 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Causality: Synthesis of Large-Scale Causal Networks from High-Dimensional Time Series Data
May 06, 2019
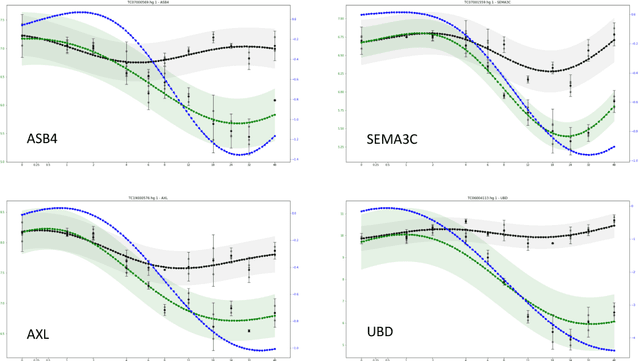
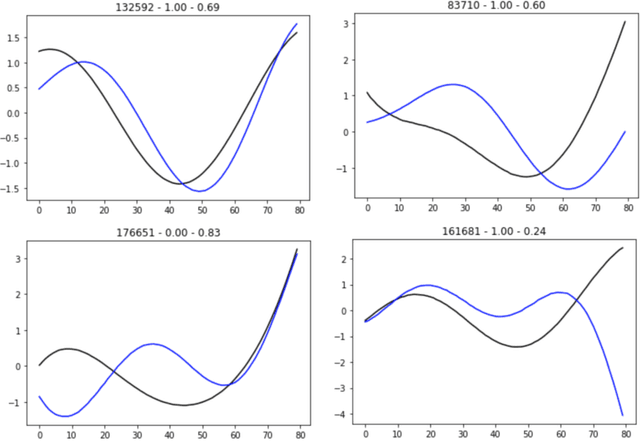
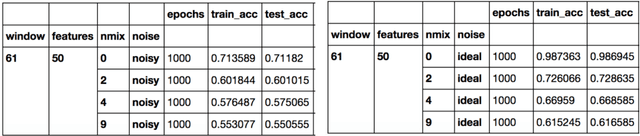
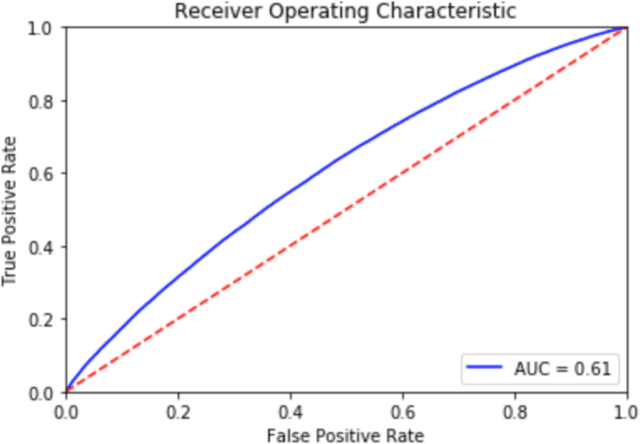
There is an abundance of complex dynamic systems that are critical to our daily lives and our society but that are hardly understood, and even with today's possibilities to sense and collect large amounts of experimental data, they are so complex and continuously evolving that it is unlikely that their dynamics will ever be understood in full detail. Nevertheless, through computational tools we can try to make the best possible use of the current technologies and available data. We believe that the most useful models will have to take into account the imbalance between system complexity and available data in the context of limited knowledge or multiple hypotheses. The complex system of biological cells is a prime example of such a system that is studied in systems biology and has motivated the methods presented in this paper. They were developed as part of the DARPA Rapid Threat Assessment (RTA) program, which is concerned with understanding of the mechanism of action (MoA) of toxins or drugs affecting human cells. Using a combination of Gaussian processes and abstract network modeling, we present three fundamentally different machine-learning-based approaches to learn causal relations and synthesize causal networks from high-dimensional time series data. While other types of data are available and have been analyzed and integrated in our RTA work, we focus on transcriptomics (that is gene expression) data obtained from high-throughput microarray experiments in this paper to illustrate capabilities and limitations of our algorithms. Our algorithms make different but overall relatively few biological assumptions, so that they are applicable to other types of biological data and potentially even to other complex systems that exhibit high dimensionality but are not of biological nature.
VisuoSpatial Foresight for Physical Sequential Fabric Manipulation
Feb 19, 2021
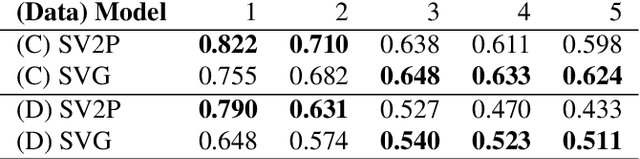
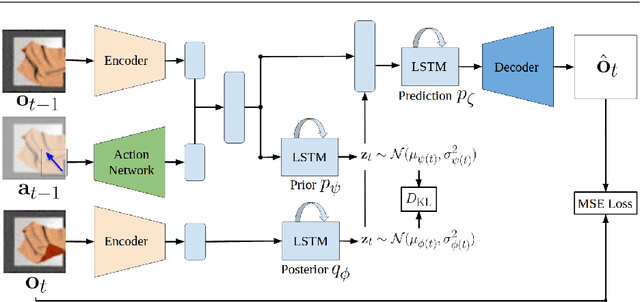
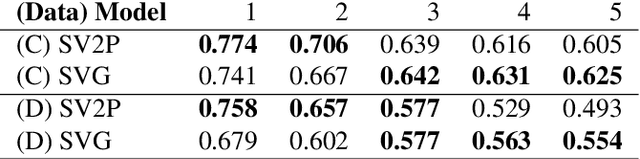
Robotic fabric manipulation has applications in home robotics, textiles, senior care and surgery. Existing fabric manipulation techniques, however, are designed for specific tasks, making it difficult to generalize across different but related tasks. We build upon the Visual Foresight framework to learn fabric dynamics that can be efficiently reused to accomplish different sequential fabric manipulation tasks with a single goal-conditioned policy. We extend our earlier work on VisuoSpatial Foresight (VSF), which learns visual dynamics on domain randomized RGB images and depth maps simultaneously and completely in simulation. In this earlier work, we evaluated VSF on multi-step fabric smoothing and folding tasks against 5 baseline methods in simulation and on the da Vinci Research Kit (dVRK) surgical robot without any demonstrations at train or test time. A key finding was that depth sensing significantly improves performance: RGBD data yields an 80% improvement in fabric folding success rate in simulation over pure RGB data. In this work, we vary 4 components of VSF, including data generation, the choice of visual dynamics model, cost function, and optimization procedure. Results suggest that training visual dynamics models using longer, corner-based actions can improve the efficiency of fabric folding by 76% and enable a physical sequential fabric folding task that VSF could not previously perform with 90% reliability. Code, data, videos, and supplementary material are available at https://sites.google.com/view/fabric-vsf/.
Using Angle of Arrival for Improving Indoor Localization
Jan 25, 2021



In this paper, we primarily explore the improvement of single stream audio systems using Angle of Arrival calculations in both simulation and real life gathered data. We wanted to learn how to discern the direction of an audio source from gathered signal data to ultimately incorporate into a multi modal security system. We focused on the MUSIC algorithm for the estimation of the angle of arrival but briefly experimented with other techniques such as Bartlett and Capo. We were able to implement our own MUSIC algorithm on stimulated data from Cornell. In addition, we demonstrated how we are able to calculate the angle of arrival over time in a real life scene. Finally, we are able to detect the direction of arrival for two separate and simultaneous audio sources in a real life scene. Eventually, we could incorporate this tracking into a multi modal system combined with video. Overall, we are able to produce compelling results for angle of arrival calculations that could be the stepping stones for a better system to detect events in a scene.
Fast Fourier Transformation for Optimizing Convolutional Neural Networks in Object Recognition
Oct 08, 2020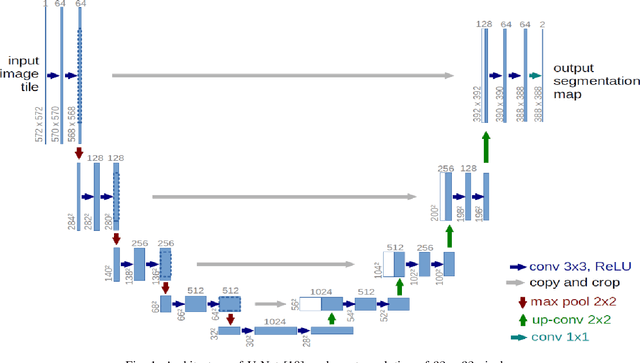
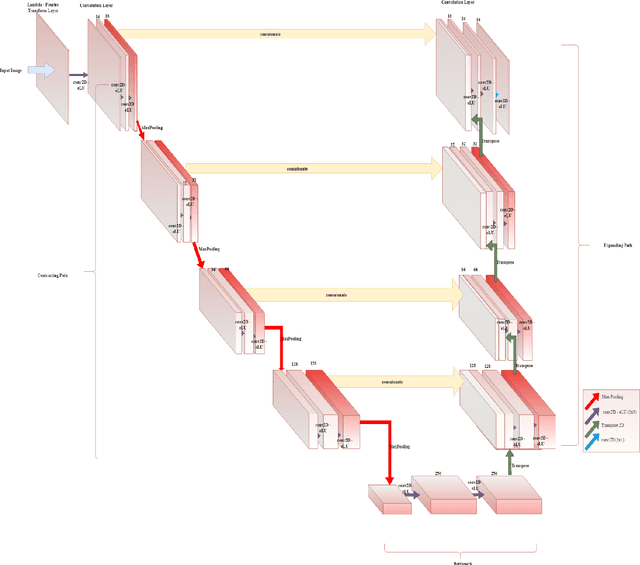
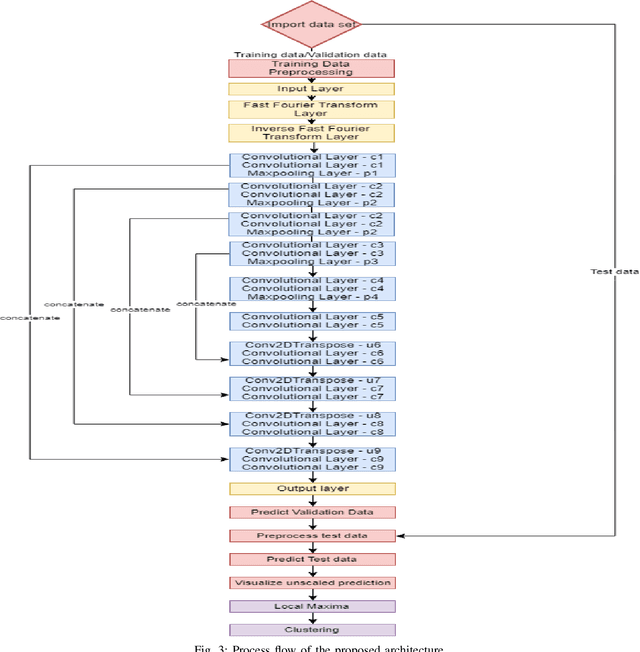

This paper proposes to use Fast Fourier Transformation-based U-Net (a refined fully convolutional networks) and perform image convolution in neural networks. Leveraging the Fast Fourier Transformation, it reduces the image convolution costs involved in the Convolutional Neural Networks (CNNs) and thus reduces the overall computational costs. The proposed model identifies the object information from the images. We apply the Fast Fourier transform algorithm on an image data set to obtain more accessible information about the image data, before segmenting them through the U-Net architecture. More specifically, we implement the FFT-based convolutional neural network to improve the training time of the network. The proposed approach was applied to publicly available Broad Bioimage Benchmark Collection (BBBC) dataset. Our model demonstrated improvement in training time during convolution from $600-700$ ms/step to $400-500$ ms/step. We evaluated the accuracy of our model using Intersection over Union (IoU) metric showing significant improvements.
MadDog: A Web-based System for Acronym Identification and Disambiguation
Jan 25, 2021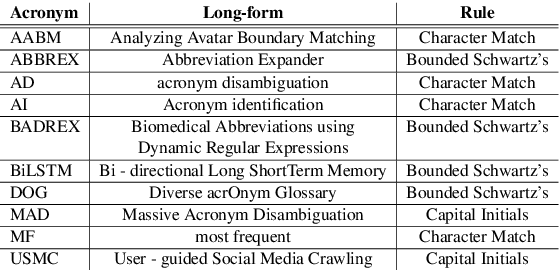

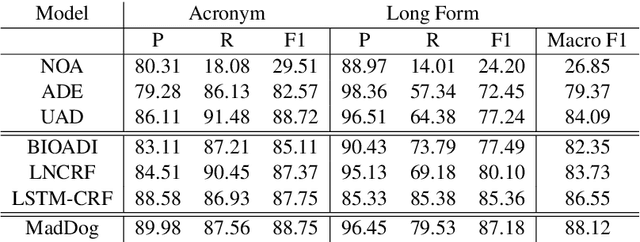
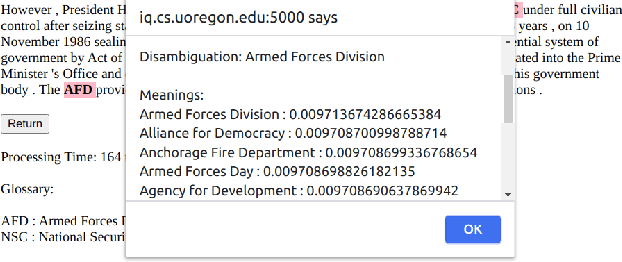
Acronyms and abbreviations are the short-form of longer phrases and they are ubiquitously employed in various types of writing. Despite their usefulness to save space in writing and reader's time in reading, they also provide challenges for understanding the text especially if the acronym is not defined in the text or if it is used far from its definition in long texts. To alleviate this issue, there are considerable efforts both from the research community and software developers to build systems for identifying acronyms and finding their correct meanings in the text. However, none of the existing works provide a unified solution capable of processing acronyms in various domains and to be publicly available. Thus, we provide the first web-based acronym identification and disambiguation system which can process acronyms from various domains including scientific, biomedical, and general domains. The web-based system is publicly available at http://iq.cs.uoregon.edu:5000 and a demo video is available at https://youtu.be/IkSh7LqI42M. The system source code is also available at https://github.com/amirveyseh/MadDog.
Spatiotemporal Imaging with Diffeomorphic Optimal Transportation
Nov 24, 2020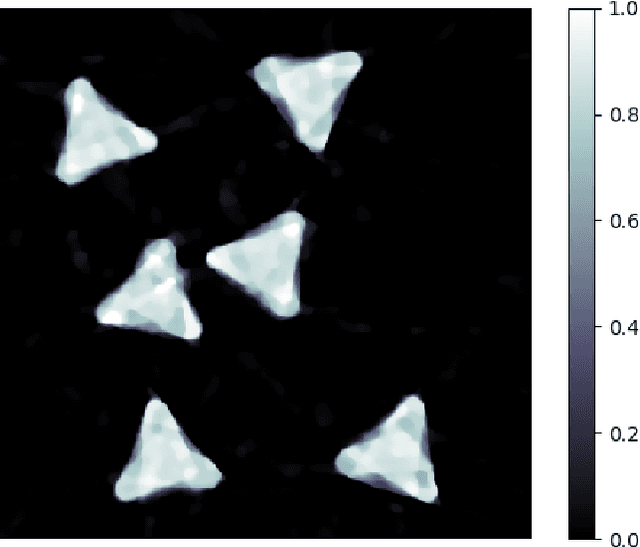

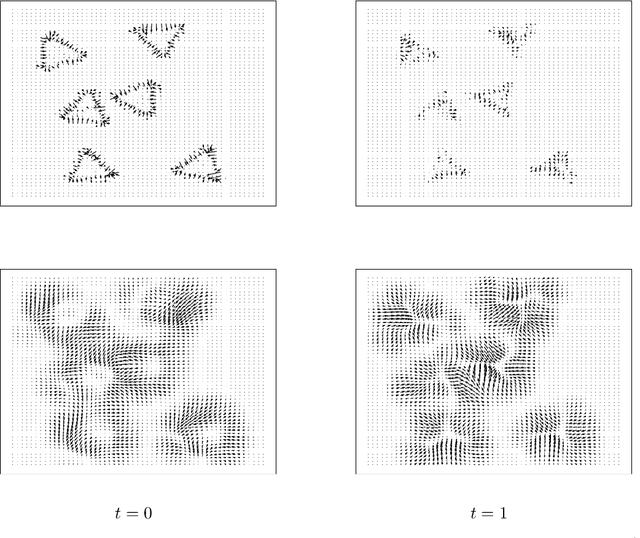
We propose a variational model with diffeomorphic optimal transportation for joint image reconstruction and motion estimation. The proposed model is a production of assembling the Wasserstein distance with the Benamou--Brenier formula in optimal transportation and the flow of diffeomorphisms involved in large deformation diffeomorphic metric mapping, which is suitable for the scenario of spatiotemporal imaging with large diffeomorphic and mass-preserving deformations. Specifically, we first use the Benamou--Brenier formula to characterize the optimal transport cost among the flow of mass-preserving images, and restrict the velocity field into the admissible Hilbert space to guarantee the generated deformation flow being diffeomorphic. We then gain the ODE-constrained equivalent formulation for Benamou--Brenier formula. We finally obtain the proposed model with ODE constraint following the framework that presented in our previous work. We further get the equivalent PDE-constrained optimal control formulation. The proposed model is compared against several existing alternatives theoretically. The alternating minimization algorithm is presented for solving the time-discretized version of the proposed model with ODE constraint. Several important issues on the proposed model and associated algorithms are also discussed. Particularly, we present several potential models based on the proposed diffeomorphic optimal transportation. Under appropriate conditions, the proposed algorithm also provides a new scheme to solve the models using quadratic Wasserstein distance. The performance is finally evaluated by several numerical experiments in space-time tomography, where the data is measured from the concerned sequential images with sparse views and/or various noise levels.
Randomized Ensembled Double Q-Learning: Learning Fast Without a Model
Jan 15, 2021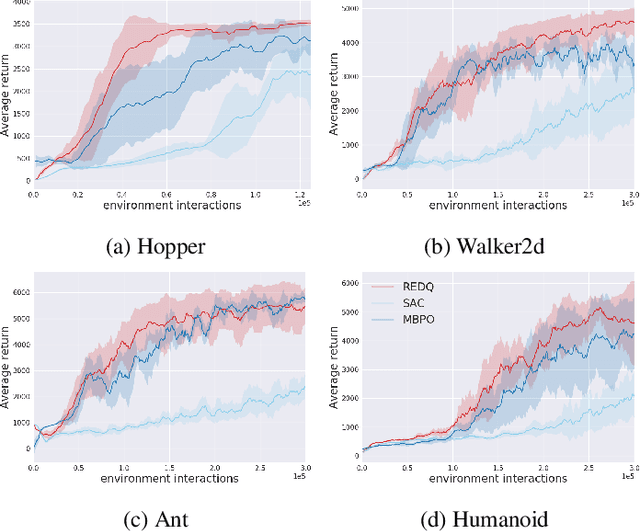
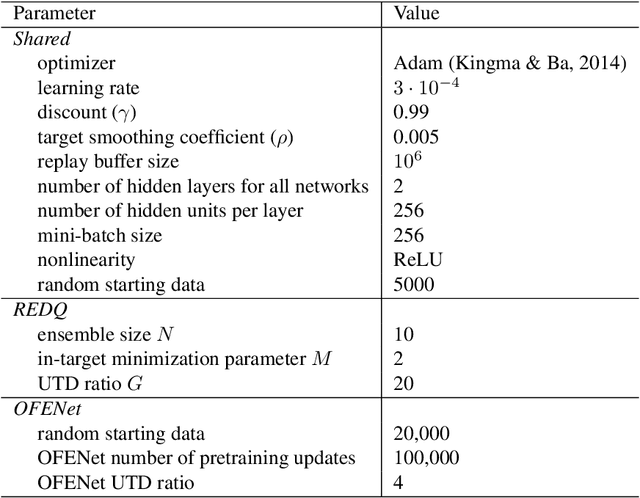
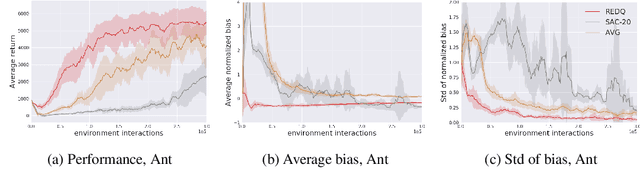

Using a high Update-To-Data (UTD) ratio, model-based methods have recently achieved much higher sample efficiency than previous model-free methods for continuous-action DRL benchmarks. In this paper, we introduce a simple model-free algorithm, Randomized Ensembled Double Q-Learning (REDQ), and show that its performance is just as good as, if not better than, a state-of-the-art model-based algorithm for the MuJoCo benchmark. Moreover, REDQ can achieve this performance using fewer parameters than the model-based method, and with less wall-clock run time. REDQ has three carefully integrated ingredients which allow it to achieve its high performance: (i) a UTD ratio >> 1; (ii) an ensemble of Q functions; (iii) in-target minimization across a random subset of Q functions from the ensemble. Through carefully designed experiments, we provide a detailed analysis of REDQ and related model-free algorithms. To our knowledge, REDQ is the first successful model-free DRL algorithm for continuous-action spaces using a UTD ratio >> 1.
Bridging the Performance Gap between FGSM and PGD Adversarial Training
Nov 07, 2020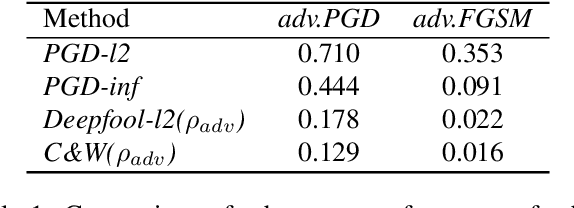

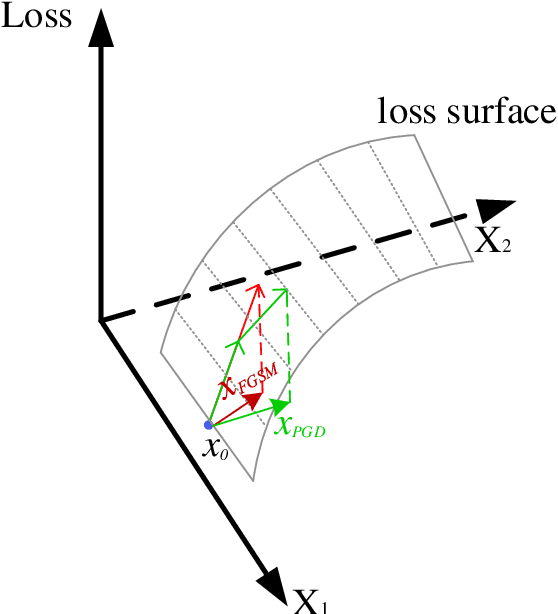

Deep learning achieves state-of-the-art performance in many tasks but exposes to the underlying vulnerability against adversarial examples. Across existing defense techniques, adversarial training with the projected gradient decent attack (adv.PGD) is considered as one of the most effective ways to achieve moderate adversarial robustness. However, adv.PGD requires too much training time since the projected gradient attack (PGD) takes multiple iterations to generate perturbations. On the other hand, adversarial training with the fast gradient sign method (adv.FGSM) takes much less training time since the fast gradient sign method (FGSM) takes one step to generate perturbations but fails to increase adversarial robustness. In this work, we extend adv.FGSM to make it achieve the adversarial robustness of adv.PGD. We demonstrate that the large curvature along FGSM perturbed direction leads to a large difference in performance of adversarial robustness between adv.FGSM and adv.PGD, and therefore propose combining adv.FGSM with a curvature regularization (adv.FGSMR) in order to bridge the performance gap between adv.FGSM and adv.PGD. The experiments show that adv.FGSMR has higher training efficiency than adv.PGD. In addition, it achieves comparable performance of adversarial robustness on MNIST dataset under white-box attack, and it achieves better performance than adv.PGD under white-box attack and effectively defends the transferable adversarial attack on CIFAR-10 dataset.
End-to-End Mispronunciation Detection and Diagnosis From Raw Waveforms
Mar 04, 2021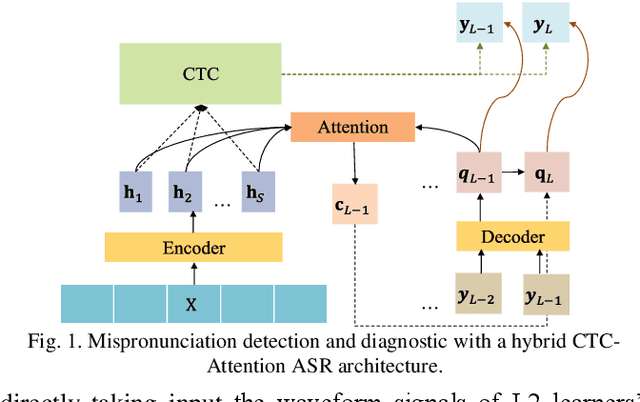
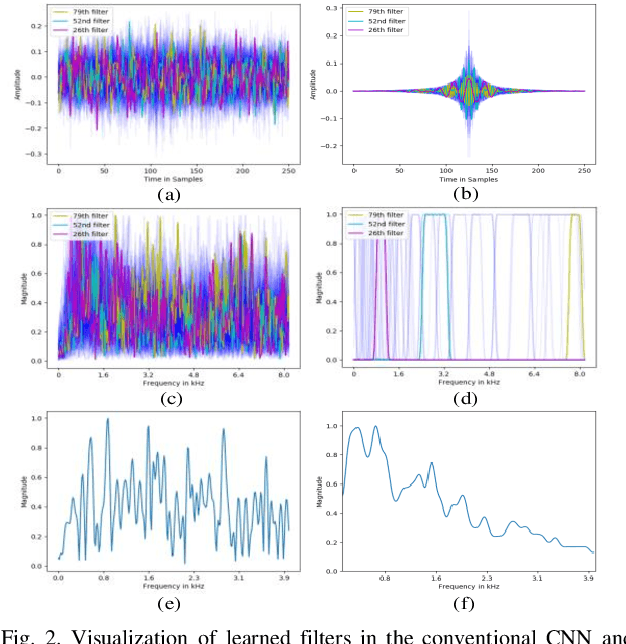
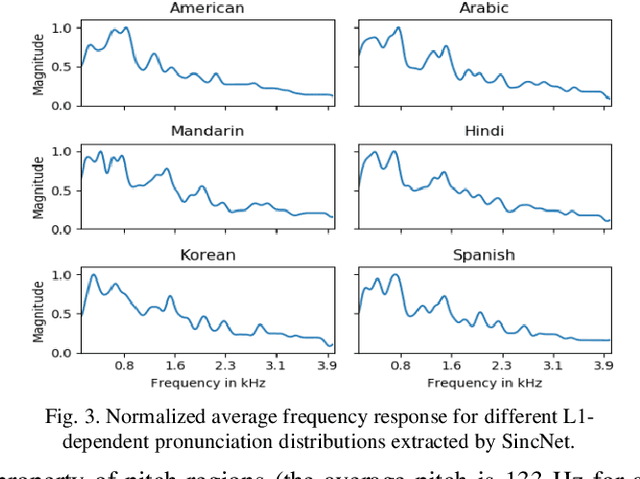
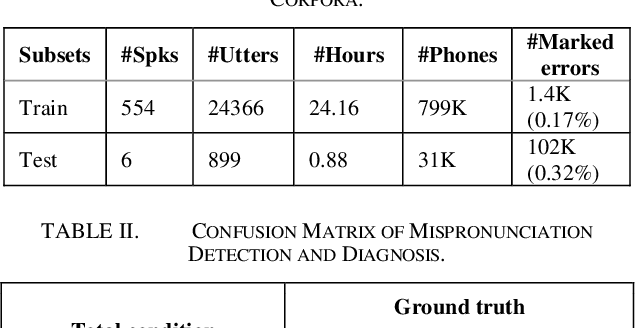
Mispronunciation detection and diagnosis (MDD) is designed to identify pronunciation errors and provide instructive feedback to guide non-native language learners, which is a core component in computer-assisted pronunciation training (CAPT) systems. However, MDD often suffers from the data-sparsity problem due to that collecting non-native data and the associated annotations is time-consuming and labor-intensive. To address this issue, we explore a fully end-to-end (E2E) neural model for MDD, which processes learners' speech directly based on raw waveforms. Compared to conventional hand-crafted acoustic features, raw waveforms retain more acoustic phenomena and potentially can help neural networks discover better and more customized representations. To this end, our MDD model adopts a co-called SincNet module to take input a raw waveform and covert it to a suitable vector representation sequence. SincNet employs the cardinal sine (sinc) function to implement learnable bandpass filters, drawing inspiration from the convolutional neural network (CNN). By comparison to CNN, SincNet has fewer parameters and is more amenable to human interpretation. Extensive experiments are conducted on the L2-ARCTIC dataset, which is a publicly-available non-native English speech corpus compiled for research on CAPT. We find that the sinc filters of SincNet can be adapted quickly for non-native language learners of different nationalities. Furthermore, our model can achieve comparable mispronunciation detection performance in relation to state-of-the-art E2E MDD models that take input the standard handcrafted acoustic features. Besides that, our model also provides considerable improvements on phone error rate (PER) and diagnosis accuracy.
Neural-Guided Deductive Search for Real-Time Program Synthesis from Examples
Sep 09, 2018


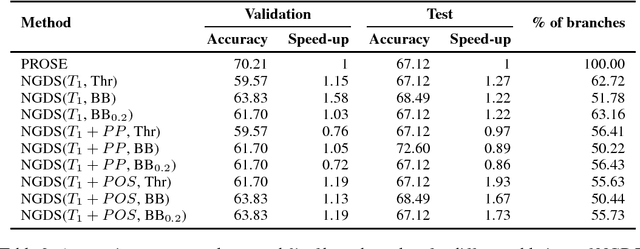
Synthesizing user-intended programs from a small number of input-output examples is a challenging problem with several important applications like spreadsheet manipulation, data wrangling and code refactoring. Existing synthesis systems either completely rely on deductive logic techniques that are extensively hand-engineered or on purely statistical models that need massive amounts of data, and in general fail to provide real-time synthesis on challenging benchmarks. In this work, we propose Neural Guided Deductive Search (NGDS), a hybrid synthesis technique that combines the best of both symbolic logic techniques and statistical models. Thus, it produces programs that satisfy the provided specifications by construction and generalize well on unseen examples, similar to data-driven systems. Our technique effectively utilizes the deductive search framework to reduce the learning problem of the neural component to a simple supervised learning setup. Further, this allows us to both train on sparingly available real-world data and still leverage powerful recurrent neural network encoders. We demonstrate the effectiveness of our method by evaluating on real-world customer scenarios by synthesizing accurate programs with up to 12x speed-up compared to state-of-the-art systems.