 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
EmMixformer: Mix transformer for eye movement recognition
Jan 10, 2024
Eye movement (EM) is a new highly secure biometric behavioral modality that has received increasing attention in recent years. Although deep neural networks, such as convolutional neural network (CNN), have recently achieved promising performance, current solutions fail to capture local and global temporal dependencies within eye movement data. To overcome this problem, we propose in this paper a mixed transformer termed EmMixformer to extract time and frequency domain information for eye movement recognition. To this end, we propose a mixed block consisting of three modules, transformer, attention Long short-term memory (attention LSTM), and Fourier transformer. We are the first to attempt leveraging transformer to learn long temporal dependencies within eye movement. Second, we incorporate the attention mechanism into LSTM to propose attention LSTM with the aim to learn short temporal dependencies. Third, we perform self attention in the frequency domain to learn global features. As the three modules provide complementary feature representations in terms of local and global dependencies, the proposed EmMixformer is capable of improving recognition accuracy. The experimental results on our eye movement dataset and two public eye movement datasets show that the proposed EmMixformer outperforms the state of the art by achieving the lowest verification error.
Invariant Causal Prediction with Locally Linear Models
Jan 10, 2024We consider the task of identifying the causal parents of a target variable among a set of candidate variables from observational data. Our main assumption is that the candidate variables are observed in different environments which may, for example, correspond to different settings of a machine or different time intervals in a dynamical process. Under certain assumptions different environments can be regarded as interventions on the observed system. We assume a linear relationship between target and covariates, which can be different in each environment with the only restriction that the causal structure is invariant across environments. This is an extension of the ICP ($\textbf{I}$nvariant $\textbf{C}$ausal $\textbf{P}$rediction) principle by Peters et al. [2016], who assumed a fixed linear relationship across all environments. Within our proposed setting we provide sufficient conditions for identifiability of the causal parents and introduce a practical method called LoLICaP ($\textbf{Lo}$cally $\textbf{L}$inear $\textbf{I}$nvariant $\textbf{Ca}$usal $\textbf{P}$rediction), which is based on a hypothesis test for parent identification using a ratio of minimum and maximum statistics. We then show in a simplified setting that the statistical power of LoLICaP converges exponentially fast in the sample size, and finally we analyze the behavior of LoLICaP experimentally in more general settings.
Mutual Information as Intrinsic Reward of Reinforcement Learning Agents for On-demand Ride Pooling
Jan 07, 2024The emergence of on-demand ride pooling services allows each vehicle to serve multiple passengers at a time, thus increasing drivers' income and enabling passengers to travel at lower prices than taxi/car on-demand services (only one passenger can be assigned to a car at a time like UberX and Lyft). Although on-demand ride pooling services can bring so many benefits, ride pooling services need a well-defined matching strategy to maximize the benefits for all parties (passengers, drivers, aggregation companies and environment), in which the regional dispatching of vehicles has a significant impact on the matching and revenue. Existing algorithms often only consider revenue maximization, which makes it difficult for requests with unusual distribution to get a ride. How to increase revenue while ensuring a reasonable assignment of requests brings a challenge to ride pooling service companies (aggregation companies). In this paper, we propose a framework for vehicle dispatching for ride pooling tasks, which splits the city into discrete dispatching regions and uses the reinforcement learning (RL) algorithm to dispatch vehicles in these regions. We also consider the mutual information (MI) between vehicle and order distribution as the intrinsic reward of the RL algorithm to improve the correlation between their distributions, thus ensuring the possibility of getting a ride for unusually distributed requests. In experimental results on a real-world taxi dataset, we demonstrate that our framework can significantly increase revenue up to an average of 3\% over the existing best on-demand ride pooling method.
O-PRESS: Boosting OCT axial resolution with Prior guidance, Recurrence, and Equivariant Self-Supervision
Jan 06, 2024Optical coherence tomography (OCT) is a noninvasive technology that enables real-time imaging of tissue microanatomies. The axial resolution of OCT is intrinsically constrained by the spectral bandwidth of the employed light source while maintaining a fixed center wavelength for a specific application. Physically extending this bandwidth faces strong limitations and requires a substantial cost. We present a novel computational approach, called as O-PRESS, for boosting the axial resolution of OCT with Prior Guidance, a Recurrent mechanism, and Equivariant Self-Supervision. Diverging from conventional superresolution methods that rely on physical models or data-driven techniques, our method seamlessly integrates OCT modeling and deep learning, enabling us to achieve real-time axial-resolution enhancement exclusively from measurements without a need for paired images. Our approach solves two primary tasks of resolution enhancement and noise reduction with one treatment. Both tasks are executed in a self-supervised manner, with equivariance imaging and free space priors guiding their respective processes. Experimental evaluations, encompassing both quantitative metrics and visual assessments, consistently verify the efficacy and superiority of our approach, which exhibits performance on par with fully supervised methods. Importantly, the robustness of our model is affirmed, showcasing its dual capability to enhance axial resolution while concurrently improving the signal-to-noise ratio.
Moving-Horizon Estimators for Hyperbolic and Parabolic PDEs in 1-D
Jan 04, 2024Observers for PDEs are themselves PDEs. Therefore, producing real time estimates with such observers is computationally burdensome. For both finite-dimensional and ODE systems, moving-horizon estimators (MHE) are operators whose output is the state estimate, while their inputs are the initial state estimate at the beginning of the horizon as well as the measured output and input signals over the moving time horizon. In this paper we introduce MHEs for PDEs which remove the need for a numerical solution of an observer PDE in real time. We accomplish this using the PDE backstepping method which, for certain classes of both hyperbolic and parabolic PDEs, produces moving-horizon state estimates explicitly. Precisely, to explicitly produce the state estimates, we employ a backstepping transformation of a hard-to-solve observer PDE into a target observer PDE, which is explicitly solvable. The MHEs we propose are not new observer designs but simply the explicit MHE realizations, over a moving horizon of arbitrary length, of the existing backstepping observers. Our PDE MHEs lack the optimality of the MHEs that arose as duals of MPC, but they are given explicitly, even for PDEs. In the paper we provide explicit formulae for MHEs for both hyperbolic and parabolic PDEs, as well as simulation results that illustrate theoretically guaranteed convergence of the MHEs.
A Wireless Ear EEG Drowsiness Monitor
Jan 11, 2024Wireless, neural wearables can enable life-saving drowsiness, cognitive, and health monitoring for heavy machinery operators, pilots, and drivers. While existing systems use in-cabin sensors to alert operators before accidents, wearables may enable monitoring across many user environments. Current neural wearables are promising but limited by consumable electrodes and bulky, wired electronics. To improve neural wearable usability, scalability, and enable discreet use in daily and itinerant environments, this work showcases the end-to-end design of the first wireless, in-ear, dry-electrode drowsiness monitoring platform. The proposed platform integrates additive manufacturing processes for gold-plated dry electrodes, user-generic earpiece designs, wireless electronics, and low-complexity machine learning algorithms. To evaluate the platform, thirty-five hours of ExG data were recorded across nine subjects performing repetitive drowsiness-inducing tasks. The data was used to train three, offline classifier models (logistic regression, support vector machine, and random forest) and evaluated with three training regimes (user-specific, leave-one-trial-out, and leave-one-user-out). The support vector machine classifier achieved an average accuracy of 93.2% while evaluating users it has seen before and 93.3% when evaluating a never-before-seen user. These results demonstrate for the first time that dry, 3D printed, user-generic electrodes can be used with wireless electronics to rapidly prototype wearable systems and achieve comparable average accuracy (>90%) to existing state-of-the-art in-ear and scalp ExG systems that utilize wet electrodes and wired, benchtop electronics. Further, this work demonstrates the feasibility of using population-trained machine learning models in future, wearable ear ExG applications focused on cognitive health and wellness tracking.
Setting the Record Straight on Transformer Oversmoothing
Jan 09, 2024Transformer-based models have recently become wildly successful across a diverse set of domains. At the same time, recent work has shown that Transformers are inherently low-pass filters that gradually oversmooth the inputs, reducing the expressivity of their representations. A natural question is: How can Transformers achieve these successes given this shortcoming? In this work we show that in fact Transformers are not inherently low-pass filters. Instead, whether Transformers oversmooth or not depends on the eigenspectrum of their update equations. Our analysis extends prior work in oversmoothing and in the closely-related phenomenon of rank collapse. We show that many successful Transformer models have attention and weights which satisfy conditions that avoid oversmoothing. Based on this analysis, we derive a simple way to parameterize the weights of the Transformer update equations that allows for control over its spectrum, ensuring that oversmoothing does not occur. Compared to a recent solution for oversmoothing, our approach improves generalization, even when training with more layers, fewer datapoints, and data that is corrupted.
Physics-informed Neural Networks for Encoding Dynamics in Real Physical Systems
Jan 07, 2024This dissertation investigates physics-informed neural networks (PINNs) as candidate models for encoding governing equations, and assesses their performance on experimental data from two different systems. The first system is a simple nonlinear pendulum, and the second is 2D heat diffusion across the surface of a metal block. We show that for the pendulum system the PINNs outperformed equivalent uninformed neural networks (NNs) in the ideal data case, with accuracy improvements of 18x and 6x for 10 linearly-spaced and 10 uniformly-distributed random training points respectively. In similar test cases with real data collected from an experiment, PINNs outperformed NNs with 9.3x and 9.1x accuracy improvements for 67 linearly-spaced and uniformly-distributed random points respectively. For the 2D heat diffusion, we show that both PINNs and NNs do not fare very well in reconstructing the heating regime due to difficulties in optimizing the network parameters over a large domain in both time and space. We highlight that data denoising and smoothing, reducing the size of the optimization problem, and using LBFGS as the optimizer are all ways to improve the accuracy of the predicted solution for both PINNs and NNs. Additionally, we address the viability of deploying physics-informed models within physical systems, and we choose FPGAs as the compute substrate for deployment. In light of this, we perform our experiments using a PYNQ-Z1 FPGA and identify issues related to time-coherent sensing and spatial data alignment. We discuss the insights gained from this work and list future work items based on the proposed architecture for the system that our methods work to develop.
Prediction of rare events in the operation of household equipment using co-evolving time series
Dec 15, 2023
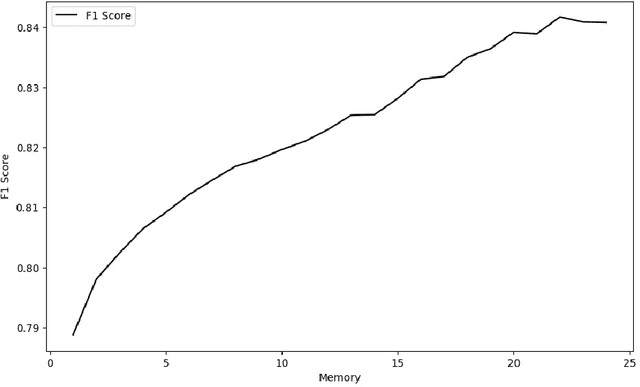
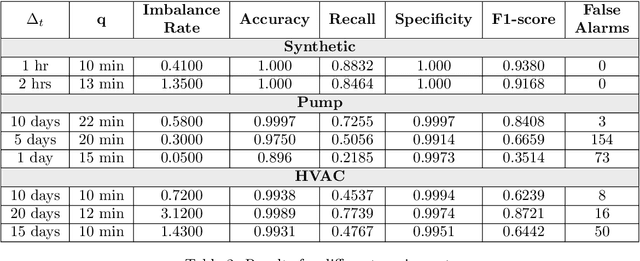
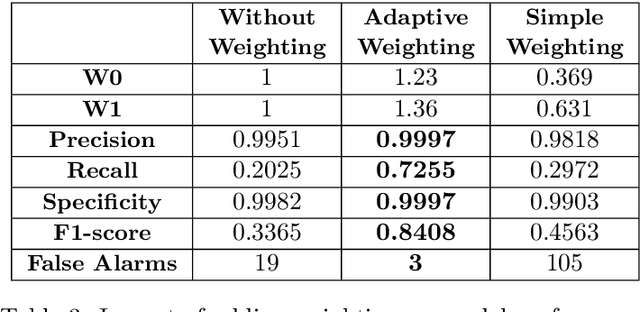
In this study, we propose an approach for predicting rare events by exploiting time series in coevolution. Our approach involves a weighted autologistic regression model, where we leverage the temporal behavior of the data to enhance predictive capabilities. By addressing the issue of imbalanced datasets, we establish constraints leading to weight estimation and to improved performance. Evaluation on synthetic and real-world datasets confirms that our approach outperform state-of-the-art of predicting home equipment failure methods.
An Augmented Surprise-guided Sequential Learning Framework for Predicting the Melt Pool Geometry
Jan 10, 2024Metal Additive Manufacturing (MAM) has reshaped the manufacturing industry, offering benefits like intricate design, minimal waste, rapid prototyping, material versatility, and customized solutions. However, its full industry adoption faces hurdles, particularly in achieving consistent product quality. A crucial aspect for MAM's success is understanding the relationship between process parameters and melt pool characteristics. Integrating Artificial Intelligence (AI) into MAM is essential. Traditional machine learning (ML) methods, while effective, depend on large datasets to capture complex relationships, a significant challenge in MAM due to the extensive time and resources required for dataset creation. Our study introduces a novel surprise-guided sequential learning framework, SurpriseAF-BO, signaling a significant shift in MAM. This framework uses an iterative, adaptive learning process, modeling the dynamics between process parameters and melt pool characteristics with limited data, a key benefit in MAM's cyber manufacturing context. Compared to traditional ML models, our sequential learning method shows enhanced predictive accuracy for melt pool dimensions. Further improving our approach, we integrated a Conditional Tabular Generative Adversarial Network (CTGAN) into our framework, forming the CT-SurpriseAF-BO. This produces synthetic data resembling real experimental data, improving learning effectiveness. This enhancement boosts predictive precision without requiring additional physical experiments. Our study demonstrates the power of advanced data-driven techniques in cyber manufacturing and the substantial impact of sequential AI and ML, particularly in overcoming MAM's traditional challenges.