 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Two-Stage Deep Learning Detection Classifier for the ATLAS Asteroid Survey
Jan 22, 2021

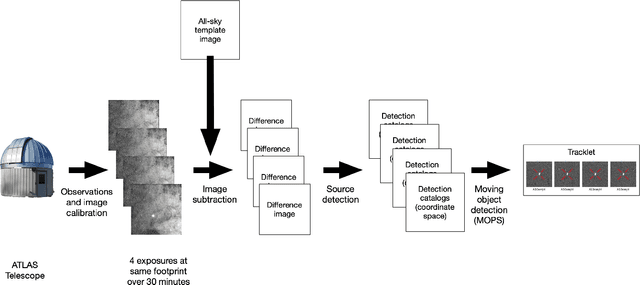
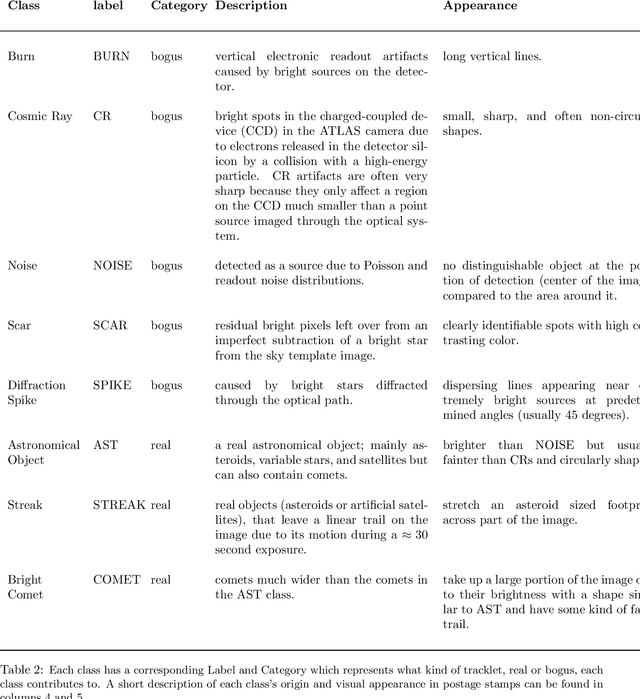
In this paper we present a two-step neural network model to separate detections of solar system objects from optical and electronic artifacts in data obtained with the "Asteroid Terrestrial-impact Last Alert System" (ATLAS), a near-Earth asteroid sky survey system [arXiv:1802.00879]. A convolutional neural network [arXiv:1807.10912] is used to classify small "postage-stamp" images of candidate detections of astronomical sources into eight classes, followed by a multi-layered perceptron that provides a probability that a temporal sequence of four candidate detections represents a real astronomical source. The goal of this work is to reduce the time delay between Near-Earth Object (NEO) detections and submission to the Minor Planet Center. Due to the rare and hazardous nature of NEOs [Harris and D'Abramo, 2015], a low false negative rate is a priority for the model. We show that the model reaches 99.6\% accuracy on real asteroids in ATLAS data with a 0.4\% false negative rate. Deployment of this model on ATLAS has reduced the amount of NEO candidates that astronomers must screen by 90%, thereby bringing ATLAS one step closer to full autonomy.
Structured low-rank matrix completion for forecasting in time series analysis
Feb 22, 2018
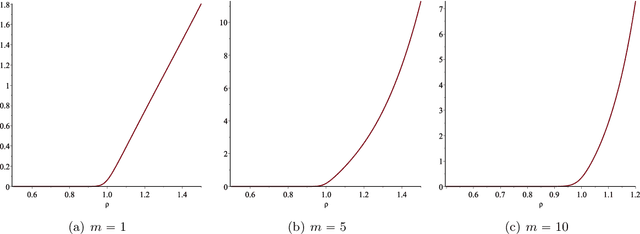
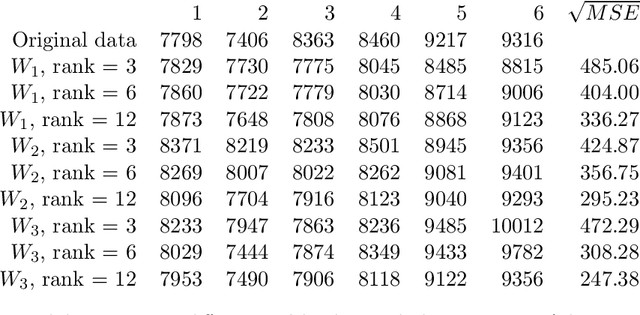
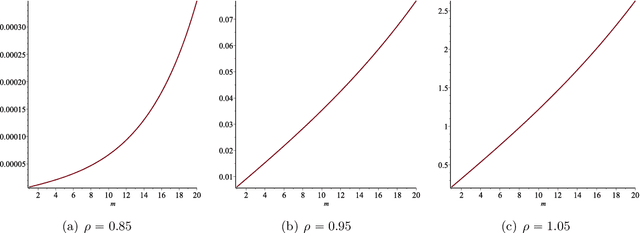
In this paper we consider the low-rank matrix completion problem with specific application to forecasting in time series analysis. Briefly, the low-rank matrix completion problem is the problem of imputing missing values of a matrix under a rank constraint. We consider a matrix completion problem for Hankel matrices and a convex relaxation based on the nuclear norm. Based on new theoretical results and a number of numerical and real examples, we investigate the cases when the proposed approach can work. Our results highlight the importance of choosing a proper weighting scheme for the known observations.
MP3net: coherent, minute-long music generation from raw audio with a simple convolutional GAN
Jan 12, 2021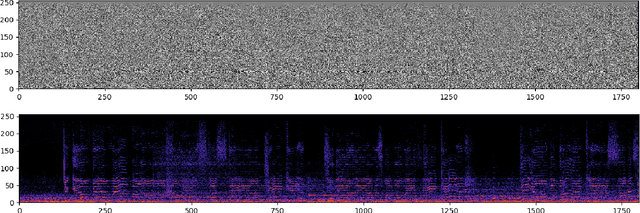
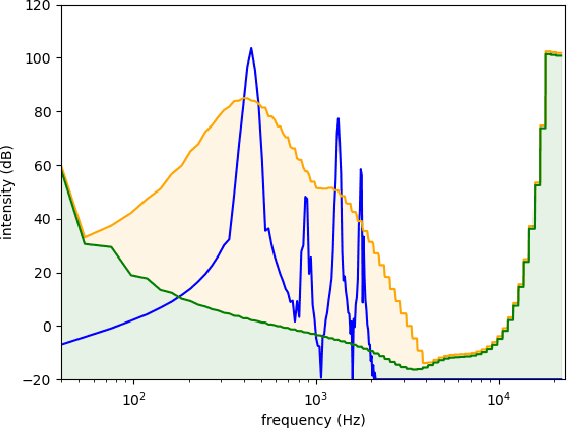
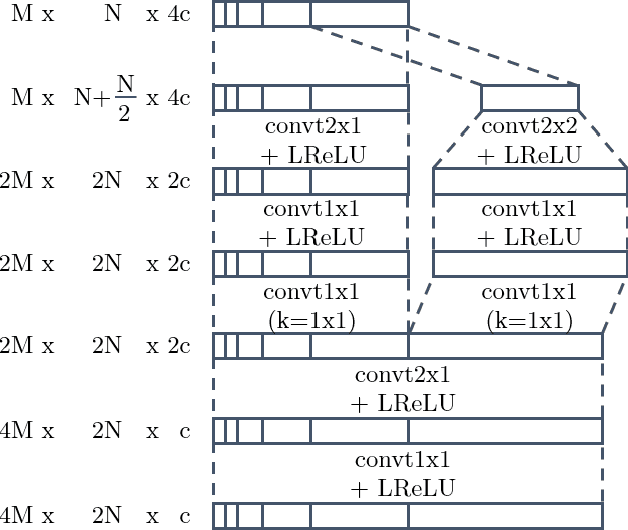
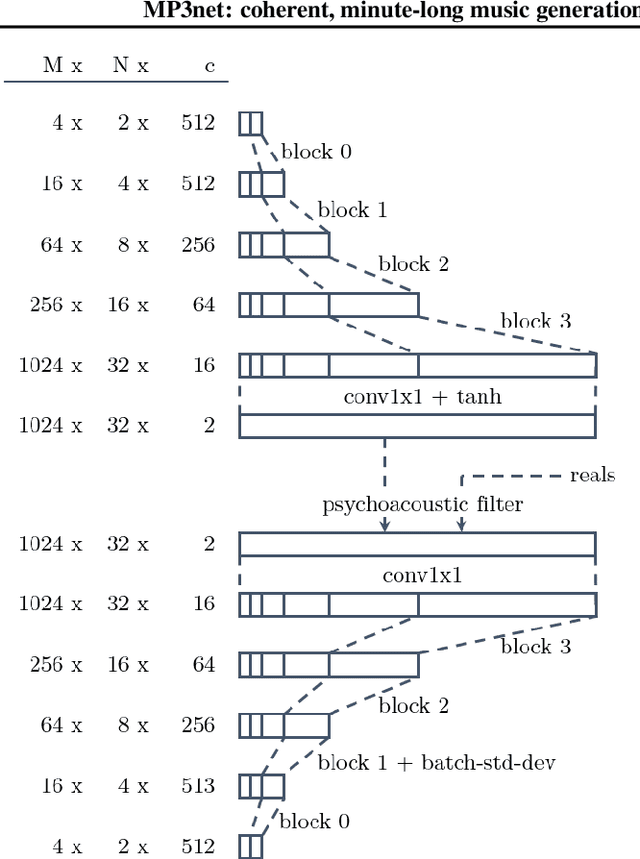
We present a deep convolutional GAN which leverages techniques from MP3/Vorbis audio compression to produce long, high-quality audio samples with long-range coherence. The model uses a Modified Discrete Cosine Transform (MDCT) data representation, which includes all phase information. Phase generation is hence integral part of the model. We leverage the auditory masking and psychoacoustic perception limit of the human ear to widen the true distribution and stabilize the training process. The model architecture is a deep 2D convolutional network, where each subsequent generator model block increases the resolution along the time axis and adds a higher octave along the frequency axis. The deeper layers are connected with all parts of the output and have the context of the full track. This enables generation of samples which exhibit long-range coherence. We use MP3net to create 95s stereo tracks with a 22kHz sample rate after training for 250h on a single Cloud TPUv2. An additional benefit of the CNN-based model architecture is that generation of new songs is almost instantaneous.
Fast robust peg-in-hole insertion with continuous visual servoing
Nov 12, 2020

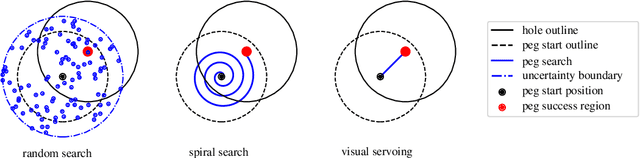

This paper demonstrates a visual servoing method which is robust towards uncertainties related to system calibration and grasping, while significantly reducing the peg-in-hole time compared to classical methods and recent attempts based on deep learning. The proposed visual servoing method is based on peg and hole point estimates from a deep neural network in a multi-cam setup, where the model is trained on purely synthetic data. Empirical results show that the learnt model generalizes to the real world, allowing for higher success rates and lower cycle times than existing approaches.
Event Camera Calibration of Per-pixel Biased Contrast Threshold
Dec 17, 2020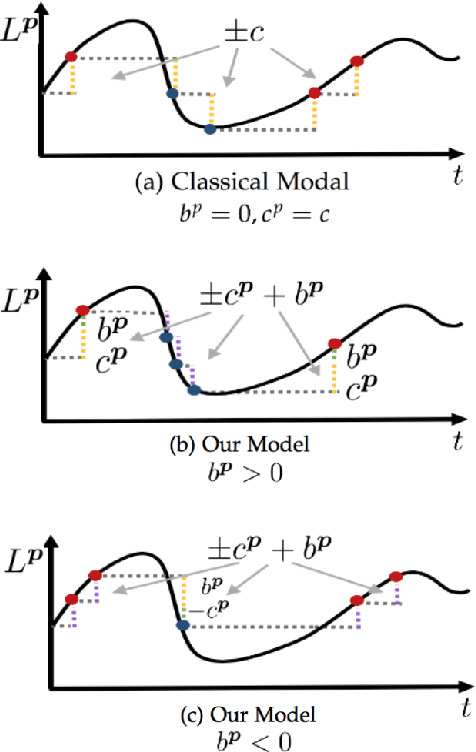
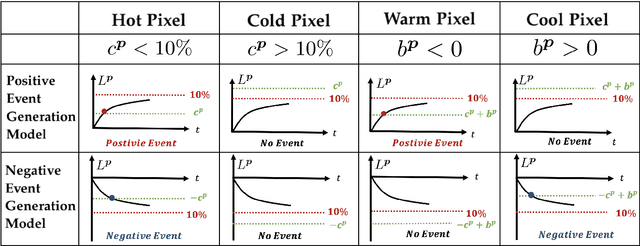
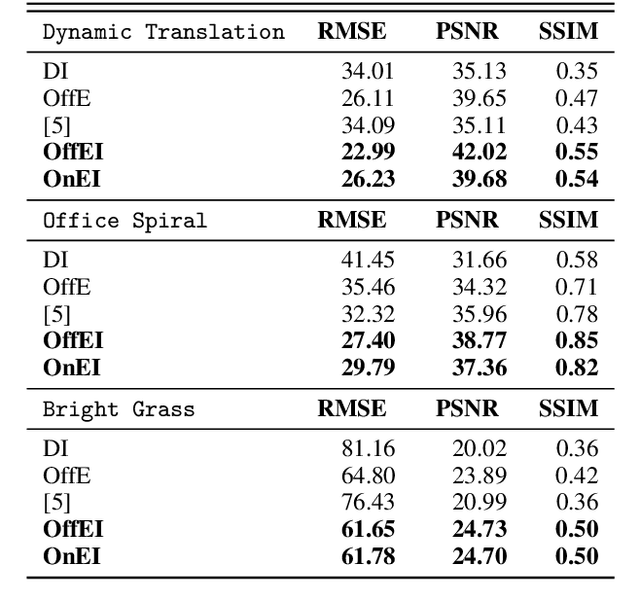
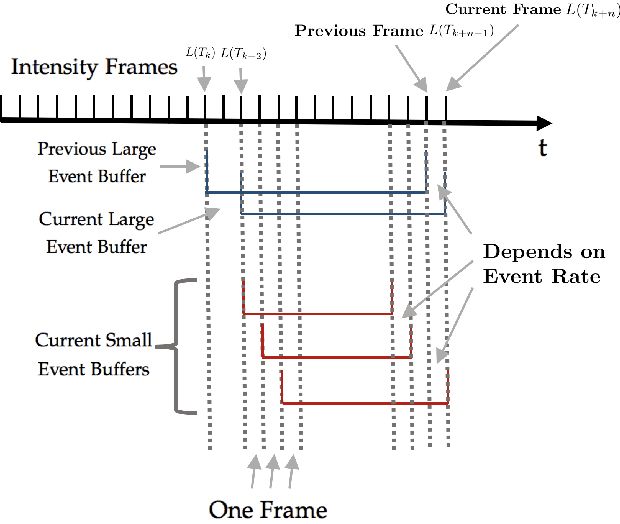
Event cameras output asynchronous events to represent intensity changes with a high temporal resolution, even under extreme lighting conditions. Currently, most of the existing works use a single contrast threshold to estimate the intensity change of all pixels. However, complex circuit bias and manufacturing imperfections cause biased pixels and mismatch contrast threshold among pixels, which may lead to undesirable outputs. In this paper, we propose a new event camera model and two calibration approaches which cover event-only cameras and hybrid image-event cameras. When intensity images are simultaneously provided along with events, we also propose an efficient online method to calibrate event cameras that adapts to time-varying event rates. We demonstrate the advantages of our proposed methods compared to the state-of-the-art on several different event camera datasets.
* 11 pages, 7 figures, the paper has been accepted for publication at the Australian Conference on Robotics and Automation, 2019
TEC: Tensor Ensemble Classifier for Big Data
Feb 26, 2021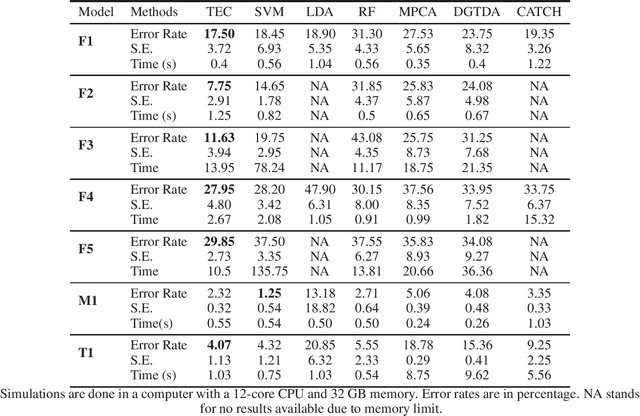
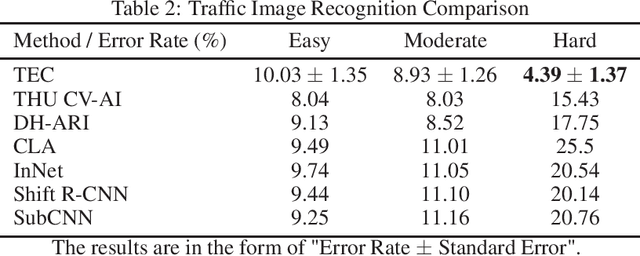
Tensor (multidimensional array) classification problem has become very popular in modern applications such as image recognition and high dimensional spatio-temporal data analysis. Support Tensor Machine (STM) classifier, which is extended from the support vector machine, takes CANDECOMP / Parafac (CP) form of tensor data as input and predicts the data labels. The distribution-free and statistically consistent properties of STM highlight its potential in successfully handling wide varieties of data applications. Training a STM can be computationally expensive with high-dimensional tensors. However, reducing the size of tensor with a random projection technique can reduce the computational time and cost, making it feasible to handle large size tensors on regular machines. We name an STM estimated with randomly projected tensor as Random Projection-based Support Tensor Machine (RPSTM). In this work, we propose a Tensor Ensemble Classifier (TEC), which aggregates multiple RPSTMs for big tensor classification. TEC utilizes the ensemble idea to minimize the excessive classification risk brought by random projection, providing statistically consistent predictions while taking the computational advantage of RPSTM. Since each RPSTM can be estimated independently, TEC can further take advantage of parallel computing techniques and be more computationally efficient. The theoretical and numerical results demonstrate the decent performance of TEC model in high-dimensional tensor classification problems. The model prediction is statistically consistent as its risk is shown to converge to the optimal Bayes risk. Besides, we highlight the trade-off between the computational cost and the prediction risk for TEC model. The method is validated by extensive simulation and a real data example. We prepare a python package for applying TEC, which is available at our GitHub.
Factorized Deep Generative Models for Trajectory Generation with Spatiotemporal-Validity Constraints
Sep 20, 2020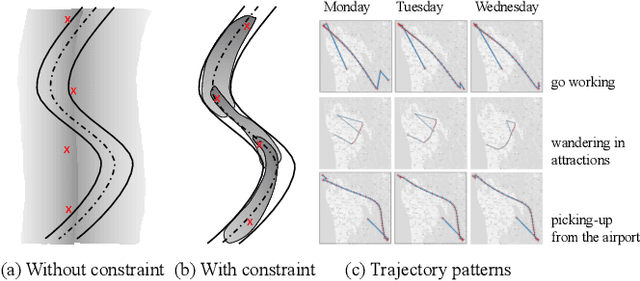
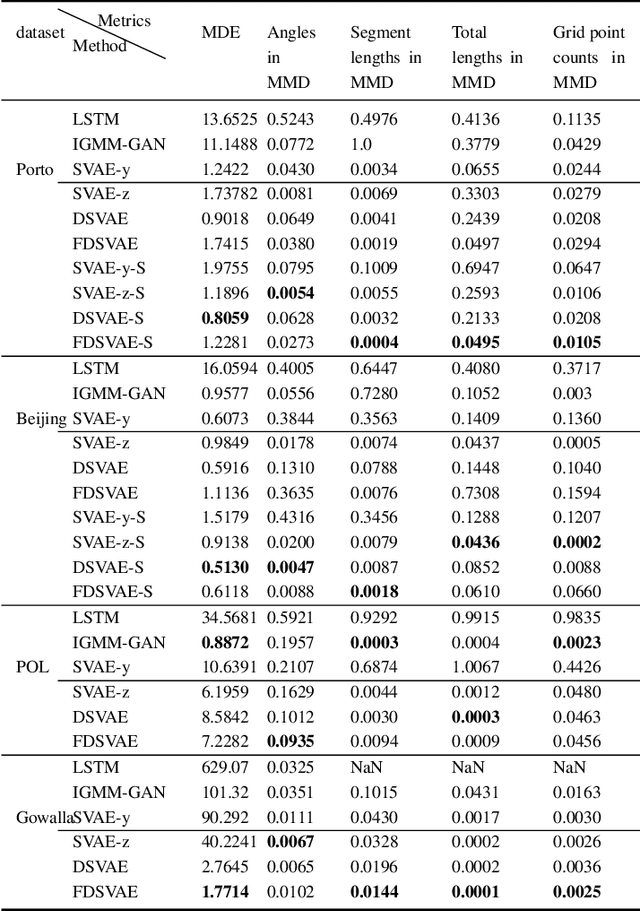
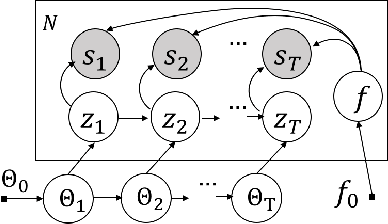
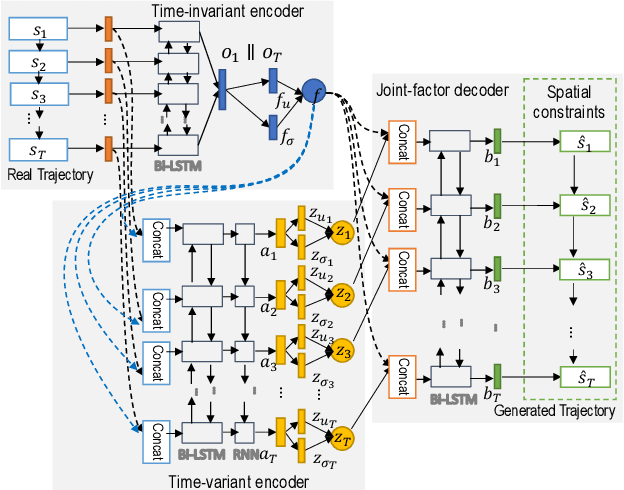
Trajectory data generation is an important domain that characterizes the generative process of mobility data. Traditional methods heavily rely on predefined heuristics and distributions and are weak in learning unknown mechanisms. Inspired by the success of deep generative neural networks for images and texts, a fast-developing research topic is deep generative models for trajectory data which can learn expressively explanatory models for sophisticated latent patterns. This is a nascent yet promising domain for many applications. We first propose novel deep generative models factorizing time-variant and time-invariant latent variables that characterize global and local semantics, respectively. We then develop new inference strategies based on variational inference and constrained optimization to encapsulate the spatiotemporal validity. New deep neural network architectures have been developed to implement the inference and generation models with newly-generalized latent variable priors. The proposed methods achieved significant improvements in quantitative and qualitative evaluations in extensive experiments.
MP Twitter Engagement and Abuse Post-first COVID-19 Lockdown in the UK: White Paper
Mar 04, 2021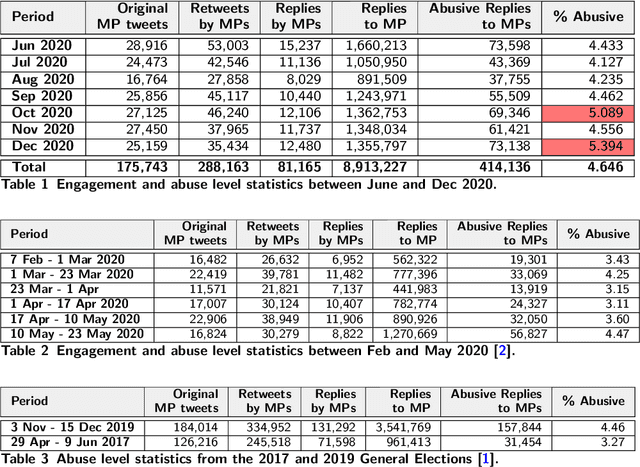
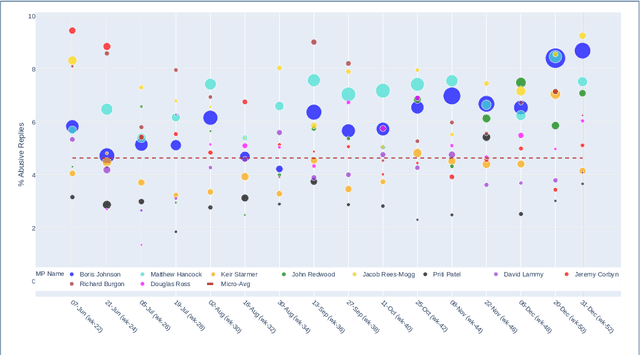
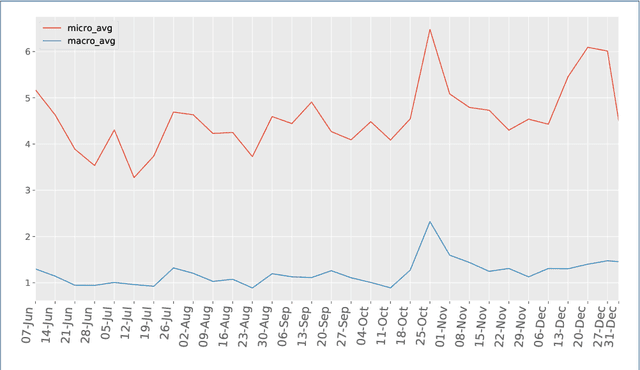
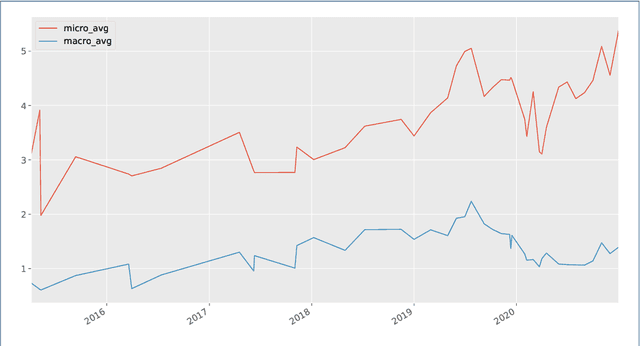
The UK has had a volatile political environment for some years now, with Brexit and leadership crises marking the past five years. With this work, we wanted to understand more about how the global health emergency, COVID-19, influences the amount, type or topics of abuse that UK politicians receive when engaging with the public. With this work, we wanted to understand more about how the global health emergency, COVID-19, influences the amount, type or topics of abuse that UK politicians receive when engaging with the public. This work covers the period of June to December 2020 and analyses Twitter abuse in replies to UK MPs. This work is a follow-up from our analysis of online abuse during the first four months of the COVID-19 pandemic in the UK. The paper examines overall abuse levels during this new seven month period, analyses reactions to members of different political parties and the UK government, and the relationship between online abuse and topics such as Brexit, government's COVID-19 response and policies, and social issues. In addition, we have also examined the presence of conspiracy theories posted in abusive replies to MPs during the period. We have found that abuse levels toward UK MPs were at an all-time high in December 2020 (5.4% of all reply tweets sent to MPs). This is almost 1% higher that the two months preceding the General Election. In a departure from the trend seen in the first four months of the pandemic, MPs from the Tory party received the highest percentage of abusive replies from July 2020 onward, which stays above 5% starting from September 2020 onward, as the COVID-19 crisis deepened and the Brexit negotiations with the EU started nearing completion.
Automatic Extraction of Rules Governing Morphological Agreement
Oct 06, 2020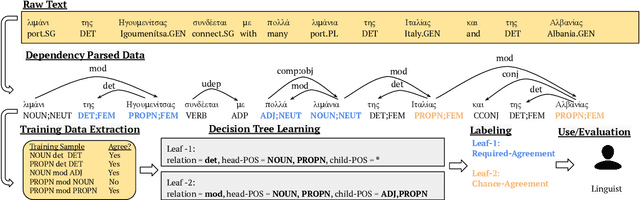
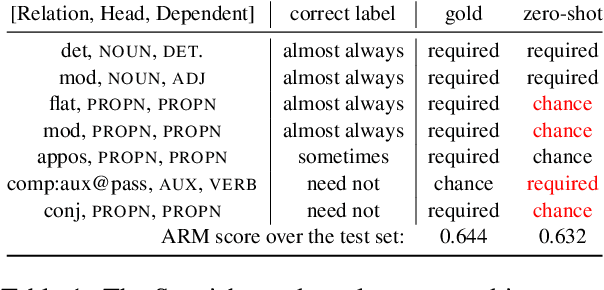
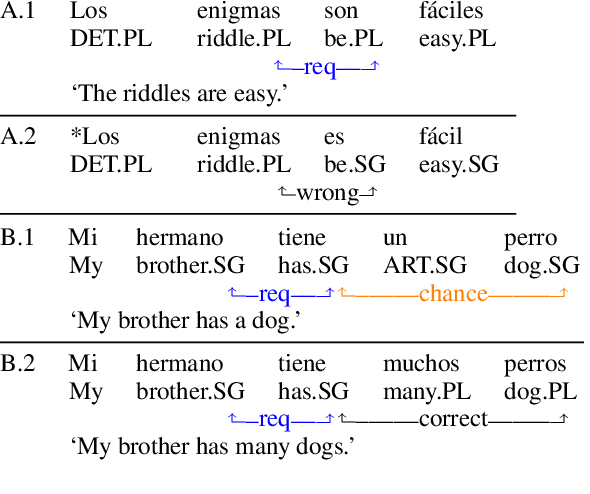
Creating a descriptive grammar of a language is an indispensable step for language documentation and preservation. However, at the same time it is a tedious, time-consuming task. In this paper, we take steps towards automating this process by devising an automated framework for extracting a first-pass grammatical specification from raw text in a concise, human- and machine-readable format. We focus on extracting rules describing agreement, a morphosyntactic phenomenon at the core of the grammars of many of the world's languages. We apply our framework to all languages included in the Universal Dependencies project, with promising results. Using cross-lingual transfer, even with no expert annotations in the language of interest, our framework extracts a grammatical specification which is nearly equivalent to those created with large amounts of gold-standard annotated data. We confirm this finding with human expert evaluations of the rules that our framework produces, which have an average accuracy of 78%. We release an interface demonstrating the extracted rules at https://neulab.github.io/lase/.
Hierarchical Recurrent Attention Networks for Structured Online Maps
Dec 22, 2020
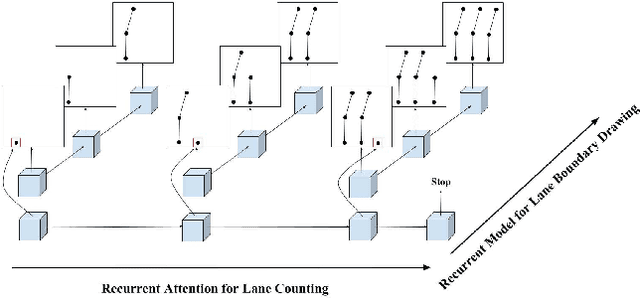

In this paper, we tackle the problem of online road network extraction from sparse 3D point clouds. Our method is inspired by how an annotator builds a lane graph, by first identifying how many lanes there are and then drawing each one in turn. We develop a hierarchical recurrent network that attends to initial regions of a lane boundary and traces them out completely by outputting a structured polyline. We also propose a novel differentiable loss function that measures the deviation of the edges of the ground truth polylines and their predictions. This is more suitable than distances on vertices, as there exists many ways to draw equivalent polylines. We demonstrate the effectiveness of our method on a 90 km stretch of highway, and show that we can recover the right topology 92\% of the time.