in visual inspections of buildings, bridges and other structures. In either outdoor autonomous or semi-autonomous flights missions strong GPS signal is vital for UAV to locate its own positions. However, strong GPS signal is not always available, and it can degrade or fully loss underneath large structures or close to power lines, which can cause serious control issues or even UAV crashes. Such limitations highly restricted the applications of UAV as a routine inspection tool in various domains. In this paper a vision-model-based real-time self-positioning method is proposed to support autonomous aerial inspection without the need of GPS support. Compared to other localization methods that requires additional onboard sensors, the proposed method uses a single camera to continuously estimate the inflight poses of UAV. Each step of the proposed method is discussed in detail, and its performance is tested through an indoor test case.
An Ontology Design Pattern for representing Recurrent Situations
Jan 01, 2021
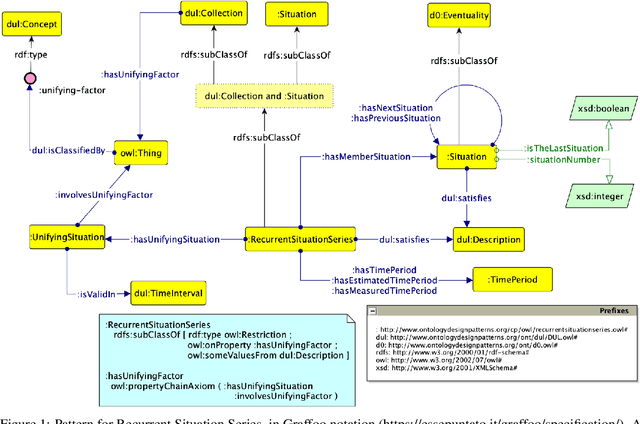
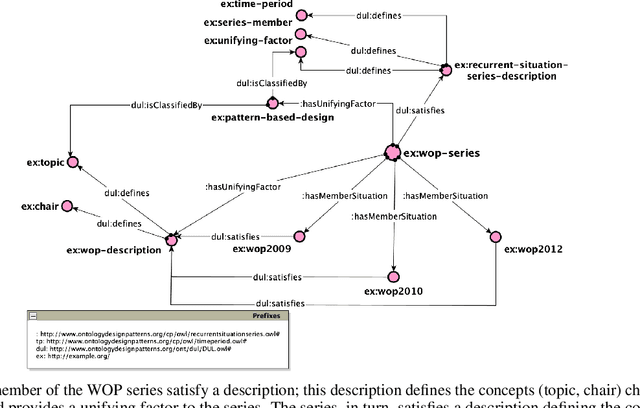
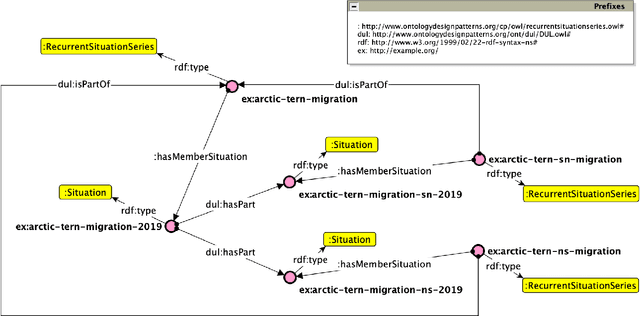
In this paper, we present an Ontology Design Pattern for representing situations that recur at regular periods and share some invariant factors, which unify them conceptually: we refer to this set of recurring situations as recurrent situation series. The proposed pattern appears to be foundational, since it can be generalised for modelling the top-level domain-independent concept of recurrence, which is strictly associated with invariance. The pattern reuses other foundational patterns such as Collection, Description and Situation, Classification, Sequence. Indeed, a recurrent situation series is formalised as both a collection of situations occurring regularly over time and unified according to some properties that are common to all the members, and a situation itself, which provides a relational context to its members that satisfy a reference description. Besides including some exemplifying instances of this pattern, we show how it has been implemented and specialised to model recurrent cultural events and ceremonies in ArCo, the Knowledge Graph of Italian cultural heritage.
Automatic Polyp Segmentation using Fully Convolutional Neural Network
Jan 11, 2021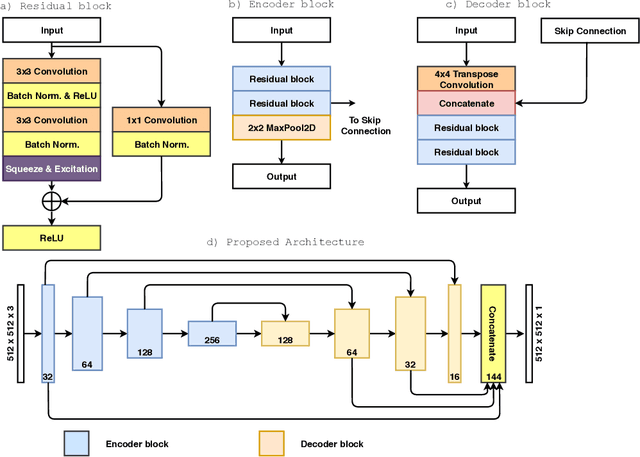
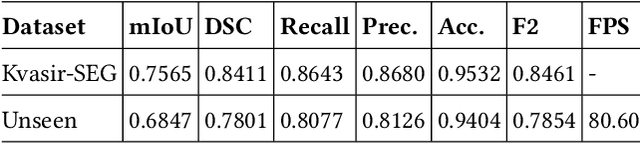
Colorectal cancer is one of fatal cancer worldwide. Colonoscopy is the standard treatment for examination, localization, and removal of colorectal polyps. However, it has been shown that the miss-rate of colorectal polyps during colonoscopy is between 6 to 27%. The use of an automated, accurate, and real-time polyp segmentation during colonoscopy examinations can help the clinicians to eliminate missing lesions and prevent further progression of colorectal cancer. The ``Medico automatic polyp segmentation challenge'' provides an opportunity to study polyp segmentation and build a fast segmentation model. The challenge organizers provide a Kvasir-SEG dataset to train the model. Then it is tested on a separate unseen dataset to validate the efficiency and speed of the segmentation model. The experiments demonstrate that the model trained on the Kvasir-SEG dataset and tested on an unseen dataset achieves a dice coefficient of 0.7801, mIoU of 0.6847, recall of 0.8077, and precision of 0.8126, demonstrating the generalization ability of our model. The model has achieved 80.60 FPS on the unseen dataset with an image resolution of $512 \times 512$.
VisualSparta: Sparse Transformer Fragment-level Matching for Large-scale Text-to-Image Search
Jan 01, 2021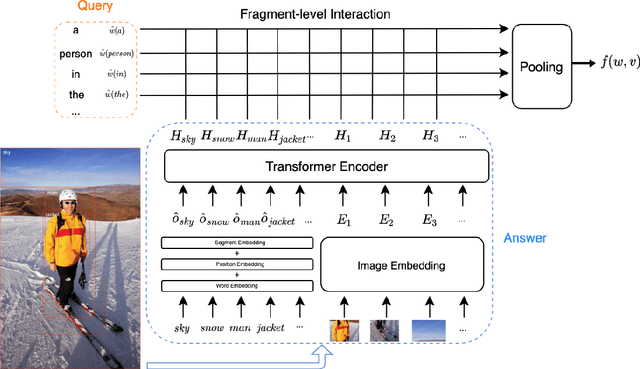
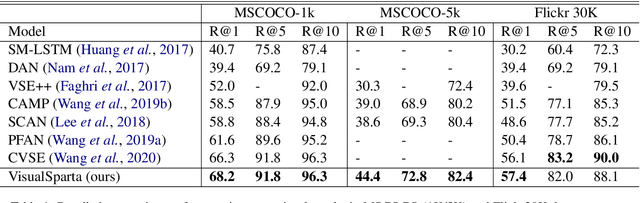
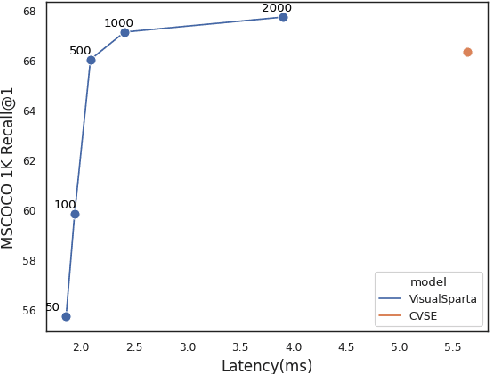
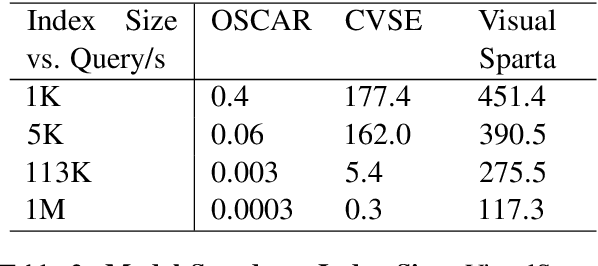
Text-to-image retrieval is an essential task in multi-modal information retrieval, i.e. retrieving relevant images from a large and unlabelled image dataset given textual queries. In this paper, we propose VisualSparta, a novel text-to-image retrieval model that shows substantial improvement over existing models on both accuracy and efficiency. We show that VisualSparta is capable of outperforming all previous scalable methods in MSCOCO and Flickr30K. It also shows substantial retrieving speed advantages, i.e. for an index with 1 million images, VisualSparta gets over 391x speed up compared to standard vector search. Experiments show that this speed advantage even gets bigger for larger datasets because VisualSparta can be efficiently implemented as an inverted index. To the best of our knowledge, VisualSparta is the first transformer-based text-to-image retrieval model that can achieve real-time searching for very large dataset, with significant accuracy improvement compared to previous state-of-the-art methods.
EdgeLoc: An Edge-IoT Framework for Robust Indoor Localization Using Capsule Networks
Sep 12, 2020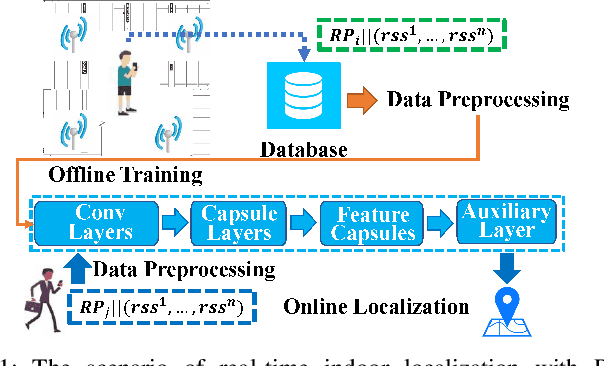
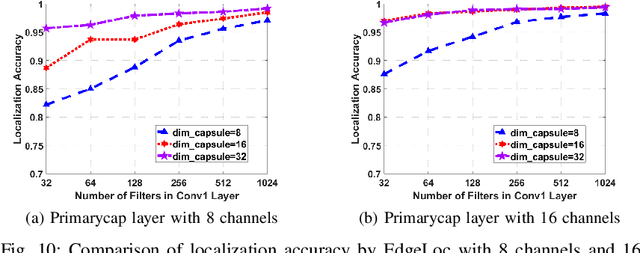
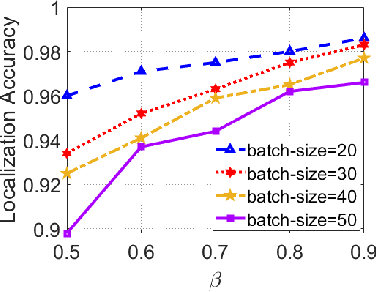
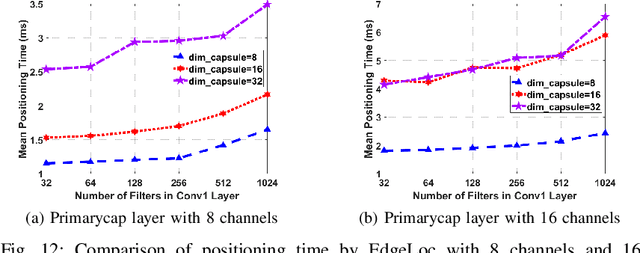
With the unprecedented demand for location-based services in indoor scenarios, wireless indoor localization has become essential for mobile users. While GPS is not available at indoor spaces, WiFi RSS fingerprinting has become popular with its ubiquitous accessibility. However, it is challenging to achieve robust and efficient indoor localization with two major challenges. First, the localization accuracy can be degraded by the random signal fluctuations, which would influence conventional localization algorithms that simply learn handcrafted features from raw fingerprint data. Second, mobile users are sensitive to the localization delay, but conventional indoor localization algorithms are computation-intensive and time-consuming. In this paper, we propose EdgeLoc, an edge-IoT framework for efficient and robust indoor localization using capsule networks. We develop a deep learning model with the CapsNet to efficiently extract hierarchical information from WiFi fingerprint data, thereby significantly improving the localization accuracy. Moreover, we implement an edge-computing prototype system to achieve a nearly real-time localization process, by enabling mobile users with the deep-learning model that has been well-trained by the edge server. We conduct a real-world field experimental study with over 33,600 data points and an extensive synthetic experiment with the open dataset, and the experimental results validate the effectiveness of EdgeLoc. The best trade-off of the EdgeLoc system achieves 98.5% localization accuracy within an average positioning time of only 2.31 ms in the field experiment.