 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Uncovering Feature Interdependencies in Complex Systems with Non-Greedy Random Forests
Oct 05, 2020
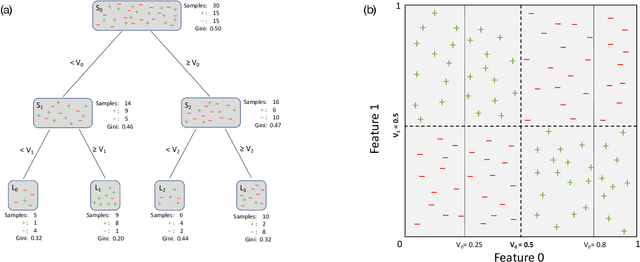
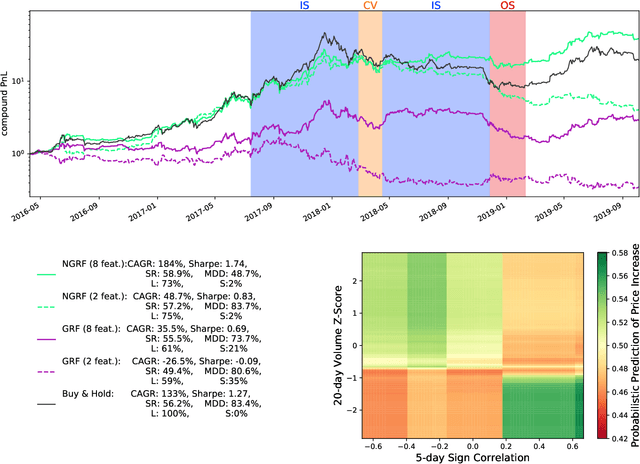
A "non-greedy" variation of the random forest algorithm is presented to better uncover feature interdependencies inherent in complex systems. Conventionally, random forests are built from "greedy" decision trees which each consider only one split at a time during their construction. In contrast, the decision trees included in this random forest algorithm each consider three split nodes simultaneously in tiers of depth two. It is demonstrated on synthetic data and bitcoin price time series that the non-greedy version significantly outperforms the greedy one if certain non-linear relationships between feature-pairs are present. In particular, both greedy and a non-greedy random forests are trained to predict the signs of daily bitcoin returns and backtest a long-short trading strategy. The better performance of the non-greedy algorithm is explained by the presence of "XOR-like" relationships between long-term and short-term technical indicators. When no such relationships exist, performance is similar. Given its enhanced ability to understand the feature-interdependencies present in complex systems, this non-greedy extension should become a standard method in the toolkit of data scientists.
MP3net: coherent, minute-long music generation from raw audio with a simple convolutional GAN
Jan 12, 2021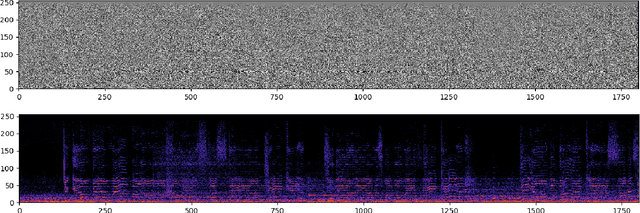
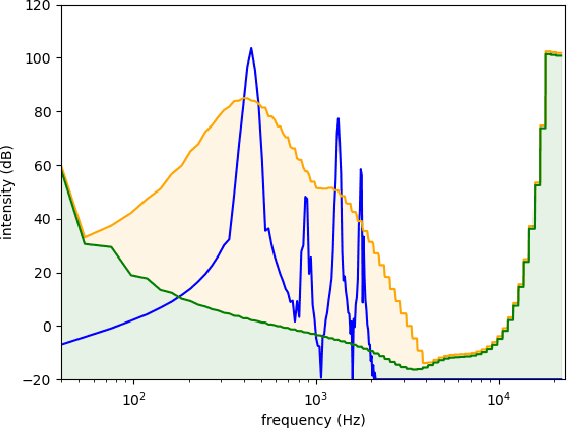
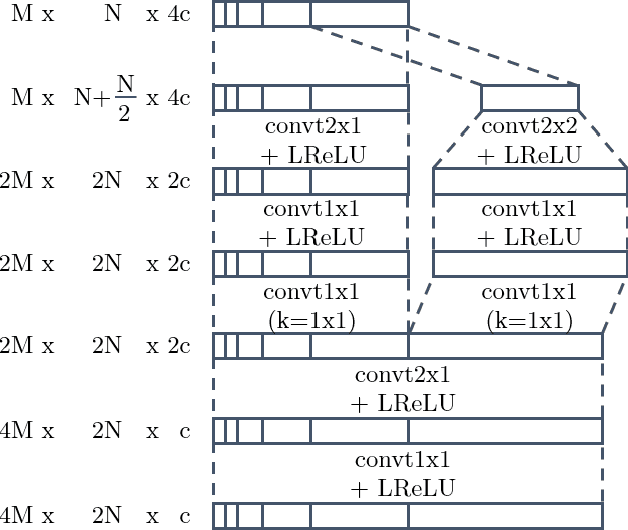
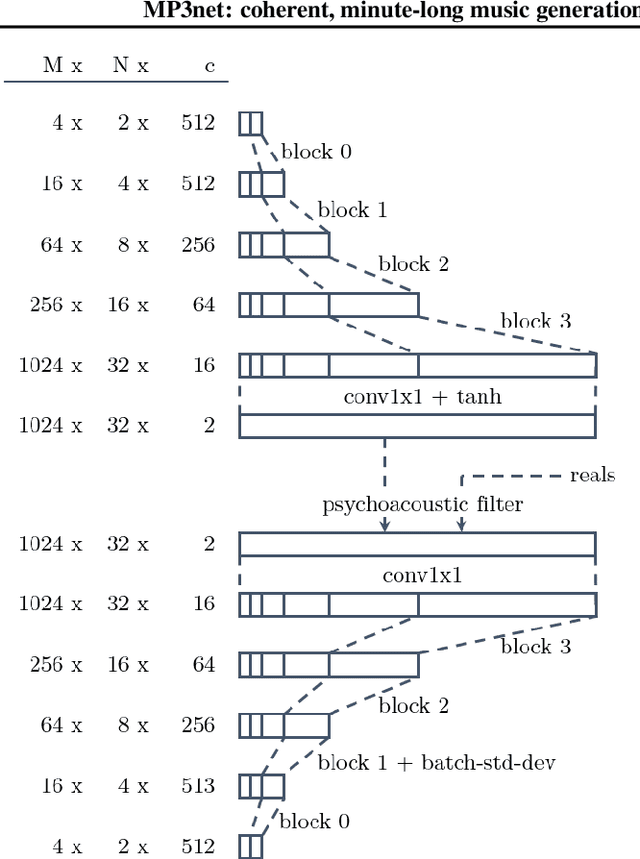
We present a deep convolutional GAN which leverages techniques from MP3/Vorbis audio compression to produce long, high-quality audio samples with long-range coherence. The model uses a Modified Discrete Cosine Transform (MDCT) data representation, which includes all phase information. Phase generation is hence integral part of the model. We leverage the auditory masking and psychoacoustic perception limit of the human ear to widen the true distribution and stabilize the training process. The model architecture is a deep 2D convolutional network, where each subsequent generator model block increases the resolution along the time axis and adds a higher octave along the frequency axis. The deeper layers are connected with all parts of the output and have the context of the full track. This enables generation of samples which exhibit long-range coherence. We use MP3net to create 95s stereo tracks with a 22kHz sample rate after training for 250h on a single Cloud TPUv2. An additional benefit of the CNN-based model architecture is that generation of new songs is almost instantaneous.
Hierarchical Recurrent Attention Networks for Structured Online Maps
Dec 22, 2020
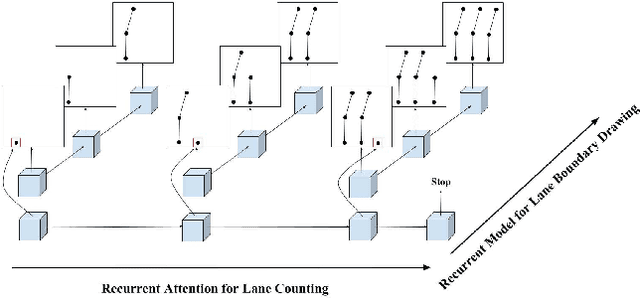

In this paper, we tackle the problem of online road network extraction from sparse 3D point clouds. Our method is inspired by how an annotator builds a lane graph, by first identifying how many lanes there are and then drawing each one in turn. We develop a hierarchical recurrent network that attends to initial regions of a lane boundary and traces them out completely by outputting a structured polyline. We also propose a novel differentiable loss function that measures the deviation of the edges of the ground truth polylines and their predictions. This is more suitable than distances on vertices, as there exists many ways to draw equivalent polylines. We demonstrate the effectiveness of our method on a 90 km stretch of highway, and show that we can recover the right topology 92\% of the time.
Multi-Agent Reinforcement Learning for Persistent Monitoring
Nov 02, 2020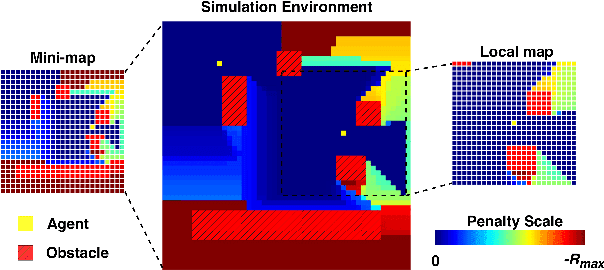
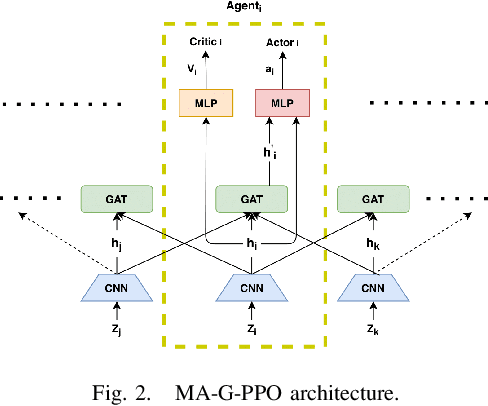

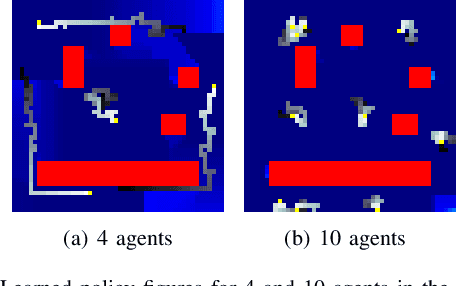
The Persistent Monitoring (PM) problem seeks to find a set of trajectories (or controllers) for robots to persistently monitor a changing environment. Each robot has a limited field-of-view and may need to coordinate with others to ensure no point in the environment is left unmonitored for long periods of time. We model the problem such that there is a penalty that accrues every time step if a point is left unmonitored. However, the dynamics of the penalty are unknown to us. We present a Multi-Agent Reinforcement Learning (MARL) algorithm for the persistent monitoring problem. Specifically, we present a Multi-Agent Graph Attention Proximal Policy Optimization (MA-G-PPO) algorithm that takes as input the local observations of all agents combined with a low resolution global map to learn a policy for each agent. The graph attention allows agents to share their information with others leading to an effective joint policy. Our main focus is to understand how effective MARL is for the PM problem. We investigate five research questions with this broader goal. We find that MA-G-PPO is able to learn a better policy than the non-RL baseline in most cases, the effectiveness depends on agents sharing information with each other, and the policy learnt shows emergent behavior for the agents.
A Two-Stage Deep Learning Detection Classifier for the ATLAS Asteroid Survey
Jan 22, 2021
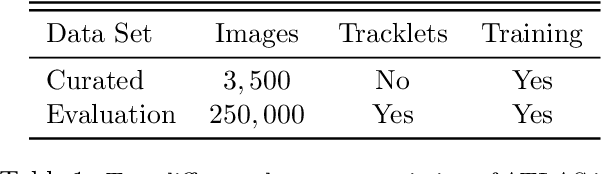
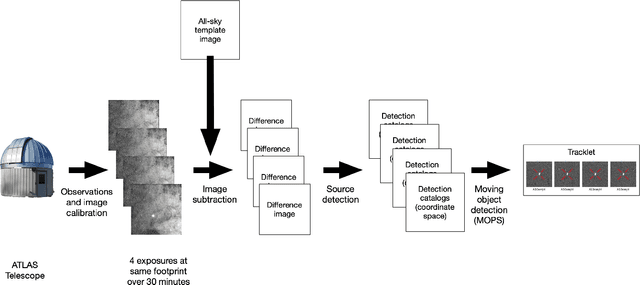
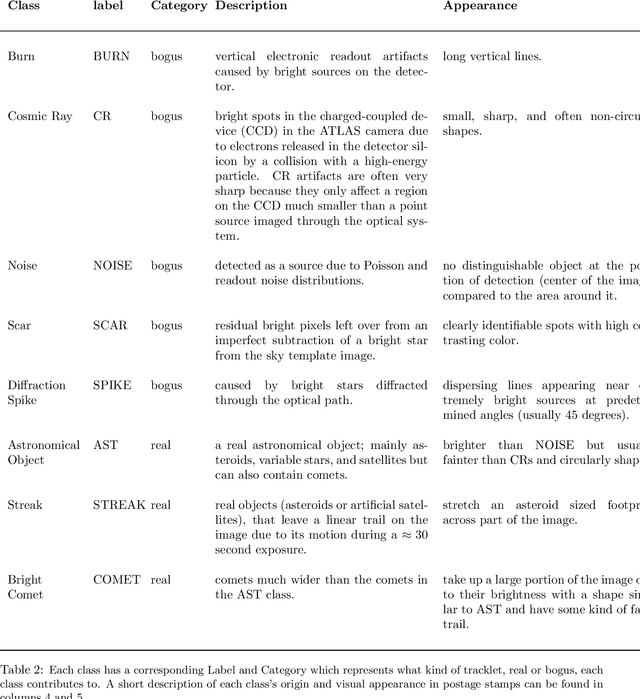
In this paper we present a two-step neural network model to separate detections of solar system objects from optical and electronic artifacts in data obtained with the "Asteroid Terrestrial-impact Last Alert System" (ATLAS), a near-Earth asteroid sky survey system [arXiv:1802.00879]. A convolutional neural network [arXiv:1807.10912] is used to classify small "postage-stamp" images of candidate detections of astronomical sources into eight classes, followed by a multi-layered perceptron that provides a probability that a temporal sequence of four candidate detections represents a real astronomical source. The goal of this work is to reduce the time delay between Near-Earth Object (NEO) detections and submission to the Minor Planet Center. Due to the rare and hazardous nature of NEOs [Harris and D'Abramo, 2015], a low false negative rate is a priority for the model. We show that the model reaches 99.6\% accuracy on real asteroids in ATLAS data with a 0.4\% false negative rate. Deployment of this model on ATLAS has reduced the amount of NEO candidates that astronomers must screen by 90%, thereby bringing ATLAS one step closer to full autonomy.
Autonomous Exploration Under Uncertainty via Deep Reinforcement Learning on Graphs
Jul 24, 2020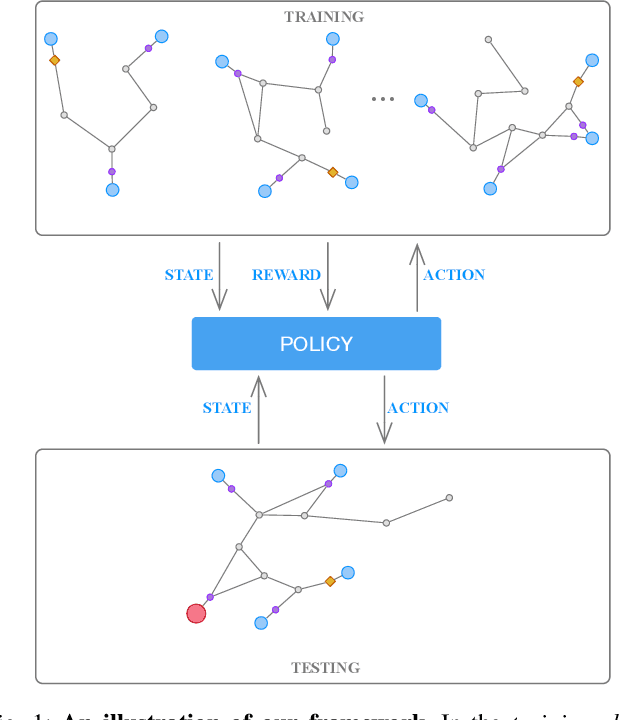
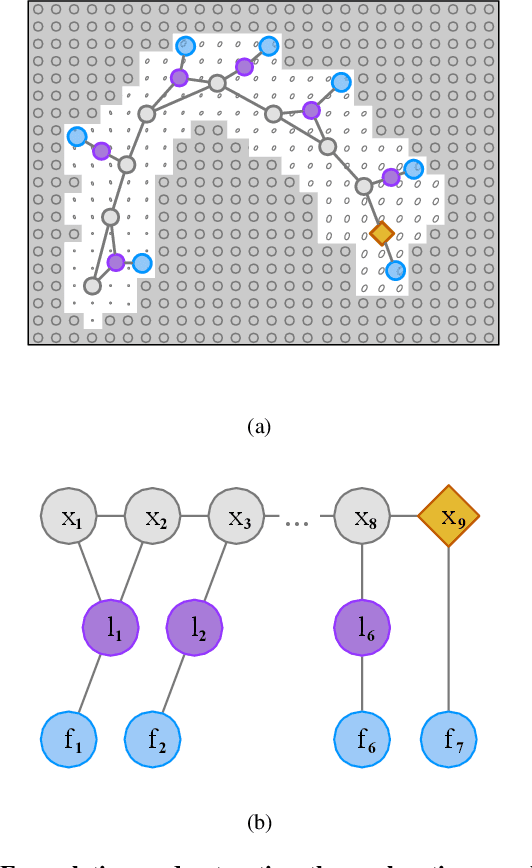
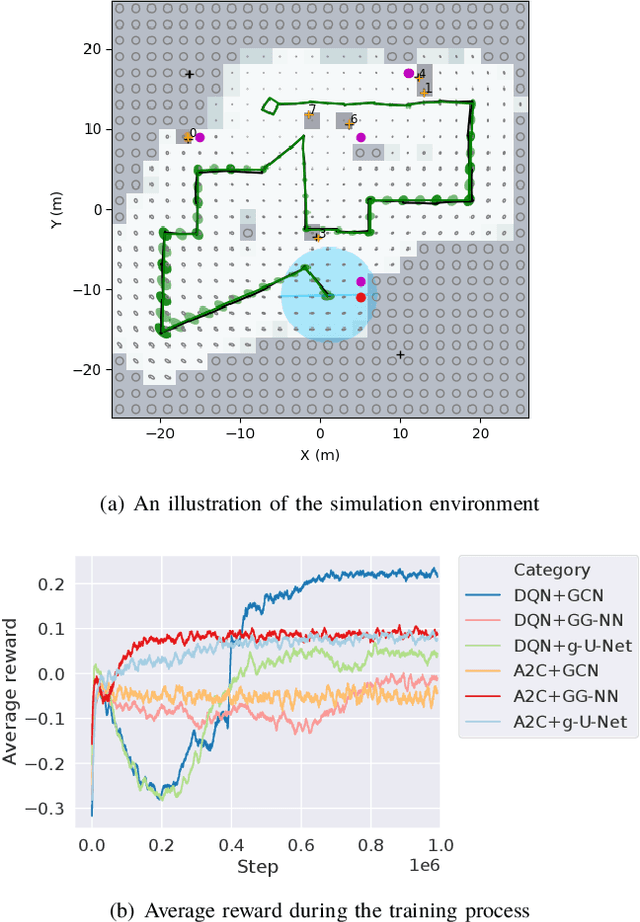
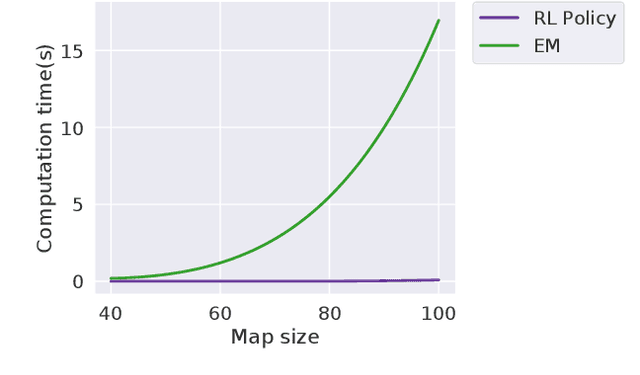
We consider an autonomous exploration problem in which a range-sensing mobile robot is tasked with accurately mapping the landmarks in an a priori unknown environment efficiently in real-time; it must choose sensing actions that both curb localization uncertainty and achieve information gain. For this problem, belief space planning methods that forward-simulate robot sensing and estimation may often fail in real-time implementation, scaling poorly with increasing size of the state, belief and action spaces. We propose a novel approach that uses graph neural networks (GNNs) in conjunction with deep reinforcement learning (DRL), enabling decision-making over graphs containing exploration information to predict a robot's optimal sensing action in belief space. The policy, which is trained in different random environments without human intervention, offers a real-time, scalable decision-making process whose high-performance exploratory sensing actions yield accurate maps and high rates of information gain.
Shortening Time Required for Adaptive Structural Learning Method of Deep Belief Network with Multi-Modal Data Arrangement
Jul 11, 2018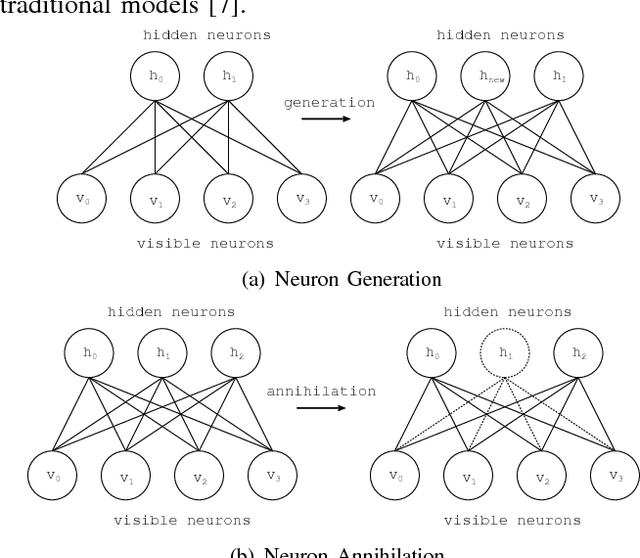
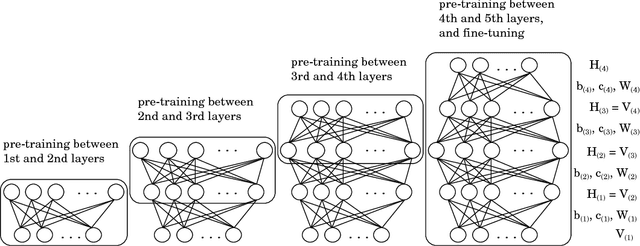
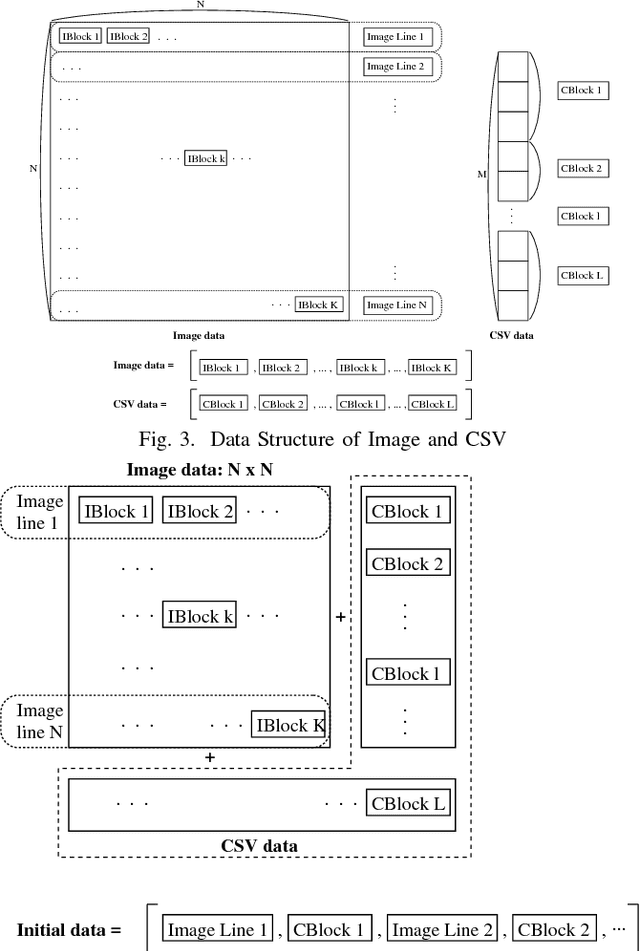
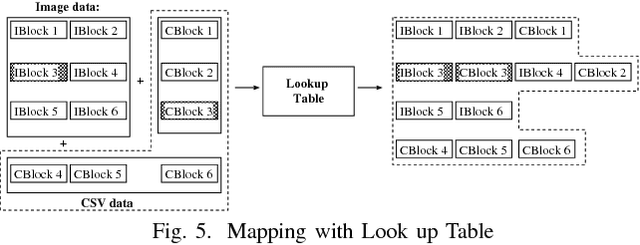
Recently, Deep Learning has been applied in the techniques of artificial intelligence. Especially, Deep Learning performed good results in the field of image recognition. Most new Deep Learning architectures are naturally developed in image recognition. For this reason, not only the numerical data and text data but also the time-series data are transformed to the image data format. Multi-modal data consists of two or more kinds of data such as picture and text. The arrangement in a general method is formed in the squared array with no specific aim. In this paper, the data arrangement are modified according to the similarity of input-output pattern in Adaptive Structural Learning method of Deep Belief Network. The similarity of output signals of hidden neurons is made by the order rearrangement of hidden neurons. The experimental results for the data rearrangement in squared array showed the shortening time required for DBN learning.
On Fast Adversarial Robustness Adaptation in Model-Agnostic Meta-Learning
Feb 20, 2021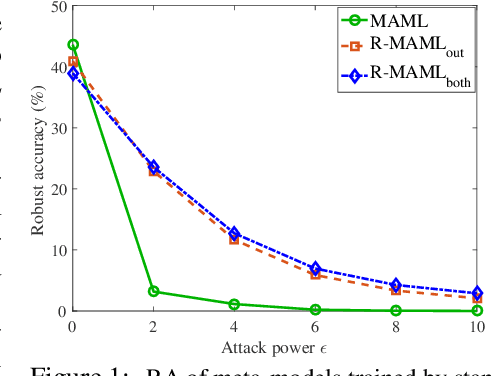

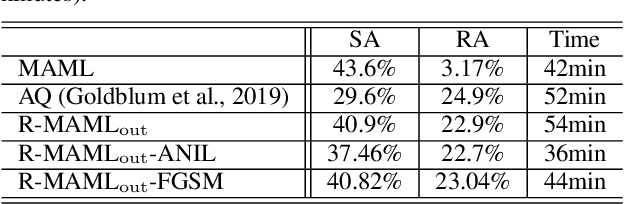
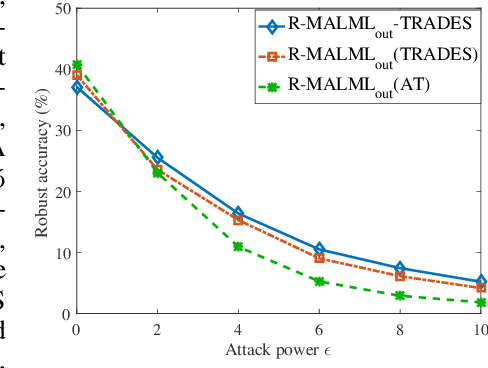
Model-agnostic meta-learning (MAML) has emerged as one of the most successful meta-learning techniques in few-shot learning. It enables us to learn a meta-initialization} of model parameters (that we call meta-model) to rapidly adapt to new tasks using a small amount of labeled training data. Despite the generalization power of the meta-model, it remains elusive that how adversarial robustness can be maintained by MAML in few-shot learning. In addition to generalization, robustness is also desired for a meta-model to defend adversarial examples (attacks). Toward promoting adversarial robustness in MAML, we first study WHEN a robustness-promoting regularization should be incorporated, given the fact that MAML adopts a bi-level (fine-tuning vs. meta-update) learning procedure. We show that robustifying the meta-update stage is sufficient to make robustness adapted to the task-specific fine-tuning stage even if the latter uses a standard training protocol. We also make additional justification on the acquired robustness adaptation by peering into the interpretability of neurons' activation maps. Furthermore, we investigate HOW robust regularization can efficiently be designed in MAML. We propose a general but easily-optimized robustness-regularized meta-learning framework, which allows the use of unlabeled data augmentation, fast adversarial attack generation, and computationally-light fine-tuning. In particular, we for the first time show that the auxiliary contrastive learning task can enhance the adversarial robustness of MAML. Finally, extensive experiments are conducted to demonstrate the effectiveness of our proposed methods in robust few-shot learning.
Graph Gamma Process Generalized Linear Dynamical Systems
Jul 25, 2020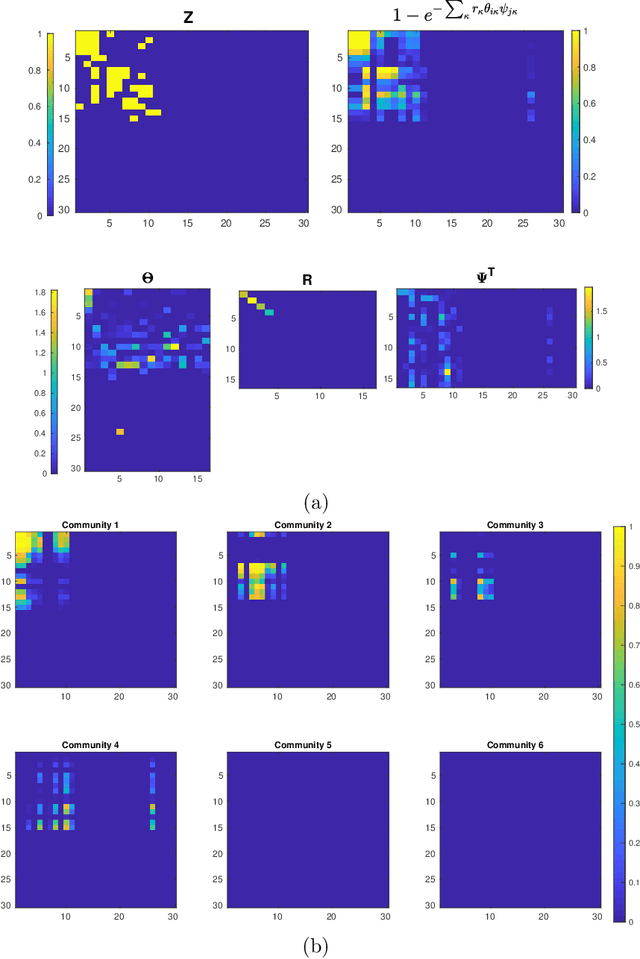
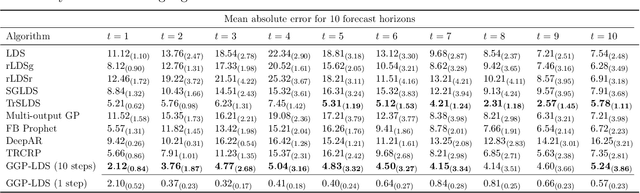

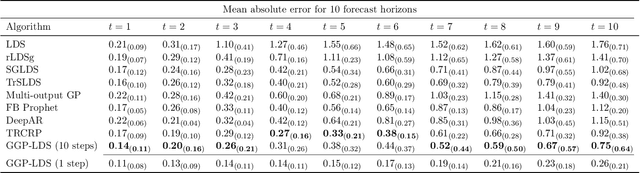
We introduce graph gamma process (GGP) linear dynamical systems to model real-valued multivariate time series. For temporal pattern discovery, the latent representation under the model is used to decompose the time series into a parsimonious set of multivariate sub-sequences. In each sub-sequence, different data dimensions often share similar temporal patterns but may exhibit distinct magnitudes, and hence allowing the superposition of all sub-sequences to exhibit diverse behaviors at different data dimensions. We further generalize the proposed model by replacing the Gaussian observation layer with the negative binomial distribution to model multivariate count time series. Generated from the proposed GGP is an infinite dimensional directed sparse random graph, which is constructed by taking the logical OR operation of countably infinite binary adjacency matrices that share the same set of countably infinite nodes. Each of these adjacency matrices is associated with a weight to indicate its activation strength, and places a finite number of edges between a finite subset of nodes belonging to the same node community. We use the generated random graph, whose number of nonzero-degree nodes is finite, to define both the sparsity pattern and dimension of the latent state transition matrix of a (generalized) linear dynamical system. The activation strength of each node community relative to the overall activation strength is used to extract a multivariate sub-sequence, revealing the data pattern captured by the corresponding community. On both synthetic and real-world time series, the proposed nonparametric Bayesian dynamic models, which are initialized at random, consistently exhibit good predictive performance in comparison to a variety of baseline models, revealing interpretable latent state transition patterns and decomposing the time series into distinctly behaved sub-sequences.
A Three-Stage Algorithm for the Large Scale Dynamic Vehicle Routing Problem with an Industry 4.0 Approach
Oct 04, 2020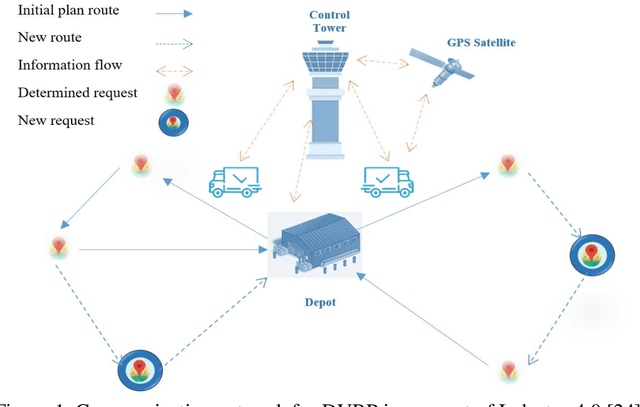

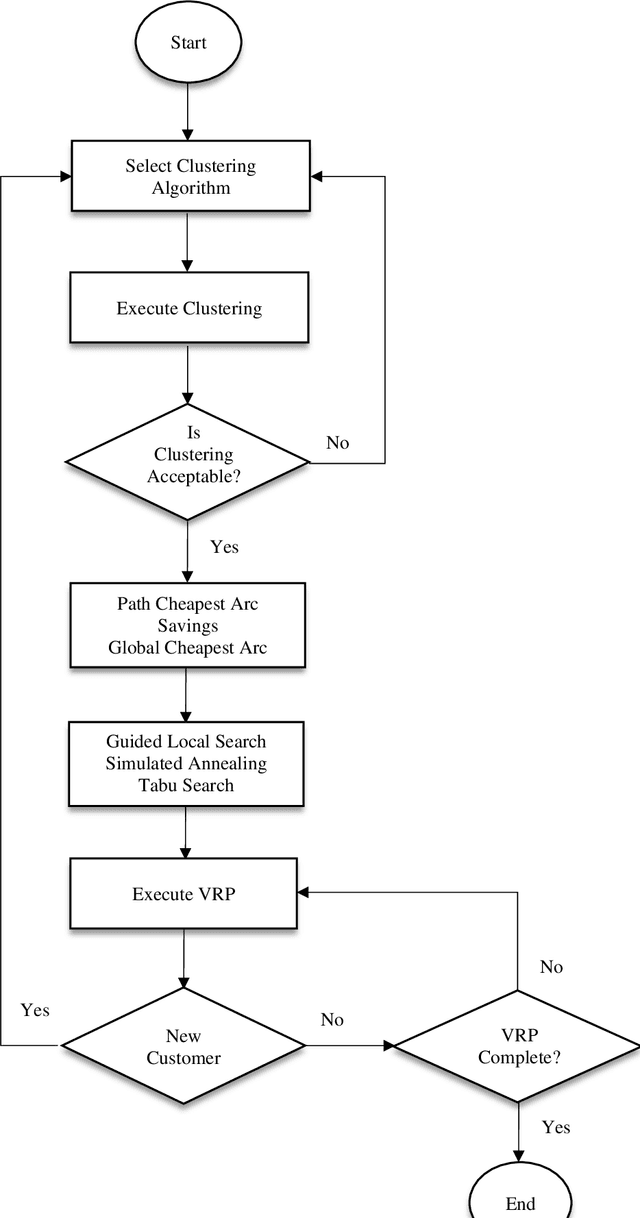
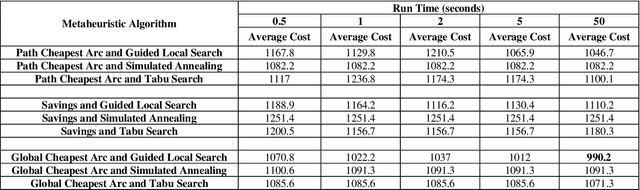
Industry 4.0 is a concept which helps companies to have a smart supply chain system when they are faced with a dynamic process. As Industry 4.0 focuses on mobility and real-time integration, it is a good framework for a Dynamic Vehicle Routing problem (DVRP). The main objective of this research is to solve the DVRP on a large-scale size. The aim of this study is to show that the delivery vehicles must serve customer demands from a common depot to have a minimum transit cost without exceeding the capacity constraint of each vehicle. In VRP, to reach an exact solution is quite difficult, and in large-size real world problems it is often impossible. Also, the computational time complexity of this type of problem grows exponentially. In order to find optimal answers for this problem in medium and large dimensions, using a heuristic approach is recommended as the best approach. A hierarchical approach consisting of three stages as cluster-first, route-construction second, route-improvement third is proposed. In the first stage, customers are clustered based on the number of vehicles with different clustering algorithms (i.e., K-mean, GMM, and BIRCH algorithms). In the second stage, the DVRP is solved using construction algorithms and in the third stage improvement algorithms are applied. The second stage is solved using construction algorithms (i.e. Savings algorithm, path cheapest arc algorithm, etc.). In the third stage, improvement algorithms such as Guided Local Search, Simulated Annealing and Tabu Search are applied. One of the main contributions of this paper is that the proposed approach can deal with large-size real world problems to decrease the computational time complexity. The results of this approach confirmed that the proposed methodology is applicable.