 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Image Retrieval: A Survey
Feb 03, 2021
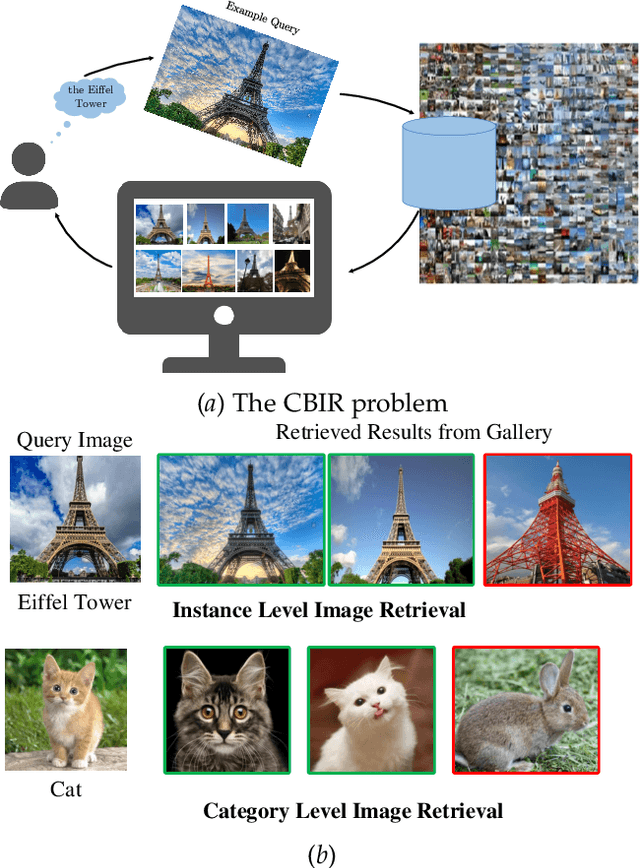
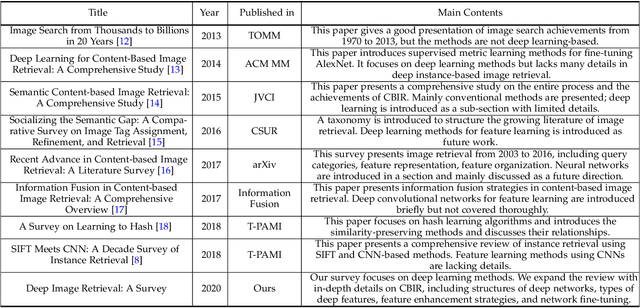
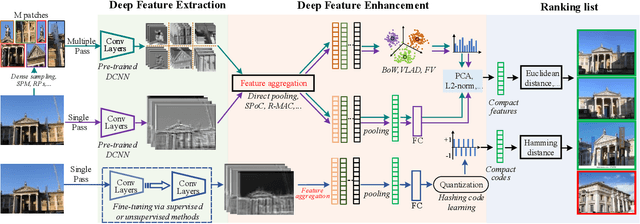
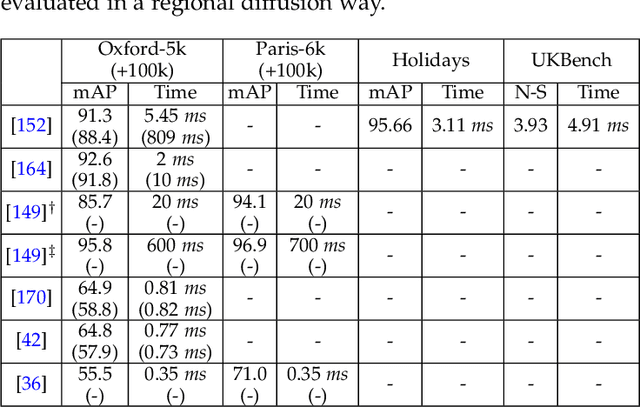
In recent years a vast amount of visual content has been generated and shared from various fields, such as social media platforms, medical images, and robotics. This abundance of content creation and sharing has introduced new challenges. In particular, searching databases for similar content, i.e.content based image retrieval (CBIR), is a long-established research area, and more efficient and accurate methods are needed for real time retrieval. Artificial intelligence has made progress in CBIR and has significantly facilitated the process of intelligent search. In this survey we organize and review recent CBIR works that are developed based on deep learning algorithms and techniques, including insights and techniques from recent papers. We identify and present the commonly-used benchmarks and evaluation methods used in the field. We collect common challenges and propose promising future directions. More specifically, we focus on image retrieval with deep learning and organize the state of the art methods according to the types of deep network structure, deep features, feature enhancement methods, and network fine-tuning strategies. Our survey considers a wide variety of recent methods, aiming to promote a global view of the field of instance-based CBIR.
Neural-Guided Deductive Search for Real-Time Program Synthesis from Examples
Sep 09, 2018


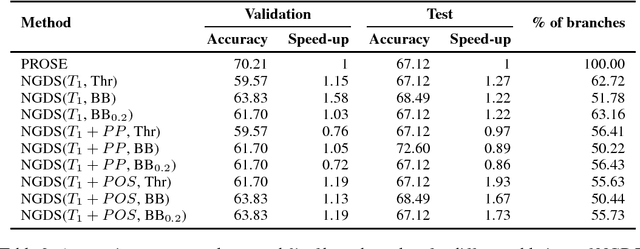
Synthesizing user-intended programs from a small number of input-output examples is a challenging problem with several important applications like spreadsheet manipulation, data wrangling and code refactoring. Existing synthesis systems either completely rely on deductive logic techniques that are extensively hand-engineered or on purely statistical models that need massive amounts of data, and in general fail to provide real-time synthesis on challenging benchmarks. In this work, we propose Neural Guided Deductive Search (NGDS), a hybrid synthesis technique that combines the best of both symbolic logic techniques and statistical models. Thus, it produces programs that satisfy the provided specifications by construction and generalize well on unseen examples, similar to data-driven systems. Our technique effectively utilizes the deductive search framework to reduce the learning problem of the neural component to a simple supervised learning setup. Further, this allows us to both train on sparingly available real-world data and still leverage powerful recurrent neural network encoders. We demonstrate the effectiveness of our method by evaluating on real-world customer scenarios by synthesizing accurate programs with up to 12x speed-up compared to state-of-the-art systems.
Probabilistic combination of eigenlungs-based classifiers for COVID-19 diagnosis in chest CT images
Mar 04, 2021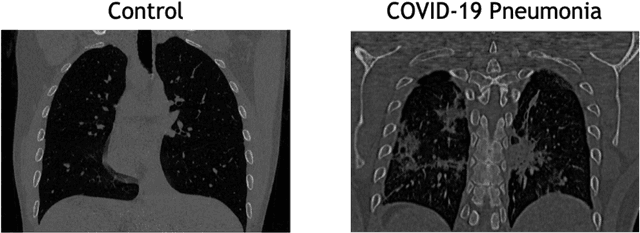
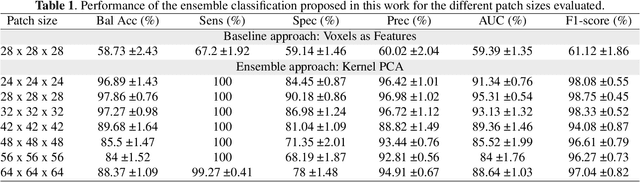
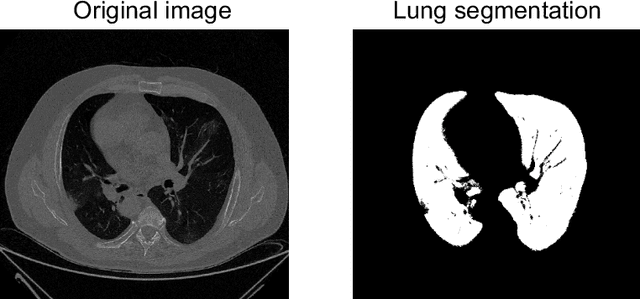

The outbreak of the COVID-19 (Coronavirus disease 2019) pandemic has changed the world. According to the World Health Organization (WHO), there have been more than 100 million confirmed cases of COVID-19, including more than 2.4 million deaths. It is extremely important the early detection of the disease, and the use of medical imaging such as chest X-ray (CXR) and chest Computed Tomography (CCT) have proved to be an excellent solution. However, this process requires clinicians to do it within a manual and time-consuming task, which is not ideal when trying to speed up the diagnosis. In this work, we propose an ensemble classifier based on probabilistic Support Vector Machine (SVM) in order to identify pneumonia patterns while providing information about the reliability of the classification. Specifically, each CCT scan is divided into cubic patches and features contained in each one of them are extracted by applying kernel PCA. The use of base classifiers within an ensemble allows our system to identify the pneumonia patterns regardless of their size or location. Decisions of each individual patch are then combined into a global one according to the reliability of each individual classification: the lower the uncertainty, the higher the contribution. Performance is evaluated in a real scenario, yielding an accuracy of 97.86%. The large performance obtained and the simplicity of the system (use of deep learning in CCT images would result in a huge computational cost) evidence the applicability of our proposal in a real-world environment.
Safe Search for Stackelberg Equilibria in Extensive-Form Games
Feb 02, 2021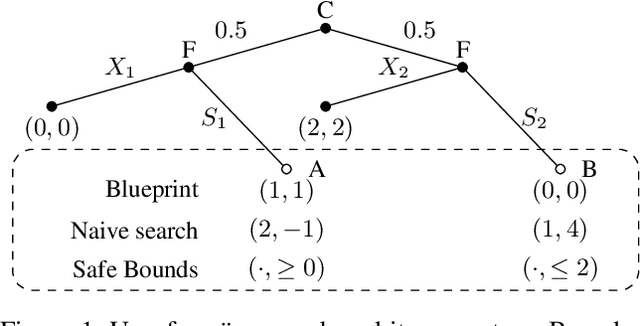
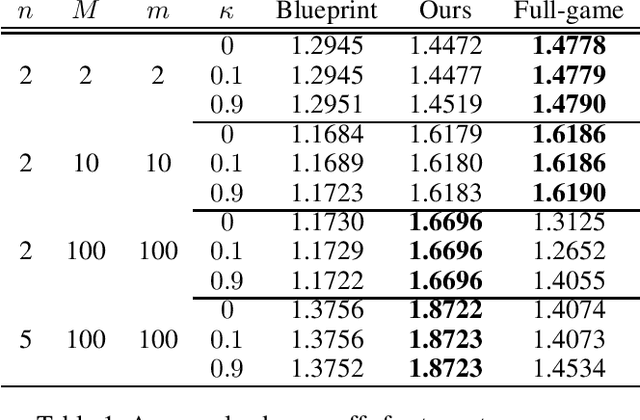
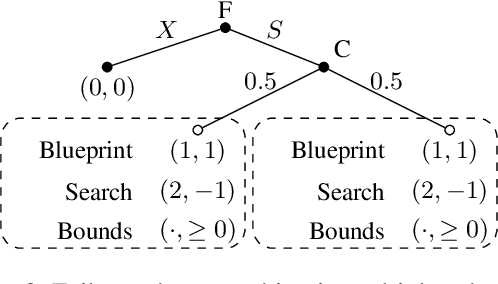

Stackelberg equilibrium is a solution concept in two-player games where the leader has commitment rights over the follower. In recent years, it has become a cornerstone of many security applications, including airport patrolling and wildlife poaching prevention. Even though many of these settings are sequential in nature, existing techniques pre-compute the entire solution ahead of time. In this paper, we present a theoretically sound and empirically effective way to apply search, which leverages extra online computation to improve a solution, to the computation of Stackelberg equilibria in general-sum games. Instead of the leader attempting to solve the full game upfront, an approximate "blueprint" solution is first computed offline and is then improved online for the particular subgames encountered in actual play. We prove that our search technique is guaranteed to perform no worse than the pre-computed blueprint strategy, and empirically demonstrate that it enables approximately solving significantly larger games compared to purely offline methods. We also show that our search operation may be cast as a smaller Stackelberg problem, making our method complementary to existing algorithms based on strategy generation.
Learning-based Real-time Detection of Intrinsic Reflectional Symmetry
Nov 01, 2019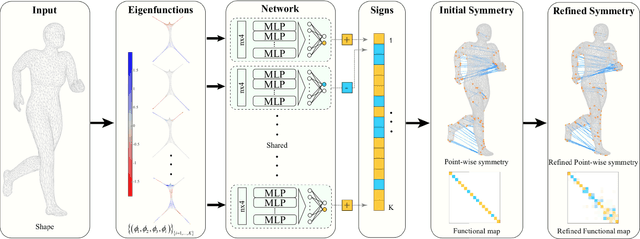


Reflectional symmetry is ubiquitous in nature. While extrinsic reflectional symmetry can be easily parametrized and detected, intrinsic symmetry is much harder due to the high solution space. Previous works usually solve this problem by voting or sampling, which suffer from high computational cost and randomness. In this paper, we propose \YL{a} learning-based approach to intrinsic reflectional symmetry detection. Instead of directly finding symmetric point pairs, we parametrize this self-isometry using a functional map matrix, which can be easily computed given the signs of Laplacian eigenfunctions under the symmetric mapping. Therefore, we train a novel deep neural network to predict the sign of each eigenfunction under symmetry, which in addition takes the first few eigenfunctions as intrinsic features to characterize the mesh while avoiding coping with the connectivity explicitly. Our network aims at learning the global property of functions, and consequently converts the problem defined on the manifold to the functional domain. By disentangling the prediction of the matrix into separated basis, our method generalizes well to new shapes and is invariant under perturbation of eigenfunctions. Through extensive experiments, we demonstrate the robustness of our method in challenging cases, including different topology and incomplete shapes with holes. By avoiding random sampling, our learning-based algorithm is over 100 times faster than state-of-the-art methods, and meanwhile, is more robust, achieving higher correspondence accuracy in commonly used metrics.
Machine learning initialization to accelerate Stokes profile inversions
Mar 16, 2021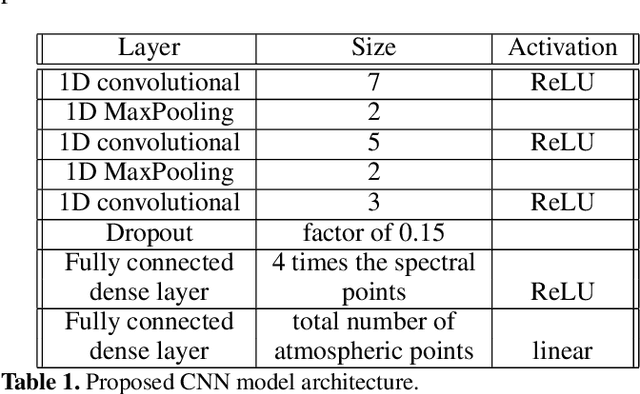

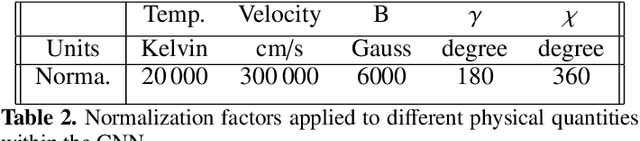
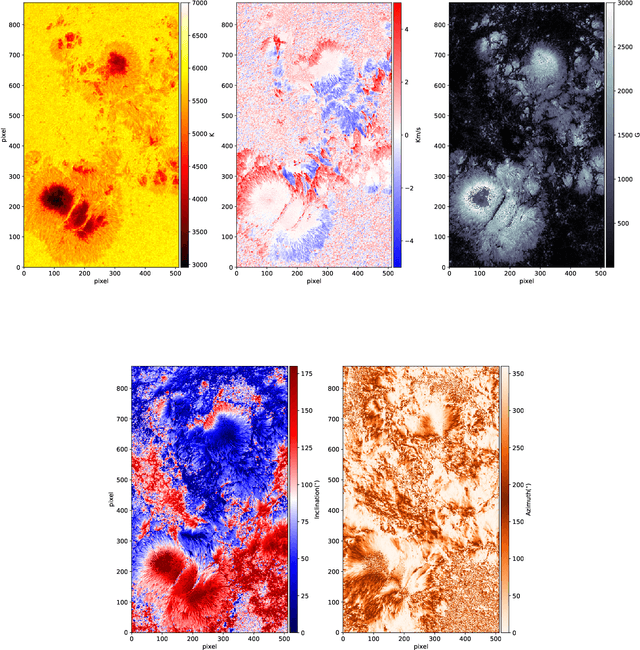
In this work, we discuss the application of convolutional neural networks (CNNs) as a tool to advantageously initialize Stokes profile inversions. To demonstrate the usefulness of CNNs, we concentrate in this paper on the inversion of LTE Stokes profiles. We use observations taken with the spectropolarimeter onboard the Hinode spacecraft as a test benchmark. First, we carefully analyze the data with the SIR inversion code using a given initial atmospheric model. The code provides a set of atmospheric models that reproduce the observations. These models are then used to train a CNN. Afterwards, the same data are again inverted with SIR but using the trained CNN to provide the initial guess atmospheric models for SIR. The CNNs allow us to significantly reduce the number of inversion cycles when used to compute initial guess model atmospheres, decreasing the computational time for LTE inversions by a factor of two to four. CNN's alone are much faster than assisted inversions, but the latter are more robust and accurate. The advantages and limitations of machine learning techniques for estimating optimum initial atmospheric models for spectral line inversions are discussed. Finally, we describe a python wrapper for the SIR and DeSIRe codes that allows for the easy setup of parallel inversions. The assisted inversions can speed up the inversion process, but the efficiency and accuracy of the inversion results depend strongly on the solar scene and the data used for the CNN training. This method (assisted inversions) will not obviate the need for analyzing individual events with the utmost care but will provide solar scientists with a much better opportunity to sample large amounts of inverted data, which will undoubtedly broaden the physical discovery space.
Image Representations Learned With Unsupervised Pre-Training Contain Human-like Biases
Oct 28, 2020
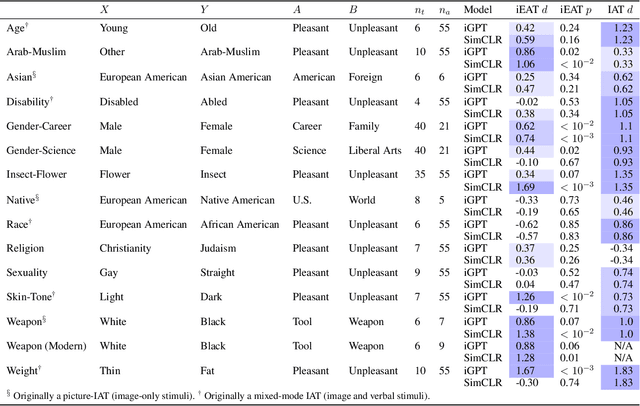
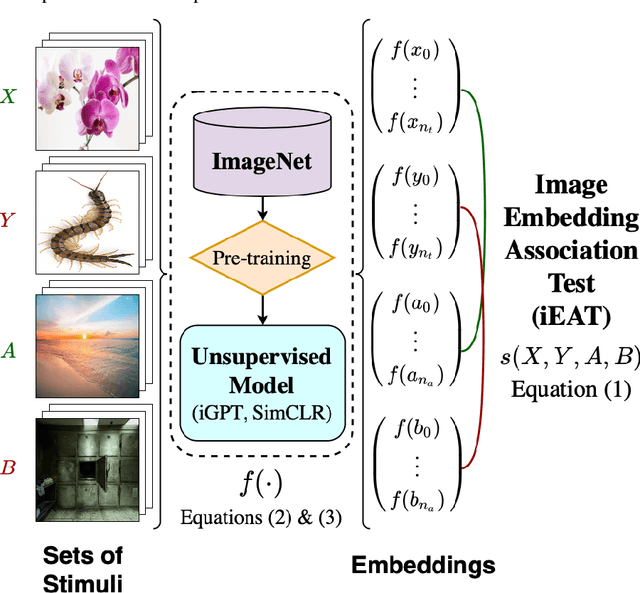
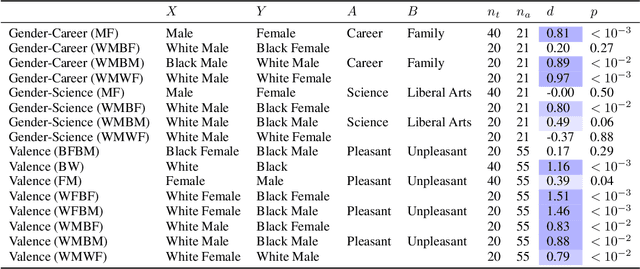
Recent advances in machine learning leverage massive datasets of unlabeled images from the web to learn general-purpose image representations for tasks from image classification to face recognition. But do unsupervised computer vision models automatically learn implicit patterns and embed social biases that could have harmful downstream effects? For the first time, we develop a novel method for quantifying biased associations between representations of social concepts and attributes in images. We find that state-of-the-art unsupervised models trained on ImageNet, a popular benchmark image dataset curated from internet images, automatically learn racial, gender, and intersectional biases. We replicate 8 of 15 documented human biases from social psychology, from the innocuous, as with insects and flowers, to the potentially harmful, as with race and gender. For the first time in the image domain, we replicate human-like biases about skin-tone and weight. Our results also closely match three hypotheses about intersectional bias from social psychology. When compared with statistical patterns in online image datasets, our findings suggest that machine learning models can automatically learn bias from the way people are stereotypically portrayed on the web.
AQuA: Analytical Quality Assessment for Optimizing Video Analytics Systems
Jan 24, 2021
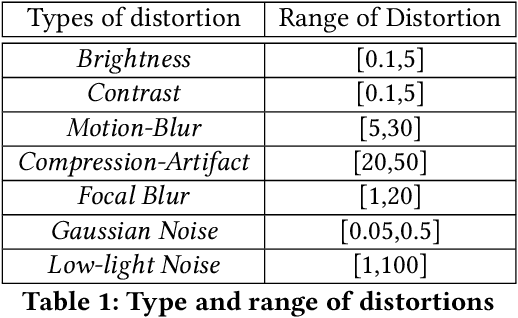

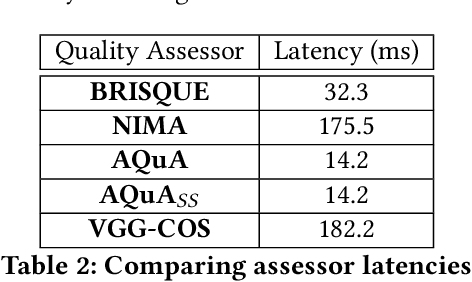
Millions of cameras at edge are being deployed to power a variety of different deep learning applications. However, the frames captured by these cameras are not always pristine - they can be distorted due to lighting issues, sensor noise, compression etc. Such distortions not only deteriorate visual quality, they impact the accuracy of deep learning applications that process such video streams. In this work, we introduce AQuA, to protect application accuracy against such distorted frames by scoring the level of distortion in the frames. It takes into account the analytical quality of frames, not the visual quality, by learning a novel metric, classifier opinion score, and uses a lightweight, CNN-based, object-independent feature extractor. AQuA accurately scores distortion levels of frames and generalizes to multiple different deep learning applications. When used for filtering poor quality frames at edge, it reduces high-confidence errors for analytics applications by 17%. Through filtering, and due to its low overhead (14ms), AQuA can also reduce computation time and average bandwidth usage by 25%.
A comparative evaluation of machine learning methods for robot navigation through human crowds
Dec 16, 2020

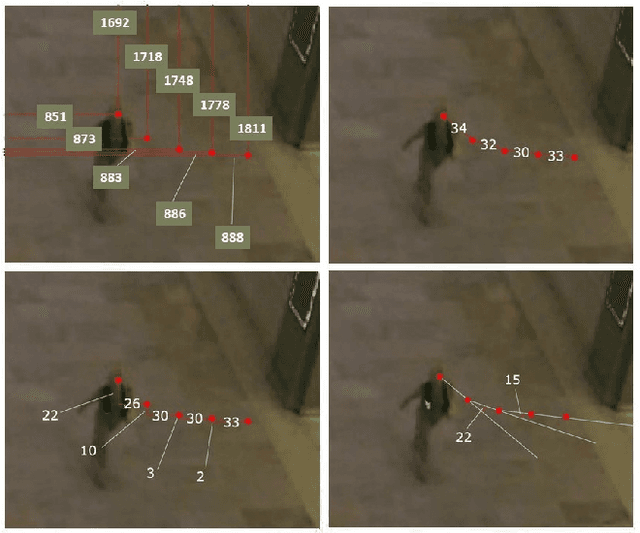
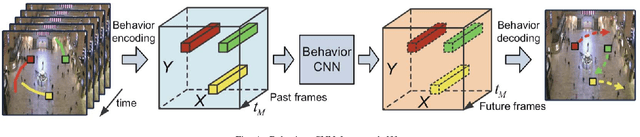
Robot navigation through crowds poses a difficult challenge to AI systems, since the methods should result in fast and efficient movement but at the same time are not allowed to compromise safety. Most approaches to date were focused on the combination of pathfinding algorithms with machine learning for pedestrian walking prediction. More recently, reinforcement learning techniques have been proposed in the research literature. In this paper, we perform a comparative evaluation of pathfinding/prediction and reinforcement learning approaches on a crowd movement dataset collected from surveillance videos taken at Grand Central Station in New York. The results demonstrate the strong superiority of state-of-the-art reinforcement learning approaches over pathfinding with state-of-the-art behaviour prediction techniques.
A Structure-Aware Method for Direct Pose Estimation
Dec 22, 2020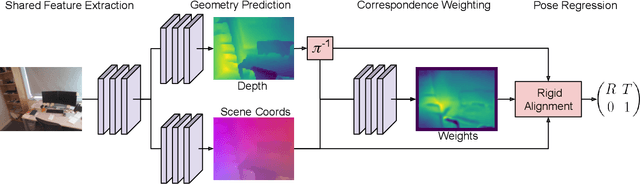
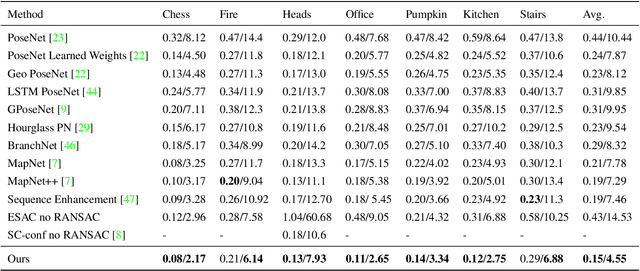
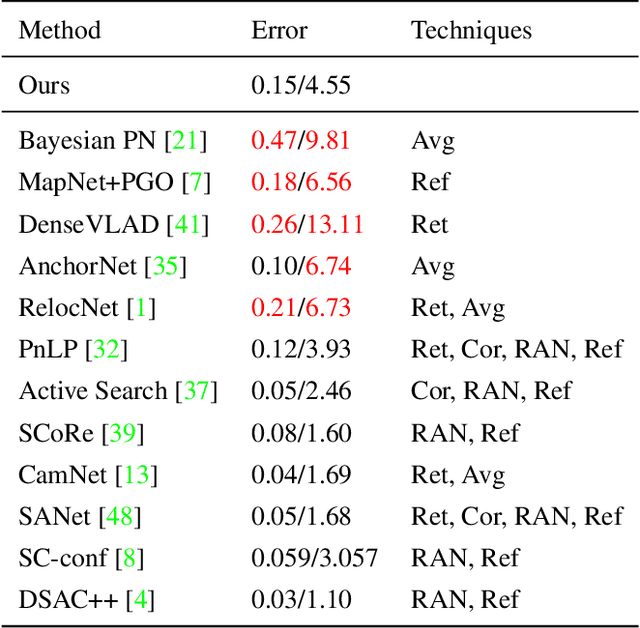
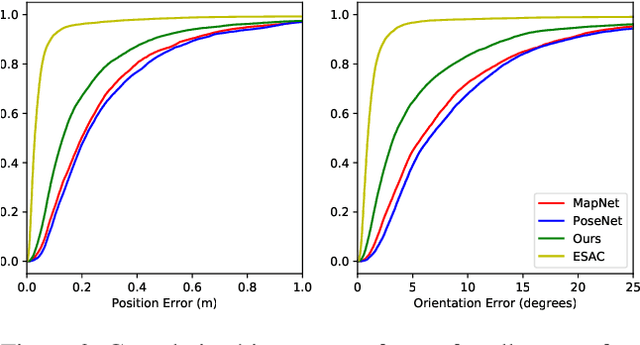
Estimating camera pose from a single image is a fundamental problem in computer vision. Existing methods for solving this task fall into two distinct categories, which we refer to as direct and indirect. Direct methods, such as PoseNet, regress pose from the image as a fixed function, for example using a feed-forward convolutional network. Such methods are desirable because they are deterministic and run in constant time. Indirect methods for pose regression are often non-deterministic, with various external dependencies such as image retrieval and hypothesis sampling. We propose a direct method that takes inspiration from structure-based approaches to incorporate explicit 3D constraints into the network. Our approach maintains the desirable qualities of other direct methods while achieving much lower error in general.