 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real Time Emulation of Parametric Guitar Tube Amplifier With Long Short Term Memory Neural Network
Apr 19, 2018
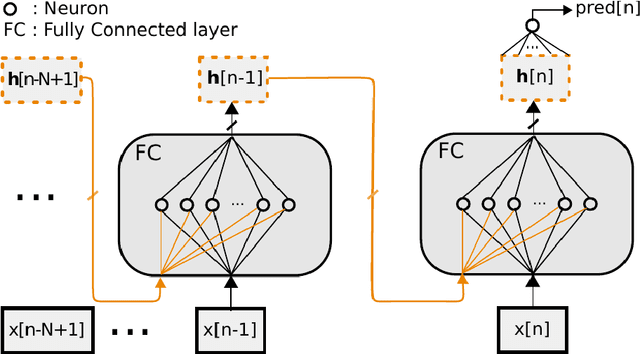
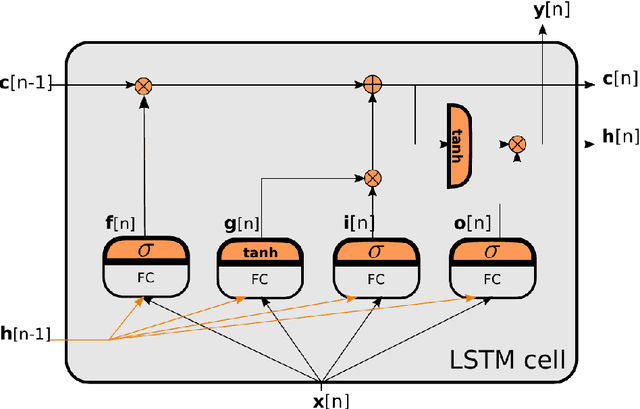
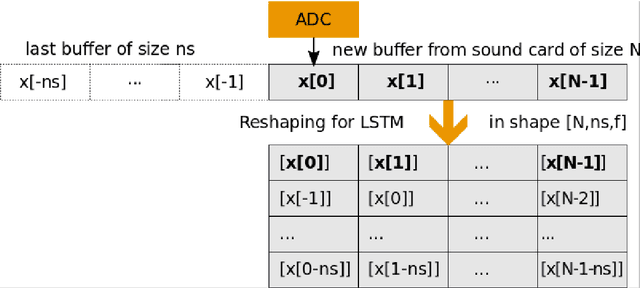
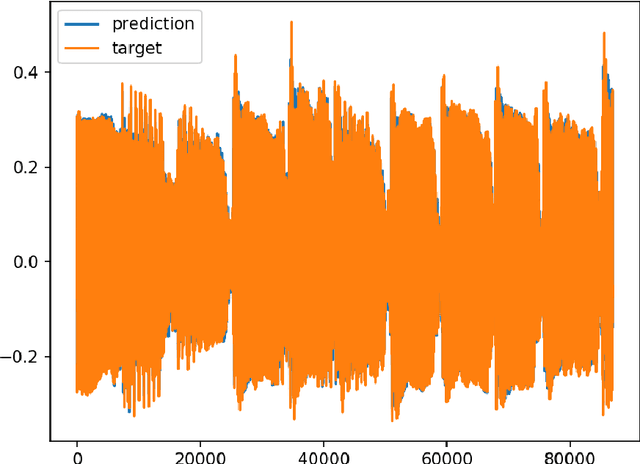
Numerous audio systems for musicians are expensive and bulky. Therefore, it could be advantageous to model them and to replace them by computer emulation. In guitar players' world, audio systems could have a desirable nonlinear behavior (distortion effects). It is thus difficult to find a simple model to emulate them in real time. Volterra series model and its subclass are usual ways to model nonlinear systems. Unfortunately, these systems are difficult to identify in an analytic way. In this paper we propose to take advantage of the new progress made in neural networks to emulate them in real time. We show that an accurate emulation can be reached with less than 1% of root mean square error between the signal coming from a tube amplifier and the output of the neural network. Moreover, the research has been extended to model the Gain parameter of the amplifier.
OpenHPS: An Open Source Hybrid Positioning System
Dec 29, 2020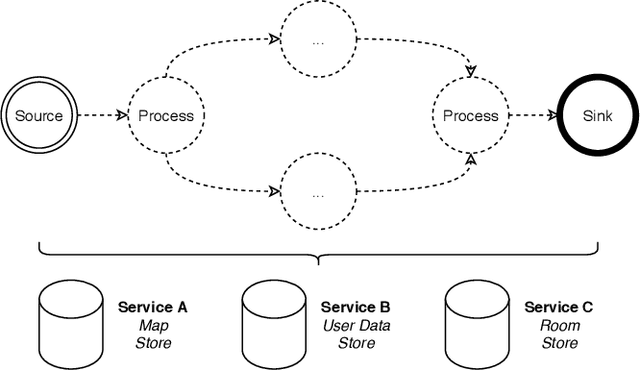
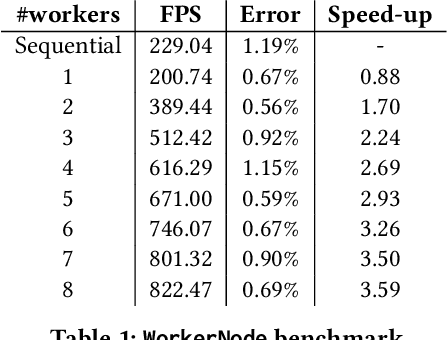
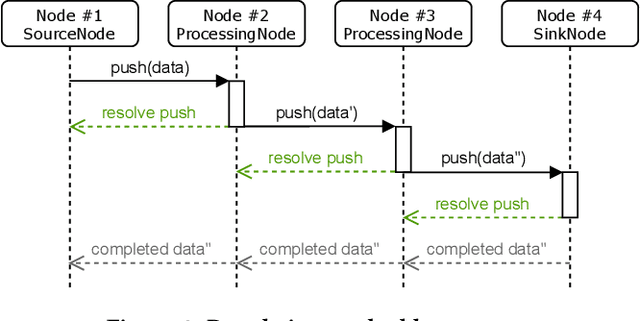
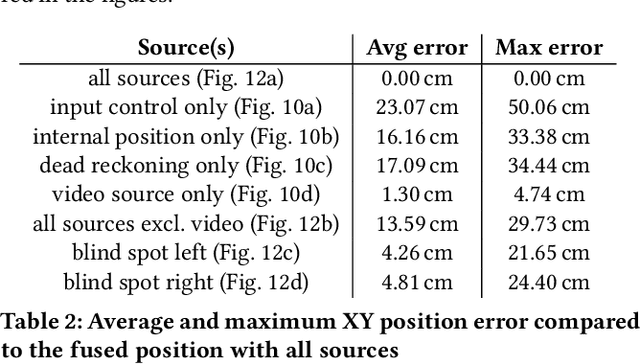
Positioning systems and frameworks use various techniques to determine the position of an object. Some of the existing solutions combine different sensory data at the time of positioning in order to compute more accurate positions by reducing the error introduced by the used individual positioning techniques. We present OpenHPS, a generic hybrid positioning system implemented in TypeScript, that can not only reduce the error during tracking by fusing different sensory data based on different algorithms, but also also make use of combined tracking techniques when calibrating or training the system. In addition to a detailed discussion of the architecture, features and implementation of the extensible open source OpenHPS framework, we illustrate the use of our solution in a demonstrator application fusing different positioning techniques. While OpenHPS offers a number of positioning techniques, future extensions might integrate new positioning methods or algorithms and support additional levels of abstraction including symbolic locations.
Near-Optimal Reactive Synthesis Incorporating Runtime Information
Jul 31, 2020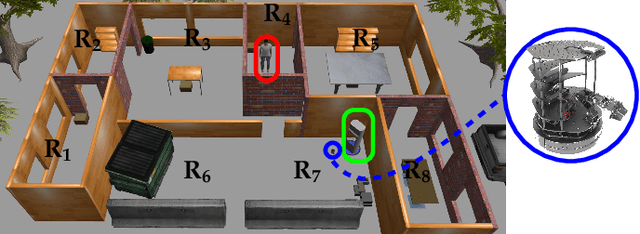
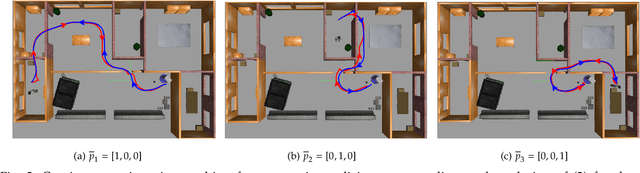
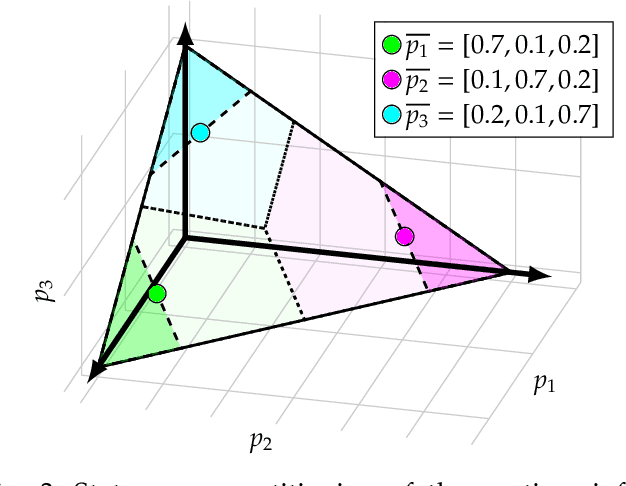
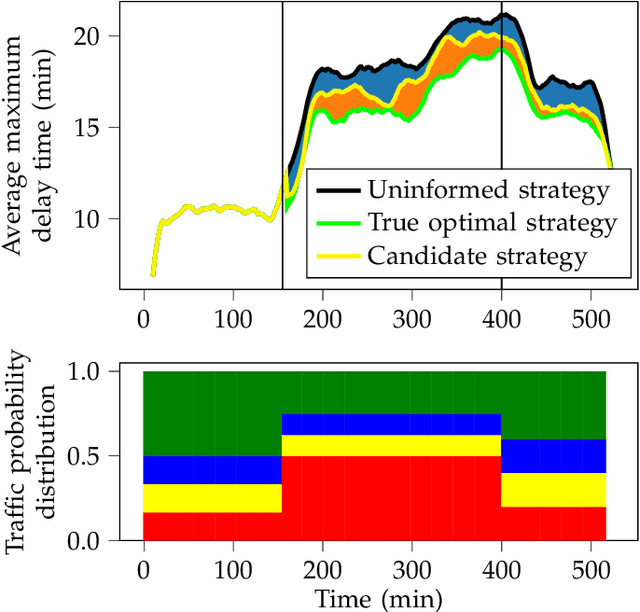
We consider the problem of optimal reactive synthesis - compute a strategy that satisfies a mission specification in a dynamic environment, and optimizes a performance metric. We incorporate task-critical information, that is only available at runtime, into the strategy synthesis in order to improve performance. Existing approaches to utilising such time-varying information require online re-synthesis, which is not computationally feasible in real-time applications. In this paper, we pre-synthesize a set of strategies corresponding to candidate instantiations (pre-specified representative information scenarios). We then propose a novel switching mechanism to dynamically switch between the strategies at runtime while guaranteeing all safety and liveness goals are met. We also characterize bounds on the performance suboptimality. We demonstrate our approach on two examples - robotic motion planning where the likelihood of the position of the robot's goal is updated in real-time, and an air traffic management problem for urban air mobility.
SCA-Net: A Self-Correcting Two-Layer Autoencoder for Hyper-spectral Unmixing
Feb 15, 2021
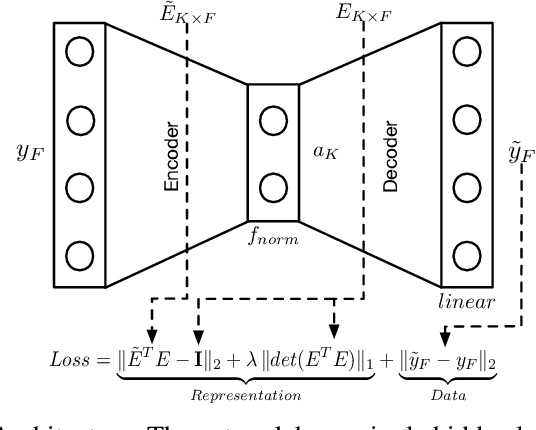
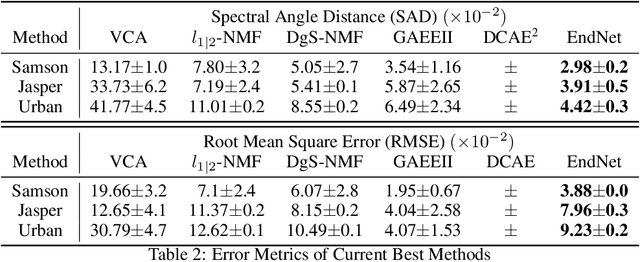
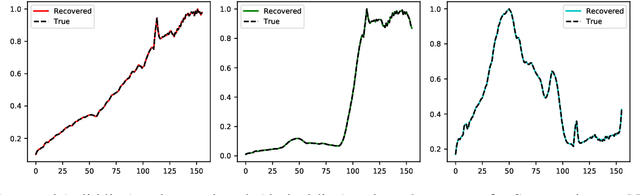
Linear Mixture Model for hyperspectral datasets involves separating a mixed pixel as a linear combination of its constituent endmembers and corresponding fractional abundances. Both optimization and neural methods have attempted to tackle this problem, with the current state of the art results achieved by neural models on benchmark datasets. However, our review of these neural models show that these networks are severely over-parameterized and consequently the invariant endmember spectra extracted as decoder weights has a high variance over multiple runs. All of these approaches require substantial post-processing to satisfy LMM constraints. Furthermore, they also require an exact specification of the number of endmembers and specialized initialization of weights from other algorithms like VCA. Our work shows for the first time that a two-layer autoencoder (SCA-Net), with $2FK$ parameters ($F$ features, $K$ endmembers), achieves error metrics that are scales apart ($10^{-5})$ from previously reported values $(10^{-2})$. SCA-Net converges to this low error solution starting from a random initialization of weights. We also show that SCA-Net, based upon a bi-orthogonal representation, performs a self-correction when the the number of endmembers are over-specified. We show that our network formulation extracts a low-rank representation that is bounded below by a tail-energy and can be computationally verified. Our numerical experiments on Samson, Jasper, and Urban datasets demonstrate that SCA-Net outperforms previously reported error metrics for all the cases while being robust to noise and outliers.
Toward Force Estimation in Robot-Assisted Surgery using Deep Learning with Vision and Robot State
Nov 04, 2020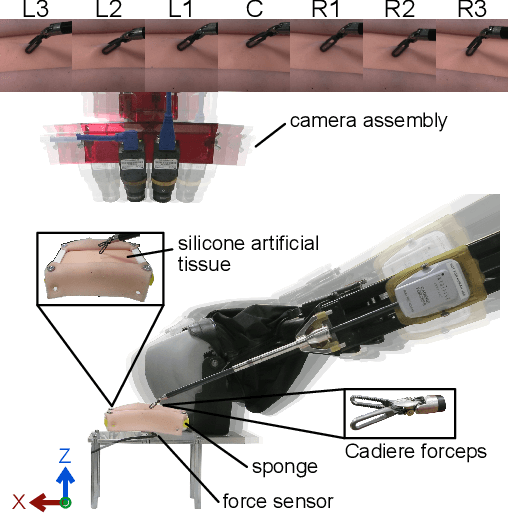
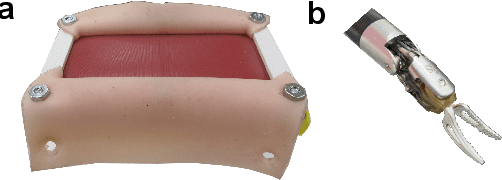
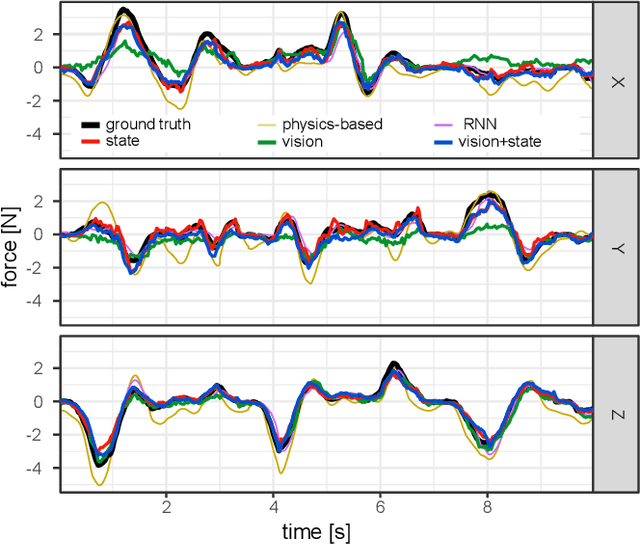
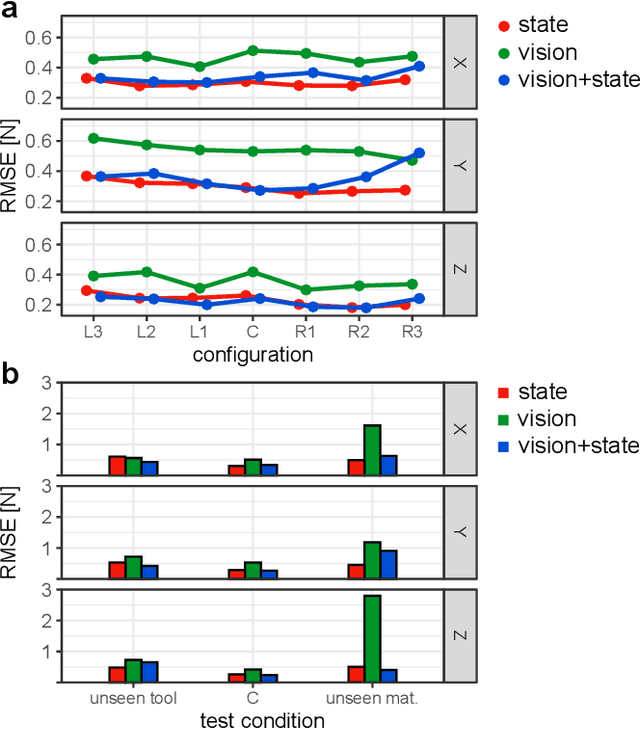
Knowledge of interaction forces during teleoperated robot-assisted surgery could be used to enable force feedback to human operators and evaluate tissue handling skill. However, direct force sensing at the end-effector is challenging because it requires biocompatible, sterilizable, and cost-effective sensors. Vision-based deep learning using convolutional neural networks is a promising approach for providing useful force estimates, though questions remain about generalization to new scenarios and real-time inference. We present a force estimation neural network that uses RGB images and robot state as inputs. Using a self-collected dataset, we compared the network to variants that included only a single input type, and evaluated how they generalized to new viewpoints, workspace positions, materials, and tools. We found that vision-based networks were sensitive to shifts in viewpoints, while state-only networks were robust to changes in workspace. The network with both state and vision inputs had the highest accuracy for an unseen tool, and was moderately robust to changes in viewpoints. Through feature removal studies, we found that using only position features produced better accuracy than using only force features as input. The network with both state and vision inputs outperformed a physics-based baseline model in accuracy. It showed comparable accuracy but faster computation times than a baseline recurrent neural network, making it better suited for real-time applications.
DeepWriteSYN: On-Line Handwriting Synthesis via Deep Short-Term Representations
Sep 14, 2020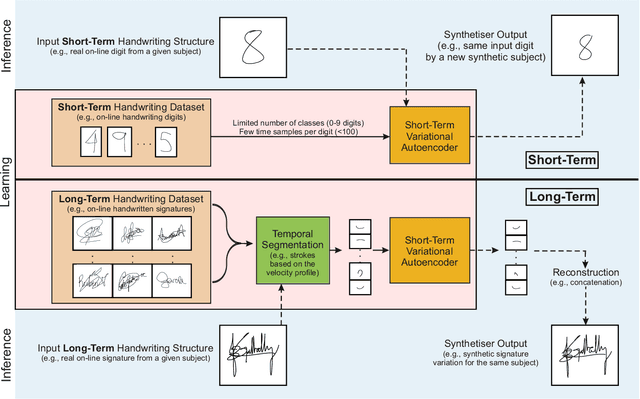
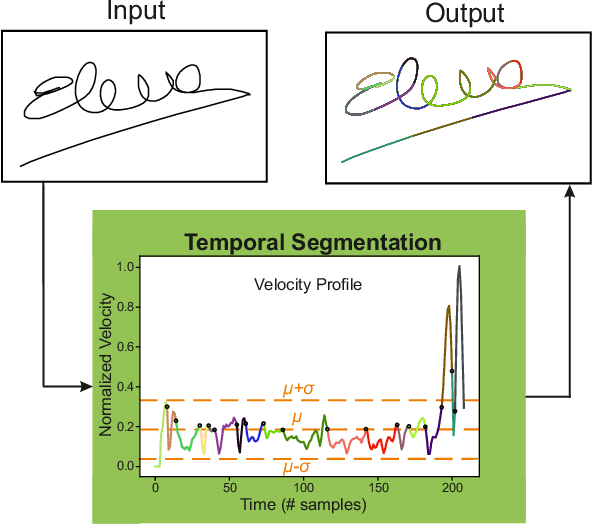
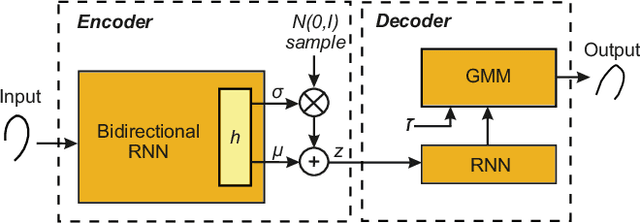
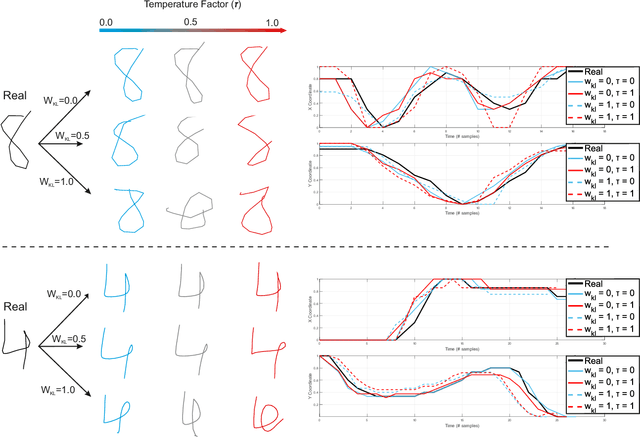
This study proposes DeepWriteSYN, a novel on-line handwriting synthesis approach via deep short-term representations. It comprises two modules: i) an optional and interchangeable temporal segmentation, which divides the handwriting into short-time segments consisting of individual or multiple concatenated strokes; and ii) the on-line synthesis of those short-time handwriting segments, which is based on a sequence-to-sequence Variational Autoencoder (VAE). The main advantages of the proposed approach are that the synthesis is carried out in short-time segments (that can run from a character fraction to full characters) and that the VAE can be trained on a configurable handwriting dataset. These two properties give a lot of flexibility to our synthesiser, e.g., as shown in our experiments, DeepWriteSYN can generate realistic handwriting variations of a given handwritten structure corresponding to the natural variation within a given population or a given subject. These two cases are developed experimentally for individual digits and handwriting signatures, respectively, achieving in both cases remarkable results. Also, we provide experimental results for the task of on-line signature verification showing the high potential of DeepWriteSYN to improve significantly one-shot learning scenarios. To the best of our knowledge, this is the first synthesis approach capable of generating realistic on-line handwriting in the short term (including handwritten signatures) via deep learning. This can be very useful as a module toward long-term realistic handwriting generation either completely synthetic or as natural variation of given handwriting samples.
Multi-agent navigation based on deep reinforcement learning and traditional pathfinding algorithm
Dec 05, 2020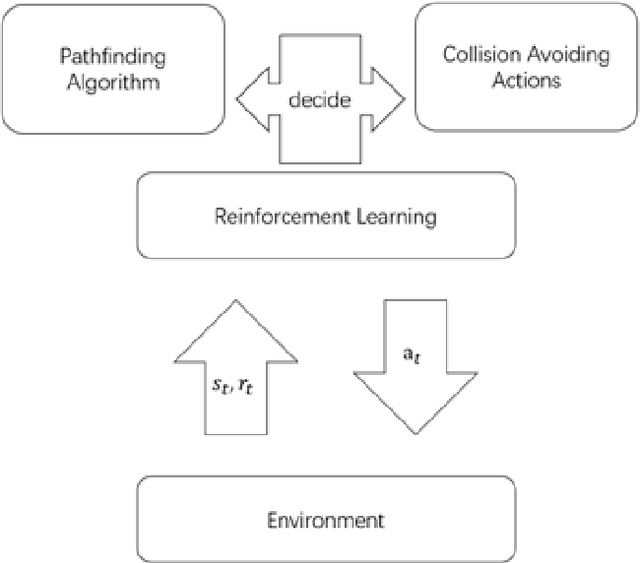
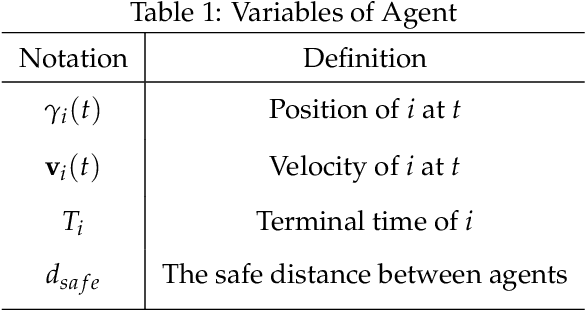
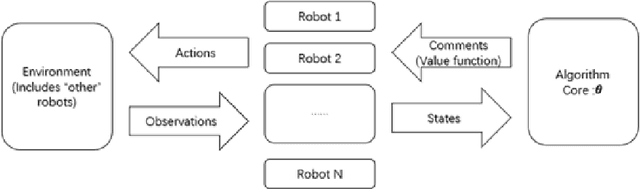

We develop a new framework for multi-agent collision avoidance problem. The framework combined traditional pathfinding algorithm and reinforcement learning. In our approach, the agents learn whether to be navigated or to take simple actions to avoid their partners via a deep neural network trained by reinforcement learning at each time step. This framework makes it possible for agents to arrive terminal points in abstract new scenarios. In our experiments, we use Unity3D and Tensorflow to build the model and environment for our scenarios. We analyze the results and modify the parameters to approach a well-behaved strategy for our agents. Our strategy could be attached in different environments under different cases, especially when the scale is large.
Hierarchical Reinforcement Learning for Optimal Control of Linear Multi-Agent Systems: the Homogeneous Case
Oct 16, 2020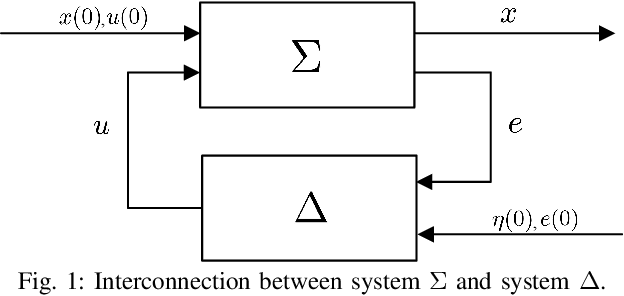



Individual agents in a multi-agent system (MAS) may have decoupled open-loop dynamics, but a cooperative control objective usually results in coupled closed-loop dynamics thereby making the control design computationally expensive. The computation time becomes even higher when a learning strategy such as reinforcement learning (RL) needs to be applied to deal with the situation when the agents dynamics are not known. To resolve this problem, this paper proposes a hierarchical RL scheme for a linear quadratic regulator (LQR) design in a continuous-time linear MAS. The idea is to exploit the structural properties of two graphs embedded in the $Q$ and $R$ weighting matrices in the LQR objective to define an orthogonal transformation that can convert the original LQR design to multiple decoupled smaller-sized LQR designs. We show that if the MAS is homogeneous then this decomposition retains closed-loop optimality. Conditions for decomposability, an algorithm for constructing the transformation matrix, a hierarchical RL algorithm, and robustness analysis when the design is applied to non-homogeneous MAS are presented. Simulations show that the proposed approach can guarantee significant speed-up in learning without any loss in the cumulative value of the LQR cost.
Common Spatial Generative Adversarial Networks based EEG Data Augmentation for Cross-Subject Brain-Computer Interface
Feb 08, 2021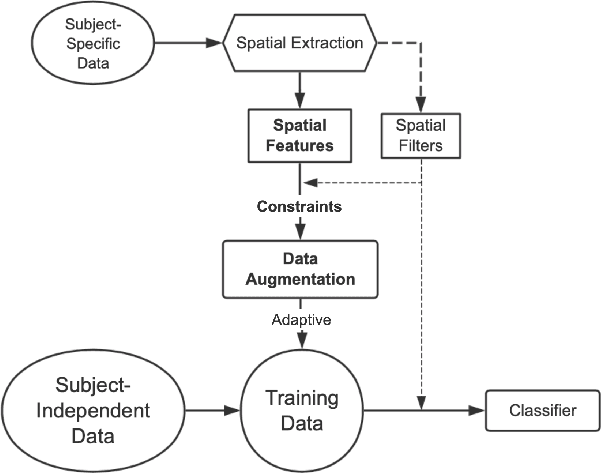
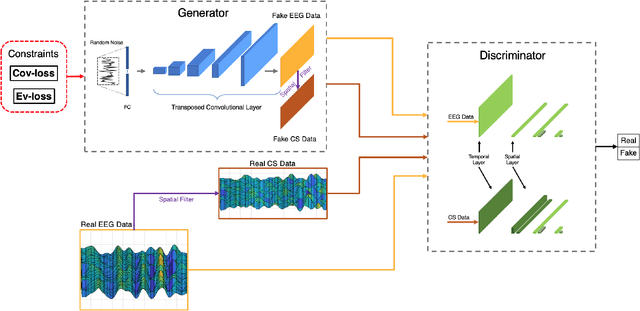
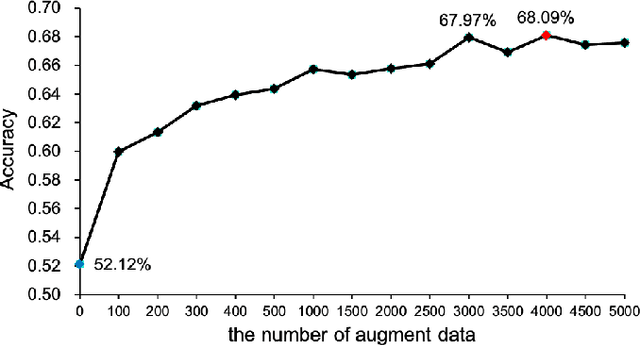
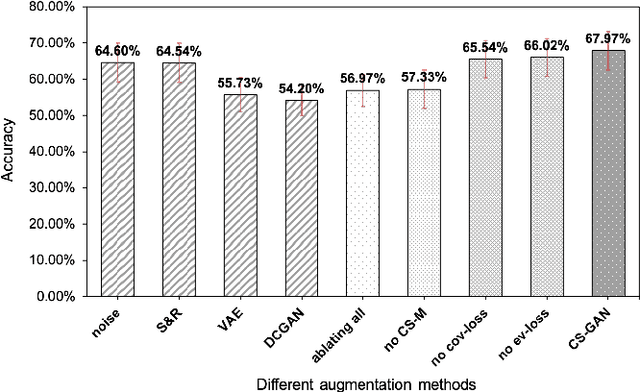
The cross-subject application of EEG-based brain-computer interface (BCI) has always been limited by large individual difference and complex characteristics that are difficult to perceive. Therefore, it takes a long time to collect the training data of each user for calibration. Even transfer learning method pre-training with amounts of subject-independent data cannot decode different EEG signal categories without enough subject-specific data. Hence, we proposed a cross-subject EEG classification framework with a generative adversarial networks (GANs) based method named common spatial GAN (CS-GAN), which used adversarial training between a generator and a discriminator to obtain high-quality data for augmentation. A particular module in the discriminator was employed to maintain the spatial features of the EEG signals and increase the difference between different categories, with two losses for further enhancement. Through adaptive training with sufficient augmentation data, our cross-subject classification accuracy yielded a significant improvement of 15.85% than leave-one subject-out (LOO) test and 8.57% than just adapting 100 original samples on the dataset 2a of BCI competition IV. Moreover, We designed a convolutional neural networks (CNNs) based classification method as a benchmark with a similar spatial enhancement idea, which achieved remarkable results to classify motor imagery EEG data. In summary, our framework provides a promising way to deal with the cross-subject problem and promote the practical application of BCI.
Object sorting using faster R-CNN
Dec 29, 2020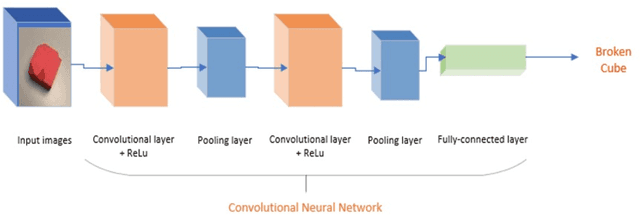
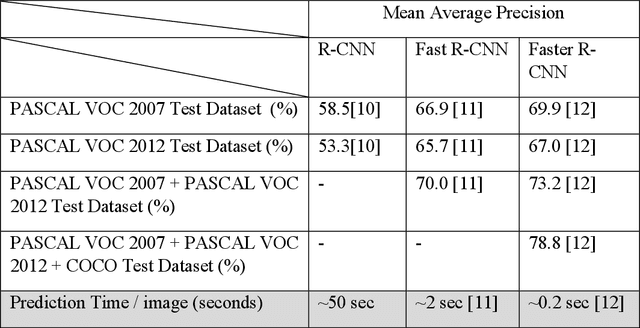
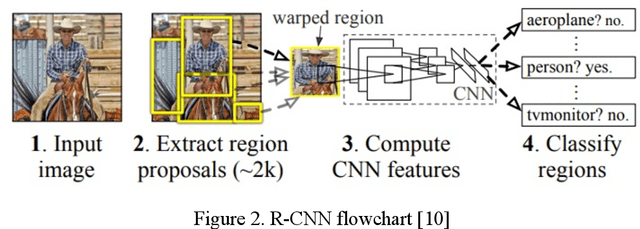
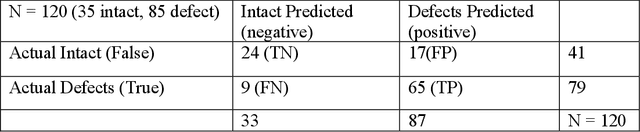
In a factory production line, different industry parts need to be quickly differentiated and sorted for further process. Parts can be of different colors and shapes. It is tedious for humans to differentiate and sort these objects in appropriate categories. Automating this process would save more time and cost. In the automation process, choosing an appropriate model to detect and classify different objects based on specific features is more challenging. In this paper, three different neural network models are compared to the object sorting system. They are namely CNN, Fast R-CNN, and Faster R-CNN. These models are tested, and their performance is analyzed. Moreover, for the object sorting system, an Arduino-controlled 5 DoF (degree of freedom) robot arm is programmed to grab and drop symmetrical objects to the targeted zone. Objects are categorized into classes based on color, defective and non-defective objects.
* 10 pages, 10 figures, 5 tables