 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Novel Collision Detection and Avoidance system for Midvehicle using Offset-based Curvilinear Motion
Feb 01, 2021
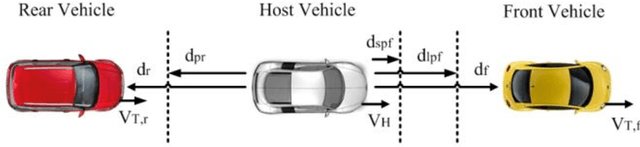
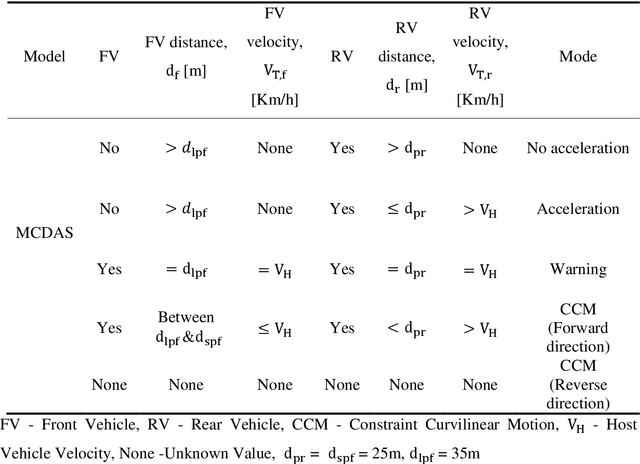
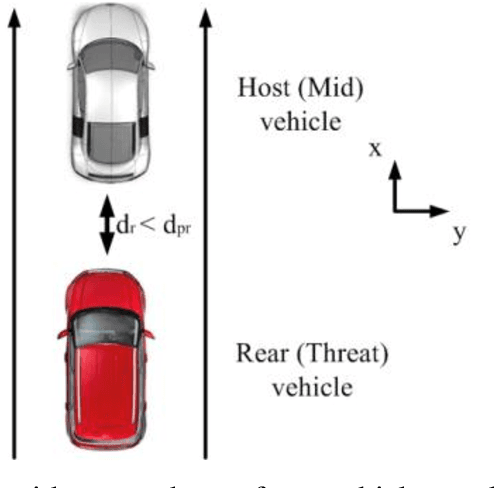
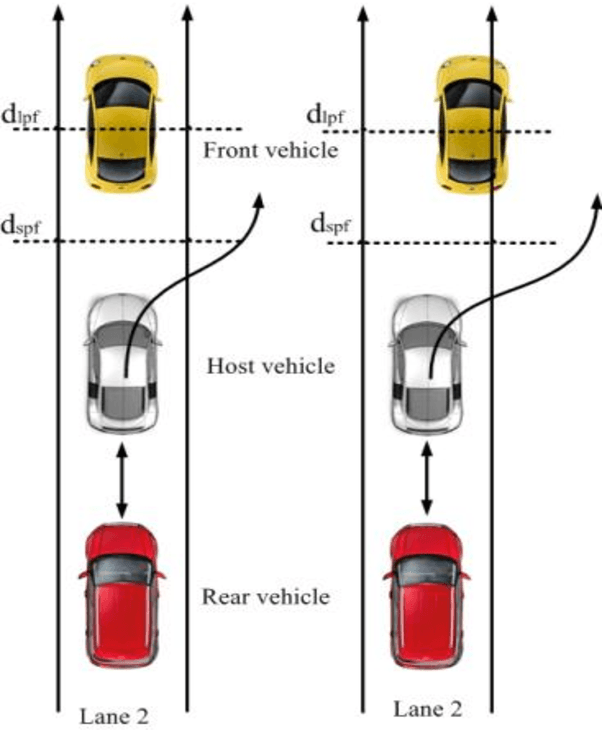
Major cause of midvehicle collision is due to the distraction of drivers in both the Front and rear-end vehicle witnessed in dense traffic and high speed road conditions. In view of this scenario, a crash detection and collision avoidance algorithm coined as Midvehicle Collision Detection and Avoidance System (MCDAS) is proposed to evade the possible crash at both ends of the host vehicle. The method based upon Constant Velocity (CV) model specifically, addresses two scenarios, the first scenario encompasses two sub-scenario namely, a) A rear-end collision avoidance mechanism that accelerates the host vehicle under no front-end vehicle condition and b) Curvilinear motion based on front and host vehicle offset (position), whilst, the other scenario deals with parallel parking issues. The offset based curvilinear motion of the host vehicle plays a vital role in threat avoidance from the front-end vehicle. A desired curvilinear strategy on left and right sides is achieved by the host vehicle with concern of possible CV to avoid both end collisions. In this methodology, path constraint is applicable for both scenarios with required direction. Monte Carlo analysis of MCDAS covering vehicle kinematics demonstrated acute discrimination with consistent performance for the collision validated on simulated with real-time data.
A practical test for a planted community in heterogeneous networks
Jan 15, 2021
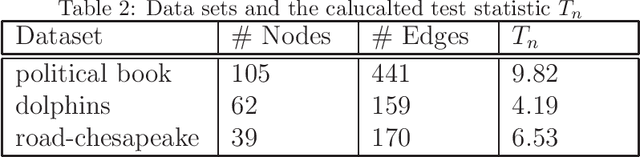
One of the fundamental task in graph data mining is to find a planted community(dense subgraph), which has wide application in biology, finance, spam detection and so on. For a real network data, the existence of a dense subgraph is generally unknown. Statistical tests have been devised to testing the existence of dense subgraph in a homogeneous random graph. However, many networks present extreme heterogeneity, that is, the degrees of nodes or vertexes don't concentrate on a typical value. The existing tests designed for homogeneous random graph are not straightforwardly applicable to the heterogeneous case. Recently, scan test was proposed for detecting a dense subgraph in heterogeneous(inhomogeneous) graph(\cite{BCHV19}). However, the computational complexity of the scan test is generally not polynomial in the graph size, which makes the test impractical for large or moderate networks. In this paper, we propose a polynomial-time test that has the standard normal distribution as the null limiting distribution. The power of the test is theoretically investigated and we evaluate the performance of the test by simulation and real data example.
Benchmarking Energy-Conserving Neural Networks for Learning Dynamics from Data
Dec 30, 2020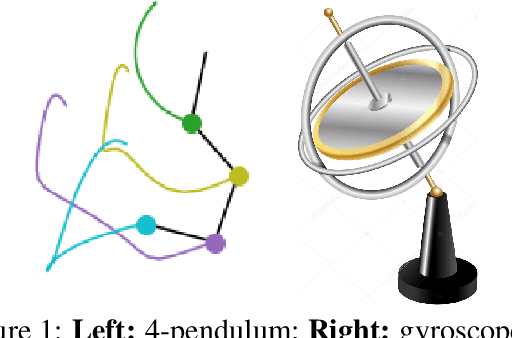
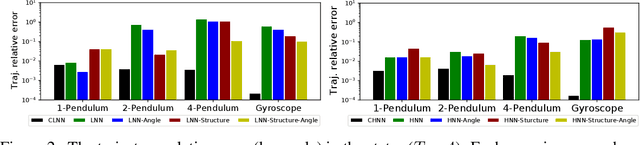
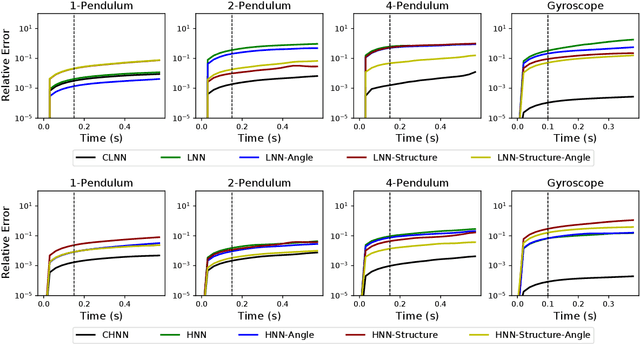
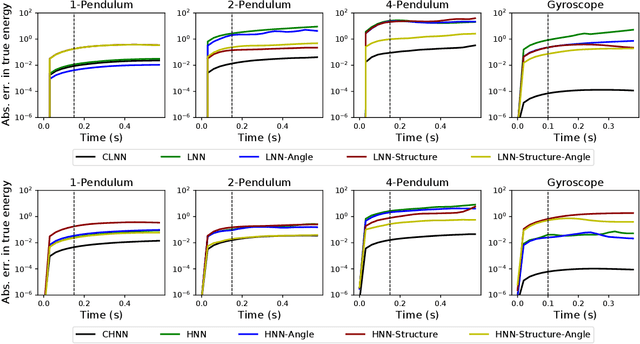
The last few years have witnessed an increased interest in incorporating physics-informed inductive bias in deep learning frameworks. In particular, a growing volume of literature has been exploring ways to enforce energy conservation while using neural networks for learning dynamics from observed time-series data. In this work, we present a comparative analysis of the energy-conserving neural networks - for example, deep Lagrangian network, Hamiltonian neural network, etc. - wherein the underlying physics is encoded in their computation graph. We focus on ten neural network models and explain the similarities and differences between the models. We compare their performance in 4 different physical systems. Our result highlights that using a high-dimensional coordinate system and then imposing restrictions via explicit constraints can lead to higher accuracy in the learned dynamics. We also point out the possibility of leveraging some of these energy-conserving models to design energy-based controllers.
Towards Metric Temporal Answer Set Programming
Aug 08, 2020

We elaborate upon the theoretical foundations of a metric temporal extension of Answer Set Programming. In analogy to previous extensions of ASP with constructs from Linear Temporal and Dynamic Logic, we accomplish this in the setting of the logic of Here-and-There and its non-monotonic extension, called Equilibrium Logic. More precisely, we develop our logic on the same semantic underpinnings as its predecessors and thus use a simple time domain of bounded time steps. This allows us to compare all variants in a uniform framework and ultimately combine them in a common implementation.
Medico Multimedia Task at MediaEval 2020: Automatic Polyp Segmentation
Dec 30, 2020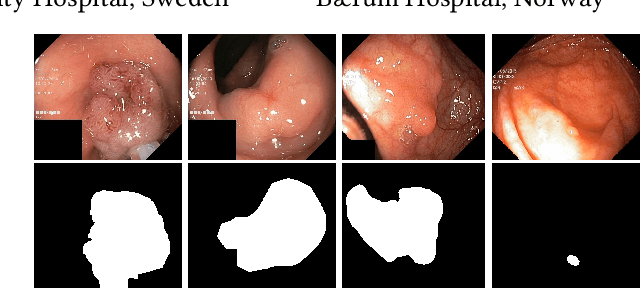

Colorectal cancer is the third most common cause of cancer worldwide. According to Global cancer statistics 2018, the incidence of colorectal cancer is increasing in both developing and developed countries. Early detection of colon anomalies such as polyps is important for cancer prevention, and automatic polyp segmentation can play a crucial role for this. Regardless of the recent advancement in early detection and treatment options, the estimated polyp miss rate is still around 20\%. Support via an automated computer-aided diagnosis system could be one of the potential solutions for the overlooked polyps. Such detection systems can help low-cost design solutions and save doctors time, which they could for example use to perform more patient examinations. In this paper, we introduce the 2020 Medico challenge, provide some information on related work and the dataset, describe the task and evaluation metrics, and discuss the necessity of organizing the Medico challenge.
Real-Time Machine Learning: The Missing Pieces
May 19, 2017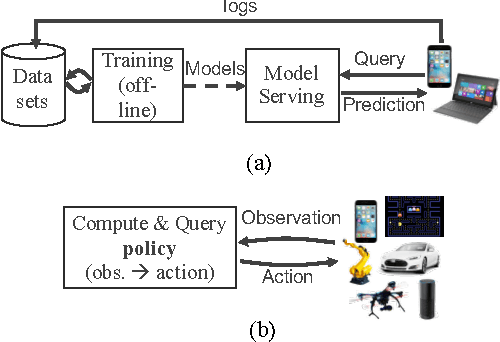
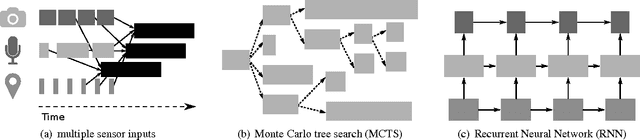
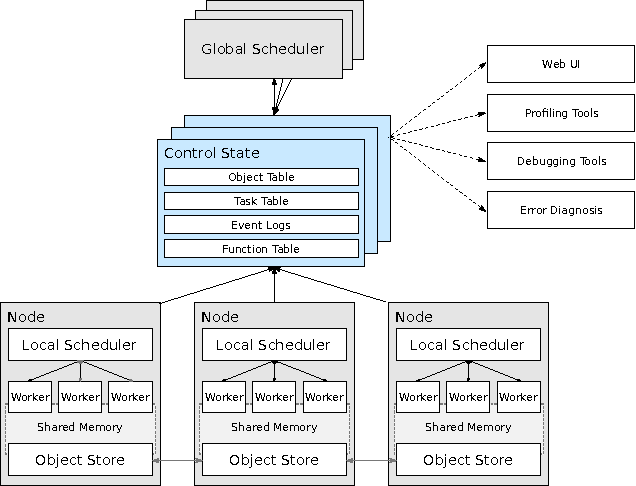
Machine learning applications are increasingly deployed not only to serve predictions using static models, but also as tightly-integrated components of feedback loops involving dynamic, real-time decision making. These applications pose a new set of requirements, none of which are difficult to achieve in isolation, but the combination of which creates a challenge for existing distributed execution frameworks: computation with millisecond latency at high throughput, adaptive construction of arbitrary task graphs, and execution of heterogeneous kernels over diverse sets of resources. We assert that a new distributed execution framework is needed for such ML applications and propose a candidate approach with a proof-of-concept architecture that achieves a 63x performance improvement over a state-of-the-art execution framework for a representative application.
Are Adaptive Face Recognition Systems still Necessary? Experiments on the APE Dataset
Oct 08, 2020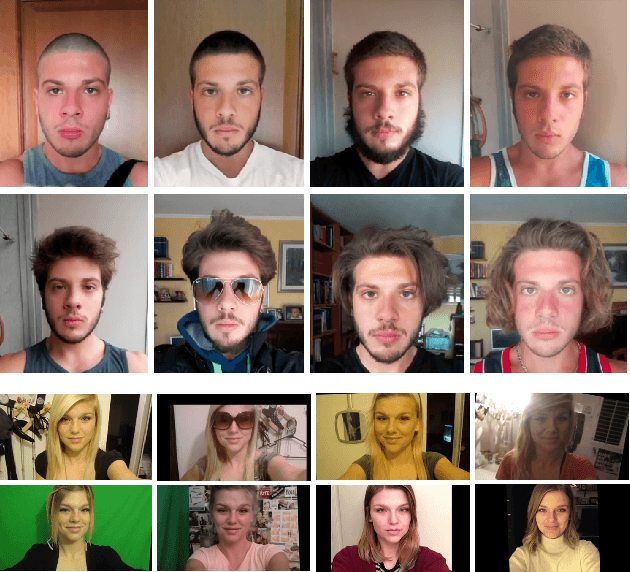

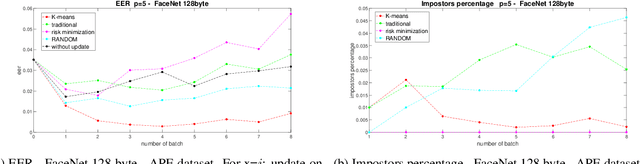
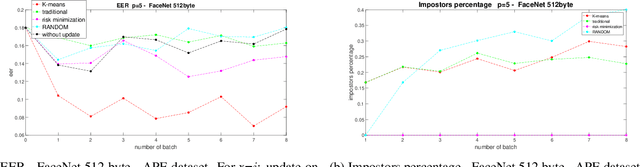
In the last five years, deep learning methods, in particular CNN, have attracted considerable attention in the field of face-based recognition, achieving impressive results. Despite this progress, it is not yet clear precisely to what extent deep features are able to follow all the intra-class variations that the face can present over time. In this paper we investigate the performance the performance improvement of face recognition systems by adopting self updating strategies of the face templates. For that purpose, we evaluate the performance of a well-known deep-learning face representation, namely, FaceNet, on a dataset that we generated explicitly conceived to embed intra-class variations of users on a large time span of captures: the APhotoEveryday (APE) dataset. Moreover, we compare these deep features with handcrafted features extracted using the BSIF algorithm. In both cases, we evaluate various template update strategies, in order to detect the most useful for such kind of features. Experimental results show the effectiveness of "optimized" self-update methods with respect to systems without update or random selection of templates.
Approximate Multiplication of Sparse Matrices with Limited Space
Sep 08, 2020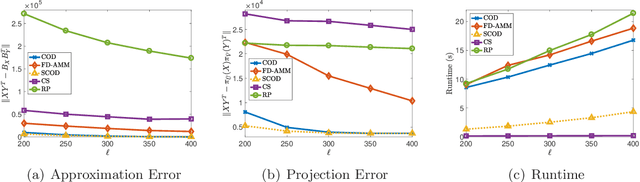
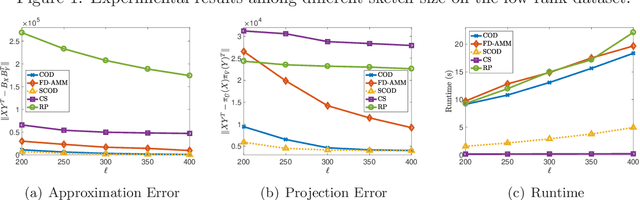
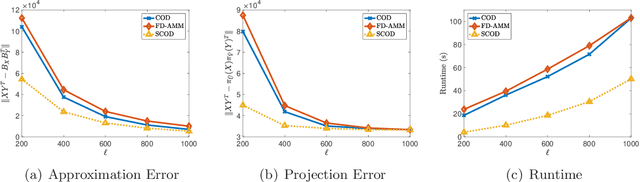
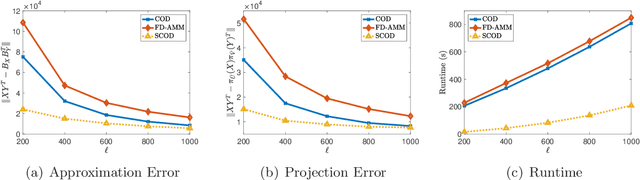
Approximate matrix multiplication with limited space has received ever-increasing attention due to the emergence of large-scale applications. Recently, based on a popular matrix sketching algorithm---frequent directions, previous work has introduced co-occuring directions (COD) to reduce the approximation error for this problem. Although it enjoys the space complexity of $O((m_x+m_y)\ell)$ for two input matrices $X\in\mathbb{R}^{m_x\times n}$ and $Y\in\mathbb{R}^{m_y\times n}$ where $\ell$ is the sketch size, its time complexity is $O\left(n(m_x+m_y+\ell)\ell\right)$, which is still very high for large input matrices. In this paper, we propose to reduce the time complexity by exploiting the sparsity of the input matrices. The key idea is to employ an approximate singular value decomposition (SVD) method which can utilize the sparsity, to reduce the number of QR decompositions required by COD. In this way, we develop sparse co-occuring directions, which reduces the time complexity to $\widetilde{O}\left((\nnz(X)+\nnz(Y))\ell+n\ell^2\right)$ in expectation while keeps the same space complexity as $O((m_x+m_y)\ell)$, where $\nnz(X)$ denotes the number of non-zero entries in $X$. Theoretical analysis reveals that the approximation error of our algorithm is almost the same as that of COD. Furthermore, we empirically verify the efficiency and effectiveness of our algorithm.
Extension of Full and Reduced Order Observers for Image-based Depth Estimation using Concurrent Learning
Aug 12, 2020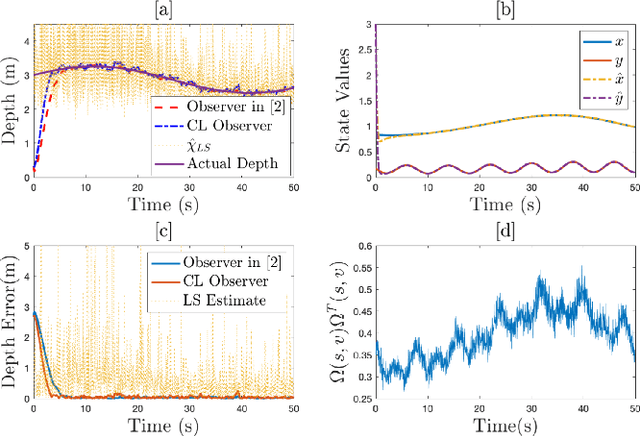
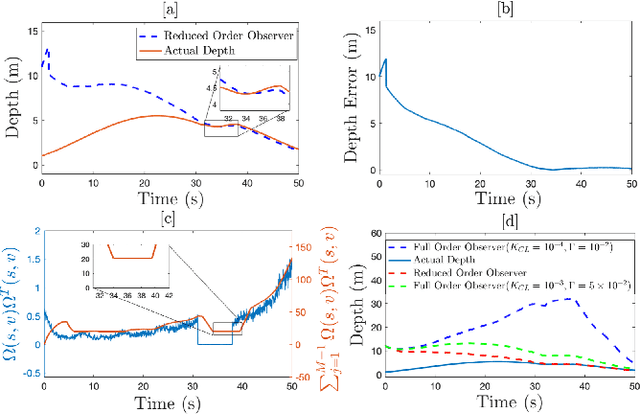
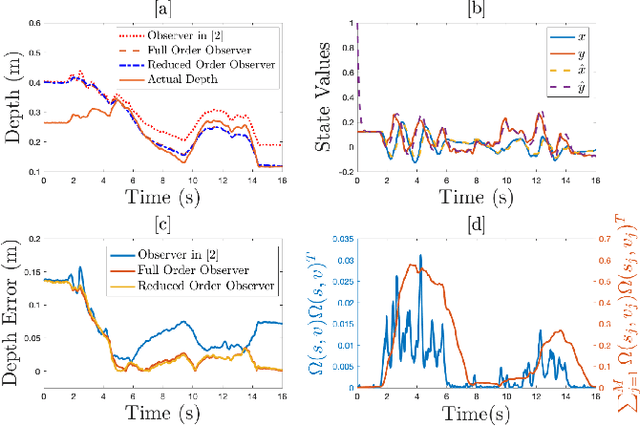
In this paper concurrent learning (CL)-based full and reduced order observers for a perspective dynamical system (PDS) are developed. The PDS is a widely used model for estimating the depth of a feature point from a sequence of camera images. Building on the current progress of CL for parameter estimation in adaptive control, a state observer is developed for the PDS model where the inverse depth appears as a time-varying parameter in the dynamics. The data recorded over a sliding time window in the near past is used in the CL term to design the full and the reduced order state observers. A Lyapunov-based stability analysis is carried out to prove the uniformly ultimately bounded (UUB) stability of the developed observers. Simulation results are presented to validate the accuracy and convergence of the developed observers in terms of convergence time, root mean square error (RMSE) and mean absolute percentage error (MAPE) metrics. Real world depth estimation experiments are performed to demonstrate the performance of the observers using aforementioned metrics on a 7-DoF manipulator with an eye-in-hand configuration.
Real-Time Hand Shape Classification
Feb 11, 2014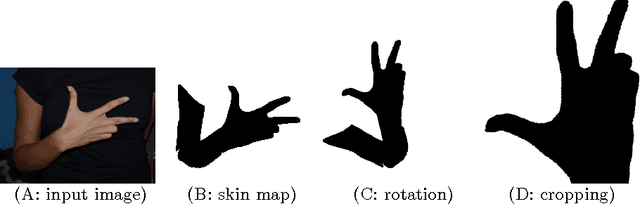
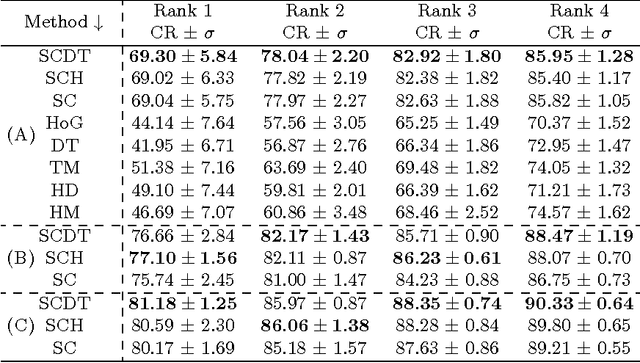

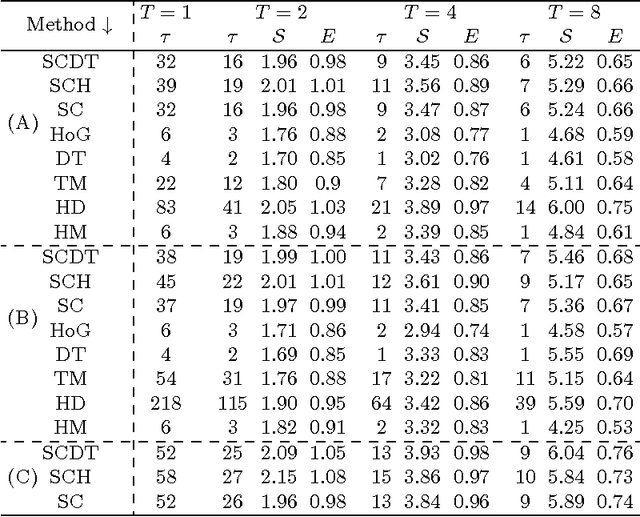
The problem of hand shape classification is challenging since a hand is characterized by a large number of degrees of freedom. Numerous shape descriptors have been proposed and applied over the years to estimate and classify hand poses in reasonable time. In this paper we discuss our parallel framework for real-time hand shape classification applicable in real-time applications. We show how the number of gallery images influences the classification accuracy and execution time of the parallel algorithm. We present the speedup and efficiency analyses that prove the efficacy of the parallel implementation. Noteworthy, different methods can be used at each step of our parallel framework. Here, we combine the shape contexts with the appearance-based techniques to enhance the robustness of the algorithm and to increase the classification score. An extensive experimental study proves the superiority of the proposed approach over existing state-of-the-art methods.