 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Social & Engaging Peer Learning: Predicting Backchanneling and Disengagement in Children
Jul 22, 2020
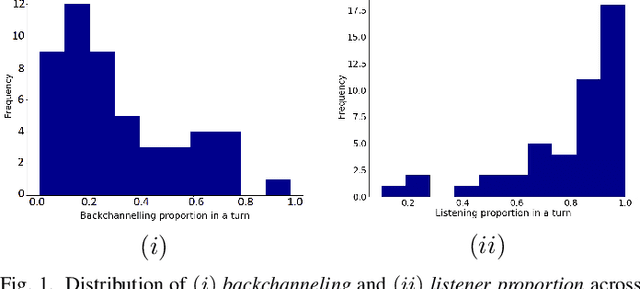
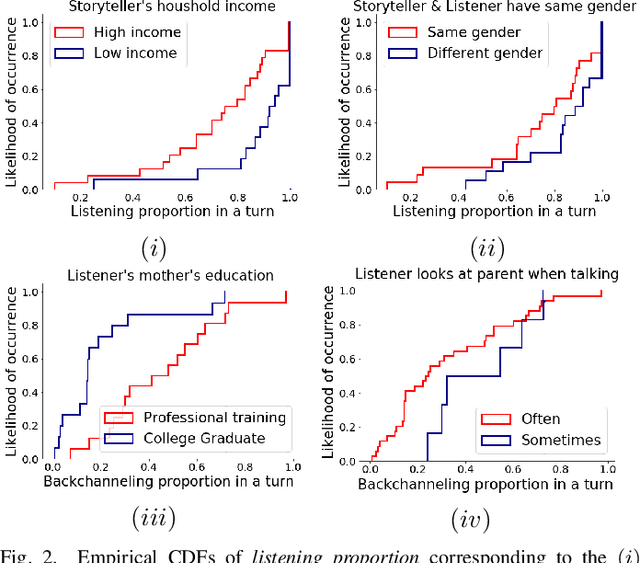

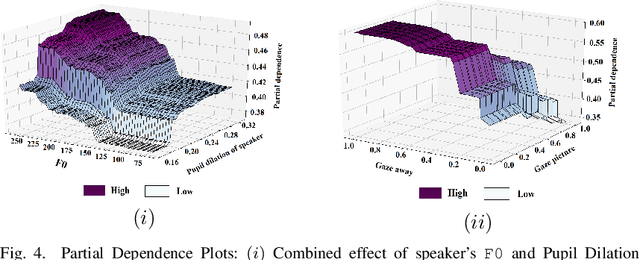
Social robots and interactive computer applications have the potential to foster early language development in young children by acting as peer learning companions. However, studies have found that children only trust robots which behave in a natural and interpersonal manner. To help robots come across as engaging and attentive peer learning companions, we develop models to predict whether the listener will lose attention (Listener Disengagement Prediction, LDP) and the extent to which a robot should generate backchanneling responses (Backchanneling Extent Prediction, BEP) in the next few seconds. We pose LDP and BEP as time series classification problems and conduct several experiments to assess the impact of different time series characteristics and feature sets on the predictive performance of our model. Using statistics & machine learning, we also examine which socio-demographic factors influence the amount of time children spend backchanneling and listening to their peers. To lend interpretability to our models, we also analyzed critical features responsible for their predictive performance. Our experiments revealed the utility of multimodal features such as pupil dilation, blink rate, head movements, facial action units which have never been used before. We also found that the dynamics of time series features are rich predictors of listener disengagement and backchanneling.
FeedRec: News Feed Recommendation with Various User Feedbacks
Feb 09, 2021
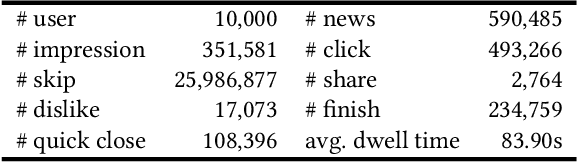
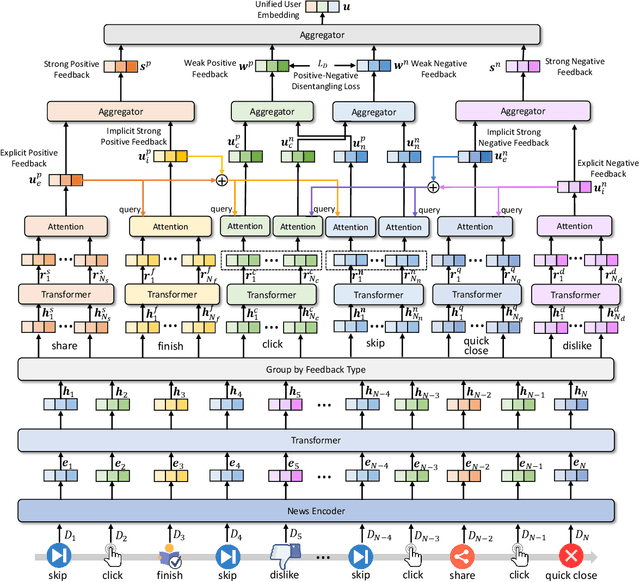
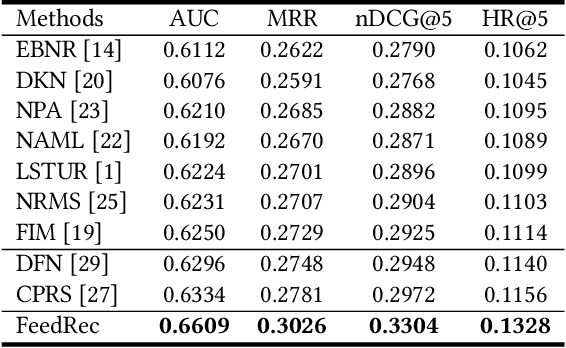
Personalized news recommendation techniques are widely adopted by many online news feed platforms to target user interests. Learning accurate user interest models is important for news recommendation. Most existing methods for news recommendation rely on implicit feedbacks like click behaviors for inferring user interests and model training. However, click behaviors are implicit feedbacks and usually contain heavy noise. In addition, they cannot help infer complicated user interest such as dislike. Besides, the feed recommendation models trained solely on click behaviors cannot optimize other objectives such as user engagement. In this paper, we present a news feed recommendation method that can exploit various kinds of user feedbacks to enhance both user interest modeling and recommendation model training. In our method we propose a unified user modeling framework to incorporate various explicit and implicit user feedbacks to infer both positive and negative user interests. In addition, we propose a strong-to-weak attention network that uses the representations of stronger feedbacks to distill positive and negative user interests from implicit weak feedbacks for accurate user interest modeling. Besides, we propose a multi-feedback model training framework by jointly training the model in the click, finish and dwell time prediction tasks to learn an engagement-aware feed recommendation model. Extensive experiments on real-world dataset show that our approach can effectively improve the model performance in terms of both news clicks and user engagement.
Resource allocation in dynamic multiagent systems
Feb 16, 2021

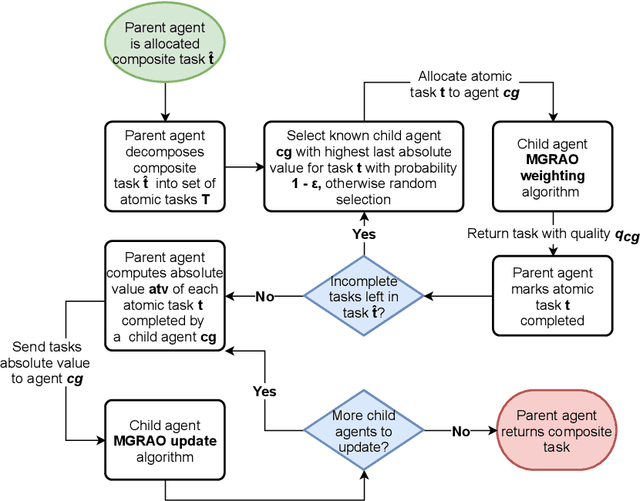

Resource allocation and task prioritisation are key problem domains in the fields of autonomous vehicles, networking, and cloud computing. The challenge in developing efficient and robust algorithms comes from the dynamic nature of these systems, with many components communicating and interacting in complex ways. The multi-group resource allocation optimisation (MG-RAO) algorithm we present uses multiple function approximations of resource demand over time, alongside reinforcement learning techniques, to develop a novel method of optimising resource allocation in these multi-agent systems. This method is applicable where there are competing demands for shared resources, or in task prioritisation problems. Evaluation is carried out in a simulated environment containing multiple competing agents. We compare the new algorithm to an approach where child agents distribute their resources uniformly across all the tasks they can be allocated. We also contrast the performance of the algorithm where resource allocation is modelled separately for groups of agents, as to being modelled jointly over all agents. The MG-RAO algorithm shows a 23 - 28% improvement over fixed resource allocation in the simulated environments. Results also show that, in a volatile system, using the MG-RAO algorithm configured so that child agents model resource allocation for all agents as a whole has 46.5% of the performance of when it is set to model multiple groups of agents. These results demonstrate the ability of the algorithm to solve resource allocation problems in multi-agent systems and to perform well in dynamic environments.
SCA-Net: A Self-Correcting Two-Layer Autoencoder for Hyper-spectral Unmixing
Feb 16, 2021
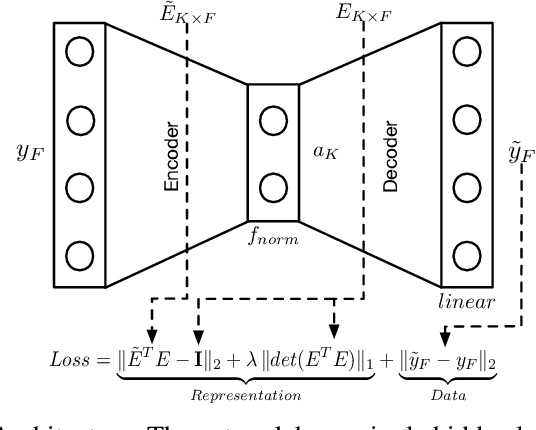
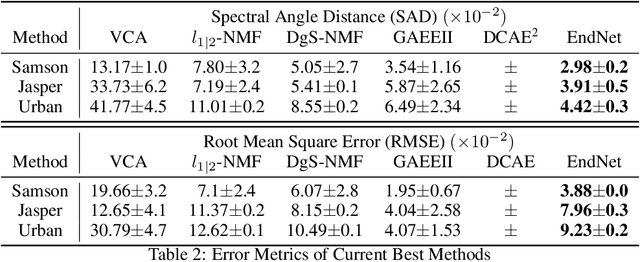
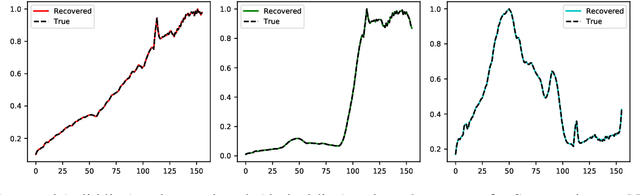
Linear Mixture Model for hyperspectral datasets involves separating a mixed pixel as a linear combination of its constituent endmembers and corresponding fractional abundances. Both optimization and neural methods have attempted to tackle this problem, with the current state of the art results achieved by neural models on benchmark datasets. However, our review of these neural models show that these networks are severely over-parameterized and consequently the invariant endmember spectra extracted as decoder weights has a high variance over multiple runs. All of these approaches require substantial post-processing to satisfy LMM constraints. Furthermore, they also require an exact specification of the number of endmembers and specialized initialization of weights from other algorithms like VCA. Our work shows for the first time that a two-layer autoencoder (SCA-Net), with $2FK$ parameters ($F$ features, $K$ endmembers), achieves error metrics that are scales apart ($10^{-5})$ from previously reported values $(10^{-2})$. SCA-Net converges to this low error solution starting from a random initialization of weights. We also show that SCA-Net, based upon a bi-orthogonal representation, performs a self-correction when the the number of endmembers are over-specified. We show that our network formulation extracts a low-rank representation that is bounded below by a tail-energy and can be computationally verified. Our numerical experiments on Samson, Jasper, and Urban datasets demonstrate that SCA-Net outperforms previously reported error metrics for all the cases while being robust to noise and outliers.
Structured low-rank matrix completion for forecasting in time series analysis
Feb 22, 2018
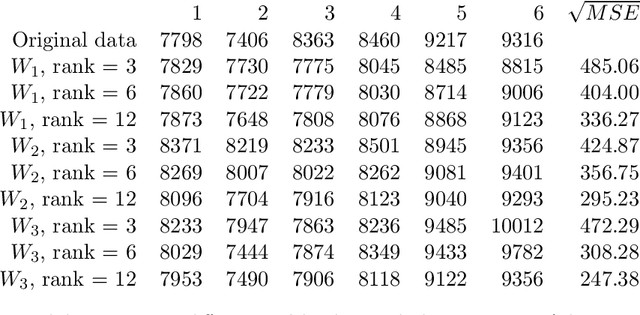
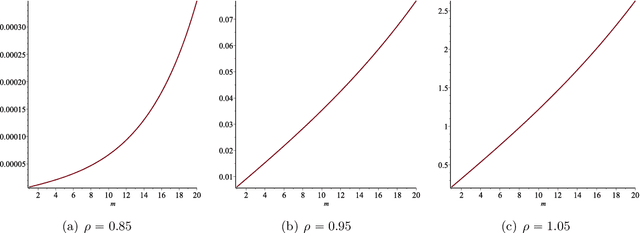
In this paper we consider the low-rank matrix completion problem with specific application to forecasting in time series analysis. Briefly, the low-rank matrix completion problem is the problem of imputing missing values of a matrix under a rank constraint. We consider a matrix completion problem for Hankel matrices and a convex relaxation based on the nuclear norm. Based on new theoretical results and a number of numerical and real examples, we investigate the cases when the proposed approach can work. Our results highlight the importance of choosing a proper weighting scheme for the known observations.
Understanding the Ability of Deep Neural Networks to Count Connected Components in Images
Jan 05, 2021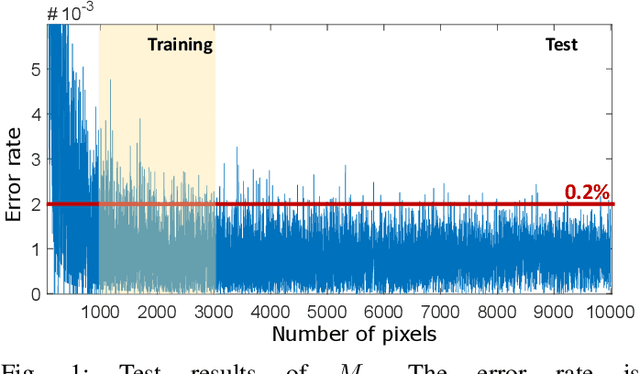
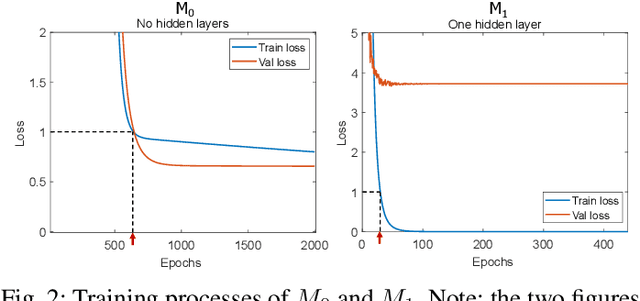
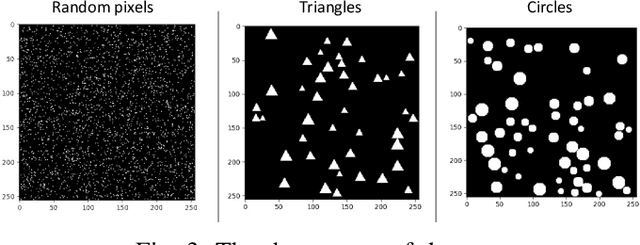
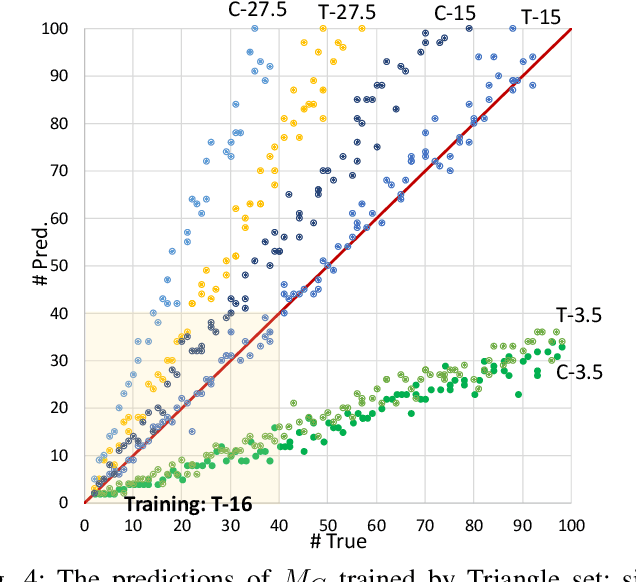
Humans can count very fast by subitizing, but slow substantially as the number of objects increases. Previous studies have shown a trained deep neural network (DNN) detector can count the number of objects in an amount of time that increases slowly with the number of objects. Such a phenomenon suggests the subitizing ability of DNNs, and unlike humans, it works equally well for large numbers. Many existing studies have successfully applied DNNs to object counting, but few studies have studied the subitizing ability of DNNs and its interpretation. In this paper, we found DNNs do not have the ability to generally count connected components. We provided experiments to support our conclusions and explanations to understand the results and phenomena of these experiments. We proposed three ML-learnable characteristics to verify learnable problems for ML models, such as DNNs, and explain why DNNs work for specific counting problems but cannot generally count connected components.
An Empirical Study on Model-agnostic Debiasing Strategies for Robust Natural Language Inference
Oct 08, 2020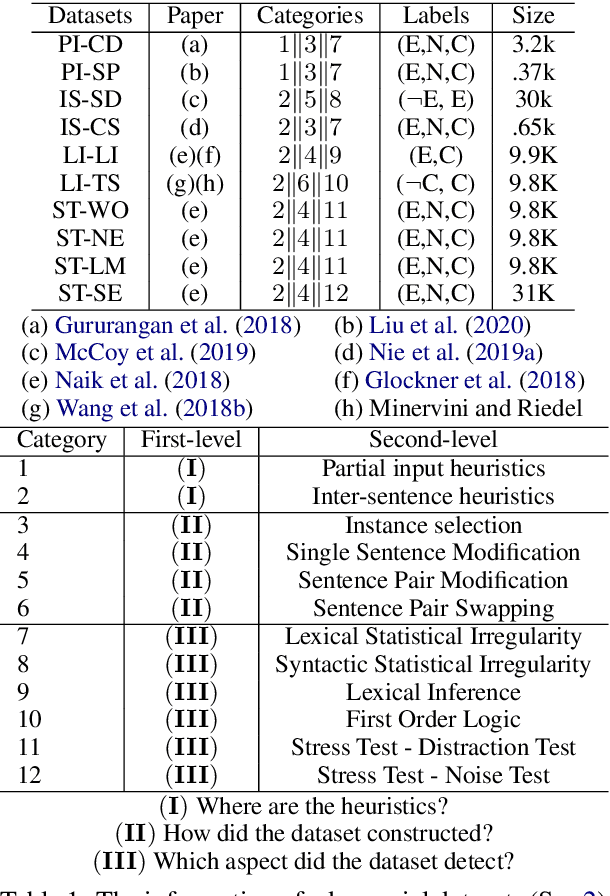
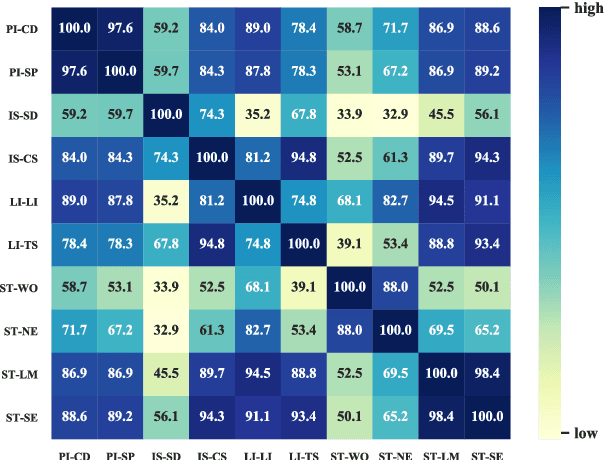
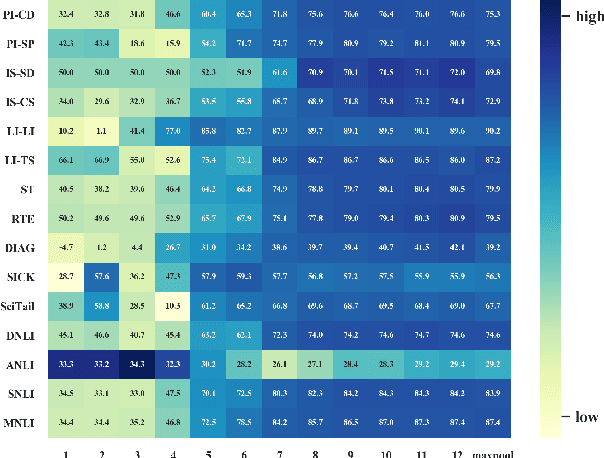
The prior work on natural language inference (NLI) debiasing mainly targets at one or few known biases while not necessarily making the models more robust. In this paper, we focus on the model-agnostic debiasing strategies and explore how to (or is it possible to) make the NLI models robust to multiple distinct adversarial attacks while keeping or even strengthening the models' generalization power. We firstly benchmark prevailing neural NLI models including pretrained ones on various adversarial datasets. We then try to combat distinct known biases by modifying a mixture of experts (MoE) ensemble method and show that it's nontrivial to mitigate multiple NLI biases at the same time, and that model-level ensemble method outperforms MoE ensemble method. We also perform data augmentation including text swap, word substitution and paraphrase and prove its efficiency in combating various (though not all) adversarial attacks at the same time. Finally, we investigate several methods to merge heterogeneous training data (1.35M) and perform model ensembling, which are straightforward but effective to strengthen NLI models.
CLOI: An Automated Benchmark Framework For Generating Geometric Digital Twins Of Industrial Facilities
Jan 05, 2021
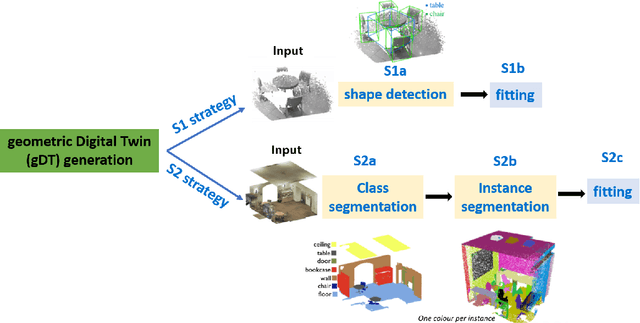
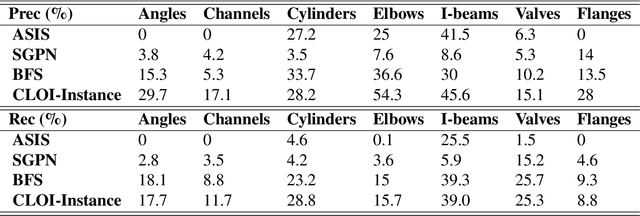
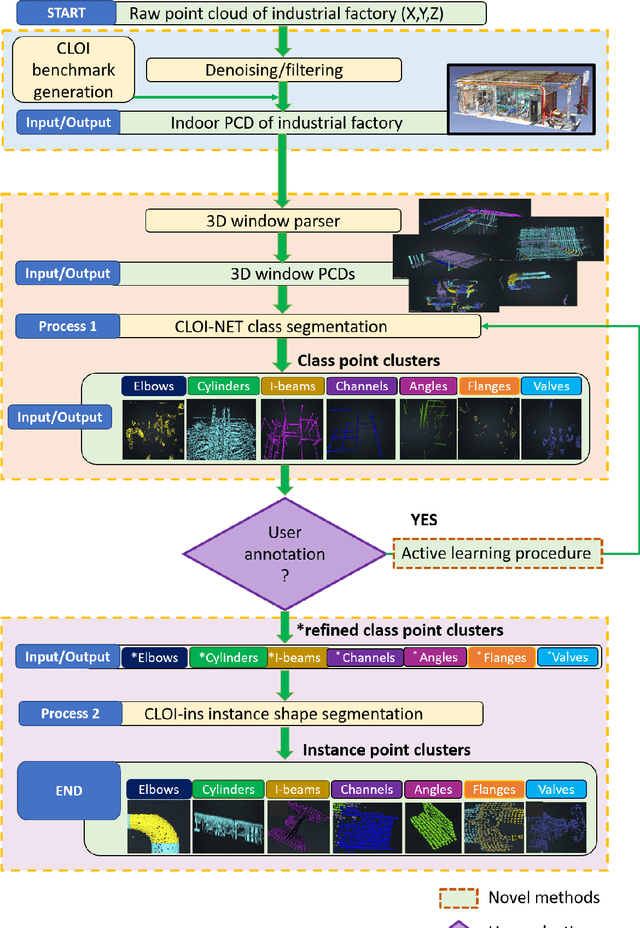
This paper devises, implements and benchmarks a novel framework, named CLOI, that can accurately generate individual labelled point clusters of the most important shapes of existing industrial facilities with minimal manual effort in a generic point-level format. CLOI employs a combination of deep learning and geometric methods to segment the points into classes and individual instances. The current geometric digital twin generation from point cloud data in commercial software is a tedious, manual process. Experiments with our CLOI framework reveal that the method can reliably segment complex and incomplete point clouds of industrial facilities, yielding 82% class segmentation accuracy. Compared to the current state-of-practice, the proposed framework can realize estimated time-savings of 30% on average. CLOI is the first framework of its kind to have achieved geometric digital twinning for the most important objects of industrial factories. It provides the foundation for further research on the generation of semantically enriched digital twins of the built environment.
Improving Deep-learning-based Semi-supervised Audio Tagging with Mixup
Feb 16, 2021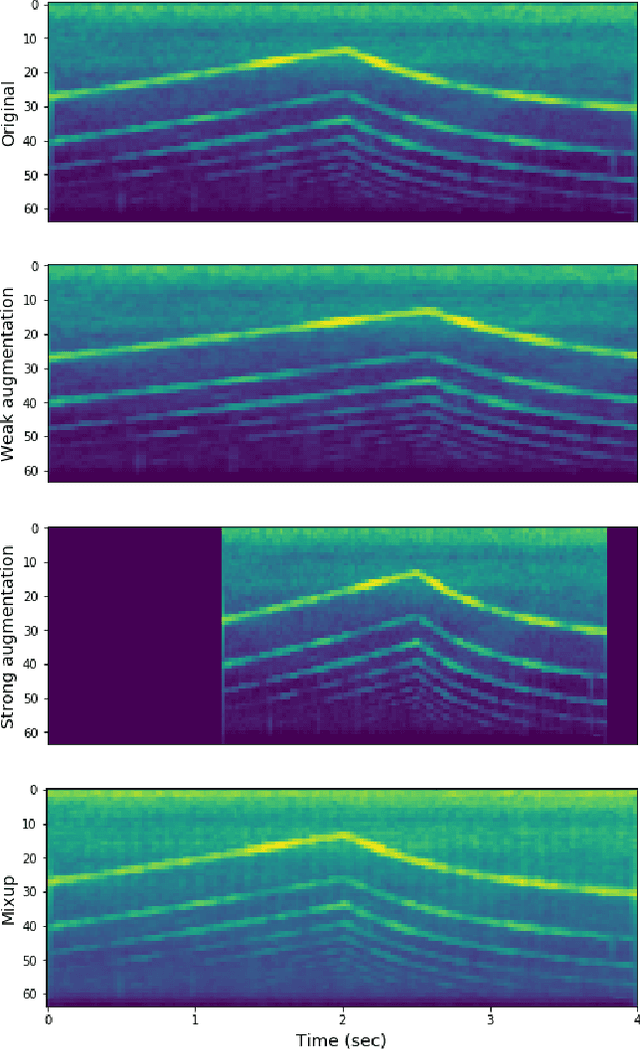
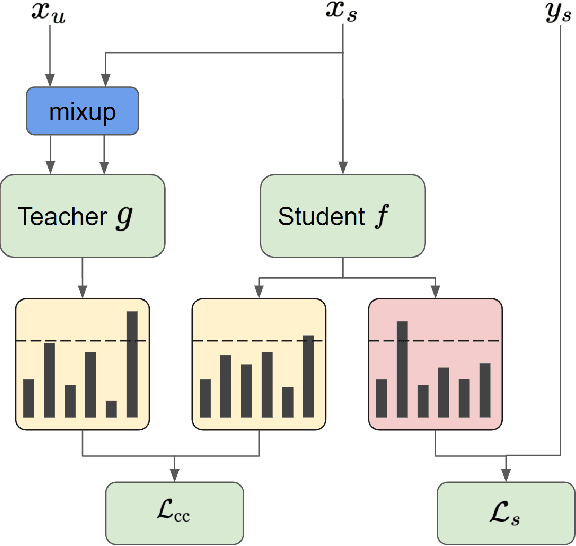
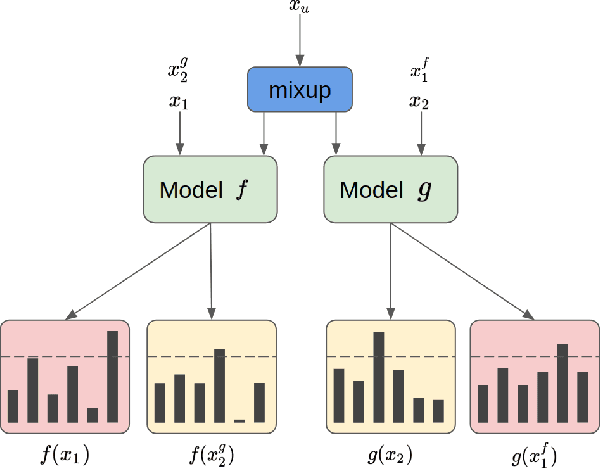
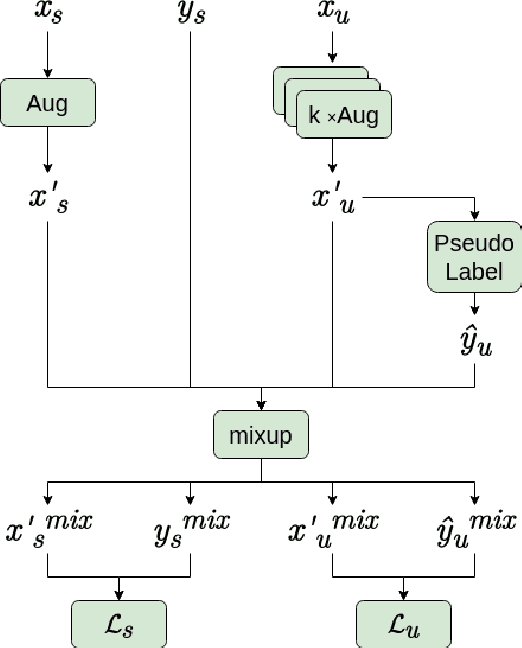
Recently, semi-supervised learning (SSL) methods, in the framework of deep learning (DL), have been shown to provide state-of-the-art results on image datasets by exploiting unlabeled data. Most of the time tested on object recognition tasks in images, these algorithms are rarely compared when applied to audio tasks. In this article, we adapted four recent SSL methods to the task of audio tagging. The first two methods, namely Deep Co-Training (DCT) and Mean Teacher (MT) involve two collaborative neural networks. The two other algorithms, called MixMatch (MM) and FixMatch (FM), are single-model methods that rely primarily on data augmentation strategies. Using the Wide ResNet 28-2 architecture in all our experiments, 10% of labeled data and the remaining 90\% as unlabeled, we first compare the four methods' accuracy on three standard benchmark audio event datasets: Environmental Sound Classification (ESC-10), UrbanSound8K (UBS8K), and Google Speech Commands (GSC). MM and FM outperformed MT and DCT significantly, MM being the best method in most experiments. On UBS8K and GSC, in particular, MM achieved 18.02% and 3.25% error rates (ER), outperforming models trained with 100% of the available labeled data, which reached 23.29% and 4.94% ER, respectively. Second, we explored the benefits of using the mixup augmentation in the four algorithms. In almost all cases, mixup brought significant gains. For instance, on GSC, FM reached 4.44% and 3.31% ER without and with mixup.
Irregular-Time Bayesian Networks
Mar 15, 2012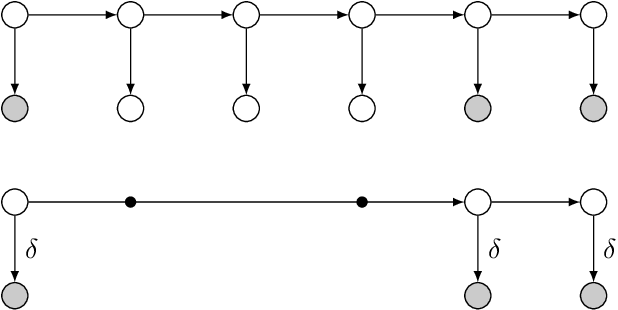
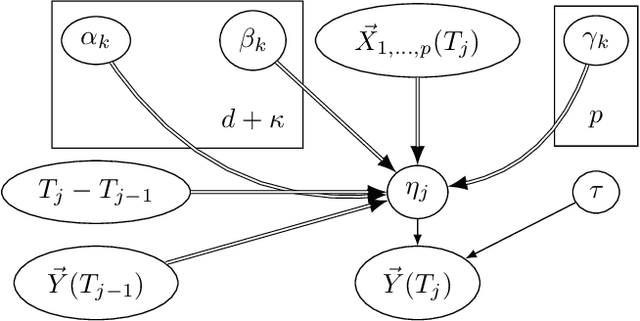
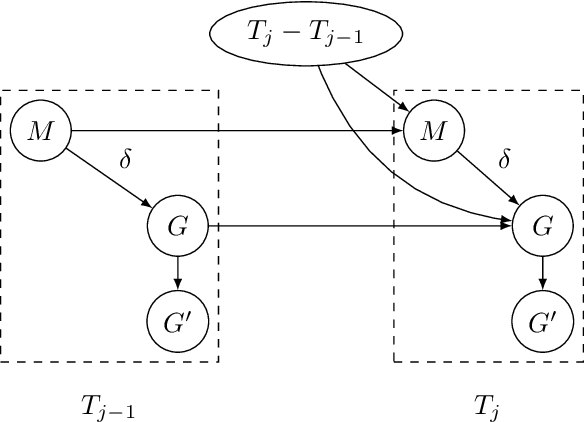
In many fields observations are performed irregularly along time, due to either measurement limitations or lack of a constant immanent rate. While discrete-time Markov models (as Dynamic Bayesian Networks) introduce either inefficient computation or an information loss to reasoning about such processes, continuous-time Markov models assume either a discrete state space (as Continuous-Time Bayesian Networks), or a flat continuous state space (as stochastic differential equations). To address these problems, we present a new modeling class called Irregular-Time Bayesian Networks (ITBNs), generalizing Dynamic Bayesian Networks, allowing substantially more compact representations, and increasing the expressivity of the temporal dynamics. In addition, a globally optimal solution is guaranteed when learning temporal systems, provided that they are fully observed at the same irregularly spaced time-points, and a semiparametric subclass of ITBNs is introduced to allow further adaptation to the irregular nature of the available data.